Ear Detection Using Convolutional Neural Network on Graphs with Filter Rotation



Abstract
:1. Introduction
1.1. Ear Detection
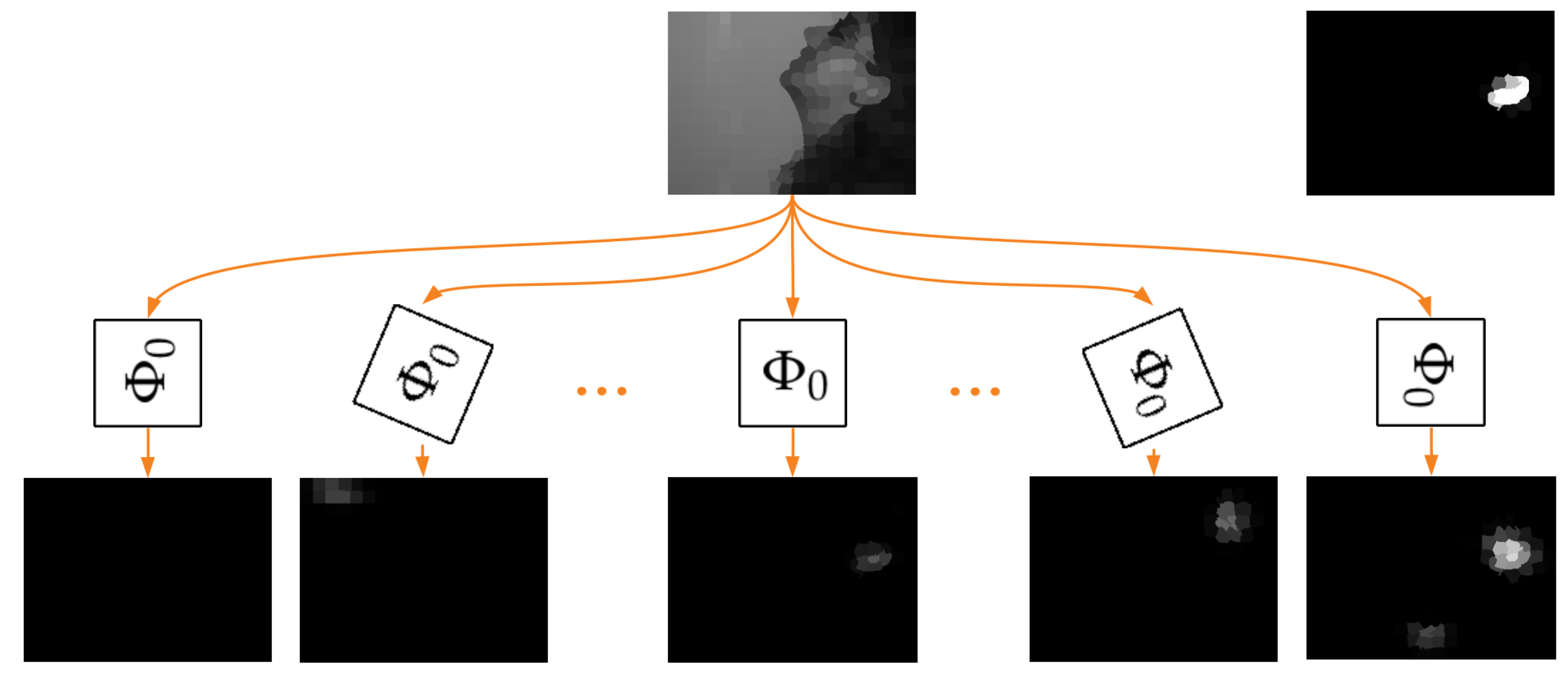
1.2. Rotation Equivariance
1.3. Geometric Deep Learning
1.4. Contribution
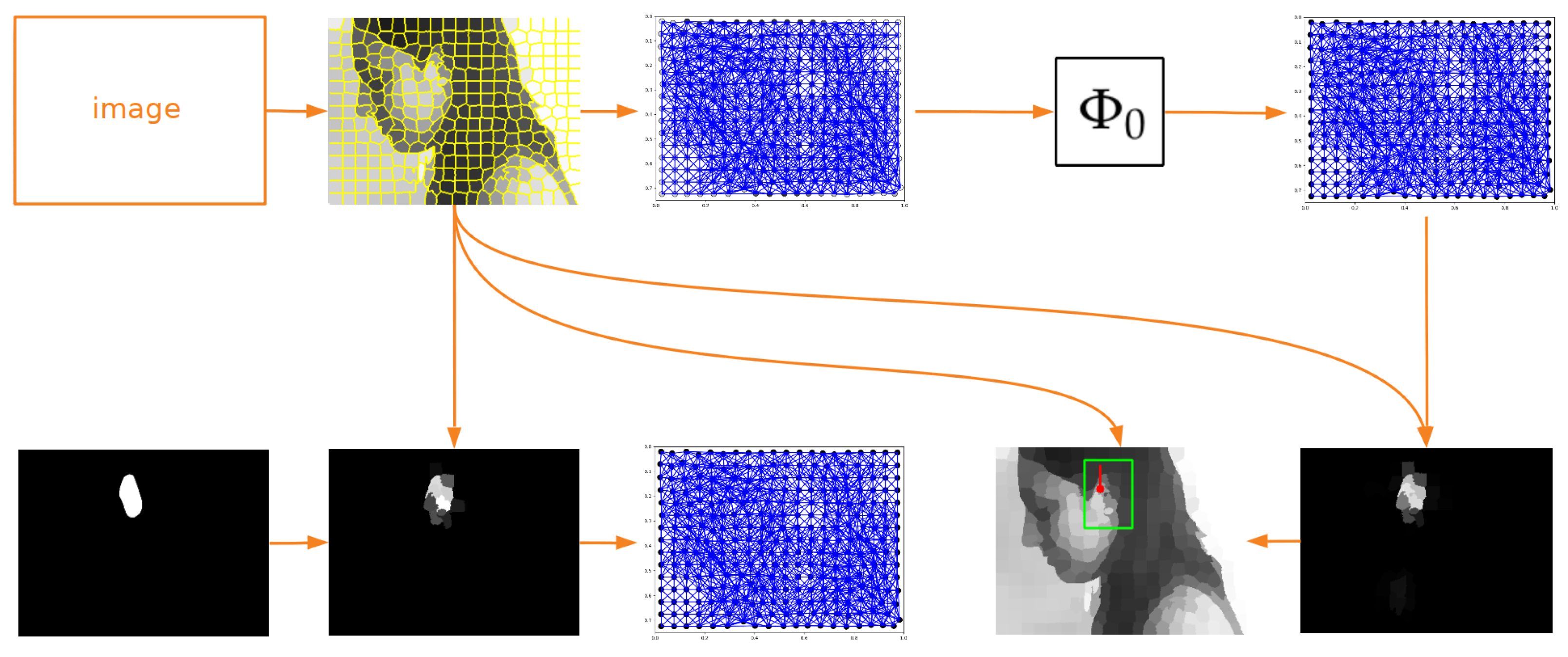
2. Materials and Method
2.1. Dataset
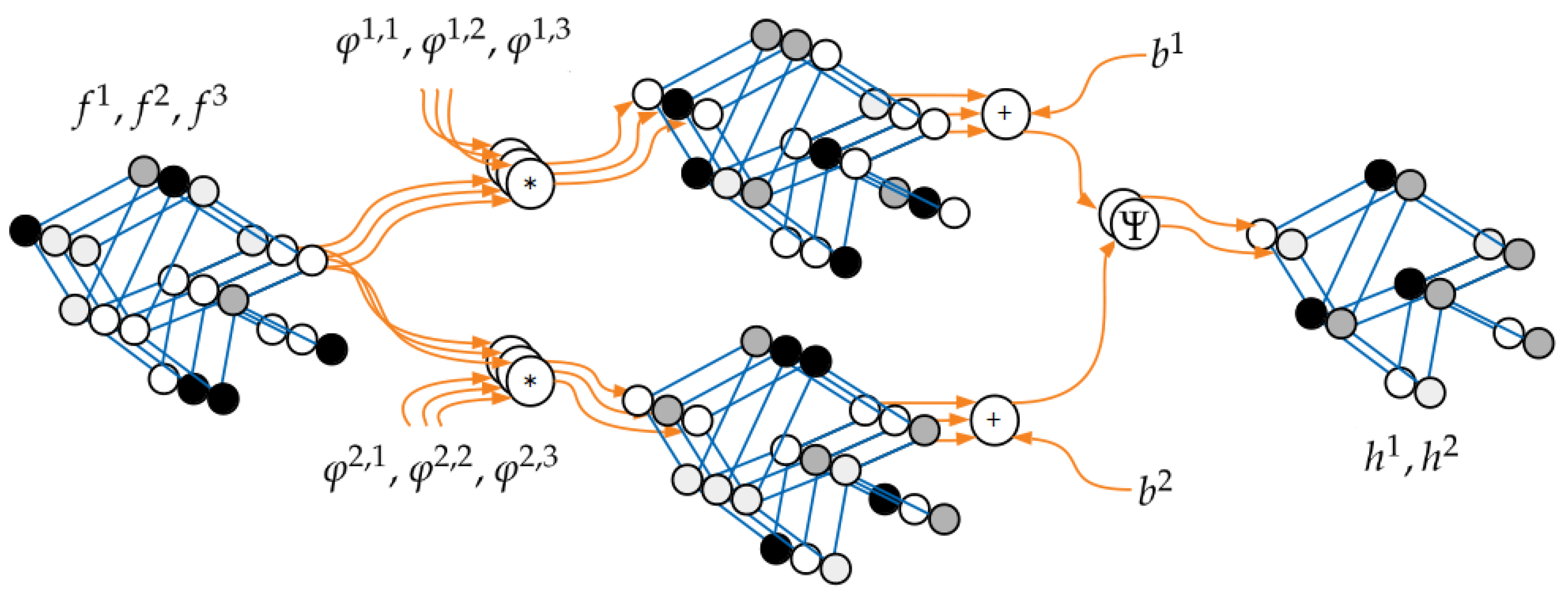
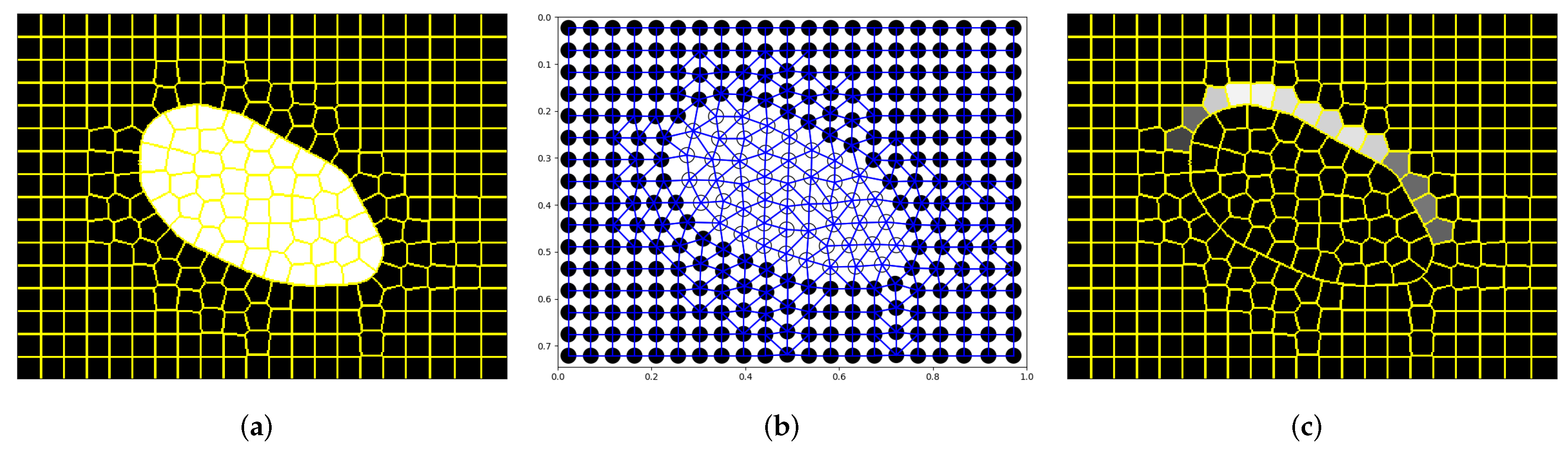
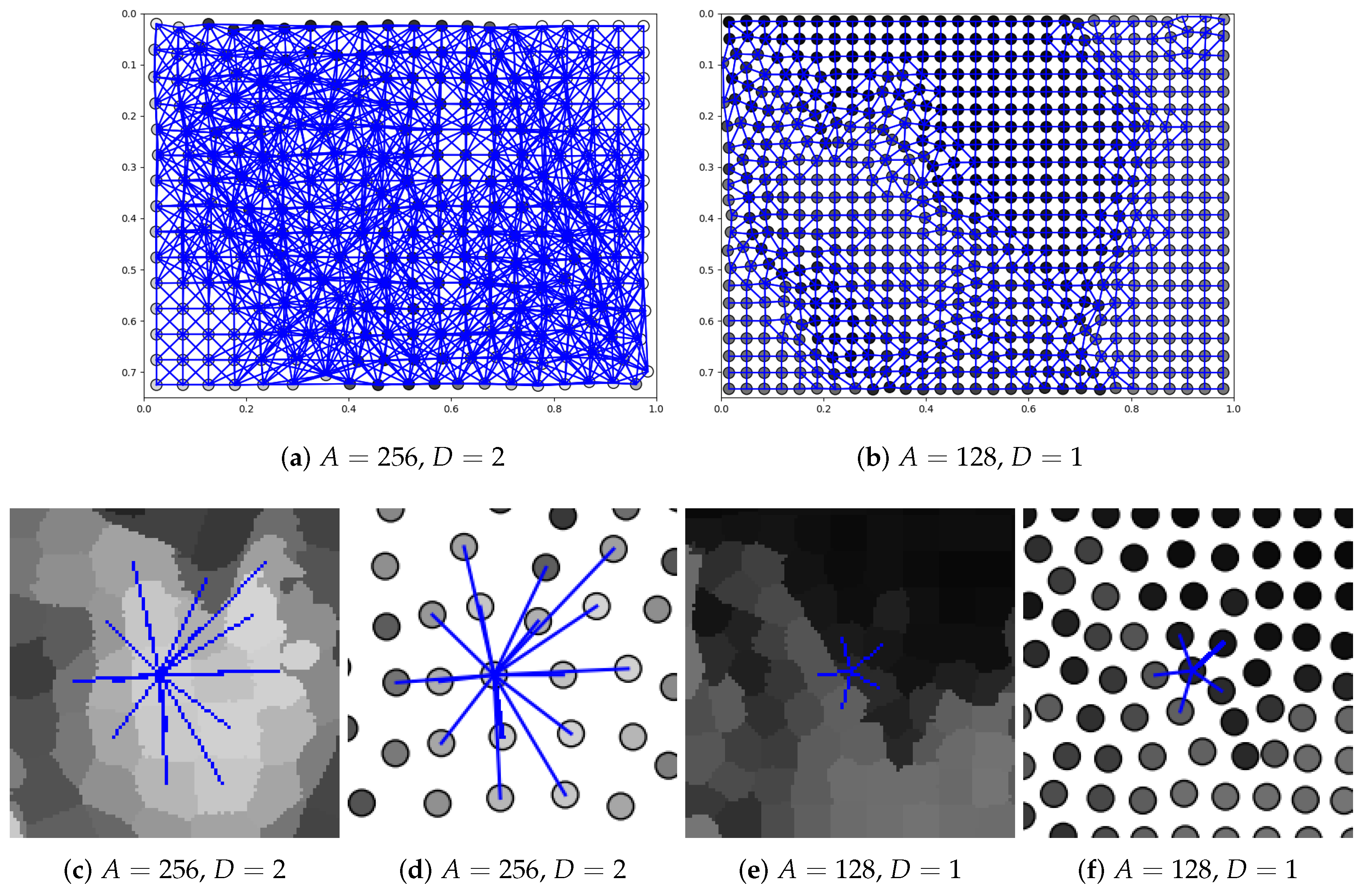
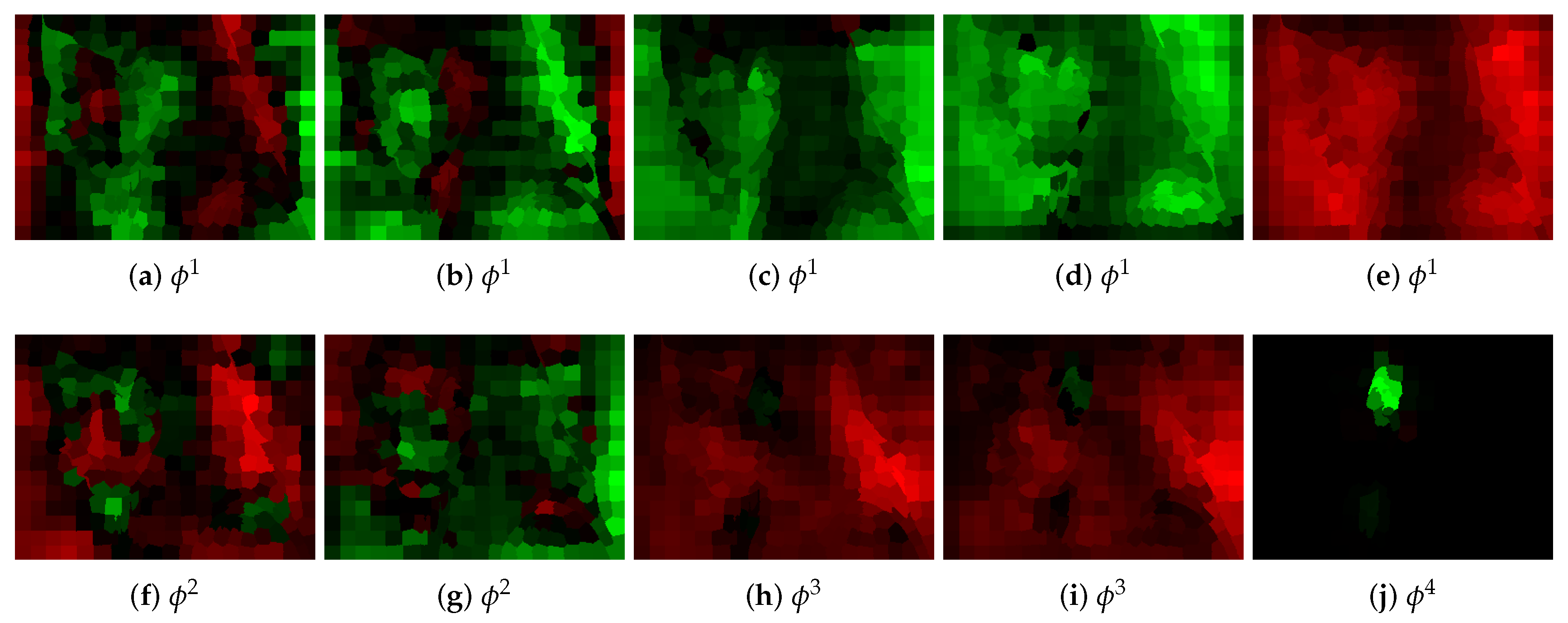
2.2. Method
2.3. Verification
3. Results and Evaluation
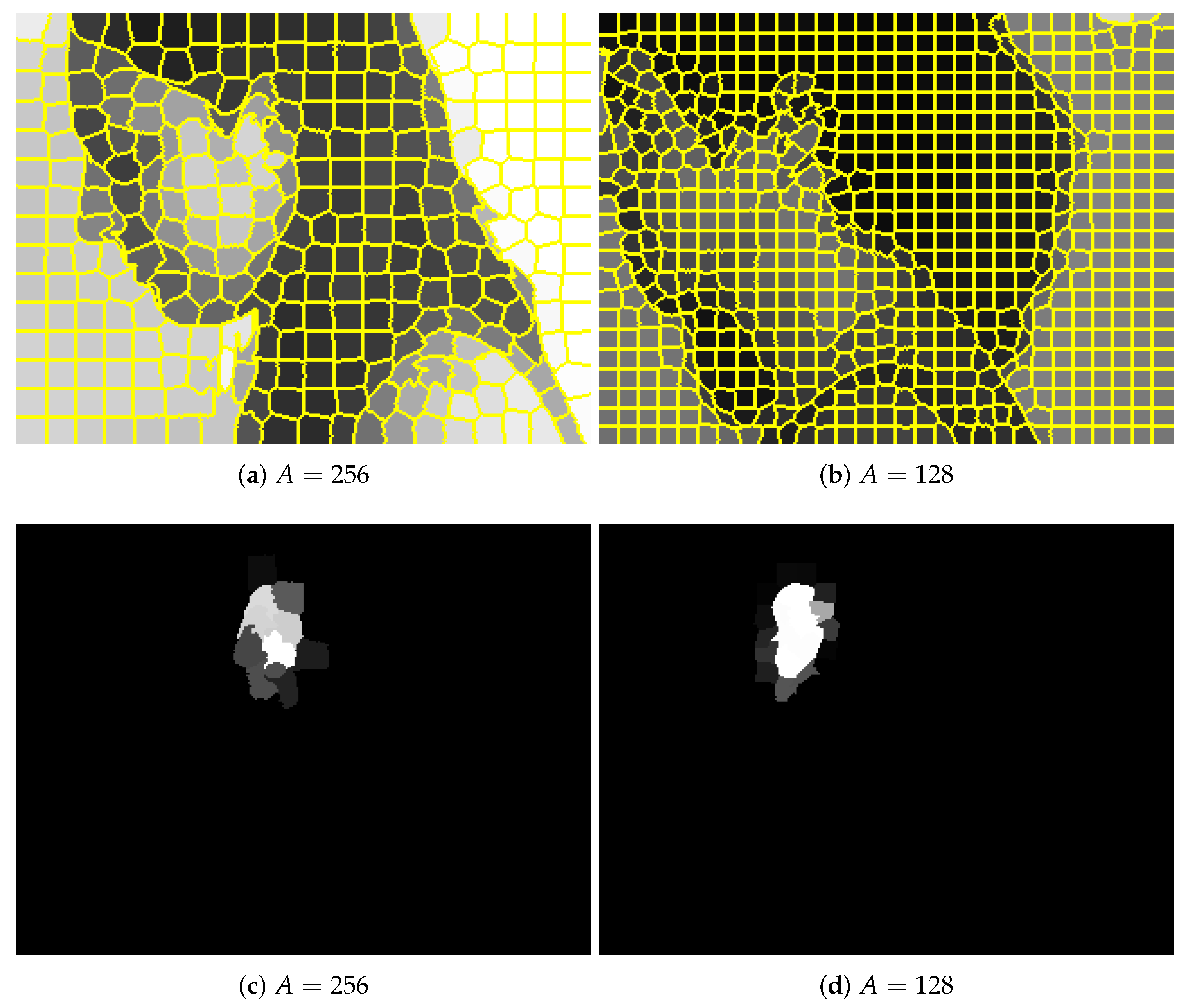
3.1. Assumptions
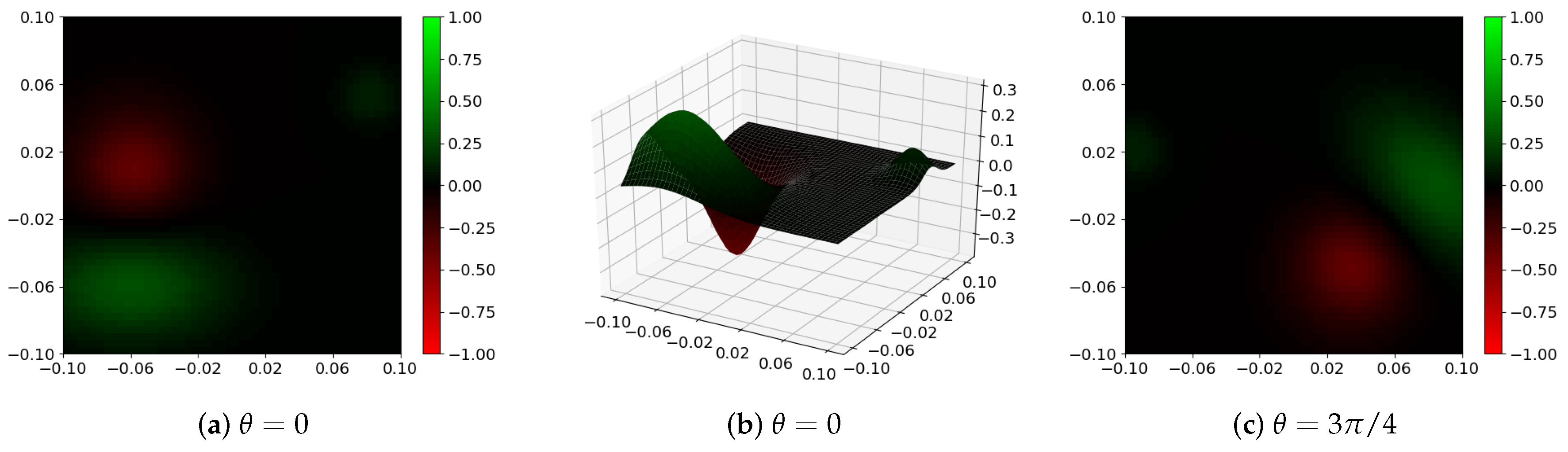
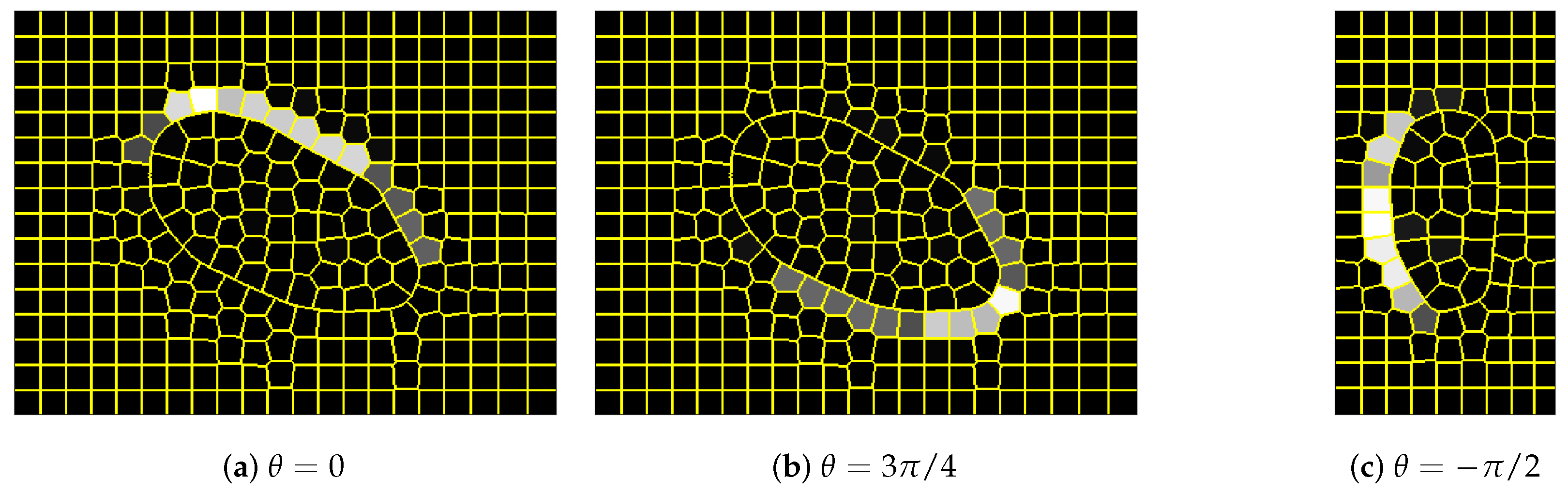
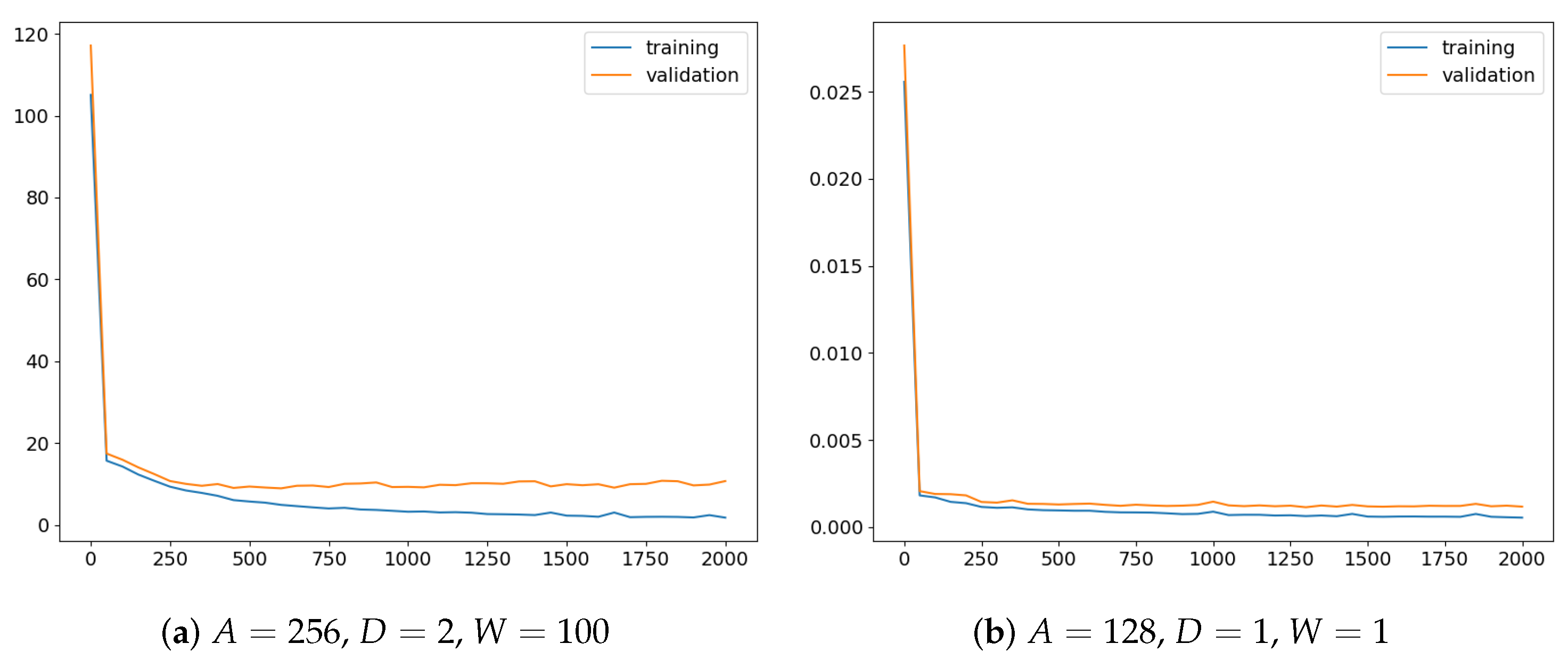
3.2. Experiment I
3.3. Experiment II
3.4. Discussion
4. Summary and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Gutiérrez, L.; Melin, P.; López, M. Modular Neural Network for Human Recognition from Ear Images Using Wavelets. In Soft Computing for Recognition Based on Biometrics; Melin, P., Kacprzyk, J., Pedrycz, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 121–135. [Google Scholar]
- Emeršič, Ž; Štruc, V.; Peer, P. Ear recognition: More than a survey. Neurocomputing 2017, 255, 26–39. [Google Scholar] [CrossRef] [Green Version]
