Soft Sensors in the Primary Aluminum Production Process Based on Neural Networks Using Clustering Methods


 and
and
Abstract
:1. Introduction
- A single ANN for all electrolysis pots; in this approach, the results are barely satisfactory, since it is very difficult for ANN to capture the behavioral differences of all pots.
- An ANN for each pot, which might be too complex and difficult to apply, since it is necessary to tune hundreds of ANNs.
- One ANN for a certain cluster of pots, which present similar behaviors.
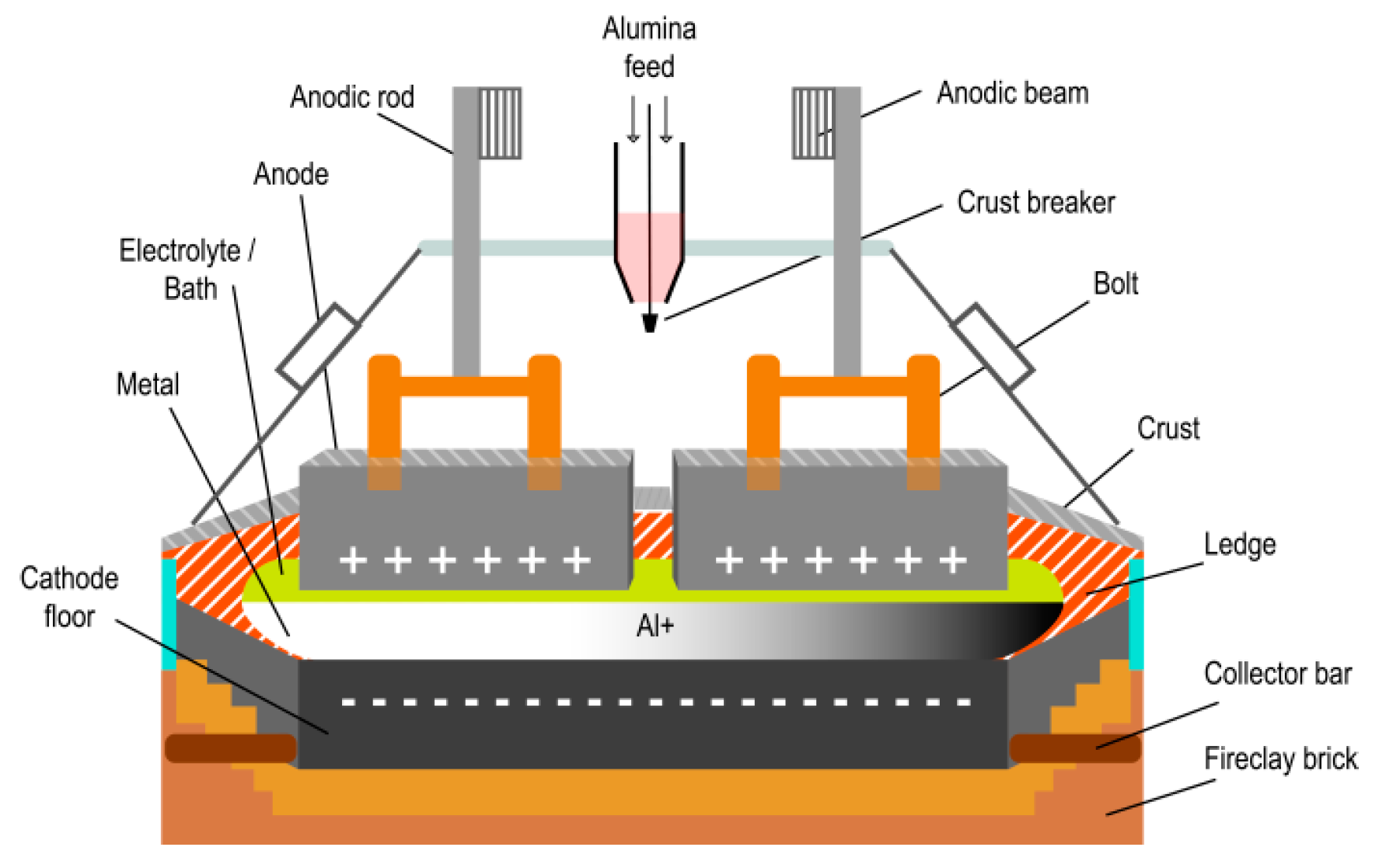
2. Brief Description of the Primary Aluminum Production Process
- Automatic control: Data are collected and processed by computers and/or microcontrollers, which then drive a control action on the plant without direct human intervention. Examples: control of electrical resistance of the pot by the anode–cathode distance (ACD) using pulse width modulation (PWM) to drive the lifting/lowering of anodes; and the control of alumina to be added to the electrolytic bath through mathematical models.
- Manual control: Data are collected through plant floor sensors or manually measured by process operators, but the calculation of the output is performed by the process engineers, taking into account mathematical models and their expertise. Examples: thermocouple to measure the temperature of the pots (Figure 3), percentage of fluoride alumina in the bath (laboratory result), metal level of the pot, replacement of anodes, and Al tapping from the pot.
3. Design of Estimation Models
3.1. Data Extraction, Imputation, and Split
3.2. Strategy for Modeling
- Consider 70% of the data from each cluster to train, 15% to validate, and 15% to test the models.
- Consider data from all pots of one entire section to train the models, except for one pot of the respective section to test the model. This was applied to section clustering and lifespan division.
