Multi-View Fusion-Based 3D Object Detection for Robot Indoor Scene Perception

 ,
,
Abstract
:1. Introduction
- (1)
- We propose a two-stage 3D object detection framework by fusing multiple views of a 3D point cloud based on a real-time visual SLAM for an indoor service robot. Keyframes are continuously processed and 3D bounding boxes of objects are estimated during the motion of a robot.
- (2)
- We construct an object database and propose an object fusion criterion to maintain it automatically. We also propose an object filtering approach based on prior knowledge including size and volume ratio to remove atypical (based on object dimension) and intersecting objects in the object dataset.
2. Related Work
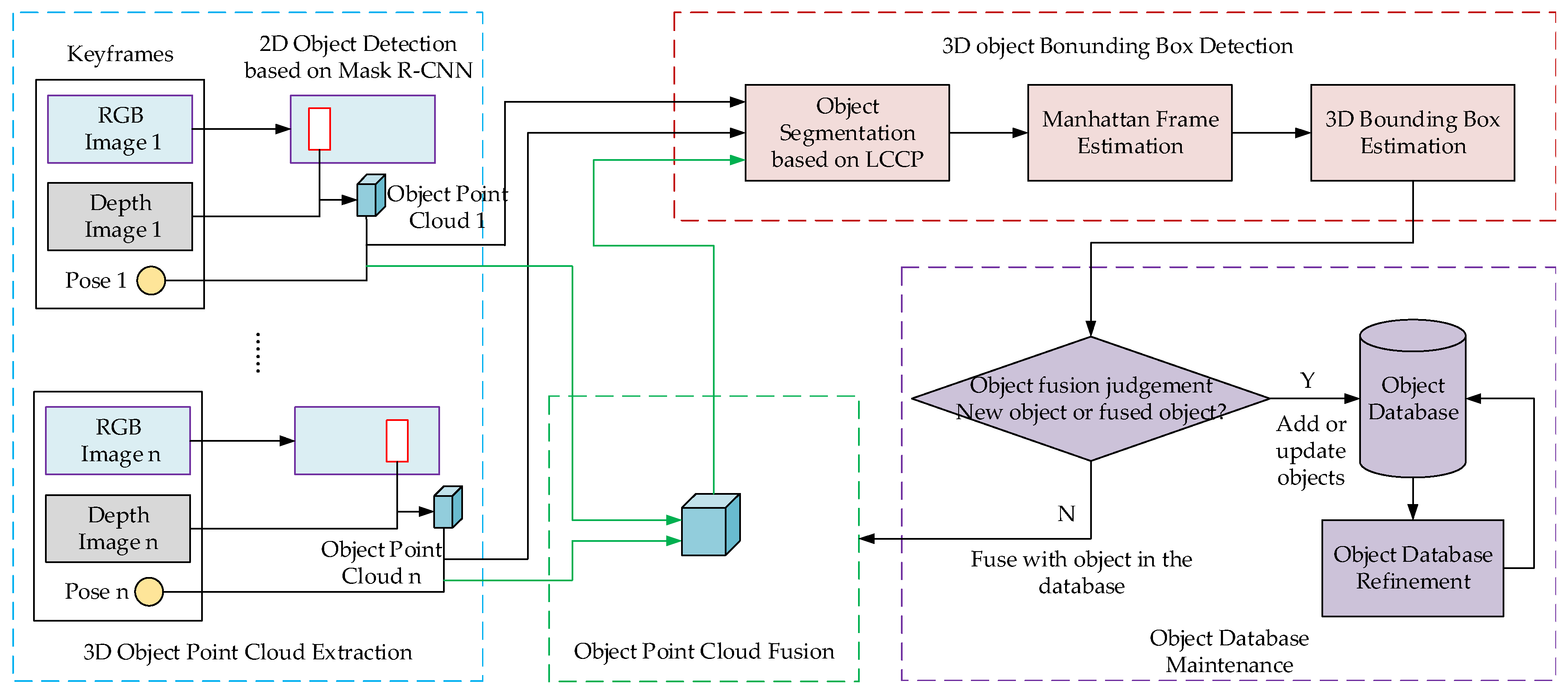
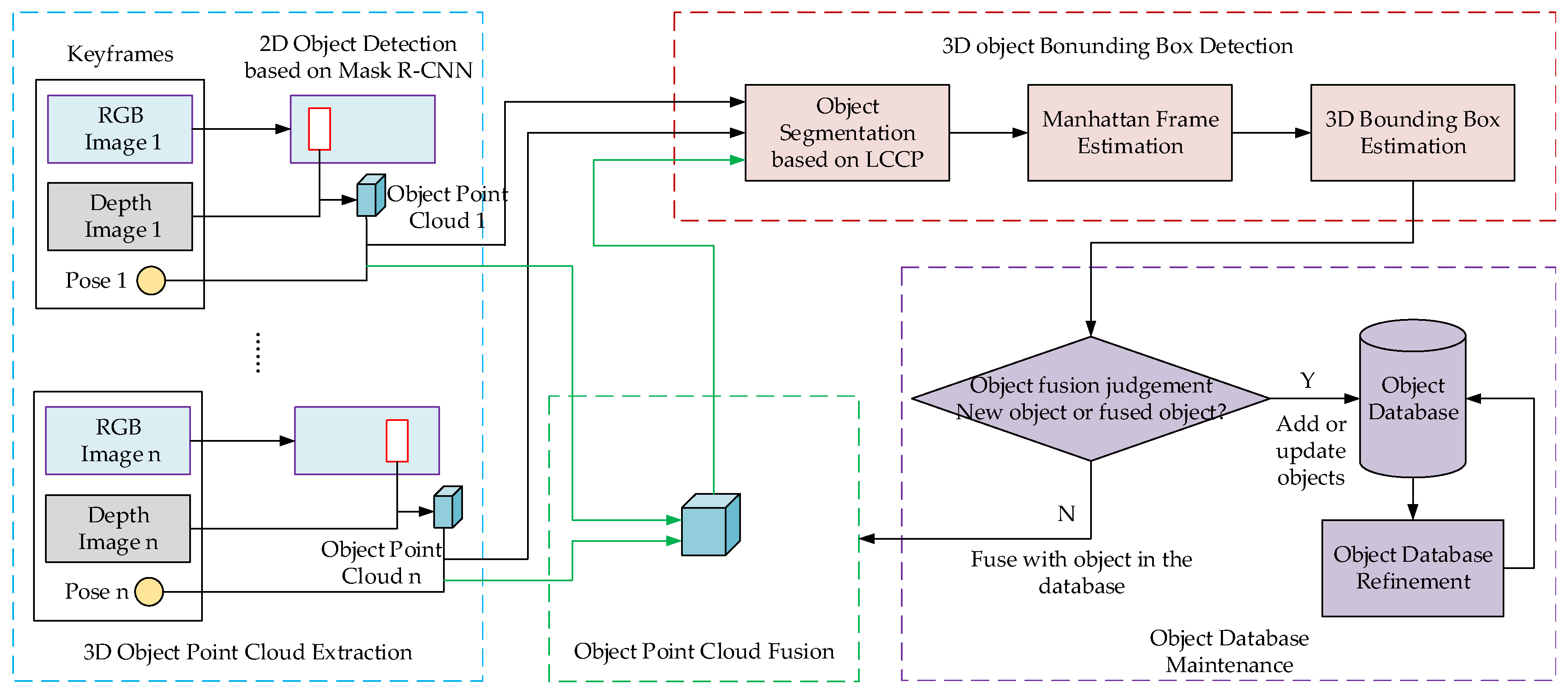
3. 3D Object Detection Algorithm Based on Multi-View Fusion
- Object point clouds extraction based on Mask R-CNN;
- Unsupervised segmentation of the object point cloud;
- 3D object bounding box estimation based on Manhattan Frame;
- Object point cloud fusion utilizing multi-view and object database maintenance;
- Object database refinement to remove error detection and object intersections.
3.1. Object Point Cloud Extraction Based on Mask R-CNN
3.2. Unsupervised Segmentation of the Object Point Cloud
3.3. 3D Object Bounding Box Estimation Based on Manhattan Frame
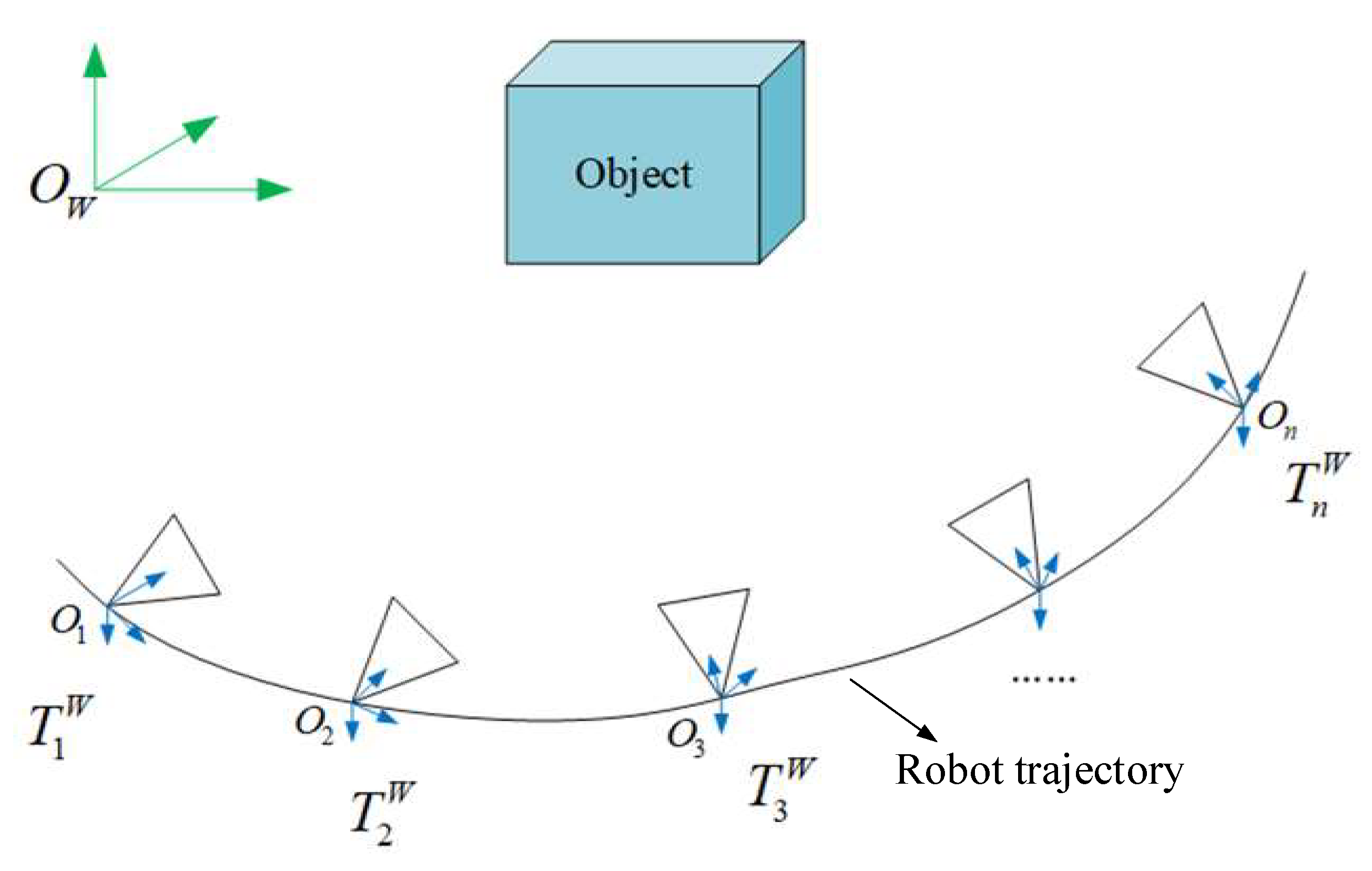
3.4. Object Point Cloud Fusion Utilizing Multi-View and Object Database Maintenance