- Pflug, A.; Busch, C. Ear biometrics: A survey of detection, feature extraction and recognition methods. IET Biometr. 2012, 1, 114–129. [Google Scholar] [CrossRef] [Green Version]
- Nanni, L.; Lumini, A. A multi-matcher for ear authentication. Pattern Recognit. Lett. 2007, 28, 2219–2226. [Google Scholar] [CrossRef]
- Tian, L.; Mu, Z. Ear recognition based on deep convolutional network. In Proceedings of the 2016 9th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Datong, China, 15–17 October 2016; pp. 437–441. [Google Scholar]
- Cireşan, D.C.; Meier, U.; Masci, J.; Gambardella, L.M.; Schmidhuber, J. Flexible, High Performance Convolutional Neural Networks for Image Classification. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence—Volume Two (IJCAI’11), Barcelona, Spain, 19–22 July 2011. [Google Scholar]
- LeCun, Y.; Bengio, Y. Convolutional Networks for Images, Speech, and Time-Series. In The Handbook of Brain Theory and Neural Networks; Arbib, M.A., Ed.; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Emeršič, Ž; Gabriel, L.L.; Štruc, V.; Peer, P. Pixel-wise Ear Detection with Convolutional Encoder-Decoder Networks. arXiv 2017, arXiv:1702.00307. [Google Scholar]