- Dataset standardization was done using the z-score method.
| Algorithm 1. Pseudocode for modeling process using clustered dataset. |
| EXPERIMENTS = 10; TOTAL_POTS = 960; POTS_BY_SECTION = 30; TOTAL_OUTPUTS = 3; for i_exp = 1 to EXPERIMENTS do for i_out = 1 to TOTAL_OUTPUTS do for i_pot = 1 to 30 to TOTAL_POTS do a) Get data from a section: (index_pot >= i_pot and index_pot <= (i_pot + POTS_BY_SECTION − 1). b) Create input and output (i_out) data matrices. c) Split data between training and validation datasets. d) Define parameters of the ANN model. e) Create ANN model. f) Train ANN model. for i_test = i_pot to (i_pot + POTS_BY_SECTION − 1) do g) Get data by index_pot = i_test. h) Create input and output (i_out) data matrices. i) Simulate ANN model using data by (step h)). j) Calculate and store MSE and R values. k) Check if MSE and R values are better than previous model. If true, store model. end_for end_for end_for end_for print/plot MSEtest values by each experiments and output variable print/plot Rtest values by each experiments and output variable l) Calculate MSEtest and Rtest average: print MSEglobal by each output variable print Rglobal by each output variable |
3.3. Parameter Learning for ANN Models
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mandin, P.; Lemoine, J.M.; Wüthrich, R.; Roustan, H. Industrial aluminium production: The Hall-Heroult process modeling. ECS Trans. 2009, 19, 1–10. [Google Scholar]
- Grjotheim, K.; Krohn, M. Aluminium Electrolysis: Fundamentals of the Hall-Heroult Process, 3rd ed.; Aluminium Verlag Marketing & Kommunikation GmbH: Düsseldorf, Germany, 2002. [Google Scholar]
- Prasad, S. Studies on the Hall-Heroult aluminum electrowinning process. J. Braz. Chem. Soc. 2000, 11, 245–251. [Google Scholar] [CrossRef]
- Fortuna, L.; Graziani, S.; Rizzo, A.; Xibilia, M.G. Soft Sensors for Monitoring and Control of Industrial Processes, 1st ed.; Springer: London, UK, 2007. [Google Scholar]
- Forssell, U.; Ljung, L. Closed-loop identification revisited. Automatica 1999, 35, 1215–1241. [Google Scholar] [CrossRef]
- Ogunmolu, O.P.; Gu, X.; Jiang, S.B.; Gans, N.R. Nonlinear Systems Identification Using Deep Dynamic Neural Networks. arXiv 2016, arXiv:1610.01439. [Google Scholar]
- Pérez-Cruz, J.H.; Chairez, I.; Rubio, J.J.; Pacheco, J. Identification and control of class of non-linear systems with non-symmetric deadzone using recurrent neural networks. IET Control Theory Appl. 2014, 8, 183–192. [Google Scholar] [CrossRef]
- Gonzalez, J.; Yu, W. Non-linear system modeling using LSTM neural networks. IFAC Papers Online 2018, 51, 485–489. [Google Scholar] [CrossRef]
- Chen, S.; Billings, S.A.; Grant, P.M. Non-linear system identification using neural networks. Int. J. Control 1990, 51, 1191–1214. [Google Scholar] [CrossRef]
- Haykin, S.O. Neural Networks and Learning Machines, 3rd ed.; Pearson Prentice Hall: Manitoba, ON, Canada, 2009. [Google Scholar]
- Le Chau, N.; Nguyen, M.Q.; Dao, T.P.; Huang, S.C.; Hsiao, T.C.; Dinh-Cong, D. An effective approach of adaptive neuro-fuzzy inference system-integrated teaching learning-based optimization for use in machining optimization of S45C CNC turning. Optim. Eng. 2019, 20, 811–832. [Google Scholar] [CrossRef]
- Le Chau, N.; Dao, T.P.; Nguyen, V.T. An Efficient Hybrid Approach of Finite Element Method, Artificial Neural Network-Based Multiobjective Genetic Algorithm for Computational Optimization of a Linear Compliant Mechanism of Nanoindentation Tester. Math. Probl. Eng. 2018. [Google Scholar] [CrossRef]
- Kadlec, P.; Gabrys, B.; Strandt, S. Data-driven soft sensors in the process industry. Comput. Chem. Eng. 2009, 33, 795–814. [Google Scholar] [CrossRef]
- Lu, B.; Chiang, L. Semi-supervised online soft sensor maintenance experiences in the chemical industry. J. Process Control 2018, 67, 23–34. [Google Scholar] [CrossRef]
- Bidar, B.; Shahraki, F.; Sadeghi, J.; Khalilipour, M.M. Soft sensor modeling based on multi-state-dependent parameter models and application for quality monitoring in industrial sulfur recovery process. IEEE Sens. J. 2018, 18, 4583–4591. [Google Scholar] [CrossRef]
- Napier, L.F.A.; Aldrich, C. An IsaMill™ Soft Sensor based on random forests and principal component analysis. IFAC-PapersOnLine 2017, 50, 1175–1180. [Google Scholar] [CrossRef]
- Kartik, C.K.N.; Narasimhan, S. A theoretically rigorous approach to soft sensor development using principal components analysis. Comput. Aided Chem. Eng. 2011, 29, 793–797. [Google Scholar]
