MFA-Net: Motion Feature Augmented Network for Dynamic Hand Gesture Recognition from Skeletal Data †


Abstract
:1. Introduction
2. Related Work
2.1. Static Hand Gesture Recognition
2.2. RGB-D Based Dynamic Hand Gesture Recognition
2.3. Skeleton-Based Dynamic Hand Gesture Recognition
2.4. Feature Augmented Method
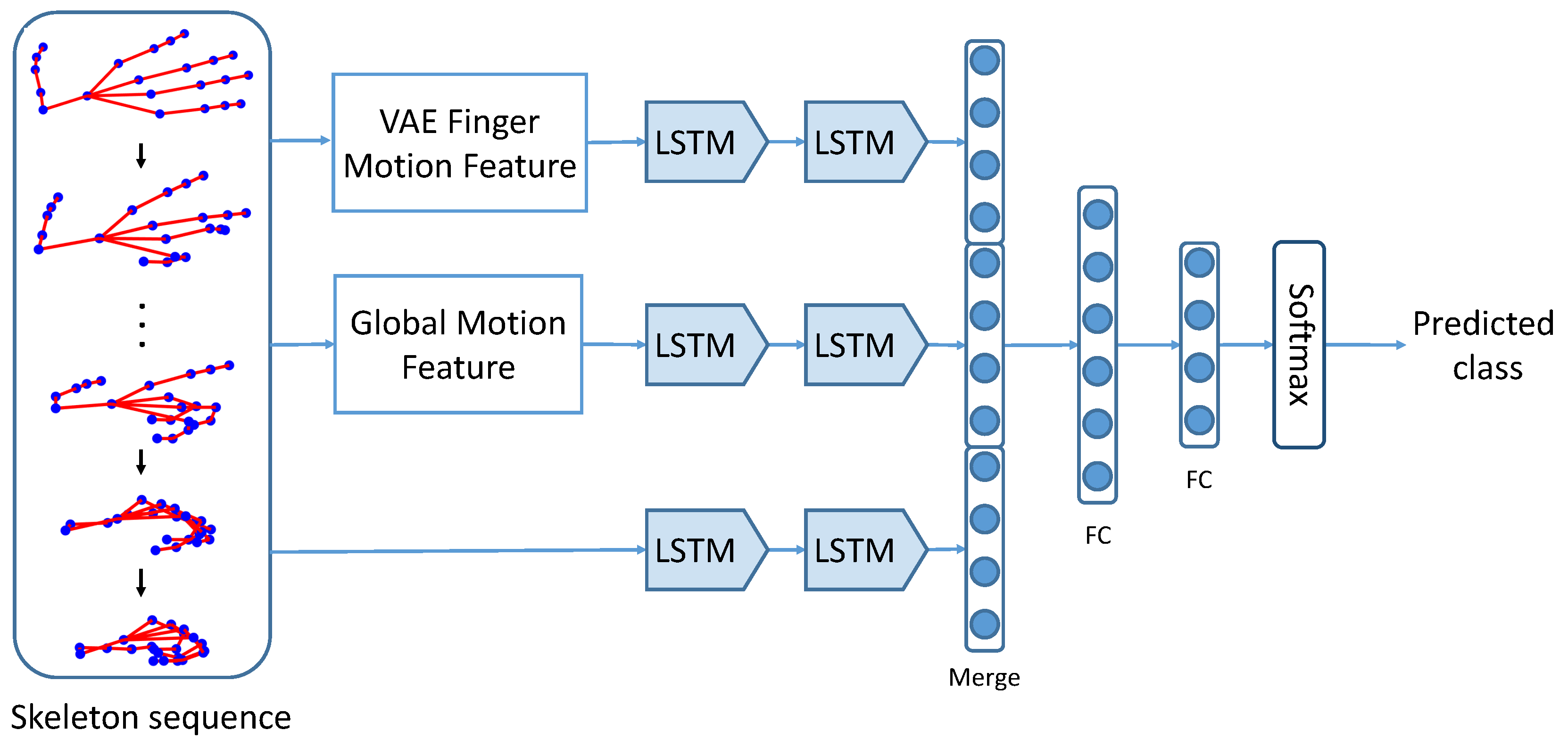
3. Overview of the Proposed Framework
4. Motion Feature Extraction
4.1. Global Motion Feature
4.2. Finger Motion Feature
4.2.1. Kinematic Finger Motion Feature
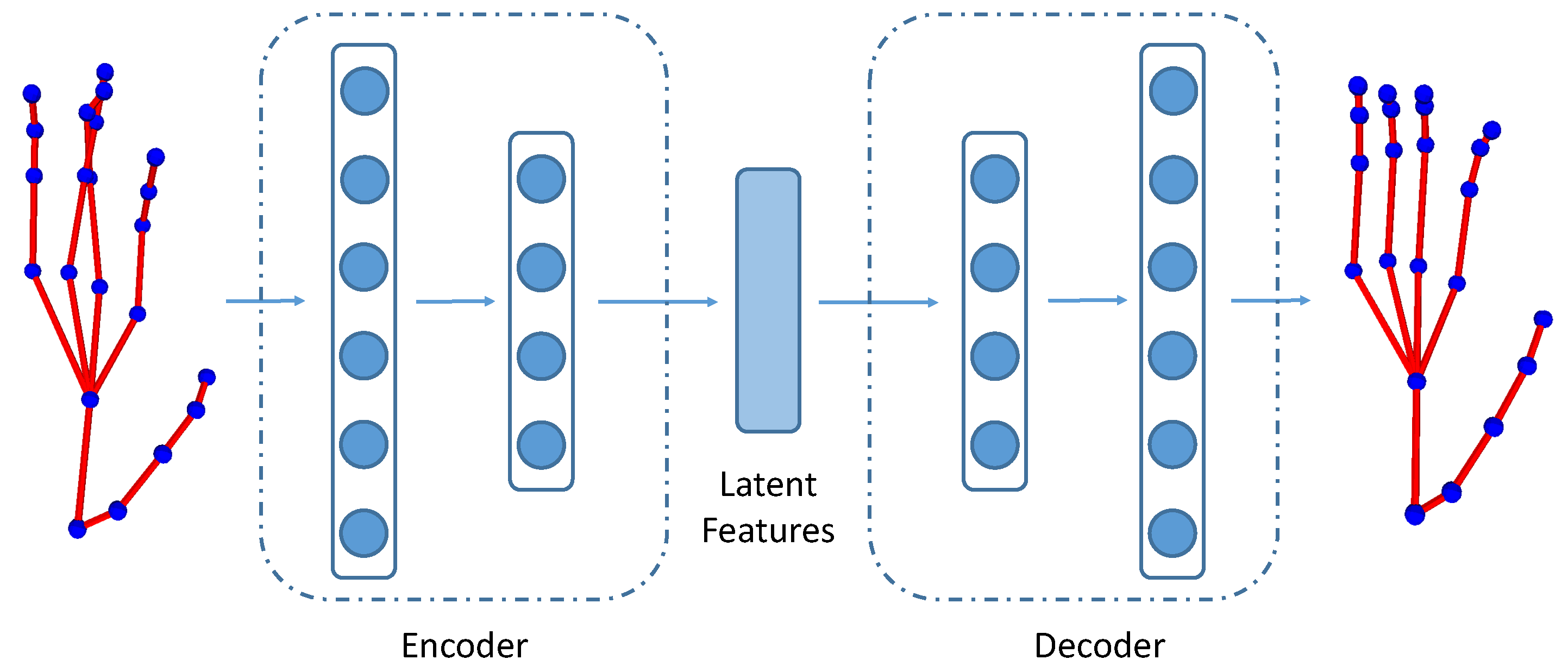
4.2.2. VAE Finger Motion Feature
5. Experiments
5.1. Implementation
5.2. Comparison with State-Of-The-Art Methods
5.2.1. DHG-14/28 Dataset
5.2.2. SHREC’17 Dataset
5.3. Ablation Studies
5.3.1. The Contributions of Motion Features Augmentation
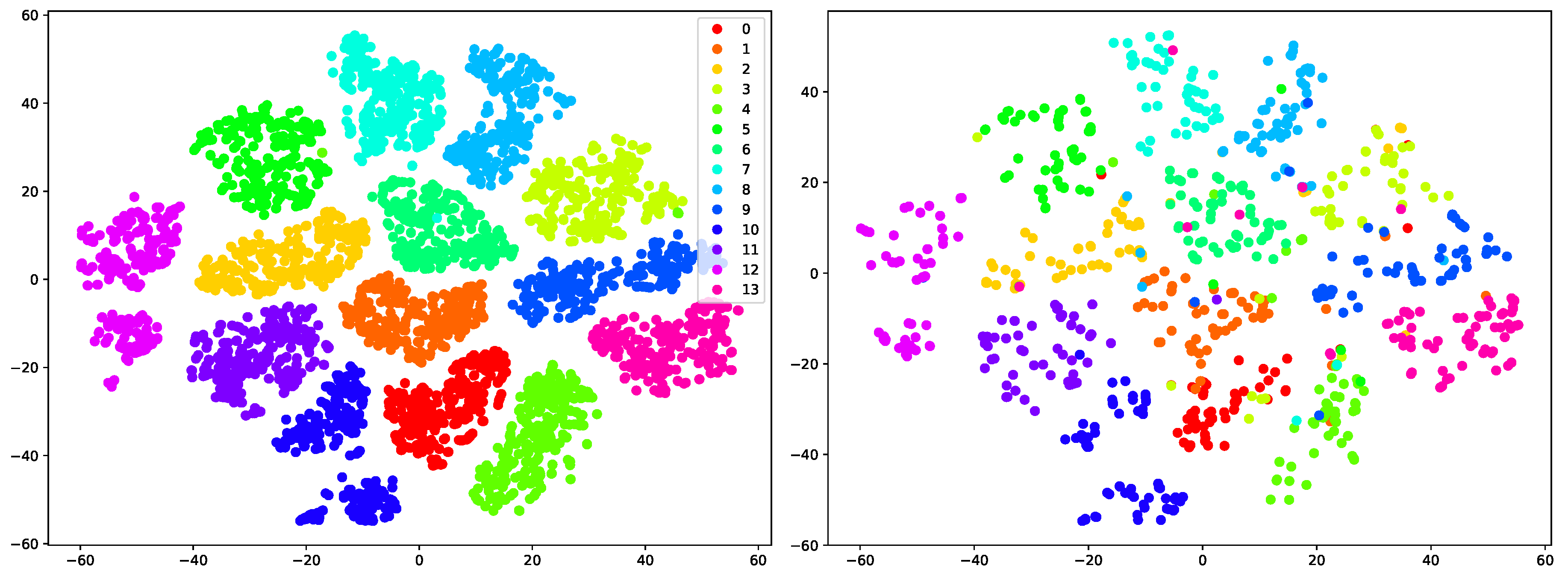
5.3.2. The Contributions of VAE Features
5.3.3. The Contributions of DAD Strategy
5.3.4. The Impacts of Different Classifiers
5.4. Run Time Analysis
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
