Vehicle Logo Recognition Based on Enhanced Matching for Small Objects, Constrained Region and SSFPD Network


Abstract
:1. Introduction
- (1)
- An enhanced matching approach based on constrained region segmentation and copy-pasting strategy is proposed to improve the contribution of small objects to feature learning in network training, which is verified in the experiment.
- (2)
- In order to further improve the detection accuracy, the proposed SSFPD network not only uses a better feature network to improve the capability of feature extraction, but also adds more semantic information about the small object for the prediction process.
- (3)
- In this paper, a large common vehicle logo dataset (CVLD) containing various manufacturers is generated to evaluate the proposed method.
2. Related Works
2.1. Vehicle Logo Detection
2.2. Vehicle Logo Classification
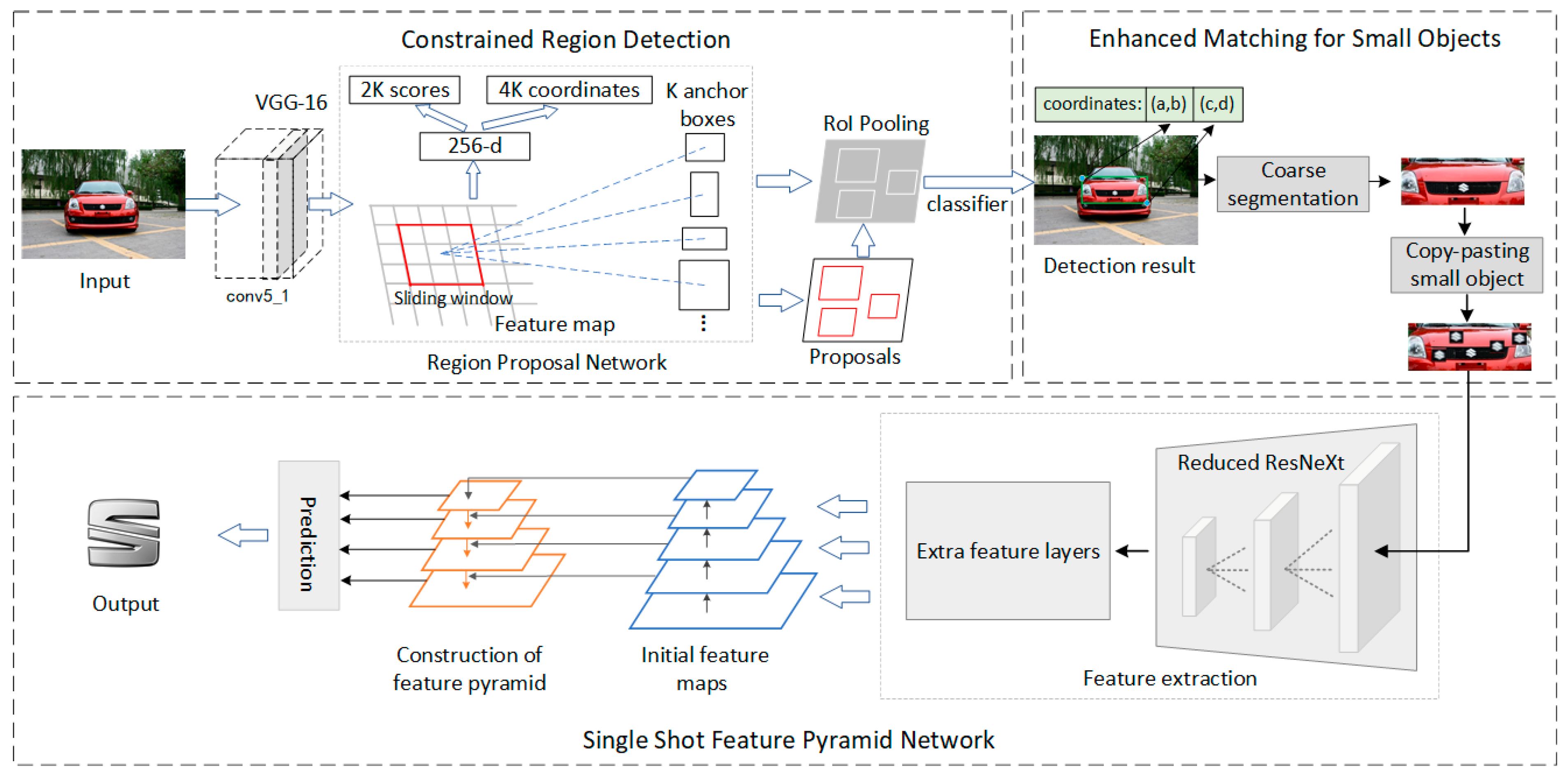
3. Overview of Proposed Method for Vehicle Logo Recognition
4. Logo Location Based on Constrained Region Detection and Enhanced Matching Method
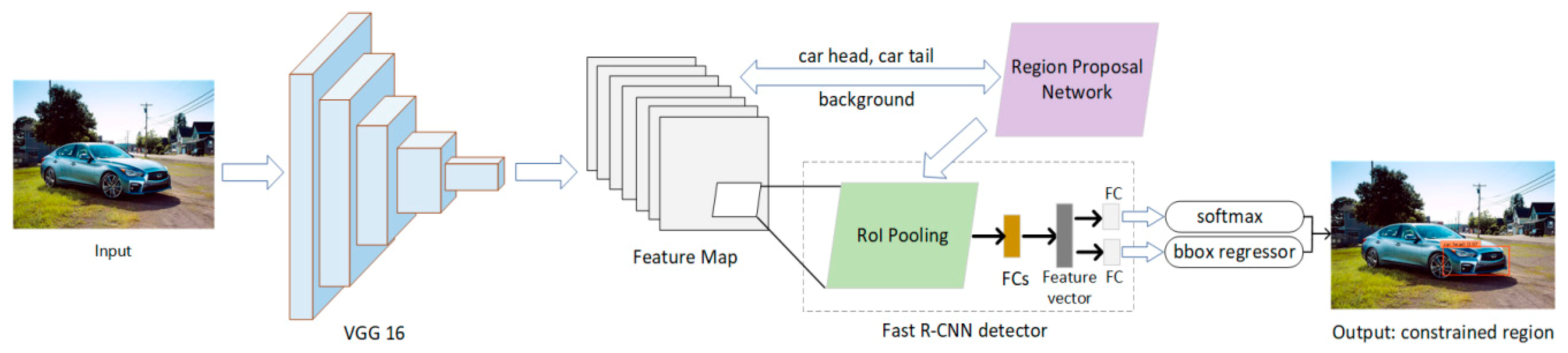
4.1. Constrained Region Detection Using Faster R-CNN
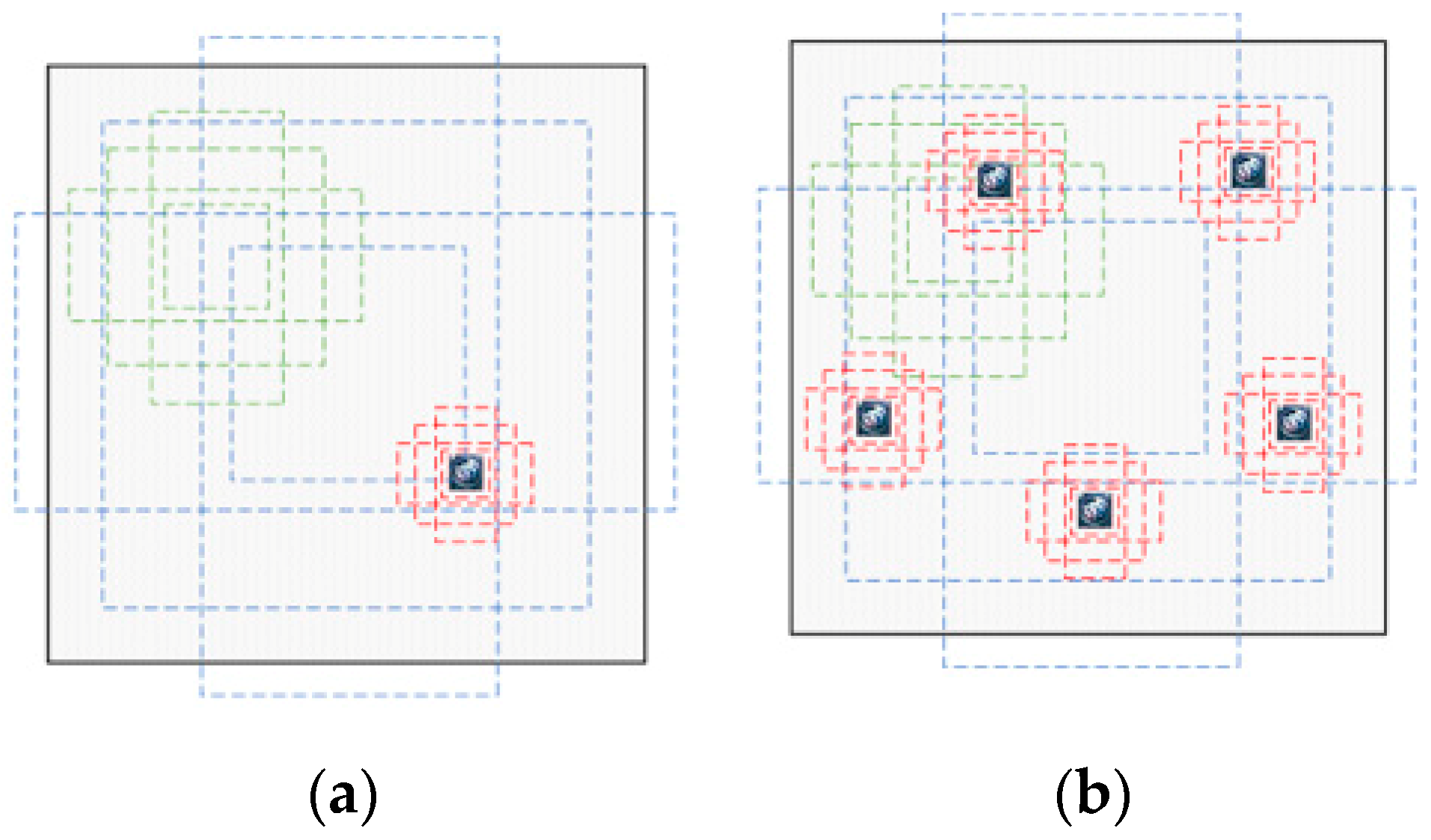
4.2. Enhanced Matching for Small Objects
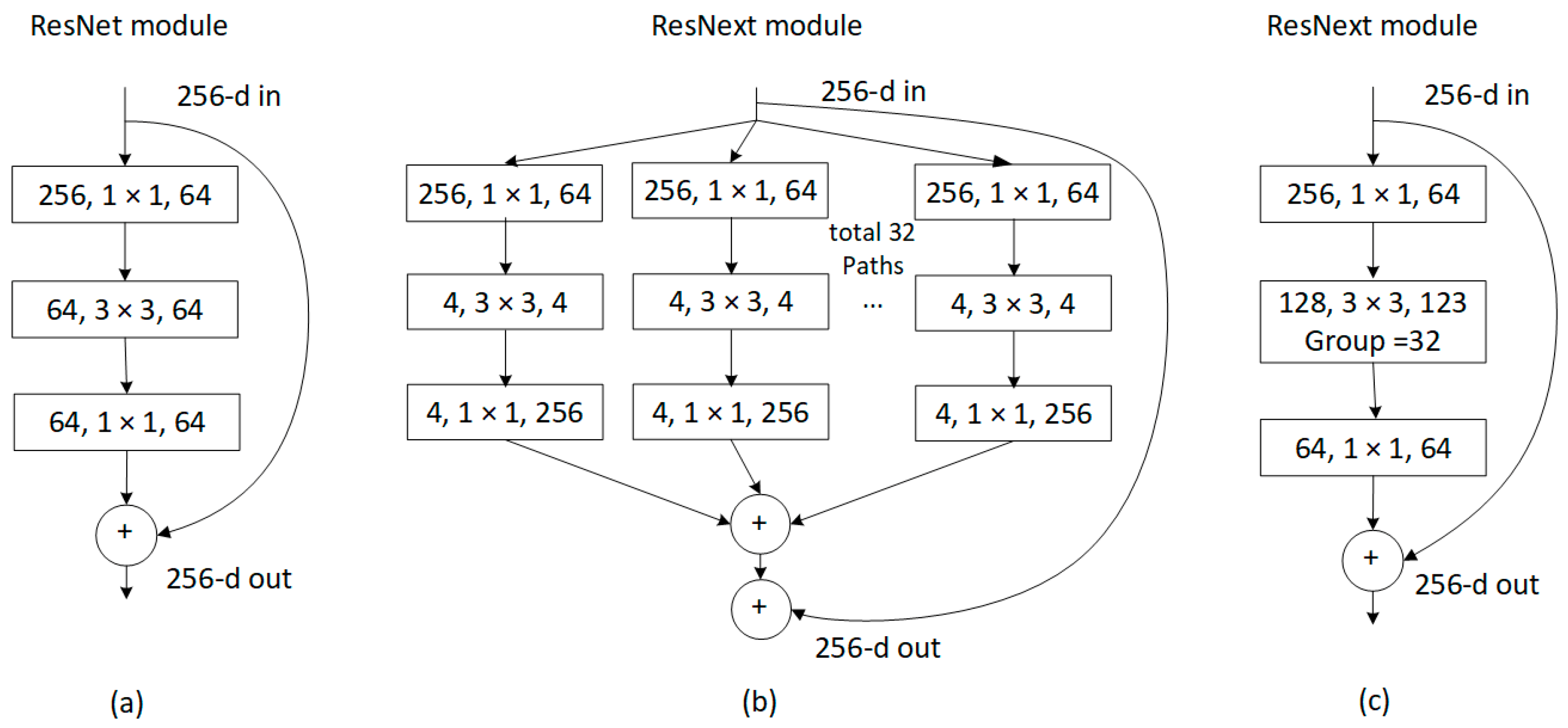
5. Proposed SSFPD Network
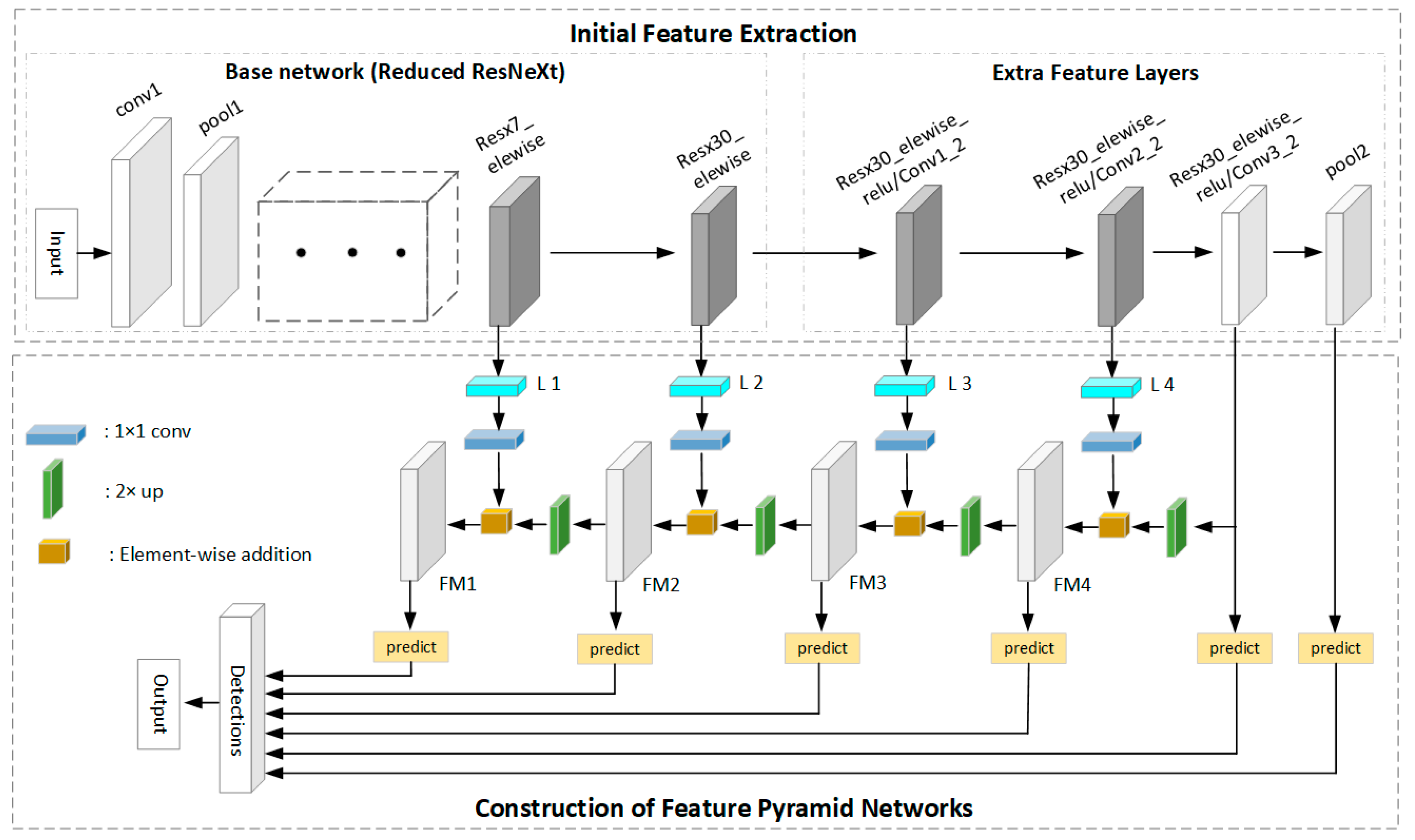
5.1. Initial Feature Extraction
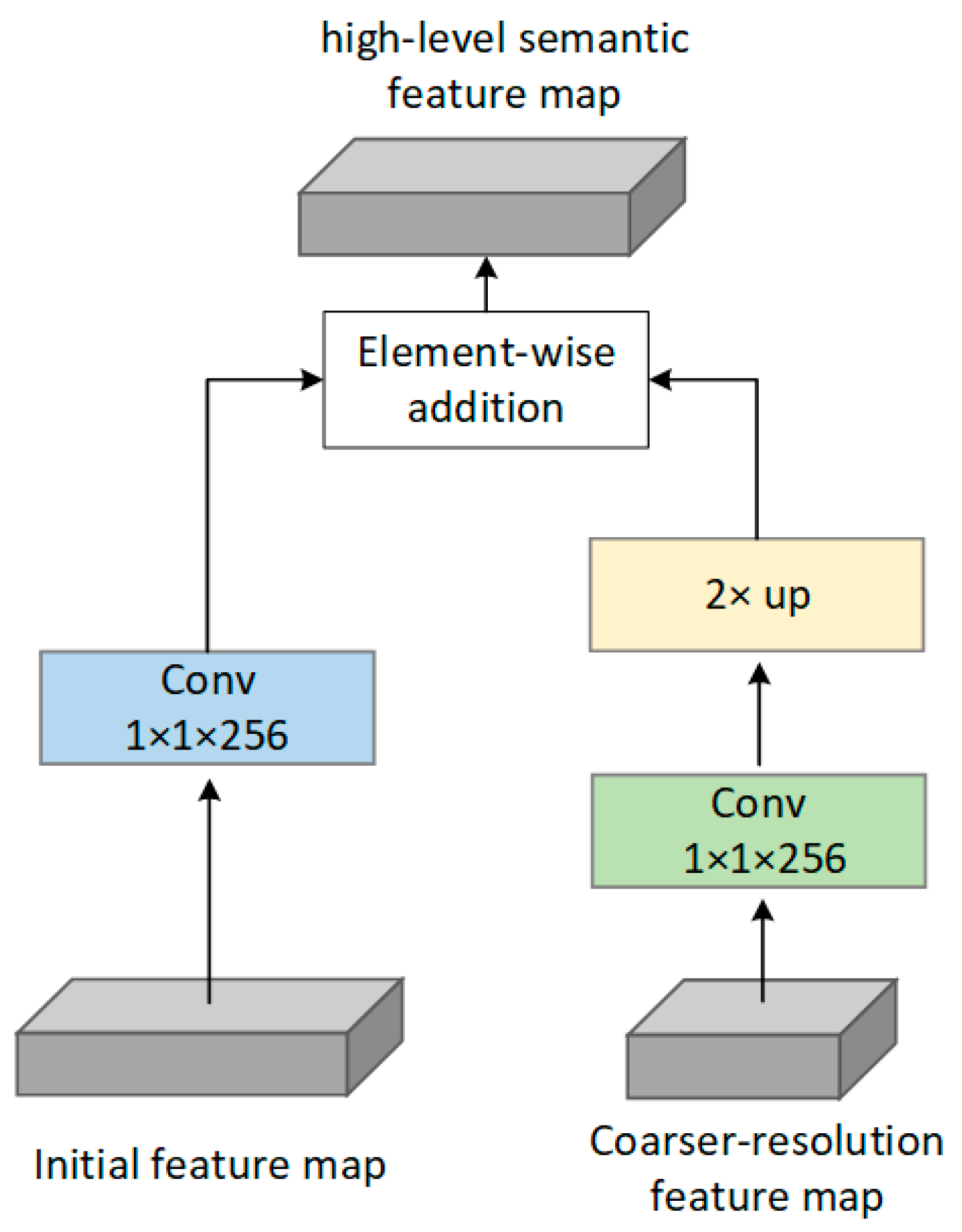
5.2. Generation of the FPN Network and Object Recognition
6. Experiments
6.1. Date Set Descriptions
6.2. Implementation Details and Model Analysis
6.3. Experimental Results
