Structure from Articulated Motion: Accurate and Stable Monocular 3D Reconstruction without Training Data

 ,
, 
Abstract
1. Introduction
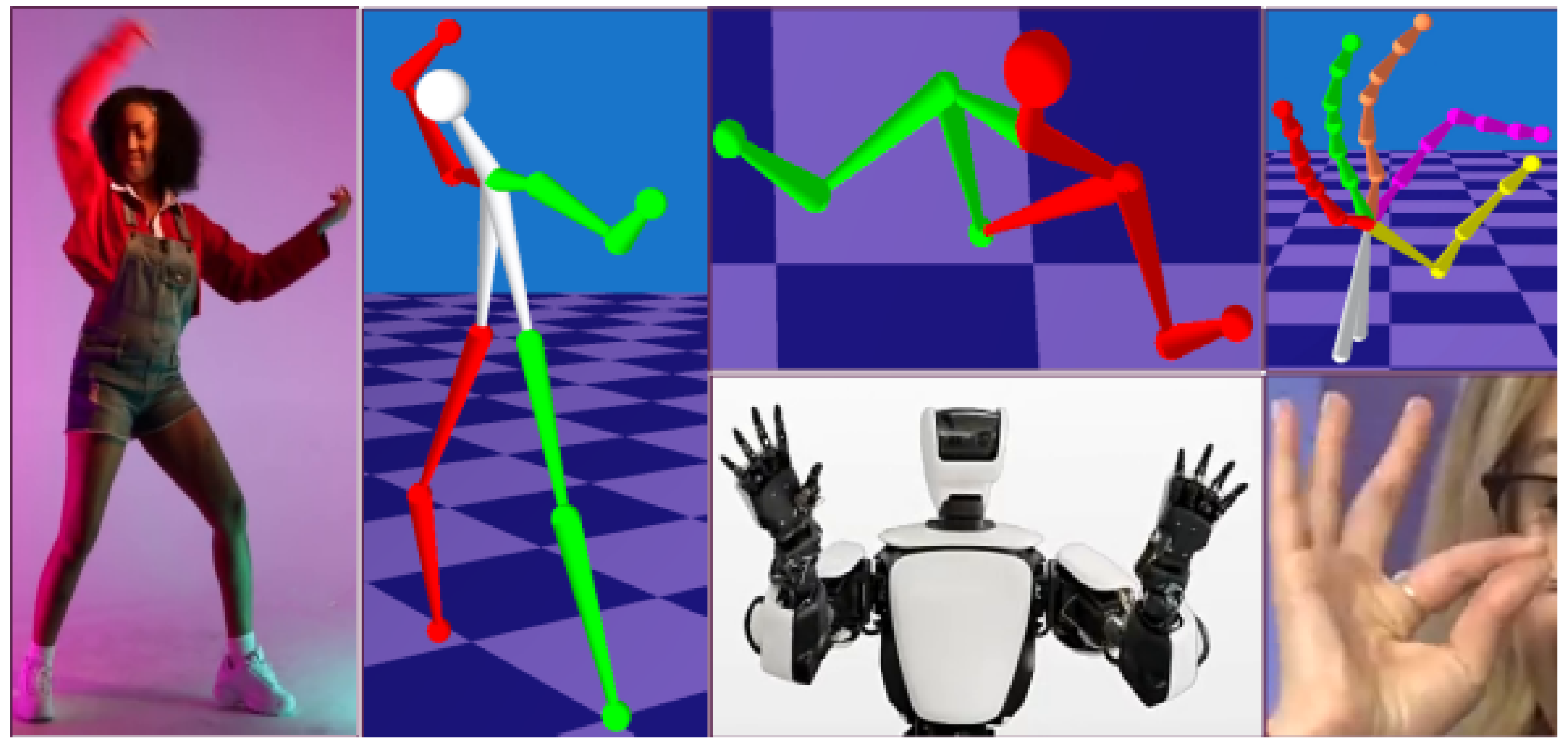
- A generic framework for articulated structure recovery which achieves state-of-the-art accuracy among not learning-based methods across public datasets. Moreover, it shows performance close to state-of-the-art learning-based methods but at the same time is not restricted to specific objects (see Section 4) and does not require training data.
- SfAM recovers sequence-specific bone proportions together with 3D joints (see Section 3). Thus, it does need known bone lengths.
- The articulated prior energy term makes our approach robust to noisy 2D observations (see Section 4.2.2) by imposing additional constraints on the 3D structure.