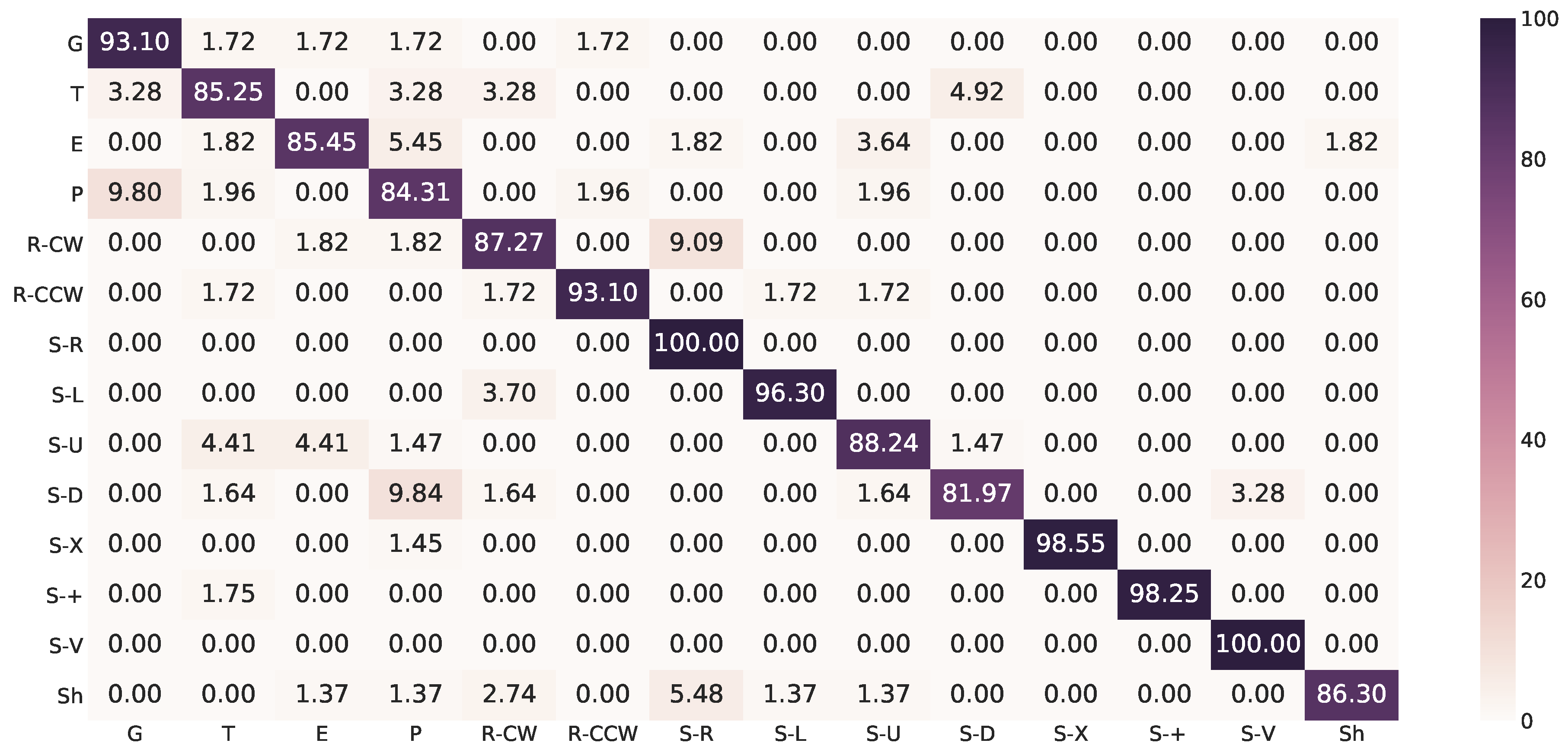
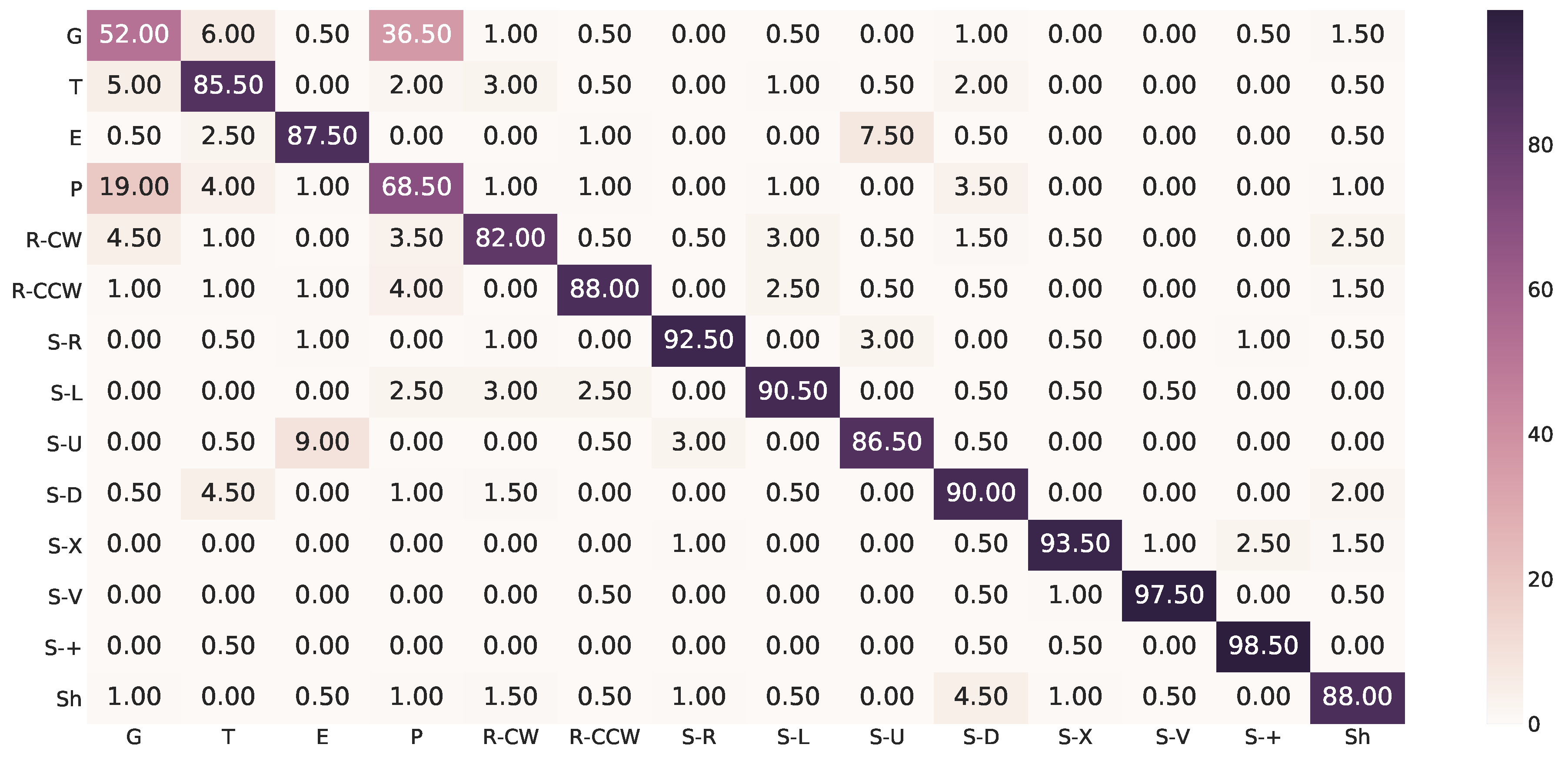
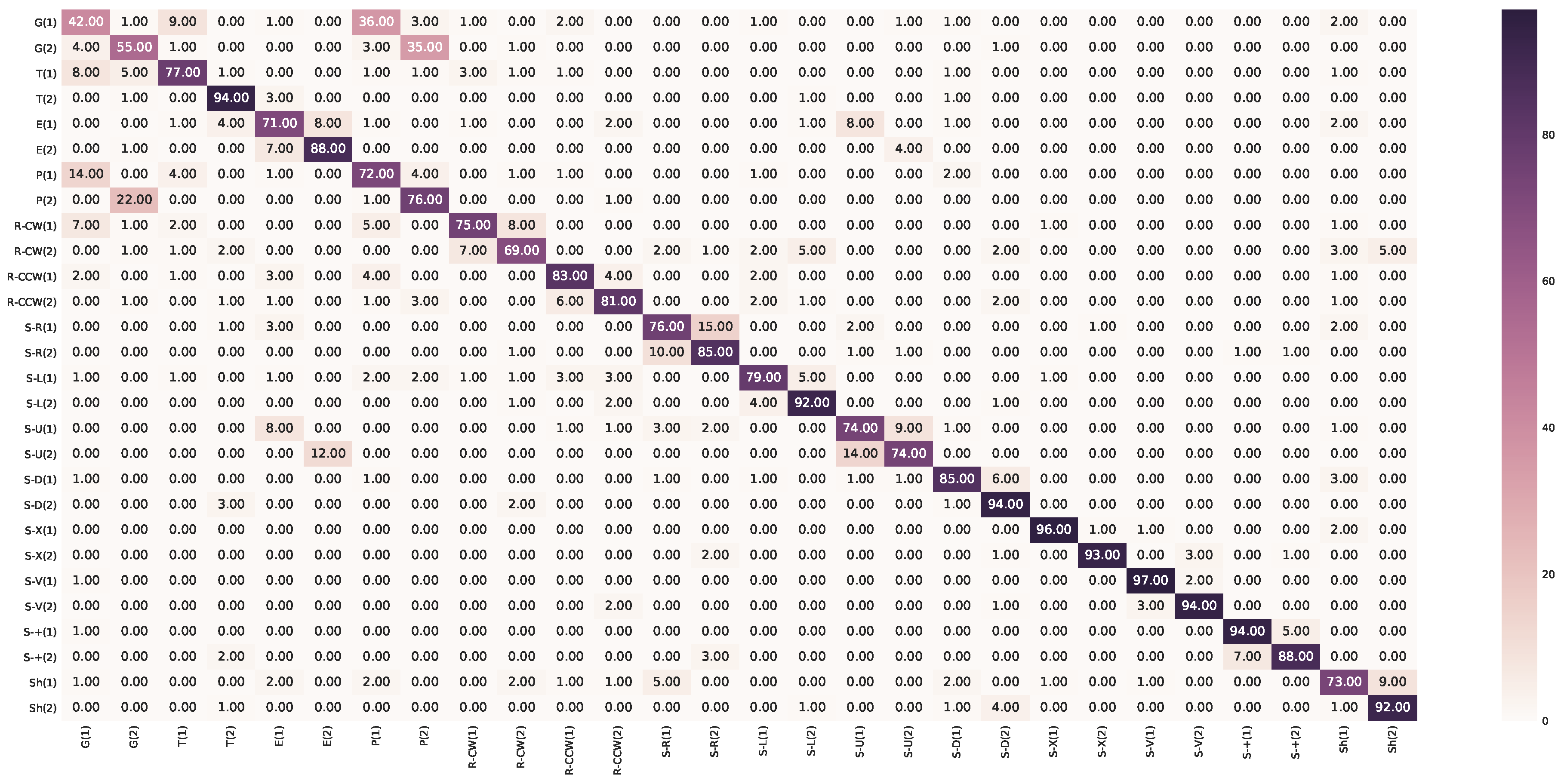
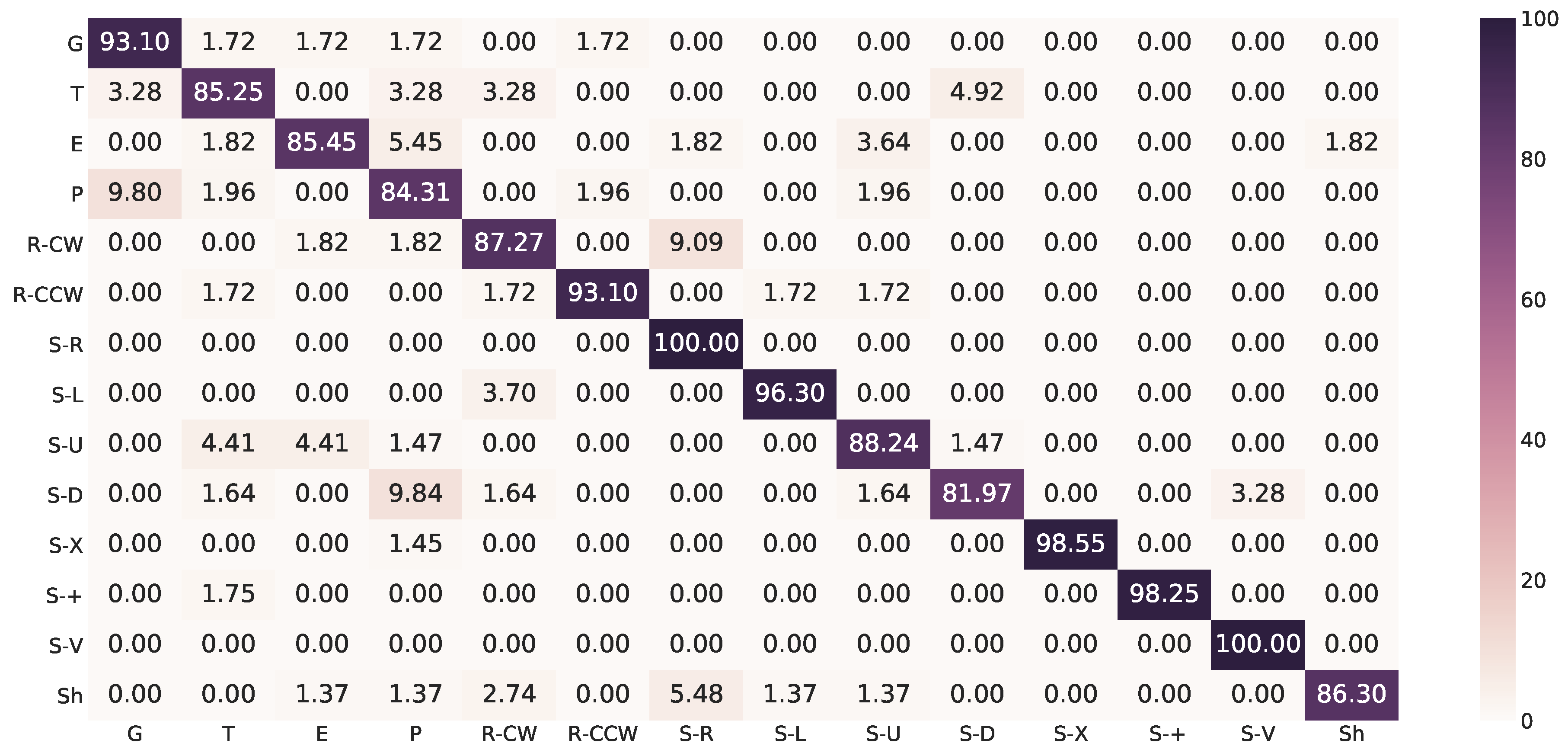
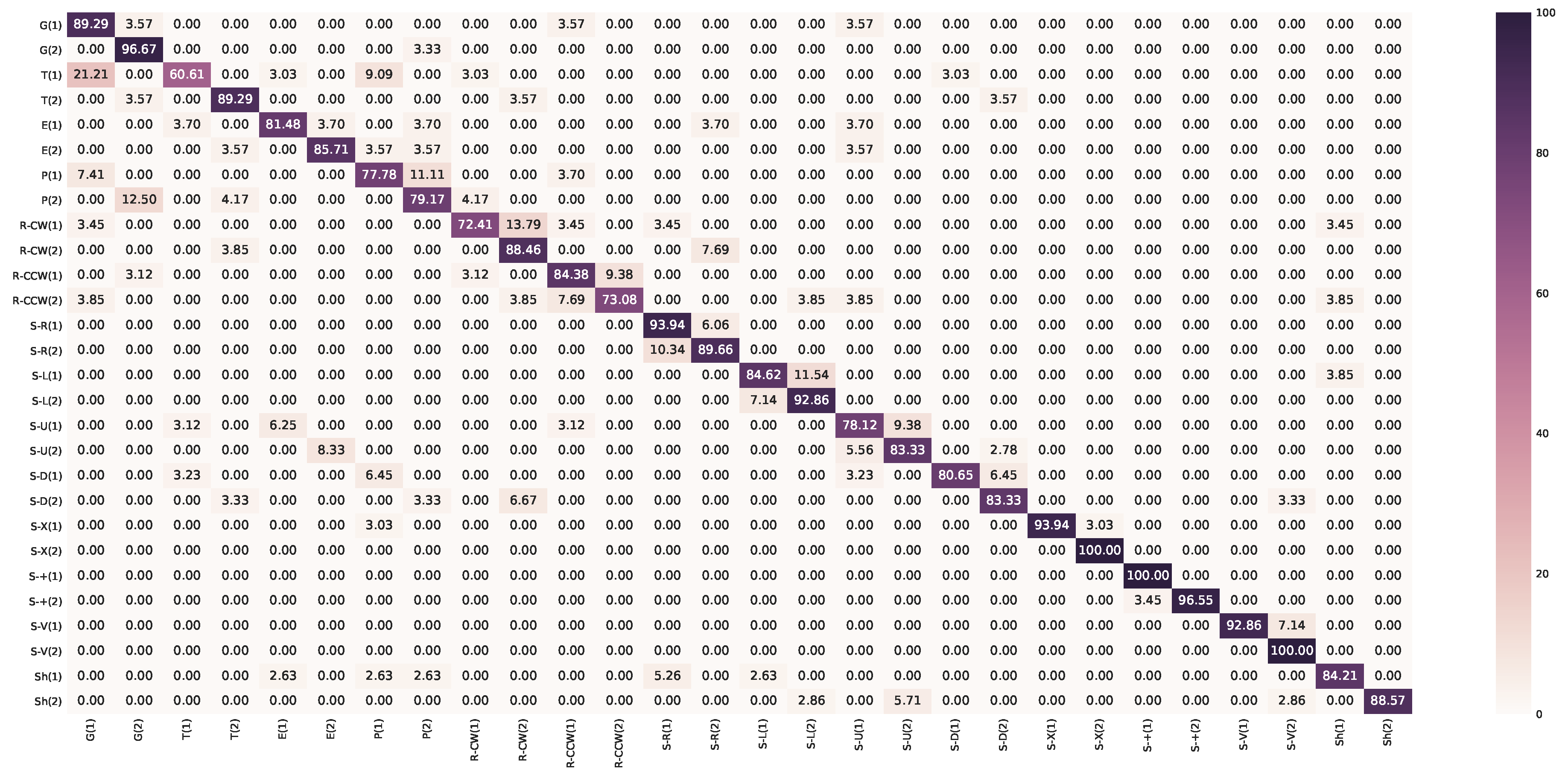
Appendix A. Confusion Matrices



References
- Mitra, S.; Acharya, T. Gesture recognition: A survey. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2007, 37, 311–324. [Google Scholar] [CrossRef]
- Zeng, B.; Wang, G.; Lin, X. A hand gesture based interactive presentation system utilizing heterogeneous cameras. Tsinghua Sci. Technol. 2012, 17, 329–336. [Google Scholar] [CrossRef]
- Chen, X.; Shi, C.; Liu, B. Static hand gesture recognition based on finger root-center-angle and length weighted Mahalanobis distance. In Proceedings of the SPIE 9897, Real-Time Image and Video Processing, Brussels, Belgium, 3–7 April 2016. [Google Scholar]
- Dong, C.; Leu, M.C.; Yin, Z. American sign language alphabet recognition using microsoft kinect. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ohn-Bar, E.; Trivedi, M.M. Hand gesture recognition in real time for automotive interfaces: A multimodal vision-based approach and evaluations. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2368–2377. [Google Scholar] [CrossRef]
- Molchanov, P.; Yang, X.; Gupta, S.; Kim, K.; Tyree, S.; Kautz, J. Online detection and classification of dynamic hand gestures with recurrent 3d convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Neverova, N.; Wolf, C.; Taylor, G.; Nebout, F. ModDrop: Adaptive Multi-Modal Gesture Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1692–1706. [Google Scholar] [CrossRef] [Green Version]
- Palacios, J.M.; Sagüés, C.; Montijano, E.; Llorente, S. Human-computer interaction based on hand gestures using RGB-D sensors. Sensors 2013, 13, 11842–11860. [Google Scholar] [CrossRef] [PubMed]
- Choi, H.R.; Kim, T. Combined dynamic time warping with multiple sensors for 3D gesture recognition. Sensors 2017, 17, 1893. [Google Scholar] [CrossRef]
- Abraham, L.; Urru, A.; Normani, N.; Wilk, M.; Walsh, M.; O’Flynn, B. Hand tracking and gesture recognition using lensless smart sensors. Sensors 2018, 18, 2834. [Google Scholar] [CrossRef]
- Zhou, Q.; Xing, J.; Chen, W.; Zhang, X.; Yang, Q. From Signal to Image: Enabling Fine-Grained Gesture Recognition with Commercial Wi-Fi Devices. Sensors 2018, 18, 3142. [Google Scholar] [CrossRef]
- Wang, X.; Tanaka, J. GesID: 3D Gesture Authentication Based on Depth Camera and One-Class Classification. Sensors 2018, 18, 3265. [Google Scholar] [CrossRef]
- Wen, R.; Tay, W.L.; Nguyen, B.P.; Chng, C.B.; Chui, C.K. Hand gesture guided robot-assisted surgery based on a direct augmented reality interface. Comput. Methods Programs Biomed. 2014, 116, 68–80. [Google Scholar] [CrossRef]
- Wen, R.; Nguyen, B.P.; Chng, C.B.; Chui, C.K. In situ spatial AR surgical planning using projector-Kinect system. In Proceedings of the Fourth Symposium on Information and Communication Technology, Danang, Vietnam, 5–6 December 2013. [Google Scholar]
- Ren, Z.; Yuan, J.; Meng, J.; Zhang, Z. Robust part-based hand gesture recognition using kinect sensor. IEEE Trans. Multimed. 2013, 15, 1110–1120. [Google Scholar] [CrossRef]
