1. Introduction
Attention is a process involving human factors. Human factors play a central role in the attentiveness determination process, especially when qualitative information and uncertainties are involved [
1,
2,
3,
4,
5]. Intuitively, attention is an essential process for starting social interaction between human beings. To begin giving attention in a social interaction, a person with whom to communicate must first be identified. Most people perform this selection subconsciously, i.e., they identify who, from those in a given room or group, is worthy of their attention. Likewise, an intelligent service robot has to select a person in the group before their bi-directional communication starts. Therefore, the robot is required to possess attention-selecting capabilities as a fundamental function based on human social expectations; when the robot is equipped with such capabilities, people can interact with it in the same way that they interact with other people [
6,
7,
8,
9,
10,
11]. However, humans often stay in groups instinctively for communication. Before starting a conversation, the speaker evaluates to their prospective communicators and selects one from among them with whom to communicate. For this reason, when the service robot communicates in a multi-person interaction, it also evaluates and prioritizes the attention of the prospective communicators members individually, in terms of their perceived attentiveness; this process is called attention prioritization. The robot then selects the person who has the highest attentiveness (i.e., the most attentive person) to be the person with whom it communicates.
Most attention systems are generally composed of two distinctive sections: (1) feature extraction and (2) an attention model. (1) Feature extraction extracts attention-related visual features (ostensive-stimuli) from an image sequence and/or audio features from a sound stream. Various visual features are often chosen to be used as stimuli for the attention system such as the distance between a robot and a person [
12,
13], the head direction of the people participating in an interaction [
14,
15,
16,
17,
18,
19], and/or visual speaking status detection [
20,
21,
22,
23,
24,
25]. When audio features are used for the attention model, the direction of a sound source and the distance to a sound source are usually adopted [
26,
27,
28]. (2) The attention model evaluates the selected stimuli and computes the attentiveness of each person. Finally, the most attentive person, as well as the attention priority of the individuals, in terms of their attentiveness, are determined. Intuitively, a robot equipped with an attention system can be considered to be more flexible and effective in their interactions with humans compared to the robot without one.
Overall, most previous methods have employed either a set of event conditions, heuristic equations, or both, such that the methods operate under predefined parameters and rules. However, the heuristic approaches presented in the literature are often susceptible to noisy observations and may produce frequent undesired attention shifts by the robot. Furthermore, their performance also suffers when they must contend with changes in the number of persons and observations, as they have difficulty adapting the state numbers accordingly in real-time.
To overcome such difficulties, a novel attentiveness determination approach based on relevance theory [
29] is introduced. The relevance theory describes how humans communicate with each other and how a person evaluates the attention of other people during interaction exchanges. Thus, this theory was applied and converted to a mathematical form that aims to determine the most attentive person and prioritize people according to their relative attentiveness. Thus, a model was developed which aims to determine the most attentive person and prioritize people according to their relative attentiveness. The proposed approach consists of
a Scalable Hidden Markov Model (Scalable HMM) for attentiveness determination and
a probabilistic approach to compute the relevance for stimuli. The Scalable HMM has a scalable number of states and observations, and online adaptability for state transition probabilities with respect to changes in the current number of states. To test the proposed approach, the Scalable HMM was applied to 10 image sequences (7567 frames) of individuals exhibiting a variety of actions (speaking, walking, turning head, and entering or leaving a robot’s view). The detection rates achieved by the proposed approach, for both determination of the most attentive person and for people attention prioritization, were obtained and compared to those by recent robot attention model approaches.
The remainder of the paper is organized as follows.
Section 2 reviews related research.
Section 3 introduces a probabilistic stimuli-relevance computation approach based on relevance theory. The Scalable HMM-based attentiveness determination method is described in
Section 4. Experimental results and the conclusions are discussed in
Section 5 and
Section 7, respectively.
2. Related Work
In the past decade, several researchers have integrated psychological studies into robotics research. Such works have estimated the mental states of other people by observing their behaviors and aimed to design a robot with human-like attention capabilities [
30,
31,
32,
33,
34]. Psycholinguistic studies revealed that speaking status plays an important role in attention, in that a listener’s visual attention is driven by what they hear [
35,
36]. As a result, the speaking status is usually considered as a fundamental feature of a robot’s attention system [
37,
38,
39,
40,
41,
42]. Robot attention models can be categorized into two groups: those which rely on fixed rules and those which rely on arithmetic equations. When fixed rules are employed based on a logical set of event conditions, the satisfaction of a given measure leads to the model selecting a person as the most attentive person. Use of adopted arithmetic equations involves computation of the attentiveness of each person; finally, people prioritization can be determined by a comparison of the computed attentiveness.
In an approach that utilized a set of event conditions based on locations of a sound source and human face [
37], an attention system was proposed for receptionists and companion robots. The system operated under the assumption that there is a single sound source at a time. The rules for the selection of the most attentive person are defined as follows:
if the location difference between a located sound source and a detected human face in the robot’s view is within
, the system associates the sound source with the human face. The person belonging to the associated face is determined as the most attentive person;
if the location difference changes such that it exceeds
for three seconds, the system dissociates the sound source from that detected face, and the robot then loses its focus on the most attentive person;
step
and
are repeated.
A few years later, a focus of attention (FOA) system based on a detected speaking person was proposed [
38]. Their method applied a multi-modal anchoring [
39] for tracking a person of interest (POI). The only speaking person, who is facing the robot, can assume the role of POI. The event conditions are as follows:
a robot determines a speaking person as the POI (i.e., the most attentive person);
as long as the speech of the POI is anchored, other speaking people are ignored;
when the POI stops speaking for more than two seconds, the POI loses its speech anchor and another person can become the POI;
if no other person appearing in the robot’s view is speaking, the previous POI remains the most attentive person.
POI selection based on the gazing direction of a human face and a sound source location [
40] was presented. However, people attention prioritization cannot be achieved in this case. In short, the face direction validates detected sounds as voices and the robot only gives attention to a person facing the robot. The logical set of event conditions for selecting the most attentive person is as follows:
there is a person facing a robot;
a sound source is located and associated to the detected face;
the person associated with the detected face and sound becomes the speaking person and the POI.
