1. Introduction
Over the past few years, the focus of several research entities as well as many industrial companies on building fully autonomous vehicles has increased drastically. One of the main aspects of building such vehicles is the localization problem, i.e., how the vehicle can determine its position relative to its environment. To address this aspect, the use of highly accurate sensors is needed such as LiDARs or differential global positioning systems. However, the use of such sensors can be very costly. Another solution is to use different sensors of lower accuracy and then apply a sensor fusion technique to the readings of all sensors in order to get a better estimate of the vehicle’s pose (position and orientation) using multiple low cost sensors [
1,
2,
3,
4,
5,
6].
Multisensor fusion localization can be divided into two techniques; filtering techniques, and smoothing techniques. Filtering techniques are probabilistic techniques which stem from the Bayesian estimation theory [
7] and can be divided into two major directions. On one hand, there are the Gaussian filters family, and among them are the nonlinear Kalman filters such as the Extended Kalman Filter (EKF) [
8], Unscented Kalman Filter (UKF) [
9] and Ensemble Kalman Filter (EnKF) [
10] as well as the Extended Information Filter (EIF) and the Iterative Sparse Extended Information Filter (ESIF) [
11]. On the other hand, there are the nonparametric family and on top of them is the particle filter (PF) and its different versions [
12].
As for smoothing techniques, these are optimization-based techniques which emerges from the need to maximize the posterior probability distribution of the vehicles pose. In other words, smoothing techniques is a Maximum a Posteriori (MAP) estimation method which comes in the form of minimizing the negative log-posterior of the vehicle pose distribution as discussed in [
13]. Among such techniques are the Moving Horizon Estimation [
14] as well as the factor graph method which is widely used in Simultaneous Localization and Mapping algorithms such as [
15,
16].
In both cases, to be able to accurately estimate the vehicle pose, the amount of noise in each of the sensors needs to be known. In almost all the cases mentioned above, the amount of noise is quantified using the covariance matrix. Either in its direct form as in the Kalman filter, as the importance factor in the particle filter as mentioned in [
7], or as the information matrix in case of the information filter or the smoothing techniques.
Unfortunately, the determination of such covariance matrices is not straightforward and in most cases infeasible. To determine the covariance matrix of a sensor, the ground truth needs to be available which is generally very difficult and costly to be acquired. Furthermore, even if the ground truth is available, the localization of a vehicle in most cases depends on odometries (wheel odometry, visual odometry, inertial odometry, and so on). Such odometries relies on integration to provide the localization measurement and therefore, tend to suffer from accumulation of error. This accumulation of error has a random nature and its amount depends on the environmental conditions as well as the nature of the sensor. This in turn results in the increase of the covariance values during operation [
17,
18].
In this paper, we propose an online algorithm for estimating the covariance of such odometries using another on-board sensor which does not suffer from drift and with known covariance. Such a sensor only suffers from random noise and is immune to accumulation of error since it does not rely on integration.
The proposed algorithm updates the drift covariance estimate with each new sensor measurement. The fact that the proposed DCE algorithm is online facilitate the estimation of the changing covariance of the odometries instantaneously during the operation of the autonomous vehicle. This makes the use of such algorithm convenient since no pre-tuning of the covariances is required.
This paper extends on the authors’ published work in [
19]. In [
19], the authors introduced the drift error model for wheel encoders and showed the feasibility of using an exteroceptive sensor to determine the covariance of a proprioceptive sensor such as wheel encoders. In this paper, the authors generalize the methodology and the ideas adopted in [
19] to any odometry regardless of the type of sensor being used. The drift error model for any arbitrary odometry and the drift covariance formula are more rigorously derived. Furthermore, the estimation methodology introduced in [
19] is generalized and more formally presented as the DCE algorithm. The generalized estimation methodology can work with any localization or SLAM techniques irrespective of its theory of action. To validate the derived error model and the proposed algorithm, a comparative study is conducted using multiple real-world experiments in different conditions as well as sequences from Oxford RobotCar Dataset [
20]. To further show the benefit of using the DCE algorithm alongside with popular open source odometry algorithms, we use the open source EU long-term dataset [
21] along with the LiDAR Odometry and Mapping algorithm (LOAM) [
22]. We report the results of the DCE-UKF compared with the results of LOAM algorithm.
This paper’s main contributions are the following:
The mathematical modeling of the random accumulation of error in the different odometries used in autonomous vehicle localization.
A general online algorithmic methodology for estimating the covariance of such drift suffering odometries using another sensor which is drift-free. This methodology is generic and suits any kind of odometry as well as any localization or SLAM algorithm either being filtering-based or smoothing-based.
The detailed implementation of an algorithm which follows this algorithmic methodology, the algorithm is available online for the benefit of the community.
To the authors knowledge, there is no previous work in the literature which addresses the problem of the covariance estimation of drift suffering odometries. Although several previous works attempt to reduce the drift in such odometries (as mentioned in
Section 2), they still always suffer from drift due to their reliance on integration. The proposed work can be integrated with such drift reduction methods in order to estimate the covariance and consequently, increase the accuracy of the localization module.
To show the benefit of integrating the DCE algorithm with odometries which suffer from drift, we use the LOAM algorithm alongside with the DCE-UKF and show the effect of using the DCE algorithm on the accuracy of the pose estimation compared to only relying on the LOAM algorithm for localization.
The remainder of the paper is organized as follows;
Section 2 reviews the related work followed by the drift error modeling in
Section 3.
Section 4 describes the proposed algorithm as well as some implementation details. Then, in
Section 5 the experimental setup, the localization algorithms, selected scenarios including the Oxford RobotCar Dataset and EU long-term dataset sequences as well as
the evaluation metrics used for validating the algorithm are introduced.
Section 6 shows the experimental results and the discussion and finally in
Section 7 the conclusion is summarized.
2. Related Work
Ever since Rudolf Kalman proposed the Kalman filter in 1960 [
23] and the continuous Kalman and Bucy filter in 1961 [
24], the search for the covariances of the sensors being used in the filtering started [
25]. Quantifying the noise covariance for a sensor in a multisensor fusion scheme has been the subject of several works in the literature. The difficulty in quantifying such covariances resulted in the emergence of adaptive filtering techniques [
26,
27].
In [
28], a combination of a fuzzy logic controller and a conventional Kalman filter for an INS/GPS is proposed for the correction of both the process noise covariance and the measurement noise covariance. The algorithm was validated using a simulation with an EKF, UKF and an Iterated EKF. However, in using such algorithm, the design of the membership function for each sensor to estimate the covariance might be challenging. Especially since each sensor differs in nature and can suffer from errors in a different way. Furthermore, in case of odometries, the behavior of drift is unpredictable and designing a membership function to describe it is impractical.
Other works use adaptive Kalman filters to estimate the covariance matrices [
29]. In [
30], a Kalman filter with recursive estimation has been presented; to estimate the noise covariance matrix from the measurement sequence of linear time-invariant systems. Additionally, in [
31], a stability analysis has been performed to verify the estimator’s stability. However, this work was introduced to linear systems and assuming that the sensors are not suffering from drift.
Beside the adaptive filtering approach which deals with the covariance of a Gaussian white noises, the fact that some sensors suffers from systematic drift errors due to aging and mis-calibration was also studied. In [
32], a blind calibration algorithm is proposed to calibrate the sensor drift using signal space projection and Kalman filtering. However, in such case, the drift being addressed is the systematic drift which can be eliminated through calibration. Also, in [
33], a deep learning approach is proposed to address the same issue.
