1. Introduction
Cognitive radio (CR) is commonly viewed as a promising technology that tremendously alleviates the increasing pressure on current rigid spectrum resource allocation regimes, by enabling dynamic access to the licensed spectrum in an opportunistic manner [
1]. The opportunistic spectrum acquisition capability of CR systems generally relies on the spectrum sensing technologies that they adopt to identify the licensed spectrum status [
2,
3]. Cognitive users, also known as secondary users (SUs), are permitted to utilize the licensed spectrum only if they can assure themselves that the licensed spectrum is not temporarily occupied by the primary users (PUs). Generally, single user based spectrum sensing technologies can be categorized into blind and knowledge aided approaches [
4]. Among various spectrum sensing methods, energy detection (ED) is an extensively used technique that requires no a priori knowledge of the PU signal and the channel environment. Capturing the received signal energy within a certain frequency band, a simple threshold test could agilely indicate whether the PU signal exists in the licensed spectrum or not. However, it is well known that the easy-to-implement energy detectors are vulnerable to noise power uncertainty effects and could not perform well under low signal to noise ratio (SNR) conditions, especially in severe multipath fading and shadowing environments.
In order to tackle the problem of single user based spectrum sensing, cooperative spectrum sensing (CSS) has been widely investigated, where multiple SUs collaborate to make a global decision on the licensed spectrum status. During each sensing interval, all SUs will report their spectrum observations or decisions to the fusion center (FC) and subsequently the FC makes a final decision based on its predefined decision strategy or fusion criterion [
5]. Typical hard decision fusion based CSS schemes can be found in [
6,
7], in which logical operations are proposed for fusing the individual decisions collected from the cooperative SUs in the network.
Apart from the conventional ED based spectrum sensing schemes, machine learning (ML) based classification methods have been attracting attention in recent years, where the problem of spectrum status identification is solved by classifying the collected spectrum observations as the PU signal component contained data or the noise-only data [
8,
9,
10]. For the purpose of spectrum sensing, ML approaches are classifiers to improve the detection performance of CSS and spectrum prediction, which is a part of spectrum sharing approaches [
11]. ML based classifiers have the function of automatic learning over a large amount of training data and are hence able to make spectrum status predictions on the test data, which in some general way allays the nuisance effects of multipath fading and shadow, encountered by threshold-test based traditional spectrum sensing strategies. Therefore, the ML based classifiers usually perform better than energy detectors and the logical criteria based CSS schemes. As for the implementation of ML algorithms, they can be roughly divided into two types: unsupervised learning, e.g., K-means, and supervised learning, e.g., support vector machine (SVM) and K-nearest neighbors (KNN) [
12,
13,
14]. The unsupervised methods directly model the input training data without exactly known labels for each training data point. In other words, they can not be sure whether the classification result of the training samples is correct or not [
15]. The feature of these algorithms is beneficial in that they demand no a priori knowledge of the PU behavior and only rely on the training samples to automatically find their potential labels according to the training samples themselves.
Unlike unsupervised learning, the supervised learning methods analyze the relationship between the training data and the corresponding labels readily available for them, and map the input test data to the appropriate prediction or decision. Specifically, when the training phase is completed, the generalized model is applied to the new test data and their labels are thus accordingly predicted. Compared with unsupervised learning, the supervised learning methods are characterized by demanding more a priori knowledge from the input training samples and the corresponding true labels.
As a typical classifier, SVM is studied in [
16] for CSS in detail, with an aim to find a linearly separable hyperplane with the help of support vectors by maximizing the margin of the classifier while minimizing the sum of classification errors. In [
17,
18], KNN is introduced and proved to be not only one of the simplest machine learning algorithms, but also one of the most basic, and best text categorization algorithms in case-based learning methods. However, to correctly apply KNN, we need to choose an appropriate value for
K, because the success of classification is highly dependent on this value. In this sense, it may be concluded that the KNN method is biased by
K, and there are many ways of choosing the
K value, among which a simple method is to run the algorithm many times with different
K values and choose the one with the best performance [
19]. However, this might not be a satisfactory plug-and-play solution for spectrum sensing in practice. Essentially as a most well-known clustering algorithm, the K-means algorithm clusters the data points with high similarity into the same cluster according to the principle of similarity [
20]. Due to its simplicity and efficiency, it has become the most widely used clustering algorithm [
21]. Since different classifiers have various advantages and drawbacks, combining different individual classifiers into a comprehensive one with better performance is a straightforward solution. In [
22,
23], the adaptive boosting (AdaBoost) algorithm is introduced, for which the constructed classifier is composed of multiple weaker models that are independently trained and whose predictions are combined to make the overall prediction.
