Thumbnail Tensor—A Method for Multidimensional Data Streams Clustering with an Efficient Tensor Subspace Model in the Scale-Space †


Abstract
:1. Introduction
2. An Overview of Shot Detection in Video Streams
- Hard cuts—an abrupt change of a content;
- Soft cuts—a gradual change of a content;
- Fade in/out—a new scene gradually appears or disappears from the current image;
- Dissolving—a current shot fades out whereas the incoming one fades in.
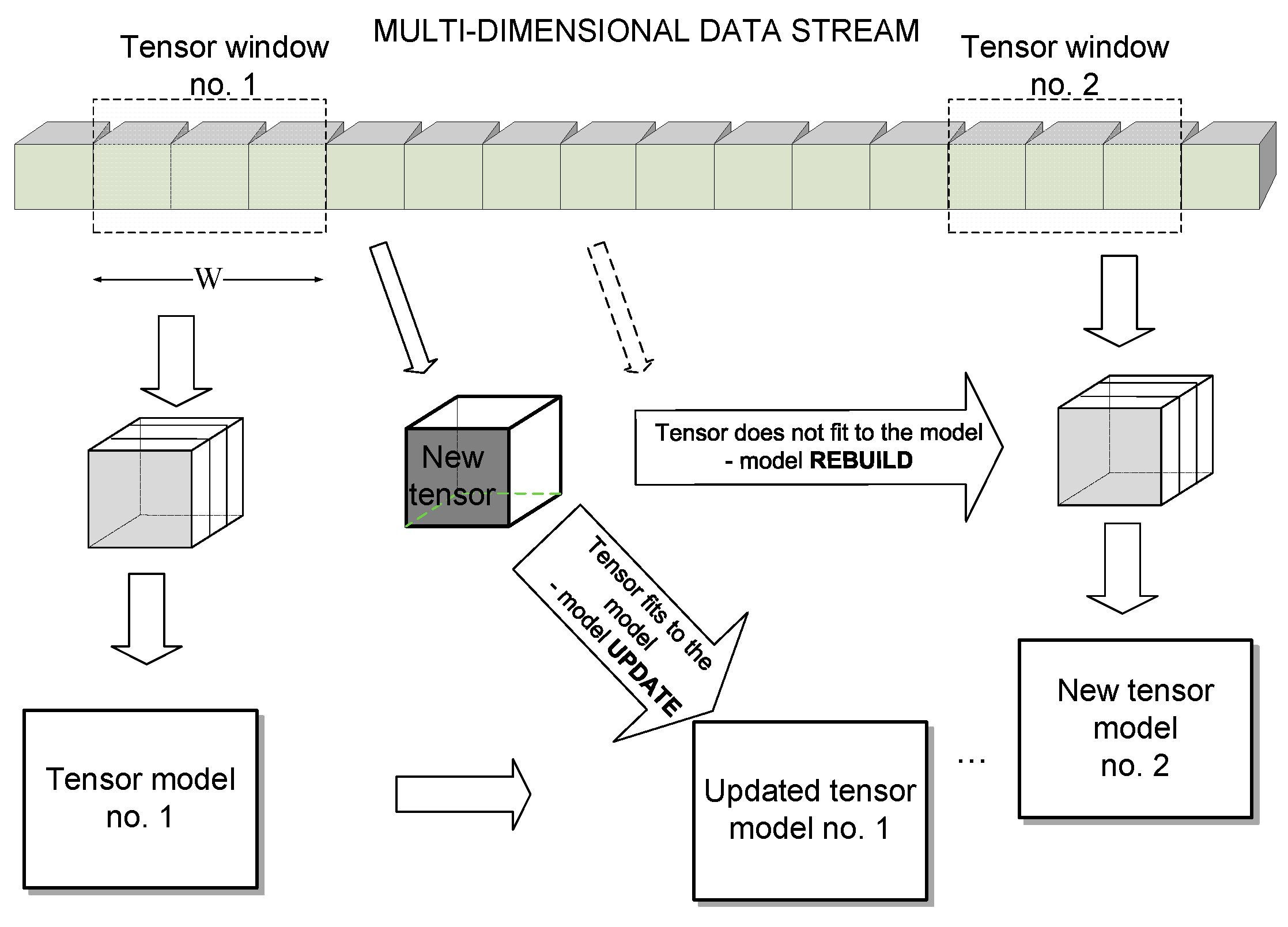
3. A Framework for Multidimensional Data Stream Clustering
4. Construction of the Orthogonal Tensor Subspace (OTS)-Based Model
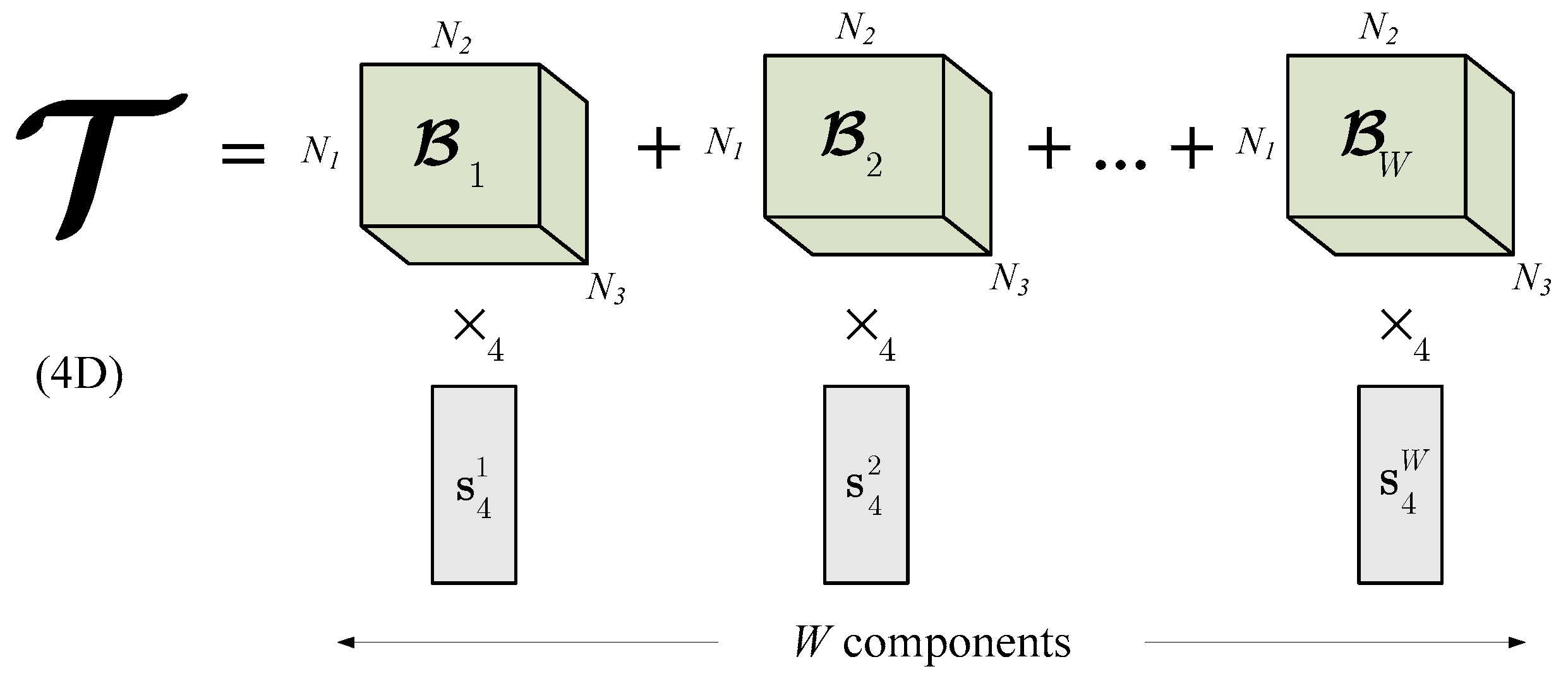
4.1. Higher-Order Singular Value Decomposition (HOSVD) for Data Stream Analysis
- Two sub-tensors and , obtained by fixing the nk index to a, or b, are orthogonal, that is, for all possible values of k for which a ≠ b the following holds:
- All sub-tensors can be ordered according to their Frobenius norms:
