Clustered Data Muling in the Internet of Things in Motion †


Abstract
:1. Introduction
- Initialization: this is done by randomly selecting k of the nodes to be cluster heads.
- Assignment step: this step consists of assigning cluster members to cluster heads, based on the least Euclidean distance between the node and cluster heads.
- Update: for each cluster, a centroid (most central node) is computed, and if it is different from the current cluster head, it replaces it.
- Iteration: this step consists of alternating Steps 2 and 3 until no more updates are possible.
Motivation and Contribution
2. Problem Formulation
2.1. The Energy Models
- Energy for sensor-data reception (): This is the energy spent by cluster heads due to its topological and environmental properties, the physical/electronic properties of the receiving node, and the nature of messages to be received. We assume that all possible cluster heads are in the same and good condition; hence, they require the same quantity of energy to receive a message. It is assumed that nodes communicate directly with their corresponding cluster head, and in the case a multi-hop communication is applicable, the least interference beaconing protocol (see [29]) is used to find sensor communication route.
- Energy for data transmission among sensors (): This is the total energy required to move the captured data from each cluster node to its corresponding cluster head. This form of energy is directly proportional to the distance separating the two communicating sensors. We assume one-hop inter-cluster communication, and hence, the considered distance is the Euclidean length of links. All nodes of the network are assumed to require the same quantity of energy for message transmissions.
- Energy for UAV data transport (): This refers to the expected energy required for a UAV to visit cluster heads. This energy depends on the number of cluster heads in the network and the distance between these nodes (the expected link length).
- Energy for UAV data collection (): This is the energy spent by the UAV to collect data from the sensor nodes (cluster heads).
2.1.1. The Terrestrial Network Energy Consumption:
2.1.2. The Data Collection Energy Consumption:
2.1.3. Energy for UAV Transportation:
2.2. Problem Definition
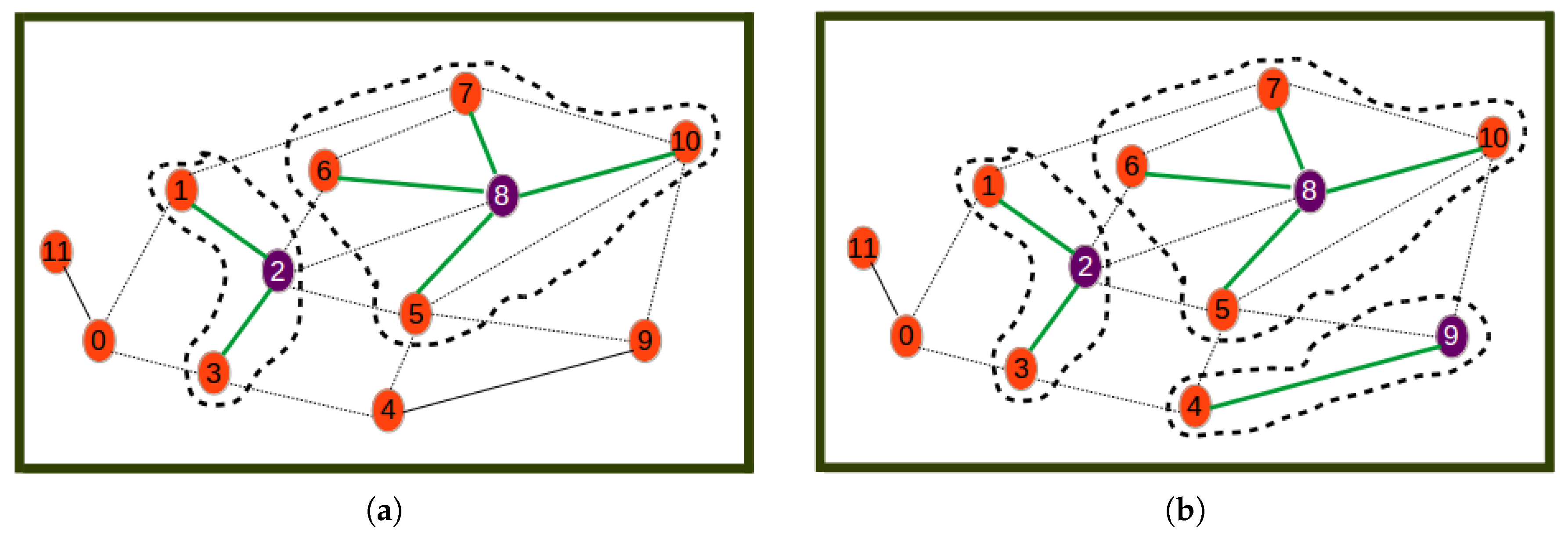
3. The Proposed Clustering Models
- The UAV-Aware k-Means (UAKM) algorithm, which computes the number k of optimal clusters for hybrid dense networks to support/complement k-means clustering. Here, the number k is calculated using both the ground and the aerial networks, and hence, it considers the movement of the UAV.
- The UAV-Aware DCC (UADC) algorithm, which adapts the DCC algorithm to include the UAVs data collection process.
3.1. The UAV-Aware K-Means Algorithm
3.2. The UAV-Aware DCC Algorithm
- Degree-aware selection policy, where nodes are assigned the cluster head identity based on their node degree . While leading to the UAV choosing data collection points with a high volume of data, this policy might lead to the UAV flying longer distances to collect these data, and hence, depleting its energy during its inbound journey.
- Distance-aware selection policy, where nodes are elected cluster heads based on the expected Dijkstra’s shortest path from the nodes to all other nodes, following the links in the airborne network (links of the network ). This policy aims at minimizing the energy usage of the airborne sensor network, but might lead to the UAV being tasked with collecting data at collection points with very few data.
- A hybrid policy that combines features from dense and distance-aware cluster head selection by combining both parameters into a weighted sum metric expressed by:
- Input: The graph of type
- Output: A dictionary of cluster heads and their cluster mates
| Algorithm 1: Optimal clustering. |
 |
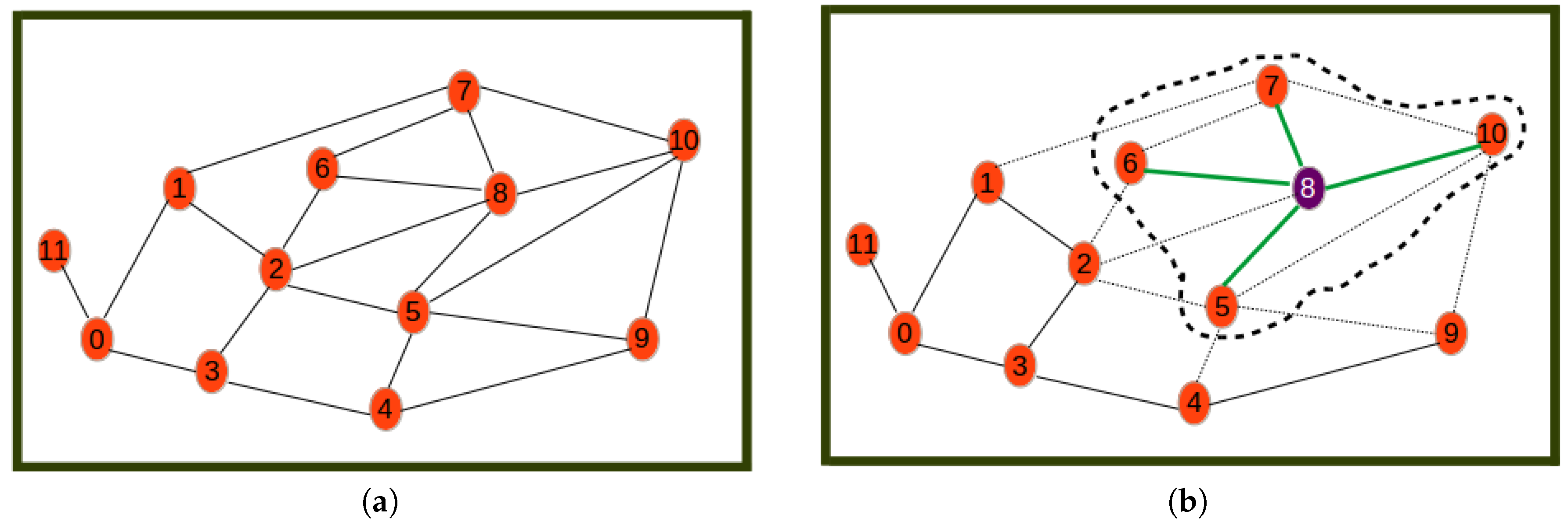
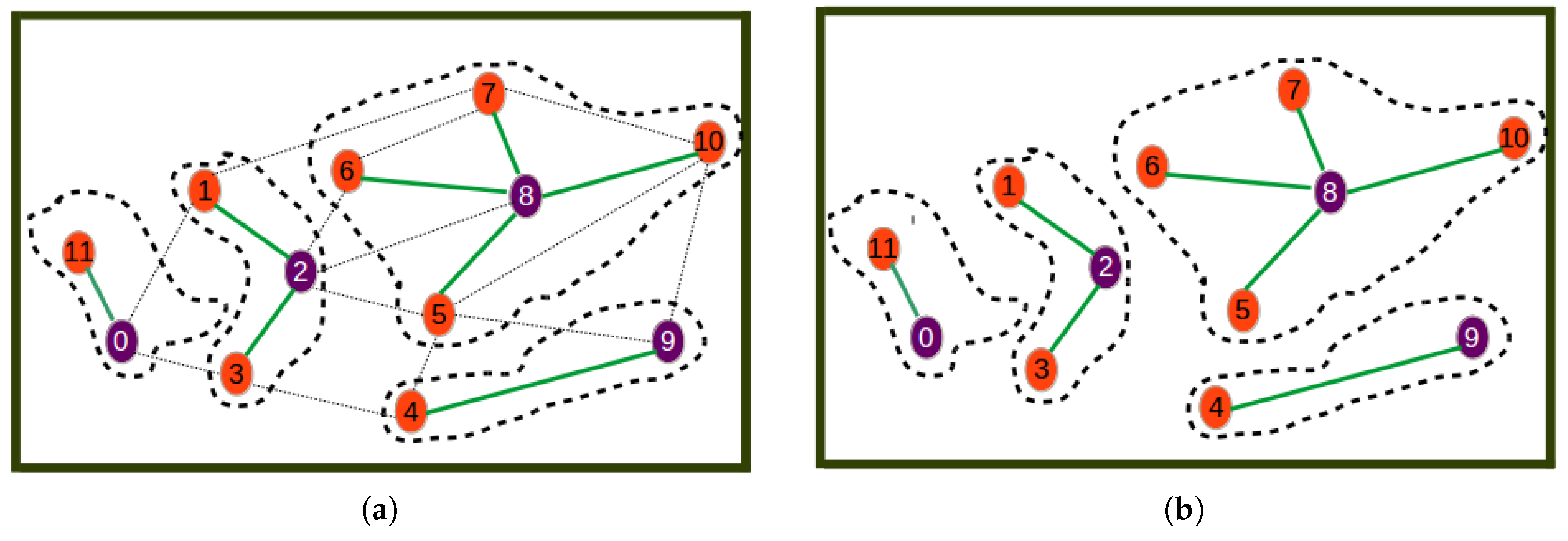
- Step 0
- is the initial step revealing the initial network.