2. Related Work
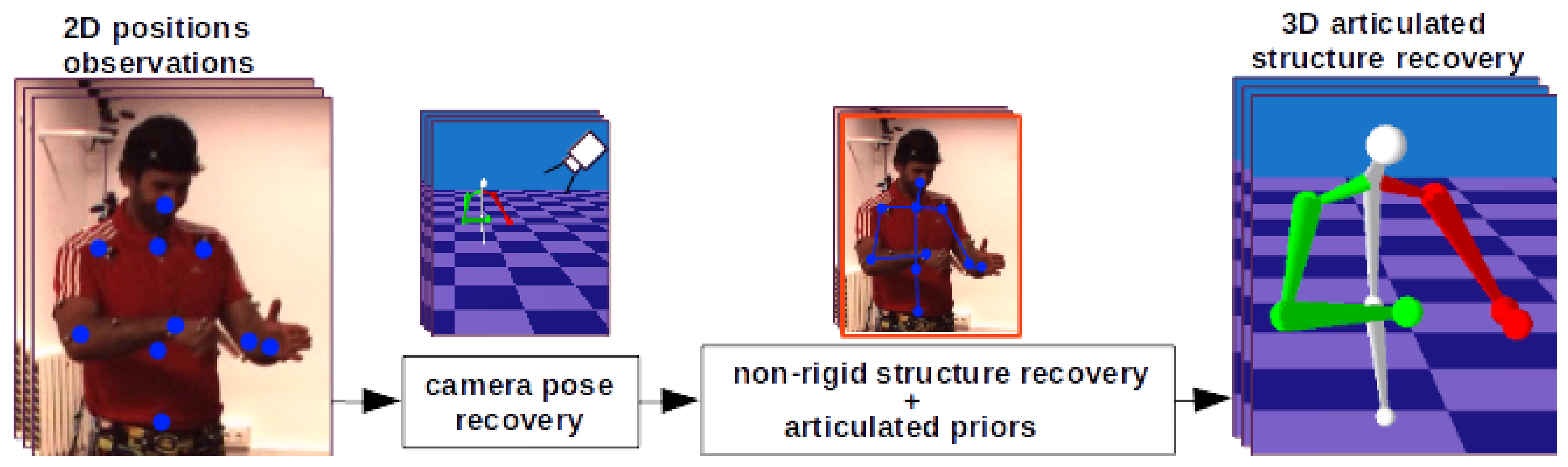
3. The Proposed SfAM Approach
3.1. Factorization Model
3.2. Recovery of Camera Poses
3.3. Articulated Structure Recovery
3.3.1. Articulated Structure Representation
3.3.2. Energy Optimization
| Algorithm 1: Structure from Articulated Motion (SfAM) |
| Input: initial normalized bone lengths , measurement matrix with 2D point tracks |
| Output: poses and 3D shapes |
| Initialize: is initialized as in [11], , , , , |
| step 1: recover with IST method [57] (Section 3.2) |
| step 2 (optional): smooth point trajectories in [11] |
| step 3: while not converged do |
| 1: |
| (optimize with Levenberg–Marquardt [55,56]) |
| 2: |
| 3: |
| 4: |
| 5: |
| end while |
4. Experiments and Results
4.1. Evaluation Methodology
4.2. Human Pose Estimation
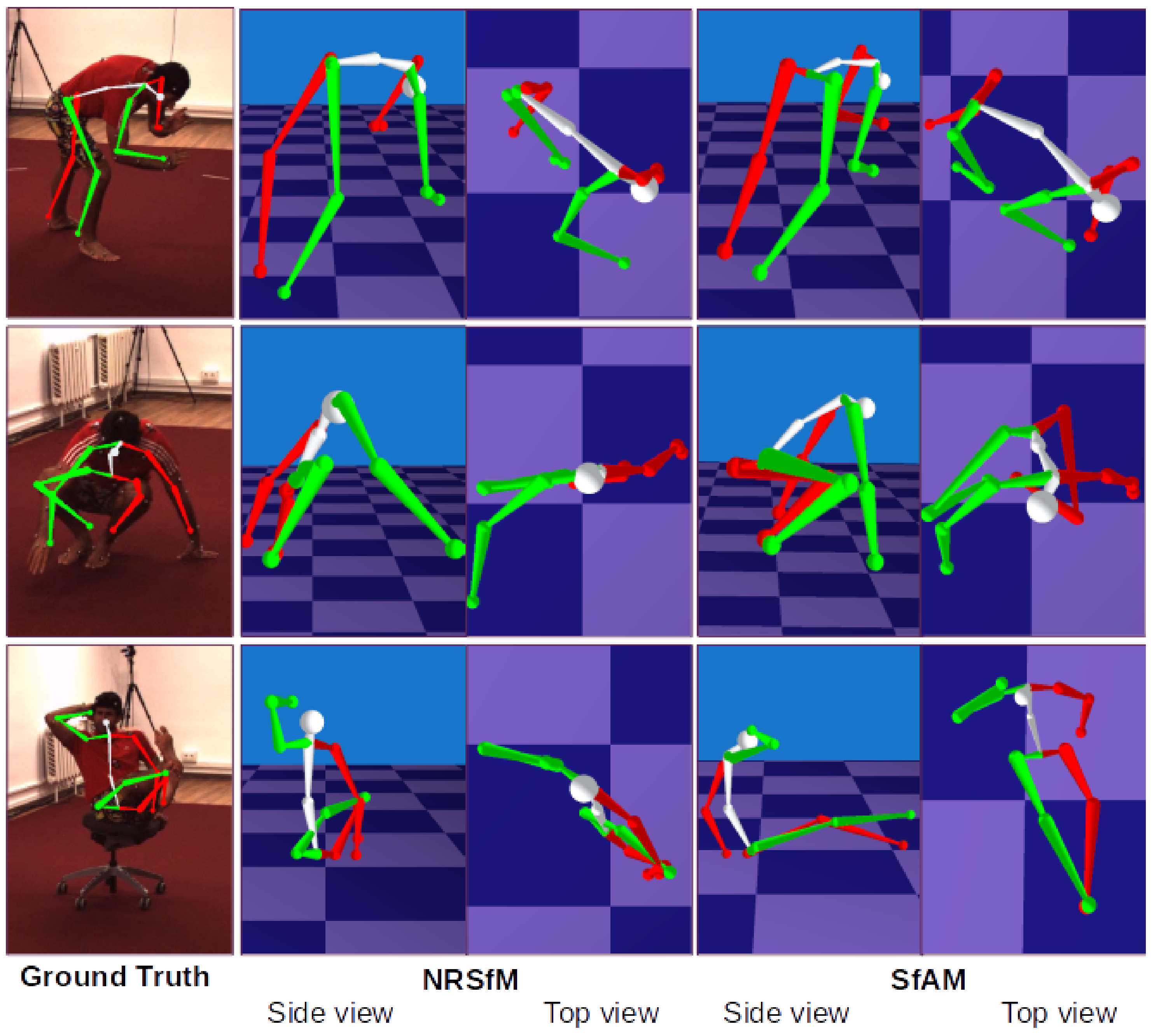
4.2.1. Human 3.6m Dataset
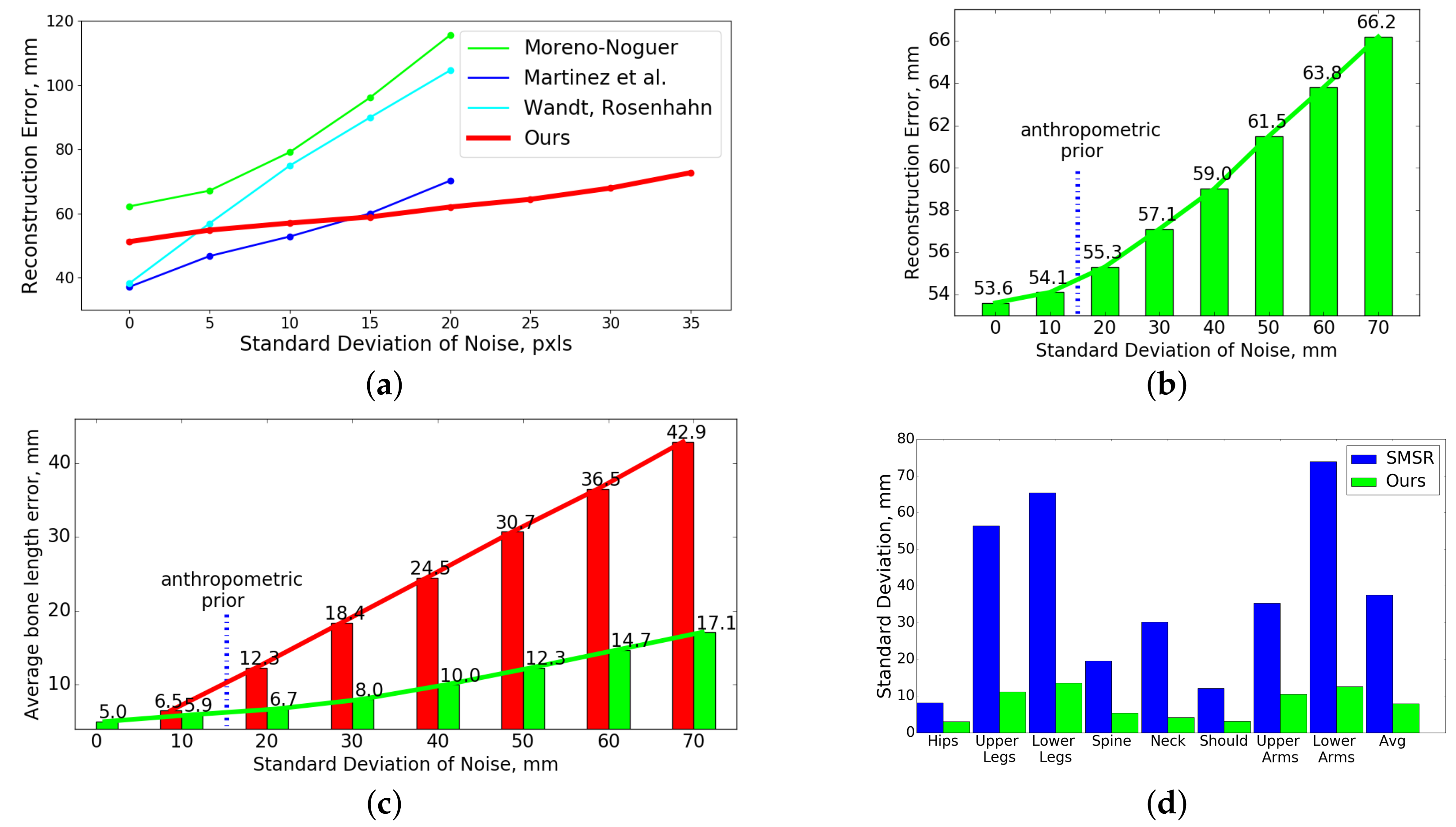
4.2.2. Robustness to Inaccurate 2D Point Tracks
4.2.3. Robustness to Incorrectly Initialized Bone Lengths and Real Bone Length Recovery
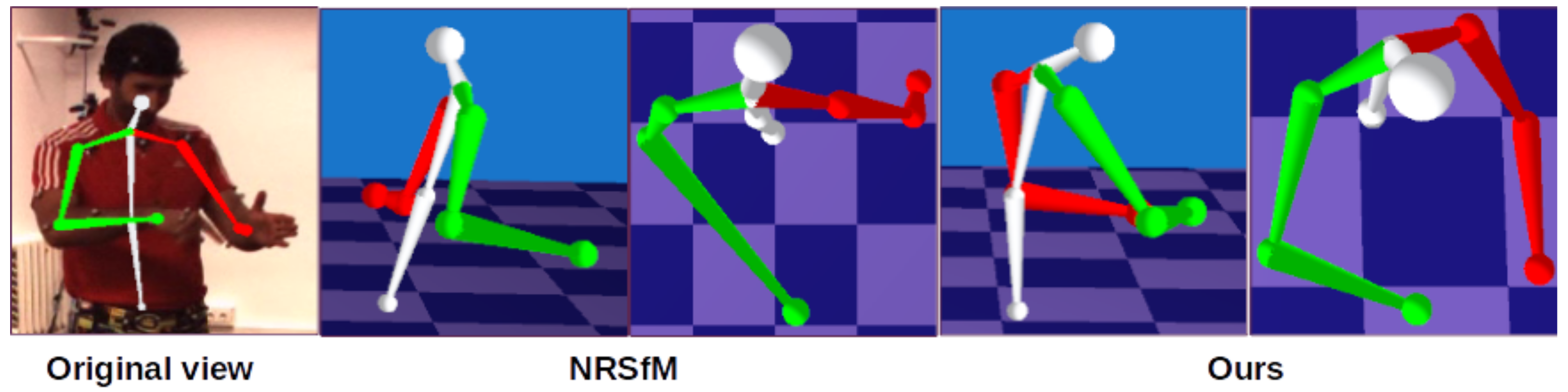
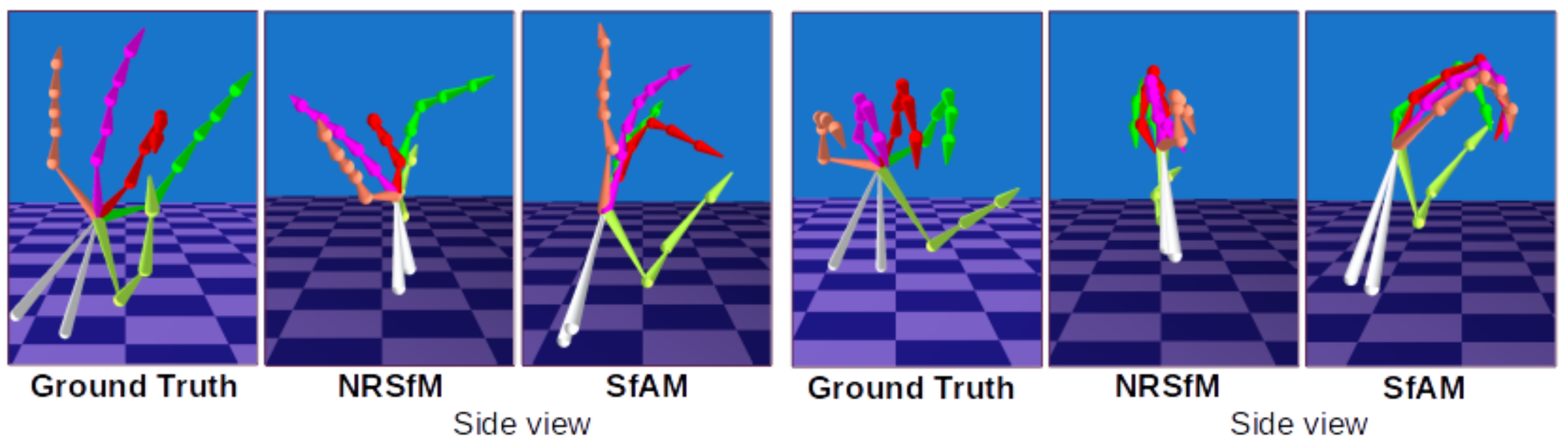
4.2.4. Synthetic NRSfM Datasets
4.2.5. Real-World Videos
4.3. Hand Pose Estimation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| SfAM | Structure from Articulated Motion |
| SfM | Structure from Motion |
| NRSfM | Non-Rigid Structure from Motion |
| FPC | Fixed-Point Continuation |
| SMSR | Scalable Monocular Surface Reconstruction |
| IST | Iterative Shrinkage-Thresholding |
Appendix A

References
- Ramakrishna, V.; Kanade, T.; Sheikh, Y. Reconstructing 3D Human Pose from 2D Image Landmarks. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 573–586. [Google Scholar]
- Wandt, B.; Ackermann, H.; Rosenhahn, B. 3D Reconstruction of Human Motion from Monocular Image Sequences. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2016, 38, 1505–1516. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Zhu, M.; Derpanis, K.; Daniilidis, K. Sparseness Meets Deepness: 3D Human Pose Estimation from Monocular Video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Leonardos, S.; Zhou, X.; Daniilidis, K. Articulated motion estimation from a monocular image sequence using spherical tangent bundles. In Proceedings of the International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 587–593. [Google Scholar]
- Lee, H.J.; Chen, Z. Determination of 3D human body postures from a single view. Comput. Vis. Graph. Image Process. (ICVGIP) 1985, 30, 148–168. [Google Scholar] [CrossRef]
- Hossain, M.R.I.; Little, J.J. Exploiting Temporal Information for 3D Human Pose Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 69–86. [Google Scholar]
- Zhou, X.; Huang, Q.; Sun, X.; Xue, X.; Wei, Y. Towards 3D Human Pose Estimation in the Wild: A Weakly-Supervised Approach. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 398–407. [Google Scholar]