In [
34,
35], a method based on Bayesian Maximum Entropy and Interacting Multiple Model is proposed to detect and correct the drift in sensors used in Internet of things (IoT) technologies. However, still in this case the drift error being addressed is the systematic drift of the sensors over time due to temperature conditions, vibrations and aging which can be calibrated and eliminated.
In [
36,
37], an online method to quantify and eliminate the random drift error in a Fiber optic gyro (FOG) is proposed through adaptive Kalman filtering. Such works only addresses the random drift noise in FOG and not in general odometries or general sensors suffering from random drift.
Most of the literature deals with drift as a systematic error which occurs due to the loss of calibration, temperature conditions, aging of the sensors or other environmental conditions. In such cases, this kind of error can be eliminated through calibration or compensation [
38,
39,
40].
However, an odometry uses a sensor in which its measurements is being integrated over time to obtain the vehicle’s pose measurements. For example, dead-reckoning (wheel odometry) is done using a wheel encoder by integrating the output of the encoder through the kinematic model to get the pose of the vehicle. In such cases, the errors in the encoders are accumulated in the calculated pose. Another example can be a visual odometry algorithm which integrates the incremental motion of the vehicle between frames to calculate the overall pose of the vehicle.
There are several works in the literature which deals with drift in odometry. However, in these works, the methodology adopted by the authors was mainly based on reducing the error in the odometries. In [
41], a visual odometry algorithm which uses a newly developed feature descriptor is introduced to reduce the drift in such visual odometry. Similarly, in [
42], a convolutional neural network was used to infer the sun direction which in turn is used to reduce the drift error in the visual odometry.
In [
43], a fusion scheme of monocular vision and radio-based ranging is introduced to reduce the drift error in a SLAM algorithm. In [
44], a learning approach was used to solve for the drift of a LiDAR-only motion estimation. In all these works, dealing with drift was through trying to reduce it; however, drift cannot be completely eliminated, and it would be significantly useful to quantify the amount of drift in a given odometry during operation.
As already mentioned, such odometries uses sensors which suffers from various types of errors due to ground conditions (slippage), temperature changes, driving behavior or lighting conditions. As a results of integration, the error in the pose calculation will accumulate while the vehicle is operating. Furthermore, due to the change of operational conditions, the drift itself cannot be predicted and the rate at which error accumulates in the measurements of an odometry will change with time.
3. Drift Modeling in Odometries
A good start to model the drift in an odometry is through a proper definition of an odometry as well as drift error in odometry as seen throughout this paper.
Definition (Odometry): Odometry is measuring a vehicle’s pose
or a subset of it
through integrating the readings of a sensor after mapping it to the state (output) space,
where
is the binary output matrix and for
, the odometry measures the overall state vector
,
is the raw measurement of the sensor used in the odometry,
is the odometry mapping (maps the sensor measurements to the odometry output increments), and
is the timestep where
and
is the sampling time and
is the time in seconds.
Notice that an odometry measures the position of a vehicle or a robot, consequently, the state vector can be defined as
where
x,
y and
z are the three Cartesian coordinates of the vehicle and
and
are pitch, roll and yaw angles of the vehicle, respectively. Some odometries also provide the accelerations or the velocities, in such cases, these states can also be added to the state vector.
Definition (Drift Error): The drift error
is the unbounded accumulation of error in the odometry measurements due to the integration of the noisy readings, where for the drift error, the following is true.
Now consider the raw measurement of a sensor
used in an odometry, where the readings of the sensor is related to the states of the vehicle through the sensor model mapping
.
Equation (
4) can be written more precisely as a function of the observable states by the sensor
as follows,
since the measurements of the sensor is only a function of the related states which in this case is the
output vector.
Consequently, the ideal odometry equation will be
Although the sensor measurement is a function of the output vector , this is an implicit representation and the only way to measure the actual output vector is through the odometry.
In reality, the readings of the sensors
suffers from noises which can be represented as
where
is the noisy readings of the sensors and
is a random variable representing the additive noise on the sensors.
Using Equation (
7) in (
6), the noisy odometry output can be written as follows:
Using the Taylor expansion assuming that
is a
smooth function, Equation (
8) can be expanded as follows:
where
are the Jacobian matrix and the Hessian matrix and so on.
Equation (
9) can also be rewritten as follows:
where
is the random drift error in the odometry. The reason that the drift is random is the fact that it depends on the random noise in the sensor measurement
.
Now assume a change
occurred in the pose of the vehicle over a one timestep. Once again, through using the Taylor expansion, the drift error can then be written as follows:
and the increment of the random drift error
can be written as:
where
and
are the so-called drift coefficient matrices and are random matrices which depend on the sensor random noise
. This in turn makes
and
random variables.
Assumption: Since normally the sampling time
T is small,
is small and the higher order terms can be neglected.
Furthermore, we assume that the drift in each of the output states is independent from other states, in other words,
Using Equation (
13) in (
11), the drift error at timestep
k can then be written as:
The covariance of the drift increment
can then be derived through the definition of covariance as follows:
where
is the mean (first moment) of the drift increment and
is the mean of the drift coefficient.
Assumption: The drift increment is a small value due to the small timestep and therefore the square of its mean
is also small and can be neglected. Therefore, the drift covariance
can be written as follows:
where
is the drift coefficient covariance matrix.
Using Equation (
13), the drift covariance matrix
can be calculated as
Using the drift model stated in Equation (
17), the drift covariance matrix
can be estimated using a sensor which does not suffer from drift as will be shown in the following section.
4. Drift Covariance Estimation
Using the model developed in the previous section, the drift covariance can be estimated using a sensor which does not suffer from drift. Throughout the rest of the paper, we call a sensor not suffering from sensor a drift-less sensor.
A good example for a drift-less sensor is a GPS which does not rely on integration for measuring the pose of the vehicle. On the other hand, an odometry can be an encoders odometry or a visual odometry. Other examples of drift-less sensors could be a camera for detecting landmarks or apriltags, a magnetometer, and so on.
4.1. Drift Covariance Estimation Algorithm
To avoid ambiguity, from now on, a measurement from an odometry will be denoted and a drift-less sensor measurement will be denoted .
Now consider a drift-less sensor measurement
with a known covariance
. The true output of the vehicle
most likely lies in the confidence ellipse of the measurement defined by the eigenvalues of
. Since the true output
is not available. We resort to sampling the measurement distribution
deterministically.
where
, and
q is the number of samples taken from the drift-less measurement distribution, and
is the
ith sample in
and
.
Using the samples in
, the innovation between the odometry output and the samples are calculated as follows:
where
is called the innovation matrix, and
is the innovation (error) function which can be defined simply as
in case of Cartesian states (position, linear velocity and linear acceleration), but needs more elaborate design in case of orientations to manage to calculate the innovation over the rotation manifold taking into account representation singularities. For more information, see [
45,
46].
The innovation values are stored in the so-called innovation memory tensor
which stores the last
innovation matrices as shown in Equation (
21). Here, we call
, the
measurement horizon. The choice of the measurement horizon
is a design parameter and would be a trade-off between accuracy of the covariance estimation and the computational cost.
where
is the matrix containing the
previous innovations calculated for a given track of sample points.
As mentioned before, a drift-less sensor does not suffer from error accumulation, but only from random error. Now let us recall the drift model in the previous section.
The drift coefficient represent the increase in the drift in the output of the odometry with respect to the change in the output states . Therefore, using a drift-less sensor, the change in the states due to drift can be captured by estimating the .
After we stored the innovation points for sample points, which encodes the deviation between the odometry and the drift-less sensor. The slope of these values is an estimate of since the normal progression of the output states is captured by both sensors but only the drift suffering sensor has the drift component .