- Lin, B.; Recke, B.; Knudsen, J.K.H.; Jørgensen, S.B. A systematic approach for soft sensor development. Comput. Chem. Eng. 2007, 31, 419–425. [Google Scholar] [CrossRef]
- Zamprogna, E.; Barolo, M.; Seborg, D.E. Optimal selection of soft sensor inputs for batch distillation columns using principal component analysis. J. Process Control 2005, 15, 39–52. [Google Scholar] [CrossRef]
- Zheng, J.; Song, Z. Semisupervised learning for probabilistic partial least squares regression model and soft sensor application. J. Process Control 2018, 64, 123–131. [Google Scholar] [CrossRef]
- Wei, G.; Tianhong, P. An adaptive soft sensor based on multi-state partial least squares regression. In Proceedings of the 34th Chinese Control Conference (CCC), Hangzhou, China, 28–30 July 2015; pp. 1892–1896. [Google Scholar]
- Liu, J.; Chen, D.-S.; Lee, M.-W. Adaptive soft sensors using local partial least squares with moving window approach. Asian-Pac. J. Chem. Eng. 2012, 7, 134–144. [Google Scholar] [CrossRef]
- Chen, K.; Castillo, I.; Chiang, L.H.; Yu, J. Soft sensor model maintenance: A case study in industrial processes. In Proceedings of the 9th International Symposium on Advanced Control of Chemical Processes, Whistler, BC, Canada, 7–10 June 2015; Volume 48, pp. 427–432. [Google Scholar]
- Murugan, C.; Natarajan, P. Estimation of fungal biomass using multiphase artificial neural network based dynamic soft sensor. J. Microbiol. Methods 2019, 159, 5–11. [Google Scholar] [CrossRef]
- Asteris, P.G.; Roussis, P.C.; Douvika, M.G. Feed-forward neural network prediction of the mechanical properties of sandcrete material. Sensors 2017, 17, 1344. [Google Scholar] [CrossRef]
- Souza, F.A.A.; Araújo, R.; Matias, T.; Mendes, J. A multilayer-perceptron based method for variable selection in soft sensor design. J. Process Control 2013, 23, 1371–1378. [Google Scholar] [CrossRef]
- Shokry, A.; Audino, F.; Vicente, P.; Escudero, G.; Moya, M.P.; Graells, M.; Espuña, A. Modeling and simulation of complex nonlinear dynamic processes using data based models: Application to photo-Fenton process. Comput. Aided Chem. Eng. 2015, 37, 191–196. [Google Scholar]
- Gonzaga, J.C.B.; Meleiro, L.A.C.; Kiang, C.; Filho, R.M. ANN-based soft-sensor for real-time process monitoring and control of an industrial polymerization process. Comput. Chem. Eng. 2009, 33, 43–49. [Google Scholar] [CrossRef]
- Zhao, T.; Li, P.; Cao, J. Soft sensor modeling of chemical process based on self-organizing recurrent interval type-2 fuzzy neural network. ISA Trans. 2019, 84, 237–246. [Google Scholar] [CrossRef] [PubMed]
- Jalee, E.A.; Aparna, K. Neuro-fuzzy soft sensor estimator for benzene toluene distillation column. Procedia Technol. 2016, 25, 92–99. [Google Scholar] [CrossRef]
- Morais, A.A., Jr.; Brito, R.P.; Sodré, C.H. Design of a soft sensor with technique NeuroFuzzy to infer the product composition of a distillation process. In Proceedings of the World Congress on Engineering and Computer Science, San Francisco, CA, USA, 22–24 October 2014. [Google Scholar]
- Mei, C.; Yang, M.; Shu, D.; Jiang, H.; Liu, G.; Liao, Z. Soft sensor based on Gaussian process regression and its application in erythromycin fermentation process. Chem. Ind. Chem. Eng. Q. 2016, 22, 127–135. [Google Scholar] [CrossRef]
- Abusnina, A. Gaussian Process Adaptive Soft Sensors and their Applications in Inferential Control Systems. Ph.D. Thesis, University of York, York, UK, 2014. [Google Scholar]
- Zheng, R.; Pan, F. Soft sensor modeling of product concentration in glutamate fermentation using Gaussian process regression. Am. J. Biochem. Biotechnol. 2016, 12, 179–187. [Google Scholar] [CrossRef]
- Jain, P.; Rahman, I.; Kulkarni, B.D. Development of a soft sensor for a batch distillation column using support vector regression techniques. Chem. Eng. Res. Des. 2007, 85, 283–287. [Google Scholar] [CrossRef]
- Li, Q.; Du, Q.; Ba, W.; Shao, C. Multiple-input multiple-output soft sensors based on KPCA and MKLS-SVM for quality prediction in atmospheric distillation column. Int. J. Innov. Comput. Inf. Control 2012, 8, 8215–8230. [Google Scholar]
- Xu, W.; Fan, Z.; Cai, M.; Shi, Y.; Tong, X.; Sun, J. Soft sensing method of LS-SVM using temperature time series for gas flow measurements. Metrol. Meas. Syst. 2015, XXII, 383–392. [Google Scholar] [CrossRef]
- Qin, S.J. Neural networks for intelligent sensors and control—Practical issues and some solutions. In Neural Systems for Control; Omidvar, O., Elliott, D.L., Eds.; Elsevier: London, UK, 1997; Chapter 8; pp. 213–234. [Google Scholar]