- Cintas, C.; Quinto-Sánchez, M.; Acuña, V.; Paschetta, C.; de Azevedo, S.; Cesar Silva de Cerqueira, C.; Ramallo, V.; Gallo, C.; Poletti, G.; Bortolini, M.C.; et al. Automatic ear detection and feature extraction using Geometric Morphometrics and convolutional neural networks. IET Biometr. 2017, 6, 211–223. [Google Scholar] [CrossRef]
- Zhang, Y.; Mu, Z. Ear Detection under Uncontrolled Conditions with Multiple Scale Faster Region-Based Convolutional Neural Networks. Symmetry 2017, 9, 53. [Google Scholar] [CrossRef]
- Ganapathi, I.I.; Prakash, S.; Dave, I.R.; Bakshi, S. Unconstrained ear detection using ensemble-based convolutional neural network model. Concurr. Comput. Pract. Exp. 2019, e5197. [Google Scholar] [CrossRef]
- Raveane, W.; Galdámez, P.L.; González Arrieta, M.A. Ear Detection and Localization with Convolutional Neural Networks in Natural Images and Videos. Processes 2019, 7, 457. [Google Scholar] [CrossRef] [Green Version]
- Dieleman, S.; Willett, K.W.; Dambre, J. Rotation-invariant convolutional neural networks for galaxy morphology prediction. Mon. Not. R. Astron. Soc. 2015, 450, 1441–1459. [Google Scholar] [CrossRef]