6.3.1. Comparison of Different Methods
6.3.2. Performance on Various Complex Conditions
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chen, L.; Hsieh, J.; Yan, Y.; Chen, D. Vehicle make and model recognition using sparse representation and symmetrical SURFs. Pattern Recognit. 2015, 48, 1979–1998. [Google Scholar] [CrossRef]
- Boukerche, A.; Siddiqui, A.; Mammeri, A. Automated vehicle detection and classification. ACM Comput. Surv. 2017, 50, 1–39. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, K.; Tian, Y.; Gou, C.; Wang, F. MFR-CNN: Incorporating multi-scale features and global information for traffic object detection. IEEE Trans. Veh. Technol. 2018, 67, 8019–8030. [Google Scholar] [CrossRef]
- Zhang, B.; Luan, S.; Chen, C.; Han, J.; Wang, W.; Alessandro, P. Latent Constrained Correlation Filter. IEEE Trans. Image Process. 2018, 27, 1038–1048. [Google Scholar] [CrossRef]
- Min, W.; Fan, M.; Guo, X.; Han, Q. A new approach to track multiple vehicles with the combination of robust detection and two classifiers. IEEE Trans. Intell. Transp. Syst. 2018, 19, 174–186. [Google Scholar] [CrossRef]
- Soon, F.; Khaw, H.; Chuah, J.; Kanesan, J. PCANet-Based convolutional neural network architecture for a vehicle model recognition system. IEEE Trans. Intell. Transp. Syst. 2019, 20, 749–759. [Google Scholar] [CrossRef]
- Lu, L.; Huang, H. A hierarchical scheme for vehicle make and model recognition from frontal images of vehicles. IEEE Trans. Intell. Transp. Syst. 2019, 20, 1774–1786. [Google Scholar] [CrossRef]
