Hierarchical Classification of Urban ALS Data by Using Geometry and Intensity Information

 ,
,
Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
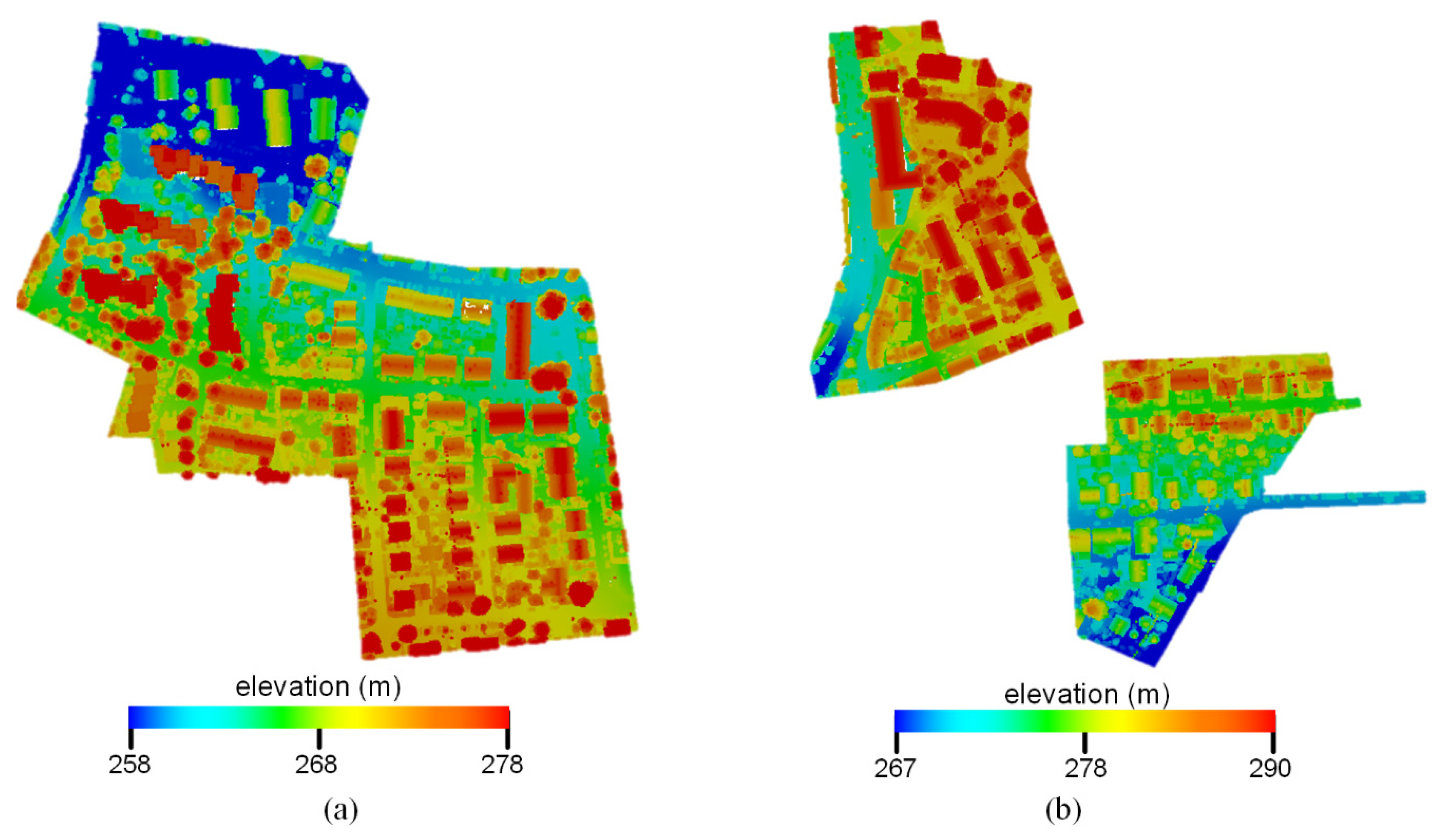
3.1. Data Used in This Study
3.2. Graphical Overview of the Proposed Method
- Supervised learning for geometry information: extract geometry feature from the ALS data and then classify the ALS data by using the trained supervised classifier. The geometry feature in this study included FPFH, normal, and height. Four common supervised learning methods, namely decision tree (DT), random forest (RF), support vector classification (SVC), and extreme gradient boost (XGBoost) were used alone to test the performance of the proposed method.
- Unsupervised learning for intensity information: after applying the supervised classifier on the ALS data, the ground-level points and the elevated points (such as building and tree) can be split from the ALS data. The ground-level points were reclassified while using an unsupervised learning method based on intensity information. The Gaussian mixture model (GMM) was the selected unsupervised classifier, because the probability distribution of the intensity of some geo-objects is approximately Gaussian distribution [31].
- Join the classification results of the supervised and unsupervised classifier: for the elevated points, the label was the result of the supervised classifier, whereas, for the ground-level points, the label was the selection from the supervised classification result and the unsupervised classification result based on the heuristic rule. Section 3.3 describes this heuristic rule.
3.3. Supervised Learning for Geometry Information
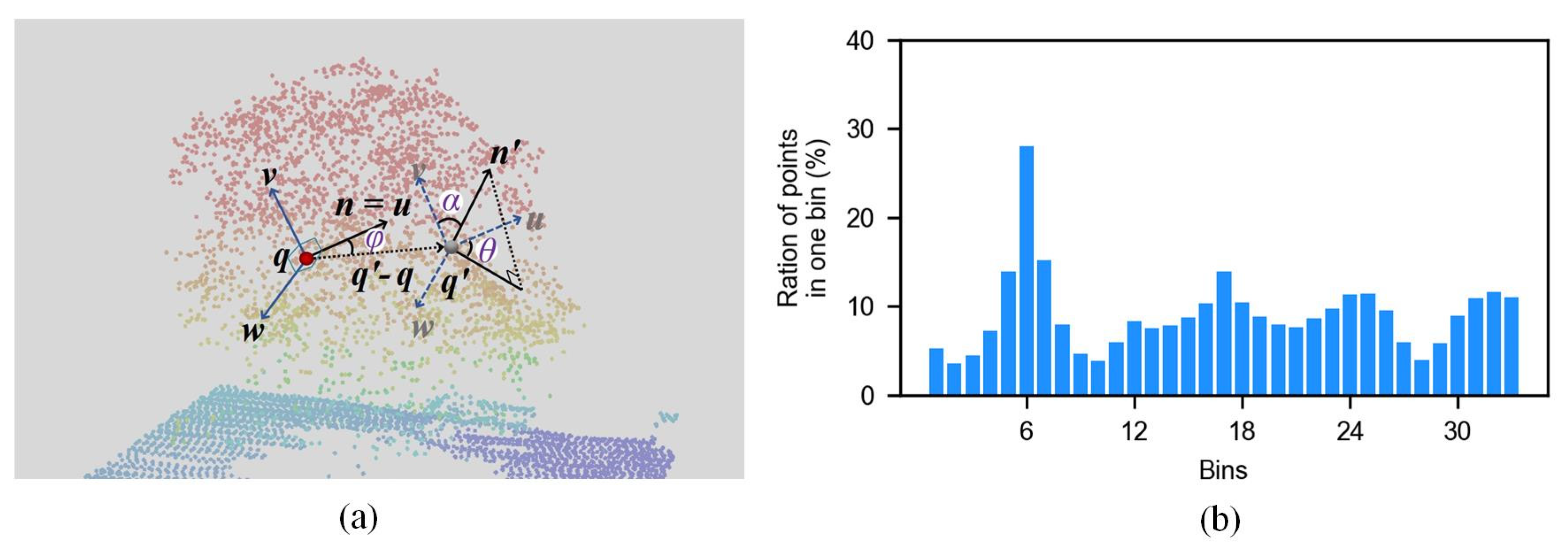
3.3.1. Geometry Feature Description
3.3.2. A Brief Introduction to Supervised Learning Methods
Decision Tree
Support Vector Classification
Random Forest
Extreme Gradient Boost
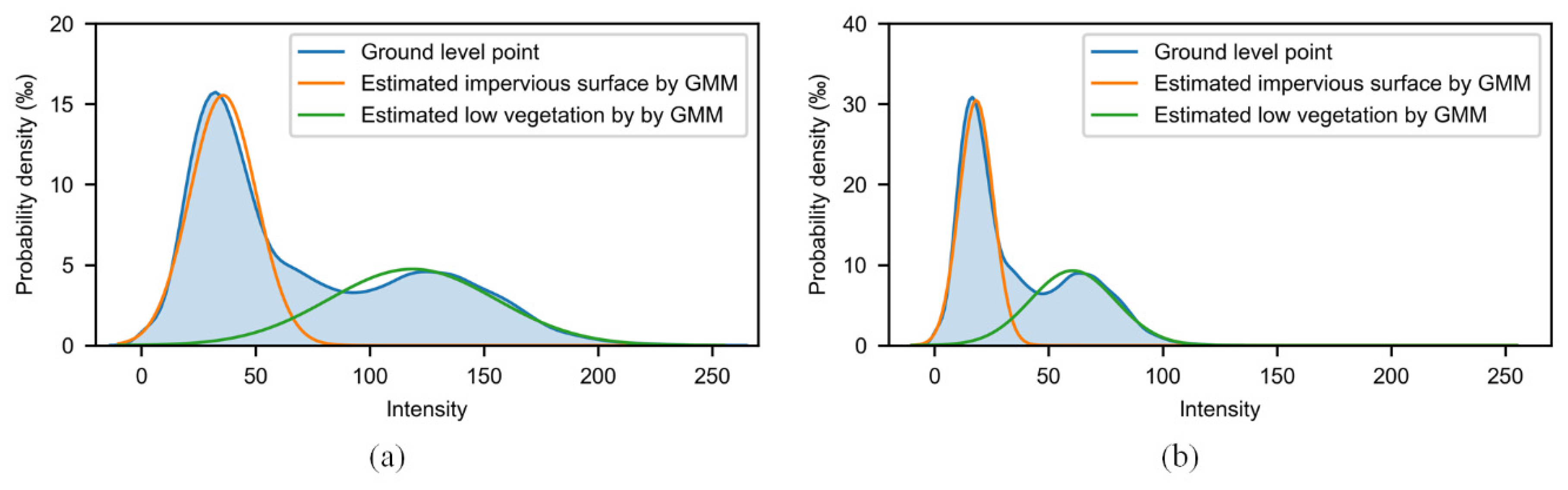
3.4. Unsupervised Learning for Intensity Information
3.5. Joint Classification Results of the Supervised and Unsupervised Classifier
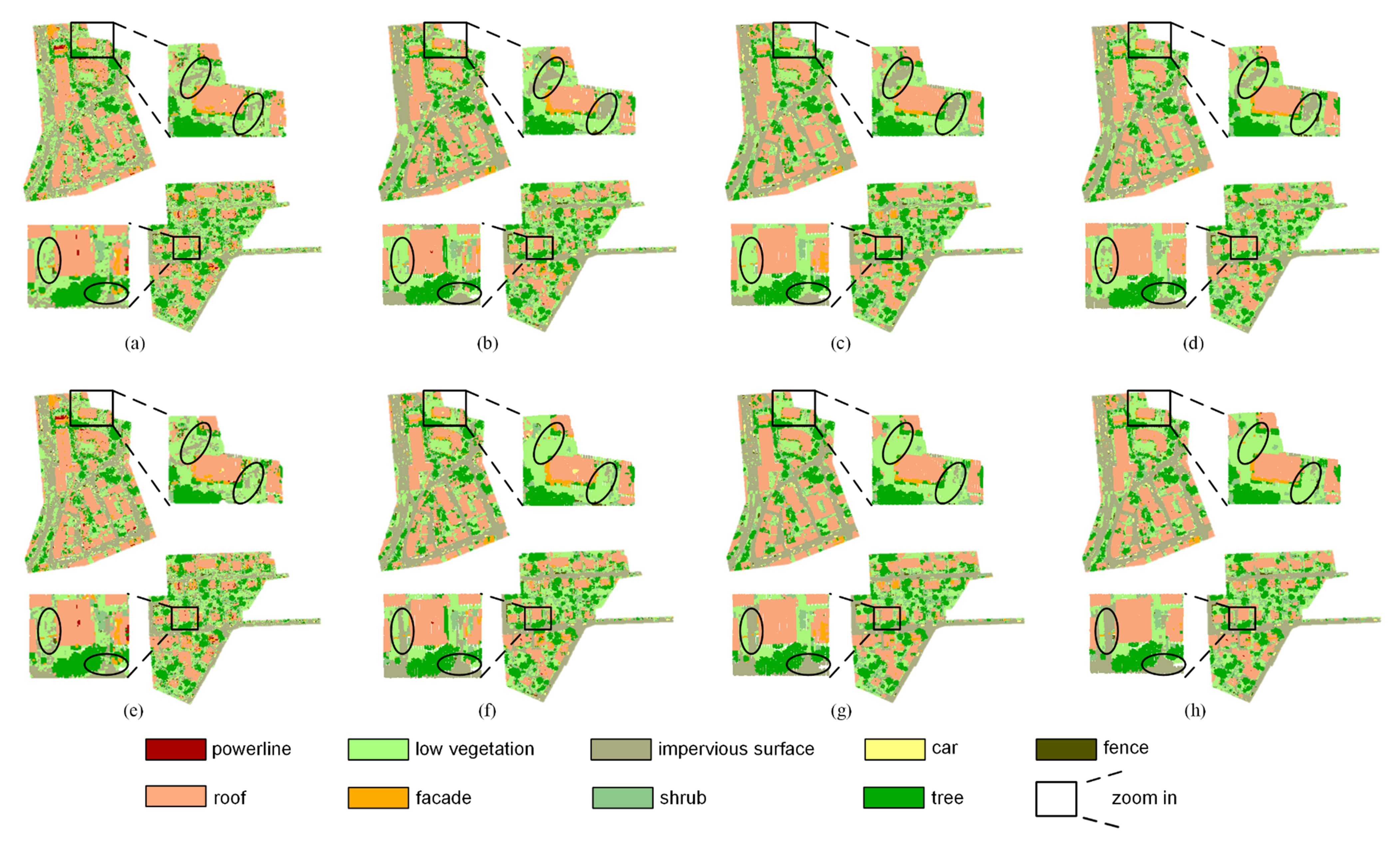
4. Results
5. Discussion
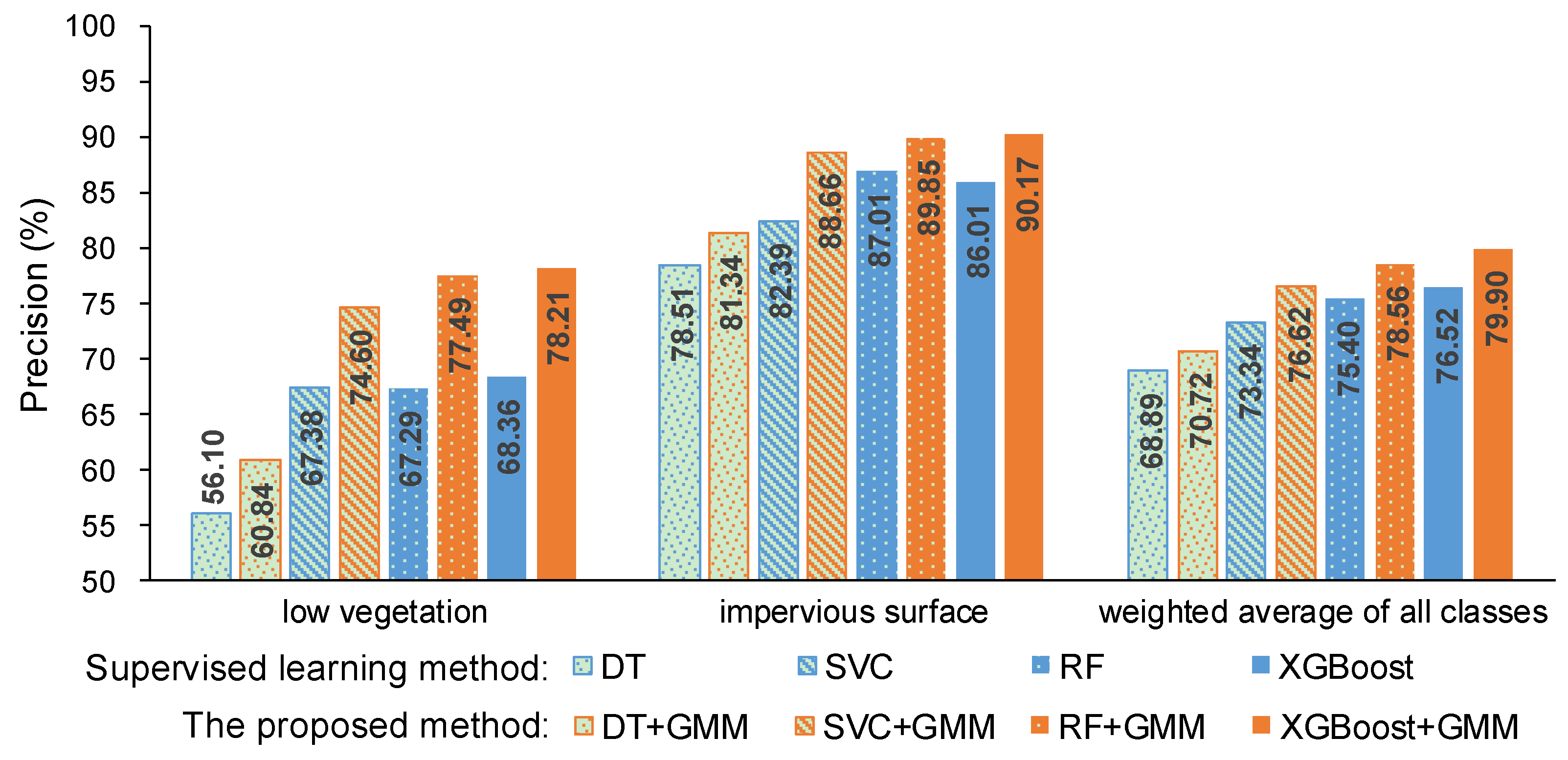
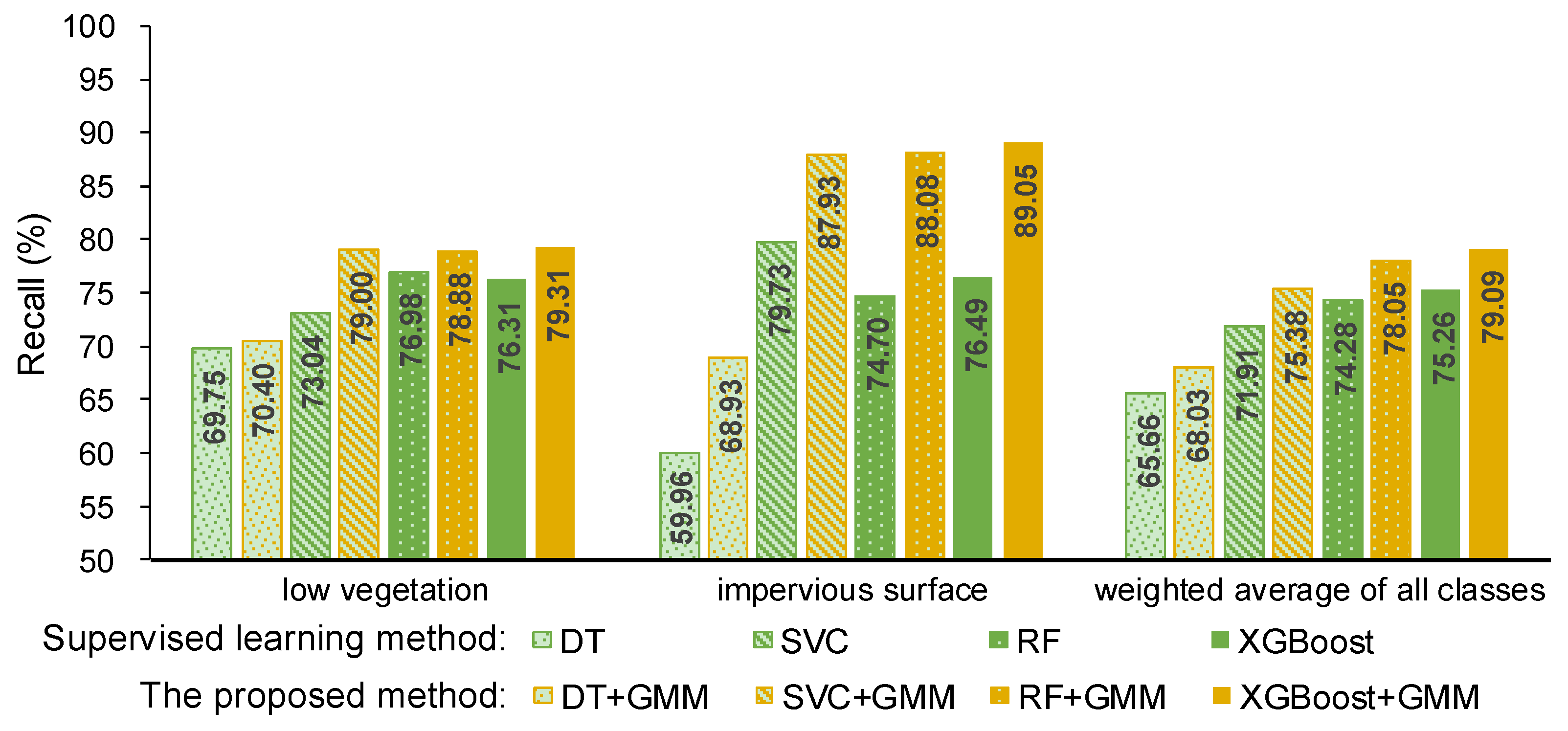
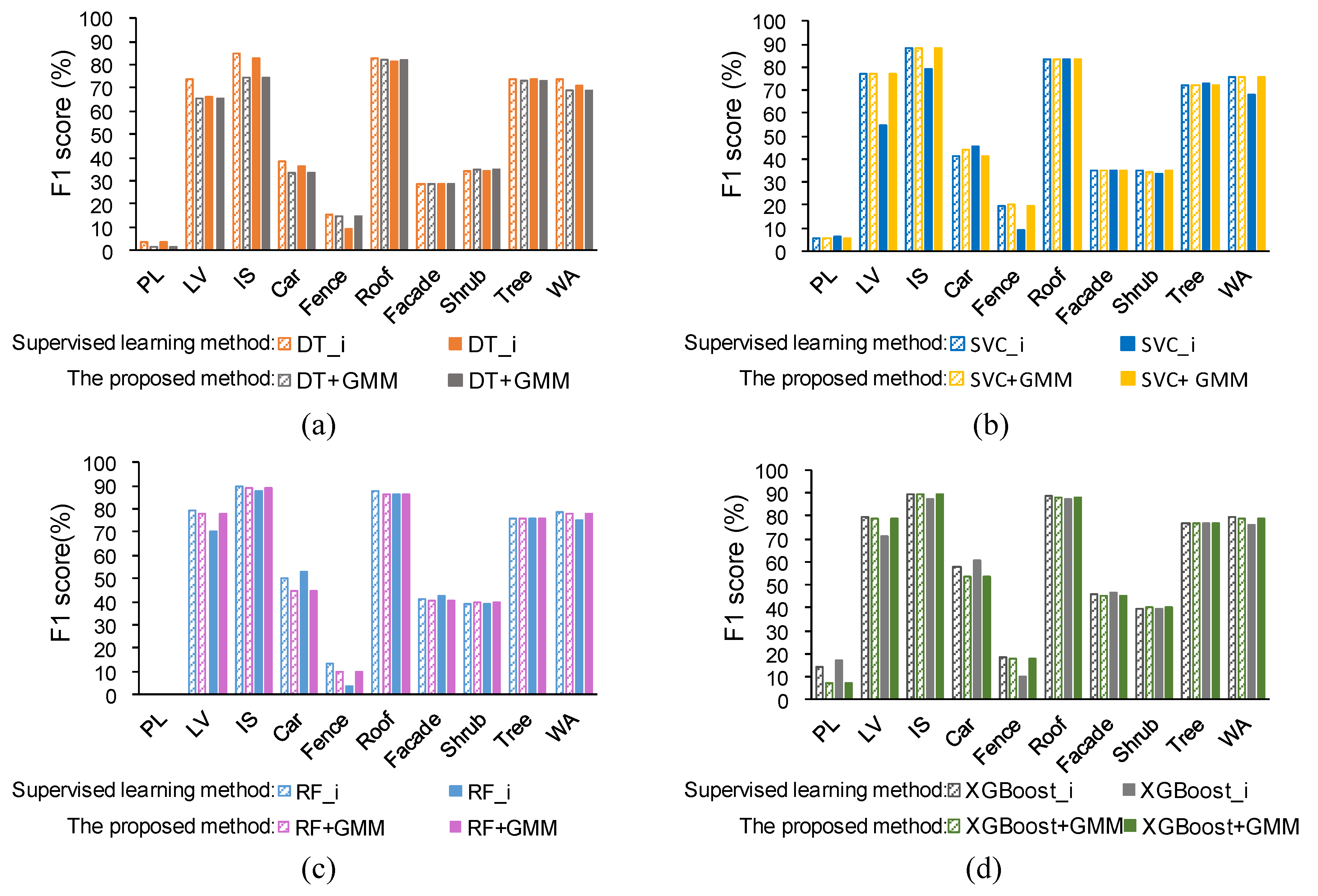
5.1. Compare the Proposed Method with the Supervised Learning Method Considering Intensity
