Abstract
Owing to the limitations of imaging principles and system imaging characteristics, infrared images generally have some shortcomings, such as low resolution, insufficient details, and blurred edges. Therefore, it is of practical significance to improve the quality of infrared images. To make full use of the information on adjacent points, preserve the image structure, and avoid staircase artifacts, this paper proposes a super-resolution reconstruction method for infrared images based on quaternion total variation and high-order overlapping group sparse. The method uses a quaternion total variation method to utilize the correlation between adjacent points to improve image anti-noise ability and reconstruction effect. It uses the sparsity of a higher-order gradient to reconstruct a clear image structure and restore smooth changes. In addition, we performed regularization by using the denoising method, alternating direction method of multipliers, and fast Fourier transform theory to improve the efficiency and robustness of our method. Our experimental results show that this method has excellent performance in objective evaluation and subjective visual effects.
1. Introduction
Image super-resolution reconstruction (SRR) uses digital signal processing to generate high-resolution (HR) images from a single or multiple frames of low-resolution (LR) images, mainly through the super-resolution method. Image super-resolution reconstruction can efficiently utilize the potential value of existing image data and has applications such as military remote sensing reconnaissance [1], target tracking and monitoring [2,3,4], target location and recognition [5], astronomical observation [6], and medical imaging [7].
There are three types of super-resolution reconstruction methods: based on regular terms representation, learning-based methods, and partial differential equation-based methods. Learning-based image super-resolution reconstruction has been studied extensively in the recent years. For example, based on the convolutional neural network (CNN), Lim proposed an enhanced deep super-resolution network (EDSR) by removing unnecessary modules [8]. Dong redesigned the super-resolution CNN (SRCNN) structure by introducing a deconvolution layer at the end of the network, reformulating the mapping layer, adopting smaller filter sizes [9]. Xu proposed a novel global dense feature fusion convolutional network (DFFNet), which can take full advantage of global intermediate features leading to a continuous global information memory mechanism [10]. To restore various scales of image details, Du enhanced the multi-scale inference capability of CNNs by introducing competition among multi-scale convolutional filters [11]. Chi proposed a uniform deep CNN (DCNN) framework to handle the denoising and super-resolution of the CT image at the same time [12]. Zhang made a comparative study of fast super-resolution CNN (FSRCNN), deeply recursive convolutional networks (DRCN), very deep super-resolution convolutional networks (VDSR) and SRCNN for single image super-resolution with the purpose of space applications, and concluded that DRCN is the best model with more generalized for space object image [13]. Xiao formulated a joint loss function by combining the output and high-dimensional features of a non-linear mapping network, which uses satellite video data itself as a training set [14]. For infrared images, Liu proposed a classified dictionary learning method which classifies features of the samples into several reasonable clusters and trained a dictionary pair for each cluster [15]. He proposed a cascaded architecture of deep neural networks with multiple receptive fields by a large scale factor (×8) [16]. These methods learn the mapping between HR and LR images by pre-selecting test samples and accordingly reconstruct HR images. They can achieve good reconstruction results; however, the computational complexity is high.
The image reconstruction method based on the partial differential equation model has good results. The most popular of these methods are those based on the total variation (TV) regularization model [17]. This method preserves the edges of the images well, while removing image noise. However, there are “staircase artifacts” and unclear texture problems in the reconstructed image. To reduce the staircase artifacts, some scholars have proposed high-order variational models [18,19]. For example, Bredies, Kunisch, and Pock proposed total generalized variation (TGV) based on the combination of TV regularization with higher-order derivatives [20]. Although these methods can reduce staircase artifacts and protect the edges of the image, they produce “spots effect” in the processed image. To balance staircase artifacts and spot effect, a fractional-order variational model, which uses a fractional gradient instead of an integer gradient, has been proposed [21,22,23]. We have also proposed a super-resolution method, which combines quaternion [24,25] and fractional-order total variation, and uses the ADMM acceleration algorithm, achieving good results in image objective evaluation, visual effect and duration [26].
The regular term representation is an image representation model that captures the main information and intrinsic geometry of the image with a few parameters and achieves good results in terms of image restoration, target tracking, and other applications. Since Yang et al. first applied sparse representation to super-resolution reconstruction [27,28], many scholars have proposed improved methods for super-resolution reconstruction based on sparse representation [29,30,31,32,33,34,35]. In recent years, Selesnick and Chen proposed overlapping group sparse total variation (OGSTV) [36], which is a non-separating regular term that preserves the sparsity of the objective function [37]. The overlapping group sparse regularization term considers the sparsity of the image difference domain and also mines the neighborhood difference information of each point, thus mining structural sparsity characteristics of the image gradient. By overlapping the combined gradients, the difference between the smooth region and the boundary region can be improved, thereby suppressing the staircase artifacts of the TV model. The work of Selesnick and Chen, Liu et al. generalized the one-dimensional overlapping sparse regularization term into a two-dimensional overlapping sparse regularization term and introduced it into an anisotropic total variational model for denoising and deconvolution [38,39,40]. Using the Lp quasinorm instead of the L1 norm, we have also proposed a method for infrared image deblurring with an overlapping group sparse total variation method, in which the Lp quasinorm introduces another degree of freedom, better describes image sparsity characteristics, and improves image restoration [41].