3.4.1. The First Time to Insert Objects to the Object Database
3.4.2. Object Fusion Criterion and Database Maintenance
3.5. Object Database Refinement
3.5.1. Atypical Object Filtering Based on Prior Knowledge
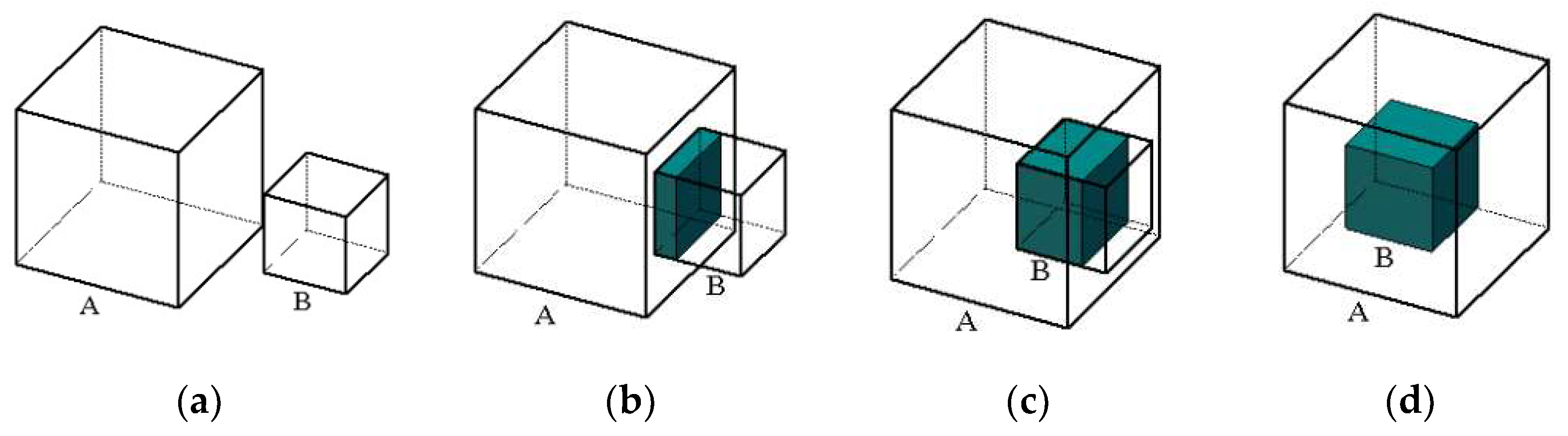
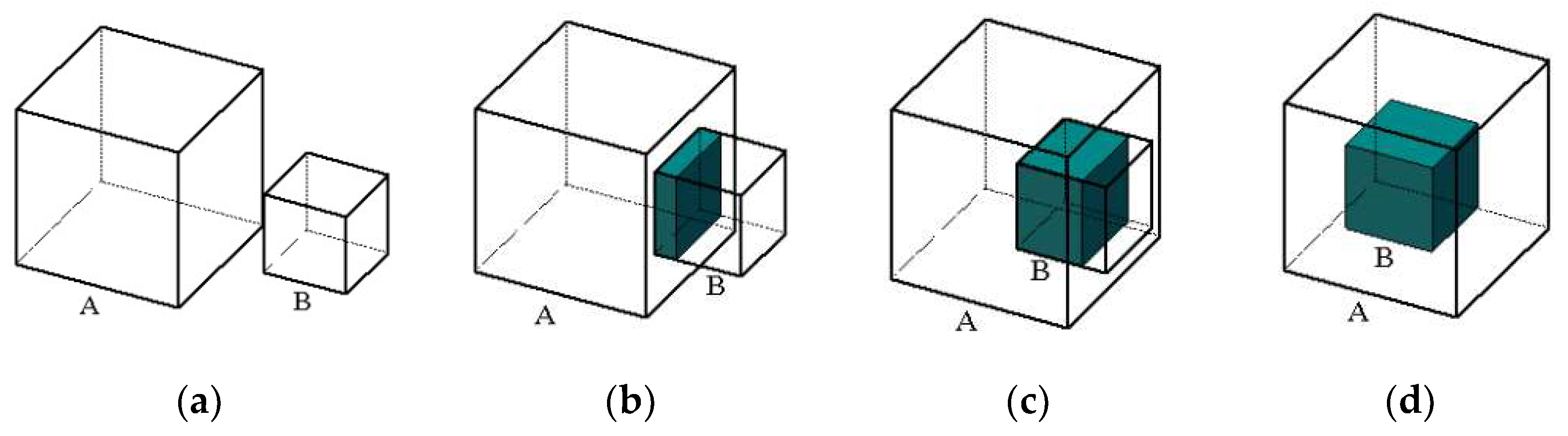
3.5.2. Intersection Object Filtering Based on Volume Ratio
| Algorithm 1: Intersection object filtering algorithm |
| : the number of objects in the database D: the array of subscripts that need to be deleted in the database |
| 1: ; |
| 2: for = 0; < ; ++ do 3: for = + 1; < ; ++ do |
| 4: Calculate the intersection between object and ; |
| 5: ; |
| 6: ; |
| 7: end for 8: ; |
| 9: if then |
| 10: ; 11: ; 12: elseif then 13: ; 14: ; |
| 15: end if |
| 16: end for 17: ; |
| 18: for = 0; < ; ++ do 19: if then 20: Delete the object in the database ; 21: end if |
| 22: end for |
4. Experimental Evaluation
4.1. Object-Level 3D Semantic Segmentation Evaluation
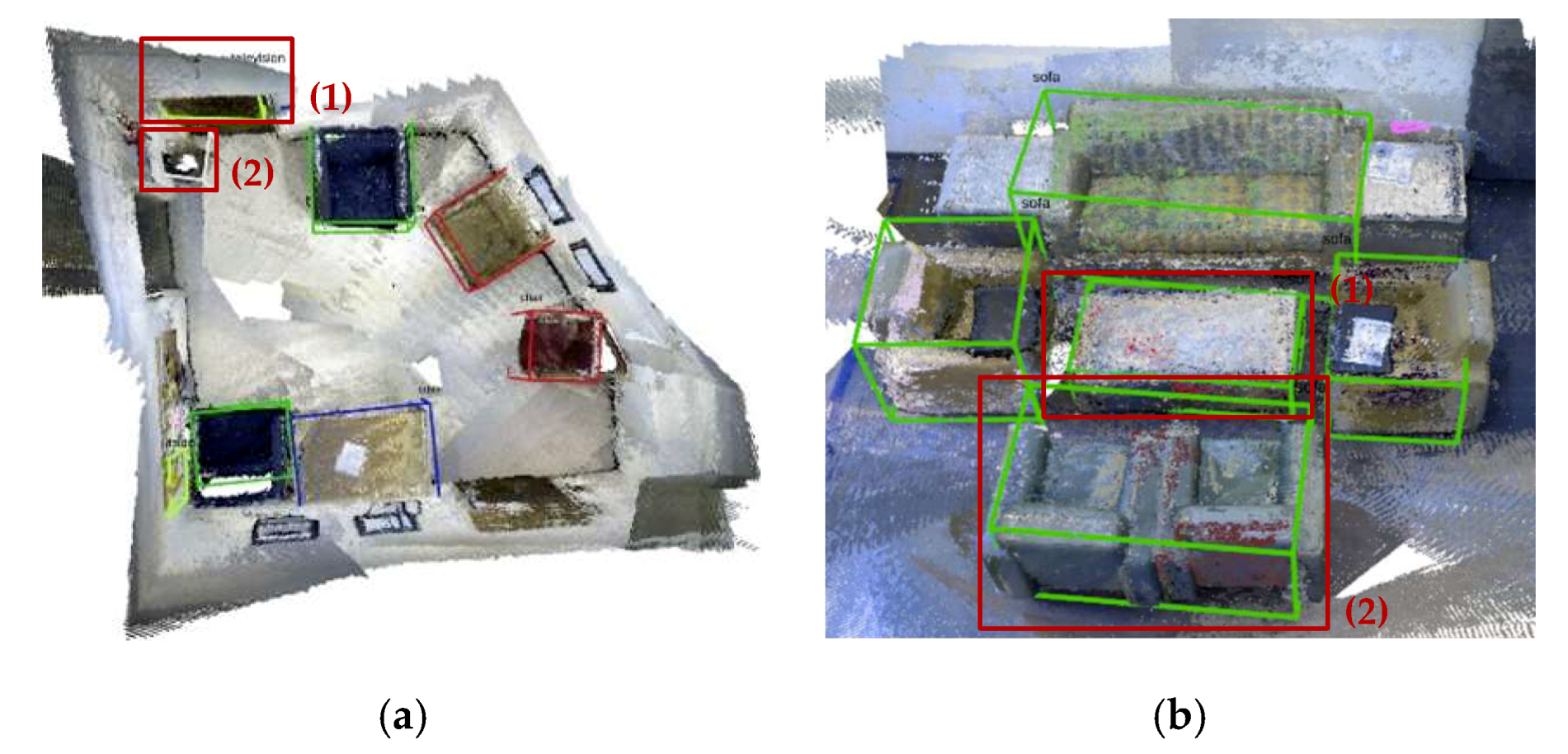
4.2. 3D object Bounding Box Detection and Database Refinement
4.3. Runtime Evaluation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelo, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 99, 1–13. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from RGBD images. In Proceedings of the 12th European Conference on Computer Vision (ECCV 2012), Florence, Italy, 7–13 October 2012; pp. 1–14. [Google Scholar]