In other words, using the innovation memory tensor
, the drift coefficient
can be estimated for each track of the sample points, by computing the first order polynomial fit of the innovation data using a linear least squares approach as shown in the following equation.
where
is the time vector for the last
instances,
is the estimated drift coefficient matrix computed for
and
is a vector containing the diagonal values of the drift coefficient matrix,
is an all ones vector, and
is the intercept which is of no use here. Equation (
23) is calculated for each sub-matrix
and
q estimates of
are calculated.
Using these estimates, the drift increment covariance
can be also estimated using Equation (
16) as
Consequently, the drift covariance matrix can be calculated as
where
is a diagonal matrix of weights. Notice that in Equation (
26), since the true output state increment
is not available, and assuming a fast sampling time, the increment from the odometry is used instead. To compensate for such change in the equation, the design parameter
is added to the algorithm. The covariance estimation algorithm is stated in Algorithm 1.
| Algorithm 1: Drift Covariance Estimation Algorithm. |
![Sensors 19 05178 i001]() |
4.2. Algorithm Implementation
A generic implementation of the covariance estimation algorithm was developed and available as online open source repository in [
47]. This implementation uses the unscented transform introduced in [
48,
49]. Normally, the unscented transform is used in the unscented Kalman filter; however, it also fits for the proposed covariance estimation algorithm for sampling the drift-less measurement distribution.
Sampling a drift-less measurement distribution using the unscented transform is as follows.
where
is the sampling parameter in the unscented transform.
The
parameter is normally calculated as
where lambda is a design parameter in the unscented transform (for more information see [
49]). This calculation method can be used for sampling the measurement distribution. However, to show that the algorithm is independent of the sampling approach, here we make the
itself a design parameter which can be set by the user without the need to specify
first
Remark: The choice of the parameter should be dependent on the accuracy of the drift-less sensor covariance. More specifically, if the drift-less sensor covariance reflects under-confidence in the sensor, then the true pose is more likely to be in the confidence ellipse and consequently, should be less than 1. However, if the covariance reflects over-confidence in the sensor, then should be greater than 1.
Also, similar to the unscented Kalman filter, rather than calculating the normal mean for the drift coefficients, we calculate a weighted mean. The weights calculations and the covariance calculation are described in the following equations.
where
is the weight for a given sampled measurement.
Remark: The choice of the weights stated in Equation (29) is a design choice. The calculation of the weights is different than that of the unscented transform. Here, we chose to give a higher weight to the sensor measurement while giving equal weights to all other samples. Again, this is a design parameter which can be changed or even completely removed from the algorithm implementation.
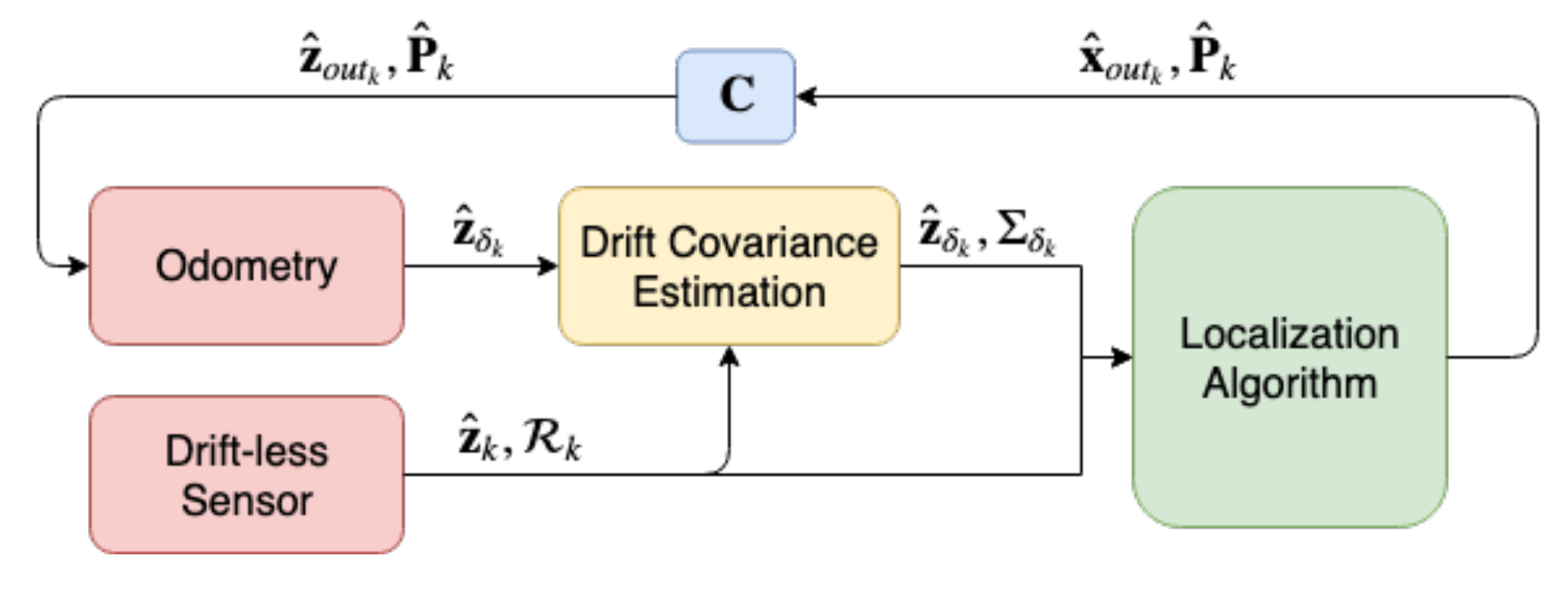
Notice that the proposed algorithm only estimates the covariance of the odometry output
but does not correct such drift. The correction can be done through using the output of the localization algorithm
as shown in the following equations and illustrated in
Figure 1.
Through using the drift covariance estimation, over time the covariance of the odometry will be more accurately quantified taking the odometry drift into consideration. This odometry with its estimated covariance is then provided to the localization algorithm which will help conserve an accurate localization output which in turn will be fed to the odometry to correct the drift.
Time and Memory Complexity
In this subsection, the time and memory complexity of the algorithm described in the last subsection are presented. As can be seen in Algorithm 1, the most computationally expensive operation is the sampling of the measurement distribution due to the matrix square root operation. The matrix square root is typically performed using Cholesky decomposition and in general the time complexity would be O(
) [
50]. Although this is normally computationally expensive, in this case, the worst-case scenario covariance matrix would be a
matrix which still considered a simple operation due to the powerful processors available presently. Furthermore, if the noise in the sensor readings is uncorrelated (for different states), the covariance matrix reduces to a diagonal matrix and the matrix square root reduces to a set of normal square root operations which is a constant time operation. Consequently, ignoring the matrix square root, several steps of the algorithm iterates over each sampled measurement making the algorithm complexity O(
q). Notice that the matrix inversion of
is only an inversion operation of a
matrix which is a constant time operation.
As for the memory complexity, this can be specified using the innovation memory tensor. In each iteration of the algorithm, the innovation memory tensor must store the m measured states for each of the q samples generated for each of the timesteps in the measurement horizon . This makes the memory complexity of the algorithm O().
5. Experimental Work
To validate the proposed algorithm, several scenarios were designed and tested over various experiments as well as Oxford RobotCar Dataset [
20].
Furthermore, to show the effect of the DCE algorithm on the localization results compared to open source odometries, we report the results of using an open source implementation of the LOAM algorithm along with the EU long-term dataset compared to that of using the same package alongside a DCE-UKF algorithm. This section describes the used platform for the real-world experiments, the testing environment, the designed scenarios, the multisensor fusion filters used in testing the algorithm, the selected evaluation metrics, and the sessions used for validation from the Oxford RobotCar Dataset
and EU long-term dataset.