- Mehta, D.; Rhodin, H.; Casas, D.; Fua, P.; Sotnychenko, O.; Xu, W.; Theobalt, C. Monocular 3D Human Pose Estimation in the Wild Using Improved CNN Supervision. In Proceedings of the International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 506–516. [Google Scholar]
- Martinez, J.; Hossain, R.; Romero, J.; Little, J.J. A Simple However, Effective Baseline for 3d Human Pose Estimation. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2659–2668. [Google Scholar]
- Dai, Y.; Li, H.; He, M. A Simple Prior-Free Method for Non-rigid Structure-from-Motion Factorization. Int. J. Comput. Vis. (IJCV) 2014, 107, 101–122. [Google Scholar] [CrossRef]
- Ansari, M.; Golyanik, V.; Stricker, D. Scalable Dense Monocular Surface Reconstruction. In Proceedings of the International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2014, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Akhter, I.; Sheikh, Y.; Khan, S.; Kanade, T. Trajectory Space: A Dual Representation for Nonrigid Structure from Motion. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2011, 33, 1442–1456. [Google Scholar] [CrossRef]
- Tompson, J.; Stein, M.; Lecun, Y.; Perlin, K. Real-Time Continuous Pose Recovery of Human Hands Using Convolutional Networks. ACM Trans. Graph. (ToG) 2014, 33, 169. [Google Scholar] [CrossRef]
- Tomasi, C.; Kanade, T. Shape and motion from image streams under orthography: A factorization method. Int. J. Comput. Vis. (IJCV) 1992, 9, 137–154. [Google Scholar] [CrossRef]
- Bregler, C.; Hertzmann, A.; Biermann, H. Recovering non-rigid 3D shape from image streams. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Hilton Head Island, SC, USA, 13–15 June 2000; pp. 690–696. [Google Scholar]
- Brand, M. A direct method for 3D factorization of nonrigid motion observed in 2D. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 122–128. [Google Scholar]
- Xiao, J.; Chai, J.X.; Kanade, T. A Closed-Form Solution to Non-rigid Shape and Motion Recovery. In Proceedings of the European Conference on Computer Vision (ECCV), Prague, Czech Republic, 11–14 May 2004; pp. 573–587. [Google Scholar]
- Bartoli, A.; Gay-Bellile, V.; Castellani, U.; Peyras, J.; Olsen, S.; Sayd, P. Coarse-to-fine low-rank structure-from-motion. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Akhter, I.; Sheikh, Y.; Khan, S.; Kanade, T. Nonrigid Structure from Motion in Trajectory Space. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 8–10 December 2008; pp. 41–48. [Google Scholar]
- Hartley, R.; Vidal, R. Perspective Nonrigid Shape and Motion Recovery. In Proceedings of the European Conference on Computer Vision (ECCV), Marseille, France, 12–18 October 2008. [Google Scholar]
- Akhter, I.; Sheikh, Y.; Khan, S. In defense of orthonormality constraints for nonrigid structure from motion. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 1534–1541. [Google Scholar]