Besides, there are some other types of image reconstruction models. Wang proposed an image self-embedding method, using authentication watermark and recovery watermark to complete image restoration. The authentication watermark locates the tampered area. The recovery watermark is compressed into different categories and encoded into variable lengths to improve the quality of the recovered images [42]. Xia proposed a new fast and accurate image matching algorithm, which first presents the district-identification method to obtain the integer-pixel matching result, then introduce gradient algorithm to match the sub-pixel position [43]. Wang proposed an image authentication and a recovery algorithm based on chaos and Hamming code, which can effectively detect image tampering and complete image recovery [44]. Wang proposed an image tampering detection and recovery algorithm based on jitter and chaos technology. The algorithm uses chaos technology to complete watermark embedding and encryption. Combined with the Chinese remainder theorem, it further reduces the impact of watermark embedding on image quality [45].
In fact, for the noisy images, the conventional super-resolution way is to denoise the images as a pre-processing step and then super-resolve the denoised images. In some new methods [46,47,48,49], such as the median filter transform (MFT) with parallelogram-shaped windows [47], denoising and super-resolving are integrated to provide improved results in comparison to the conventional way.
Super-resolution models based on regular terms can be solved by the alternating direction method of multipliers (ADMM) algorithm [50]. In recent years, many scholars have proposed various algorithms based on the classic ADMM, such as the plug-and-play (PnP) ADMM [51,52,53,54,55] and and regularization by denoising (RED) framework [56,57,58,59]. They are powerful image-recovery frameworks that aim to minimize an explicit regularization objective constructed from a plug-in image-denoising function. Since their introduction, they have demonstrated extremely promising results in image restoration and signal recovery problems [60,61,62].
In this study, we explore quaternion total variation and high-order to improve the sparsity exploitation of OGSTV. Our proposed method is called the quaternion and high-order overlapping group sparse (HOGS4), which is efficiently solved through the RED framework. The novelty of our work is two-fold. First, the HOGS4 method is considerably less restrictive than the OGSTV method for infrared image reconstruction as it shows good performance in terms of detail preservation by incorporating high-order image derivatives and also achieves accurate measurement of the sparsity potential from prior regularity. Second, it provides fast and efficient closed-form solutions for computationally complex sub-minimization problems using FFT.
The remainder of this paper is organized as follows. Section 2 briefly introduces the majorization–minimization (MM) method and RED framework. Section 3 describes the proposed method. In Section 4, our experiments and results are described. Finally, Section 5 and Section 6 present the discussion and conclusions, respectively.
2. Related Works
2.1. Overlapping Group Sparse Total Variation
The overlapping group sparse total variation (OGSTV) model [36] is as follows:
where the symbol * is the convolution operator; is the reconstructed image; and are the horizontal and vertical differential convolution kernels, respectively. is used to solve the combined gradient, where is defined as
where K is the group size, , . is the largest integer value less than or equal to x.
From Equation (2), it can be seen that the combined gradient considers the gradient information of the neighborhood pixel, and the gradient information of these neighboring pixels is recombined by the L2 norm, thereby improving the difference between the smooth region and the edge region of the image [39].
The overlapping group sparse model can be solved using the MM method [63]:
where is the overlapping group sparse regular term, and is an overlapping group sparse matrix of size .
According to the MM method, to minimize , we need to find a function , such that for all and , and the equality holds if and only if . According to this, the minimum value of calculated each time is the optimized value of , and Equation (3) can be written as
According to the following inequalities:
where the equal sign is only true when .
Equation (6) can be written as:
where is the vector form of the matrix , is independent of and can be considered as a constant term for ; is a diagonal matrix whose diagonal elements are defined as follows:
By combining Equations (4) and (6), Equation (3) can be transformed into the following iterative optimization method:
Its iterative optimal solution is as follows:
where is the identity matrix, is the vector form of , and represents the vector matrixing operator.
Therefore, we obtain Algorithm 1 to solve Equation (3).
| Algorithm 1 MM method |
| Initialize:, , , , , , Maximum inner iterations NIt, Whiledo
End While Return |
2.2. Regularization by Denoising
For image super-resolution reconstruction, the model can be expressed as
where is a circular matrix that represents the convolution for the anti-aliasing filter. is a binary sampling matrix, where the rows are subsets of the identity matrix. Further, is an observation image, and represents the corresponding original image.
To solve the above model, we can transform it into image denoising using regularization by denoising (RED) [56,57], which relies on a general structural smoothness penalty term for regularizing any desired inverse problem. Specifically, the regularization term is defined as
where is defined as the image denoising engine
The denoising engine is applied to image , and the induced penalty is proportional to the inner product between the image and its denoising residual. The smooth regularization effectively uses image adaptive Laplacian, and then extracts its definition from any image denoising engine . Interestingly, under the mild assumption of , it is proved that the regularized gradient is manageable, just like the given denoising residual [58,59].