- Randomization, by means of a random selection of rows and columns. This is based on the Mersenne uniform twister in order to achieve tensor of given lower dimensions. As shown in recent works by Halko et al. [5], as well as by Zhou et al. [38], such randomization simplifies tensor processing and, even more importantly, allows for the discovery of the low-rank structure in huge tensors.
4.2. Efficient Computation of the Orthogonal Tensor Subspaces
| Algorithm 1. Computation steps of the OTS tensor model building. | |
| Input: | A finite partition of the multi-dimensional data stream from a window W; |
| Output: | An orthogonal tensor subspace (OTS) represented with the base tensors ; |
| 1. | Fill the buffer with W input data and construct scale-space/randomized tensor in (8); |
| 2. | Construct the flattened matrix T(4) of a tensor ; |
| 3. | Compute the product ; |
| 4. | With Algorithm 3 compute the S4 as eigenvectors of the symmetric matrix in (14); |
| 5. | From (12) compute the bases ; |
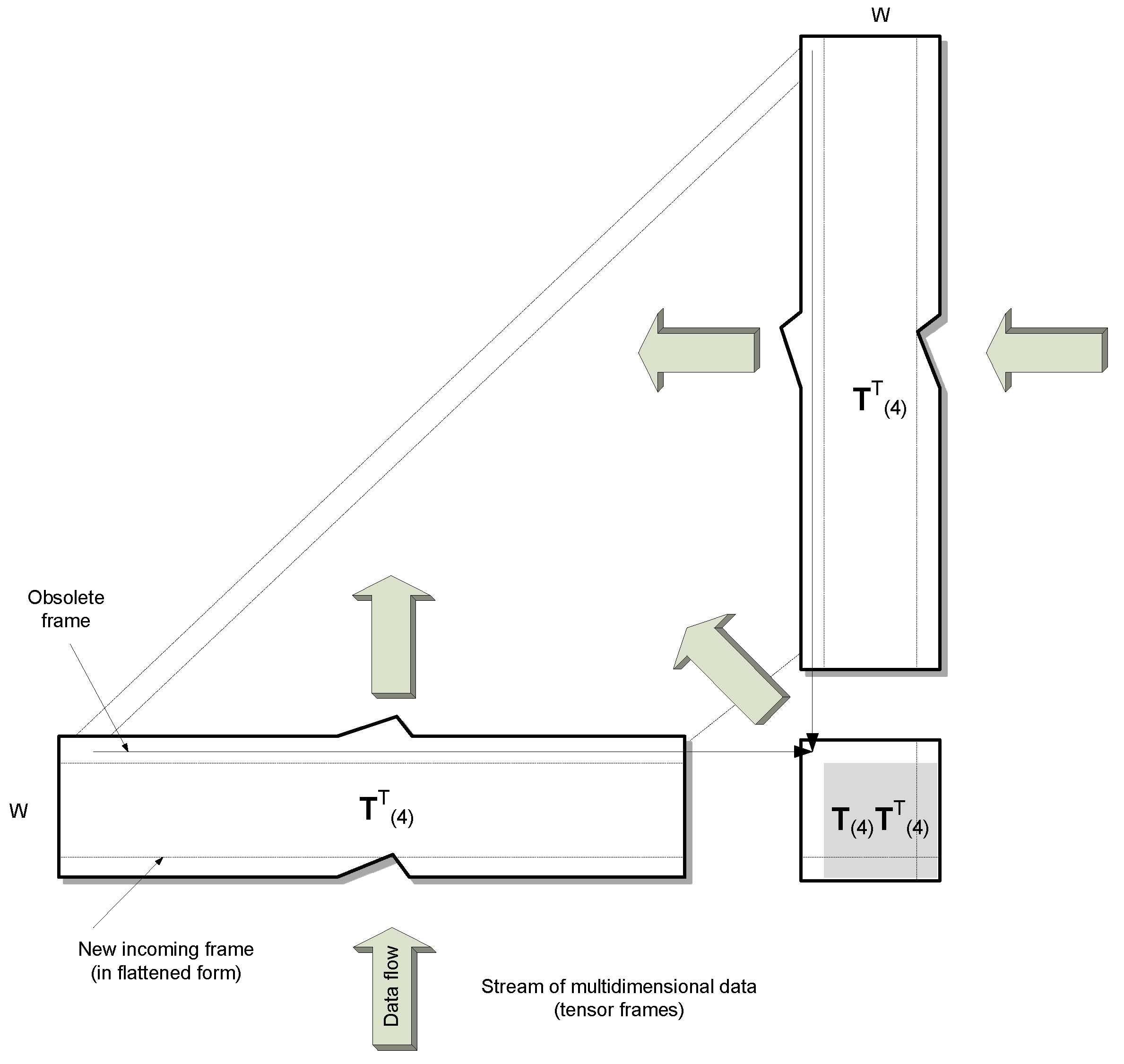
4.3. Model Fitness Measure and Efficient Model Updating Scheme
| Algorithm 2. Tensor model updating algorithm. | |
| Input: | New tensor frame; |
| Output: | New model (bases ); |
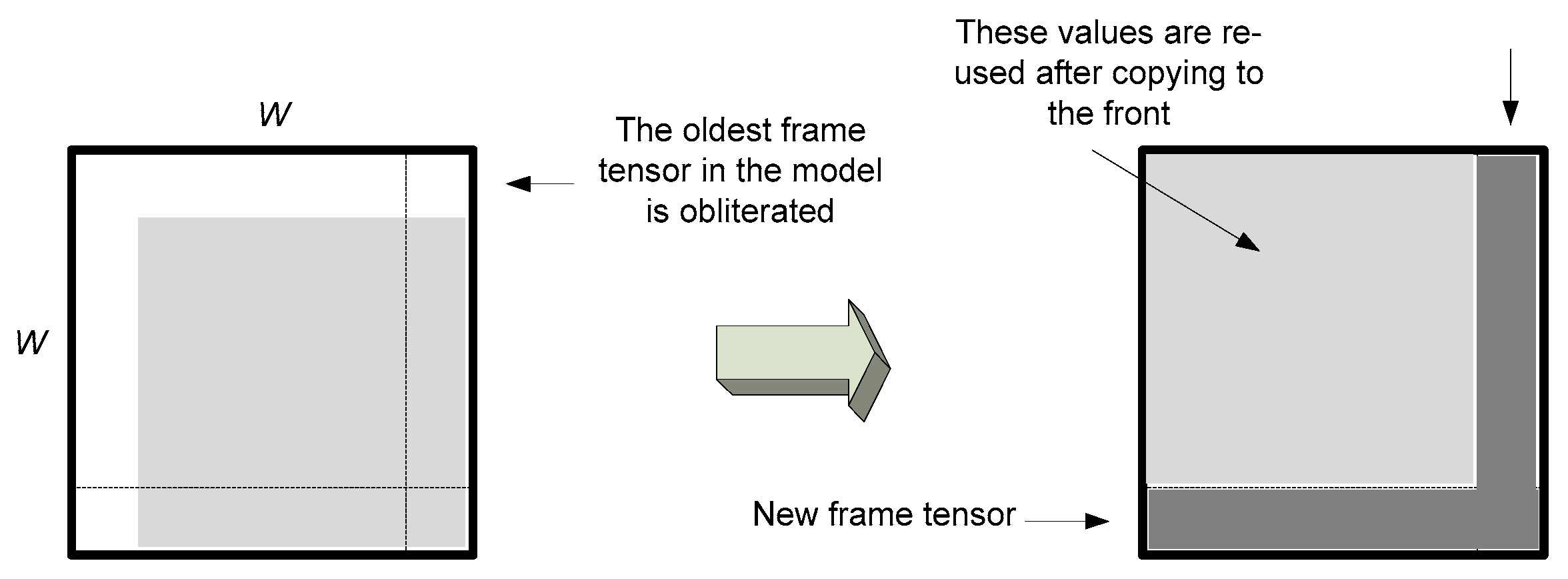