- Gotardo, P.F.U.; Martínez, A.M. Non-rigid structure from motion with complementary rank-3 spaces. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 3065–3072. [Google Scholar]
- Zhu, Y.; Huang, D.; la Torre Frade, F.D.; Lucey, S. Complex Non-Rigid Motion 3D Reconstruction by Union of Subspaces. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Kumar, S.; Cherian, A.; Dai, Y.; Li, H. Scalable Dense Non-Rigid Structure-From-Motion: A Grassmannian Perspective. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Paladini, M.; Del Bue, A.; Xavier, J.; Agapito, L.; Stosić, M.; Dodig, M. Optimal Metric Projections for Deformable and Articulated Structure-from-Motion. Int. J. Comput. Vis. (IJCV) 2012, 96, 252–276. [Google Scholar] [CrossRef]
- Costeira, J.P.; Kanade, T. A Multibody Factorization Method for Independently Moving Objects. Int. J. Comput. Vis. (IJCV) 1998, 29, 159–179. [Google Scholar] [CrossRef]
- Tresadern, P.; Reid, I. Articulated structure from motion by factorization. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 1110–1115. [Google Scholar]
- Yan, J.; Pollefeys, M. A Factorization-Based Approach for Articulated Nonrigid Shape, Motion and Kinematic Chain Recovery From Video. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2008, 30, 865–877. [Google Scholar] [CrossRef]
- Fayad, J.; Russell, C.; Agapito, L. Automated Articulated Structure and 3D Shape Recovery from Point Correspondences. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 431–438. [Google Scholar]
- Park, H.S.; Sheikh, Y. 3D reconstruction of a smooth articulated trajectory from a monocular image sequence. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Valmadre, J.; Zhu, Y.; Sridharan, S.; Lucey, S. Efficient Articulated Trajectory Reconstruction Using Dynamic Programming and Filters. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 72–85. [Google Scholar]
- Kumar, S.; Dai, Y.; Li, H. Spatio-temporal union of subspaces for multi-body non-rigid structure-from-motion. Pattern Recognit. 2017, 71, 428–443. [Google Scholar] [CrossRef]
- Golyanik, V.; Jonas, A.; Stricker, D. Consolidating Segmentwise Non-Rigid Structure from Motion. In Proceedings of the International Conference on Machine Vision Applications (MVA), Tokyo, Japan, 27–31 May 2019. [Google Scholar]
- Taylor, J.; Jepson, A.D.; Kutulakos, K.N. Non-rigid structure from locally-rigid motion. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2761–2768. [Google Scholar]
- Fayad, J.; Agapito, L.; Del Bue, A. Piecewise Quadratic Reconstruction of Non-Rigid Surfaces from Monocular Sequences. In Proceedings of the European Conference on Computer Vision (ECCV), Heraklion, Greece, 5–11 September 2010; pp. 297–310. [Google Scholar]