- Song, S.; Lichtenberg, S.P.; Xiao, J. SUN RGB-D: A RGB-D scene understanding benchmark suite. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015; pp. 567–576. [Google Scholar]
- Song, S.; Xiao, J. Deep sliding shapes for amodal 3D object detection in RGB-D images. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 808–816. [Google Scholar]
- Qi, C.; Su, H.; Mo, K.; Guibas, L. PointNet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Qi, C.; Yi, L.; Su, H.; Guibas, L. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5100–5109. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum PointNets for 3D object detection from RGB-D Data. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2018), Salt Lake City, UT, USA, 18–22 June 2018; pp. 918–927. [Google Scholar]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved techniques for grid mapping with Rao-Blackwellized particle filters. IEEE Trans. Rob. 2007, 23, 34–46. [Google Scholar] [CrossRef]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-time loop closure in 2D LIDAR SLAM. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA 2016), Stockholm, Sweden, 16–21 May 2016; pp. 1271–1278. [Google Scholar]
- Mur-Artal, R.; Tardos, J. ORB-SLAM2: An open-source SLAM system for monocular, stereo, and RGB-D cameras. IEEE Trans. Rob. 2017, 33, 1–8. [Google Scholar] [CrossRef]
- Whelan, T.; Salas-Moreno, R.; Glocker, B.; Davison, A. ElasticFusion. Int. J. Robot. Res. 2016, 35, 1697–1716. [Google Scholar] [CrossRef]