- Min, W.; Li, X.; Wang, Q.; Zeng, Q.; Liao, Y. New approach to vehicle license plate location based on new model YOLO-L and plate pre-identification. Image Process. 2019, 13, 1041–1049. [Google Scholar] [CrossRef]
- Zhang, B.; Gu, J.; Chen, C.; Han, J.; Sua, X.; Cao, X.; Liue, J. One-two-one networks for compression artifacts reduction in remote sensing. ISPRS J. Photogramm. Remote Sens. 2018, 145, 184–196. [Google Scholar] [CrossRef] [Green Version]
- Zhang, B.; Yang, Y.; Chen, C.; Yang, L.; Han, J.; Shao, L. Action recognition using 3D histograms of texture and a multi-class boosting classifier. IEEE Trans. Image Process. 2017, 26, 4648–4660. [Google Scholar] [CrossRef]
- Zhang, B.; Perina, A.; Li, Z.; Murino, V.; Liu, J.; Ji, R. Bounding Multiple Gaussians Uncertainty with Application to Object Tracking. Int. J. Comput. Vis. 2016, 3, 364–379. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1397–1400. [Google Scholar]
- Luan, S.; Chen, C.; Zhang, B.; Han, J.; Liu, J. Gabor convolutional networks. IEEE Trans. Image Process. 2018, 27, 4357–4366. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 10, 1499–1503. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Z.; Xiao, F. A fast coarse-to-fine vehicle logo detection and recognition method. In Proceedings of the 2007 IEEE International Conference on Robotics and Biomimetics (ROBIO), Sanya, China, 15–18 December 2007; pp. 691–696. [Google Scholar]
- Xie, L.; Ahmad, T.; Jin, L.; Liu, Y.; Zhang, S. A new CNN-based method for multi-directional car license plate detection. IEEE Trans. Intell. Transp. Syst. 2018, 19, 507–517. [Google Scholar] [CrossRef]