5.1.1. Comparison Conditions Setting
5.1.2. Comparison under the Same Conditions
5.1.3. Comparison under Different Conditions
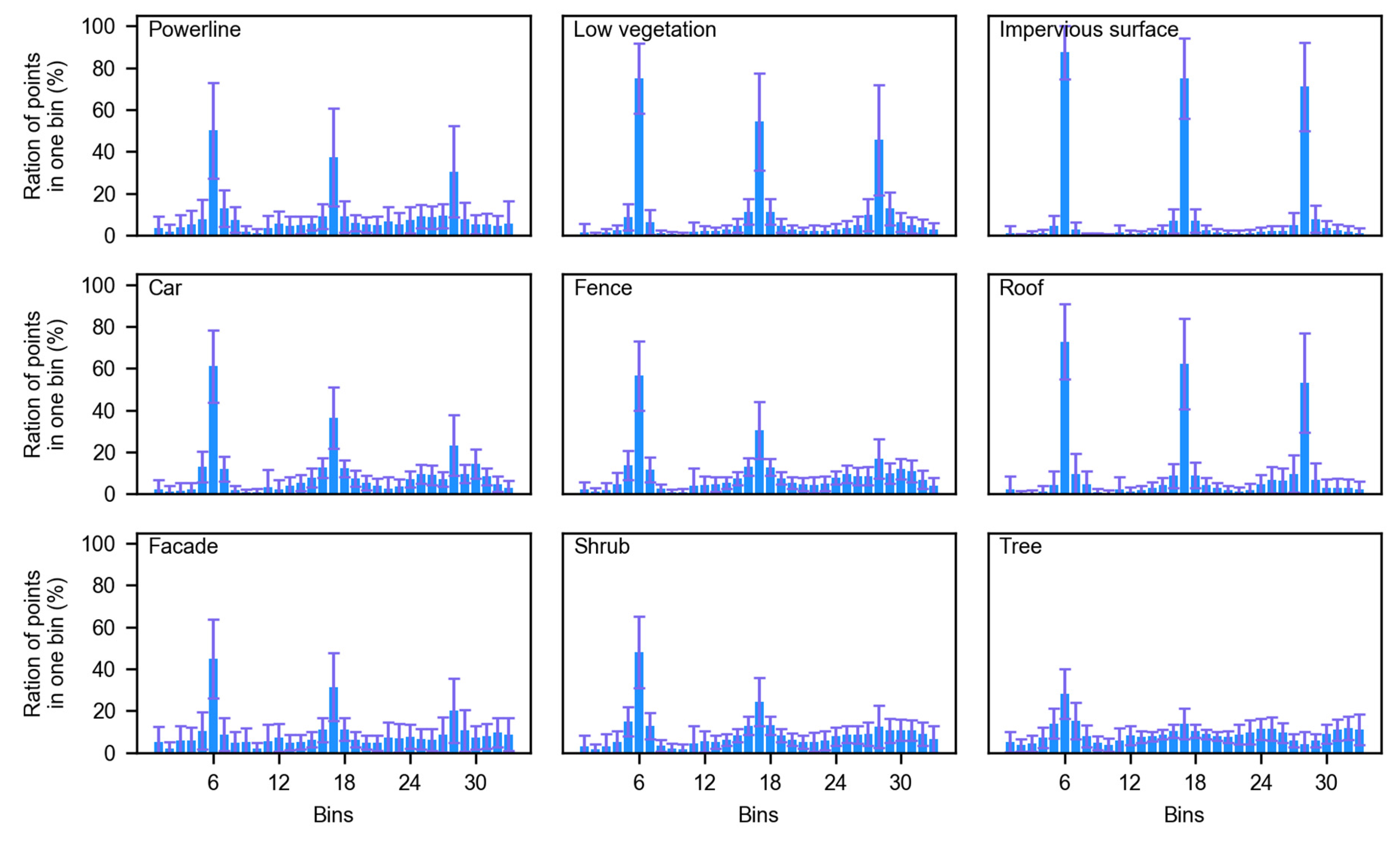
5.2. The Effect of Joint Parameter on the Performance of the Proposed Method
5.3. The Limitation of the Proposed Method
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
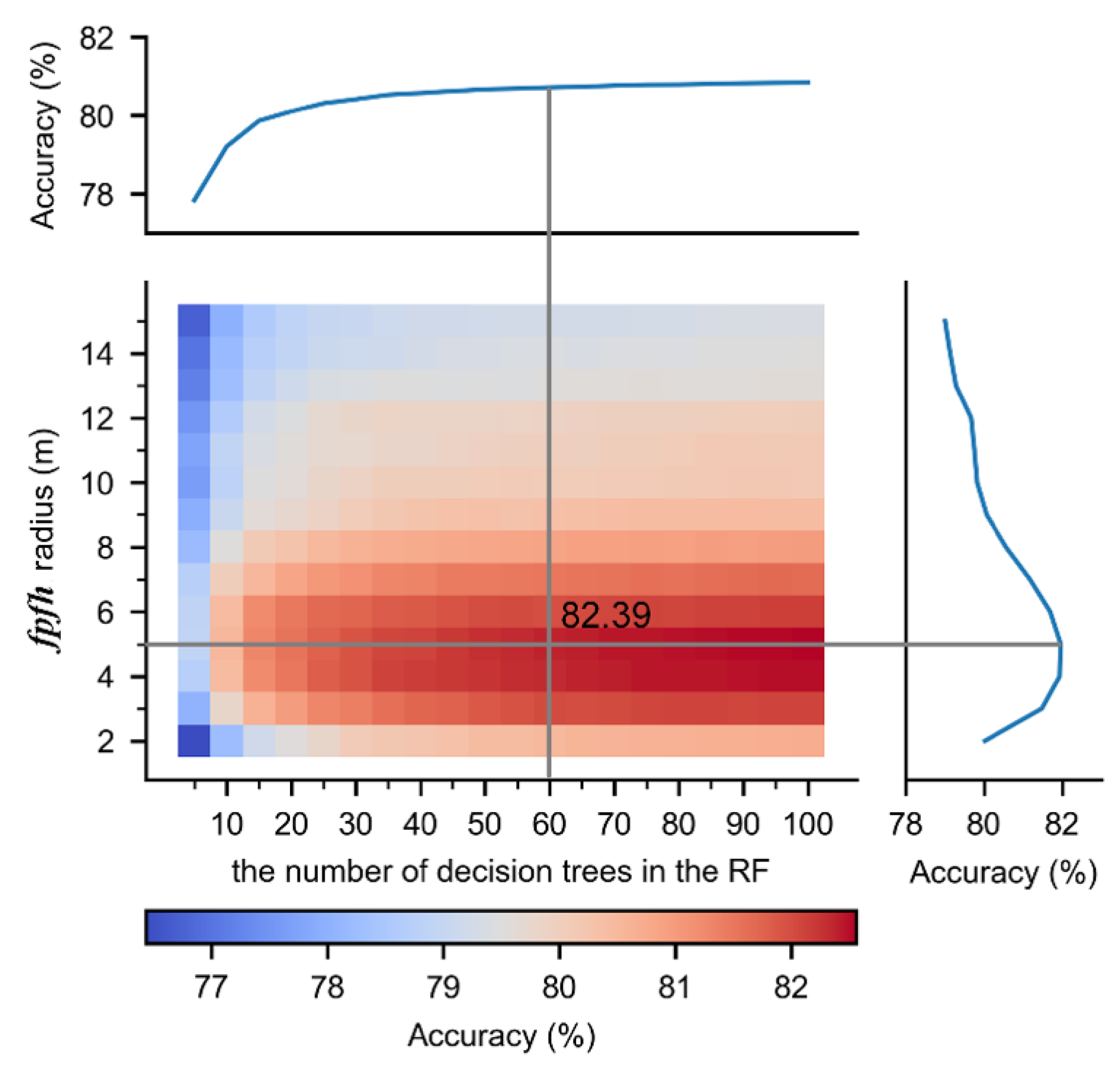
Appendix A.1. The Parameters in RF and FPFH Radius

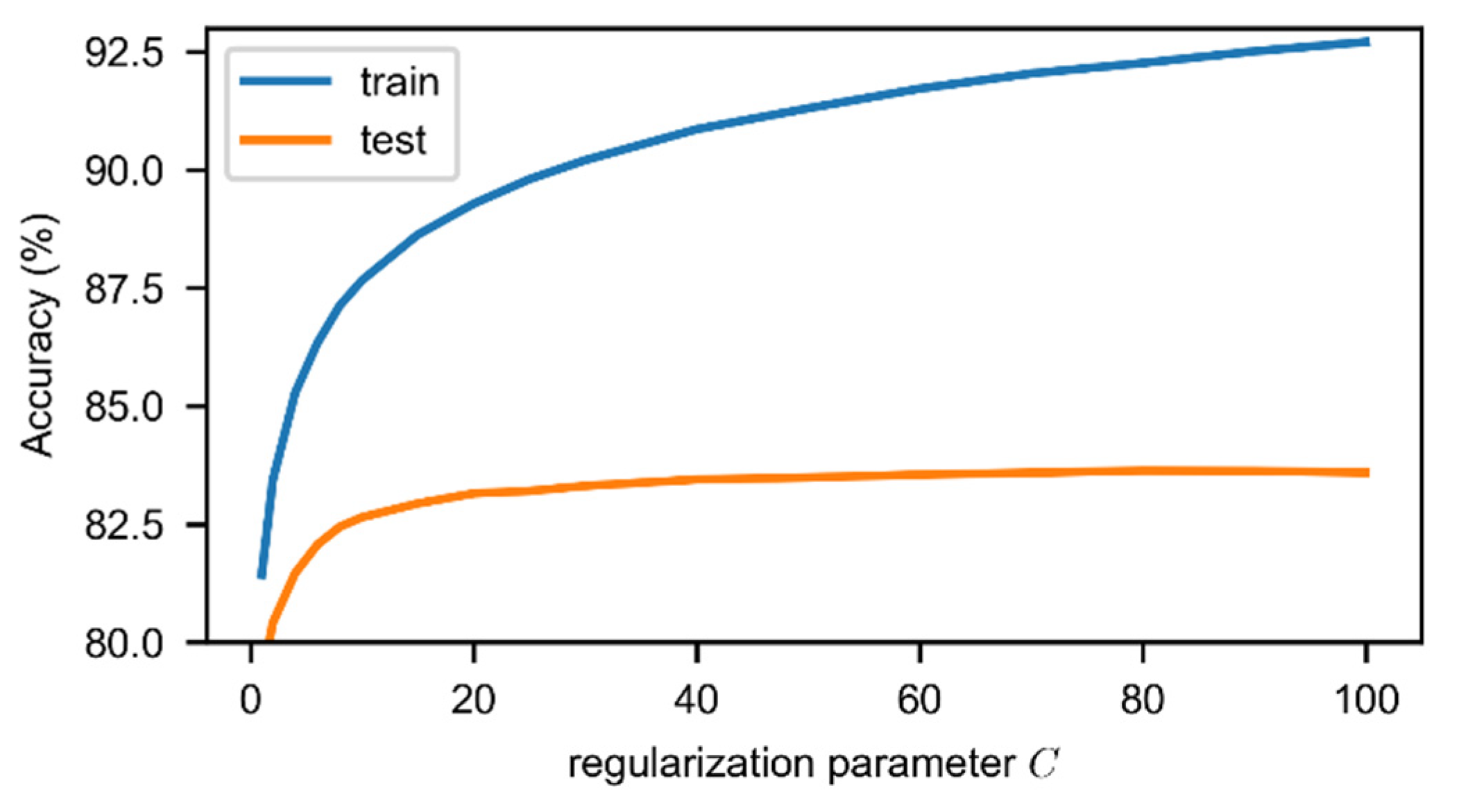
Appendix A.2. The Parameter in SVC

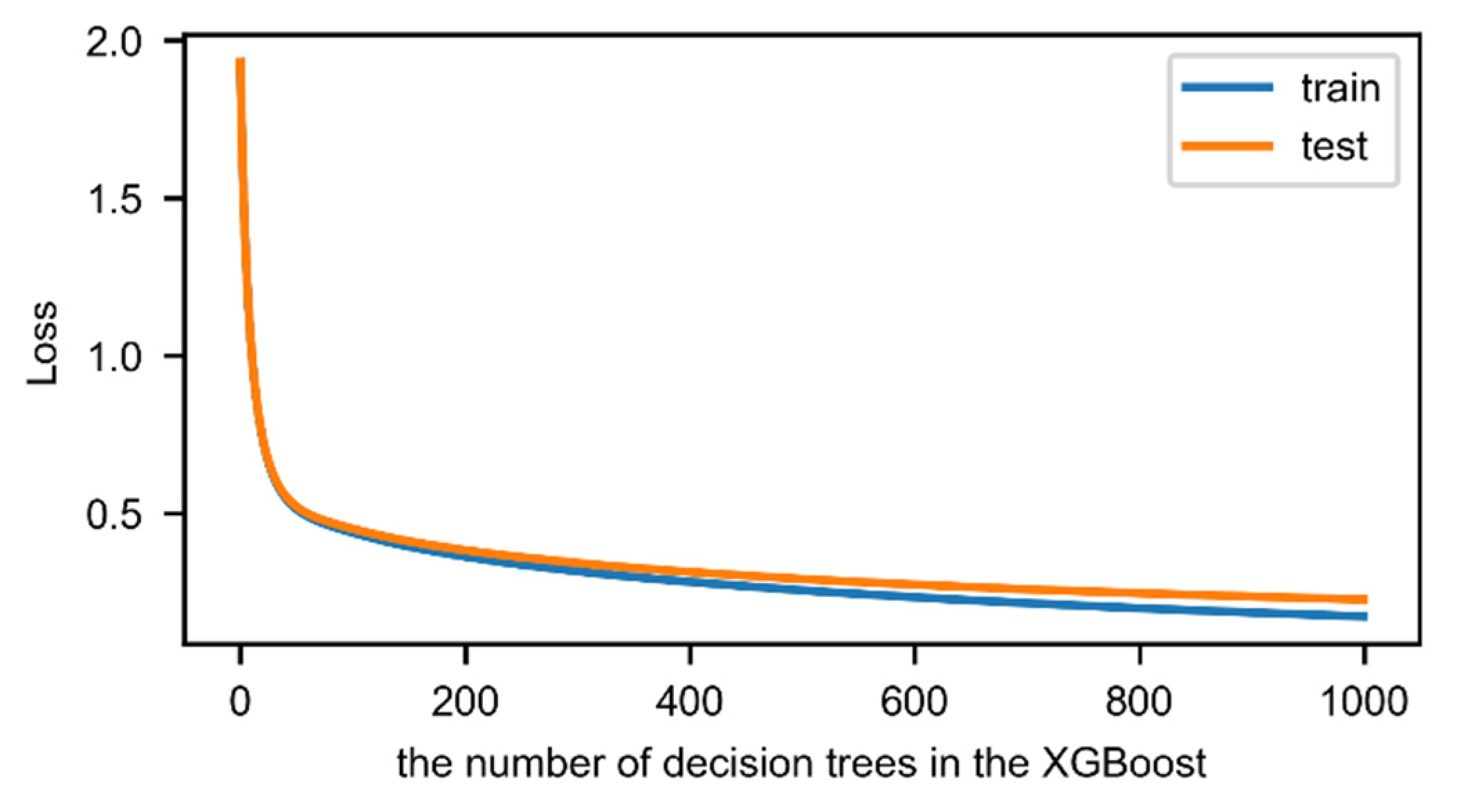
Appendix A.3. The Parameters in XGBoost


References
- Nations, U. World Urbanization Prospects: The 2018 Revision(ST/ESA/SER.A/420); United Nations, Department of Economic and Social Affairs: New York, NY, USA, 2018. [Google Scholar]
- Walde, I.; Hese, S.; Berger, C.; Schmullius, C. From land cover-graphs to urban structure types. Int. J. Geogr. Inf. Sci. 2014, 28, 584–609. [Google Scholar] [CrossRef]
- Zhu, Z.; Zhou, Y.; Seto, K.C.; Stokes, E.C.; Deng, C.; Pickett, S.T.A.; Taubenböck, H. Understanding an urbanizing planet: Strategic directions for remote sensing. Remote Sens. Environ. 2019, 228, 164–182. [Google Scholar] [CrossRef]
- Eitel, J.U.H.; Höfle, B.; Vierling, L.A.; Abellán, A.; Asner, G.P.; Deems, J.S.; Glennie, C.L.; Joerg, P.C.; LeWinter, A.L.; Magney, T.S.; et al. Beyond 3-D: The new spectrum of lidar applications for earth and ecological sciences. Remote Sens. Environ. 2016, 186, 372–392. [Google Scholar] [CrossRef] [Green Version]
- Yan, W.Y.; Shaker, A.; El-Ashmawy, N. Urban land cover classification using airborne LiDAR data: A review. Remote Sens. Environ. 2015, 158, 295–310. [Google Scholar] [CrossRef]
- Tran, T.; Ressl, C.; Pfeifer, N. Integrated change detection and classification in urban areas based on airborne laser scanning point clouds. Sensors 2018, 18, 448. [Google Scholar] [CrossRef] [PubMed]
- Okyay, U.; Telling, J.; Glennie, C.L.; Dietrich, W.E. Airborne lidar change detection: An overview of Earth sciences applications. Earth Sci. Rev. 2019. [Google Scholar] [CrossRef]
- Godwin, C.; Chen, G.; Singh, K.K. The impact of urban residential development patterns on forest carbon density: An integration of LiDAR, aerial photography and field mensuration. Landsc. Urban Plan. 2015, 136, 97–109. [Google Scholar] [CrossRef]