| 1. | Shift data in T(4) by one row up (Figure 4) and fill the last row with flattened version of ; |
| 2. | Shift all data in the old matrix by one row up and to the left (Figure 5); |
| 3. | Fill up the last row and right column in with a product of the flattened and all remaining (old) frames from T(4); |
| 4. | Perform steps 4 and 5 of the model build Algorithm 1; |
4.4. Efficient Computation of the Leading Eigenvectors
| Algorithm 3. An efficient computation of the K leading eigenvectors of a symmetric product matrix P. | |
| Input: | A real symmetric matrix P; A number K of expected eigenvectors: 1 ≤ K ≤ rows(P); A maximal number of iterations imax; An orthogonality threshold ε; |
| Output: | K leading eigenvectors of P; |
| 1. | Randomly initialize ; |
| 2. | Set k ← 0; |
| 3. | Set err ← 2ε; |
| 4. | whilek < K |
| 5. | Set i ← 1; |
| 6. | while and i < imax |
| 7. | |
| 8. | ( normalization) |
| 9. | (Gram-Schmidt) |
| 10. | ( normalization) |
| 11. | |
| 12. | Set i ← i + 1 |
4.5. Computation of the Leading Eigenvectors
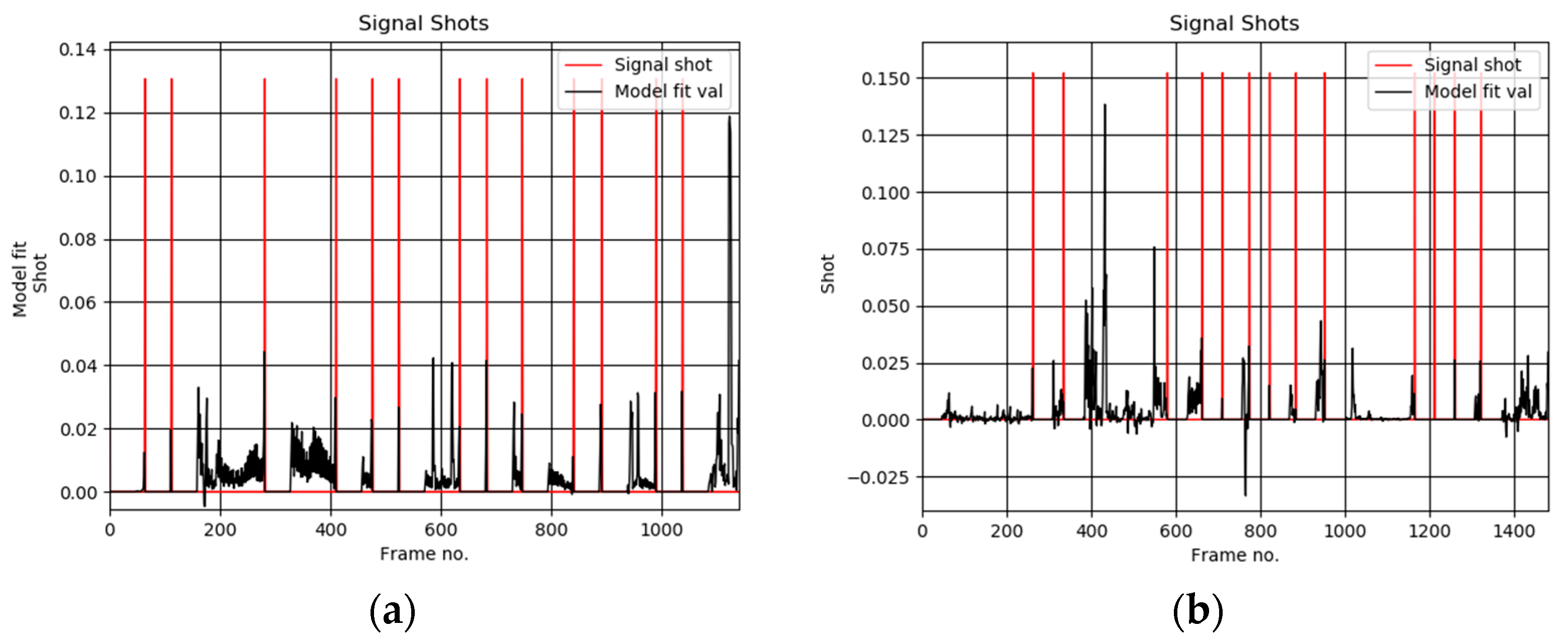