Noticing that employing ML techniques for CSS may be currently a novel solution in discerning the licensed spectrum status, we study the potentiality and feasibility of adopting ML algorithms in CSS, where the FC handles the spectrum data in a totally different manner compared to the conventional hard decision fusion based CSS schemes. To be more specific, we propose a hybrid AdaBoost classification algorithm which combines a strong ML algorithm (e.g., SVM, K-Means, and KNN) and multiple weak ML classifier (e.g., DS) for CSS in the cognitive radio network (CRN). Taking into account the fact that the ML classifier and DS serve as relatively strong and weak sub-classifiers respectively, the proposed algorithm employs one of the common ML classification algorithms (SVM, KNN, and K-Means) as the first-stage classifier and DS as the second-stage classifier to eventually determine the class that the spectrum observations belong to. For the scenario that there is one single PU and multiple SUs in the CRN, the proposed hybrid AdaBoost classification algorithm yields higher detection probability than the pure ML classification algorithms themselves and the DS based AdaBoost classification algorithm as well. In our proposed schemes, the SVM based hybrid AdaBoost performs the best. When compared with the traditional CSS schemes, e.g., AND and OR criteria based hard decision fusion algorithms, the proposed hybrid AdaBoost classification algorithm achieves better performance too. All these verifications prove that the proposed algorithms could be utilized in practice as a newfangled solution for CSS.
The remainder of this paper is organized as follows. In
Section 2, we present the system model and some assumptions.
Section 3 introduces the conventional spectrum sensing methods.
Section 4 investigates various typical ML classifiers for CSS. In
Section 5, we propose and describe the hybrid AdaBoost classification algorithm in detail. In
Section 6, performance evaluation results of the proposed hybrid AdaBoost classification algorithm are given and compared with the conventional algorithms. Finally,
Section 7 concludes the paper.
2. System Model
We consider a CRN consisting of a single PU transmitter and N SU receivers indexed by . In the CRN, the n-th SU is located at the geographic coordinate . We assume that the probability of the PU being active over the licensed spectrum is and there are two hypotheses, and with probability and , respectively.
The received signal at the
n-th SU is expressed as
where
denotes the channel gain from the PU transmitter to
n-th SU,
is the PU’s transmitted signal,
is the PU’s transmitting power, and
is the additive white gaussian noise (AWGN) with zero-mean and variance
. If the time duration of each spectrum sensing interval is denoted as
and the spectrum bandwidth is
W, each SU usually grasps
samples of its received signal during the sensing duration
.
The noise variance normalized energy statistic of the
n-th SU in the first CSS phase (It is assumed that multiple SUs collect their spectrum observations in the first phase of CSS and the second phase is for global decision making in the FC.) can be denoted by
:
In the second CSS phase, all SUs report their spectrum decision
or energy observation
to the FC as:
where the FC operates over
or
via different criteria to make the global decision on the spectrum status.
The power attenuations between the PU and the SU depend on the channel coefficient
in that
, where the power attenuation coefficient
can be expressed as:
where
stands for the Euclidean distance or equivalently the L2-norm of the vector
,
is the pathloss for the relative distance
d with the propagation loss exponent
,
denotes the coordinate of the PU tranmitter,
is the shadow fading coefficient, and
the multipath fading coefficient.
4. Typical ML Classifiers for CSS
In this section, we investigate and propose some typical ML classifiers for the proposed CSS model. For ML method based CSS, a sufficiently large number of training energy vectors are demanded as training samples to train the classifiers. Let denote the l-th training energy vector obtained as and the spectrum availability flag (or label) corresponding to . Thus, the training set of energy vectors are and the spectrum availability labels are represented by , where L is the number of training samples (energy vectors) in the training set. After the classifier is successfully trained over the given training set , it is able to classify the input test energy vector with label denoting its true spectrum availability label. In addition, the set of test energy vectors can be denoted as and the set of corresponding spectrum availability labels is , where M is the number of test samples in the test set. If is used to denote the m-th test sample’s spectrum availability label decided by the classifier, it is either the spectrum available label (i.e., ) or the spectrum unavailable label (i.e., ). If the test energy vector is classified and labeled as spectrum available, it means that there is no PU in the active state and the licensed spectrum is available for the SU to access; otherwise, the SU cannot gain spectrum opportunity when the label is drawn as spectrum unavailable.