- Step 1
- selects Node 8 as the one with highest utility (computed by Equation (20)) to become the cluster head. The first cluster is formed by assigning all its neighbors as its cluster members.
- Step 2
- selects Node 2 as the next best cluster node. Here, to calculate the utility, the nodes or links involved in the formed cluster are not considered. This is why for example Node 2 has a new degree of two. The new degree of Node 0 is greater than that of Node 2 even though the utility of Node 2 is highest since it is the closest node to the remaining nodes.
- Step 3
- is a step where Node 9 is selected as the next best cluster head, which is joined by only Node 4 as its cluster member.
- Step 4
- is a step where Node 0 is selected as the last best cluster head, which is joined by Node 11 as its neighbor to form the last cluster.
- Step 5
- is the last phase where the resulting cluster and the corresponding communication links through which nodes have to send sensor readings to cluster heads are shown.
- P1.
- Termination property: We first show that the algorithm terminates. Notice that the algorithm iterates over a finite set (see Line 5) and loops for some iterations (Line 11). It is sufficient to show that the inner loop on Line 11 halts. Notice that the loop starts with a finite set of nodes, and updates the set by removing at least one element during each iteration. It is clear that in at most steps, , which is a condition for the loop to stop.
- P2.
- Dominating set property: Lines 6, 8, and 11 show that at the end, each node becomes either a cluster head or a cluster member. On the other hand, Lines 1, 2, 9, and 6 show that only neighbors of the cluster head are added in the same cluster to be cluster members. It then follows that when the algorithm halts, if a node is not a cluster head, then it is connected to the cluster head in the same cluster.
- P3.
- Partition property: Line 13 shows that no node (cluster member or cluster head) belongs to more than one cluster. Hence, the formed clusters are mutually exclusive. On the other hand, Lines 6, 8, and 11 show that the algorithm halts when each node has either been a cluster member or (exclusively) a cluster head. This shows that in the end, each node belongs in a unique cluster. Hence, cluster nodes constitute a partition of the ground network nodes.
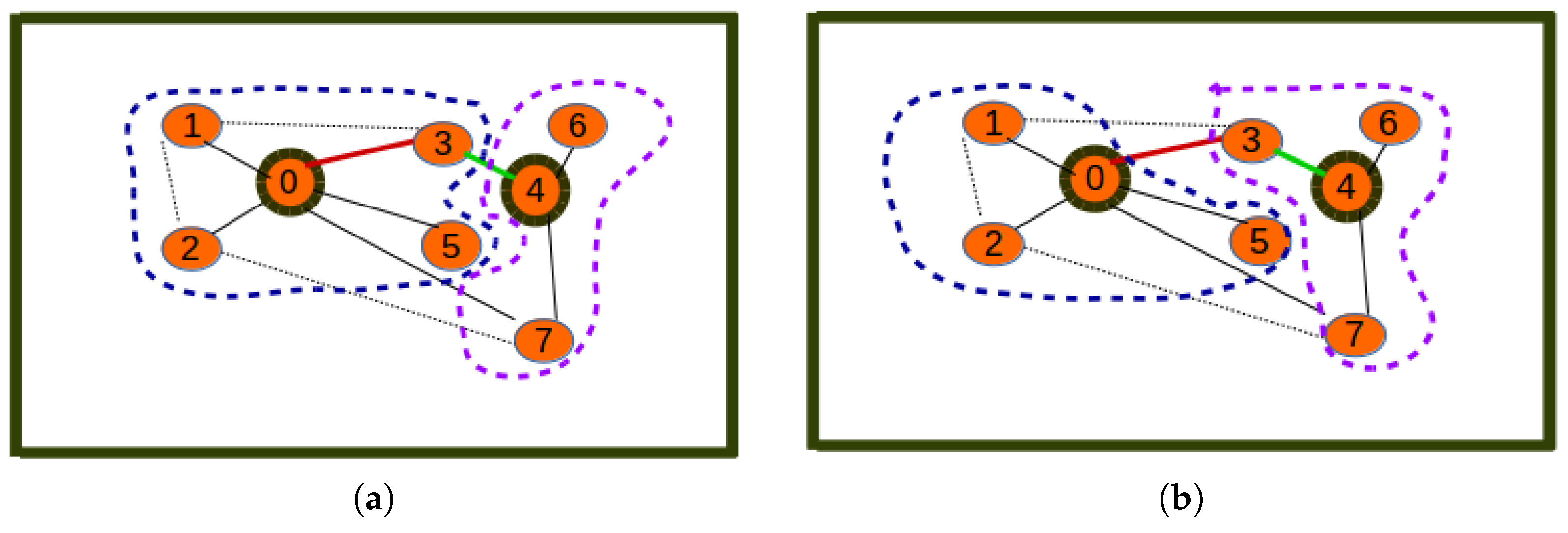
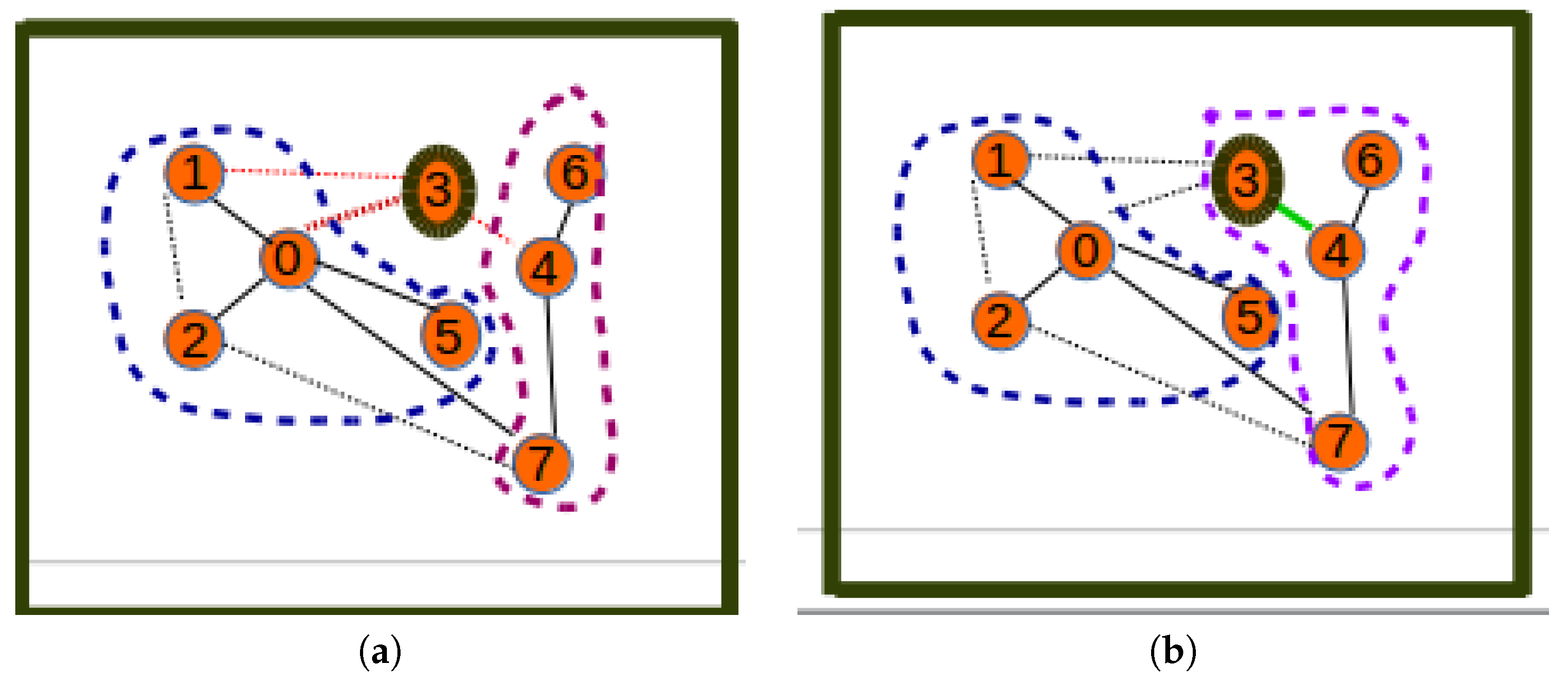
4. Issues and Relaxation
4.1. Energy Inefficiency
- Input:
- →
- The graph of type .