A parameter of intimacy to determine the selection priority of an interactive partner using interaction distance was also proposed [
41]. This proposed method is based on the concept of proxemics for communication between a robot and multiple people. Proxemics suggests that the more intimate the communication, the nearer the target person stands. Interaction distance is roughly classified into four groups: intimate distance, personal distance, social distance, and public distance. A person with the highest intimacy is determined as the most attentive person for an interaction, with parameters of the intimacy equation pre-defined heuristically.
A value representing the attentiveness of a person was presented by Bennewitz et al. [
42]. This value is computed by a weighted sum of three multimodal factors where the weights are constant and heuristically decided. Three factors are:
the time when the person last spoke,
the distance of the person to the robot (estimated according to the size of a bounding box around a person’s face), and
the person’s location relative to the front of the robot. The person with the highest value is determined as the most attentive person and is given the robot’s focused attention of attention of the robot. Attention prioritization is then simply achieved by sorting the magnitude of the computed values.
4. Attentiveness Determination Using Scalable Hidden Markov Model
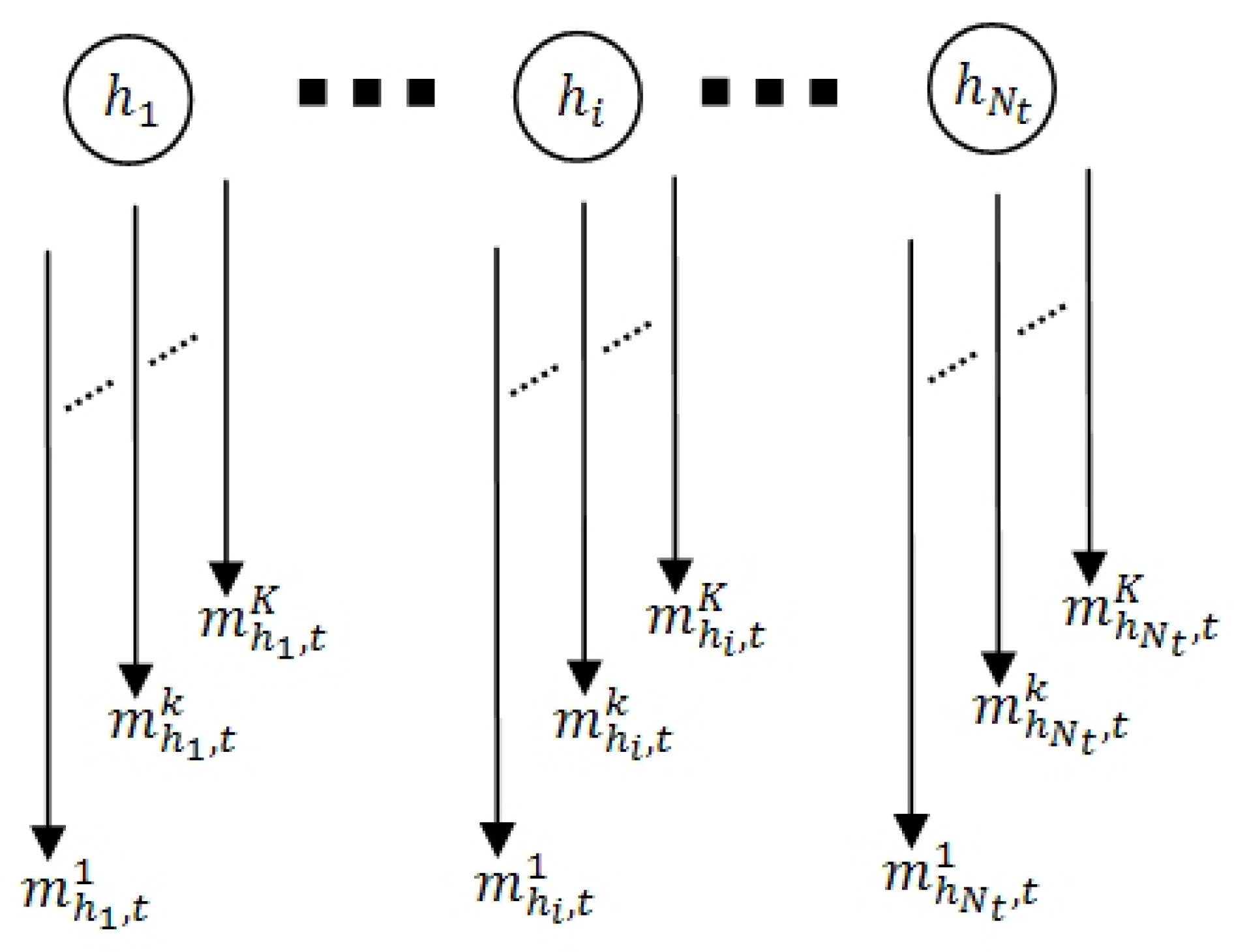
In this section, a Scalable HMM, based on the relevance theory, for attentiveness determination is described. The Scalable HMM recalls a similar approach [
43]. Both the proposed model and the dynamic HMM are able to handle changes in the number of states during run-time. Differently, our proposed Scalable HMM is also capable of coping with changes in the number of observations attributed to changes in the number of states.
Figure 3 depicts the main processes of the proposed approach in five parts. First, the probabilistic attentiveness computation based on stimuli-relevance (
Section 4.1) presents the method by which the stimuli-relevance probabilities are computed using the three ostensive-stimuli (distance from person-to-robot, angle of a person’s head pan and a person’s speaking status). Next, an online probabilistic attentiveness analysis (
Section 4.2) demonstrates the probabilistic computation between the previous and current states, for the case in which the number of detected persons changes.
Section 4.3 explains how the most attentive person is selected and the attention prioritized in run-time. Finally,
Section 4.4 describes how the Scalable HMM-based attention model is applied, using Particle Swarm Optimization (PSO), to the robot attention model.
4.1. Probabilistic Acomputation Based on Stimuli-Relevance
Probabilistic attentiveness computation from three ostensive-stimuli (introduced in
Section 3.2) is thoroughly explained in two parts: (1)
Section 4.1.1 describes how stimuli-relevance probabilities from two stimuli (a person-to-robot distance and angle of a head pan) are obtained; (2)
Section 4.1.2 depicts the adaptable state transition probabilities, which are used to flexibly consider state transition probabilities in run-time and thus increase efficient attentiveness determination for the robot attention model. In consideration of state transition probabilities, a person’s speaking status, as well as the number of persons in camera view, are used to determine probabilistic attentiveness in run-time. Then, the probabilistic attentiveness is used to determine the most attentive person and arrange people attention prioritization, as discussed in the following sections.