Therefore, the spectrum availability is correctly determined in the case that
, while mis-detection (or false alarm) occurs in the case that
and
(or
and
). Thus, the prediction error (
) is defined as the probability of mis-prediction of the status of the licensed spectrum:
where
is the indicator function that takes the value 1 if its argument is true and 0 otherwise.
4.1. K-Means Clustering
The K-means clustering algorithm operates in an unsupervised manner and partitions a set of the training energy vectors (i.e.,
) into
K disjoint clusters, which represents the
K categories of training vectors. In other words, the training energy vectors can be assigned into
K subsets of spectrum observations denoted by cluster labels
,
. Normally, if we purposely set the number of clusters as two in advance, we can obtain two clusters by using the K-means algorithm without knowing the true labels that these two clusters actually correspond to. In spectrum sensing, it is applicable to set cluster 1 and cluster 2 as the cluster with channel availability label
and the cluster with channel availability label 1, respectively. In this way, the K-means clustering algorithm serves as an ML classifier, equivalently. The core idea of K-means is each cluster has a centroid that is defined as the mean of all training energy vectors within itself. Let
be the centroid of cluster
k and
be the indicative variable. We define
, if the energy vector
is assigned to cluster
k, otherwise,
. Through several iterations of distance calculation, the values of
are updated sample by sample as follows:
The objective function of K-means is to minimize the squared error in clustering:
where
and
.
Figure 1 shows the two-user based classification results of the K-means clustering algorithm on the training samples when SNR
dB and SNR
dB respectively. We can see the farther the distance between samples belonging to two different labels, the better the classification result that can be obtained.
4.2. Support Vector Machine
The SVM provides a binary model in machine learning which strives to find a linearly separable hyperplane with the help of support vectors (i.e., energy vectors that lie closest to the decision surface) by maximizing the margin of the classifier while minimizing the sum of classification errors [
24]. As shown in
Figure 2, the learning strategy of SVM is to maximize the margin and its learning goal is to find a hyperplane in the
N-dimensional sample space.
The hyperplane equation can be expressed as
where
is the weighting vector and
b is the bias. Based on
, we need to minimize the vector norm of
so as to maximize the category margin, and hence the objective function is
Therefore, the SVM should satisfy the following condition for all
:
In practice, when a test energy vector
is fed into the SVM model, the SVM can determine which class it belongs to through the following rules:
However, in practice for most of the time, the test samples are usually not linearly separable. For this case, the hyperplane satisfying such conditions does not exist at all. Then, we need to find a fixed nonlinear feature mapping function
to map the non-linear samples into a new feature space and use a linear SVM in the feature space [
25]. Hence, the non-linear SVM should satisfy the following condition for all
:
and the decision rule for the non-linear SVM is given as:
Although the training energy vectors have been mapped into a higher dimensional feature space, practically we cannot achieve a perfect linearly separable hyperplane that satisfies the condition in Equation (
15) for each
. Hence, we rewrite the optimization problem as a convex optimization problem as follows:
where
C is the soft margin constant, for which a larger
C means the assignment of a higher penalty to errors, and
is the slack variable.
Figure 3 shows the training samples classified by SVM-rbf. We can notice that the decision surface divides the energy vectors in each class as clearly as possible, which leads to improved detection performance. Also, the decision surface can separate energy vectors more accurately as the SNR increases.