- Rani, A.; Singh, V.; Gupta, J.R.P. Development of soft sensor for neural network based control of distillation column. ISA Trans. 2013, 52, 438–449. [Google Scholar] [CrossRef] [PubMed]
- Sun, W.Z.; Wang, J.S. Elman neural network soft-sensor model of conversion velocity in polymerization process optimized by chaos whale optimization algorithm. IEEE Access 2017, 5, 13062–13076. [Google Scholar] [CrossRef]
- Duchanoya, C.A.; Moreno-Armendáriza, M.A.; Urbina, L.; Cruz-Villar, C.A.; Calvo, H.; Rubio, J.J. A novel recurrent neural network soft sensor via a differential evolution training algorithm for the tire contact patch. Neurocomputing 2017, 235, 71–82. [Google Scholar] [CrossRef]
- Paquet-Durand, O.; Assawarajuwan, S.; Hitzmann, B. Artificial neural network for bioprocess monitoring based on fluorescence measurements: Training without offline measurements. Eng. Life Sci. 2017, 17, 874–880. [Google Scholar] [CrossRef]
- Conga, Q.; Yu, W. Integrated soft sensor with wavelet neural network and adaptive weighted fusion for water quality estimation in wastewater treatment process. Measurement 2018, 124, 436–446. [Google Scholar] [CrossRef]
- Poerio, D.V.; Brown, S.D. Localized and adaptive soft sensor based on an extreme learning machine with automated self-correction strategies. J. Chemom. 2018, 1, e3088. [Google Scholar] [CrossRef]
- Akbari, E.; Mir, M.; Vasiljeva, M.V.; Alizadeh, A.; Nilashi, M. A computational model of neural learning to predict graphene based ISFET. J. Electron. Mater. 2019, 48, 4647–4652. [Google Scholar] [CrossRef]
- Zhao, C.; Yu, S.-h.; Miller, C.; Ghulam, M.; Li, W.-h.; Wang, L. Predicting aircraft seat comfort using an artificial neural network. Hum. Factors Ergon. Manuf. 2019, 29, 154–162. [Google Scholar] [CrossRef]
- Shang, C.; Yang, F.; Huang, D.; Lyu, W. Data-driven soft sensor development based on deep learning technique. J. Process Control 2014, 24, 223–233. [Google Scholar] [CrossRef]
- Yan, W.; Tang, D.; Lin, Y. A Data-driven soft sensor modeling method based on deep learning and its application. IEEE Trans. Ind. Electron. 2017, 64, 4237–4245. [Google Scholar] [CrossRef]
- Gopakumar, V.; Tiwari, S.; Rahman, I. A deep learning based data driven soft sensor for bioprocesses. Biochem. Eng. J. 2018, 136, 28–39. [Google Scholar] [CrossRef]
- Yuan, X.; Ou, C.; Wang, Y.; Yang, C.; Gui, W. Deep quality-related feature extraction for soft sensing modeling: A deep learning approach with hybrid VW-SAE. Neurocomputing 2019, Article in press. [Google Scholar] [CrossRef]
- Soares, F.M.; Souza, A.M.F. Neural Network Programming with Java, 2nd ed.; Packt Publishing: Birmingham, UK, 2017. [Google Scholar]
- Bhattacharyay, D.; Kocaefe, D.; Kocaefe, Y.; Morais, B. An artificial neural network model for predicting the CO2 reactivity of carbon anodes used in the primary aluminum production. Neural Comput. Appl. 2017, 28, 553–563. [Google Scholar] [CrossRef]
- Piuleac, C.G.; Rodrigo, M.A.; Cañizares, P.; Curteanu, S.; Sáezb, C. Ten steps modeling of electrolysis processes by using neural networks. Environ. Model. Softw. 2010, 25, 74–81. [Google Scholar] [CrossRef]
- Sadighi, S.; Mohaddecy, R.S.; Ameri, Y.A. Artificial neural network modeling and optimization of Hall-Héroult process for aluminum production. Int. J. Technol. 2015, 3, 480–491. [Google Scholar] [CrossRef]
- Chermont, P.R.S.; Soares, F.M.; de Oliveira, R.C.L. Simulations on the bath chemistry variables using neural networks. Light Met. 2016, 1, 607–612. [Google Scholar]
- Karri, V. Drilling performance prediction using general regression neural networks. Intell. Probl. Solving Methodol. Approaches 2000, 1821, 67–73. [Google Scholar]
- Frost, F.; Karri, V. Identifying significant parameters for Hall-Héroult Process using general regression neural networks. Intell. Probl. Solving Methodol. Approaches 2010, 1821, 73–78. [Google Scholar]
- Lima, F.A.N.; Souza, A.M.F.; Soares, F.M.; Cardoso, D.L.; Oliveira, R.C.L. Clustering aluminum smelting potlines using fuzzy C-means and K-means algorithms. Light Met. 2017, 1, 589–597. [Google Scholar]
- Xu, M.; Isac, M.; Guthrie, R.I.L. A Numerical simulation of transport phenomena during the horizontal single belt casting process using an inclined feeding system. Metall. Mater. Trans. B 2018, 49, 1003–1013. [Google Scholar] [CrossRef]
- Renaudier, S.; Langlois, S.; Bardet, B.; Picasso, M.; Masserey, A. A unique suite of models to optimize pot design and performance. Light Met. 2018, 1, 541–549. [Google Scholar]