- Laptev, D.; Savinov, N.; Buhmann, J.M.; Pollefeys, M. TI-POOLING: Transformation-Invariant Pooling for Feature Learning in Convolutional Neural Networks. arXiv 2016, arXiv:1604.06318. [Google Scholar]
- Marcos, D.; Volpi, M.; Tuia, D. Learning rotation invariant convolutional filters for texture classification. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016. [Google Scholar]
- Weiler, M.; Hamprecht, F.A.; Storath, M. Learning Steerable Filters for Rotation Equivariant CNNs. arXiv 2017, arXiv:cs.LG/1711.07289. [Google Scholar]
- Tarasiuk, P.; Pryczek, M. Geometric Transformations Embedded into Convolutional Neural Networks. J. Appl. Comput. Sci. 2016, 24, 33–48. [Google Scholar]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A.; Vandergheynst, P. Geometric Deep Learning: Going beyond Euclidean data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar] [CrossRef] [Green Version]
- Duvenaud, D.K.; Maclaurin, D.; Iparraguirre, J.; Bombarell, R.; Hirzel, T.; Aspuru-Guzik, A.; Adams, R.P. Convolutional Networks on Graphs for Learning Molecular Fingerprints. In Advances in Neural Information Processing Systems 28; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2015; pp. 2224–2232. [Google Scholar]