4.3. K-Nearest-Neighbor
The supervised K-nearest neighbors is a case-based learning method, which keeps all the training samples for classification. Being a lazy learning method prohibits it in many applications such as dynamic web mining for a large repository, as the KNN classifier requires storing the whole training set and may be too costly when this set is too large. One way to improve its efficiency is to find some representatives of the whole training data for classification, building an inductive learning model from the training samples, and classifying the test samples based on a similarity measure (e.g., distance functions), for example:
According to the given distance measure,
K samples with the nearest neighbor of test energy vector
are found in the training set
and the domain of covering these
K samples is
. Among them, the setting of
K value is generally lower than the square root of the number of samples, and it must be an odd number. Then the spectrum availability label for the spectrum data
can be predicted based on classification decision rules (e.g., majority voting) as:
where
and
is the training label of the
k-th nearest neighbor in
.
4.4. AdaBoost Algorithm
As for the weak classifier DS, it is a one-dimension decision tree, that uses only a single attribute of the spectrum data for splitting and makes only one judgment on each attribute (i.e., one of the test sample’s dimensions). It is also well known that the decision stumps (DS) are often used as sub-classifiers in ensemble methods.
In addition to the weak DS and strong ML classifiers, AdaBoost (adaptive boosting) algorithm is an ensemble learning algorithm composed of plenty of sub-classifiers to overcome the drawbacks of poor classification of individual sub-classifiers [
26,
27]. The core idea is to train different sub-classifiers
on the same training samples. As one kind of weak classifier, the DS is often used as sub-classifier in the AdaBoost algorithm [
28,
29], and these weak sub-classifiers are grouped together to construct a final stronger classifier. In
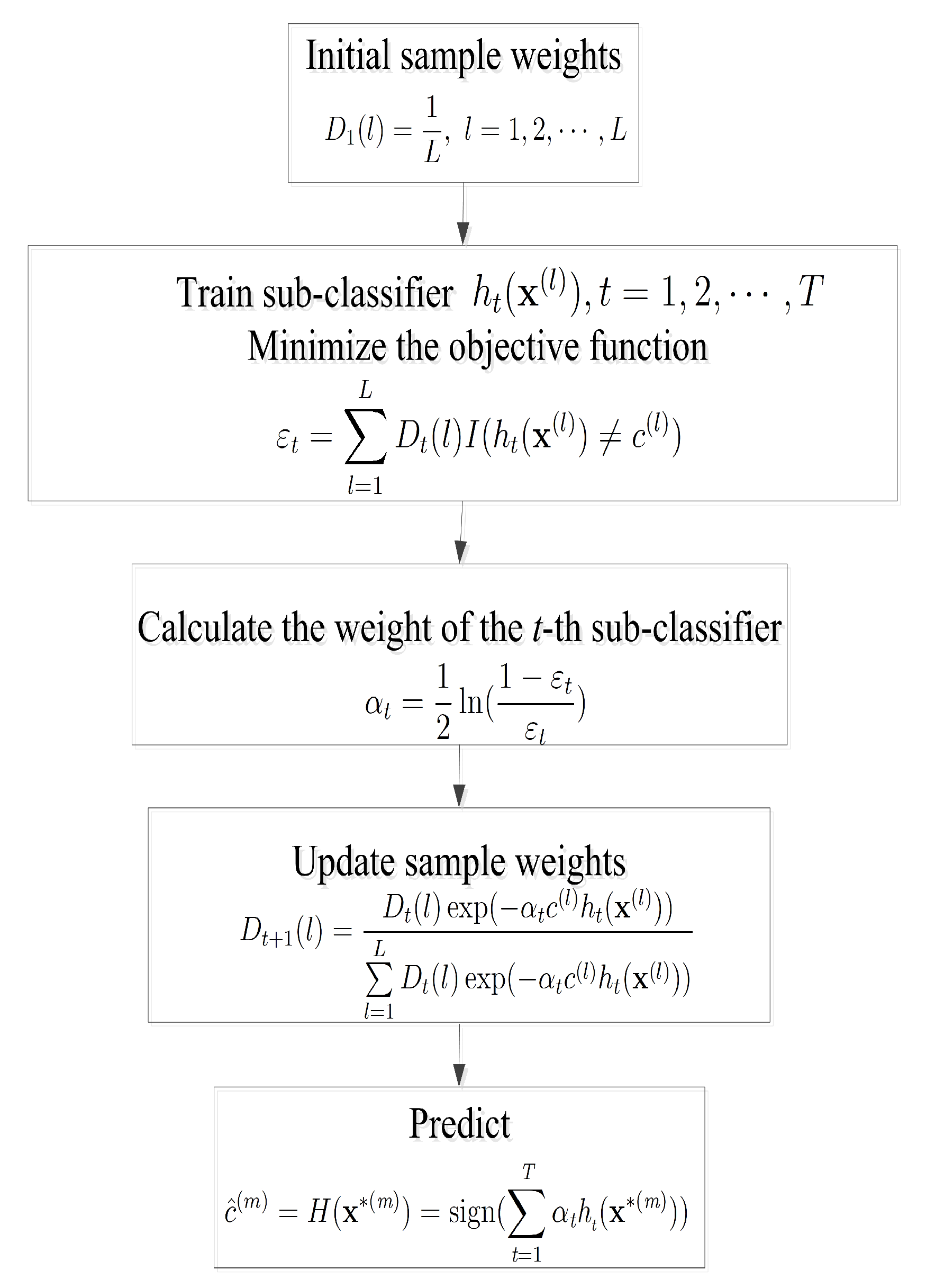
Figure 4, we present the flowchart of the AdaBoost algorithm.