- →
- the initial clustering (using Algorithm 1): each node and its initial cluster head denoted by n and , respectively.
- Output:
- ←
- A more efficient clustering.
4.2. Orphan Nodes
- Input:
- →
- The graph of type .
- →
- the initial clustering (using Algorithm 1): each node and its initial cluster head denoted by n and , respectively.
- Output:
- ←
- A more efficient clustering.
| Algorithm 2: Distance-aware cluster restructuring. |
 |
4.3. The Update Step
- The distance-aware relaxation algorithm proposed above may lead to energy consumption improvement.
- The restructuring of the terrestrial sensor network is another relaxation technique that follows the same distance-aware strategy for a different purpose, but it can also lead to energy consumption improvement.
5. Results and Discussion
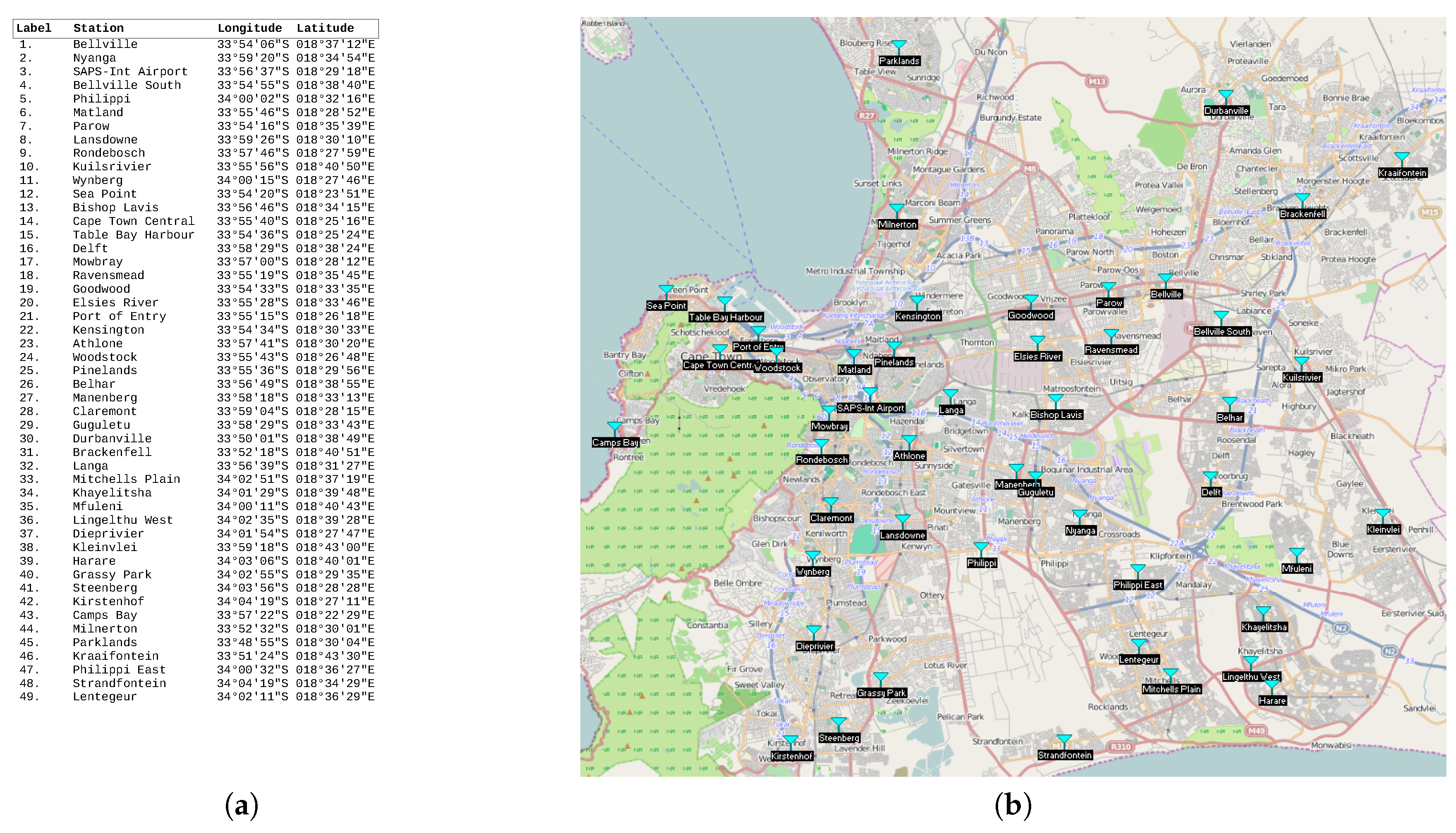
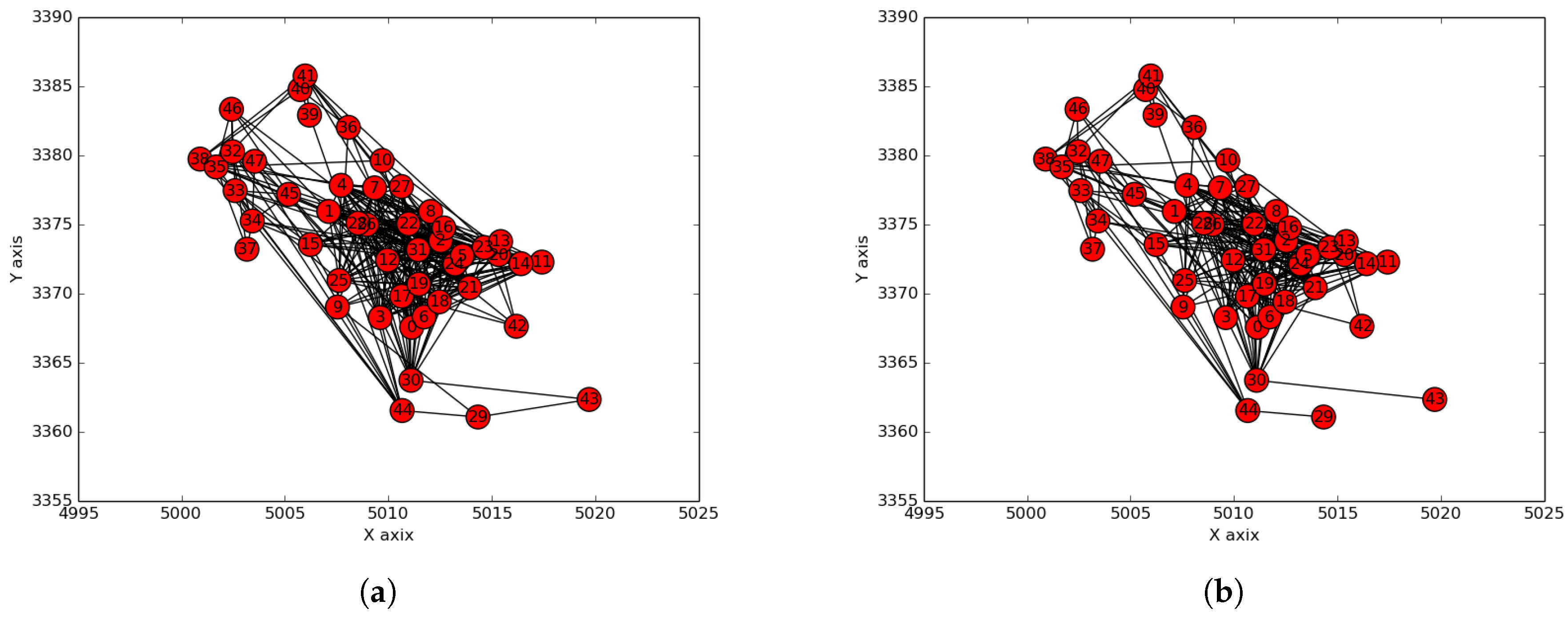
5.1. Smart City Use-Case
5.2. Hybrid Clustering: and and
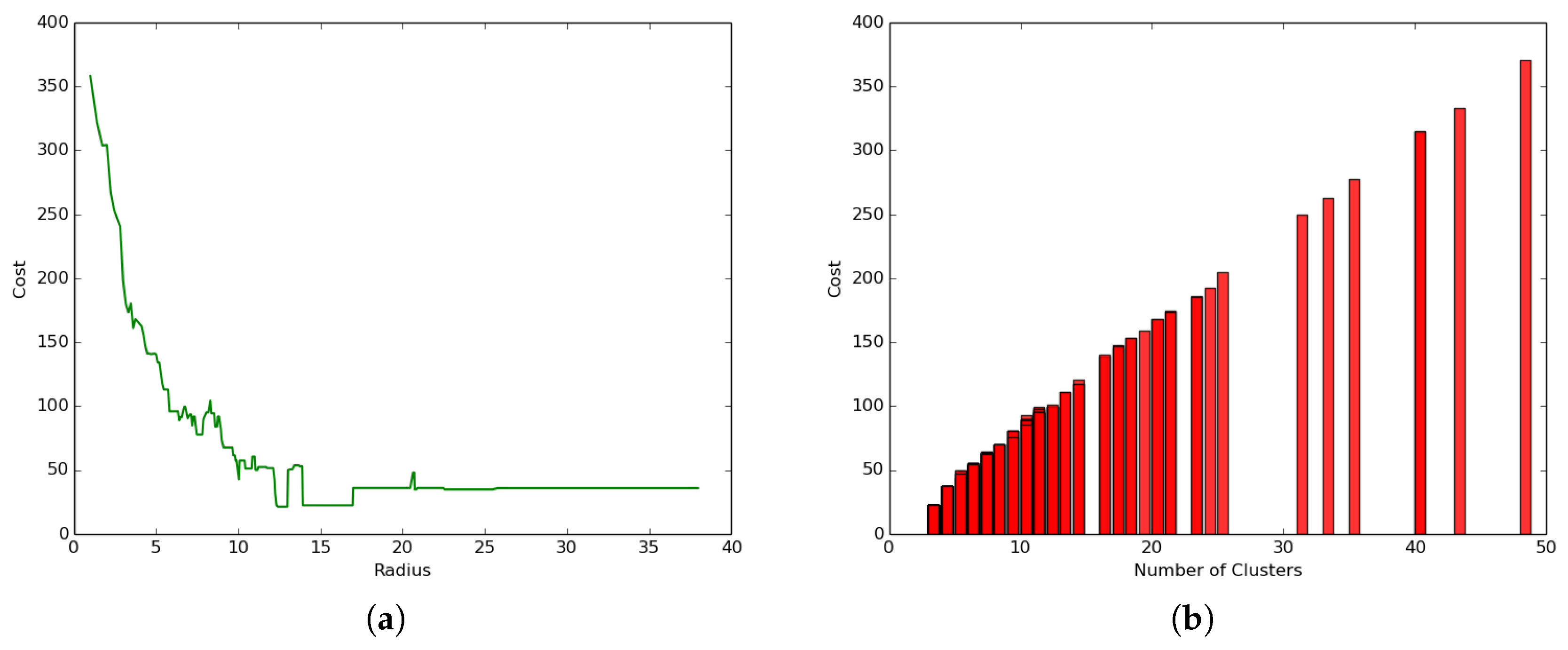
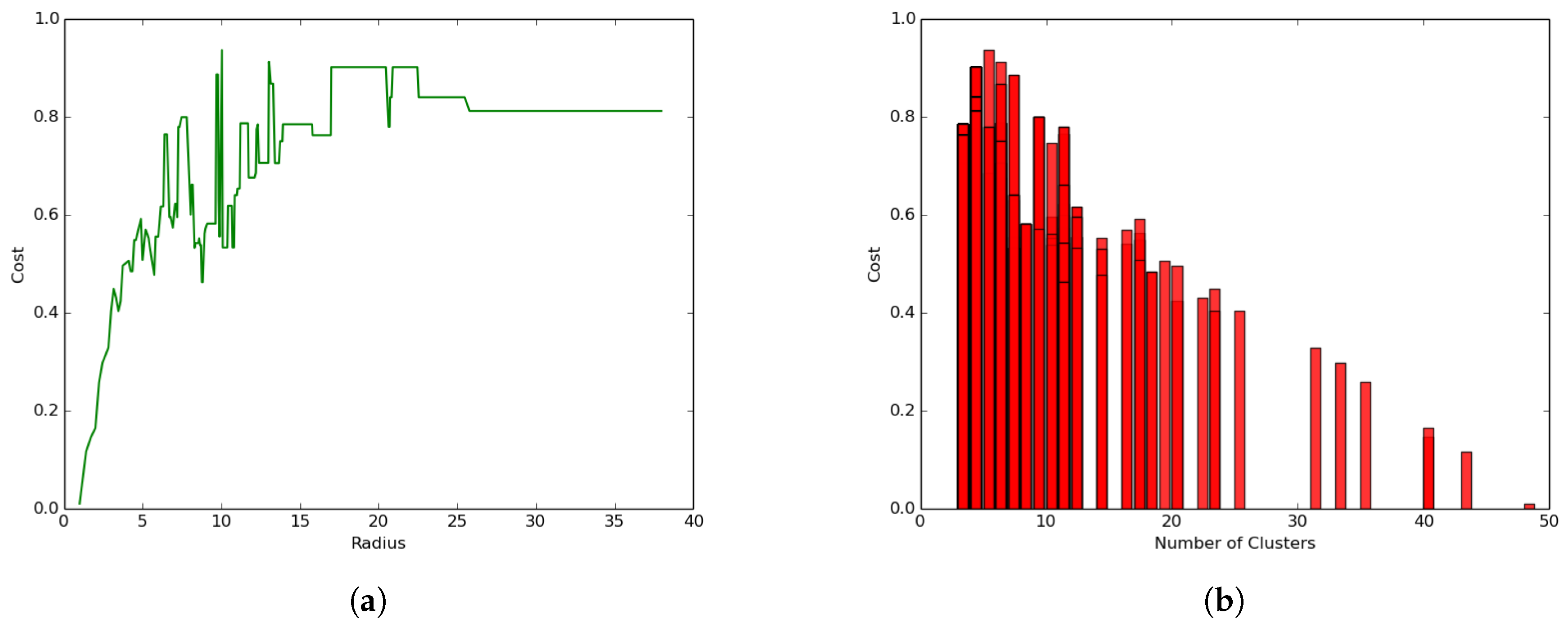
5.3. Terrestrial Clustering: and and
- The coverage cost function increases with the increase in the radius size following an exponential function leading to a convergence value where the cost becomes constant.
- The clustering process leads to much smaller coverage cost values (less than 1.0 joule) as compared to the general case where the coverage cost values ranged between 20 and 370 joules.
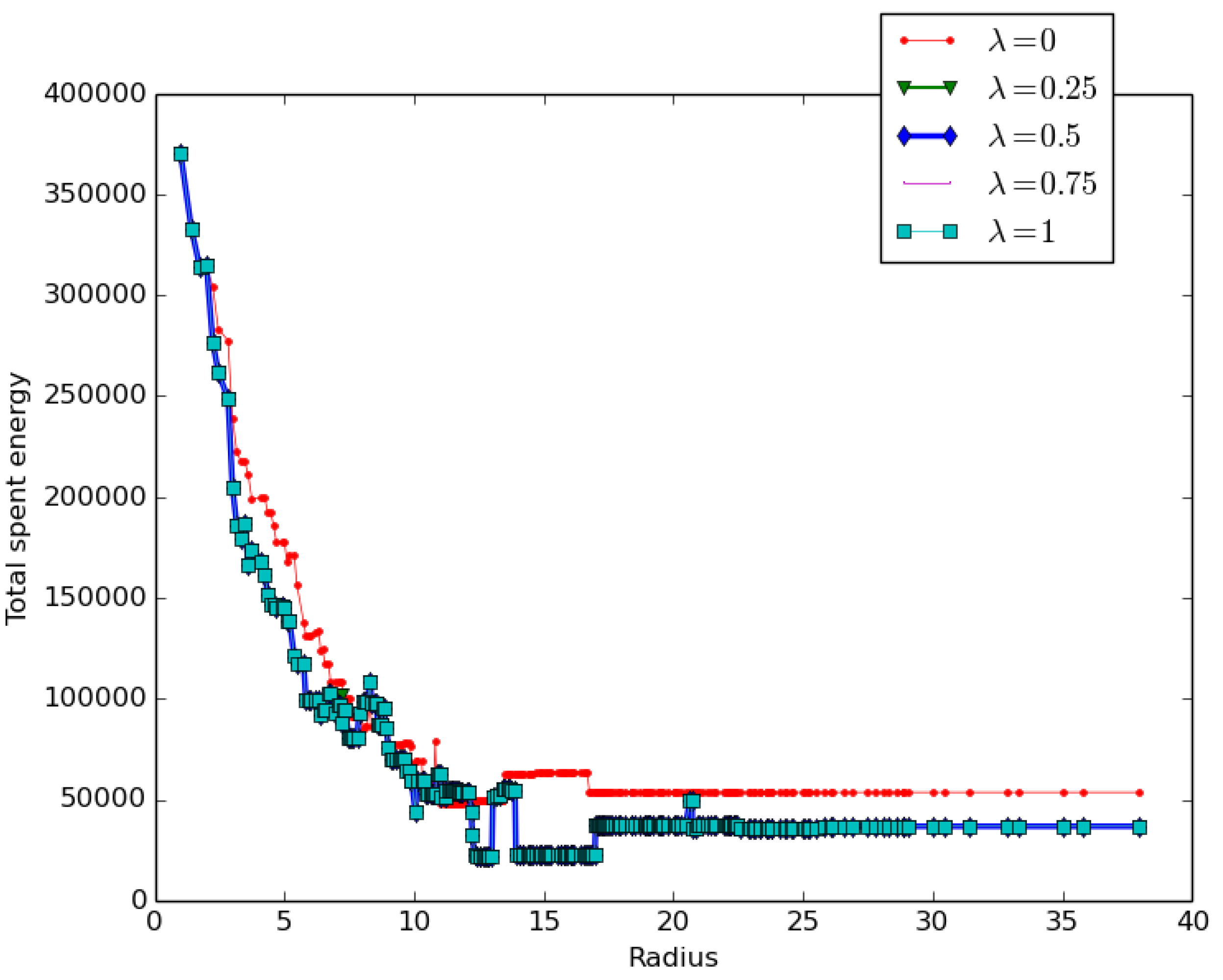
5.4. The Impact of the Cluster Head Selection Parameter on Performance
- expressing a distance awareness policy.