4.1.1. Probabilistic Stimuli-Relevance Computation
As discussed in
Section 3.1, an ostensive-stimulus both attracts the attention of a robot and tries to convey to the robot the meaning intended by the communicators. Because ostensive-stimuli are noisy, the probabilistic approach is considered as a potentially superior alternative to computing the stimuli-relevance of a given person.
In particular, human’s relevance computation here consists of two fundamental properties. The first is the attraction of ostensive-stimuli, wherein a person’s intention to communicate is conveyed through the emission of stimuli in the form of probability density function (pdf). The other is restraint of ostensive-stimuli, wherein a person has no intention to emit particular stimuli, and is also in the form of pdf. Considering
and the ostensive-stimuli vector of any person
, the probabilities of attraction,
, and restraint,
, can be defined by
where
and
denote the attraction and the restraint distributions of the
kth ostensive-stimulus, respectively.
From cognitive psychology, attention is the behavioral and cognitive process of selectively concentrating on a discrete aspect of information [
44], whether deemed subjective or objective, while ignoring other perceivable information. Building on this, we define a state variable,
, where a person
has an intention to start communication with the robot while others have no intention to do it. Consider
as a group of participating people. Using Equations (
1) and (2), the probability of relevance of the ostensive-stimuli of given a state
,
, is defined as follows:
For example, if the current number of participating people is
, Equation (
3) becomes:
Note that Equations (
1)–(
3) illustrate good scalability in the sense that
adapts efficiently with respect to the number of participating people and observations in run-time. As a result, effective computation of attentiveness of people can be achieved.
4.1.2. Online Adaptable State Transition Probabilities
This section introduces online adjustable state transition probabilities based on the speaking statuses of participants. Speaking statuses of persons are used as the conditional parameter in the model. Furthermore, the current number of participants are also taken into account. Hence, an effective and improved computation of attentiveness can be achieved in terms of sensitivity and adaptability with respect to speakers and changes in the number of participants.
Let us denote
as the speaking statuses of person
at time
, where NS is the non-speaking status and SP is the speaking status. The state transition probability distribution given a person’s speaking status,
, is denoted by
where
and
define the sensibility parameters of the attention model, influencing the sensitivity of the robot’s attention shifts with regard to the speaking and non-speaking persons during run-time. Further,
is the dimension of the state transition matrix.
The state transition matrix is now designed such that the transition to the same person (state) is or times more likely than the transitions to other persons, conditioned according to the previous speaking status of that person, whether it was non-speaking or speaking, respectively. Note also that , and R is a normalizing constant used to ensure that each row of the state transition matrix sums to 1.
4.2. Online Probabilistic Attentiveness Analysis
Relevance theory states that a person retrieves relevance assumptions stored in their memory (knowledge of ostensive-stimuli with respect to a situation) and processes them with an inferential procedure to draw a conclusion.
To implement this procedure into the robot’s attention model in a similar manner, the inferential procedure can be mathematically emulated by statistical inference. The inference is performed by using quantitative data. A greater informativeness quantity results in better accuracy of inference.
For the analysis of attentiveness of a person
until the current time
t, we consider the probability of relevance of the partial observation sequence until time
t,
and state
given a robot’s attention model
. This yields:
Efficiently, we can solve for
from Equation (
6) inductively, as follows:
- (1)
- (2)
Induction
- (2.1)
Validation
- -
Checking the current number of participants.
- -
Iterating over states at and t for states comparison and validation.
Correcting state indexes, if required.
- (2.2)
Computation
case 3:
where
is the initial state distribution of Scalable HMM for the attention model, and
are the state transition probabilities.
Figure 4 illustrates the induction procedure, showing how state
can be reached at time
t from the
possible states at previous time
. Prior to
computation, the validation process (Step (2.1)) must be performed at each induction step. The process, which has
computational complexity, validates the current number of states (the participants in a robot’s view). In the case of a decrease in the number of participants, an index re-correction of the participants may be required, such that computation failure can be avoided in run-time.
4.3. Online Most Attentive Person Selection and People Attention Prioritization
For selecting the most attentive person and prioritizing people based on their attentiveness, the proposed attention model first evaluates the probabilistic stimuli-relevance of participants. Next, the probabilistic attentiveness of each person, , is computed.
Finally, the most attentive person, denoted by
, is determined as the person with the maximum attentiveness. Hence,
is denoted by
By comparing
for current participants at
t, the prioritization of participants with respect to their attentiveness can be achieved.
4.4. Learning Approach for Scalable HMM-Based Attention Model Using Particle Swarm Optimization
In general, the HMM parameters are estimated using the Baum–Welch algorithm [
45]. However, it is well known that the Baum–Welch algorithm easily converges to local optimum solutions. To find the global solution or better optimum solutions, estimating HMM parameters using Particle Swarm Optimization (PSO) [
25,
46,
47] has been an alternative method, showing superior results compared to the conventional Baum–Welch method. Further, the PSO algorithm also provides a simple method for solving complex optimization problems. Therefore, we apply a training approach based on PSO for our robot attention model.
The PSO-based learning approach is briefly introduced in this section. Let us denote as a vector of system parameters to be estimated, where and are the means and variances of attraction and restraint distributions of ostensive-stimuli, , respectively.
In the PSO-based learning approach, the model is encoded into a string of real numbers. The vector acts as a particle, representing the position vector . With each position vector , there is an associate velocity vector , modeling the capacity of the particle to move from a given position at the zth iteration to another position in a successive iteration of the space solution sampling process.
The initial positions
and their velocities
of
particles of the swarm can be randomly generated [
48]. The ranges can differ for different dimensions of particles.
The degree of optimality of each particle is evaluated at the
zth iteration by computing its
. The fitness function is defined as follows:
where
is the
observation sequence. The previous best particle,
pbest, storing the best position that has been reached up to now by the
ith particle, is found by
. Next, the global best particle,
gbest, which is the optimum position in the overall swarm, can be computed by
.
The velocity of the
of each particle is updated with dynamic inertia as follows:
where
and
are two uniformly distributed random positive numbers, used to provide the stochastic weighting.
w is the inertia weight, affecting the influence of the old velocity on the new velocity.
and
are constants, called cognition and social acceleration, respectively. Next, the particle position is then updated as follows:
The velocity and position updating, and the optimization process are stopped when the condition of termination is satisfied. Finally, gbest is assumed to be the optimum solution for the model.