As a combination of multiple sub-classifiers, the AdaBoost algorithm can be used for classification by choosing suitable sub-classifiers. The conventional AdaBoost algorithm adopts DS as sub-classifiers and it is proved to be efficient for many applications. However, complexity of this pure DS based structure is , and clearly it would spend more time to train and predict with the increase of the number of training samples and iteration rounds.
5. Hybrid AdaBoost Classification Algorithm
In this section, we propose a hybrid AdaBoost algorithm which uses a strong ML algorithm and multiple DS as sub-classifiers. The philosophy of employing both the strong ML algorithm and the DS lies in the feature of non-misclassification on training samples of decision stumps based AdaBoost algorithm and the feature of high classification accuracy of the strong ML algorithm. The hybrid AdaBoost algorithm adopts a strong ML algorithm to be a first sub-classifier and it is supposed to obtain the same classification result as that of many DS classifiers jointly operating together. Therefore, it decreases the number of iteration rounds and demands lower computational complexity than the conventional AdaBoost algorithm. As expected and verified, the proposed hybrid structure of the sub-classifiers in AdaBoost helps increase the detection probability and reduces the time consumed in operations. In our work, the aforementioned typical ML based strong classifiers (e.g., SVM and KNN) and clustering algorithm (e.g., K-Means) are first considered for serving as sub-classifiers in constructing a comprehensive classification algorithm to achieve better performance. We must point out that only cluster 1 or cluster 2 are obtained by K-Means and are not able to get the labels of data. But K-Means can still be used here in AdaBoost as the first sub-classifier, as long as we set cluster 1 and cluster 2 as label −1 and label 1 respectively.
To be more specific, we assign the initial weight
to each training sample as
in the first step. A strong ML classifier is adopted as the first sub-classifier and multiple DS are used as the following sub-classifiers (i.e.,
). After hybrid AdaBoost classification is performed, we can obtain the weight of each sub-classifier as follows:
where
is the classification error at the
t-th AdaBoost round by using the
t-th sub-classifier and it is defined as:
where
is the predicted class of
by classifier
and
denotes the
l-th training sample’s weight at the
t-th AdaBoost round.
In the proposed hybrid AdaBoost algorithm, the correctly classified sample’s weight increases and the falsely classified sample’s weight decreases at the end of each AdaBoost round, with the weights updated as:
where
presents the normalization factor which is defined as:
Since a strong ML classifier’s classification performance is generally better than that of the single DS, the weight of the strong ML classifier
classifier is usually greater than that of the other single DS classifiers
. Finally, these sub-classifiers are linearly combined to obtain a final classifier to predict the spectrum availability label on the basis of the test samples
. The classification result for the CSS is then obtained as:
where
represents the hybrid AdaBoost operator.
Specifically, the proposed AdaBoost algorithm based on the hybrid structure of a strong ML classifier and multiple DS is described in Algorithm 1.
| Algorithm 1 A Strong Machine Learning Classifier and Decision Stumps Based Hybrid Adaboost Classification Algorithm. |
Require:,,(number of sub-classifiers).
Ensure:.