- Baiteche, M.; Taghavi, S.M.; Ziegler, D.; Fafard, M. LES turbulence modeling approach for molten aluminium and electrolyte flow in aluminum electrolysis cell. Light Met. 2017, 1, 679–686. [Google Scholar]
- Dupuis, M.; Jeltsch, R. On the importance of field validation in the use of cell thermal balance modeling tools. Light Met. 2016, 1, 327–332. [Google Scholar]
- Gunasegaram, D.R.; Molenaar, D. Towards improved energy efficiency in the electrical connections of Hall-Héroult cells through finite element analysis (FEA) modeling. J. Clean. Prod. 2015, 93, 174–192. [Google Scholar] [CrossRef]
- Totten, G.E.; MacKenzie, D.S. Introduction to aluminum. In Handbook of Aluminum, Physical Metallurgy and Processes, 1st ed.; Sverdlin, A., Ed.; CRC Press: New York, NY, USA, 2003; Volume 1, pp. 1–31. [Google Scholar]
- Taylor, M.P.; Etzion, R.; Lavoie, P.; Tang, J. Energy balance regulation and flexible production: A new frontier for aluminum smelting. Metall. Mater. Trans. E 2014, 1, 292–302. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.J.J.; Taylor, M.P. Control of temperature and aluminium fluoride in aluminium reduction. Alum. Int. J. Ind. Res. Appl. 2005, 81, 678–682. [Google Scholar]
- Haupin, W. The influence of additives on Hall-Héroult bath properties. J. Miner. Metals Mater. Soc. (TMS)–JOM 1991, 43, 28–34. [Google Scholar] [CrossRef]
- Taylor, M.P.; Chen, J.J.J.; Young, B.R. Control for Aluminum Production and Other Processing Industries; CRC Press Taylor & Francis Group: Boca Raton, FL, USA, 2014. [Google Scholar]
- Lumley, R. Fundamentals of Aluminium Metallurgy: Production, Processing and Applications, 1st ed.; Elsevier: Sawston, Cambridge, UK, 2010. [Google Scholar]
- Chen, X.; Jie, L.; Zhang, W.; Zou, Z.; Ding, F.; Liu, Y.; Li, Q. The development and application of data warehouse and data mining in aluminum electrolysis control systems. TMS Light Met. 2006, 1, 515–519. [Google Scholar]
- Ugarte, B.; Hajji, A.; Pellerina, R.; Artibab, A. Development and integration of a reactive real-time decision support system in the aluminum industry. Eng. Appl. Artif. Intell. 2009, 22, 897–905. [Google Scholar] [CrossRef]
- Pereira, V.G. Automatic Control of AlF3 Addition in Aluminum Reduction Pots Using Fuzzy Logic. Master’s Thesis, Postgraduate Program in Electrical Engineering, Federal University of Pará, Belém, Brazil, 2005. (In Portuguese). [Google Scholar]
- Majid, N.A.A.; Taylor, M.P.; Chen, J.J.J.; Stam, M.A.; Mulder, A.; Brent, Y.R. Aluminium process fault detection by multiway principal component analysis. Control Eng. Pract. 2011, 19, 367–379. [Google Scholar] [CrossRef]
- Braga, C.A.P.; Netto, J.V.F. A dynamic state observer to control the energy consumption in aluminium production cells. Syst. Sci. Control Eng. 2016, 4, 307–319. [Google Scholar] [CrossRef]
- Mares, E.; Sokolowski, J.H. Artificial intelligence-based control system for the analysis of metal casting properties. J. Achiev. Mater. Manuf. Eng. 2010, 40, 149–154. [Google Scholar]
- Du, Y.-C.; Stephanus, A. Levenberg-Marquardt neural network algorithm for degree of arteriovenous fistula stenosis classification using a dual optical photoplethysmography sensor. Sensors 2018, 18, 2322. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hagan, M.T.; Menhaj, M.B. Training feedforward networks with the Marquardt algorithm. IEEE Trans. Neural Netw. 1994, 5, 989–993. [Google Scholar] [CrossRef] [PubMed]
- Feng, J.; Sun, Q.; Li, Z.; Sun, Z.; Jia, K. Back-propagation neural network-based reconstruction algorithm for diffuse optical tomography. J. Biomed. Opt. 2018, 24, 051407. [Google Scholar] [CrossRef] [PubMed]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Complete Name | Unit |
|---|---|---|
| %CaO | Calcium Oxide Percentage | % |
| %Fe2O3 | Iron Oxide Percentage | % |
| %MnO | Manganese Dioxide Percentage | % |
| %Na2O | Sodium Oxide Percentage | % |
| %P2O5 | Phosphorus Pentoxide Percentage | % |
| %SiO2 | Silicon Oxide Percentage | % |
| %TiO2 | Titanium Dioxide Percentage | % |
| %V2O5 | Vanadium Pentoxide Percentage | % |
| %ZnO | Zinc Oxide Percentage | % |
| <325 m | <325 Mesh | % |
| >100 m | >100 Mesh | % |
| >200 m | >200 Mesh | % |
| CR | Friction Index | % |
| CRF | Thin Crust | % |
| DA | Apparent Density | g/cm3 |
| LOI1 | Loss on ignition (300–1000 °C) | % |
| LOI2 | Loss on ignition (110–1000 °C) | % |
| LOI3 | Loss on ignition (110–300 °C) | % |
| SE | Specific Surface | m2/g |
| %FE | Iron Content in Metal | ppm |
| %Ga | Gallium Content | % |
| %Mn | Manganese Content | % |
| %Na | Sodium Content in Metal | % |