- Raciti, S.M.; Hutyra, L.R.; Newell, J.D. Mapping carbon storage in urban trees with multi-source remote sensing data: Relationships between biomass, land use, and demographics in Boston neighborhoods. Sci. Total Environ. 2014, 500, 72–83. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual classification of lidar data and building object detection in urban areas. ISPRS J. Photogramm. Remote Sens. 2014, 87, 152–165. [Google Scholar] [CrossRef]
- Kang, Z.; Yang, J. A probabilistic graphical model for the classification of mobile LiDAR point clouds. ISPRS J. Photogramm. Remote Sens. 2018, 143, 108–123. [Google Scholar] [CrossRef]
- Sithole, G.; Vosselman, G. Experimental comparison of filter algorithms for bare-Earth extraction from airborne laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2004, 59, 85–101. [Google Scholar] [CrossRef]
- Liu, X.; Chen, Y.; Cheng, L.; Yao, M.; Deng, S.; Li, M.; Cai, D. Airborne laser scanning point clouds filtering method based on the construction of virtual ground seed points. J. Appl. Remote Sens. 2017, 11, 16032. [Google Scholar] [CrossRef]
- Awrangjeb, M.; Fraser, C. Automatic segmentation of raw LiDAR data for extraction of building roofs. Remote Sens. 2014, 6, 3716–3751. [Google Scholar] [CrossRef]
- Sun, S.; Salvaggio, C. Aerial 3D building detection and modeling from airborne LiDAR point clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 1440–1449. [Google Scholar] [CrossRef]
- Jwa, Y.; Sohn, G.; Kim, H.B. Automatic 3d powerline reconstruction using airborne lidar data. Int. Arch. Photogramm. Remote Sens 2009, 38, W8. [Google Scholar]
- Sohn, G.; Jwa, Y.; Kim, H.B. Automatic powerline scene classification and reconstruction using airborne lidar data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 13, 28. [Google Scholar] [CrossRef]
- Xu, Z.; Guan, K.; Casler, N.; Peng, B.; Wang, S. A 3D convolutional neural network method for land cover classification using LiDAR and multi-temporal Landsat imagery. ISPRS J. Photogramm. Remote Sens. 2018, 144, 423–434. [Google Scholar] [CrossRef]
- Cook, B.D.; Bolstad, P.V.; Næsset, E.; Anderson, R.S.; Garrigues, S.; Morisette, J.T.; Nickeson, J.; Davis, K.J. Using LiDAR and quickbird data to model plant production and quantify uncertainties associated with wetland detection and land cover generalizations. Remote Sens. Environ. 2009, 113, 2366–2379. [Google Scholar] [CrossRef]