The terminating condition is that the maximum number of iterations, , is reached () or the increase of the optimum fitness is below a given threshold (i.e., ).
6. Results
The human mind is a complex entity that represents a particular characteristic of people [
51]. Every person has an individual opinion regarding who is the most attentive person during an interaction. Because of this, the common ground truth for determining the selection criteria for the most attentive person is difficult to practically determine.
Hence, to evaluate the proposed attention model, attention evaluation experiments were conducted with people. In these human evaluations of the most attentive person including attention prioritization were obtained. Ten users participated with the experiments on the same 10 image sequences used for testing the proposed attention model with the robot as the attention evaluator. They were asked to watch videos of image sequences of interacting people (see
Figure 6), to evaluate who is the most attentive person, and prioritize people based on attentiveness. The users were also asked to consider only speaking statuses, distance, and head pan for the evaluation of attentiveness. Finally, for each image sequence, the most likely outcomes of the human evaluation were obtained by finding the maximum among user decisions.
The probabilities of detection (), false alarm (), and attention shift during intervals () were used as performance indicators. indicates the attention model’s performance regarding the detection of the most attentive person and the detection of people prioritization with respect to attentiveness. Let us denote as the ratio of the frames where the most attentive person is correctly detected to the total number of frames with the most attentive person. is the ratio of the frames where people’s attention is correctly prioritized to the total number of frames.
is the ratio of the frames where a person who is not the most attentive person is incorrectly detected as the most attentive person to the total number of frames where the given person is not the most attentive person. Finally,
is calculated as follows:
where
N is the total number of participants. MP and
refer to “the most attentive person” and “not the most attentive person,” respectively.
In the experiments with our proposed attention model, the model parameters were estimated with the PSO approach described in
Section 4.4 using the training data (sequences of the observed ostensive-stimuli of people: speaking statuses, person-to-robot distance, and head-pan angle).
In the experiments with the two other attention methods, i.e., the set of event conditions [
38] and the heuristic equations [
42], the respective parameters of each approach were determined according to recommendations described in their studies. The same observations used in our proposed method were also used in these two approaches. A brief description of each approach is provided in
Section 1.
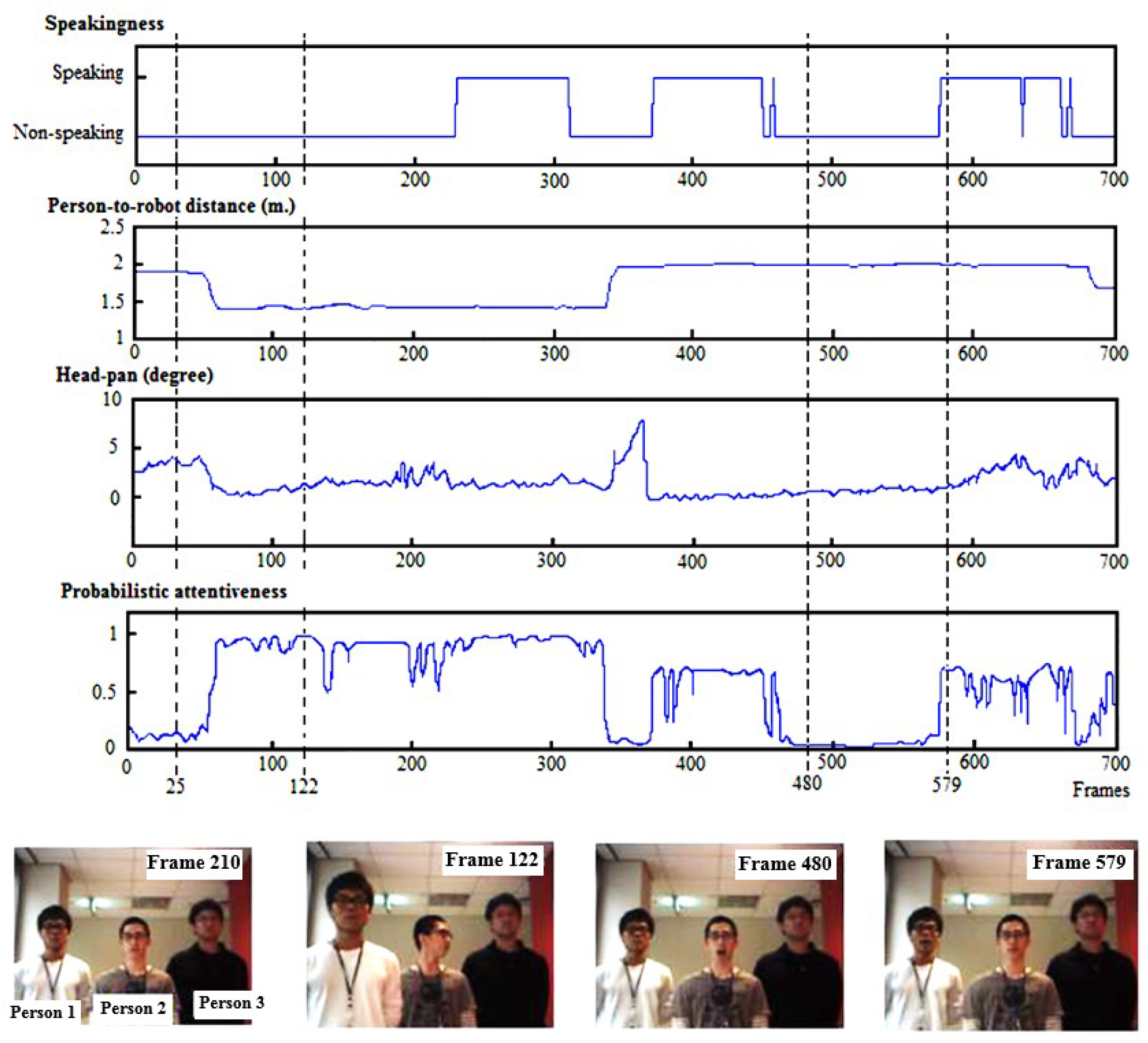
Figure 9 demonstrates the observed ostensive-stimuli of a single person (person 1) from one of the image sequences. The first three graphs from the top depict the detected speaking status of person 1, the person’s estimated distance from the robot in meters, and the estimated head-pan angle in degrees over time, respectively. The fourth graph illustrates the probabilistic attentiveness result of person 1, computed by the proposed attentiveness computation model. Sample images on the right side of the figure illustrate the action sequences of people in this image sequence, in which the people are labeled as person no. 1, person no. 2, and person no. 3.