- Wang, G.; Yin, X.; Pei, X.; Shi, C. Depth estimation for speckle projection system using progressive reliable points growing matching. Appl. Opt. 2013, 52, 516–524. [Google Scholar] [CrossRef]
- Shi, C.; Wang, G.; Yin, X.; Pei, X.; He, B.; Lin, X. High-accuracy stereo matching based on adaptive ground control points. IEEE Trans. Image Process. 2015, 24, 1412–1423. [Google Scholar]
- Supancic, J.S.; Rogez, G.; Yang, Y.; Shotton, J.; Ramanan, D. Depth-based hand pose estimation: Data, methods, and challenges. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Oberweger, M.; Wohlhart, P.; Lepetit, V. Training a feedback loop for hand pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Tang, D.; Taylor, J.; Kohli, P.; Keskin, C.; Kim, T.K.; Shotton, J. Opening the black box: Hierarchical sampling optimization for estimating human hand pose. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ye, Q.; Yuan, S.; Kim, T.K. Spatial Attention Deep Net with Partial PSO for Hierarchical Hybrid Hand Pose Estimation. In Proceedings of the The European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Guo, H.; Wang, G.; Chen, X.; Zhang, C.; Qiao, F.; Yang, H. Region Ensemble Network: Improving Convolutional Network for Hand Pose Estimation. In Proceedings of the 24th IEEE International Conference on Image Processing, Beijing, China, 12–17 September 2017. [Google Scholar]
- Chen, X.; Wang, G.; Guo, H.; Zhang, C. Pose Guided Structured Region Ensemble Network for Cascaded Hand Pose Estimation. arXiv 2017, arXiv:1708.03416. [Google Scholar]
- Wang, G.; Chen, X.; Guo, H.; Zhang, C. Region Ensemble Network: Towards Good Practices for Deep 3D Hand Pose Estimation. J. Vis. Commun. Image Represent. 2018, 55, 404–414. [Google Scholar] [CrossRef]
- Chen, X.; Wang, G.; Zhang, C.; Kim, T.K.; Ji, X. SHPR-Net: Deep Semantic Hand Pose Regression from Point Clouds. IEEE Access 2018, 6, 43425–43439. [Google Scholar] [CrossRef]
- Motion, L. Leap Motion Controller. 2015. Available online: https://www.leapmotion.com (accessed on 2 December 2018).