- Lee, M.; Cho, J.; Oh, S. Consensus of Non-rigid Reconstructions. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4670–4678. [Google Scholar]
- Rehan, A.; Zaheer, A.; Akhter, I.; Saeed, A.; Mahmood, B.; Usmani, M.; Khan, S. NRSfM using Local Rigidity. In Proceedings of the Winter Conference on Applications of Computer Vision (WACV), Steamboat Springs, CO, USA, 24–26 March 2014; pp. 69–74. [Google Scholar]
- Taylor, C.J. Reconstruction of Articulated Objects from Point Correspondences in a Single Uncalibrated Image. In Proceedings of the Computer Vision and Image Understanding (CVIU), Hilton Head Island, SC, USA, 13–15 June 2000; pp. 349–363. [Google Scholar]
- Wei, X.K.; Chai, J. Modeling 3D human poses from uncalibrated monocular images. In Proceedings of the International Conference on Computer Vision (ICCV), Kyoto, Japan, 29 September–2 October 2009; pp. 1873–1880. [Google Scholar]
- Akhter, I.; Black, M.J. Pose-conditioned joint angle limits for 3D human pose reconstruction. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Wandt, B.; Ackermann, H.; Rosenhahn, B. A Kinematic Chain Space for Monocular Motion Capture. In Proceedings of the European Conference on Computer Vision Workshops (ECCVW), Munich, Germany, 8–14 September 2018; pp. 31–47. [Google Scholar]
- Xu, W.; Chatterjee, A.; Zollhöfer, M.; Rhodin, H.; Mehta, D.; Seidel, H.P.; Theobalt, C. MonoPerfCap: Human Performance Capture From Monocular Video. ACM Trans. Graph. (ToG) 2018, 37, 27. [Google Scholar] [CrossRef]
- Rogez, G.; Weinzaepfel, P.; Schmid, C. LCR-Net++: Multi-person 2D and 3D Pose Detection in Natural Images. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2019. [Google Scholar] [CrossRef] [PubMed]
- Kanazawa, A.; Black, M.J.; Jacobs, D.W.; Malik, J. End-to-End Recovery of Human Shape and Pose. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7122–7131. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Daniilidis, K. Ordinal Depth Supervision for 3D Human Pose Estimation. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Moreno-Noguer, F. 3D Human Pose Estimation from a Single Image via Distance Matrix Regression. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1561–1570. [Google Scholar]
- Malik, J.; Elhayek, A.; Stricker, D. WHSP-Net: A Weakly-Supervised Approach for 3D Hand Shape and Pose Recovery from a Single Depth Image. Sensors 2019, 19, 3784. [Google Scholar] [CrossRef] [PubMed]
- Malik, J.; Elhayek, A.; Stricker, D. Structure-Aware 3D Hand Pose Regression from a Single Depth Image. In International Conference on Virtual Reality and Augmented Reality; Springer: Berlin, Germany, 2018; pp. 3–17. [Google Scholar]
- Malik, J.; Elhayek, A.; Nunnari, F.; Varanasi, K.; Tamaddon, K.; Heloir, A.; Stricker, D. DeepHPS: End-to-end Estimation of 3D Hand Pose and Shape by Learning from Synthetic Depth. In Proceedings of the International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018. [Google Scholar]