3. Proposed Method
Inspired by the overlapping group sparse and quaternion total variation methods, this paper proposed a denoising model that uses the RED framework to complete infrared image super-resolution reconstruction (HOGS4). The traditional OGSTV does not fully consider pixel points, only considers first-order information [40]. To improve the denoising effect, we extend the traditional OGSTV to the high-order total variation model. The proposed model of high-order overlapping group sparse total variation not only considers first-order information but also adds the high-order gradient information of the horizontal, vertical, back diagonal and diagonal directions to the prior term. The introduction of quaternion and high-order information is used to make the prior knowledge more accurate, thus protecting the edges of the image [26], and also suppressing the influence of small edges on the estimation of the blurring core [20]. The denoising model is defined as follows:
where represents the convolution kernels along the horizontal, vertical, back diagonal, and diagonal directions, respectively. These are defined as follows:
Then according to Equation (11), the HOGS4 for infrared image super-resolution reconstruction method based on RED framework can be expressed as:
where regularization term in RED framework can be defined as
To solve the HOGS4 model in the RED framework, according to the principle of ADMM, an assistant variable is required to convert the unconstrained problem given by Equation (16) into a constrained problem:
Consequently, the corresponding augmented Lagrangian function is as follows:
where is a Lagrange multiplier, and is a penalty parameter.
Because and are decoupled, the minimizer of Equation (18) can be found by solving the following sequence of and sub-problems:
The procedure comprises the following steps:
1. To solve the sub-problem of , let . Then, Equation (20) can be represented as follows:
Considering and are fixed, by setting the first-order derivative of in Equation (22) as zero, we have
According to the ADMM, the solution of the sub-problem of is
Considering and are fixed, by setting the first-order derivative of in Equation (25) as zero, we have
which can be solved by the fixed point strategy, leading to the following update rule for [56]:
where is HOGS4 denoising engine, which is defined as:
Euqation (27) means that our approach in this case is computationally more expensive, as it will require several activations of the denoising engine [56].
3. Then we update the Lagrange multiplier as
The proposed SRR method is summarized in Algorithm 2.
| Algorithm 2 Super-resolution using RED-HOGS4 |
| Initialize:, , N While
End While |
Regarding the sub-problem , Equation (28) can be converted into the following constraint problem:
Accordingly, the augmented Lagrangian function is:
where and () is the Lagrange multipliers; and are penalty parameters.
The minimizer of Equation (30) is the saddle point of , which can be found by solving the following sequence of subproblems:
The procedure comprises the following steps:
1. To solve the sub-problem , the 2D Fourier transform of can be obtained by employing the convolution theorem [64]:
where the symbol ∘ represents component-wise multiplication.
Considering , , , and are fixed, by setting the first-order derivative of in Equation (35) as zero, we have
Then, according to Equation (37), we have
where is the conjugate map of .
2. To solve the sub-problem of in Equation (33), the MM (Algorithm 1) can be used:
where represents the iteration of the MM algorithm for , and as
3. To solve the sub-problem , we set the first-order derivative of in Equation (34) as zero, and get:
4. Lastly, the Lagrange multiplier can be updated as
In this manner, all the sub-problems of Equation (28) are solved independently. In all iterations, the sub-problem is solved by MM algorithm according to Equations (41) and (42). Considering the special structure of the differential matrices in the sub-problem of , we regard the differential operators as convolution operators. By introducing the convolution theorem [64], the sub-problem is solved in the frequency domain. The entire algorithm to solve Equation (28) is summarized in Algorithm 3. Besides, for Algorithm 3, regarded as HOGS4 denoising engine, we can also use it as an independent denoising algorithm, using quaternion and high-order overlapping group sparse total variation to complete the image denoising.
| Algorithm 3 HOGS4 denoising engine using ADMM |
| Initialize: While End While Return |
4. Experiments and Results
4.1. Materials and Method
In this section, we present several numerical results to illustrate the performance of the proposed method. RED-HOGS4 is compared with different noise levels and Gaussian blur conditions with several other methods, including the MFT [47], RED-TV [17], RED-TGV [20], and RED-OGSTV [36] methods. Among the four methods, the MFT method used the scripts provided in [47] while other methods are based on the literatures and are combined with the RED framework for super-resolution reconstruction. Eight infrared images are selected from the infrared image database LTIR [65] and IRData [66] as test pictures, as shown in Figure 1. Our experiments were performed on a PC with an Intel CPU 2.8 GHz and 8 GB RAM using MATLAB R2014a.

Figure 1.
HR infrared images: (a) Streets [65], (b) Garden [65], (c) Station [66], (d) Gate [66], (e) Cars [66], (f) Sidewalk [66], (g) Building [66], (h) Office [66].
For the objective evaluation, we calculated the peak signal-to-noise ratio (PSNR) [67] and structural similarity (SSIM) [68]. PSNR is an engineering term, which can compare the similarity of two input images or signals based on the mean square error. SSIM is also a method to measure the similarity between two input images, which is designed to improve on other methods such as PSNR which are not consistent with human eye perception. These can be defined as follows:
where and are the original image; and are the reconstructed image; and are the mean values of and , respectively. Further, and are the variances of and , respectively; is the covariance of and . The parameters and are set such that the denominator of SSIM is a nonzero number. In this study, we set and [68].
In general, larger values of PSNR and SSIM indicate better performance. Therefore, in this experiment, we focus on the PSNR as well as the SSIM. In all experiments, we set the parameters empirically as follows: , , [57]. If , the Algorithm 3 is a classic ADMM, but makes it converge noticeably faster than [38]; therefore, we set . Besides, for the tol value in Algorithm 3, when N is recommended to be set to 3 in the literature [57], we found that when , the PSNR value is high, so we set in all experiments. The blur matrix in Equation (11) is set as a corresponding matrix to the blur kernel, which was generated by a MATLAB built-in command “fspecial (‘gaussian’, 7, 1.6)”. is set as a K-fold downsampling operator which is generated by the MATLAB built-in function “downsample(X,K)”.