- Bulan, O.; Kozitsky, V.; Ramesh, P.; Shreve, M. Segmentation- and annotation-free license plate recognition with deep localization and failure identification. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2351–2363. [Google Scholar] [CrossRef]
- Peng, H.; Wang, X.; Wang, H.; Yang, W. Recognition of low-resolution logos in vehicle images based on statistical random sparse distribution. IEEE Trans. Intell. Transp. Syst. 2015, 16, 681–691. [Google Scholar] [CrossRef]
- Huang, Y.; Wu, R.; Sun, Y.; Wang, W.; Ding, X. Vehicle logo recognition system based on convolutional neural networks with a pretraining strategy. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1951–1960. [Google Scholar] [CrossRef]
- Li, W.; Li, L. A novel approach for vehicle logo location based on edge detection and morphological filter. In Proceedings of the 2009 Second International Symposium on Electronic Commerce and Security, Nanchang, China, 22–24 May 2009; pp. 343–345. [Google Scholar]
- Liu, Y.; Li, S. A vehicle-logo location approach based on edge detection and projection. In Proceedings of the IEEE International Conference on Vehicular Electronics and Safety, Beijing, China, 10–12 July 2011; pp. 165–168. [Google Scholar]
- Sulehria, H.; Zhang, Y. Vehicle logo recognition using mathematical morphology. In Proceedings of the Wseas International Conference on Telecommunications and Informatics, Dallas, TX, USA, 22–24 March 2007. [Google Scholar]
- Psyllos, A.; Anagnostopoulos, C.; Kayafas, E. Vehicle logo recognition using a SIFT-Based enhanced matching scheme. IEEE Trans. Intell. Transp. Syst. 2010, 11, 322–328. [Google Scholar] [CrossRef]