5.1. Experimental Platform
The aforementioned approach was tested over an automated ground vehicle, which is a part of the Intelligent Campus Automobile (iCab) project [
51]. The vehicle is an electric golf cart, which is equipped with multiple on-board sensors, including LiDAR, stereo camera, optical encoders for wheel and steering, digital magnetometer and GPS module. Moreover, the vehicle is equipped with an embedded computer, which operates with Robot Operating System (ROS)-based architecture [
52]. This architecture enables the vehicle to perform self-localization, navigation, planning and environment perception, among others.
5.2. Scenarios
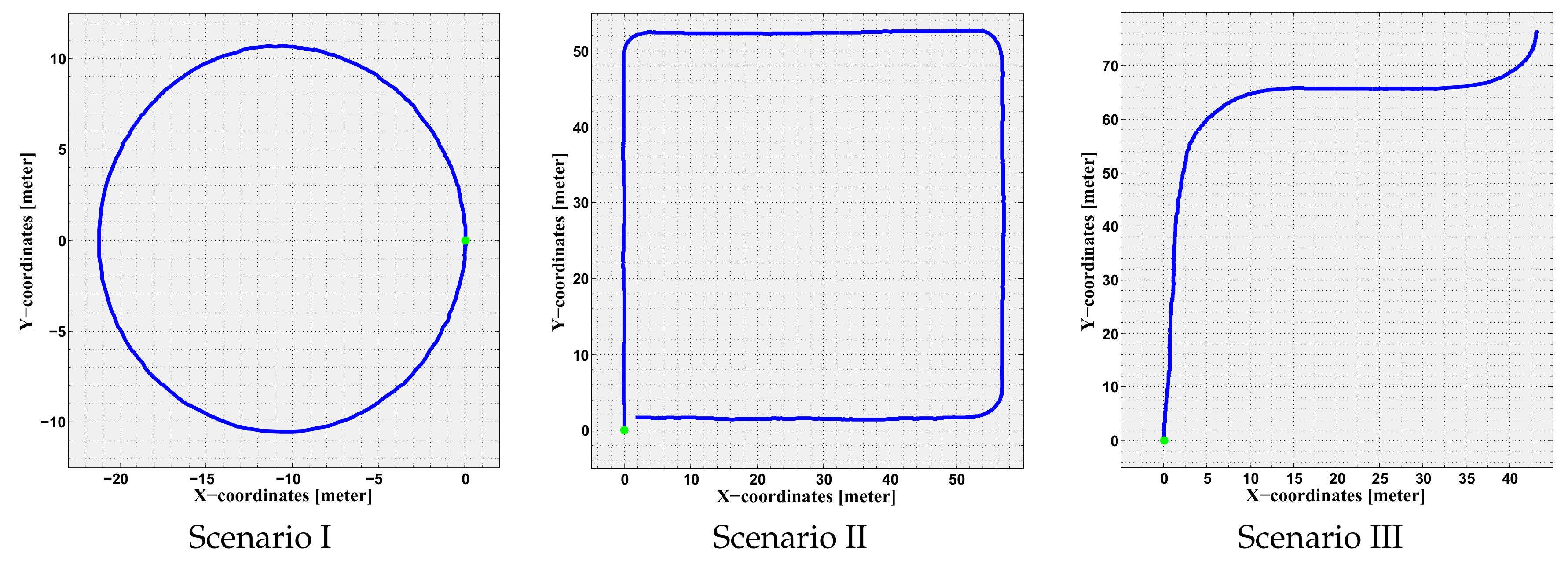
The testing environment was the off-road vicinity of the campus, which has free pedestrian areas and surrounded with many buildings. In this environment, three scenarios were designed to evaluate the proposed approach, and each scenario was experimented three times under different conditions. The scenarios are depicted in
Figure 2 and described in the following subsections.
5.2.1. Scenario I
The first scenario was designed as a circle of total diameter of 22 m, in which the iCab steering wheel was adjusted to 8.5 and average velocity of 5 kmph. In this case, the theoretical path was designed as a pure circle with the same diameter to be compared with the obtained odometries. The scenario was selected to evaluate the proposed approach performance in optimizing the localization in simple circular motion. Moreover, it is a closed loop, thus the vehicle end point is the same as the starting point.
5.2.2. Scenario II
The second scenario was designed as a quadratic shape of total length of 54 m and width of 56 m. This was also a closed shape, where the theoretical path was designed as a right-angled quadratic shape, thus the vehicle end point is the same as the starting point. The iCab followed the shape with average velocity of 5 kmph and rotating with sharp around the corners. The scenario was selected to evaluate the proposed approach performance in optimizing the localization in both straight-line and curved motions.
5.2.3. Scenario III
The third and last scenario was designed as a trajectory from one building to another in the campus. The selected points are part of the pick-up/drop-off points of the iCab project. The theoretical path was obtained from the path planner to be compared with the obtained odometries. The path consists of multiple curves, straight-lines, dynamic obstacles, and it is one of the normal trajectories that the iCab follows in its daily operation. The iCab followed the path with average velocity of 5 kmph and a maximum of 15 steering angle during curvatures.
For the iCab experiments, we chose to use the velodyne sensor along with the LOAM algorithm as a reference odometry since the ground truth was absent through the experiments. The reason for choosing the LOAM algorithm (which is also considered an odometry) is the fact that package accuracy over the KITTI Benchmark [
53] is in the second place in the list of the most accurate odometry algorithms, with values of
and 0.0014
/m for the
and
(defined in the evaluation metrics subsection) respectively. Furthermore, The iCab experiments were executed with low speeds which enhance the accuracy of the LOAM algorithm as can be seen in
Figure 2. Therefore, LOAM readings were considered to be the closest to ground truth in comparison with all other available sensors in the iCab, and accordingly it was set as the reference odometry through the experiments.
5.3. Oxford RobotCar Dataset
The Oxford RobotCar is a dataset for autonomous driving which was recorded through the period of May 2014 till December 2015 through traversing a fixed route through central Oxford using Oxford RobotCar platform which is an Autonomous Nissan LEAF [
20]. The autonomous vehicle used is equipped with 6 Cameras, a LiDAR, GPS and INS + GPS as the ground truth.
In this paper, several sessions were used from the dataset to verify the covariance estimation algorithm. In the dataset, the GPS data contains its covariance. Accordingly, a multisensor fusion algorithm can be used to fuse the GPS data with visual odometry data also provided by the dataset.
Given that the visual odometry algorithm suffers from drift, the covariance of the visual odometry is estimated using the proposed algorithm with the GPS covariance then the localization using both visual odometry and GPS measurements. Moreover, since these are pre-recorded data, no correction was made to the results of the odometry. These tests are useful to validate the covariance estimation even without correction of the odometry output and its covariance.
5.4. EU Long-Term Dataset
The EU long-term Dataset [
21] is a dataset for autonomous driving which contains the sensors data from multiple heterogeneous sensors. The data was collected using the UTBM car in human driving mode through driving the car in the downtown of Montpelier in France. For the long-term data, the driving distance was about 5.0 km per session which was driven over 16 min.
In this paper, we use the LiDAR data to validate the DCE algorithm. Since the GPS/RTK data from the dataset is the ground truth, we induced an artificial noise over its data and used it as a drift-less sensor for the covariance estimation. Furthermore, an open source implementation of the LOAM algorithm was used as a LiDAR odometry suffering from drift. Here, because the dataset was recorded with a relatively high speed (50 kmph), the results of the LOAM algorithm deteriorated very fast and showed a considerable amount of drift. Therefore, it was suitable for comparison with the DCE-UKF results.