In frame 25, person no. 1 was approximately away from the robot and was looking relatively straight at the robot. He had a respectively low attentiveness of . Next, in frame 122, his attentiveness became higher () because he came closer to the robot ( away). At frame 480, person no. 1 had a very low attentiveness of because he was very far away from the robot (), even though he looked straight at the robot. However, his attentiveness rose gradually as he spoke, and his attentiveness became at frame 579.
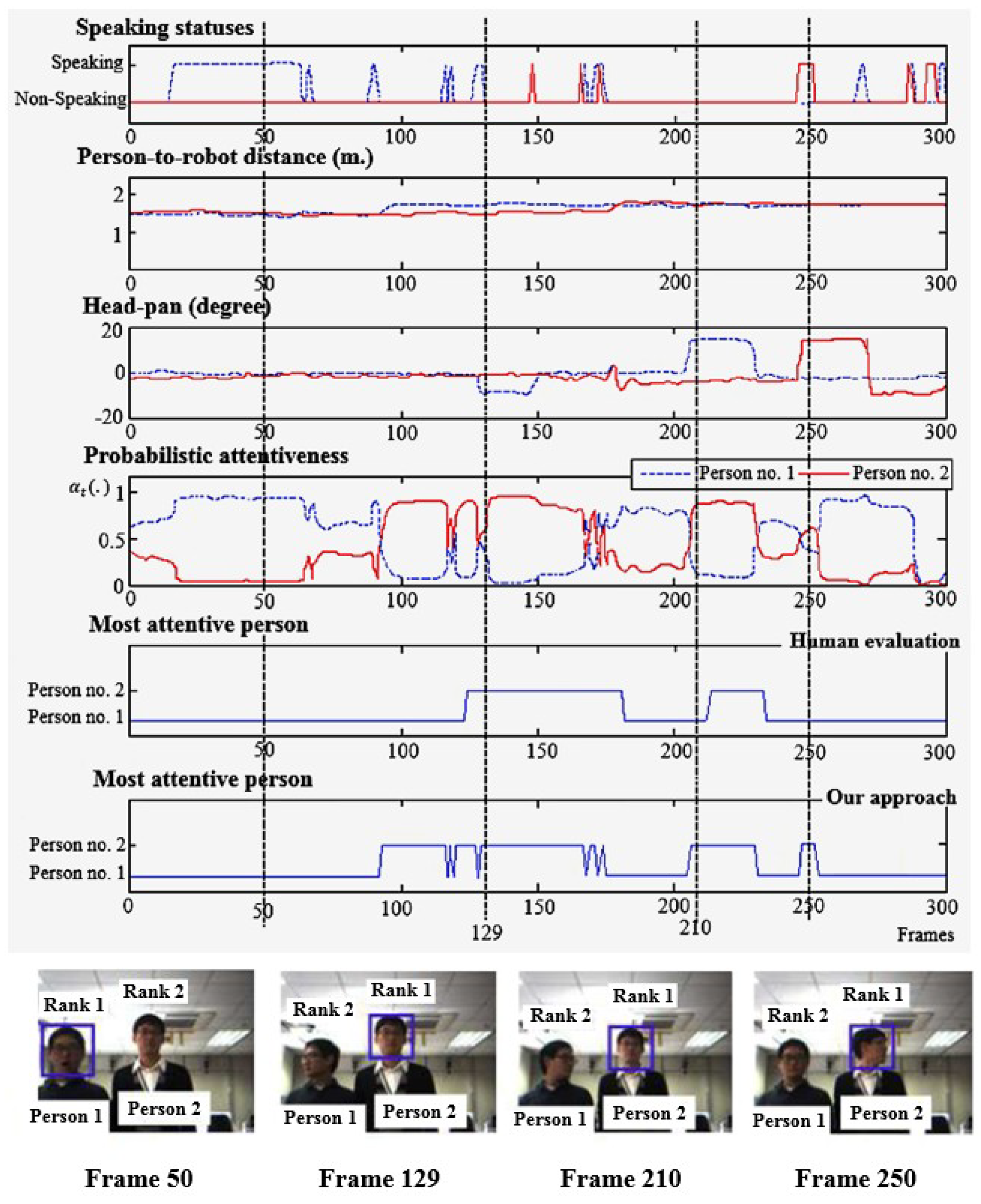
Figure 10 illustrates the attention outcomes of one image sequence of a situation of two participants and the observed ostensive-stimuli of each person. The sample images of the sequence are also shown at the bottom of the figure. The most attentive person is indicated by a rectangle, and the attentiveness ranking is labeled by a number above each person.
At frame 50, person no. 1 was detected as a speaking person. His attentiveness became larger than the attentiveness of person no. 2. Examining frames 100 to 120, the proposed attention model chose person no. 2 as the most attentive person, while human evaluation considered person no. 1 as the most attentive person. The outcomes were different because both participants were located at similar distances, making it difficult for people to determine whether person no. 1 or person no. 2 was closer. Consequently, the most attentive person selection based on distance becomes critical. However, in the case of attentiveness quantification by a robot, the distance is computed as a real number, so determining the closest person among participants is an easy task.
At frames 129 and 210, the participant (person no. 1) turned his head and looked away from the robot. This resulted in a decrease in his attentiveness, and made another participant become more interesting to the robot. As a result, the other participant’s attentiveness significantly increased. Frame 250 demonstrates a possible error in the selection of the most attentive person caused by consecutive false speaking status detection.