- Liu, H.; Huang, Z.; Talab, A. Patch-based vehicle logo detection with patch intensity and weight matrix. J. Cent. South Univ. 2015, 22, 4679–4686. [Google Scholar] [CrossRef]
- Hsieh, J.W.; Chen, L.C.; Chen, D.Y. Symmetrical SURF and its applications to vehicle detection and vehicle make and model recognition. IEEE Trans. Intell. Transp. Syst. 2014, 15, 6–20. [Google Scholar] [CrossRef]
- Yu, S.; Zheng, S.; Yang, H.; Liang, L. Vehicle logo recognition based on Bag-of-Words. In Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance, Krakow, Poland, 27–30 August 2013; pp. 353–358. [Google Scholar]
- Llorca, D.; Arroyo, R.; Sotelo, M. Vehicle logo recognition in traffic images using hog features and svm. In Proceedings of the 16th International IEEE Conference on Intelligent Transportation Systems (ITSC), The Hague, The Netherlands, 6–9 October 2013; pp. 2229–2234. [Google Scholar]
- Cyganek, B.; Wozniak, M. An improved vehicle logo recognition using a classifier ensemble based on pattern tensor representation and decomposition. New Gener. Comput. 2015, 33, 389–408. [Google Scholar] [CrossRef]
- Li, J.; Liang, X.; Wei, Y.; Xu, T.; Feng, J.; Yan, S. Perceptual generative adversarial networks for small object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1951–1959. [Google Scholar]
- Fang, L.; Zhao, X.; Zhang, S. Small-objectness sensitive detection based on shifted single shot detector. Multimed. Tools Appl. 2018, 4, 1–19. [Google Scholar] [CrossRef]