5.5. Multisensor Fusion-Based Localization Algorithms
To evaluate the true potential of the proposed algorithm, the performance and results are compared relative to different values of constant covariances in a different multisensor fusion algorithms, and the
package was selected in order to do the fusion [
54]. The package contains two fusion algorithms: Extended Kalman Filter (EKF) and Unscented Kalman Filter (UKF). Also, a third filter was added by the author to the
which is the Extended H-infinity filter.
5.5.1. Extended Kalman Filter
The Extended Kalman Filter(EKF) is the direct extension of the most widely used filter for sensor noise filtering which is the Kalman filter algorithm [
23]. EKF uses the first order Taylor expansion to linearize the nonlinear system and propagate them using the error propagation theory. The EKF is a recursive algorithm which provides the optimal minimum mean-squared error (MMSE) state estimation assuming that the prior predictions and observations are both Gaussian random variables.
5.5.2. Unscented Kalman Filter
The Unscented Kalman Filter (UKF) is another nonlinear extension of the linear Kalman filter algorithm [
48,
49,
55]. However, in case of the UKF, the algorithm deals with the nonlinear system directly without the need for linearization which leads to increased accuracy of the state estimation. UKF uses the unscented transform to propagate the error through the nonlinear system directly but still in this case both the prior prediction and observation are assumed to be Gaussian random variables.
5.5.3. Extended H-Infinity Filter
The Extended H-infinity filter is another probabilistic filter which aims at minimizing a different objective than that of the Kalman filters [
56]. In EH-infinity, a game theory approach is used in which nature is considered the opponent of the filter and is trying to maximize the errors in the estimation. In other words, the EH-infinity assumes the worst-case scenario in which both the estimation and observation errors, are maximum [
57]. This worst-case scenario is modeled by the cost function which is then converted to a minimax problem and the EH-infinity solves this minimax problem.
In this paper, the three filters are used to show the efficacy and accuracy of the covariance estimation algorithm being proposed. The choice of using package was made to use an already verified and published fusion package, thus focusing on the effect of using different covariances under the same conditions.
5.6. Evaluation Metrics
The evaluation metrics for the sensor fusion algorithms were calculated for both translation and orientation. First, the mean and maximum error percentages of the translation; which are calculated as shown in Equations (33) and (34) respectively.
where
are the estimated coordinates of the vehicle and
are the true coordinates at time step
k.
As for the orientation, the mean and maximum error in the orientation are divided by the total distance covered by the vehicle, which are calculated as shown in Equations (35) and (36) respectively.
where
is the estimated orientation of the vehicle and
is the true orientation of the vehicle at time step
k.
6. Results and Discussion
Five different sensors were used in the iCab platform through experiments; the LiDAR as the reference odometry, GPS as a drift-less sensor, wheel encoders odometry and visual odometry [
58]. Additionally, compass orientation was included to the fusion algorithm. The covariance was estimated for the odometries (Encoders and Visual) using the available covariance of the drift-less sensor (GPS). For the covariance estimation algorithm, the encoder odometry measured the three planar states of the vehicle
while the visual odometry only estimated the planar position of the vehicle
.
As for Oxford RobotCar Dataset, the sessions used in this paper are a total of four days driving in the dataset which is about 7165 meters driving. However, in the case of the dataset, only the translation errors are calculated due to the absence of measurements of the orientation.
Furthermore, for the EU long-term dataset, a total of three sessions were used for the comparison, these are a total of 15,000 km of driving divided over three days in different weather conditions. Similar to Oxford RobotCar Dataset, only the translational ground truth data are available in the dataset (from the GPS/RTK), so here we only show the result of the fusion for the translation.
To show the efficacy of the Drift Covariance Estimation (DCE) algorithm, its localization results are compared to the results of different values of constant covariances. The values used are percentages of the True Variances (TV) of the odometries, which are calculated retroactively from the data of the experiments.
The constant values of covariances are selected depending on the error values for each experiment. As shown in the tables below, of the TV gave higher error than of the TV. Observing these results, smaller percentages of the TV were used in order to reach better accuracy. In addition, lower than of the TV were omitted, because they also provided less accurate results.
All the data from the different scenarios are fused using the three filters mentioned in
Section 5. It is worth mentioning that the results from each filter are taken separately as no direct comparison between the filters is intended in the paper. For example, the EH
filter contain a parameter called the performance bound which needs tuning and can significantly enhance the results of the filter; however, the enhancement of the filter results is out of scope since the main concern is to validate the efficacy of the DCE algorithm for different fusion algorithms using the same filter parameters for constant and adaptive covariances.
Also, notice that the correction step was used through the experiments of the iCab and the EU Long-term dataset. The covariance for the odometries based on the TV was calculated as follows:
where
is the covariance matrix containing the true variances for each of the output states.
6.1. Platform Experiments
In
Figure 3, one of the three experiments which were executed for Scenario I using the EKF is shown as well as the error plots for each of the covariance values and the GPS which was used to estimate the covariance of the odometries. Notice that for the TV and the
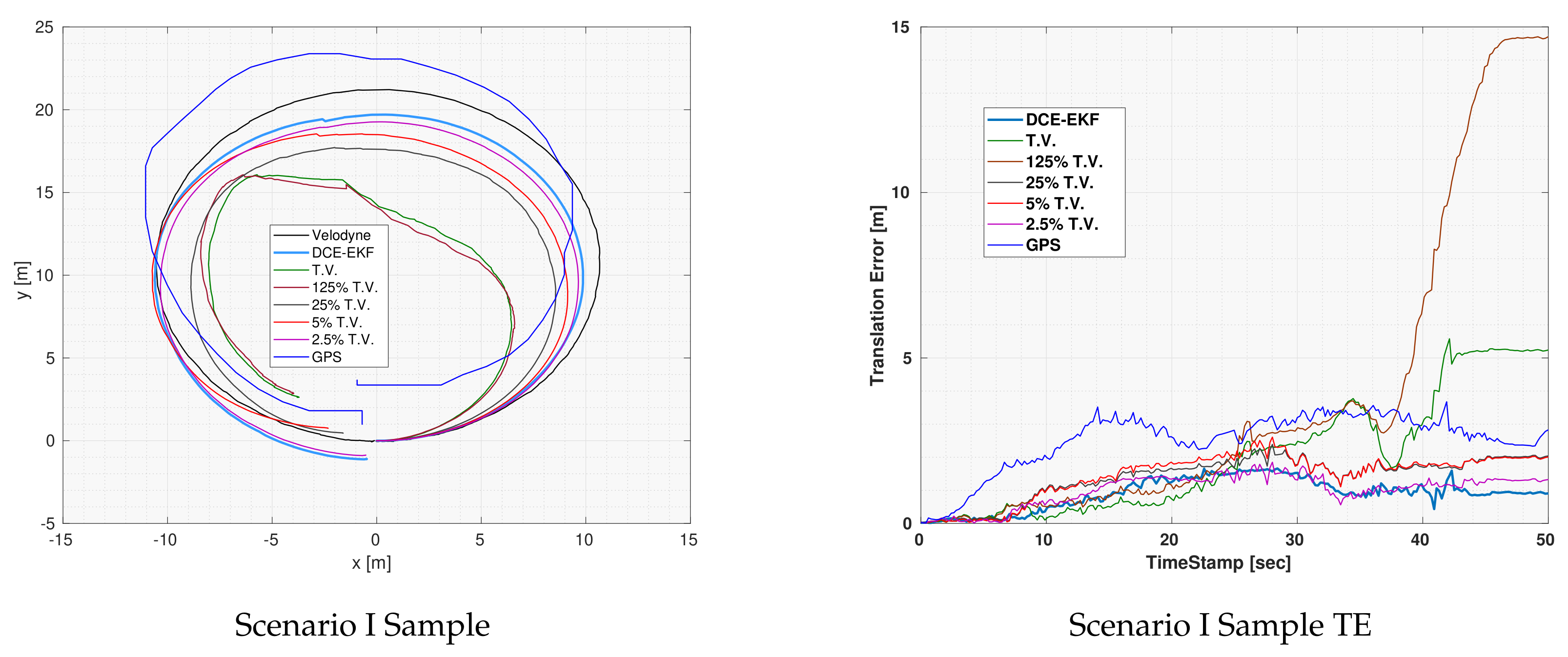
of TV, the output of the EKF diverged which means that even the use of the true variance did not result in good fusion results. This is expected because the covariance of an odometry should increase with time as the drift error increases in the measurements. Overall, the DCE-EKF outperformed all other covariance values as can be seen in the error plot.