- Buján, S.; González-Ferreiro, E.; Reyes-Bueno, F.; Barreiro-Fernández, L.; Crecente, R.; Miranda, D. Land Use Classification from Lidar Data and Ortho-Images in a Rural Area. Photogramm. Rec. 2012, 27, 401–422. [Google Scholar] [CrossRef]
- Cao, Y.; Wei, H.; Zhao, H.; Li, N. An effective approach for land-cover classification from airborne lidar fused with co-registered data. Int. J. Remote Sens. 2012, 33, 5927–5953. [Google Scholar] [CrossRef]
- Murphy, J.M.; Le Moigne, J.; Harding, D.J. Automatic image registration of multimodal remotely sensed data with global shearlet features. IEEE Trans. Geosci. Remote Sens. 2015, 54, 1685–1704. [Google Scholar] [CrossRef] [PubMed]
- Mastin, A.; Kepner, J.; Fisher, J. Automatic registration of LIDAR and optical images of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Yang, B.; Chen, C. Automatic registration of UAV-borne sequent images and LiDAR data. ISPRS J. Photogramm. Remote Sens. 2015, 101, 262–274. [Google Scholar] [CrossRef]
- Song, J.-H.; Han, S.-H.; Yu, K.Y.; Kim, Y.-I. Assessing the possibility of land-cover classification using lidar intensity data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2002, 34, 259–262. [Google Scholar]
- Charaniya, A.P.; Manduchi, R.; Lodha, S.K. Supervised Parametric Classification of Aerial LiDAR Data. In Proceedings of the Computer Vision and Pattern Recognition Workshop, 2004. CVPRW’04, Washington, DC, USA, 27 June–2 July 2004; p. 30. [Google Scholar]
- Matikainen, L.; Karila, K.; Hyyppä, J.; Litkey, P.; Puttonen, E.; Ahokas, E. Object-based analysis of multispectral airborne laser scanner data for land cover classification and map updating. ISPRS J. Photogramm. Remote Sens. 2017, 128, 298–313. [Google Scholar] [CrossRef]
- Li, N.; Liu, C.; Pfeifer, N. Improving LiDAR classification accuracy by contextual label smoothing in post-processing. ISPRS J. Photogramm. Remote Sens. 2019, 148, 13–31. [Google Scholar] [CrossRef]
- Yang, Z.; Jiang, W.; Xu, B.; Zhu, Q.; Jiang, S.; Huang, W. A convolutional neural network-based 3D semantic labeling method for ALS point clouds. Remote Sens. 2017, 9, 936. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Sörgel, U.; Heipke, C. Hierarchical higher order crf for the classification of airborne lidar point clouds in urban areas. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. Arch. 2016, 41, 655–662. [Google Scholar] [CrossRef]