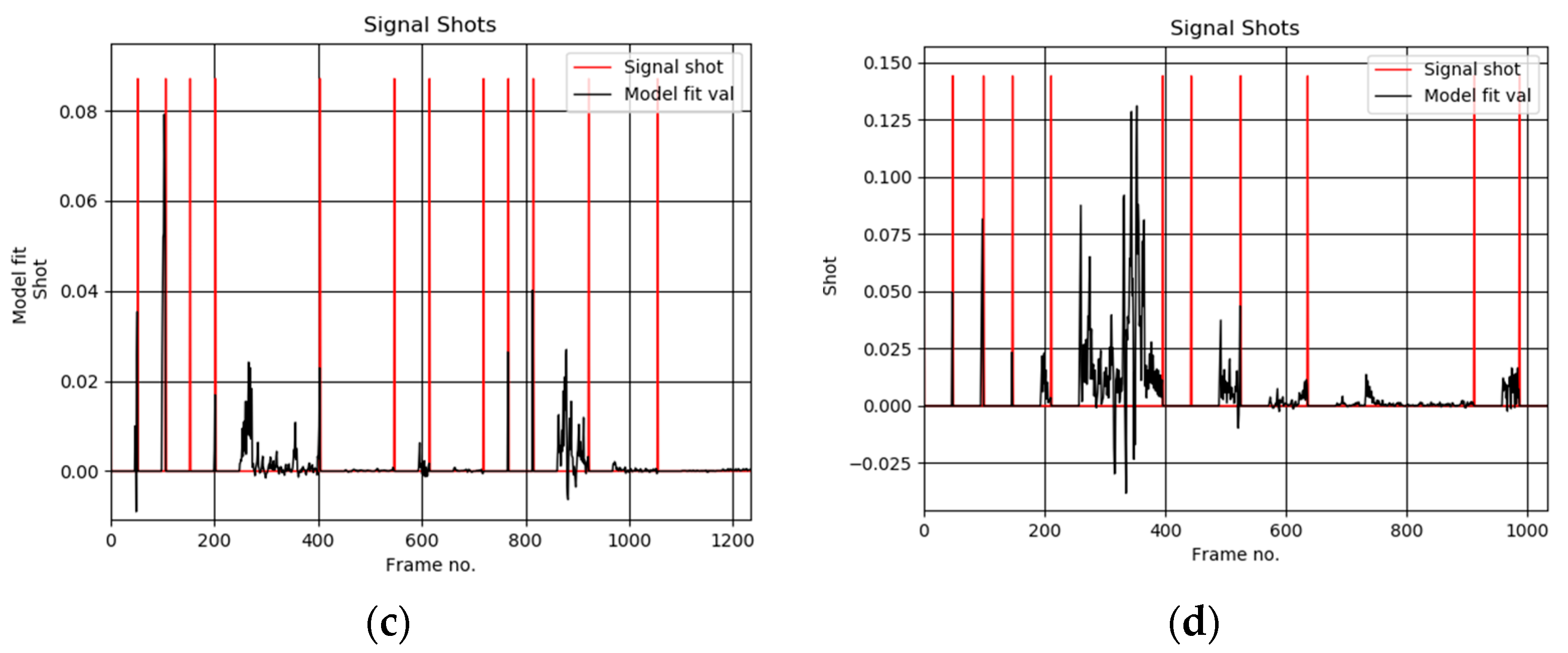
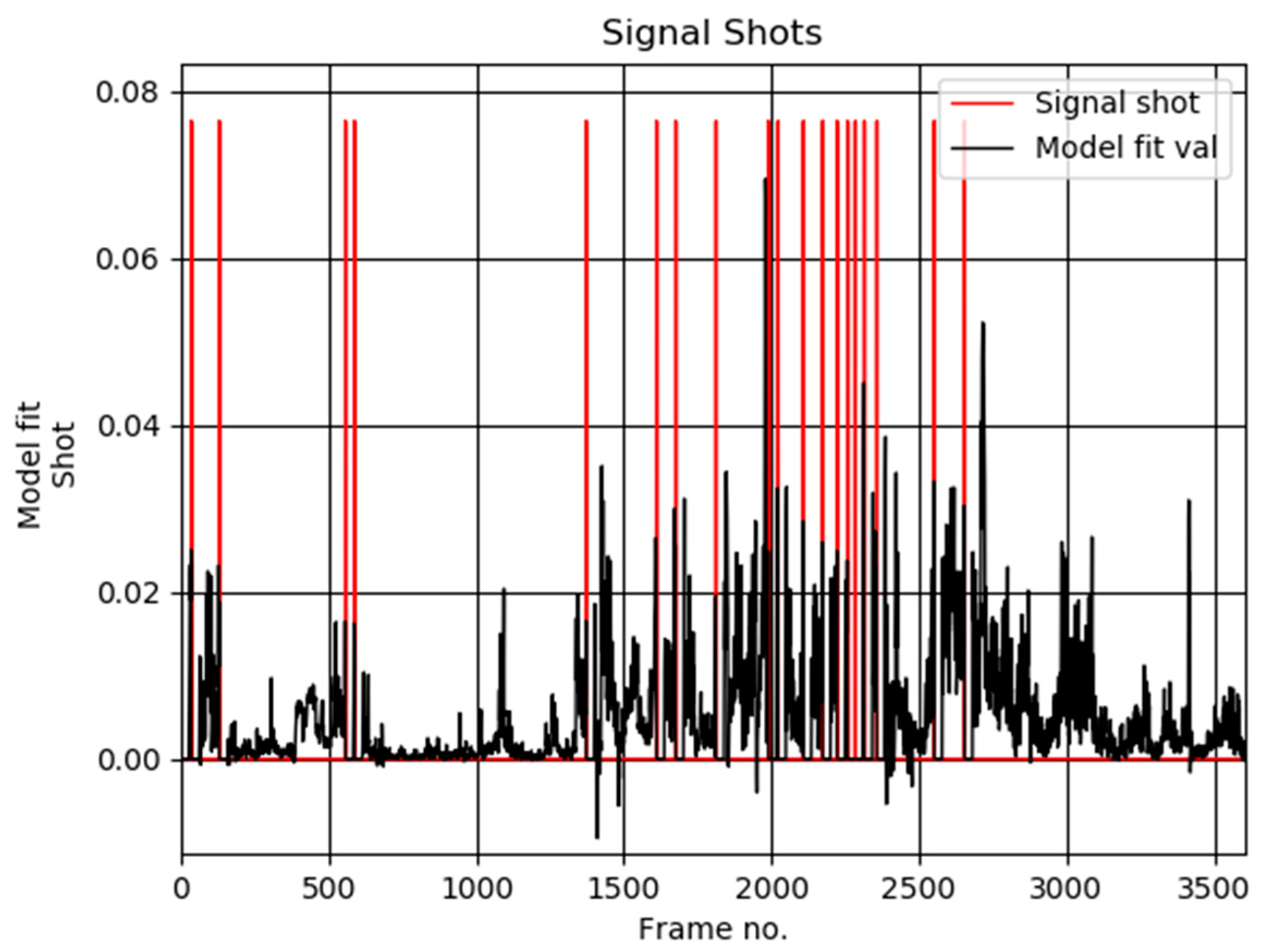
5. Experimental Results
6. Conclusions
Funding
Conflicts of Interest
References
- Gama, J. Knowledge Discovery from Data Streams; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Burduk, R.; Walkowiak, K. Static classifier selection with interval weights of base classifiers. In Proceedings of the Asian Conference on Intelligent Information and Database Systems, Bali, Indonesia, 23–25 March 2015; pp. 494–502. [Google Scholar]
- Krawczyk, B.; Minkub, L.L.; Gama, J.; Stefanowski, J.; Woźniak, M. Ensemble learning for data stream analysis: A survey. Inf. Fusion. 2017, 37, 132–156. [Google Scholar] [CrossRef]
- The Open Video Project. Home Page. Available online: https://open-video.org/ (accessed on 21 July 2019).
- Halko, N.; Martinsson, P.; Tropp, J. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions. Siam Rev. 2011, 53, 217–288. [Google Scholar] [CrossRef]
- Cyganek, B. Object Detection and Recognition in Digital Images: Theory and Practice; Wiley: Hoboken, NJ, USA, 2013. [Google Scholar]