Notice that although the TV was outperforming the DCE algorithm during the first 25 seconds of the experiment, as shown in the translation error plot, the DCE algorithm had significantly more accurate results afterwards. This is a result of the fact that the DCE relies on previous data to estimate the covariance and at the beginning of the experiment, there was no enough data to estimate the covariance accurately and the GPS was suffering from increasing error imitating that of an odometry (as shown in
Figure 3). However, after having enough data the DCE algorithm managed to converge to a much better estimate of the covariance and consequently of the vehicle’s location.
Table 1,
Table 2 and
Table 3 summarizes the quantitative results for Scenario I over the three executed experiments. The DCE showed better accuracy while using any of the localization algorithm (UKF, EKF or EH
) in both orientation and translation.
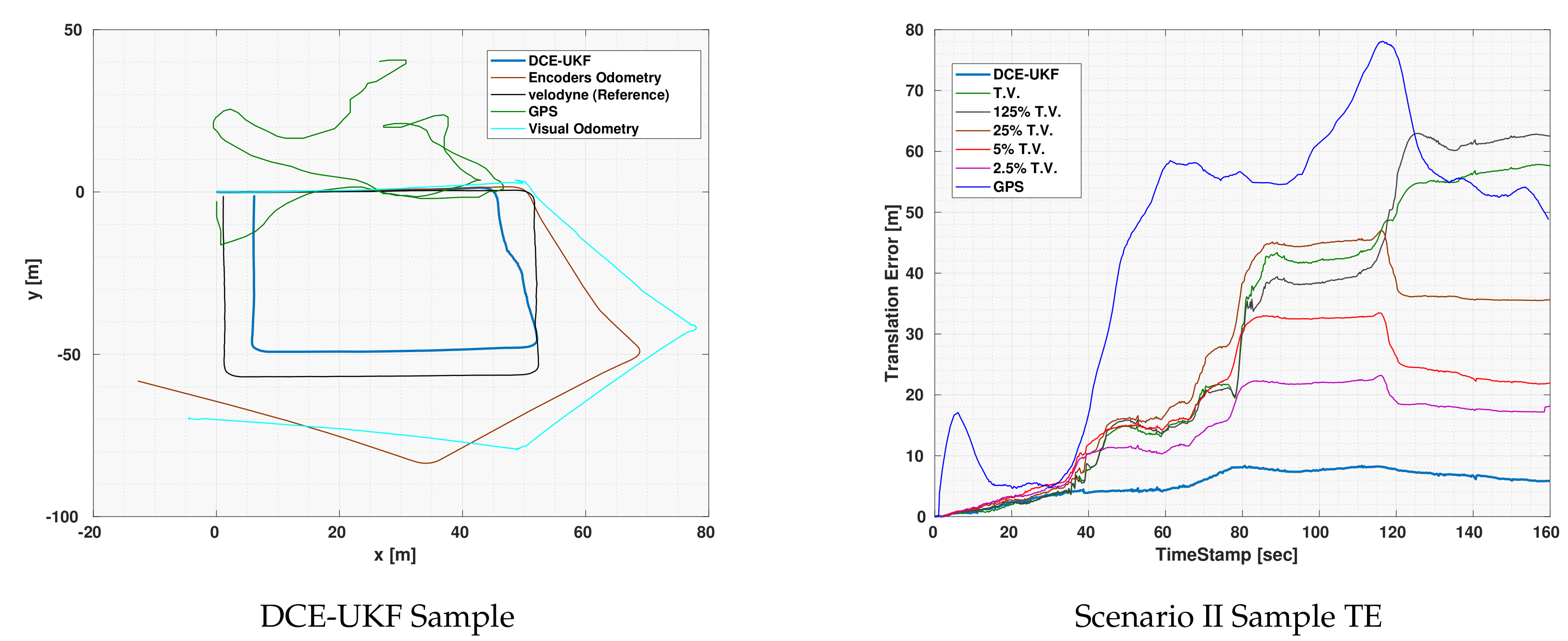
Figure 4 shows the localization output of the DCE-UKF along with the odometries and the GPS measurements. This experiment was executed while the vehicle was moving very close to a building which led to very bad GPS measurements. It can also be seen that both the encoders and the visual odometries suffered from a huge amount of drift. Given all these inaccuracies, through the use of the DCE algorithm and the correction step, the drift in both odometries were eliminated. Notice that although the other runs with constant covariance also had a correction step, the effect of the drift and the inaccuracies in the GPS deteriorated the localization output which shows the efficacy of the DCE algorithm.
Although the GPS error was significantly fluctuating as can be seen in the error plot, the output of the DCE-UKF did not diverge or deteriorate unlike other covariance values. There are two reasons for such results. First, the algorithm relies on calculating the first order polynomial fit of innovations between the odometry and the drift-less sensor, which means that the magnitude of the error in the drift-less sensor itself does not affect the result of the DCE algorithm but only the slope of such error. Second, although the GPS readings suffer from sudden increases in the error, due to the fact that the estimation algorithm does not rely on only one measurement but a series of past measurement (measurement horizon ) to estimate the covariance, the estimated covariance algorithm was accurate enough to get much better results compared to the sensors used and to any other constant covariance.
In Scenario II, the localization output for the
TV and diverged which again confirms the fact that using constant covariances for odometries is not accurate as well as finding accurate values for the covariances through experiments is not applicable since the drift behavior changes with operation conditions. Even if the
TV can be quantified, using it will not produce accurate localization results and even if it works for a given experiments, it might lead to divergence in other operation conditions or in longer durations of operation.
Table 4,
Table 5 and
Table 6 shows the quantitative results for scenario II. The DCE algorithm shows better performance than constant covariances for the three used localization algorithms. In the EKF results, the maximum orientation error for other values of covariance was better than that of the DCE algorithm. This is because the experiments for Scenario II was made while the vehicle was moving very close to the walls of a building which might affected the readings of the magnetometer (due to interference with magnetic fields). This led to an underestimation of the magnetometer covariance in this case. Notice that the same constant value for magnetometer covariance was used in all experiments of all scenarios. Again, we stress the fact that even if a set of TV values gave accurate results for a given set of experiments, it might not be the correct value through long operations.
As for Scenario III,
Figure 5 shows the
path and error plot for one of the experiments using EH
for localization. As shown in the figure, all constant covariance led to the divergence of the localization output. However, in case of DCE, the output did not diverge and shows more accurate results than that of the constant covariances.