- Kashani, A.; Olsen, M.; Parrish, C.; Wilson, N. A review of LiDAR radiometric processing: From ad hoc intensity correction to rigorous radiometric calibration. Sensors 2015, 15, 28099–28128. [Google Scholar] [CrossRef]
- Yu, Y.; Li, J.; Guan, H.; Jia, F.; Wang, C. Learning hierarchical features for automated extraction of road markings from 3-D mobile LiDAR point clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 8, 709–726. [Google Scholar] [CrossRef]
- Hu, X.; Li, Y.; Shan, J.; Zhang, J.; Zhang, Y. Road Centerline Extraction in Complex Urban Scenes From LiDAR Data Based on Multiple Features. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7448–7456. [Google Scholar]
- Landrieu, L.; Raguet, H.; Vallet, B.; Mallet, C.; Weinmann, M. A structured regularization framework for spatially smoothing semantic labelings of 3D point clouds. ISPRS J. Photogramm. Remote Sens. 2017, 132, 102–118. [Google Scholar] [CrossRef] [Green Version]
- Vosselman, G.; Coenen, M.; Rottensteiner, F. Contextual segment-based classification of airborne laser scanner data. ISPRS J. Photogramm. Remote Sens. 2017, 128, 354–371. [Google Scholar] [CrossRef]
- Schindler, K. An overview and comparison of smooth labeling methods for land-cover classification. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4534–4545. [Google Scholar] [CrossRef]
- Thomas, H.; Goulette, F.; Deschaud, J.-E.; Marcotegui, B. Semantic Classification of 3D Point Clouds with Multiscale Spherical Neighborhoods. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 390–398. [Google Scholar]
- Mallet, C.; Bretar, F.; Roux, M.; Soergel, U.; Heipke, C. Relevance assessment of full-waveform lidar data for urban area classification. ISPRS J. Photogramm. Remote Sens. 2011, 66, S71–S84. [Google Scholar] [CrossRef]
- Secord, J.; Zakhor, A. Tree detection in urban regions using aerial lidar and image data. IEEE Geosci. Remote Sens. Lett. 2007, 4, 196–200. [Google Scholar] [CrossRef]
- Lodha, S.K.; Fitzpatrick, D.M.; Helmbold, D.P. Aerial lidar data classification using adaboost. In Proceedings of the Sxith International Conference on 3-D Digital Imaging and Modeling (3DIM 2007), Montreal, QC, Canada, 21–23 August 2007; pp. 435–442. [Google Scholar]