- Niepert, M.; Ahmed, M.; Kutzkov, K. Learning Convolutional Neural Networks for Graphs. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Balcan, M.F., Weinberger, K.Q., Eds.; PMLR: New York, NY, USA, 2016; Volume 48, pp. 2014–2023. [Google Scholar]
- Atwood, J.; Towsley, D. Diffusion-Convolutional Neural Networks. arXiv 2015, arXiv:cs.LG/1511.02136. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: New York, NY, USA, 2017; pp. 1025–1035. [Google Scholar]
- Fey, M.; Lenssen, J.E.; Weichert, F.; Müller, H. SplineCNN: Fast Geometric Deep Learning with Continuous B-Spline Kernels. arXiv 2017, arXiv:1711.08920. [Google Scholar]
- Monti, F.; Boscaini, D.; Masci, J.; Rodolà, E.; Svoboda, J.; Bronstein, M.M. Geometric Deep Learning on Graphs and Manifolds Using Mixture Model CNNs. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 5425–5434. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering. In Advances in Neural Information Processing Systems 29; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2016; pp. 3844–3852. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Susstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:cs.CV/1706.05587. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Stasiak, B.; Tarasiuk, P.; Michalska, I.; Tomczyk, A. Application of convolutional neural networks with anatomical knowledge for brain MRI analysis in MS patients. Bull. Polish Acad. Sci. Tech. Sci. 2018, 66, 857–868. [Google Scholar]
- Tomczyk, A.; Stasiak, B.; Tarasiuk, P.; Gorzkiewicz, A.; Walczewska, A.; Szczepaniak, P. Localization of Neuron Nucleuses in Microscopy Images with Convolutional Neural Networks. In Proceedings of the 11th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2018), Funchal, Portugal, 19–21 January 2018. [Google Scholar]
- Raposo, R.; Hoyle, E.; Peixinho, A.; Proença, H. UBEAR: A Dataset of Ear Images Captured On-the-move in Uncontrolled Conditions. In Proceedings of the 2011 IEEE Workshop on Computational Intelligence inBiometrics and Identity Management (SSCI 2011 CIBIM), Paris, France, 11–15 April 2011; pp. 84–90. [Google Scholar]
- Carreira-Perpinan, M.A. Compression Neural Networks for Feature Extraction: Application to Human Recognition from Ear Images. Master’s Thesis, Technical University of Madrid, Madrid, Spain, 1995. (In Spanish). [Google Scholar]
- Kumar, A.; Wu, C. Automated human identification using ear imaging. Pattern Recognit. 2012, 45, 956–968. [Google Scholar] [CrossRef]