- Gupta, S.; Arbeláez, P.; Malik, J. Perceptual organization and recognition of indoor scenes from RGB-D images. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2013), Portland, OR, USA, 18–22 June 2013; pp. 564–571. [Google Scholar]
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning rich features from RGB-D images for object detection and segmentation. In Proceedings of the 12th European Conference on Computer Vision (ECCV 2014), Zurich, Switzerland, 6–12 September 2014; pp. 345–360. [Google Scholar]
- Ren, X.; Bo, L.; Fox, D. RGB-(D) scene labeling: Features and algorithms. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2012), Providence, RI, USA, 16–21 June 2012; pp. 2759–2766. [Google Scholar]
- Lin, D.; Fidler, S.; Urtasun, R. Holistic scene understanding for 3D object detection with RGBD cameras. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV 2013), Sydney, NSW, Australia, 3–6 December 2013; pp. 1417–1424. [Google Scholar]
- Zhuo, D.; Latecki, L.J. Amodal detection of 3D objects: Inferring 3D bounding boxes from 2D ones in RGB-Depth images. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 398–406. [Google Scholar]
- Ren, Z.; Sudderth, E.B. Three-dimensional object detection and layout prediction using clouds of oriented gradients. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 1525–1533. [Google Scholar]
- Lahoud, J.; Ghanem, B. 2D-driven 3D object detection in RGB-D images. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 4632–4640. [Google Scholar]