- expressing a balanced policy with a more focused distance awareness trend.
- expressing a fair, balanced policy between density and distance awareness.
- expressing a balanced policy with a more focused density awareness trend.
- expressing the density awareness policy.
- Distance awareness decreases the total coverage cost more slowly than density awareness: at any given radius, the distance awareness policy cost is higher than the density awareness policy cost, as revealed by the red curve corresponding to .
- Any balanced policy leads to the same and lower energy cost as the density awareness policy .
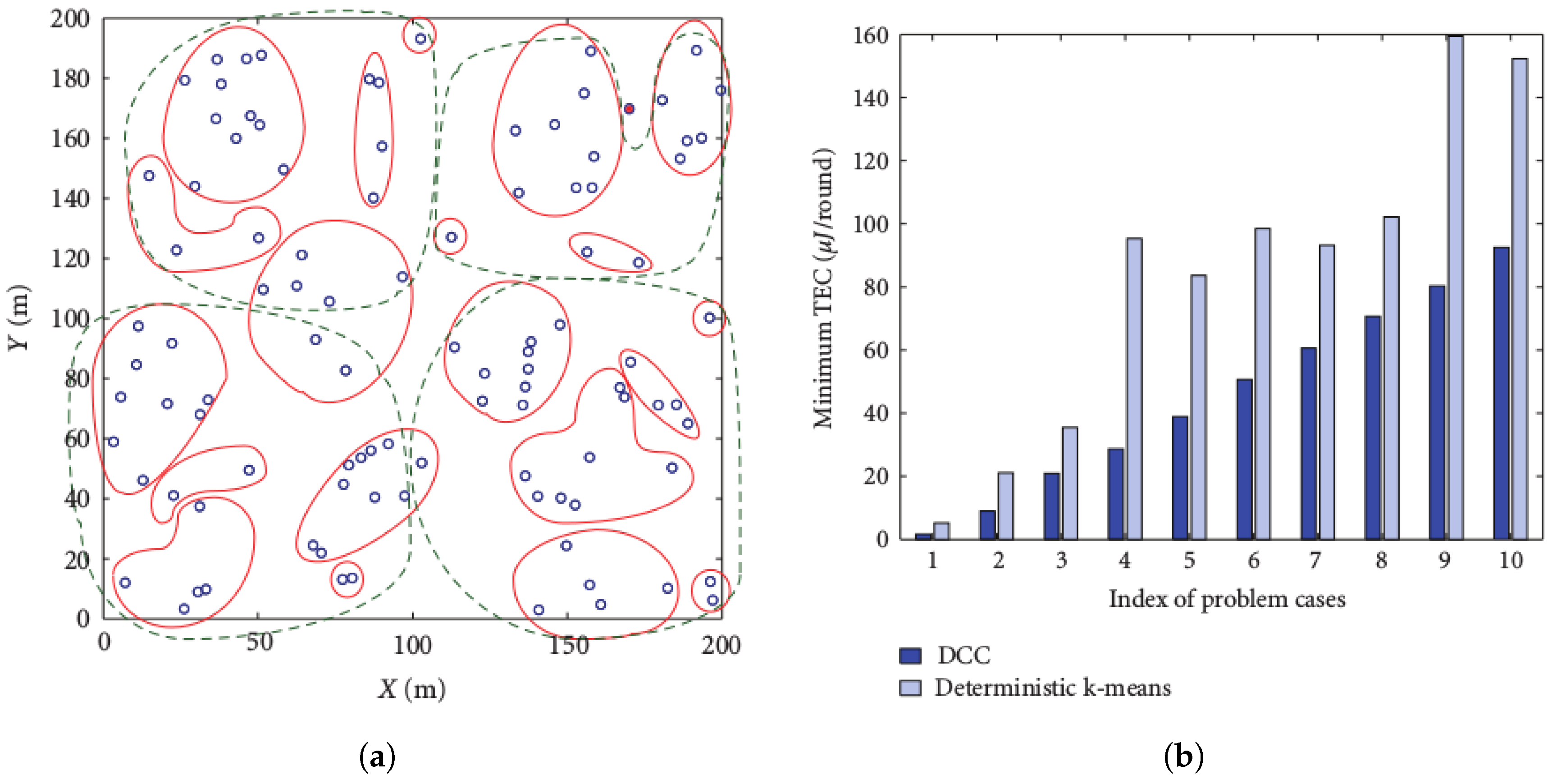
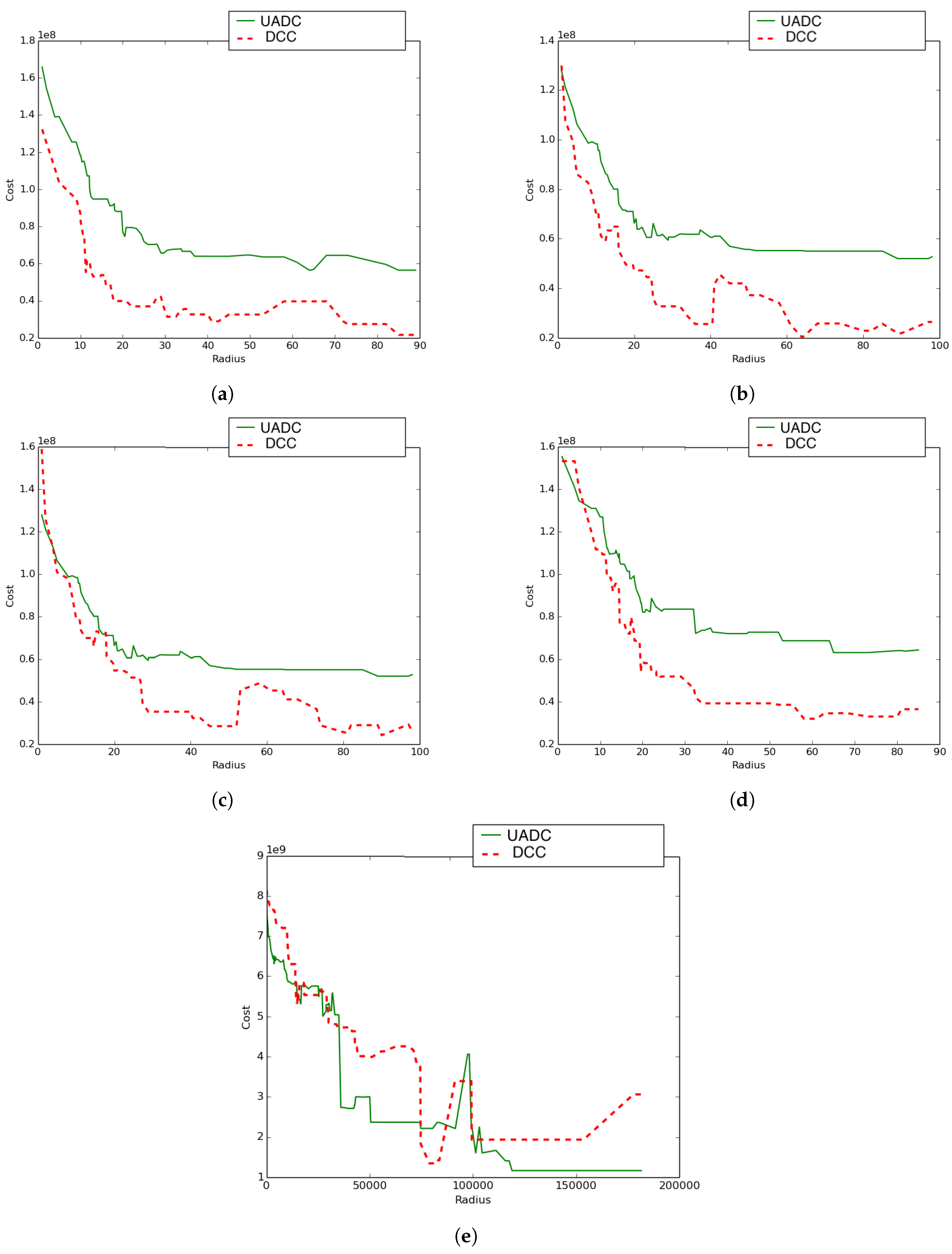
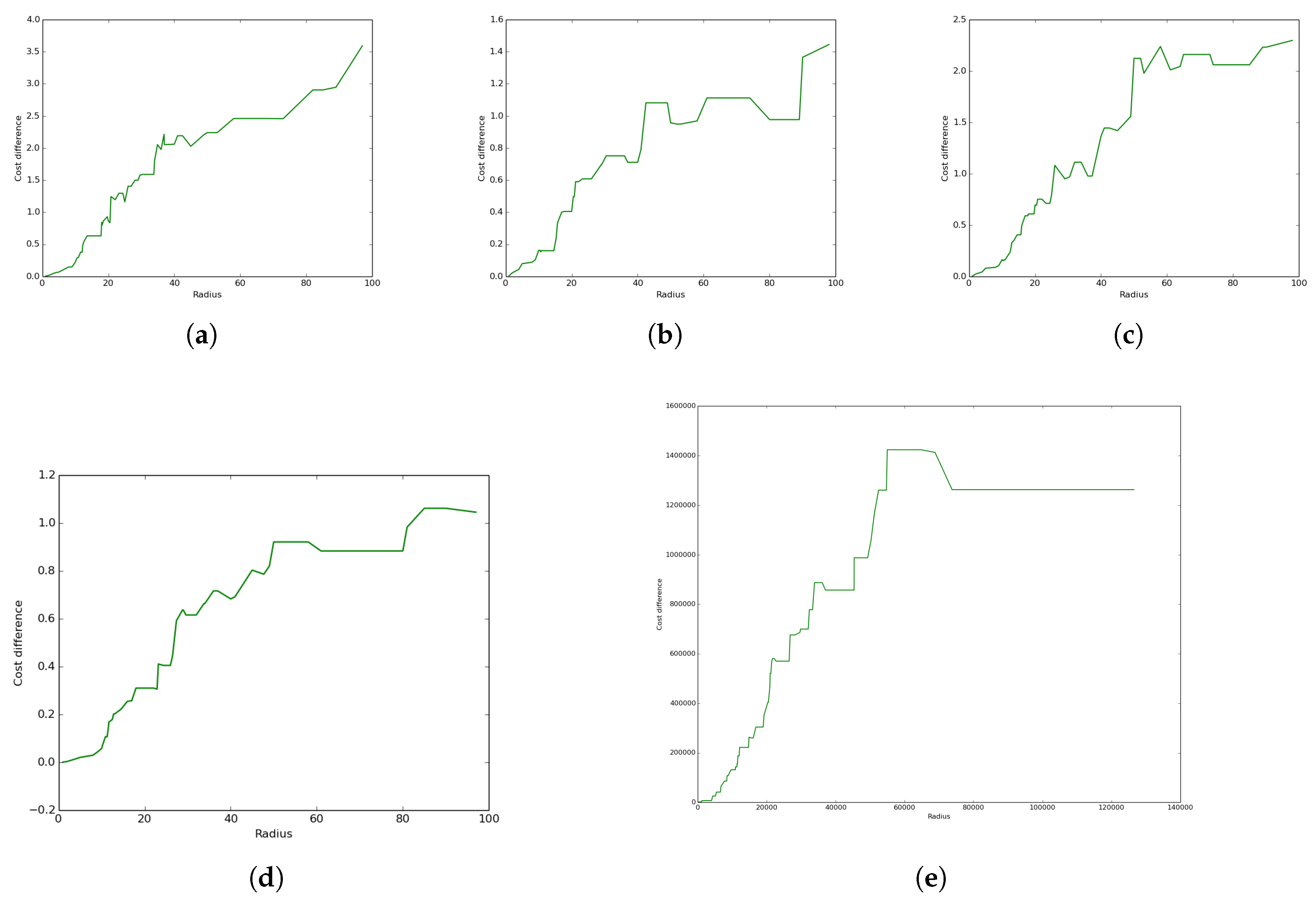
5.5. UADC versus DCC Performance Comparison
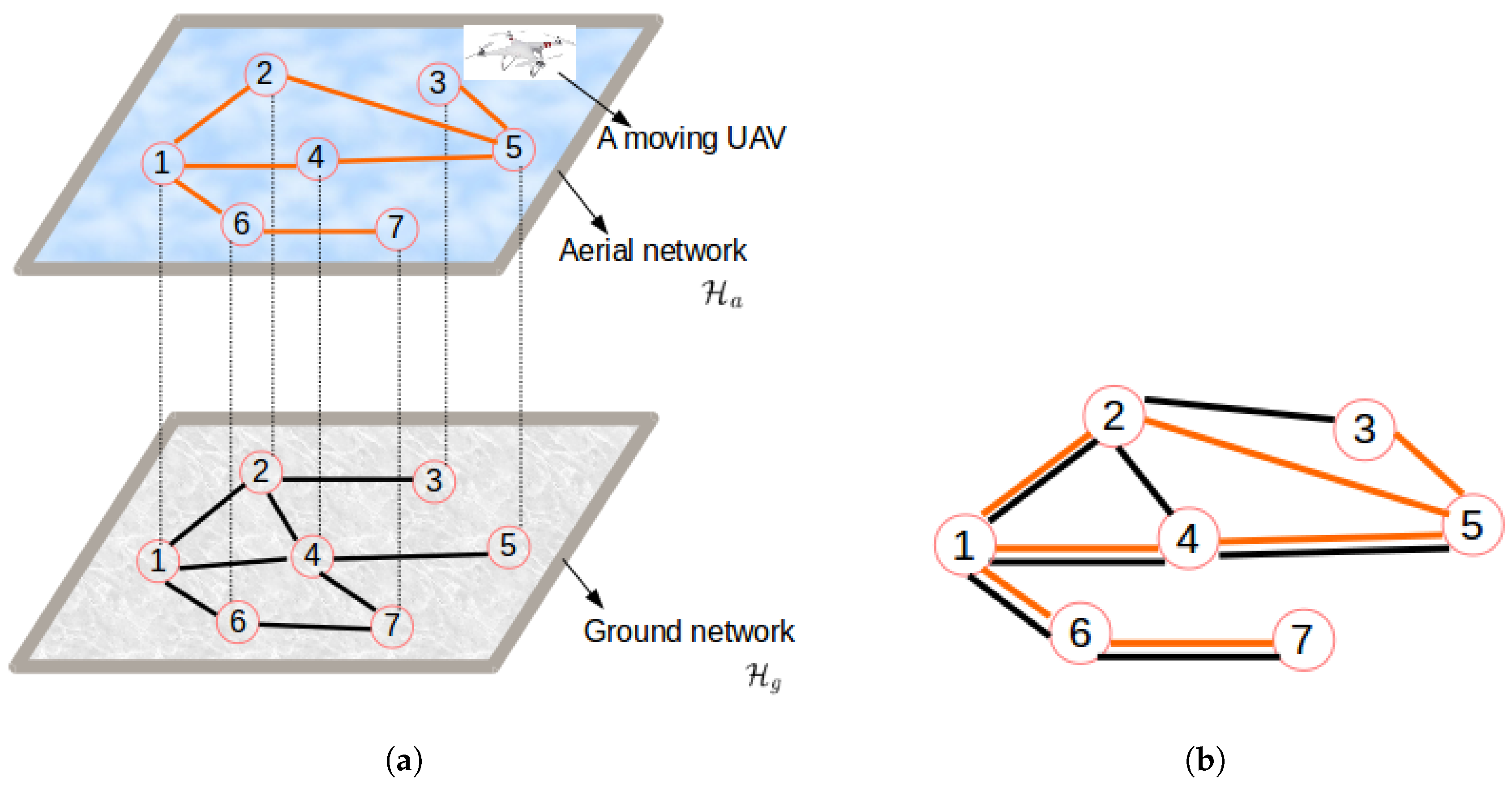
- Case 1: The UAV’s paths constitute a proper sub-network of the terrestrial communication network.
- Case 2: The terrestrial communication network is a proper sub-network of the UAVs’ network. This has been achieved by interchanging the networks chosen for the experiment in Figure 14a.
- Case 3: The two networks (terrestrial and aerial) are the same. Here, the assumed network is shown by Figure 10a.
- Case 4: In this experiment, positions were kept the same, and for both types of networks, the connections were generated randomly.
- Case 5: In this experiment, both the positions and links of both networks were generated randomly. The total number of considered nodes was still 48, and the positions were generated by randomly selecting the coordinates from a normal distribution with mean = 500 and a standard deviation of 300 ().
- With the exception of Case 5, UADC leads to higher coverage cost compared to DCC as a result of the data muling cost due to the energy consumption of the UAV.
- The case where the terrestrial communication network is a proper sub-network of the aerial network (Case 2) leads to lower coverage cost compared to the reverse case (Case 1) where the aerial network is a sub-network of the terrestrial network.
- The lowest UADC cost is achieved when the aerial network and the terrestrial networks are the same (Case 3).
- The case where both networks have the same positions, but randomly-generated connections (Case 4) leads to higher coverage cost compared to the case where both networks are the same (Case 3) for both the UADC and DCC algorithms.
- The case where positions and links are randomly generated for both networks (Case 5) is the only case where the UADC algorithm outperforms the DCC algorithm for some of the higher radius sizes.