- IIT Delhi Ear Database. Available online: http://www.comp.polyu.edu.hk/~csajaykr/IITD/Database_Ear.htm (accessed on 20 May 2019).
- AMI Ear Database. Available online: http://ctim.ulpgc.es/research_works/ami_ear_database (accessed on 20 May 2019).
- Frejlichowski, D.; Tyszkiewicz, N. The West Pomeranian University of Technology Ear Database—A Tool for Testing Biometric Algorithms. In Proceedings of the 7th International Conference on Image Analysis and Recognition, ICIAR 2010, Póvoa de Varzin, Portugal, 21–23 June 2010; Proceedings, Part II. Springer: Berlin/Heidelberg, Germany, 2010; pp. 227–234. [Google Scholar]
- Annotated Web Ears (AWE). Available online: http://awe.fri.uni-lj.si (accessed on 20 May 2019).
- Fey, M.; Lenssen, J.E. Fast Graph Representation Learning with PyTorch Geometric. In Proceedings of the ICLR Workshop on Representation Learning on Graphs and Manifolds, New Orleans, LA, UAS, 6 May 2019. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; Teh, Y.W., Titterington, M., Eds.; PMLR: Sardinia, Italy, 2010; Volume 9, pp. 249–256. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0 | |||||
|---|---|---|---|---|---|
| 33 | |||||