4.2. Infrared Image Super-Resolution Experiment without Noise
In the experiment, the LR images without noise are obtained by downsampling the HR images (2-fold, 3-fold, and 4-fold). To evaluate the performance objectively, PSNR and SSIM are calculated under different levels of super-resolving operators (corresponding to ×2, ×3, and ×4). The experimental results of each method are listed in Table 1.

Table 1.
Infrared image super-resolution experiment results without noise.
It can be seen from the experimental results in Table 1 that when there is no noise in the infrared images, in the ×2 reconstruction results, the PSNR values of Street are MFT 31.6188 dB, RED-TV 36.3936 dB, RED-TGV 36.4216 dB, RED-OGSTV 36.3983 dB, and RED-HOGS4 36.4195 dB. The results show that: 1. compared RED-HOGS4 36.4195 dB with RED-OGSTV 36.3983 dB, the high-order has improvement compared with the first-order; 2. compared RED-HOGS4 36.4195 dB with RED-TGV 36.4216 dB, though the result of RED-HOGS4 is worse than that of RED-TGV, the experimental values are close. The SSIM values of Street are MFT 0.9561, RED-TV 0.9867, RED-TGV 0.9911, RED-OGSTV 0.9915, and RED-HOGS4 0.9912. Because the parameter setting in the experiment is mainly to ensure PSNR, not SSIM, the SSIM is given as a reference. However, it can be seen from SSIM results that the SSIM of RED-HOGS4 is only worse than that of RED-OGSTV in five methods. Besides, the best PSNR values of Station, Building and Office are RED-OGSTV 33.1898 dB, RED-TGV 33.6576 dB and RED-TGV 31.2934 dB, while the PSNR values of RED-HOGS4 are 33.1657 dB, 33.6553 dB, 31.2891 dB, respectively. The difference between them is little. On the contrary, we can see the best PSNR values of Garden, Gate, Car and Sidewalk are RED-HOGS4 44.1652 dB, 32.1942 dB, 32.6179 dB and 33.8876 dB in the ×2 reconstruction results. Taken together, although the RED-HOGS4 method only has the best PSNR value for the four images in the ×2 reconstruction results, from an overall perspective, the average PSNR of the eight images processed by the RED-HOGS4 method is greater than that of other methods. The RED-HOGS4 method exhibits better SSIM only in individual pictures; however, the mean SSIM is worse than the processing result obtained by the MFT method. Simultaneously, the PSNR values of all the images processed by the MFT method are poor. As the super-resolution levels of super-resolving operators increase to ×3 and ×4, the results of RED-HOGS4 become significantly better than several other methods. For example, in the ×3 reconstruction results, the PSNR values of RED-HOGS4 are higher than those of RED-OGSTV by about 0.02 dB~0.08 dB. Further, in the ×4 reconstruction results, the deference is expanded to 0.02 dB~0.23 dB. Meanwhile, the SSIM values of RED-HOGS4 are also higher than those of other methods. However, as the RED-HOGS4 method is relatively complex, it takes the longest time compared to all other methods.
The following is a comparison of visual effects on three images: Street, Station, and Gate after 4-fold down-sampling of the original image without any noise using the five methods. The LR images are shown in Figure 2, in which the rectangles are compared with the SRR effects of the five methods in Figure 3, Figure 4 and Figure 5, respectively.

Figure 2.
LR infrared images that are down-sampled 4-fold without noise: (a) Street, (b) Station, (c) Gate; (d–f) enlarged details from the rectangles in (a–c), respectively.

Figure 3.
Super-resolution ×4 results of the LR Street images without noise. (a–c,g–i) are original image and the results of MFT, RED-TV, RED-TGV, RED-OGSTV, and RED-HOGS4 methods, respectively. (d–f,j–l) show the enlarged details from the rectangles in (a–c,g–i), respectively.

Figure 4.
Super-resolution ×4 results of the LR Station images without noise. (a–c,g–i) are original image and the results of MFT, RED-TV, RED-TGV, RED-OGSTV, and RED-HOGS4 methods, respectively. (d–f,j–l) show the enlarged details from the rectangles in (a–c,g–i), respectively.

Figure 5.
Super-resolution ×4 results of the LR Gate images without noise. (a–c,g–i) are original image and the results of MFT, RED-TV, RED-TGV, RED-OGSTV, and RED-HOGS4 methods, respectively. (d–f,j–l) show the enlarged details from the rectangles in (a–c,g–i), respectively.
As can be seen from Figure 3, Figure 4 and Figure 5, in the case no noise is introduced, after 4 times super-resolution processing, the effect of MFT processing is the worst among the images obtained by the five methods. The three images obtained by MFT have the phenomenon of unclear boundary and blur. In the visual comparison of images generated through RED-TV, RED-TGV, RED-OGSTV, and RED-HOGS4, we can see that RED-HOGS4 is better for boundary and overall processing of the image. Especially under 4 times magnification in Figure 5, the results of RED-HOGS4 method clearly show the outlines of letters and strokes, which are significantly better than the other methods.