| %Ni | Nickel Content | % |
| %P | Metal Phosphorus Content | ppm |
| %SI | Silicon Content in Metal | ppm |
| %TBase | Percentage of Time on Base Feed | % |
| %TChk | Check Feed Time Percentage | % |
| %TInic | Percentage of Initial Feeding Time | % |
| %TOthers | Percentage of Time Other Feeding Modes | % |
| %TOV | Percentage of Feeding Over Time | % |
| %TUN | Percentage of Feeding Time Under | % |
| %V_ | Vanadium Content | % |
| A%1 | Feeding (Al2O3) | % |
| ALF | Aluminum Fluoride (% in Bath) | % |
| ALF3A | Amount of AlF3 Added | kg/Misc |
| ALF3AB | AlF3–Base Addition–Total | kg/Misc |
| ALF3ABF | AlF3–Base Addition–ABF | kg/t Al |
| ALF3ABFC | AlF3–Base Addition–Factor C | kg/t Al |
| ALF3ABN | AlF3–Base Addition–Na2O | kg/t Al |
| ALF3ABT | AlF3–Base Addition–Total | kg/Misc |
| ALF3ABV | AlF3–Base Addition–Life | kg/Misc |
| ALF3Ac | Amount of AlF3 Added–Correction | kg/Misc |
| ALF3AE | ALF3A–Extra Addition | kg/Misc |
| ALF3Ah | Amount of AlF3 Added–Historic | kg/Misc |
| ALF3Am | Amount of AlF3 Added–Maintenance | kg/Misc |
| ALF3AR | AlF3 Deviation Reference | kg/Misc |
| ALF3ARB | ALF3A–[Real–Base] | kg/Misc |
| ALF3AS | AlF3–Hopper Balance Correction | kg/Misc |
| ALF3At | Amount of AlF3 Added–Trend | kg/Misc |
| ALF3ATS | Hopper Balance | kg/Misc |
| ALF3ATSAc | Accumulated Hopper Balance | kg/Misc |
| ALF3CA | AlF3–% AlF3 Correction | kg/Misc |
| ALF3CM | AlF3 Quantity–Manual Correction | kg/Misc |
| ALF3CT | AlF3–Temperature Correction | kg/Misc |
| ALF3DA | AlF3 Added–Cumulative Deviation | kg |
| ALF3DALI | AlF3–Accumulated Deviation–Lower Limit | kg |
| ALF3DALS | AlF3–Accumulated Deviation–Upper Limit | kg |
| ALF3LC | AlF3–Limit Check Correction | kg/Misc |
| ALFca | Aluminum Fluoride for CA | % |
| ALFcalc | Calculated Aluminum Fluoride | % |
| ALM | Feeder | Kg |
| CAF | Calcium Fluoride (% in Bath) | % |
| CAF2A | Amount of CaF2 Added | kg |
| CAF2CM | CaF2 Quantity–Manual Correction | kg |
| CAN | Anode Coverage | cm |
| CE | Specific Energy Consumption | kWh/kg Al |
| CoLiq | Liquid Column | cm |
| CQB-Efetiv | Chemical Bath Control—Effectiveness | % |
| DeltaR | Resistance Delta | uOhm |
| DeltaT | Super Heat | °C |
| DeltaT1 | Super Heat | °C |
| DeltaTM | Super Heat Measured | °C |
| DeltRCI | DeltaR–Instability Calculation | uOhm |
| DesAnodCAR | Anode Descent in CAR | un |
| DesAutAnod | Automatic Anode Descent | un |
| DifNME | Metal Level (Real-Set) | cm |
| DifRMR | Rreal-Rset | uOhm |
| DifRSO | Rtarget-Rset | uOhm |
| DRPTro | Post-Trade Resistance Delta | uOhm |
| EaEnergL | Anode Effect (AE)–Net Energy | Kwh/EA |
| EAN | Unscheduled Anode Effect | EA/d |
| EAP | Scheduled Anode Effect | ea/d |
| EaDurPol | AE–Polarization Duration | seg/Ea |
| EaDurPolTot | AE–Total Duration of Polarization | seg/F/Day |
| EaVBruta | AE–Gross Voltage | V/Ea |
| EaVLiq | AE–Liquid Voltage | V/Ea |
| EaVMax | AE–Maximum Voltage | V |
| EaVPol | AE–Voltage Polarization | V/Ea |
| ECO | Current Efficiency | % |
| FAB | AlF3 Base Addition | kg/Misc |
| FARB | Addition (Real + Extra − Base) | kg/Misc |
| IMx | Current Intensity | kA |
| IncCTAlim | Increment–CTFeed | uOhm |
| IncCTOsc | Increment–CTOsc | uOhm |
| IncOp | Increment–Operation | uOhm |
| IncOs | Increment–Oscillation | uOhm |
| IncTm | Increment–Temperature | uOhm |
| IncTr | Increment–Anode Exchange | uOhm |
| Na | Sodium Content in Metal (PPM) | ppm |
| NA2CO3A | Added Amount of Na2CO3 | kg |
| NA2CO3CM | Na2CO3 Quantity–Manual Correction | kg |
| NBA | Bath Level | cm |
| NBAA | Bath Addition | Kg |
| NBAc | Bath Control | Kg |
| NBAR | Bath Removal | Kg |
| NCicSEA | SEA Cycle Number | Ciclos/SEA |
| NEA | Total Anode Effect | ea/d |
| NEARecorr | Total Recurrent Anode Effect | EA/d |
| NME | Metal Level | cm |
| NOV | Number of Overs | un |
| NSA | Number of Feed Shots | un |
| NTR | Number of Tracks | - |
| NumOverUnder | Number of Overs Followed by Unders | un |
| PAN | Anodic Loss | uOhm |
| PCA | Cathodic Loss | mV |
| PCO | Cathodic Loss (uOhms) | mOhm |
| PHV | Loss Rod Beam | uOhm |
| PreEA | Anode Pre-Effect | ea/d |
| PrvEA | Anode Effect Prediction | ea/d |
| PUR | Metal Purity (% Al) | % |
| QALr | Feed Quantity (Real) | kg |
| QALt | Feed Quantity (Theoretical) | kg |
| QME | Amount of Flushed Metal (Real) | ton |
| RMR | Real Resistance | uOhm |
| RS | Resistance Setpoint | uOhm |
| RSO | Target Resistance | uOhm |
| SetNBA | Bath Level Setpoint | cm |
| SetNME | Metal Level Setpoint | cm |
| SILO | Alf3 Silo Filling Control | - |