- Antonello, M.; Wolf, D.; Prankl, J.; Ghidoni, S.; Menegatti, E.; Vincze, M. Multi-view 3D entangled forest for semantic segmentation and mapping. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA 2018), Brisbane, QLD, Australia, 21–25 May 2018; pp. 1855–1862. [Google Scholar]
- Tateno, K.; Tombari, F.; Navab, N. When 2.5D is not enough: Simultaneous reconstruction, segmentation and recognition on dense SLAM. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA 2016), Stockholm, Sweden, 16–21 May 2016; pp. 2295–2302. [Google Scholar]
- Nakajima, Y.; Saito, H. Efficient Object-Oriented Semantic Mapping with Object Detector. IEEE Access. 2019, 7, 3206–3213. [Google Scholar] [CrossRef]
- Prisacariu, V.; Kähler, O.; Golodetz, S.; Sapienza, M.; Cavallari, T.; Torr, P.; Murray, D. InfiniTAM v3: A Framework for Large-Scale 3D Reconstruction with Loop Closure. arXiv 2017, arXiv:1708.00783. [Google Scholar]
- Grinvald, M.; Furrer, F.; Novkovic, T.; Chung, J.; Cadena, C.; Siegwart, R.; Nieto, J. Volumetric instance-aware semantic mapping and 3D object discovery. IEEE Robot. Automat. Lett. 2019, 4, 3037–3044. [Google Scholar] [CrossRef]
- Joo, K.; Oh, T.; Kim, I. Globally optimal Manhattan frame estimation in real-time. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 1763–1771. [Google Scholar]
- Hua, B.; Pham, Q.; Nguyen, D.; Tran, M.; Yu, L. SceneNN: A Scene Meshes Dataset with aNNotations. In Proceedings of the 2016 4th International Conference on 3D Vision (3DV 2016), Stanford, CA, USA, 25–28 October 2016; pp. 92–101. [Google Scholar]