- Cyganek, B. Change detection in multidimensional data streams with efficient tensor subspace model, HAIS 2018-Hybrid Artificial Intelligent Systems. In Proceedings of the 13th International Conference, Oviedo, Spain, 20–22 June 2018; pp. 694–705. [Google Scholar]
- Sun, J.; Tao, D.; Faloutsos, C. Beyond Streams and Graphs: Dynamic Tensor Analysis; ACM: Philadelphia, PA, USA, 2006. [Google Scholar]
- Sun, J.; Tao, D.; Faloutsos, C. Incremental Tensor Analysis: Theory and Applications. ACM Trans. Knowl. Discov. Data 2008, 2, 11. [Google Scholar] [CrossRef]
- Cyganek, B.; Woźniak, M. A Tensor Framework for Data Stream Clustering and Compression. In Proceedings of the International Conference on Image Analysis and Processing, ICIAP 2017, Catania, Italy, 11–15 September 2017; pp. 1–11. [Google Scholar]
- De Avila, S.E.F.; Lopes, A.P.B.; Luz da Jr, A.; Araújo, A.A. VSUMM: A mechanism designed to produce static video summaries and a novel evaluation method. Pattern Recognit. Lett. 2011, 32, 56–68. [Google Scholar] [CrossRef]
- VSUMM. Home Page. Available online: https://sites.google.com/site/vsummsite/home (accessed on 21 July 2019).