| SIM | Impossible Anode Effect Suppression | % |
| SIMTot | Impossible Total Anode Effect Suppression | % |
| SPEA | Anode Pre-Suppression | ea/d |
| SPEAIM | Impossible Anode Pre-Effect Suppression | % |
| SubAnodCAR | CAR Anode Rise | un |
| SubAutAnod | Automatic Anode Rise | un |
| SWF | Strong Oscillation | % |
| SWT | Total Oscillation | % |
| TAS | Suspended Feed Time | min |
| TC1 | Check Time | min |
| TEA | Anode Effect Time | min |
| TMP | Bath Temperature | °C |
| TMPcat | CA Bath Temperature | °C |
| TMPLI | Bath Temperature–Lower Limit | °C |
| TMPLiq | Liquid Temperature | °C |
| TMPLS | Bath Temperature–Upper Limit | °C |
| TMT | Track Time | min |
| TOV | Over Time | min |
| TUN | Under Time | min |
| VIDA | Pot Life | days |
| WF | Real Consumption of Oven | kW |
| WFA | Oven Target Consumption | kW |
| AF | Fresh Alum Silo Level | % |
| af%F | Adsorbed Fluoride (Fluorinated Alumina) | % |
| af%F(Cor) | Corrected plant fluoridation | % |
| af%Na2O | Sodium Oxide (Fluorinated Alumina) | % |
| af%UM | Moisture (Fluorinated Alumina) | % |
| Af < 325 m | <325 Mesh (Fluorinated Alumina) | % |
| Af < 400 m | <400 Mesh (Fluorinated Alumina) | % |
| Af > 100 m | >100 Mesh (Fluorinated Alumina) | % |
| Af > 200 m | >200 Mesh (Fluorinated Alumina) | % |
| afDA | Apparent Density (Fluorinated Alumina) | g/cm3 |
| afLOI1 | L.O.I. (110–300 °C; AF) | % |
| AluT | Transported Alumina | T |
| Na2Odif | Sodium Oxide (Fluorinated Alumina–Virgin) | % |
| SPVZ | Fresh Alumina Flow Setpoint | T/h |
| VZ | Fresh Alumina Flow | T/h |
| af%UMx | Moisture (Fluorinated Alumina) | % |
| ALF LI | Lower Limit ALF | % |
| ALF LS | ALF Upper Limit | % |
| IA | Target Current | kA |
| IM | Current Intensity | kA |
| IMBB | Booster Current Intensity | kA |
| IMC | Current Intensity (Pot) | kA |
| IMRB | Current Intensity | kA |
| VL | Line Voltage | V |
| WL | Actual Line Consumption | MW |
| ECp | Predicted Current Efficiency | % |
| ECr | Real Current Efficiency | % |
| PRODReal | Real Production | t |
| ID | Type | Variable | Abbreviation | Unit | Delay | R w/TMP | R w/ALF | R w/NME |
|---|---|---|---|---|---|---|---|---|
| 1 | Input | Gross Voltage | VMR-1 | V | 1-step | −0.49 | 0.43 | 0.30 |
| 2 | Gross Resistance | RMR-1 | uOhm | −0.48 | 0.41 | 0.24 | ||
| 3 | Bath Level | NBA-1 | cm | 0.58 | −0.41 | −0.69 | ||
| 4 | Calcium Fluoride (% in the Bath) | CAF-1 | % | −0.53 | −0.49 | 0.37 | ||
| 5 | Percentage of Sodium Oxide | PNA2O-1 | % | −0.52 | −0.67 | 0.31 | ||
| 6 | Percent of Calcium Oxide | PCAO-1 | % | −0.57 | 0.72 | 0.32 | ||
| 7 | Amount of AlF3 Added | ALF3A-1 | kg/misc | 0.40 | −0.46 | −0.30 | ||
| 8 | Amount Fed (Real) | QALR-1 | kg | −0.35 | 0.32 | 0.52 | ||
| 9 | Temperature | TMP-1 | °C | 0.88 | −0.79 | 0.32 | ||
| 10 | Aluminum Fluoride (% in the Bath) | ALF-1 | % | −0.78 | 0.94 | 0.25 | ||
| 11 | Metal Level | NME-1 | cm | −0.41 | 0.34 | 0.94 | ||
| 12 | Output | Temperature | TMP | °C | - | - | - | |
| 13 | Aluminum Fluoride (% in the Bath) | ALF | % | - | - | - | - | |
| 14 | Metal Level | NME | cm | - | - | - |
| Lifespan Division | Training Algorithm | Number of Models |
|---|---|---|
| Starting point | ANN-LM | 32 sections × 3 outputs = 96 All dataset × 3 outputs = 3 |
| ANN-BP | 32 sections × 3 outputs = 96 All dataset × 3 outputs = 3 | |
| Stationary regime | ANN-LM | 32 sections × 3 outputs = 96 All dataset × 3 outputs = 3 |
| ANN-BP | 32 sections × 3 outputs = 96 All dataset × 3 outputs = 3 | |
| Shutdown point | ANN-LM | 32 sections × 3 outputs = 96 All dataset × 3 outputs = 3 |
| ANN-BP | 32 sections × 3 outputs = 96 All dataset × 3 outputs = 3 | |
| TOTAL | 576 models (clustered data) 18 models (all dataset) 594 models |
| Parameter | Value | Justification |
|---|---|---|
| Number of hidden layers | 1 | Empirical attempts. |
| Number of neurons in the hidden layer | 2 | |
| Transfer function in the hidden layer | Symmetric Sigmoid | |
| Transfer function in the output layer | Linear | |
| Learning algorithms | LM | To build models faster, because this algorithm considers an approximation of Newton’s method, which uses an array of second-order derivatives and a first-order derivative matrix (Jacobian matrix). On the other hand, it uses more memory to calculate optimal weights [76,77]. |
| BP | To create models based on the most traditional learning algorithm: descendent gradient. It is slower than LM, but it uses less memory [78,79]. |
| Lifespan Division | ANN Training Algorithm | Output Variable | MSEglobal | Rglobal | MIN and MAX MSE | MIN and MAX R |