- Malik, J.; Elhayek, A.; Stricker, D. Simultaneous Hand Pose and Skeleton Bone-Lengths Estimation from a Single Depth Image. In Proceedings of the International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 557–565. [Google Scholar]
- Sun, X.; Shang, J.; Liang, S.; Wei, Y. Compositional Human Pose Regression. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2621–2630. [Google Scholar]
- Wandt, B.; Rosenhahn, B. RepNet: Weakly Supervised Training of an Adversarial Reprojection Network for 3D Human Pose Estimation. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Ma, S.; Goldfarb, D.; Chen, L. Fixed point and Bregman iterative methods for matrix rank minimization. Math. Program. 2011, 128, 321–353. [Google Scholar] [CrossRef]
- Levenberg, K. A method for the solution of certain nonlinear problems in least squares. Q. Appl. Math. 1944, 2, 164–168. [Google Scholar] [CrossRef]
- Marquardt, D.W. An algorithm for least-squares estimation of nonlinear parameters. J. Soc. Ind. Appl. Math. 1963, 11, 431–441. [Google Scholar] [CrossRef]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]
- Dabral, R.; Mundhada, A.; Kusupati, U.; Afaque, S.; Sharma, A.; Jain, A. Learning 3D Human Pose from Structure and Motion. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 679–696. [Google Scholar]
- Yasin, H.; Iqbal, U.; Krüger, B.; Weber, A.; Gall, J. 3D Pose Estimation from a Single Monocular Image. arXiv 2015, arXiv:1509.06720. [Google Scholar]
- Agarwal, S.; Mierle, K. Ceres Solver. Available online: http://ceres-solver.org (accessed on 21 March 2019).
- Bogo, F.; Kanazawa, A.; Lassner, C.; Gehler, P.V.; Romero, J.; Black, M.J. Keep It SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 561–578. [Google Scholar]
- Rogez, G.; Schmid, C. MoCap-guided Data Augmentation for 3D Pose Estimation in the Wild. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016; pp. 3108–3116. [Google Scholar]
- Chen, C.; Ramanan, D. 3D Human Pose Estimation = 2D Pose Estimation + Matching. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5759–5767. [Google Scholar]
- Nie, B.X.; Wei, P.; Zhu, S. Monocular 3D Human Pose Estimation by Predicting Depth on Joints. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3467–3475. [Google Scholar]
- Omran, M.; Lassner, C.; Pons-Moll, G.; Gehler, P.V.; Schiele, B. Neural Body Fitting: Unifying Deep Learning and Model Based Human Pose and Shape Estimation. In Proceedings of the International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 484–494. [Google Scholar]
- Zhou, X.; Zhu, M.; Pavlakos, G.; Leonardos, S.; Derpanis, K.G.; Daniilidis, K. MonoCap: Monocular Human Motion Capture using a CNN Coupled with a Geometric Prior. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2018, 41, 901–914. [Google Scholar] [CrossRef]