- Guo, B.; Huang, X.; Zhang, F.; Sohn, G. Classification of airborne laser scanning data using JointBoost. ISPRS J. Photogramm. Remote Sens. 2015, 100, 71–83. [Google Scholar] [CrossRef]
- Guo, L.; Chehata, N.; Mallet, C.; Boukir, S. Relevance of airborne lidar and multispectral image data for urban scene classification using Random Forests. ISPRS J. Photogramm. Remote Sens. 2011, 66, 56–66. [Google Scholar] [CrossRef]
- Weinmann, M.; Urban, S.; Hinz, S.; Jutzi, B.; Mallet, C. Distinctive 2D and 3D features for automated large-scale scene analysis in urban areas. Comput. Graph. 2015, 49, 47–57. [Google Scholar] [CrossRef]
- Dittrich, A.; Weinmann, M.; Hinz, S. Analytical and numerical investigations on the accuracy and robustness of geometric features extracted from 3D point cloud data. ISPRS J. Photogramm. Remote Sens. 2017, 126, 195–208. [Google Scholar] [CrossRef]
- Osada, R.; Funkhouser, T.; Chazelle, B.; Dobkin, D. Shape distributions. ACM Trans. Graph. 2002, 21, 807–832. [Google Scholar] [CrossRef]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast point feature histograms (FPFH) for 3D registration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar]
- Rusu, R.B.; Marton, Z.C.; Blodow, N.; Beetz, M. Persistent point feature histograms for 3D point clouds. In Proceedings of the 10th International Conference Intelligent Autonomous Systems (IAS-10), Baden-Baden, Germany, 23–25 July 2008; pp. 119–128. [Google Scholar]
- Blomley, R.; Weinmann, M.; Leitloff, J.; Jutzi, B. Shape distribution features for point cloud analysis-a geometric histogram approach on multiple scales. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 2, 9. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195. [Google Scholar] [CrossRef] [PubMed]
- Zhao, R.; Pang, M.; Wang, J. Classifying airborne LiDAR point clouds via deep features learned by a multi-scale convolutional neural network. Int. J. Geogr. Inf. Sci. 2018, 32, 960–979. [Google Scholar] [CrossRef]
- Yan, W.Y.; Shaker, A. Radiometric correction and normalization of airborne LiDAR intensity data for improving land-cover classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7658–7673. [Google Scholar]