- Cyganek, B.; Woźniak, M. Tensor-based shot boundary detection in video streams. New Gener. Comput. 2017, 35, 311–340. [Google Scholar] [CrossRef]
- Cyganek, B. Road Signs Recognition by the Scale-Space Template Matching in the Log-Polar Domain. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2007; pp. 330–337. [Google Scholar]
- Gao, Y.; Wang, W.-B.; Yong, J.-H.; Gu, H.-J. Dynamic video summarization using two-level redundancy detection. Multimed. Tools Appl. 2009, 42, 233–250. [Google Scholar] [CrossRef]
- Asghar, M.N.; Hussain, F.; Manton, R. Video Indexing: A Survey. Int. J. Comput. Inf. Technol. 2014, 3, 148–169. [Google Scholar]
- Truong, B.T.; Venkatesh, S. Video abstraction: A systematic review and classification. ACM Trans. Multimedia Comput. Comm. Appl. 2007, 3. [Google Scholar] [CrossRef]
- Fu, Y.; Guo, Y.; Zhu, Y.; Liu, F.; Song, C.; Zhou, Z.-H. Multi-View Video Summarization. IEEE Trans. Multimed. 2010, 12, 717–729. [Google Scholar] [CrossRef]
- Valdes, V.; Martinez, J. Efficient video summarization and retrieval tools. In Proceedings of the International Workshop on Content-Based Multimedia Indexing, Madrid, Spain, 13–15 June 2011; pp. 43–44. [Google Scholar]
- Del Fabro, M.; Böszörmenyi, L. State-of-the-art and future challenges in video scene detection: A survey. In Multimedia Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 427–454. [Google Scholar]
- Lee, H.; Yu, J.; Im, Y.; Gil, J.-M.; Park, D. A unified scheme of shot boundary detection and anchor shot detection in news video story parsing. Multimed. Tools Appl. 2011, 51, 1127–1145. [Google Scholar] [CrossRef]
- De Menthon, D.; Kobla, V.; Doermann, D. Video summarization by curve simplification. In Proceedings of the 6th ACM international conference on Multimedia, ACM, Bristol, UK, 13–16 September 1998; pp. 211–218. [Google Scholar]
- Mundur, P.; Rao, Y.; Yesha, Y. Keyframe-based video summarization using Delaunay clustering. Internat. J. Dig. Libr. 2006, 6, 219–232. [Google Scholar] [CrossRef]
- Kuanar, S.K. Video key frame extraction through dynamic Delaunay clustering with a structural constraint. J. Vis. Commun. Image Represent 2013, 24, 1212–1227. [Google Scholar] [CrossRef]
- Furini, M.; Geraci, F.; Montangero, M.; Pellegrini, M. STIMO: STIll and Moving video storyboard for the web scenario. Multimedia Tools App. 2010, 46, 47–69. [Google Scholar] [CrossRef]
- Cayllahua-Cahuina, E.J.; Cámara-Chávez, G.; Menotti, D. A Static Video Summarization Approach with Automatic Shot Detection Using Color Histograms; UFOP: Ouro Preto, Brazil, 2012. [Google Scholar]
- Medentzidou, P.; Kotropoulos, C. Video summarization based on shot boundary detection with penalized contrasts. In Proceedings of the IEEE 9th International Symposium on Image and Signal Processing and Analysis (ISPA), Edinburgh, UK, 6–8 September 2015; pp. 199–203. [Google Scholar]
- Mahmoud, K.A.; Ismail, M.A.; Ghanem, N.M. VSCAN: An Enhanced Video Summarization Using Density-Based Spatial Clustering. In Image Analysis and Processing–ICIAP 2013. LNCS; Springer: Berlin/Heidelberg, Germany, 2013; pp. 733–742. [Google Scholar] [Green Version]
- Aja-Fernández, S.; de Luis Garcia, R.; Tao, D.; Li, X. Tensors in Image Processing and Computer Vision; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Cichocki, A.; Zdunek, R.; Amari, S. Nonnegative Matrix and Tensor Factorization. IEEE Signal Process. Mag. 2008, 25, 142–145. [Google Scholar] [CrossRef]
- Cichocki, A.; Zdunek, R.; Phan, A.H.; Amari, S.-I. Nonnegative Matrix and Tensor Factorizations. In Applications to Exploratory Multi-Way Data Analysis and Blind Source Separation; Wiley: Hoboken, NJ, USA, 2009. [Google Scholar]
- De Lathauwer, L.; De Moor, B.; Vandewalle, J. On the Best Rank-1 and Rank-(R1, R2, …, RN) Approximation of Higher-Order Tensors. Siam J. Matrix Anal. Appl. 2000, 21, 1324–1342. [Google Scholar] [CrossRef]
- Kiers, H.A.L. Towards a standardized notation and terminology in multiway analysis. J. Chemom. 2000, 14, 105–122. [Google Scholar] [CrossRef]
- Kolda, T.G.; Bader, B.W. Tensor Decompositions and Applications. Siam Rev. 2008, 51, 455–500. [Google Scholar] [CrossRef]
- De Lathauwer, L. Signal Processing Based on Multilinear Algebra. Ph.D. Thesis, Katholieke Universiteit Leuven, Leuven, Belgium, 1997. [Google Scholar]
- De Lathauwer, L.; De Moor, B.; Vandewalle, J. A Multilinear Singular Value Decomposition. Siam J. Matrix Anal. Appl. 2000, 21, 1253–1278. [Google Scholar] [CrossRef] [Green Version]
- Tucker, L.R. Some mathematical notes on three-mode factor analysis. Psychometrika 1966, 31, 279–311. [Google Scholar] [CrossRef] [PubMed]
- Zhou, G.; Cichocki, A.; Xie, S. Decomposition of Big Tensors with Low Multilinear Rank. arXiv 2014, arXiv:1412.1885. [Google Scholar]
- Lowe, D. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Cyganek, B. Comparison of nonparametric transformations and bit vector matching for stereo correlation. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2004; pp. 534–547. [Google Scholar]
- Savas, B.; Eldén, L. Handwritten digit classification using higher order singular value decomposition. Pattern Recognit. 2007, 40, 993–1003. [Google Scholar] [CrossRef]
- Cyganek, B.; Woźniak, M. On robust computation of tensor classifiers based on the higher-order singular value decomposition. In Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2016; pp. 193–201. [Google Scholar]
- Muti, D.; Bourennane, S. Survey on tensor signal algebraic filtering. Signal Process. 2007, 87, 237–249. [Google Scholar] [CrossRef]
- Hyvarinen, A. Fast and robust fixed-point algorithms for independent component analysis. IEEE Trans. Neural Netw. 1999, 10, 626–634. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- DeRecLib. 2013. Available online: http://www.wiley.com/go/cyganekobject (accessed on 21 July 2019).