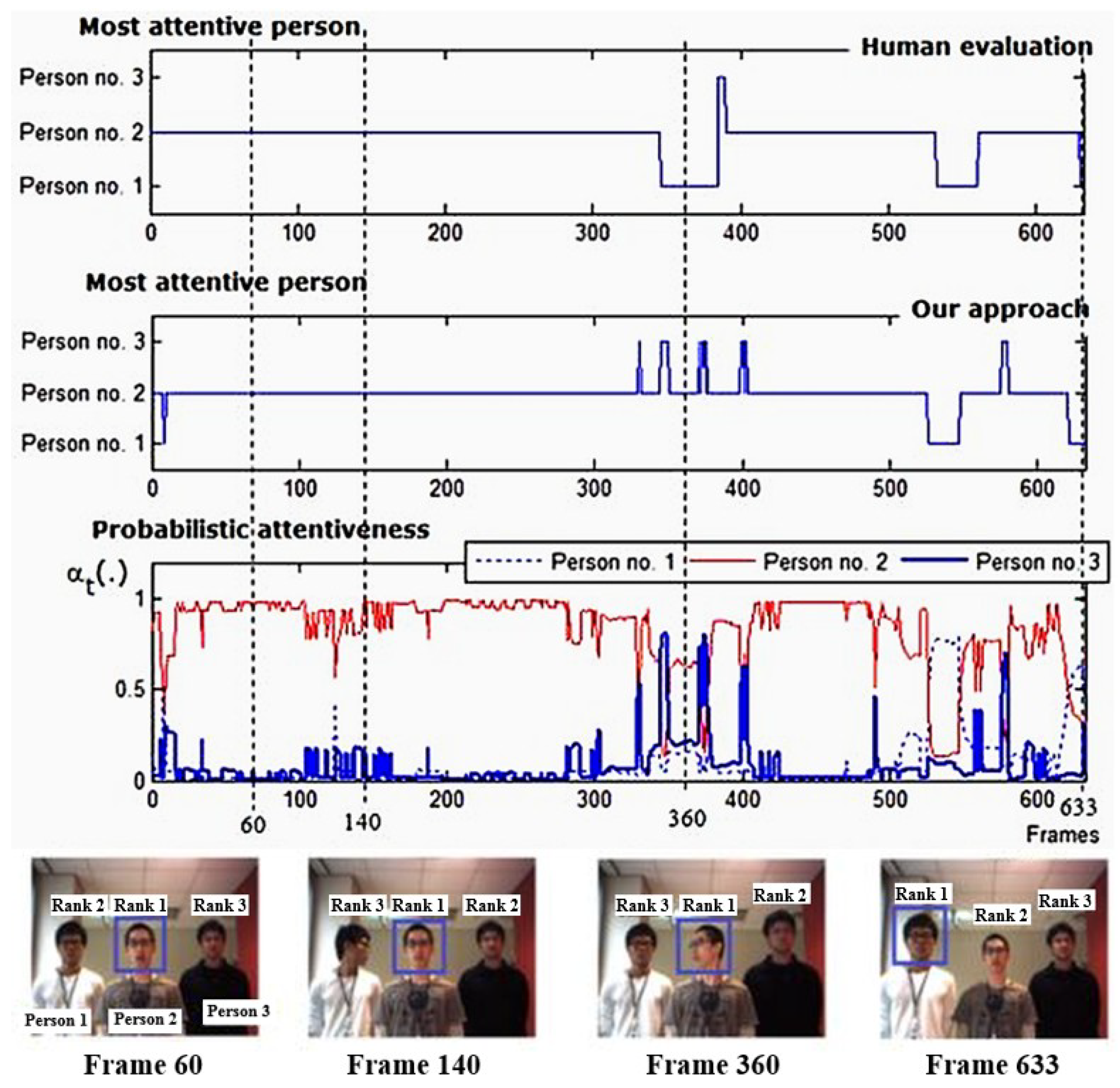
Figure 11 depicts the attention outcomes of one image sequence of a situation of three participants. The middle graph shows the selection of the most attentive person over time compared to the human evaluation, which is illustrated in the top graph. The bottom graph depicts the computed probabilistic attentiveness of participants in the robot’s view.
In frames 350–370 (
Figure 11), the proposed attention approach chose person no. 2 as the most attentive person instead of person no. 1, and there were several undesired attention shifts. These were caused by continuous errors in the estimated observations. These errors were due to consecutive errors in the estimation of the head-pan angles of person no. 2. Hence, despite the effective probabilistic attentiveness computation for the most attentive person selection and people attention prioritization, our approach cannot withstand extreme error in observations if the error occurs continuously for a long period of time.
The proposed approach performed well, as expected in terms of determining the most attentive person (
Figure 10 at frames 50, 129, and 210, and
Figure 11 at frame 60, 140, and 663). Even when there was no speaking person present, the proposed approach was able to determine the most attentive person, such as in frames 70–300 in
Figure 10 and in frames 140 and 663. In the absence of a speaking person, the transition probabilities of the robot’s FOA become equally well-distributed according to the adaptable state transition probabilities described in
Section 4.1.2. As a result, the selection procedure of the most attentive person is efficiently conducted and altered by other visual features.
Figure 12 depicts the attention outcomes of one image sequence of a situation, in which there is a change in the number of participants. At the beginning, there were two participants in the robot’s view. Our proposed attention approach prioritized these two persons with respect to the computed attentiveness. Starting from frame 289, a new person appeared and stayed in the robot’s view. The current number of people in a robot’s view became three. That person was included automatically and seamlessly into the attention model, and his attentiveness was calculated and compared with those of the other participants. This confirms the scalability of our proposed attention model based on the Scalable HMM in terms of the change in the number of people and observations. The model scalability also applies to situations with a decreasing number of participants.
The set of event conditions [
38] for the determination of a robot’s FOA are listed as follows:
If the robot detects a speaking person, the speaker becomes the most attentive person.
As long as the person is speaking, the speaking of other people is ignored.
When the attentive person stops talking for more than two seconds, the robot loses its anchor on that person as being the most attentive person.
Only a speaking person can take over the role of the most attentive person.
For the heuristic approach, the weighted sum approach [
42] is tested. Five sets of pre-defined weights (
Figure 13) for the three ostensive-stimuli were investigated to explore the approach’s performance, where
is a set of weights, and
,
, and
are weights for distance, head-pan angle, and speaking status, respectively.
