1. Introduction
Due to the continuous development of measurement technology and the constant updating of high sensitivity sensor equipment, the accuracy of measured time series is greatly improved, which is conducive to the further analysis and processing of time series [
1,
2]. The complexity of time series is one of the most important means to represent the characteristics of time series. Entropy, as an effective complexity measure of time series, has been widely developed and used in different fields. Classic examples include permutation entropy (PE) [
3], sample entropy (SE) [
4], approximate entropy (AE) [
5], fuzzy entropy (FE) [
6], and multi-scale ones. However, among these different kinds of entropy, PE has successfully attracted attention from academics and practitioners by virtue of its own advantages.
In 2002, PE was first suggested in a scientific article by Bandt and Pompe [
7]. As a complexity measure, PE introduced arrangement into time series, and determined each arrangement pattern according to the neighboring values. PE has the characteristics of easy implementation and high computation efficiency. With its own advantages, PE has been widely used in different fields, including the medical field [
8], mechanical engineering field [
9,
10], economic field [
11,
12], and underwater acoustic field [
13,
14]. Aiming at weaknesses of PE, many revised PE methods have been proposed to improve the performance of traditional PE.
In 2013, Fadlallah et al. brought forward weighted-permutation entropy (W-PE) and first applied it to electroencephalogram signal processing [
15]. In order to solve the limitation of PE, W-PE introduced amplitude information to weight each arrangement pattern by using variance information. Compared with PE, W-PE responds better to the sudden change of amplitude, in addition, it has better robustness and stability than PE at low signal-to-noise ratio (SNR). As an improvement of PE, W-PE has important influence and status in different fields [
16,
17,
18]. For example, W-PE can show a better performance than PE in distinguishing Alzheimer’s disease patients from normal controls [
19].
In 2016, Rostaghi and Azami proposed dispersion entropy (DE) to quantify the complexity of time series and first applied it to electroencephalograms and bearing fault diagnosis database [
20]. Unlike W-PE, DE introduced amplitude information to map the original signal to the dispersion signal by using the normal cumulative distribution function (NCDF). Compared with PE, DE has a better ability to detect the change of simultaneous frequency and amplitude, and also has a better ability to distinguish different datasets and requires less computation time. In [
21], PE, AE, and DE were compared, the results suggest that DE leads to more stable results in describing the state of rotating machinery, and it is more suitable for real-time applications.
In 2017, reverse PE (RPE) was put forward by Bandt and employed to identify different sleep stages by using electroencephalogram data [
22]. Since RPE is defined as the distance from white noise, it has the opposite trend with PE, W-PE, and DE. In [
23,
24], RPE was used for feature extraction of underwater acoustic signals, compared with PE, RPE has more stable performance and a higher classification recognition rate.