In this experiment, the GPS error was suffering from increasing error similar to drift error. However, this drift error was small compared to that of the odometries. Consequently, the error in the localization also suffered from a slight drift. Still, even with this slight drift, the output was significantly better than constant covariances as can be seen in the figure. Notice that the fact that the GPS is suffering from increasing error is not due to the theory of action of the GPS but only a random event that might be due to a certain noise in the path chosen for the vehicle.
Table 7,
Table 8 and
Table 9 shows the quantitative results for Scenario III which shows superior performance of the DCE algorithm compared to constant covariances. Although the orientation accuracy of some constant covariances were more accurate than the DCE, the value of such covariance differed from one experiment to another and from one filter to another as you might notice in the tables which again leads to the same conclusion that using constant covariance for drift suffering odometries is
incomprehensible.
6.2. Oxford RobotCar Dataset
Table 10,
Table 11 and
Table 12 shows the quantitative results for the sessions of Oxford Dataset. As shown in the tables, the covariance estimation algorithm outperformed the constant covariances while using the three fusion filters which shows the efficacy of the algorithm even over longer distances than those tested using the iCab platform and even without any corrective feedback for the odometry being used.
It can be seen that due to the absence of corrective feedback, the average and maximum errors are relatively large. This would not be the case if corrective feedback was incorporated in the results. However, no corrective feedback was made to show the effect of the DCE algorithm over the localization without the effect of the corrections. If corrections were made throughout the runs, the results would have been much better. Despite the fact that the visual odometry will suffer from large error throughout the dataset runs in the absence of the correction due to the accumulation of error with time, the DCE algorithm managed to provide the most accurate results over the dataset runs as shown in the tables.
It is also important to mention specific cases which shows the inconsistency of using constant covariances for odometry fusion. Through using the constant covariance, a given percentage could provide good fusion results (compared to other percentages) for a given experiment but then does not work for another. This can first be seen between
the results of different TVs in the results tables.
For example, in the Oxford dataset tables, the best UKF results after those of the DCE-UKF is provided by the
TV constant covariance; however, it is not the case for EKF fusion.
Furthermore,
Table 13 shows the best average results through using constant covariance for each of the sessions used from Oxford dataset. The inconsistency of using constant covariance can be obviously seen from the results as in each day, one constant covariance value is better than the others. However, in 3 of the 4 days the DCE algorithm showed superior results compared to all constant covariance values and on average over the whole dataset test, the DCE algorithm was superior using the three fusion filters as shown in
Table 10,
Table 11 and
Table 12.
The reason that in day 4 the DCE was outperformed by the
TV is circumstantial because the DCE provides an estimate of the covariance. This does not mean that it provides the optimal or the true value of the covariance but only a good estimate which can be used to get good localization results using odometries which as was shown throughout the paper cannot have a constant covariance and the true value of the covariance cannot be determined at any time or for any kind of operations except retroactively as was done in the results with using a reference.
Table 13 is also evidence that the usage of constant covariances is infeasible and will deteriorate the localization results due to the fact that odometries have variable covariance throughout operation.
6.3. EU Long-Term Dataset
Table 14 shows the results of the DCE-UKF algorithm compared with different constant covariance similar to the results shown in the previous two subsections. As shown in the table, the results of the DCE-UKF outperform those of the UKF with constant covariances. Those results for the LiDAR odometry (LOAM) conform with the findings of the previous two subsections which shows the results of the DCE algorithm for visual odometry (Oxford Dataset), and visual and encoder odometries (iCab experiments). Although the results of the DCE-UKF compared to constant covariance shows the efficacy of the DCE algorithm, the aim of this subsection and the validation with EU Long-term Dataset is to show the effect of the DCE algorithm when integrated with the LOAM and show the fact that DCE can be integrated with any odometry algorithm in order to estimate its drift covariance and consequently achieve more accurate pose estimation through multisensor fusion.
The data in the EU long-term dataset was recorded while the vehicle was driven with a relatively high speed, consequently, the LOAM algorithm suffered from a substantial amount of drift error. Using the DCE algorithm, we were able to achieve a much better pose estimation. In addition to being better than the LOAM algorithm, we also show here that the DCE results through using the GPS (with added artificial white noise
) is better than the pose estimate of the noisy GPS.
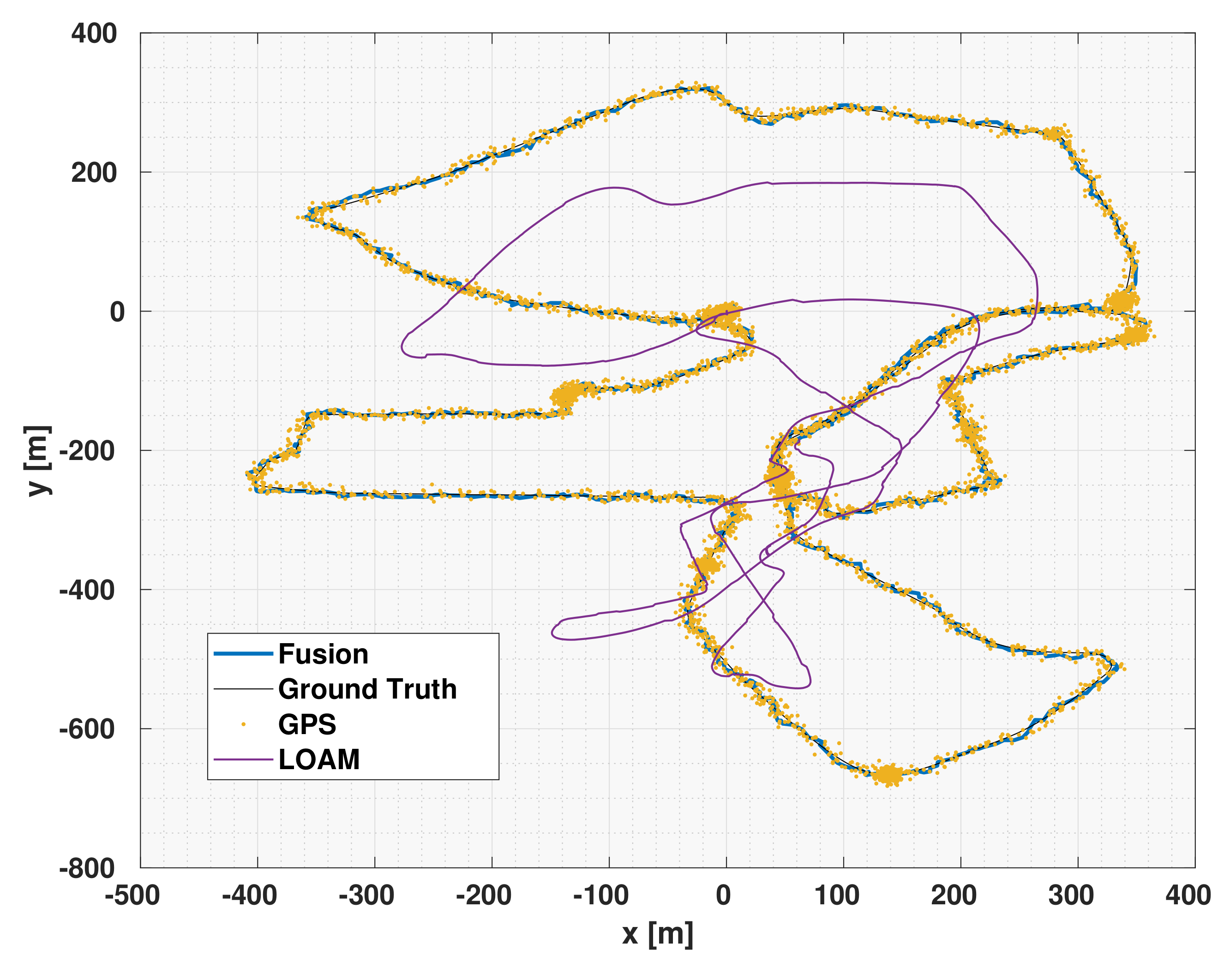
Figure 6 shows the fusion results of the LOAM with DCE compared to the results of the LOAM alone which suffered from substantial amount of drift as can be shown in the figure. In addition to the LOAM data, the figure also shows the noisy data of the GPS. It can also be seen that the DCE-UKF output is smoother and more accurate than that of the GPS results.