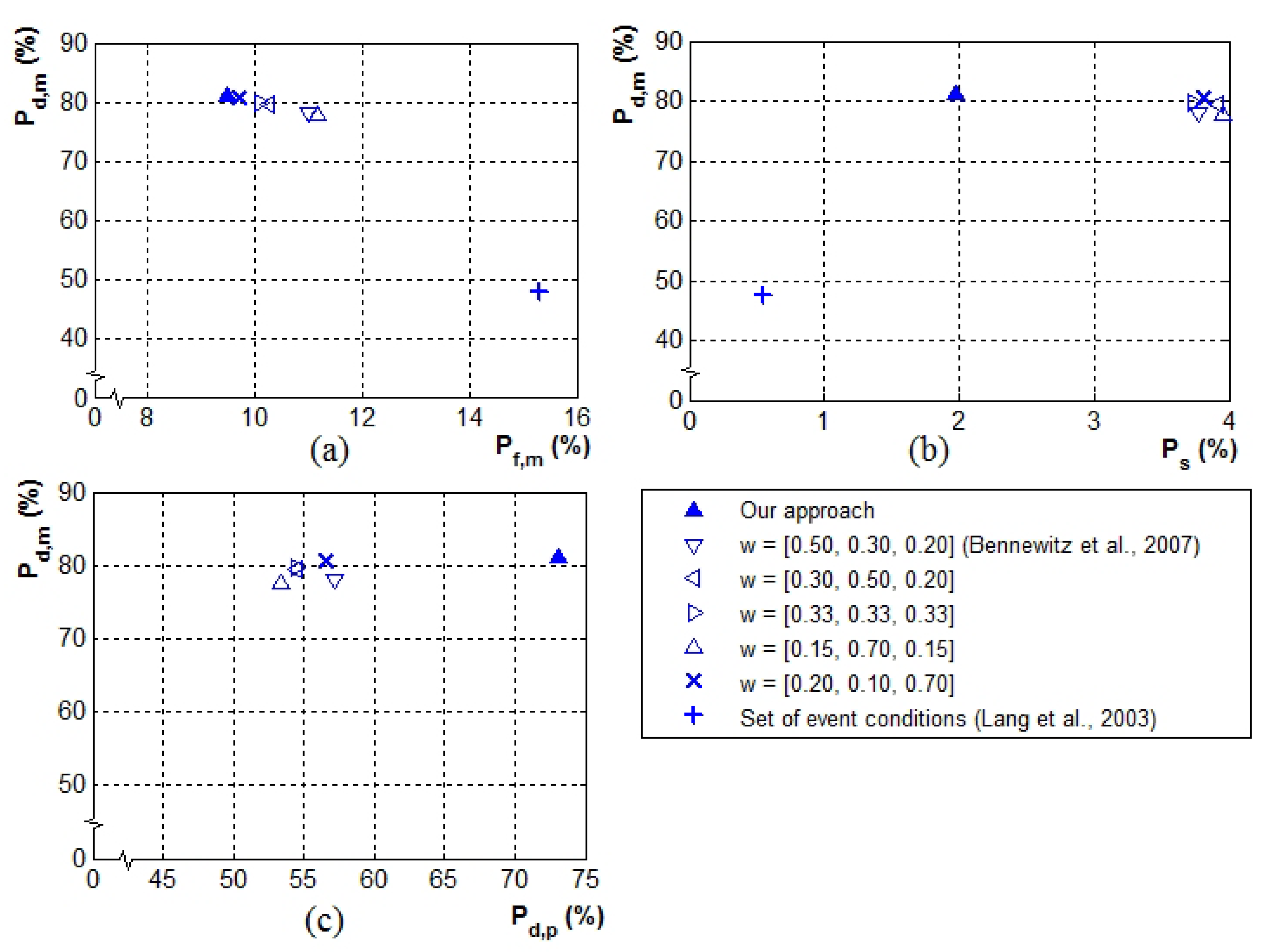
The performance comparison in terms of the most attentive person selection using the receiver operating characteristic (ROC) space is shown in
Figure 13a,b. The ROC curve is a graphical plot which illustrates the performance of a system via the comparison of two relative operating characteristics [
52,
53].
Figure 13c shows a performance comparison with respect to both the most attentive person selection and people attention prioritization. The plots show that our proposed robot attention model outperforms these two heuristic attention approaches.
Our attention model succeeded in obtaining a high detection rate of the most attentive person (≈76% of ) and the highest detection rate of people attention prioritization (≈75% of ) compared to the other two approaches. The proposed approach also achieved a small rate of attention shift during intervals, , which was only (≈2%). Additionally, was improved by over compared to Lang et al.’s approach (the approach using the set of event conditions) and by almost compared to Bennewitz et al.’s weighted sum approach. Compared to the other two attention approaches, the proposed approach had significant improvement of almost regarding and approximately regarding .
For the approach using the set of event conditions [
38], although it achieved a very small rate of
(≈1%), an extremely low rate of
(≈47%) and a rather high rate of
(≈16%) resulted.
could not be calculated in this case because the designed event conditions were too simplified and did not cover the issue of people attention prioritization.
Considering the performance of the weighted sum approach [
42], for all five weight sets, there were similar performances despite the differences in weight sets (≈73% of
, ≈54 of
,
of
, and
of
). This indicates that a fixed weight distribution of stimuli did not guarantee the optimum performance of the attention model. The approach with one fixed weight set might result in a high detection rate of the most attentive person, but may deliver a low detection rate of people attention prioritization, with high susceptibility to frequent undesired attention shifts, or vice versa. This implies that with the heuristic equation approach, the determination of suitable parameters that ensure the optimum trade-off between the hit rate and false alarm rate is critical.