- Pavlakos, G.; Zhou, X.; Derpanis, K.G.; Daniilidis, K. Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Kinauer, S.; Güler, R.A.; Chandra, S.; Kokkinos, I. Structured Output Prediction and Learning for Deep Monocular 3D Human Pose Estimation. In Proceedings of the Energy Minimization Methods in Computer Vision and Pattern Recognition (EMMCVPR), Venice, Italy, 30 October–1 November 2017; pp. 34–48. [Google Scholar]
- Tekin, B.; Márquez-Neila, P.; Salzmann, M.; Fua, P. Learning to Fuse 2D and 3D Image Cues for Monocular Body Pose Estimation. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3961–3970. [Google Scholar]
- Habibie, I.; Xu, W.; Mehta, D.; Pons-Moll, G.; Theobalt, C. In the Wild Human Pose Estimation Using Explicit 2D Features and Intermediate 3D Representations. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhao, L.; Peng, X.; Tian, Y.; Kapadia, M.; Metaxas, D.N. Semantic Graph Convolutional Networks for 3D Human Pose Regression. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Arnab, A.; Doersch, C.; Zisserman, A. Exploiting temporal context for 3D human pose estimation in the wild. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Chen, X.; Lin, K.; Liu, W.; Qian, C.; Wang, X.; Lin, L. Weakly-Supervised Discovery of Geometry-Aware Representation for 3D Human Pose Estimation. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Sun, X.; Xiao, B.; Wei, F.; Liang, S.; Wei, Y. Integral Human Pose Regression. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 536–553. [Google Scholar]
- Pavllo, D.; Feichtenhofer, C.; Grangier, D.; Auli, M. 3D human pose estimation in video with temporal convolutions and semi-supervised training. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Paladini, M.; Del Bue, A.; Stosic, M.; Dodig, M.; Xavier, J.M.F.; Agapito, L. Factorization for non-rigid and articulated structure using metric projections. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 2898–2905. [Google Scholar]
- Gotardo, P.F.U.; Martinez, A.M. Kernel non-rigid structure from motion. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 802–809. [Google Scholar]
- Agudo, A.; Moreno-Noguer, F. A Scalable, Efficient, and Accurate Solution to Non-Rigid Structure from Motion. Comput. Vis. Image Underst. (CVIU) 2018, 167, 121–133. [Google Scholar] [CrossRef]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional Pose Machines. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Gordon, C.C.; Churchill, T.; Clauser, C.E.; Bradtmiller, B.; McConville, J.T. 1988 Anthropometric Survey of U.S. Army Personnel: Methods and Summary Statistics; United States Army Natick Soldier Research, Development and Engineering Center: Natick, MA, USA, 1989; p. 649. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | P1 | P2 | P3 |
|---|---|---|---|