- Nguyen, D.; Hua, B.; Yu, L.; Yeung, S. A robust 3D-2D interactive tool for scene segmentation and annotation. IEEE T. Vis. Comput. Gr. 2018, 24, 3005–3018. [Google Scholar] [CrossRef]
- Pham, Q.; Hua, B.; Nguyen, D.; Yeung, S. Real-time progressive 3D semantic segmentation for indoor scene. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV 2019), Hilton Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1089–1098. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence ID | 011 | 016 | 030 | 061 | 078 | 086 | 096 | 206 | 223 | 255 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Categories | |||||||||||
| Bed | - | 56.9 | - | - | - | - | 65.9 | - | - | - | |
| Chair | 63.1 | 0 | 67.4 | - | 77.7 | 54.4 | 59.4 | 41.4 | 51.3 | - | |
| Sofa | - | 72.1 | 62.9 | 72.5 | - | - | - | 65.1 | - | - | |
| Table | 61.2 | - | 59.4 | 0 | 42.6 | 0 | 5.2 | 77.2 | 41.8 | - | |
| Books | - | - | 52.9 | - | 53.8 | 45.8 | 20.3 | - | - | - | |
| Refrigerator | - | - | - | - | 0 | - | - | - | - | 56.4 | |
| Television | - | - | - | - | 72.2 | 73.6 | 45.1 | - | - | - | |
| Toilet | - | - | - | - | - | - | - | - | - | - | |
| Bag | - | - | - | - | - | 55.0 | 0 | 0 | - | - | |
| Average | 62.2 | 43.0 | 60.7 | 36.3 | 49.3 | 45.8 | 32.7 | 46.0 | 46.6 | 56.4 | |
| Sequence ID | 011 | 016 | 030 | 061 | 078 | 086 | 096 | 206 | 223 | 255 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Categories | |||||||||||
| [31] | 52.1 | 34.2 | 56.8 | 59.1 | 34.9 | 35.0 | 26.5 | 41.7 | 40.9 | 48.6 | |