4.3. Infrared Image Super-Resolution Experiment with Added White Gaussian Noise
In this experiment, the LR infrared images were generated by downsampling the original images by a factor of two after adding white Gaussian noise of different variance values (). To evaluate the performance variations based on the noise content for each method objectively, PSNR and SSIM were calculated at the ×2 super-resolving operator. These results are listed in Table 2.
Table 2.
Infrared image super-resolution ×2 experiment results with added white Gaussian noise.
The experimental results show that the MFT method has better PSNR in a few images, but worse PSNR mean values; the processing results of RED-TV and RED-TGV are better than that of the MFT, but worse than those of RED-OGSTV and RED-HOGS4. When the noise is small, the PSNR of the RED-OGSTV method is lower than that of the RED-HOGS4 and its SSIM value is higher than that of RED-HOGS4. With the increase in noise, the reconstruction results of the RED-OGSTV method are further lower than those of the RED-HOGS4 method. In terms of processing time, the RED-HOGS4 is relatively more time consuming compared to the other methods.
The visual effects comparison based on the Street, Station, and Gate images, which had added white Gaussian noise () and were downsampled by a factor of two, is shown as example in Figure 6, in which the rectangles are compared with the SRR effects of the five methods in Figure 7, Figure 8 and Figure 9, respectively.

Figure 6.
LR infrared images that are downsampled by a factor of two with added white Gaussian noise (): (a) Street, (b) Station, (c) Gate; (d–f) enlarged details from the rectangles in (a–c), respectively.

Figure 7.
Super-resolution ×2 results of the LR images of the Street with added white Gaussian noise (): (a–c,g–i) original image and the results of the MFT, RED-TV, RED-TGV, RED-OGSTV, and RED-HOGS4 methods, respectively; (d–f,j–l) enlarged details from the rectangles in (a–c,g–i), respectively.

Figure 8.
Super-resolution ×2 results of the LR images of the Station with added white Gaussian noise (): (a–c,g–i) ground truth and the results of the MFT, RED-TV, RED-TGV, RED-OGSTV, and RED-HOGS4 methods, respectively; (d–f,j–l) enlarged details from the rectangles in (a–c,g–i), respectively.
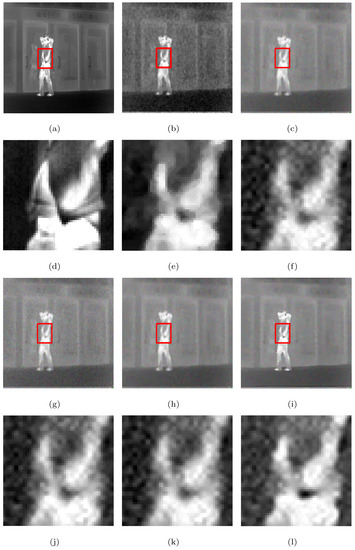
Figure 9.
Super-resolution ×2 results of the LR images of the Gate with added white Gaussian noise (): (a–c,g–i) ground truth and the results of the MFT, RED-TV, RED-TGV, RED-OGSTV, and RED-HOGS4 methods, respectively; (d–f,j–l) enlarged details from the rectangles in (a–c,g–i), respectively.
From Figure 7, Figure 8 and Figure 9, we see that the MFT has less noise in the reconstructed image, but the entire image is too smooth, resulting in serious loss of boundary information; RED-TV and RED-TGV reconstructed images have inadequate noise removal and information protection, whereas RED-OGSTV and RED-HOGS4 have better reconstructed images, as shown in Figure 7. In Figure 8 and Figure 9, the proposed method shows better results compared to RED-OGSTV for image edge reconstruction and noise effect.
5. Discussion
The HOGS4 method adopts quaternion TV and high-order OGSTV, which fully utilizes image correlations in quaternion and extends the first-order overlapping group sparsity to a higher-order such that a clear image can be reconstructed in the presence of noise interference. As to the OGSTV method, in the presence of noise, staircase artifacts are still present, and the noise removal is not as good as that of the HOGS4.
When the MFT method is used to reconstruct an image, regardless of the image being noiseless or noisy, the reconstruction result is very smooth, because of which the details are unclear.
The TV method preserves the edge and detail information of the image and smoothens the image piece by piece; hence, the result usually includes stair artifacts. The TGV method effectively reduces stair artifacts using first-order and second-order gradients during image processing. However, it also causes excessive smoothing and image distortion.
However, compared with other methods, this method is more time consuming because it introduces high-order OGSTV and quaternion, which have higher computational complexity. In the next study, we may use some accelerated iterative methods to improve the convergence speed of the algorithm, thus reducing the time consumption. As the methods in the literatures [26,69], the acceleration operator can be used to reduce the number of iterations of the ADMM algorithm, thereby reducing the time consuming of the super-resolution reconstruction algorithm. Besides, the proposed method may have other shortcomings. For example, the parameter optimization is mainly based on experience; because of the limited number of test infrared images, the parameters may not be fully applied to other sets of infrared images. For practical applications, the parameters are still necessary to optimize for the sets of infrared images. Alternatively, the adaptive mechanism of parameter optimization can be adopted in conjunction with this method.