|---|---|---|---|---|---|---|
| Starting point | LM | TMP | avg: 0.182 std: 0.001 | avg: 0.903 std: 0.0006 | 0.031; 0.639 | 0.623; 0.986 |
| ALF | avg: 0.124 std: 0.002 | avg: 0.935 std: 0.0009 | 0.015; 0.899 | 0.568; 0.993 | ||
| NME | avg: 0.110 std: 0.0008 | avg: 0.927 std: 0.0005 | 0.001; 0.496 | 0.727; 0.997 | ||
| BP | TMP | avg: 31.833 std: 13.102 | avg: 0.618 std: 0.013 | 0.053; 424.58 | 2.5 × 10−5; 0.973 | |
| ALF | avg: 28.133 std: 22.021 | avg: 0.675 std: 0.017 | 0.029; 460.52 | 0.0002; 0.988 | ||
| NME | avg: 69.322 std: 23.053 | avg: 0.333 std: 0.011 | 0.005; 668.16 | 8.6 × 10−6; 0.971 | ||
| Stationary regime | LM | TMP | avg: 0.196 std: 0.0001 | avg: 0.896 std: 8.5 × 10−5 | 0.093; 0.326 | 0.821; 0.952 |
| ALF | avg: 0.105 std: 5.5 × 10−5 | avg: 0.945 std: 3.0 × 10−5 | 0.041; 0.205 | 0.891; 0.979 | ||
| NME | avg: 0.129 std: 7.9 × 10−5 | avg: 0.932 std: 3.6 × 10−5 | 0.002; 0.299 | 0.839; 0.982 | ||
| BP | TMP | avg: 12.45 std: 12.84 | avg: 0.731 std: 0.042 | 0.109; 310.31 | 0.0002; 0.943 | |
| ALF | avg: 4.84 std: 11.96 | avg: 0.817 std: 0.041 | 0.057; 234.28 | 0.0005; 0.970 | ||
| NME | avg: 41.15 std: 39.82 | avg: 0.526 std: 0.015 | 0.015; 946.94 | 7.7 × 10−5; 0.972 | ||
| Shutdown point | LM | TMP | avg: 0.213 std: 0.0004 | avg: 0.886 std: 0.0003 | 0.018; 0.503 | 0.705; 0.991 |
| ALF | avg: 0.112 std: 0.0003 | avg: 0.941 std: 0.0001 | 0.010; 0.283 | 0.850; 0.996 | ||
| NME | avg: 0.184 std: 0.0003 | avg: 0.897 std: 0.0001 | 0.001; 0.462 | 0.742; 0.998 | ||
| BP | TMP | avg: 11.36 std: 17.93 | avg: 0.730 std: 0.033 | 0.047; 342.54 | 0.0008; 0.976 | |
| ALF | avg: 14.34 std: 27.38 | avg: 0.742 std: 0.025 | 0.017; 634.69 | 5.1 × 10−5; 0.991 | ||
| NME | avg: 11.36 std: 17.93 | avg: 0.581 std: 0.015 | 0.006; 725.00 | 2.3 × 10−5; 0.990 | ||
| All data | LM | TMP | avg: 0.80 std: 0.25 | avg: 0.70 std: 0.26 | 0.241; 0.990 | 0.061; 0.890 |
| ALF | avg: 0.83 std: 0.15 | avg: 0.82 std: 0.03 | 0.534; 0.945 | 0.772; 0.909 | ||
| NME | avg: 0.50 std: 0.32 | avg: 0.83 std: 0.08 | 0.131; 0.969 | 0.730; 0.932 | ||
| BP | TMP | avg: 1.07 std: 0.04 | avg: 0.30 std: 0.18 | 1.020; 1.160 | 0.084; 0.585 | |
| ALF | avg: 0.88 std: 0.08 | avg: 0.79 std: 0.06 | 0.756; 0.996 | 0.612; 0.833 | ||
| NME | avg: 2.75 std: 0.23 | avg: 0.30 std: 0.22 | 2.359; 3.252 | 0.061; 0.649 |
| ANN Training Algorithm | Lifespan Division | Data Type | MSE | R |
|---|---|---|---|---|
| LM | Starting point | Clustered | TMP: 9.939 ALF: 0.083 NME: 0.014 | TMP: 0.977 ALF: 0.996 NME: 0.999 |
| All data | TMP: 73.18 ALF: 5.39 NME: 0.54 | TMP: 0.809 ALF: 0.867 NME: 0.913 | ||
| Stationary regime | Clustered | TMP: 14.37 ALF: 0.179 NME: 0.007 | TMP: 0.941 ALF: 0.989 NME: 0.999 | |
| All data | TMP: 53.12 ALF: 6.92 NME: 1.00 | TMP: 0.874 ALF: 0.733 NME:0.905 | ||
| Shutdown point | Clustered | TMP: 15.669 ALF: 0.1652 NME: 0.018 | TMP: 0.940 ALF: 0.991 NME: 0.998 | |
| All data | TMP: 48.58 ALF: 6.92 NME: 0.83 | TMP: 0.888 ALF: 0.757 NME: 0.839 | ||
| BP | Starting point | Clustered | TMP: 10.96 ALF: 0.077 NME: 0.012 | TMP: 0.975 ALF: 0.996 NME: 0.999 |
| All data | TMP: 139.13 ALF: 5.19 NME: 3.17 | TMP: −0.760 ALF: 0.779 NME: 0.818 | ||
| Stationary regime | Clustered | TMP: 14.06 ALF: 0.177 NME: 0.010 | TMP: 0.942 ALF: 0.989 NME: 0.999 | |
| All data | TMP: 141.94 ALF: 6.57 NME: 3.51 | TMP: −0.663 ALF: 0.782 NME:0.775 | ||
| Shutdown point | Clustered | TMP: 16.624 ALF: 0.158 NME: 0.020 | TMP: 0.935 ALF: 0.992 NME: 0.998 | |
| All data | TMP: 137.31 ALF: 6.60 NME: 3.53 | TMP: −0.542 ALF: 0.863 NME: 0.831 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Souza, A.M.F.d.; Soares, F.M.; Castro, M.A.G.d.; Nagem, N.F.; Bitencourt, A.H.d.J.; Affonso, C.d.M.; Oliveira, R.C.L.d. Soft Sensors in the Primary Aluminum Production Process Based on Neural Networks Using Clustering Methods. Sensors 2019, 19, 5255. https://doi.org/10.3390/s19235255
Souza AMFd, Soares FM, Castro MAGd, Nagem NF, Bitencourt AHdJ, Affonso CdM, Oliveira RCLd. Soft Sensors in the Primary Aluminum Production Process Based on Neural Networks Using Clustering Methods. Sensors. 2019; 19(23):5255. https://doi.org/10.3390/s19235255
Chicago/Turabian StyleSouza, Alan Marcel Fernandes de, Fábio Mendes Soares, Marcos Antonio Gomes de Castro, Nilton Freixo Nagem, Afonso Henrique de Jesus Bitencourt, Carolina de Mattos Affonso, and Roberto Célio Limão de Oliveira. 2019. "Soft Sensors in the Primary Aluminum Production Process Based on Neural Networks Using Clustering Methods" Sensors 19, no. 23: 5255. https://doi.org/10.3390/s19235255