- Ren, Y.; Zhu, C.; Xiao, S. Small object detection in optical remote sensing images via modified Faster R-CNN. Appl. Sci. 2018, 8, 813. [Google Scholar] [CrossRef]
- Hu, P.; Ramanan, D. Finding tiny faces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1522–1530. [Google Scholar]
- Chen, C.; Liu, M.; Tuzel, O.; Xiao, J. R-CNN for small object detection. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2017; pp. 214–230. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for small object detection. arXiv 2019, arXiv:1902.07296. [Google Scholar]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–10 February 2017; pp. 4278–4284. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 630–645. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Xu, Z.; Yang, W.; Meng, A.; Lu, N.; Huang, H.; Ying, C.; Huang, L. Towards end-to-end license plate detection and recognition: A large dataset and baseline. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 255–271. [Google Scholar]
- Yang, L.; Luo, P.; Loy, C.; Tang, X. A large-scale car dataset for fine-grained categorization and verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3973–3981. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Psyllos, A.; Anagnostopoulos, C.; Kayafas, E. M-SIFT: A new method for vehicle logo recognition. In Proceedings of the IEEE International Conference on Vehicular Electronics and Safety, Istanbul, Turkey, 24–27 July 2013; pp. 261–266. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Car Head | Car Tail |
|---|---|---|
| SSD [39] | 95.4% | 92.7% |
| YOLO [38] | 96.1% | 93.5% |