5.6. The Impact of Relaxation on Performance
| Algorithm 3: Distance-aware node redistribution. |
 |
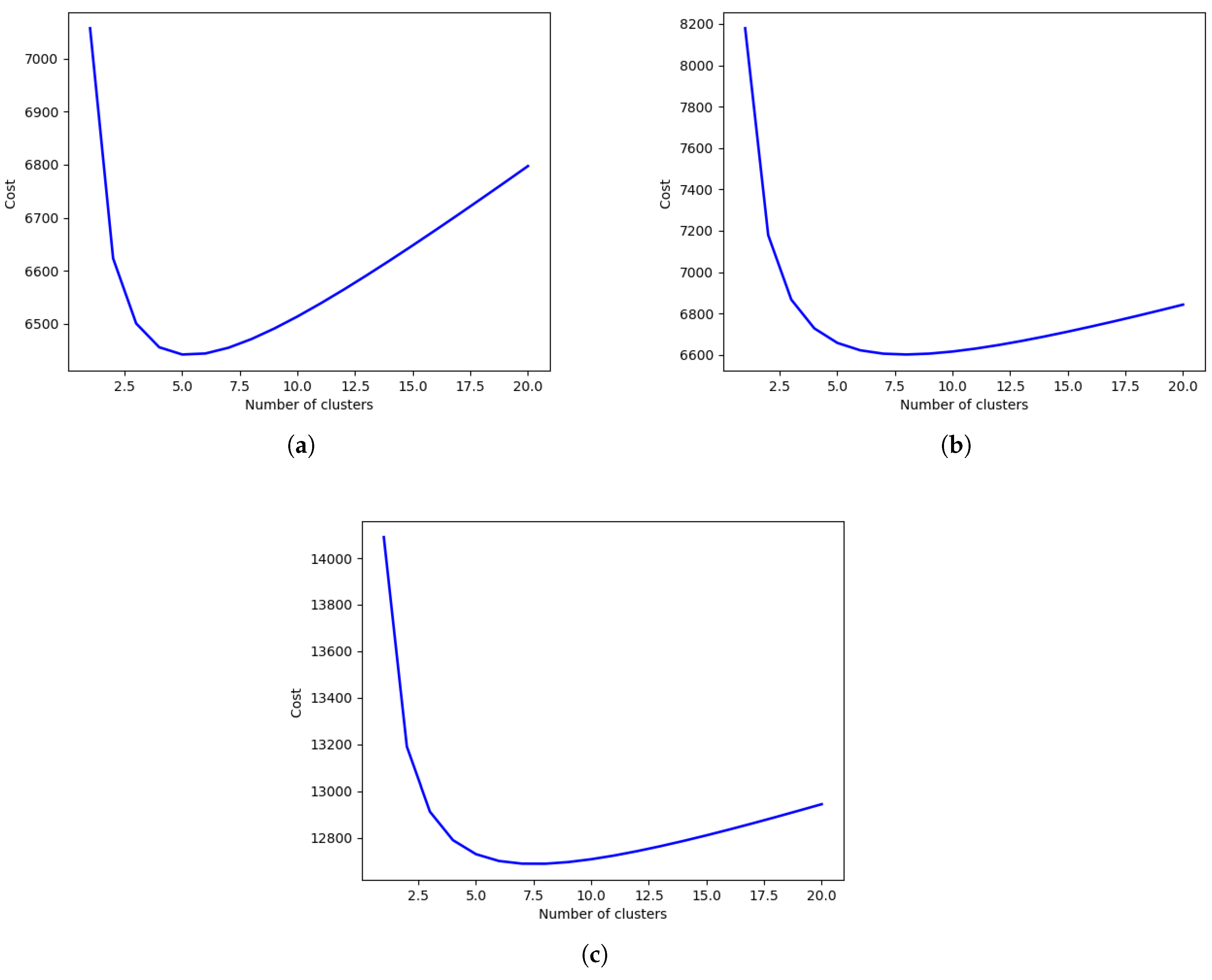
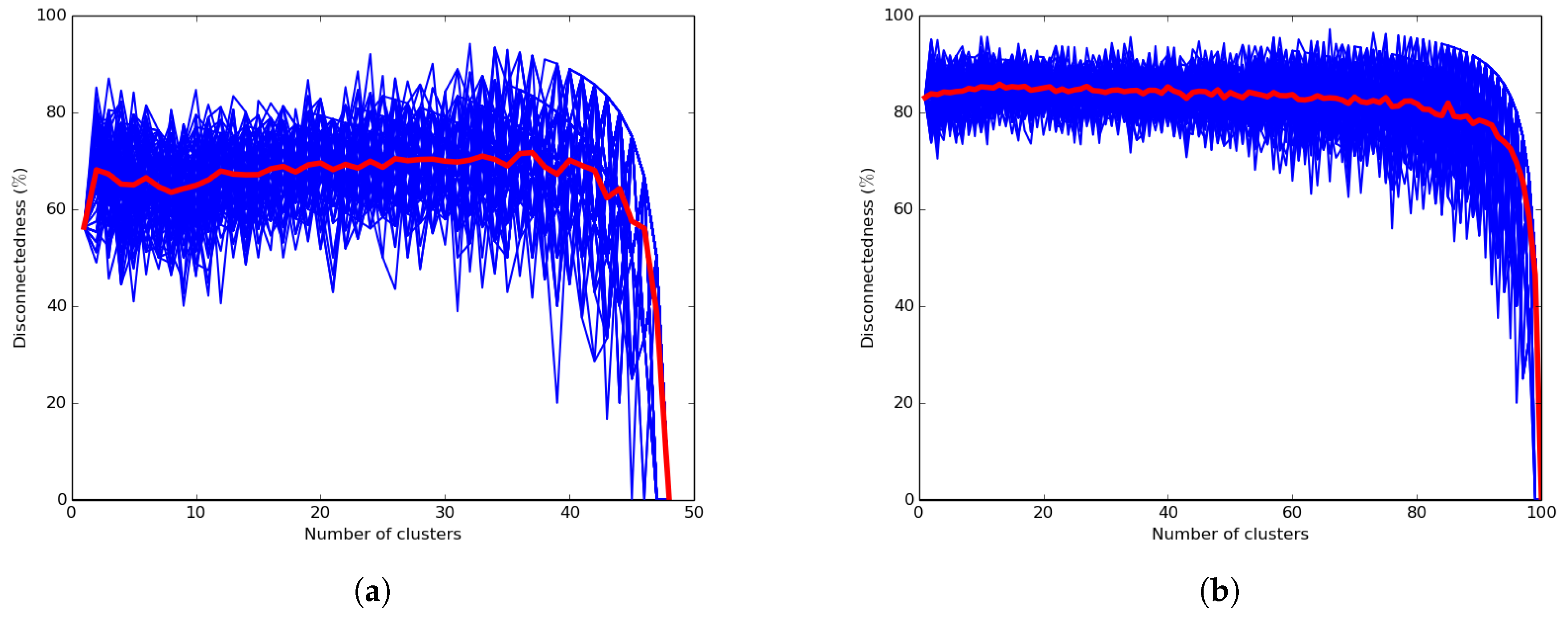
5.7. Reliability of the Family of k-Means Algorithms
6. Conclusions
6.1. Summary
6.2. Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Las Fargeas, J.; Kabamba, P.; Girard, A. Cooperative surveillance and pursuit using unmanned aerial vehicles and unattended ground sensors. Sensors 2015, 15, 1365–1388. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Wang, C.; Liu, C. Optimal number of clusters in dense wireless sensor networks: A cross-layer approach. IEEE Trans. Veh. Technol. 2009, 58, 966–976. [Google Scholar] [CrossRef]
- Duarte-Melo, E.J.; Liu, M. Energy efficiency of many-to-one communications in wireless networks. In Proceedings of the 2002 45th Midwest Symposium on Circuits and Systems, Tulsa, OK, USA, 4–7 August 2002; Volume 1. [Google Scholar]
- Chen, G.; Nocetti, F.G.; Gonzalez, J.S.; Stojmenovic, I. Connectivity based k-hop clustering in wireless networks. In Proceedings of the 35th Annual Hawaii International Conference on System Sciences, Big Island, HI, USA, 7–10 January 2002; pp. 2450–2459. [Google Scholar]
- Heinzelman, W.R.; Chandrakasan, A.; Balakrishnan, H. Energy-efficient communication protocol for wireless microsensor networks. In Proceedings of the 33rd Annual Hawaii International Conference on System Sciences, Maui, HI, USA, 4–7 January 2000. [Google Scholar]
- Gu, Y.; Wu, Q.; Rao, N.S.V. Optimizing cluster heads for energy efficiency in large-scale heterogeneous wireless sensor networks. Int. J. Distrib. Sens. Netw. 2010, 6, 961591. [Google Scholar] [CrossRef]
- Yang, H.; Sikdar, B. Optimal cluster head selection in the leach architecture. In Proceedings of the IEEE 2007 Performance, Computing, and Communications Conference, New Orleans, LA, USA, 11–13 April 2007; pp. 93–100. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm as 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.D.; Silverman, R.; Wu, A.Y. An efficient k-means clustering algorithm: Analysis and implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar] [CrossRef]
- Bradley, P.S.; Fayyad, U.M. Refining Initial Points for k-Means Clustering; MSR-TR-98-36; ICML: Redmond, WA, USA, 1998; Volume 98, pp. 91–99. [Google Scholar]
- Zha, H.; He, X.; Ding, C.; Gu, M.; Simon, H.D. Spectral relaxation for k-means clustering. In Proceedings of the 14th International Conference on Neural Information Processing Systems: Natural and Synthetic, Vancouver, BC, Canada, 3–8 December 2001; pp. 1057–1064. [Google Scholar]
- Likas, A.; Vlassis, N.; Verbeek, J.J. The global k-means clustering algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef] [Green Version]
- Alsabti, K.; Ranka, S.; Singh, V. An Efficient k-Means Clustering Algorithm. Electr. Eng. Comput. Sci. 1997, 43, 1–7. [Google Scholar]
- Kise, K.; Sato, A.; Iwata, M. Segmentation of page images using the area voronoi diagram. Comput. Vis. Image Understand. 1998, 70, 370–382. [Google Scholar] [CrossRef]
- Lu, Y.; Lu, S.; Fotouhi, F.; Deng, Y.; Brown, S.J. Fgka: A fast genetic k-means clustering algorithm. In Proceedings of the 2004 ACM symposium on Applied Computing, New York, NY, USA, 14–17 March 2004; pp. 622–623. [Google Scholar]
- Ray, S.; Turi, R.H. Determination of number of clusters in k-means clustering and application in colour image segmentation. In Proceedings of the 4th International Conference on Advances in Pattern Recognition and Digital Techniques, Calcutta, India, 27–29 December 1999; pp. 137–143. [Google Scholar]
- Luccheseyz, L.; Mitray, S.K. Color image segmentation: A state-of-the-art survey. Proc. Indian Natl. Sci. Acad. 2001, 67, 207–221. [Google Scholar]
- Ferdous, R. An efficient k-means algorithm integrated with jaccard distance measure for document clustering. In Proceedings of the First Asian Himalayas International Conference on Internet, Kathmandu, Nepal, 2–5 November 2009; pp. 1–6. [Google Scholar]
- Bezdek, J.C.; Ehrlich, R.; Full, W. Fcm: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Zang, C.; Zang, S. Mobility prediction clustering algorithm for uav networking. In Proceedings of the GLOBECOM Workshops (GC Wkshps), Houston, TX, USA, 5–9 December 2011; pp. 1158–1161. [Google Scholar]
- Shi, N.; Luo, X. A novel cluster-based location-aided routing protocol for uav fleet networks. Int. J. Digit. Content Technol. Appl. 2012, 6, 376. [Google Scholar]
- Okcu, H.; Soyturk, M. Distributed clustering approach for uav integrated wireless sensor networks. Int. J. Ad Hoc Ubiquitous Comput. 2014, 15, 106–120. [Google Scholar] [CrossRef]
- De Freitas, E.P.; Heimfarth, T.; Netto, I.F.; Eduardo Lino, C.; Pereira, C.E.; Ferreira, A.M.; Rech Wagner, F.; Larsson, T. Uav relay network to support wsn connectivity. In Proceedings of the 2010 International Congress on Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT), Moscow, Russia, 18–20 October 2010; pp. 309–314. [Google Scholar]
- Marinho, M.A.; De Freitas, E.P.; da Costa, J.P.C.L.; de Almeida, A.L.F.; de Sousa, R.T. Using cooperative mimo techniques and uav relay networks to support connectivity in sparse wireless sensor networks. In Proceedings of the 2013 International Conference on Computing, Management and Telecommunications (ComManTel), Ho Chi Minh City, Vietnam, 21–24 January 2013; pp. 49–54. [Google Scholar]
- Bandyopadhyay, S.; Giannella, C.; Maulik, U.; Kargupta, H.; Kun, L.; Datta, S. Clustering distributed data streams in peer-to-peer environments. Inf. Sci. 2006, 176, 1952–1985. [Google Scholar] [CrossRef]