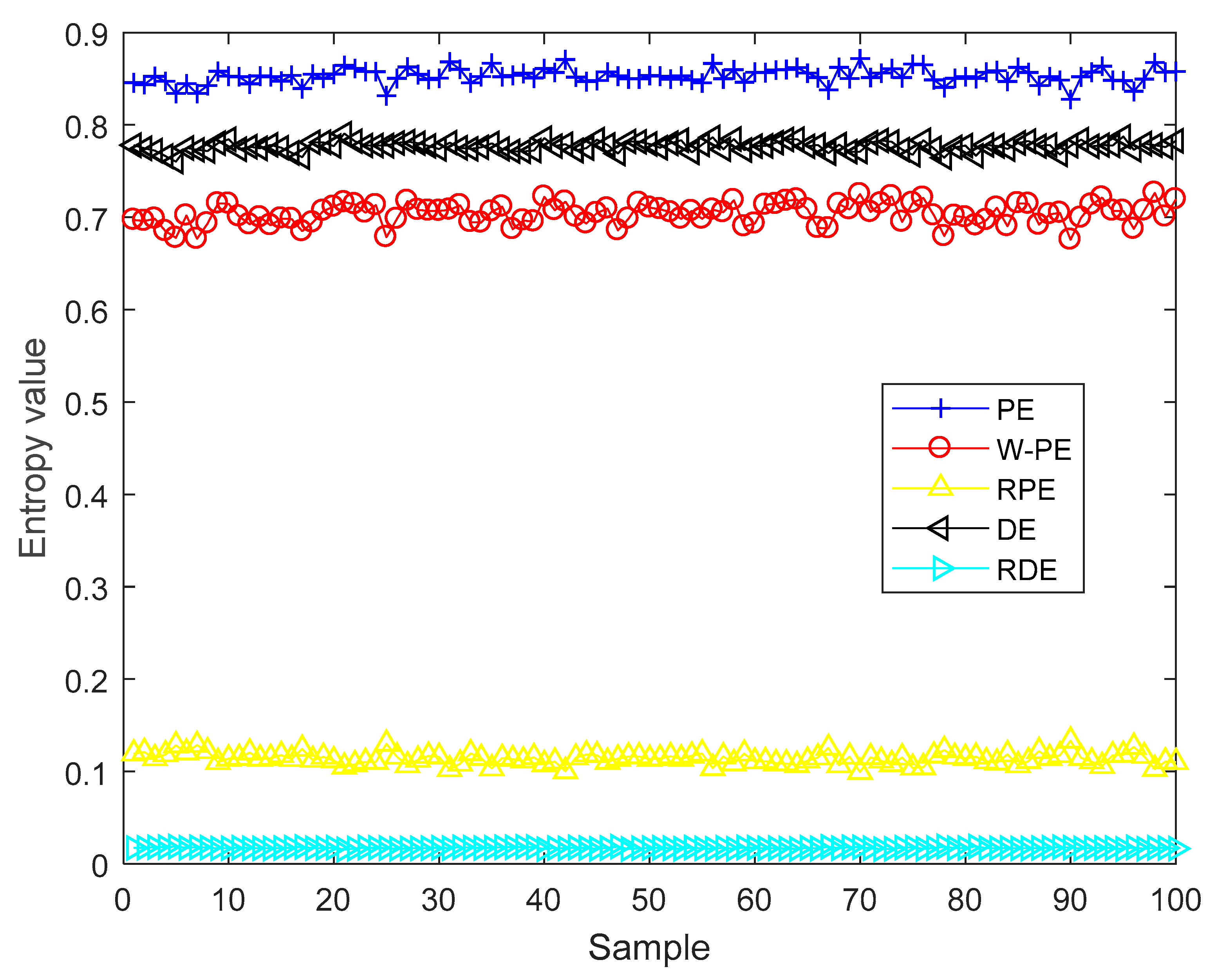
To improve the performance of PE and integrate the advantages of DE and RPE, we propose a new complexity measure for analyzing time series in this paper, and term reverse dispersion entropy (RDE) through introducing amplitude information of DE and distance information of RPE. In the next section, RDE is described in detail through comparison with PE, W-PE, RPE, and DE. In
Section 3 and
Section 4, simulation experiments are carried out to further compare and analyze five kinds of PE. Finally, we summarize the total research work in
Section 5.
2. Reverse Dispersion Entropy
RDE, as a new complexity measure for analyzing time series, takes PE as its theoretical basis and combines the advantages of DE and RPE. The flow chart of PE and RDE are shown in
Figure 1. As shown in
Figure 1, all steps of PE and RDE are different except for phase space reconstruction.
The specific steps of RDE and detailed comparisons with the other four entropies are as follows [
7,
15,
20,
22]:
Step 1: mapping time series to classes.
(1) Mapping by normal cumulative distribution function (NCDF)
For a time series with values, we map to by NCDF, where ranges from 0 to 1.
(2) Mapping by .
We map to by using , where is the number of classes and is a positive integer from 1 to . There is no difference in this step between DE and RDE.
Step 2: phase space reconstruction.
We reconstruct
into
. embedding vectors with the time delay
and embedding dimension
, respectively. The matrix consisting of all embedding vectors can be represented as follows:
where the number of embedding vectors
is equal to
. There is no difference in this step between PE, W-PE, RPE, and RDE.
Step 3: mapping each embedding vector to a dispersion pattern.
Since the embedding dimension and the number of classes are and , respectively, there exists dispersion patterns, and each embedding vector can be mapped to a dispersion pattern . For PE and W-PE, there exist arrangement patterns, which is different from DE and RDE. However, there is also no difference in this step between DE and RDE.
Step 4: calculating the relative frequency of each dispersion pattern.
The relative frequency of
dispersion pattern can be expressed as follows:
In truth, represents the proportion of the number of dispersion patterns to the number of embedding vectors. The four kinds of entropy are the same in this step.
Step 5: calculating RDE.
Like RPE, RDE is defined as the distance to white noise by combining distance information. It can be expressed as:
when
, the value of
is 0 (minimum value). In step 5, the calculation formulas of PE, W-PE, and DE are the same based on the definition of Shannon entropy, however, the calculation formula of RDE is the same as that of RPE by combining distance information.
When there is only one dispersion pattern, that is
, the value of
is
(maximum value). Therefore, the normalized RDE can be expressed as:
Based on the test of simulation signals and real sensor signals, the recommended parameters of RDE are shown in
Table 1. More details about PE, W-PE, DE, and RPE can be found in [
7,
15,
20,
22].















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}