6. Conclusions
In this paper, an infrared image super-resolution reconstruction method based on quaternion overlapping group sparse is proposed. This method produces improved image super-resolution reconstruction capability because it uses a combination of quaternion total variation and high-order group sparse methods. In addition, by introducing the RED framework, the super-resolution problem is transformed into multiple denoising sub-problems. When addressing these sub-problems, multiple difference operators are processed in convolution form. Using this method, according to the convolution theory, it can be converted to frequency domain operations, thereby avoiding large-scale matrix operations. Compared to MFT, TV, TGV, and OGSTV methods, the experimental results prove that the proposed method has better performance.
Although the proposed method only focuses on HOGS4, it can be easily extended to other regular models, such as TGV model, and combined with other methods, such as Lp quasinorm, to improve the performance of super-resolution reconstruction. Besides, in practical application, the method can be used for super-resolution reconstruction or denoising of grayscale images. We will continue to perform these extensions in our follow-up work.
Author Contributions
X.L. wrote this manuscript. Y.C., Z.P. and J.W. contributed to the writing, direction, and content, and revised the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (Nos. 61571096, 61775030), the Scientific and Technological Research Program of Chongqing Municipal Education Commission (Nos. KJ1729409, KJQN201903106), the Education and Scientific Research Foundation of Education Department of Fujian Province for Middle-aged and Young Teachers (Nos. JT180309, JT180310, JT180311), the Foundation of Fujian Province Great Teaching Reform (No. FBJG20180015).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhou, M.; Jing, M.; Liu, D.; Xia, Z.; Zou, Z.; Shi, Z. Multi-resolution networks for ship detection in infrared remote sensing images. Infrared Phys. Technol. 2018, 92, 183–189. [Google Scholar] [CrossRef]
- Zhang, T.; Wu, H.; Liu, Y.; Peng, L.; Yang, C.; Peng, Z. Infrared Small Target Detection Based on Non-Convex Optimization with Lp-Norm Constraint. Remote Sens. 2019, 11, 559. [Google Scholar] [CrossRef]
- Zhang, L.; Peng, Z. Infrared Small Target Detection Based on Partial Sum of the Tensor Nuclear Norm. Remote Sens. 2019, 11, 382. [Google Scholar] [CrossRef]
- Li, M.; Peng, L.; Chen, Y.; Huang, S.; Qin, F.; Peng, Z. Mask Sparse Representation Based on Semantic Features for Thermal Infrared Target Tracking. Remote Sens. 2019, 11, 1967. [Google Scholar] [CrossRef]
- Rasti, P.; Uiboupin, T.; Escalera, S.; Anbarjafari, G. Convolutional neural network super resolution for face recognition in surveillance monitoring. In International Conference on Articulated Motion and Deformable Objects; Springer: Cham, Switzerland, 2016; pp. 175–184. [Google Scholar]
- Li, Z.; Peng, Q.; Bhanu, B.; Zhang, Q.; He, H. Super resolution for astronomical observations. Astrophys. Space Sci. 2018, 363, 92. [Google Scholar] [CrossRef]
- Shi, W.; Caballero, J.; Ledig, C.; Zhuang, X.; Bai, W.; Bhatia, K.; de Marvao, A.M.S.M.; Dawes, T.; O’Regan, D.; Rueckert, D. Cardiac image super-resolution with global correspondence using multi-atlas patchmatch. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2013; pp. 9–16. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 391–407. [Google Scholar]
- Xu, W.; Chen, R.; Huang, B.; Zhang, X.; Liu, C. Single Image Super-Resolution Based on Global Dense Feature Fusion Convolutional Network. Sensors 2019, 19, 316. [Google Scholar] [CrossRef]
- Du, X.; Qu, X.; He, Y.; Guo, D. Single image super-resolution based on multi-scale competitive convolutional neural network. Sensors 2018, 18, 789. [Google Scholar] [CrossRef]
- Chi, J.; Zhang, Y.; Yu, X.; Wang, Y.; Wu, C. Computed Tomography (CT) Image Quality Enhancement via a Uniform Framework Integrating Noise Estimation and Super-Resolution Networks. Sensors 2019, 19, 3348. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, P.; Zhang, C.; Jiang, Z. A Comparable Study of CNN-Based Single Image Super-Resolution for Space-Based Imaging Sensors. Sensors 2019, 19, 3234. [Google Scholar] [CrossRef]
- Xiao, A.; Wang, Z.; Wang, L.; Ren, Y. Super-resolution for “Jilin-1” satellite video imagery via a convolutional network. Sensors 2018, 18, 1194. [Google Scholar] [CrossRef]
- Liu, F.; Han, P.; Wang, Y.; Li, X.; Bai, L.; Shao, X. Super resolution reconstruction of infrared images based on classified dictionary learning. Infrared Phys. Technol. 2018, 90, 146–155. [Google Scholar] [CrossRef]