- VSCAN. Video Summarization using Density-based Spatial Clustering. Available online: https://sites.google.com/site/vscansite/home (accessed on 21 July 2019).
- Guan, G.; Wang, Z.; Yu, K.; Mei, S.; He, M.; Feng, D. Video summarization with global and local features. In Proceedings of the 2012 IEEE International Conference on Multimedia and Expo Workshops, IEEE Computer Society, Washington, DC, USA, 9–13 July 2012; pp. 570–575. [Google Scholar]
- Wu, Z.; Lu, Z.; Hung, P.C.K.; Huang, S.-C.; Tong, Y.; Wang, Z. QaMeC: A QoS-driven IoVs application optimizing deployment scheme in multimedia edge clouds. Future Gener. Comput. Syst. 2019, 92, 17–28. [Google Scholar] [CrossRef]
- Chen, X.; Tang, S.; Lu, Z.; Wu, J.; Duan, Y.; Huang, S.-C.; Tang, Q. iDiSC: A New Approach to IoT-Data-Intensive Service Components Deployment in Edge-Cloud-Hybrid System. IEEE Access 2019, 7, 59172–59184. [Google Scholar] [CrossRef]












{kind=link}
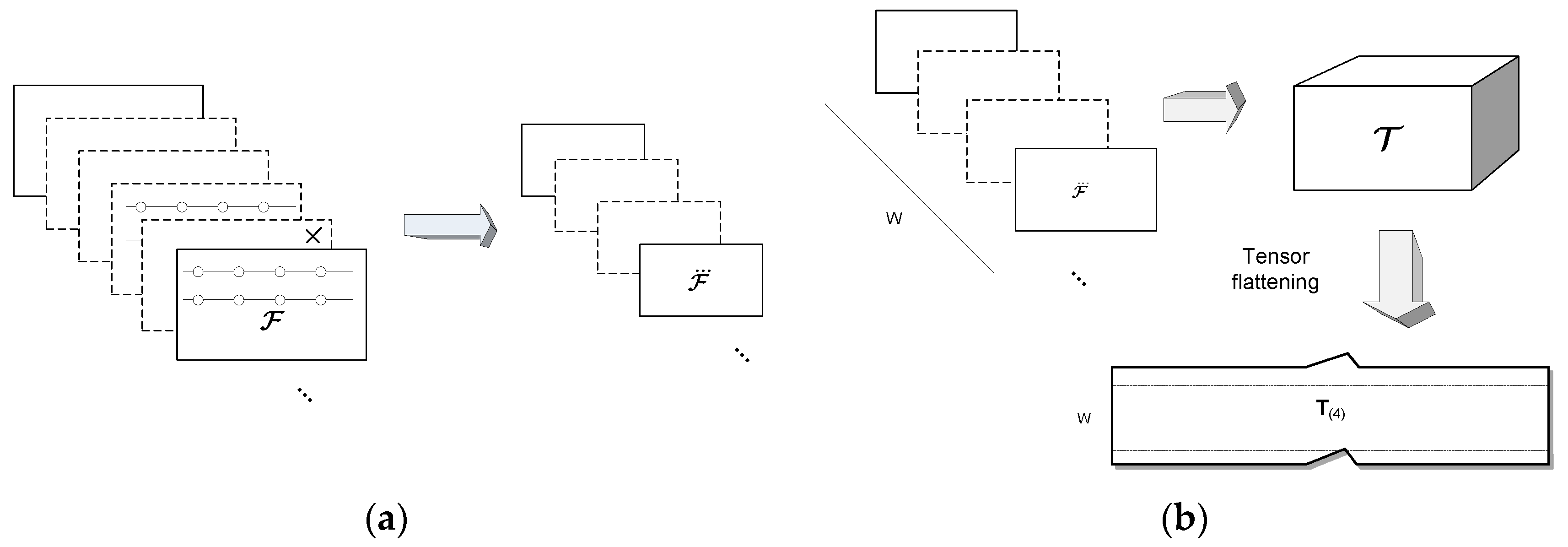{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | OV [22] | DT [23] | STIMO [25] | VSUMM [11] | VSCAN [28] | Best rank-R [13] | HOSVD [7] | HOSVD (This Paper) |
|---|---|---|---|---|---|---|---|---|
| F | 0.67 | 0.61 | 0.65 | 0.72 | 0.77 | 0.73 | 0.73 | 0.77 |
| F-MONO | NA | NA | NA | NA | NA | NA | 0.71 | 0.76 |
| Seq. No. | CUSA | CUSE | P | R | F |
|---|---|---|---|---|---|
| 21 | 0.64 | 0.45 | 0.58 | 0.64 | 0.61 |
| 22 | 0.75 | 0.25 | 0.75 | 0.75 | 0.75 |
| 23 | 1.00 | 0.29 | 0.78 | 1.00 | 0.88 |
| 24 | 0.58 | 0.00 | 1.00 | 0.58 | 0.74 |
| 25 | 0.58 | 0.08 | 0.88 | 0.58 | 0.70 |
| 26 | 0.63 | 0.38 | 0.63 | 0.63 | 0.63 |
| 27 | 0.75 | 0.75 | 0.50 | 0.75 | 0.60 |
| 28 | 0.65 | 0.00 | 1.00 | 0.65 | 0.79 |
| 29 | 0.88 | 0.25 | 0.78 | 0.88 | 0.82 |
| 30 | 0.60 | 0.00 | 1.00 | 0.60 | 0.75 |
| 31 | 0.64 | 0.00 | 1.00 | 0.64 | 0.78 |
| 32 | 0.33 | 0.50 | 0.40 | 0.33 | 0.36 |
| 33 | 0.72 | 0.11 | 0.87 | 0.72 | 0.79 |
| 34 | 1.00 | 0.00 | 1.00 | 1.00 | 1.00 |
| 35 | 0.44 | 0.44 | 0.50 | 0.44 | 0.47 |
| 36 | 0.83 | 2.00 | 0.29 | 0.83 | 0.43 |
| 37 | 0.80 | 0.80 | 0.50 | 0.80 | 0.62 |
| 38 | 0.82 | 0.45 | 0.64 | 0.82 | 0.72 |
| 39 | 0.86 | 0.29 | 0.75 | 0.86 | 0.80 |
| 40 | 0.80 | 0.50 | 0.62 | 0.80 | 0.70 |
| 41 | 0.82 | 0.36 | 0.69 | 0.82 | 0.75 |
| 42 | 0.78 | 0.56 | 0.58 | 0.78 | 0.67 |
| 43 | 0.94 | 0.17 | 0.85 | 0.94 | 0.89 |
| 44 | 0.90 | 0.30 | 0.75 | 0.90 | 0.82 |
| 45 | 1.00 | 0.33 | 0.75 | 1.00 | 0.86 |
| 46 | 0.90 | 0.50 | 0.64 | 0.90 | 0.75 |