- 1:
Initialize sample weight - 2:
- 3:
- 4:
- 5:
fordo - 6:
- 7:
- 8:
- 9:
end for - 10:
Predict the class of the m-th test sample
|
6. Simulations Results
In this section, the performance of the proposed hybrid AdaBoost classification algorithm is evaluated in computer simulations. We consider both a small scale CRN and a large scale CRN and the layout of a small scale CRN with two SUs participating in CSS is shown in
Figure 5a, where the SU are located respectively at (−1, 0) km and (0, 0) km and the PU at (−0.6,−0.6) km. The large scale layout with nine SU is shown in
Figure 5b, where all the SU are uniformly scattered within a 2.0 km × 2.0 km square area and the single PU is located at (−0.6,−0.6) km.
The PU signal bandwidth W is fixed as 5 MHz, the sensing duration is set as 100 s, and the path-loss exponent is chosen as 4. The shadow fading and the multi-path fading components are set as normal random variables with , and . In addition, the number of training samples L is 1000.
6.1. Prediction Error for Different Classifiers
The prediction errors of different ML technique based CSS algorithms for different sets of cooperative SUs are evaluated and compared in
Figure 6 and
Figure 7, respectively. It is shown that the prediction error of the proposed hybrid AdaBoost (e.g., SVM-AdaBoost, K-Means-AdaBoost, and KNN-AdaBoost) and the conventional DS-AdaBoost algorithms deteriorate when the number of AdaBoost rounds increases. Although the prediction errors of SVM, KNN, and K-Means algorithms remain consistent, they are inferior to the hybrid AdaBoost algorithms respectively. The prediction error performance is closely related to the number of SUs participating in CSS, since it is shown to be unacceptably deteriorating when the number of the cooperative SUs is as small as two. However, it is apparent that for the number of AdaBoost rounds being approximately 50, the SVM-AdaBoost algorithm achieves the best performance among all the algorithms, regardless of the number of SUs participating in the CSS.
It is important to note that the DS-AdaBoost algorithm and the proposed hybrid AdaBoost algorithms both encounter the overfitting problem when the number of AdaBoost rounds is unnecessarily increased, which makes the prediction error increase. In particular, the overfitting point of both the DS-AdaBoost and the hybrid AdaBoost are approximately around 100 rounds. Through this case, it is suitable to choose the number of iterations less than 100 in hybrid AdaBoost. It is verified that the SVM-AdaBoost algorithm achieves the lowest prediction error among all hybrid AdaBoost algorithms, outperforming all the other algorithms investigated in this paper.
6.2. Detection Probability for Different Classifiers
In addition to the prediction error, we also compare the detection probability performance of the conventional CSS schemes, e.g., hard decision fusion based AND and OR methods, and the hyrbid AdaBoost classifiers based CSS algorithms, as shown in
Figure 8. The results are obtained, with 10-fold cross-validation, for a desired false alarm probability of
when nine and two SUs participate in CSS, respectively. Simulation results show that all the ML classifiers based CSS schemes studied in this paper outperform the traditional logical based CSS methods. Moreover, the proposed SVM-AdaBoost scheme performs the best among all the CSS schemes.
6.3. Training Duration and Prediction Duration
The training duration for different classifiers with different numbers of training samples are shown in
Table 1. The training duration is reasonably increased with the increase of the number of training samples. The DS-AdaBoost shows the longest training duration (
s for 1000 training samples) among all these algorithms, whereas the proposed hybrid AdaBoost algorithms take relatively lower training durations. The proposed hybrid AdaBoost algorithms take less training time than the DS-AdaBoost algorithm, due to the high classification accuracy of the strong classifier that replaces the role of some DS in DS-AdaBoost and accelerates the training processing. The K-means classifier has the capability of detecting the spectrum availability more agilely in comparison to other ML classifiers. The times taken for deciding the spectrum availability for different classifiers with different numbers of test samples are shown in
Table 2. It is clear to observe that for the same test samples readily given, the prediction durations of all classifiers increase more or less with the increase of the number of test samples and the KNN algorithm takes the longest time for determining the spectrum availability. In
Table 2, it is also easy to notice that the SVM-AdaBoost algorithm takes the lowest time and the KNN-AdaBoost takes the longest time among the proposed hybrid AdaBoost algorithms when the number of test samples is the same.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}