| Faster R-CNN [37] | 98.3% | 96.2% |
| Layers | Output |
|---|---|
| pool | |
| resx1_eleswise to resx7_eleswise | |
| resx8_eleswise to resx30_eleswise | |
| resx30_eleswise to resx33_eleswise |
| Test Set | Conditions | Image Amount |
|---|---|---|
| CVLD_weather | Fog, Snow and Rain | 920 |
| CVLD_night | Night | 665 |
| CVLD_tilt | Tilt | 750 |
| Layer | Resolution |
|---|---|
| FM 1 | |
| FM 2 | |
| FM 3 | |
| FM 4 | |
| Resx30_elewise_relu/Conv3_2 | |
| Pool 2 |
| Architect of SSFPD | The Final Used Architect | Not Using Copy-Pasting Strategy | Using Resx33_elewise, Not Using Resx7_elewise and Resx30_elewise | Not Using FPN |
|---|---|---|---|---|
| mAP | 93.79% | 91.69% | 89.96% | 86.47% |
| Methods | Network | mAP | Testing Time | Memory | Input Resolution |
|---|---|---|---|---|---|
| SSD [39] | VGG 16 | 79.2% | 23 ms | 110.7 M | |
| ResNext-101 | 85.7% | 45 ms | 133.1 M | ||
| Faster R-CNN [37] | VGG 16 | 81.9% | 30 ms | 217.9 M | |
| ResNext-101 | 86.3% | 56 ms | 346.3 M | ||
| YOLO v3 [38] | DarkNet-53 | 82.7% | 20 ms | 226.6 M | |
| Resnext-101 | 89.8% | 49 ms | 346.3 M | ||
| Pre-training CNN [20] | --- | 88.9% | 21 ms | 88.6 M | |
| MTCNN [15] | --- | 90.4% | 34 ms | 101.5 M | |
| Proposed method | ReaNext-101 | 91.7% | 52 ms | 169.1 M |
| Methods | mAP | Testing Time |
|---|---|---|
| MFM [24] | 94% | 1020 ms |
| M-SIFT [48] | 94.6% | 816 ms |
| MTCNN [15] | 98.76% | 35 ms |
| Pre-training CNN [20] | 99.07% | 12 ms |
| proposed method (SSFPD) | 99.26% | 52 ms |
| proposed method (SSFPD + enhanced matching) | 99.52% | 108 ms |