- Keselman, L.; Iselin Woodfill, J.; Grunnet-Jepsen, A.; Bhowmik, A.; Gupta, M.; Jauhari, A.; Kulkarni, K.; Jayasuriya, S.; Molnar, A.; Turaga, P.; et al. Intel RealSense Stereoscopic Depth Cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Venice, Italy, 21–26 July 2017. [Google Scholar]
- De Smedt, Q.; Wannous, H.; Vandeborre, J.P. Skeleton-based Dynamic hand gesture recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- De Smedt, Q.; Wannous, H.; Vandeborre, J.P. 3D Hand Gesture Recognition by Analysing Set-of-Joints Trajectories. In Proceedings of the International Conference on Pattern Recognition (ICPR)/UHA3DS 2016 Workshop, Cancun, Mexico, 4 December 2016. [Google Scholar]
- Boulahia, S.Y.; Anquetil, E.; Multon, F.; Kulpa, R. Dynamic hand gesture recognition based on 3D pattern assembled trajectories. In Proceedings of the 7th IEEE International Conference on Image Processing Theory, Tools and Applications (IPTA 2017), Montreal, QC, Canada, 28 November–1 December 2017. [Google Scholar]
- Caputo, F.M.; Prebianca, P.; Carcangiu, A.; Spano, L.D.; Giachetti, A. Comparing 3D trajectories for simple mid-air gesture recognition. Comput. Gr. 2018, 73, 17–25. [Google Scholar] [CrossRef]
- Núñez, J.C.; Cabido, R.; Pantrigo, J.J.; Montemayor, A.S.; Vélez, J.F. Convolutional Neural Networks and Long Short-Term Memory for skeleton-based human activity and hand gesture recognition. Pattern Recognit. 2018, 76, 80–94. [Google Scholar] [CrossRef]
- Ma, C.; Wang, A.; Chen, G.; Xu, C. Hand joints-based gesture recognition for noisy dataset using nested interval unscented Kalman filter with LSTM network. Vis. Comput. 2018, 34, 1053–1063. [Google Scholar] [CrossRef]
- De Smedt, Q.; Wannous, H.; Vandeborre, J.P.; Guerry, J.; Le Saux, B.; Filliat, D. SHREC’17 Track: 3D Hand Gesture Recognition Using a Depth and Skeletal Dataset. In Proceedings of the 10th Eurographics Workshop on 3D Object Retrieval, Lyon, France, 23–24 April 2017. [Google Scholar]
- Chen, X.; Guo, H.; Wang, G.; Zhang, L. Motion Feature Augmented Recurrent Neural Network for Skeleton-based Dynamic Hand Gesture Recognition. In Proceedings of the 24th IEEE International Conference on Image Processing (ICIP), Beijing, China, 7–20 September 2017. [Google Scholar]
- Cheng, H.; Yang, L.; Liu, Z. Survey on 3D Hand Gesture Recognition. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 1659–1673. [Google Scholar] [CrossRef]
- Asadi-Aghbolaghi, M.; Clapés, A.; Bellantonio, M.; Escalante, H.J.; Ponce-López, V.; Baró, X.; Guyon, I.; Kasaei, S.; Escalera, S. Deep learning for action and gesture recognition in image sequences: A survey. In Gesture Recognition; Springer: Belin, Germany, 2017; pp. 539–578. [Google Scholar]
- Cheok, M.J.; Omar, Z.; Jaward, M.H. A review of hand gesture and sign language recognition techniques. Int. J. Mach. Learn. Cybern. 2017. [Google Scholar] [CrossRef]
- Wang, P.; Li, W.; Ogunbona, P.; Wan, J.; Escalera, S. RGB-D-based human motion recognition with deep learning: A survey. Comput. Vis. Image Understand. 2018, 171, 118–139. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Liu, Z.; Chan, S.C. Superpixel-based hand gesture recognition with kinect depth camera. IEEE Trans. Multimed. 2015, 17, 29–39. [Google Scholar] [CrossRef]
- Koller, O.; Ney, H.; Bowden, R. Deep hand: How to train a CNN on 1 million hand images when your data is continuous and weakly labelled. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, P.; Li, Z.; Hou, Y.; Li, W. Action recognition based on joint trajectory maps using convolutional neural networks. In Proceedings of the 2016 ACM on Multimedia Conference, Amsterdam, The Netherlands, 15–19 October 2016. [Google Scholar]
- Hou, Y.; Wang, S.; Wang, P.; Gao, Z.; Li, W. Spatially and temporally structured global to local aggregation of dynamic depth information for action recognition. IEEE Access 2018, 6, 2206–2219. [Google Scholar] [CrossRef]
- Zhu, G.; Zhang, L.; Shen, P.; Song, J. Multimodal gesture recognition using 3-D convolution and convolutional LSTM. IEEE Access 2017, 5, 4517–4524. [Google Scholar] [CrossRef]
- Zhang, L.; Zhu, G.; Shen, P.; Song, J.; Shah, S.A.; Bennamoun, M. Learning spatiotemporal features using 3D CNN and convolutional lstm for gesture recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wan, J.; Guo, G.; Li, S.Z. Explore efficient local features from RGB-D data for one-shot learning gesture recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1626–1639. [Google Scholar] [CrossRef]
- Wan, J.; Ruan, Q.; Li, W.; An, G.; Zhao, R. 3D SMoSIFT: three-dimensional sparse motion scale invariant feature transform for activity recognition from RGB-D videos. J. Electron. Imaging 2014, 23, 023017. [Google Scholar] [CrossRef]
- Wan, J.; Ruan, Q.; Li, W.; Deng, S. One-shot learning gesture recognition from RGB-D data using bag of features. J. Mach. Learn. Res. 2013, 14, 2549–2582. [Google Scholar]
- Wan, J.; Zhao, Y.; Zhou, S.; Guyon, I.; Escalera, S.; Li, S.Z. Chalearn looking at people RGB-D isolated and continuous datasets for gesture recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Köpüklü, O.; Köse, N.; Rigoll, G. Motion Fused Frames: Data Level Fusion Strategy for Hand Gesture Recognition. arXiv, 2018; arXiv:1804.07187. [Google Scholar]
- Boulahia, S.Y.; Anquetil, E.; Kulpa, R.; Multon, F. HIF3D: Handwriting-Inspired Features for 3D skeleton-based action recognition. In Proceedings of the 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016. [Google Scholar]
- Sadanandan, S.K.; Ranefall, P.; Wählby, C. Feature Augmented Deep Neural Networks for Segmentation of Cells. In Proceedings of the European Conference on Computer Vision Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016. [Google Scholar]
- Egede, J.; Valstar, M.; Martinez, B. Fusing deep learned and hand-crafted features of appearance, shape, and dynamics for automatic pain estimation. In Proceedings of the 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Amsterdam, The Netherlands, 8–10 October 2017. [Google Scholar]
- Manivannan, S.; Li, W.; Zhang, J.; Trucco, E.; McKenna, S.J. Structure Prediction for Gland Segmentation with Hand-Crafted and Deep Convolutional Features. IEEE Trans. Med. Imaging 2018, 37, 210–221. [Google Scholar] [CrossRef]
- Wang, S.; Hou, Y.; Li, Z.; Dong, J.; Tang, C. Combining convnets with hand-crafted features for action recognition based on an HMM-SVM classifier. Multimed. Tools Appl. 2016, 77, 18983–18998. [Google Scholar] [CrossRef]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Kabsch, W. A solution for the best rotation to relate two sets of vectors. Acta Crystallogr. Sect. A 1976, 32, 922–923. [Google Scholar] [CrossRef] [Green Version]
- Liang, H.; Yuan, J.; Thalmann, D. Parsing the hand in depth images. IEEE Trans. Multimed. 2014, 16, 1241–1253. [Google Scholar] [CrossRef]
- Chen, H.; Wang, G.; Xue, J.H.; He, L. A novel hierarchical framework for human action recognition. Pattern Recognit. 2016, 55, 148–159. [Google Scholar] [CrossRef] [Green Version]
- Chollet, F. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 16 July 2018).