| [27] | 75.0 | 33.3 | 56.1 | 62.5 | 45.2 | 20.0 | 29.2 | 79.6 | 43.8 | 75.0 | |
| Single frame | 45.8 | 26.4 | 48.2 | 19.7 | 35.1 | 30.7 | 18.3 | 33.9 | 27.2 | 34.8 | |
| Our method | 62.2 | 43.0 | 60.7 | 36.3 | 49.3 | 45.8 | 32.7 | 46.0 | 46.6 | 56.4 | |
| Sequence ID | 011 | 016 | 030 | 061 | 078 | 086 | 096 | 206 | 223 | 255 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Categories | |||||||||||
| -Filter | 60.5 | 41.4 | 57.4 | 34.8 | 47.5 | 44.3 | 30.1 | 43.5 | 43.8 | 54.2 | |
| -LCCP | 55.2 | 40.8 | 55.1 | 33.4 | 46.2 | 42.4 | 28.5 | 43.2 | 41.5 | 52.8 | |
| -Filter-LCCP | 54.6 | 40.2 | 52.9 | 31.1 | 44.7 | 41.6 | 26.4 | 40.2 | 40.7 | 48.7 | |
| Our method | 62.2 | 43.0 | 60.7 | 36.3 | 49.3 | 45.8 | 32.7 | 46.0 | 46.6 | 56.4 | |
| Sequence ID | 011 | 016 | 030 | 061 | 078 | 086 | 096 | 206 | 223 | 255 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Items | |||||||||||
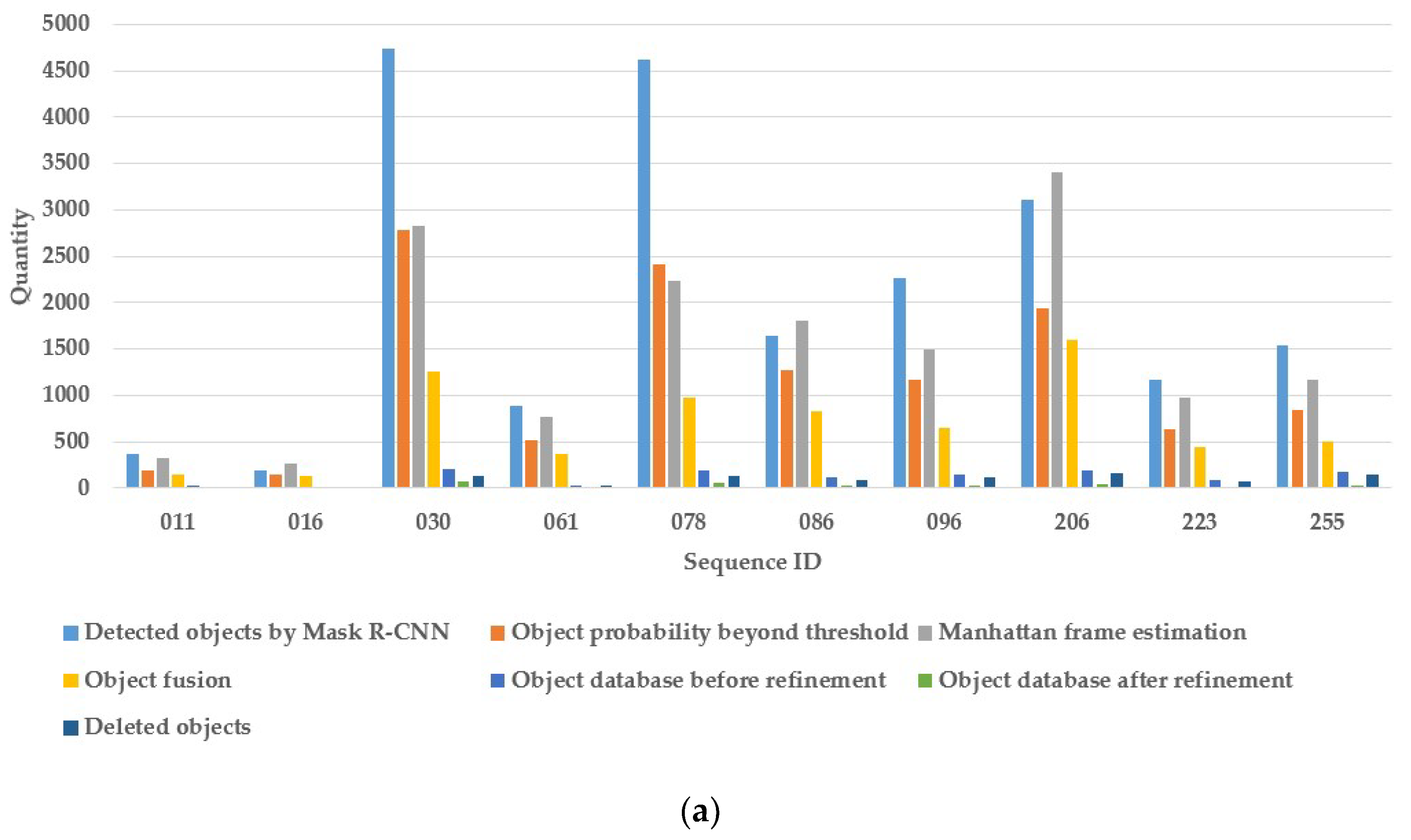
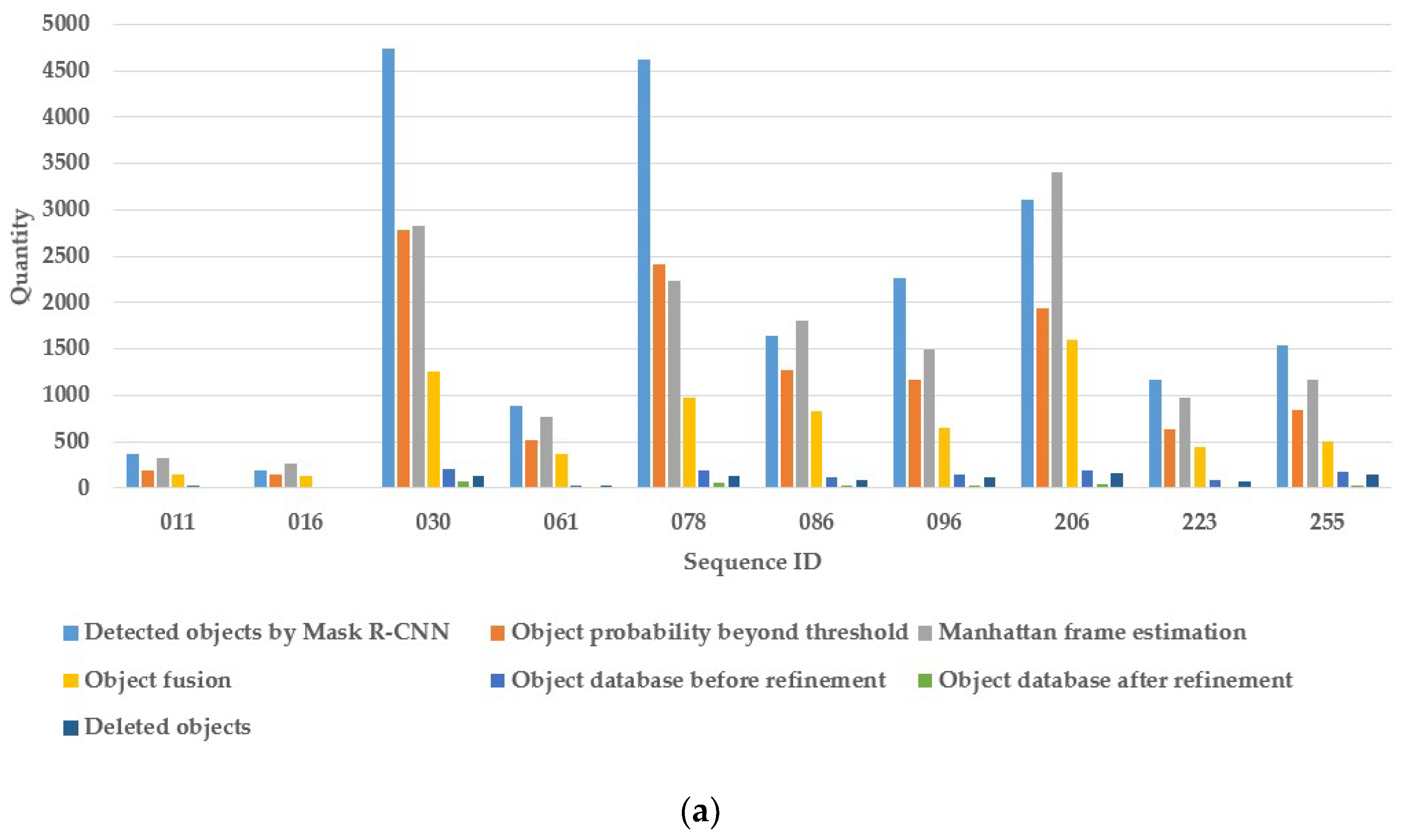
| Images | 3700 | 1300 | 4100 | 3400 | 7000 | 5900 | 9500 | 10100 | 4500 | 5400 | |
| Keyframes | 370 | 130 | 410 | 340 | 700 | 590 | 950 | 1010 | 450 | 540 | |
| Detected objects by Mask R-CNN | 361 | 190 | 4740 | 881 | 4621 | 1637 | 2267 | 3111 | 1172 | 1540 | |
| Object probability beyond threshold | 190 | 140 | 2788 | 523 | 2407 | 1278 | 1174 | 1937 | 632 | 846 | |
| Manhattan frame estimation | 321 | 260 | 2832 | 773 | 2239 | 1808 | 1497 | 3404 | 982 | 1172 | |