- He, Z.; Tang, S.; Yang, J.; Cao, Y.; Yang, M.Y.; Cao, Y. Cascaded Deep Networks with Multiple Receptive Fields for Infrared Image Super-Resolution. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 2310–2322. [Google Scholar] [CrossRef]
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithms. Phys. D Nonlinear Phenom. 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Lysaker, M.; Lundervold, A.; Tai, X.C. Noise removal using fourth-order partial differential equation with applications to medical magnetic resonance images in space and time. IEEE Trans. Image Process. 2003, 12, 1579–1590. [Google Scholar] [CrossRef] [PubMed]
- Chan, T.F.; Esedoglu, S.; Park, F. A fourth order dual method for staircase reduction in texture extraction and image restoration problems. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 4137–4140. [Google Scholar]
- Bredies, K.; Kunisch, K.; Pock, T. Total generalized variation. SIAM J. Imaging Sci. 2010, 3, 492–526. [Google Scholar] [CrossRef]
- Ren, Z.; He, C.; Zhang, Q. Fractional order total variation regularization for image super-resolution. Signal Process. 2013, 93, 2408–2421. [Google Scholar] [CrossRef]
- Zhang, J.; Wei, Z. A class of fractional-order multi-scale variational models and alternating projection algorithm for image denoising. Appl. Math. Model. 2011, 35, 2516–2528. [Google Scholar]
- Chen, G.; Zhang, J.; Li, D. Fractional-order total variation combined with sparsifying transforms for compressive sensing sparse image reconstruction. J. Vis. Commun. Image Represent. 2016, 38, 407–422. [Google Scholar] [CrossRef]
- Wang, C.; Wang, X.; Li, Y.; Xia, Z.; Zhang, C. Quaternion polar harmonic Fourier moments for color images. Inf. Sci. 2018, 450, 141–156. [Google Scholar] [CrossRef]
- Wang, C.; Wang, X.; Xia, Z.; Zhang, C. Ternary radial harmonic Fourier moments based robust stereo image zero-watermarking algorithm. Inf. Sci. 2019, 470, 109–120. [Google Scholar] [CrossRef]
- Liu, X.; Chen, Y.; Peng, Z.; Wu, J.; Wang, Z. Infrared image super-resolution reconstruction based on quaternion fractional order total variation with Lp quasinorm. Appl. Sci. 2018, 8, 1864. [Google Scholar] [CrossRef]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Wright, J.; Huang, T.; Ma, Y. Image super-resolution as sparse representation of raw image patches. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Zhao, J.; Hu, H.; Cao, F. Image super-resolution via adaptive sparse representation. Knowl.-Based Syst. 2017, 124, 23–33. [Google Scholar] [CrossRef]
- Xu, M.; Yang, Y.; Sun, Q.; Wu, X. Image super-resolution reconstruction based on adaptive sparse representation. Concurr. Comput. Pract. Exp. 2018, 30, e4968. [Google Scholar] [CrossRef]
- Wang, H.; Gao, X.; Zhang, K.; Li, J. Fast single image super-resolution using sparse Gaussian process regression. Signal Process. 2017, 134, 52–62. [Google Scholar] [CrossRef]
- Tang, Y.; Gong, W.; Yi, Q.; Li, W. Combining sparse coding with structured output regression machine for single image super-resolution. Inf. Sci. 2018, 430, 577–598. [Google Scholar] [CrossRef]
- Mandal, S.; Bhavsar, A.; Sao, A.K. Noise adaptive super-resolution from single image via non-local mean and sparse representation. Signal Process. 2017, 132, 134–149. [Google Scholar] [CrossRef]
- Jiang, C.; Zhang, Q.; Fan, R.; Hu, Z. Super-resolution ct image reconstruction based on dictionary learning and sparse representation. Sci. Rep. 2018, 8, 8799. [Google Scholar] [CrossRef]
- Alvarez-Ramos, V.; Ponomaryov, V.; Reyes-Reyes, R. Image super-resolution via two coupled dictionaries and sparse representation. Multimed. Tools Appl. 2018, 77, 13487–13511. [Google Scholar] [CrossRef]
- Chen, P.Y.; Selesnick, I.W. Group-sparse signal denoising: Non-convex regularization, convex optimization. IEEE Trans. Signal Process. 2014, 62, 3464–3478. [Google Scholar] [CrossRef]
- Selesnick, I.; Farshchian, M. Sparse signal approximation via nonseparable regularization. IEEE Trans. Signal Process. 2017, 65, 2561–2575. [Google Scholar] [CrossRef]
- Liu, J.; Huang, T.Z.; Liu, G.; Wang, S.; Lv, X.G. Total variation with overlapping group sparsity for speckle noise reduction. Neurocomputing 2016, 216, 502–513. [Google Scholar] [CrossRef]
- Liu, G.; Huang, T.Z.; Liu, J.; Lv, X.G. Total variation with overlapping group sparsity for image deblurring under impulse noise. PLoS ONE 2015, 10, e0122562. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Peng, Z.; Li, M.; Yu, F.; Lin, F. Seismic signal denoising using total generalized variation with overlapping group sparsity in the accelerated ADMM framework. J. Geophys. Eng. 2019, 16, 30–51. [Google Scholar] [CrossRef]
- Liu, X.; Chen, Y.; Peng, Z.; Wu, J. Total variation with overlapping group sparsity and Lp quasinorm for infrared image deblurring under salt-and-pepper noise. J. Electron. Imaging 2019, 28, 043031. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, D.; Guo, X. Authentication and recovery of images using standard deviation. J. Electron. Imaging 2013, 22, 033012. [Google Scholar] [CrossRef]