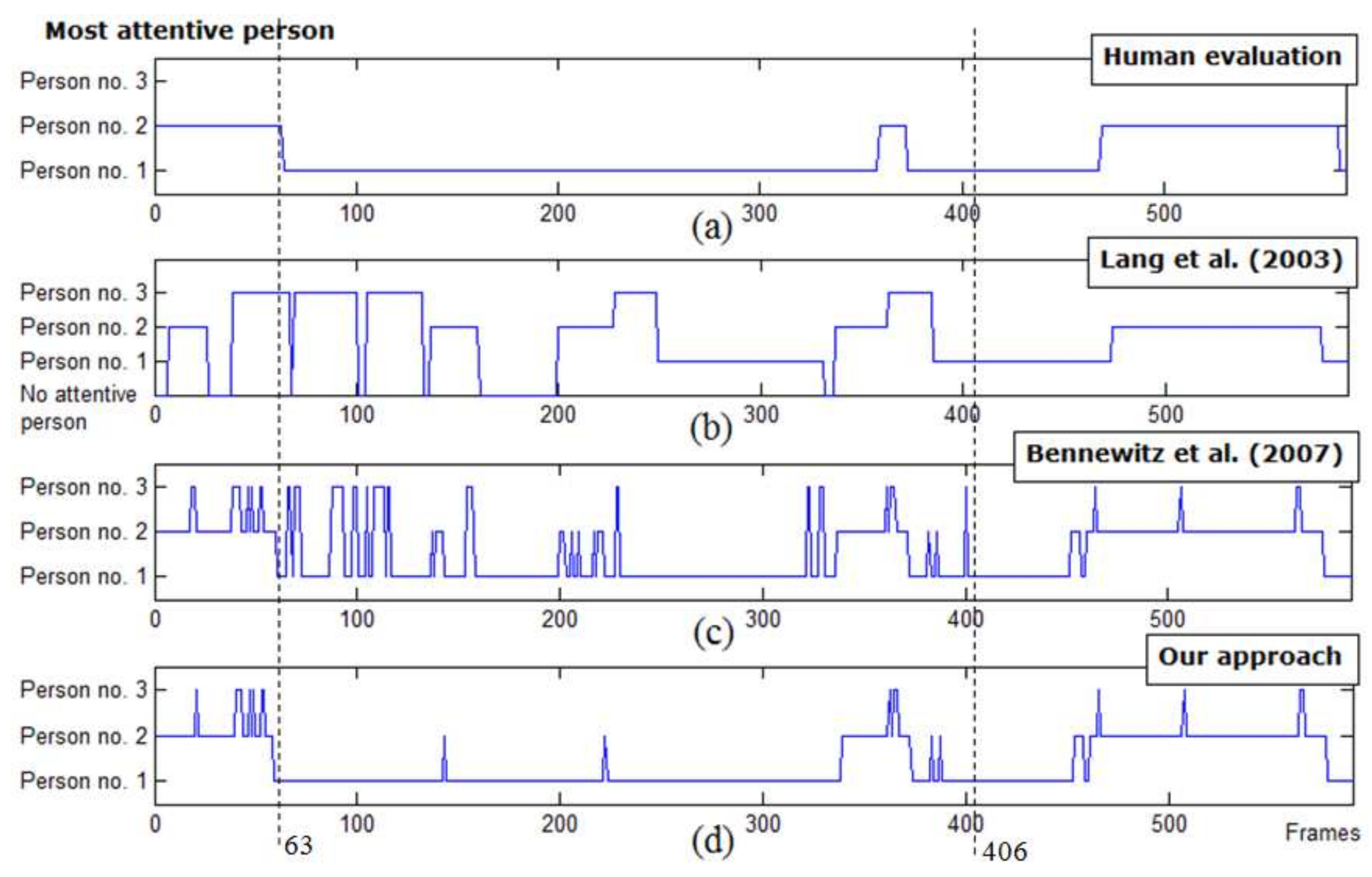
Figure 14 depicts the most attentive person selection outcomes of Lang et al.’s approach (the set of event conditions), Bennewitz et al.’s approach (the weighted sum approach), and our proposed approach tested on one image sequence of the three-person situation, compared to human evaluation.
The first graph (
Figure 14a) illustrates human evaluation of the most attentive person. The second graph (
Figure 14b) depicts the result of Lang et. al.’s approach. Note that, compared to
Figure 14c,d, there were several noticeable undetermined intervals of the most attentive person in
Figure 14b (i.e., losing attention from the most attentive person). Specifically, these occurred during intervals in which no speaking person was detected. As a result, the attentive person was not unable to be determined by the proposed method.
The third graph (
Figure 14c) depicts the result of Bennewitz et al.’s approach (
). Next, the fourth graph (
Figure 14d) shows the result of our proposed method. Considering frames 63–406 in
Figure 14b–d, as expected from the probabilistic approach, several undesired attention shifts were moderated while correct detections of the most attentive person were maintained.
7. Conclusions
A novel vision-based attentiveness determination method has been presented to improve a robot attention model’s performance in determining the most attentive person and prioritizing people based on attentiveness. Additionally, the effective computation of attentiveness and adaptation to changes in the number of participants and observations was accounted for in the proposed method. The proposed approach is based on relevance theory, a human communication methodology that explains how people evaluate the attention of other people during interactions.
The proposed approach consists of a computation method for probabilistic stimuli-relevance and Scalable HMM, an attentiveness determination model for most attentive person selection and people attention prioritization. Unlike the conventional HMM, the Scalable HMM has a scalable number of states and observations, and online adaptability of the state transition probabilities with respect to changes in the number of states. Furthermore, for effective attentiveness determination, the speaking status of people was employed as conditional parameter for adaptable state transition probabilities, unlike most previous attention approaches. A better, more robust attentiveness determination was achieved, wherein the selection of the most attentive person could be conducted even in situations where no speaking person was detected. By employing online forward analysis, the probabilistic attentiveness of each person can be determined in real-time with low computation cost. A comparison of the computed attentiveness of people yielded the most attentive person selection and the people prioritization based on their attentiveness. The parameters of our proposed approach can be efficiently and conveniently learned based on PSO, such that good resistance to noisy observations and a good performance rate was achieved. The approach was successfully tested on 10 image sequences (7567 frames) with encouraging experimental results (≈76% accuracy in most attentive person detection and more than accuracy for people attention prioritization). Additionally, the proposed method works robustly online in various lighting conditions and with changes in the number of participants. Compared to the two other more conventional attention approaches, improvements of nearly in people attention prioritization and in resisting undesired attention shifts were achieved. Overall, the most optimal performance was presented with the proposed method.
Despite being sufficiently robust in lighting variation, low-resolution images, and noisy observations, the proposed vision-based attentiveness determination for the most attentive person selection and people attention prioritization cannot operate well under extremely poor lighting conditions; in such conditions, image noise is high, resulting in extreme error in observations and a poor performance rate with the proposed model. Hence, in order to improve the model’s efficiency, additional ostensive-stimuli could be included into the attentiveness determination model, such as hand gestures, facial expression, and natural language that can be trained using various deep learning architectures in [
54,
55]. Furthermore, to succeed in imitating a more human-like the attention system, a robot’s head-eye control system and audio information could also be incorporated with visual information. In this manner, the robot could consider both vision and sound for its decision-making process, as humans do, thus improving its human likeness.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