| Object fusion | 151 | 124 | 1255 | 361 | 976 | 832 | 650 | 1603 | 446 | 495 | |
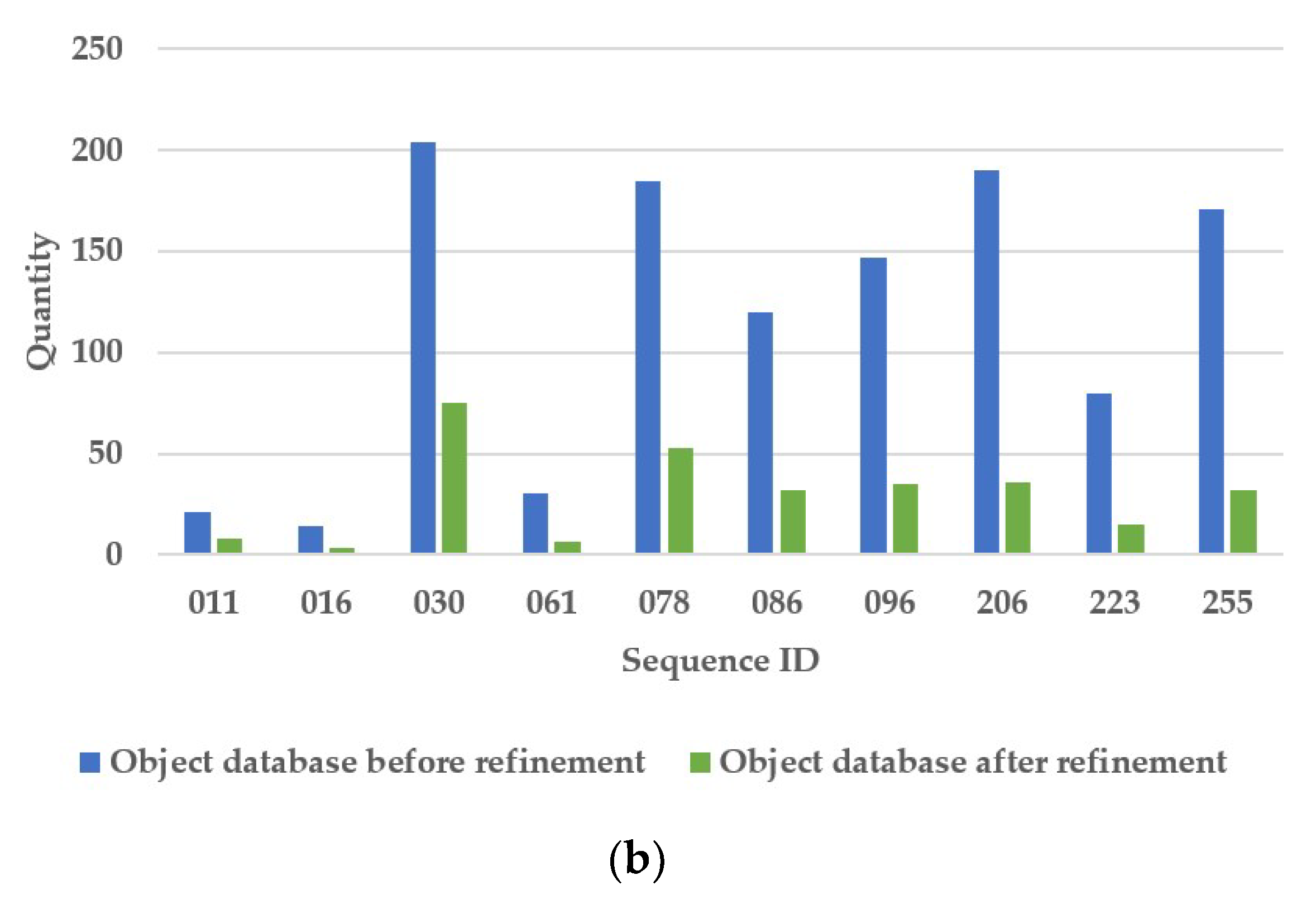
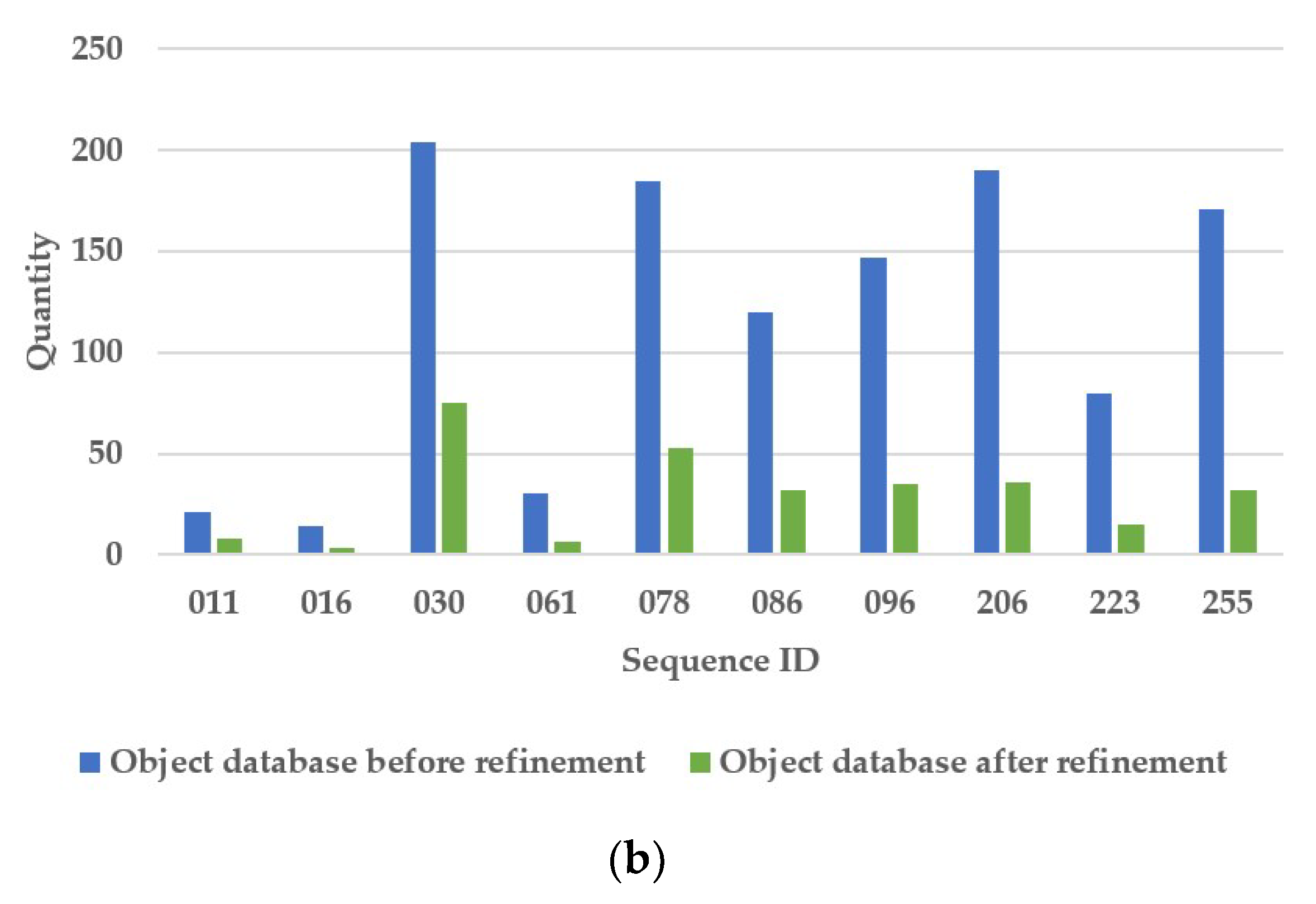
| Object database before refinement | 21 | 14 | 204 | 30 | 185 | 120 | 147 | 190 | 80 | 171 | |
| Object database after refinement | 8 | 3 | 75 | 6 | 53 | 32 | 35 | 36 | 15 | 32 | |
| Components | Time (ms) |
|---|---|
| Mask R-CNN | 192.3 |
| Object extraction and filter | 160.9 |
| LCCP | 51.5 |
| MFE | 43.4 |
| Other | 66.4 |
| Total | 514.5 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Li, R.; Sun, J.; Liu, X.; Zhao, L.; Seah, H.S.; Quah, C.K.; Tandianus, B. Multi-View Fusion-Based 3D Object Detection for Robot Indoor Scene Perception. Sensors 2019, 19, 4092. https://doi.org/10.3390/s19194092
Wang L, Li R, Sun J, Liu X, Zhao L, Seah HS, Quah CK, Tandianus B. Multi-View Fusion-Based 3D Object Detection for Robot Indoor Scene Perception. Sensors. 2019; 19(19):4092. https://doi.org/10.3390/s19194092
Chicago/Turabian StyleWang, Li, Ruifeng Li, Jingwen Sun, Xingxing Liu, Lijun Zhao, Hock Soon Seah, Chee Kwang Quah, and Budianto Tandianus. 2019. "Multi-View Fusion-Based 3D Object Detection for Robot Indoor Scene Perception" Sensors 19, no. 19: 4092. https://doi.org/10.3390/s19194092
APA StyleWang, L., Li, R., Sun, J., Liu, X., Zhao, L., Seah, H. S., Quah, C. K., & Tandianus, B. (2019). Multi-View Fusion-Based 3D Object Detection for Robot Indoor Scene Perception. Sensors, 19(19), 4092. https://doi.org/10.3390/s19194092