- Xia, Z.; Wang, X.; Wang, C.; Zhang, C. Subpixel-Based Accurate and Fast Dynamic Tumor Image Recognition. J. Med. Imaging Health Inform. 2018, 8, 925–931. [Google Scholar] [CrossRef]
- Wang, X.-Y.; Zhang, J.-M. A novel image authentication and recovery algorithm based on chaos and Hamming code. Acta Phys. Sin. 2014, 63, 020701. [Google Scholar]
- Wang, X.-Y.; Zhang, J.-M. A novel image authentica-tion and recovery algorithm based on dither and chaos. Acta Phys. Sin. 2014, 63, 210701. [Google Scholar]
- Ding, L.; Zhang, H.; Xiao, J.; Li, B.; Lu, S.; Norouzifard, M. An improved image mixed noise removal algorithm based on super-resolution algorithm and CNN. Neural Comput. Appl. 2019, 31, 325–336. [Google Scholar] [CrossRef]
- López-Rubio, E. Superresolution from a single noisy image by the median filter transform. SIAM J. Imaging Sci. 2016, 9, 82–115. [Google Scholar] [CrossRef]
- Zhang, X.; Li, C.; Meng, Q.; Liu, S.; Zhang, Y.; Wang, J. Infrared image super resolution by combining compressive sensing and deep learning. Sensors 2018, 18, 2587. [Google Scholar] [CrossRef] [PubMed]
- Tirer, T.; Giryes, R. Super-resolution via image-adapted denoising CNNs: Incorporating external and internal learning. IEEE Signal Process. Lett. 2019, 26, 1080–1084. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends® Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Venkatakrishnan, S.V.; Bouman, C.A.; Wohlberg, B. Plug-and-play priors for model based reconstruction. In Proceedings of the 2013 IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013; pp. 945–948. [Google Scholar]
- Brifman, A.; Romano, Y.; Elad, M. Turning a denoiser into a super-resolver using plug and play priors. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1404–1408. [Google Scholar]
- Chan, S.H.; Wang, X.; Elgendy, O.A. Plug-and-play ADMM for image restoration: Fixed-point convergence and applications. IEEE Trans. Comput. Imaging 2016, 3, 84–98. [Google Scholar] [CrossRef]
- Ljubenović, M.; Figueiredo, M.A. Plug-and-play approach to class-adapted blind image deblurring. Int. J. Doc. Anal. Recognit. (IJDAR) 2019, 22, 79–97. [Google Scholar] [CrossRef]
- Shi, B.; Lian, Q.; Fan, X. PPR: Plug-and-play regularization model for solving nonlinear imaging inverse problems. Signal Process. 2019, 162, 83–96. [Google Scholar] [CrossRef]
- Romano, Y.; Elad, M.; Milanfar, P. The little engine that could: Regularization by denoising (RED). SIAM J. Imaging Sci. 2017, 10, 1804–1844. [Google Scholar] [CrossRef]
- Reehorst, E.T.; Schniter, P. Regularization by denoising: Clarifications and new interpretations. IEEE Trans. Comput. Imaging 2018, 5, 52–67. [Google Scholar] [CrossRef]
- Brifman, A.; Romano, Y.; Elad, M. Unified Single-Image and Video Super-Resolution via Denoising Algorithms. IEEE Trans. Image Process. 2019, 28, 6063–6076. [Google Scholar] [CrossRef]
- Hong, T.; Romano, Y.; Elad, M. Acceleration of RED via vector extrapolation. J. Vis. Commun. Image Represent. 2019, 63, 102575. [Google Scholar] [CrossRef]
- Tirer, T.; Giryes, R. Image restoration by iterative denoising and backward projections. IEEE Trans. Image Process. 2018, 28, 1220–1234. [Google Scholar] [CrossRef] [PubMed]
- Shi, M.; Feng, L. Plug-and-play prior based on Gaussian mixture model learning for image restoration in sensor network. IEEE Access 2018, 6, 78113–78122. [Google Scholar] [CrossRef]
- He, T.; Sun, Y.; Chen, B.; Qi, J.; Liu, W.; Hu, J. Plug-and-play inertial forward–backward algorithm for Poisson image deconvolution. J. Electron. Imaging 2019, 28, 043020. [Google Scholar] [CrossRef]
- Sun, Y.; Babu, P.; Palomar, D.P. Majorization-minimization algorithms in signal processing, communications, and machine learning. IEEE Trans. Signal Process. 2016, 65, 794–816. [Google Scholar] [CrossRef]
- Oppenheim, A.V.; Willsky, A.S.; Nawab, S.H. Signals and Systems; Prentice-Hall: Englewood Cliffs, NJ, USA, 1983; Volume 2, p. 10. [Google Scholar]
- Berg, A.; Ahlberg, J.; Felsberg, M. The LTIR Dataset. Available online: http://www.cvl.isy.liu.se/research/datasets/ltir/version1.0/ (accessed on 23 November 2019).
- Project, D.G. IRData. Available online: http://www.dgp.toronto.edu/~nmorris/data/IRData/ (accessed on 23 November 2019).
- Kahaki, S.M.; Arshad, H.; Nordin, M.J.; Ismail, W. Geometric feature descriptor and dissimilarity-based registration of remotely sensed imagery. PLoS ONE 2018, 13, e0200676. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Huang, B.; Ma, S.; Goldfarb, D. Accelerated linearized Bregman method. J. Sci. Comput. 2013, 54, 428–453. [Google Scholar] [CrossRef]









© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).