- Yan, W.Y.; Shaker, A.; Habib, A.; Kersting, A.P. Improving classification accuracy of airborne LiDAR intensity data by geometric calibration and radiometric correction. ISPRS J. Photogramm. Remote Sens. 2012, 67, 35–44. [Google Scholar] [CrossRef]
- Cramer, M. The DGPF-test on digital airborne camera evaluation—Overview and test design. Photogramm. Fernerkund. Geoinf. 2010, 2010, 73–82. [Google Scholar] [CrossRef]
- fpfh_estimation @ pointclouds.org. Available online: http://pointclouds.org/documentation/tutorials/fpfh_estimation.php (accessed on 23 August 2019).
- Girardeau-Montaut, D. CloudCompare Version 2.6. 1-User Manual. 2015. Available online: http//www.danielgm.net/cc/doc/qCC/CloudCompare%20v2.6.1%20%20User%20manual.pdf (accessed on 20 August 2019).
- Zhang, K.; Chen, S.-C.; Whitman, D.; Shyu, M.-L.; Yan, J.; Zhang, C. A progressive morphological filter for removing nonground measurements from airborne LIDAR data. IEEE Trans. Geosci. Remote Sens. 2003, 41, 872–882. [Google Scholar] [CrossRef] [Green Version]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- svm @ scikit-learn.org. Available online: https://scikit-learn.org/stable/modules/svm.html#svm-classification (accessed on 23 August 2019).
- Wu, T.-F.; Lin, C.-J.; Weng, R.C. Probability estimates for multi-class classification by pairwise coupling. J. Mach. Learn. Res. 2004, 5, 975–1005. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chehata, N.; Guo, L.; Mallet, C. Airborne lidar feature selection for urban classification using random forests. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2009, 38, W8. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Georganos, S.; Grippa, T.; Vanhuysse, S.; Lennert, M.; Shimoni, M.; Wolff, E. Very high resolution object-based land use-land cover urban classification using extreme gradient boosting. IEEE Geosci. Remote Sens. Lett. 2018, 15, 607–611. [Google Scholar] [CrossRef]
- Borgelt, C. Prototype-Based Classification and Clustering. Magdeburg, Germany. 2006. Available online: https://opendata.uni-halle.de/bitstream/1981185920/10725/1/chrborgelt1.pdf (accessed on 10 October 2019).
- Reynolds, D. Gaussian mixture models. Encycl. Biom. 2015, 827–832. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Geo-objects→ Method↓ | PL | LV | IS | Car | Fence | Roof | Façade | Shrub | Tree | WA |