Table 15 shows the
and
of the DCE-UKF, LOAM, GPS and filtered GPS over 3 driving sessions of the EU long-term dataset (15,000 km). The use of the DCE-UKF along with the LOAM data achieved much better results than just using the LOAM. This shows the importance of using a fusion algorithm with accurate covariance estimation to achieve more accurate pose estimation than that of an odometry regardless of the amount of drift the odometry might suffer from.
Due to the high amount of drift error in the LOAM results, as shown in
Figure 6, one might think that the results of only using a UKF to filter the readings from the GPS might lead to a better results than fusing the GPS with a LiDAR odometry and using the DCE algorithm. For this, we also show the results of filtered GPS readings using a UKF without fusing the results of the LOAM at all. As it can be seen in
Table 15, the result of fusing DCE-LOAM with the noisy GPS readings led to better results than ignoring the data from the LOAM completely.
The results achieved from the EU long-term dataset conforms with those of the iCab experiments and the Oxford dataset and show the effect of the DCE algorithm when integrated with a drift suffering odometry. It also confirms the fact that the DCE algorithm can be an integral part of an odometry which can lead to a better pose estimation. The results also show the effect of the DCE algorithm over an even longer driving duration and in different weather conditions.
Finally, all the experiments were executed using an Intel Core i7 CPU at 2.10 GHz processor. The average computation time of the algorithm was ms. This small computation time shows the efficiency of using the DCE algorithm on an autonomous vehicle since the performance of the localization or the SLAM modules will not be significantly affected. Furthermore, the maximum and minimum computation time were ms and ms respectively along with standard deviation of ms which shows that the performance of the DCE algorithm is consistent and does not significantly fluctuate through operation.
7. Conclusions and Future Work
This paper presented a novel approach for estimating the covariance of odometries which suffers from an accumulation of error (drift) due to the reliance on integration to measure the pose of the vehicle. The algorithm uses the covariance of another sensor which does not suffer from drift (drift-less sensor). The drift covariance estimation algorithm overcomes the challenges of quantifying the constant covariances through the presence of the ground truth or through hard-tuning and also taking into consideration the fact that the covariance of such odometries is dynamic and changes with time during the operation of the sensor used in the odometry depending on different factors.
The drift covariance estimation algorithm was tested using several real-world experiments by using an experimental automated platform as well as Oxford RobotCar Dataset and the EU Long-term Dataset. The testing was done by using three different localization algorithms namely the extended and unscented Kalman filter as well as the extended H filter. The localization output through using the drift covariance estimation was then compared to the localization output with different constant covariance values. The results showed that the drift covariance estimation algorithm outperformed the constant covariances in almost all the experiments which confirms that the use of constant covariances for drift suffering sensor is neither optimal nor practical. It also shows the efficacy of the drift covariance estimation algorithm from the localization accuracy point of view.
Furthermore, the results of the EU Long-term Dataset were compared with the results of an open source implementation of the well know LOAM algorithm. The results of the comparison showed that integrating the DCE algorithm with the LOAM led to the enhancement of the pose estimation even over longer driving distances and in different weather conditions.
As for the future work, we plan to further investigate possible solutions to generalize the proposed algorithm to work on arbitrary sensors (drift suffering or drift-less).





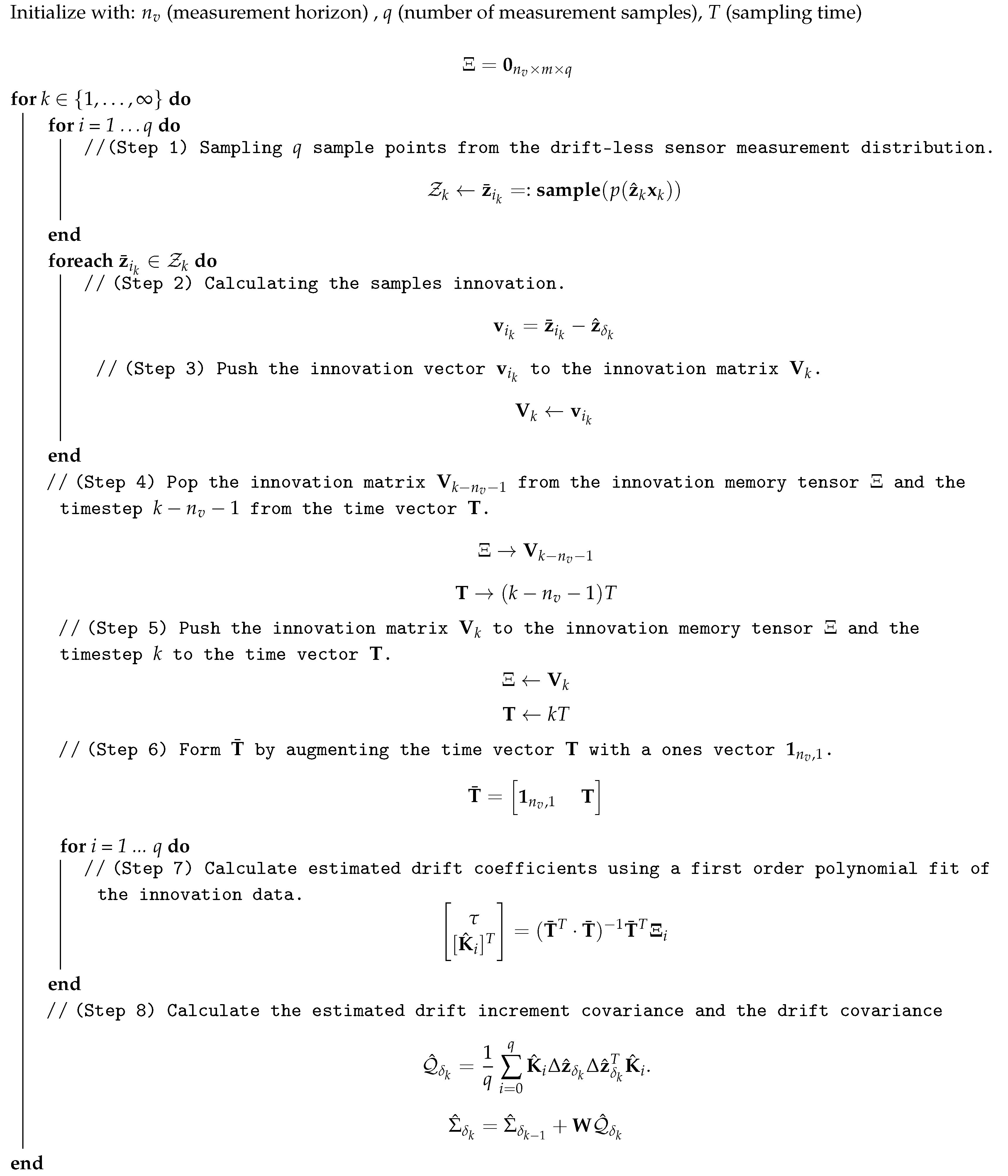






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}