| 47 | 1.00 | 0.00 | 1.00 | 1.00 | 1.00 |
| 48 | 0.88 | 0.75 | 0.54 | 0.88 | 0.67 |
| 49 | 0.87 | 0.20 | 0.81 | 0.87 | 0.84 |
| 50 | 0.88 | 0.50 | 0.64 | 0.88 | 0.74 |
| 51 | 0.75 | 0.13 | 0.86 | 0.75 | 0.80 |
| 52 | 1.00 | 0.13 | 0.89 | 1.00 | 0.94 |
| 53 | 1.00 | 0.25 | 0.80 | 1.00 | 0.89 |
| 54 | 0.80 | 0.40 | 0.67 | 0.80 | 0.73 |
| 55 | 0.80 | 0.20 | 0.80 | 0.80 | 0.80 |
| 56 | 0.78 | 0.11 | 0.88 | 0.78 | 0.82 |
| 57 | 1.00 | 0.29 | 0.78 | 1.00 | 0.88 |
| 58 | 0.75 | 0.17 | 0.82 | 0.75 | 0.78 |
| 59 | 0.90 | 0.00 | 1.00 | 0.90 | 0.95 |
| 60 | 1.00 | 0.33 | 0.75 | 1.00 | 0.86 |
| 61 | 1.00 | 0.57 | 0.64 | 1.00 | 0.78 |
| 62 | 1.00 | 0.25 | 0.80 | 1.00 | 0.89 |
| 63 | 0.86 | 0.29 | 0.75 | 0.86 | 0.80 |
| 64 | 0.79 | 0.21 | 0.79 | 0.79 | 0.79 |
| 65 | 0.88 | 0.25 | 0.78 | 0.88 | 0.82 |
| 66 | 0.83 | 0.33 | 0.71 | 0.83 | 0.77 |
| 67 | 0.63 | 0.38 | 0.63 | 0.63 | 0.63 |
| 68 | 0.75 | 0.00 | 1.00 | 0.75 | 0.86 |
| 69 | 0.80 | 0.20 | 0.80 | 0.80 | 0.80 |
| 70 | 0.80 | 0.00 | 1.00 | 0.80 | 0.89 |
| Average | 0.77 | ||||
| Method | Best rank-R [13] | HOSVD [7] | HOSVD (This Paper) |
|---|---|---|---|
| Processing time (frames/s) | 3 | 15 | 160 |
| Parameter | Description | Value |
|---|---|---|
| W | Size of the tensor window used to build a model (step 1 in Algorithm 1) | 47 |
| a, b | Tensor frame fit measure (16) | a = 3.0 |
| b = 0.02 | ||
| G | Number of consecutive frames to launch rebuild of the tensor model. | 9 |
| D | Randomization factor. | 0.33 |
| η | Eigenvalue fit parameter in (19). | 1.1 |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cyganek, B. Thumbnail Tensor—A Method for Multidimensional Data Streams Clustering with an Efficient Tensor Subspace Model in the Scale-Space. Sensors 2019, 19, 4088. https://doi.org/10.3390/s19194088
Cyganek B. Thumbnail Tensor—A Method for Multidimensional Data Streams Clustering with an Efficient Tensor Subspace Model in the Scale-Space. Sensors. 2019; 19(19):4088. https://doi.org/10.3390/s19194088
Chicago/Turabian StyleCyganek, Bogusław. 2019. "Thumbnail Tensor—A Method for Multidimensional Data Streams Clustering with an Efficient Tensor Subspace Model in the Scale-Space" Sensors 19, no. 19: 4088. https://doi.org/10.3390/s19194088
APA StyleCyganek, B. (2019). Thumbnail Tensor—A Method for Multidimensional Data Streams Clustering with an Efficient Tensor Subspace Model in the Scale-Space. Sensors, 19(19), 4088. https://doi.org/10.3390/s19194088