|---|---|---|---|---|---|---|---|---|---|---|
| DT + GMM | 1.83 | 65.27 | 74.62 | 33.26 | 14.43 | 81.84 | 28.67 | 34.76 | 73.23 | 68.89 |
| SVM + GMM | 5.46 | 76.74 | 88.29 | 40.97 | 19.19 | 83.15 | 35.12 | 34.81 | 72.16 | 75.57 |
| RF + GMM | N/A | 78.18 | 88.96 | 44.76 | 10.00 | 86.56 | 40.18 | 39.71 | 76.18 | 77.80 |
| XGBoost + GMM | 7.44 | 78.76 | 89.60 | 53.52 | 17.93 | 88.30 | 45.51 | 40.10 | 76.51 | 79.01 |
| Reference→ Predicted↓ | PL | LV | IS | Car | Fence | Roof | Façade | Shrub | Tree | Total | UA |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PL | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | - |
| LV | 3 | 77,853 | 11,558 | 569 | 1442 | 1732 | 992 | 5396 | 929 | 100,474 | 77% |
| IS | 0 | 8811 | 89,820 | 417 | 95 | 158 | 244 | 288 | 123 | 99,956 | 90% |
| Car | 0 | 17 | 6 | 1125 | 24 | 13 | 15 | 81 | 38 | 1319 | 85% |
| Fence | 0 | 85 | 8 | 342 | 434 | 117 | 5 | 203 | 63 | 1257 | 35% |
| Roof | 383 | 3605 | 218 | 167 | 623 | 90,211 | 1453 | 1096 | 1637 | 99,393 | 91% |
| Façade | 84 | 195 | 39 | 5 | 321 | 5700 | 4646 | 230 | 678 | 11,898 | 39% |
| Shrub | 8 | 6430 | 231 | 1064 | 3298 | 2330 | 1208 | 10,821 | 4301 | 29,691 | 36% |
| Tree | 122 | 1694 | 106 | 19 | 1185 | 8787 | 2661 | 6703 | 46,457 | 67,734 | 69% |
| Total | 600 | 98,690 | 101,986 | 3708 | 7422 | 10,9048 | 11,224 | 24,818 | 54,226 | 411,722 | |
| PA | 0% | 79% | 88% | 30% | 6% | 83% | 41% | 44% | 86% | 78% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Chen, Y.; Li, S.; Cheng, L.; Li, M. Hierarchical Classification of Urban ALS Data by Using Geometry and Intensity Information. Sensors 2019, 19, 4583. https://doi.org/10.3390/s19204583
Liu X, Chen Y, Li S, Cheng L, Li M. Hierarchical Classification of Urban ALS Data by Using Geometry and Intensity Information. Sensors. 2019; 19(20):4583. https://doi.org/10.3390/s19204583
Chicago/Turabian StyleLiu, Xiaoqiang, Yanming Chen, Shuyi Li, Liang Cheng, and Manchun Li. 2019. "Hierarchical Classification of Urban ALS Data by Using Geometry and Intensity Information" Sensors 19, no. 20: 4583. https://doi.org/10.3390/s19204583
APA StyleLiu, X., Chen, Y., Li, S., Cheng, L., & Li, M. (2019). Hierarchical Classification of Urban ALS Data by Using Geometry and Intensity Information. Sensors, 19(20), 4583. https://doi.org/10.3390/s19204583