| Testing Set | Accuracy | ||
|---|---|---|---|
| M-SIFT [48] | Pretraining CNN [20] | Proposed Method | |
| CVLD_weather | 74.8% | 77.4% | 80.6% |
| CVLD_night | 77.6% | 82.1% | 84.0% |
| CVLD_tilt | 79.9% | 83.7% | 86.5% |
| Testing Set | Real Result | Prediction | Recall | Precision | Accuracy | |
|---|---|---|---|---|---|---|
| Positive | Negative | |||||
| CVLD_weather | True | 764 | 18 | 83.04% | 95.98% | 80.61% |
| False | 32 | 156 | ||||
| CVLD_night | True | 579 | 12 | 87.06% | 95.70% | 84.06% |
| False | 26 | 86 | ||||
| CVLD_tilt | True | 663 | 15 | 88.4% | 97.36% | 86.59% |
| False | 18 | 87 | ||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, R.; Han, Q.; Min, W.; Zhou, L.; Xu, J. Vehicle Logo Recognition Based on Enhanced Matching for Small Objects, Constrained Region and SSFPD Network. Sensors 2019, 19, 4528. https://doi.org/10.3390/s19204528
Liu R, Han Q, Min W, Zhou L, Xu J. Vehicle Logo Recognition Based on Enhanced Matching for Small Objects, Constrained Region and SSFPD Network. Sensors. 2019; 19(20):4528. https://doi.org/10.3390/s19204528
Chicago/Turabian StyleLiu, Ruikang, Qing Han, Weidong Min, Linghua Zhou, and Jianqiang Xu. 2019. "Vehicle Logo Recognition Based on Enhanced Matching for Small Objects, Constrained Region and SSFPD Network" Sensors 19, no. 20: 4528. https://doi.org/10.3390/s19204528
APA StyleLiu, R., Han, Q., Min, W., Zhou, L., & Xu, J. (2019). Vehicle Logo Recognition Based on Enhanced Matching for Small Objects, Constrained Region and SSFPD Network. Sensors, 19(20), 4528. https://doi.org/10.3390/s19204528