| 36 | |||||
| 256 | 128 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 2 | ||||||
| 1 | 100 | 1 | 100 | 1 | 100 | 1 | 100 | ||
| 415 | |||||||||
| 135 | |||||||||
| 154 | |||||||||
| 491 | |||||||||
| 149 | |||||||||
| 186 | |||||||||
| max | any | |||||
|---|---|---|---|---|---|---|
| 415 | ||||||
| 135 | ||||||
| 154 | ||||||
| 491 | ||||||
| 149 | ||||||
| 186 | ||||||
| 1361 | ||||||
| 423 | ||||||
| 513 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tomczyk, A.; Szczepaniak, P.S. Ear Detection Using Convolutional Neural Network on Graphs with Filter Rotation. Sensors 2019, 19, 5510. https://doi.org/10.3390/s19245510
Tomczyk A, Szczepaniak PS. Ear Detection Using Convolutional Neural Network on Graphs with Filter Rotation. Sensors. 2019; 19(24):5510. https://doi.org/10.3390/s19245510
Chicago/Turabian StyleTomczyk, Arkadiusz, and Piotr S. Szczepaniak. 2019. "Ear Detection Using Convolutional Neural Network on Graphs with Filter Rotation" Sensors 19, no. 24: 5510. https://doi.org/10.3390/s19245510
APA StyleTomczyk, A., & Szczepaniak, P. S. (2019). Ear Detection Using Convolutional Neural Network on Graphs with Filter Rotation. Sensors, 19(24), 5510. https://doi.org/10.3390/s19245510