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Oreifej, O.; Liu, Z. Hon4d: Histogram of oriented 4d normals for activity recognition from depth sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Ohn-Bar, E.; Trivedi, M. Joint angles similarities and HOG2 for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Lai, K.; Yanushkevich, S.N. CNN + RNN Depth and Skeleton based Dynamic Hand Gesture Recognition. In Proceedings of the 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018. [Google Scholar]
- Devanne, M.; Wannous, H.; Berretti, S.; Pala, P.; Daoudi, M.; Del Bimbo, A. 3-d human action recognition by shape analysis of motion trajectories on riemannian manifold. IEEE Trans. Cybern. 2015, 45, 1340–1352. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, B.P.; Tay, W.L.; Chui, C.K. Robust Biometric Recognition From Palm Depth Images for Gloved Hands. IEEE Trans. Hum.-Mach. Syst. 2015, 45, 799–804. [Google Scholar] [CrossRef]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | DHG-14 | DHG-28 | ||
|---|---|---|---|---|
| Fine | Coarse | Both | Both | |
| HON4D [62] | - | - | 75.53 | 74.03 |
| HOG [63] | - | - | 80.85 | 76.53 |
| Smedt et al. [29] | - | - | 82.50 | 68.11 |
| SoCJ + HoHD + HoWR [28] | 73.60 | 88.33 | 83.07 | 80.0 |
| NIUKF-LSTM [33] | - | - | 84.92 | 80.44 |
| SL-fusion-Average [64] | 76.00 | 90.72 | 85.46 | 74.19 |
| CNN + LSTM [32] | 78.0 | 89.8 | 85.6 | 81.1 |
| MFA-Net (Ours) | 75.60 | 91.39 | 85.75 | 81.04 |
| Method | 14 Gestures | 28 Gestures |
|---|---|---|
| HOD4D [62] | 78.53 | 74.03 |
| Riemannian Manifold [65] | 79.61 | 62.00 |
| Key Frames [34] | 82.90 | 71.90 |
| HOG [63] | 83.85 | 76.53 |
| SoCJ + HoHD + HoWR [28] | 88.24 | 81.90 |
| 3 cent + OED + FAD [31] | 89.52 | - |
| Boulahia et al. [30] | 90.48 | 80.48 |
| MFA-Net (Ours) | 91.31 | 86.55 |
| Method | Fine | Coarse | Both | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Best | Worst | Avg ± Std | Best | Worst | Avg ± Std | Best | Worst | Avg ± Std | |
| Skeleton | 86.0 | 42.0 | 61.2 ± 12.37 | 97.78 | 74.44 | 86.44 ± 7.94 | 93.57 | 67.86 | 77.43 ± 6.82 |
| MF(Kinematic) | 84.0 | 46.0 | 71.5 ± 11.44 | 96.67 | 64.44 | 81.94 ± 8.17 | 90.0 | 58.57 | 78.21 ± 7.49 |
| S + MF(Kinematic) | 90.0 | 56.0 | 76.9 ± 9.19 | 97.78 | 72.22 | 89.0 ± 7.55 | 94.29 | 67.86 | 84.68 ± 6.67 |
| S + MF(VAE) | 96.0 | 48.0 | 75.6 ± 10.29 | 100.0 | 76.67 | 91.39 ± 7.30 | 96.43 | 71.43 | 85.75 ± 6.71 |
| Method | Fine | Coarse | Both | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Best | Worst | Avg ± Std | Best | Worst | Avg ± Std | Best | Worst | Avg ± Std | |
| MFA-Net w/o DAD | 92.0 | 42.0 | 74.2 ± 11.81 | 100.0 | 75.56 | 90.39 ± 6.89 | 97.14 | 67.86 | 84.60 ± 7.22 |
| MFA-Net | 96.0 | 48.0 | 75.6 ± 10.29 | 100.0 | 76.67 | 91.39 ± 7.30 | 96.43 | 71.43 | 85.75 ± 6.71 |
| Method | 14 Gestures | 28 Gestures |
|---|---|---|
| k-NN | 90.60 | 86.07 |
| CD k-NN [66] | 90.83 | 86.07 |
| Random Forest | 90.36 | 85.24 |
| FC Layers (Ours) | 91.31 | 86.55 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Wang, G.; Guo, H.; Zhang, C.; Wang, H.; Zhang, L. MFA-Net: Motion Feature Augmented Network for Dynamic Hand Gesture Recognition from Skeletal Data. Sensors 2019, 19, 239. https://doi.org/10.3390/s19020239
Chen X, Wang G, Guo H, Zhang C, Wang H, Zhang L. MFA-Net: Motion Feature Augmented Network for Dynamic Hand Gesture Recognition from Skeletal Data. Sensors. 2019; 19(2):239. https://doi.org/10.3390/s19020239
Chicago/Turabian StyleChen, Xinghao, Guijin Wang, Hengkai Guo, Cairong Zhang, Hang Wang, and Li Zhang. 2019. "MFA-Net: Motion Feature Augmented Network for Dynamic Hand Gesture Recognition from Skeletal Data" Sensors 19, no. 2: 239. https://doi.org/10.3390/s19020239
APA StyleChen, X., Wang, G., Guo, H., Zhang, C., Wang, H., & Zhang, L. (2019). MFA-Net: Motion Feature Augmented Network for Dynamic Hand Gesture Recognition from Skeletal Data. Sensors, 19(2), 239. https://doi.org/10.3390/s19020239