- Datta, S.; Bhaduri, K.; Giannella, C.; Wolff, R.; Kargupt, H. Distributed data mining in peer-to-peer networks. IEEE Internet Comput. 2006, 10, 18–26. [Google Scholar] [CrossRef]
- Datta, S.; Giannella, C.; Kargupta, H. Approximate distributed k-means clustering over a peer-to-peer network. IEEE Trans. Knowl. Data Eng. 2009, 21, 1372–1388. [Google Scholar] [CrossRef]
- Tuyishimire, E.; Bagula, B.A.; Ismail, A. Optimal clustering for efficient data muling in the internet-of-things in motion. In International Symposium on Ubiquitous Networking; Springer: Cham, Switzerland, 2018; pp. 359–371. [Google Scholar]
- Tuyishimire, E.; Bagula, B.A.; Sanders, J.W. Internet of Things: Least Interference Beaconing Algorithms. Ph.D. Thesis, University of Cape Town, Cape Town, South Africa, 2014. [Google Scholar]
- Aurenhammer, F.; Klein, R.; Lee, D.-T.; Klein, R. Voronoi Diagrams and Delaunay Triangulations; World Scientific: Singapore, 2013; Volume 8. [Google Scholar]
- Skiena, S. Dijkstra’s algorithm. In Implementing Discrete Mathematics: Combinatorics and Graph Theory with Mathematica; Addison-Wesley: Reading, MA, USA, 1990; pp. 225–227. [Google Scholar]
- Roger Coudé. Radio Mobile. Available online: http://www.cplus.org/rmw/english1.html (accessed on 22 December 2018).
- Ismail, A.; Bagula, B.; Tuyishimire, E. Internet-of-things in motion: A uav coalition model for remote sensing in smart cities. Sensors 2018, 18, 2184. [Google Scholar] [CrossRef] [PubMed]
- Ismail, A.; Tuyishimire, E.; Bagula, A. Generating dubins path for fixed wing uavs in search missions. In International Symposium on Ubiquitous Networking; Springer: Berlin, Germany, 2018. [Google Scholar]
- Bagula, A.; Tuyishimire, E.; Wadepoel, J.; Boudriga, N.; Rekhis, S. Internet-of-things in motion: A cooperative data muling model for public safety. In Proceedings of the 2016 Intl IEEE Conferences on Ubiquitous Intelligence & Computing, Advanced and Trusted Computing, Scalable Computing and Communications, Cloud and Big Data Computing, Internet of People, and Smart World Congress (UIC/ATC/ScalCom/CBDCom/IoP/SmartWorld), Toulouse, France, 18–21 July 2016; pp. 17–24. [Google Scholar]
- Tuyishimire, E.; Bagula, A.; Rekhis, S.; Boudriga, N. Cooperative data muling from ground sensors to base stations using uavs. In Proceedings of the 2017 IEEE Symposium on Computers and Communications (ISCC), Heraklion, Greece, 3–6 July 2017; pp. 35–41. [Google Scholar]
- Tuyishimire, E.; Ismail, A.; Rekhis, S.; Bagula, B.A.; Boudriga, N. Internet of things in motion: A cooperative data muling model under revisit constraints. In Proceedings of the 2016 Intl IEEE Conferences on Ubiquitous Intelligence & Computing, Advanced and Trusted Computing, Scalable Computing and Communications, Cloud and Big Data Computing, Internet of People, and Smart World Congress (UIC/ATC/ScalCom/CBDCom/IoP/SmartWorld), Toulouse, France, 18–21 July 2016; pp. 1123–1130. [Google Scholar]
- Bagula, A.; Abidoye, A.P.; Zodi, G.L. Service-aware clustering: An energy-efficient model for the internet-of-things. Sensors 2015, 16, 9. [Google Scholar] [CrossRef] [PubMed]
- Bagula, A.; Castelli, L.; Zennaro, M. On the design of smart parking networks in the smart cities: An optimal sensor placement model. Sensors 2015, 15, 15443–15467. [Google Scholar] [CrossRef] [PubMed]
- Chiaraviglio, L.; Blefari-Melazzi, N.; Liu, W.; Gutirrez, J.A.; van de Beek, J.; Birke, R.; Chen, L.; Idzikowski, F.; Kilper, D.; Monti, P.; et al. Bringing 5g into rural and low-income areas: Is it feasible? IEEE Commun. Stand. Mag. 2017, 1, 50–57. [Google Scholar] [CrossRef]
- Masinde, M.; Bagula, A. A framework for predicting droughts in developing countries using sensor networks and mobile phones. In Proceedings of the 2010 Annual Research Conference of the South African Institute of Computer Scientists and Information Technologists, Bela Bela, South Africa, 11–13 October 2010; pp. 390–393. [Google Scholar]
- Masinde, M.; Bagula, A.; Mthama, T.N. The role of icts in downscaling and up-scaling integrated weather forecasts for farmers in sub-saharan africa. In Proceedings of the ICTD, Atlanta, GE, USA, 12–15 March 2012; pp. 122–129. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Network 1 | Network 2 | Network 3 | Units |
|---|---|---|---|---|
| n | 100 | 100 | 200 | |
| 20 | 20 | 20 | nJ/bit | |
| 21 | 21 | 21 | nJ/bit/signal | |
| 1 | 1 | 1 | pJ/bit/m2 | |
| L | 30 | 60 | 30 | m |
| a | 0.0008 | 0.0008 | 0.0008 | |
| b | 9 | 9 | 9 | |
| D | 6 | 6 | 6 | |
| 3 | 3 | 3 | nJ/bit/signal |
| Cluster Head | Cluster Members | Disconnectedness |
|---|---|---|
| 33 | 38, 47, 37, 35, 34, 32 | 66.6 |
| 3 | 25, 45, 15, 17, 44, 30, 29, 0, 6, 9 | 80.0 |
| 2 | 42, 24, 26, 27, 20, 21, 22, 23, 28, 43, 1, 5, 4, 7, 8, 11, 13, 12, 14, 16, 19, 18, 31 | 52.2 |
| 36 | 46, 10, 39, 40, 41 | 80.0 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tuyishimire, E.; Bagula, A.; Ismail, A. Clustered Data Muling in the Internet of Things in Motion. Sensors 2019, 19, 484. https://doi.org/10.3390/s19030484
Tuyishimire E, Bagula A, Ismail A. Clustered Data Muling in the Internet of Things in Motion. Sensors. 2019; 19(3):484. https://doi.org/10.3390/s19030484
Chicago/Turabian StyleTuyishimire, Emmanuel, Antoine Bagula, and Adiel Ismail. 2019. "Clustered Data Muling in the Internet of Things in Motion" Sensors 19, no. 3: 484. https://doi.org/10.3390/s19030484
APA StyleTuyishimire, E., Bagula, A., & Ismail, A. (2019). Clustered Data Muling in the Internet of Things in Motion. Sensors, 19(3), 484. https://doi.org/10.3390/s19030484