| Zhou et al. [3] * | 106.7 | - | - |
| Akhter et al. [41] | - | 181.1 | - |
| Ramakrishna et al. [1] | - | 157.3 | - |
| Bogo et al. [61] | - | 82.3 | - |
| Kanazawa et al. [45] * | 67.5 | 66.5 | - |
| Moreno-Noguer [47] * | 62.2 | - | - |
| Yasin et al. [59] | - | - | 110.2 |
| Rogez et al. [62] | - | - | 88.1 |
| Chen, Ramanan [63] * | - | - | 82.7 |
| Nie et al. [64] * | - | - | 79.5 |
| Sun et al. [52] * | - | - | 48.3 |
| Omran et al. [65] * | 59.9 | - | - |
| Zhou et al. [66] * | 54.7 | - | - |
| Mehta et al. [8] * | 54.6 | - | - |
| Pavlakos et al. [67] * | 51.9 | - | - |
| Kinauer et al. [68] * | 50.3 | - | - |
| Tekin et al. [69] * | 50.1 | - | - |
| Rogez et al. [44] * | 49.2 | 51.1 | 42.7 |
| Habibie et al. [70] * | 49.2 | - | - |
| Martinez et al. [9] * | 45.6 | - | - |
| Zhao et al. [71] * | 43.8 | - | - |
| Pavlakos et al. [46] * | 41.8 | - | - |
| Arnab, Doersch et al. [72] * | 41.6 | - | - |
| Chen, Lin et al. [73] * | 41.6 | - | - |
| Sun et al. [74] * | 40.6 | - | - |
| Wandt, Rosenhahn [53] * | 38.2 | - | - |
| Pavllo et al. [75] * | 36.5 | - | - |
| Dabral et al. [58] * | 36.3 | - | - |
| SMSR [11] | 106.6 | 105.2 | 102.9 |
| SMSR [11]+[38] | 145.2 | 124.0 | 139.9 |
| Our SfAM | 51.2 | 51.7 | 53.9 |
| Method | Drink | PickUp | Stretch | Yoga |
|---|---|---|---|---|
| MP [76] | 0.4604 | 0.4332 | 0.8549 | 0.8039 |
| PTA [20] | 0.0250 | 0.2369 | 0.1088 | 0.1625 |
| CSF1 [77] | 0.0223 | 0.2301 | 0.0710 | 0.1467 |
| CSF2 [23] | 0.0223 | 0.2277 | 0.0684 | 0.1465 |
| BMM [10] | 0.0266 | 0.1731 | 0.1034 | 0.1150 |
| Lee [37] | 0.8754 | 1.0689 | 0.9005 | 1.2276 |
| PPTA [78] | 0.011 | 0.235 | 0.084 | 0.158 |
| SMSR [11] | 0.0287 | 0.2020 | 0.0783 | 0.1493 |
| SMSR [11]+[38] | 0.4348 | 0.4965 | 0.3721 | 0.4471 |
| Our SfAM | 0.0226 | 0.1921 | 0.0673 | 0.1242 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kovalenko, O.; Golyanik, V.; Malik, J.; Elhayek, A.; Stricker, D. Structure from Articulated Motion: Accurate and Stable Monocular 3D Reconstruction without Training Data. Sensors 2019, 19, 4603. https://doi.org/10.3390/s19204603
Kovalenko O, Golyanik V, Malik J, Elhayek A, Stricker D. Structure from Articulated Motion: Accurate and Stable Monocular 3D Reconstruction without Training Data. Sensors. 2019; 19(20):4603. https://doi.org/10.3390/s19204603
Chicago/Turabian StyleKovalenko, Onorina, Vladislav Golyanik, Jameel Malik, Ahmed Elhayek, and Didier Stricker. 2019. "Structure from Articulated Motion: Accurate and Stable Monocular 3D Reconstruction without Training Data" Sensors 19, no. 20: 4603. https://doi.org/10.3390/s19204603
APA StyleKovalenko, O., Golyanik, V., Malik, J., Elhayek, A., & Stricker, D. (2019). Structure from Articulated Motion: Accurate and Stable Monocular 3D Reconstruction without Training Data. Sensors, 19(20), 4603. https://doi.org/10.3390/s19204603