1. Introduction
Ship detection plays a critical role in maritime management, dynamic surveillance of harbors, ship rescue, etc. Remote sensing can efficiently acquire images covering the vast area of ocean, which provides unique advantages for ship detection at a large-scale. With the development of the aerospace industry, various countries have rushed to launch high-resolution imaging satellites, and the capacity of detection equipment mounted on them has also rapidly increased. This means that a large amount of raw data and good development prospect for ship detection. Due to their large-scale and high-resolution; however, we must face the challenge of handling more complex and massive data, including complicated background.
Kanjira et al. [
1] provided a review based on 119 ship detection and classification papers from 1978 to 2017. From the review we can see that there are two main types of methods for traditional ship detection. One type of method is to extract the preset features such as the shape [
2,
3,
4], aspect ratio [
5], or area of the connected region after pretreatments including sea–land segmentation. In order not to lose the details of the object, another type of method is to extract features directly using all pixels in the image [
6]. These two types of features are then used as basic information for ship detection. In these methods, the performance of ship detection depends on the design of the features. However, the method of artificially designing specific features is not robust enough to extract effective features constantly, as well as requiring a very rich professional knowledge, a large amount of manpower, and material resources. Meanwhile, the method of extracting features using all pixels is too cumbersome and brings in a large amount of redundant information. Therefore, artificial feature design is increasingly difficult to adapt to the current situation in which the amount of information is soaring.
With the development of computer vision, deep learning has achieved the great success in a wide range of problems in the past few years, such as object detection [
7], classification [
8,
9], and semantic labeling [
10]. In the field of remote sensing, many deep learning-based methods have also been proposed for object detection [
11,
12,
13,
14,
15,
16,
17], such as oil tank [
12,
13], airplane [
14,
15], and vehicle [
16,
17]. A great breakthrough has been made in ship detection based on deep learning. Meanwhile, massive high-resolution images have many detailed texture information, which coincides with the fact that deep learning requires a large number of training samples and detects objects based on image texture information. Therefore, it is suitable to adopt the deep learning method to solve the ship detection problem using large-scale high-resolution optical images.
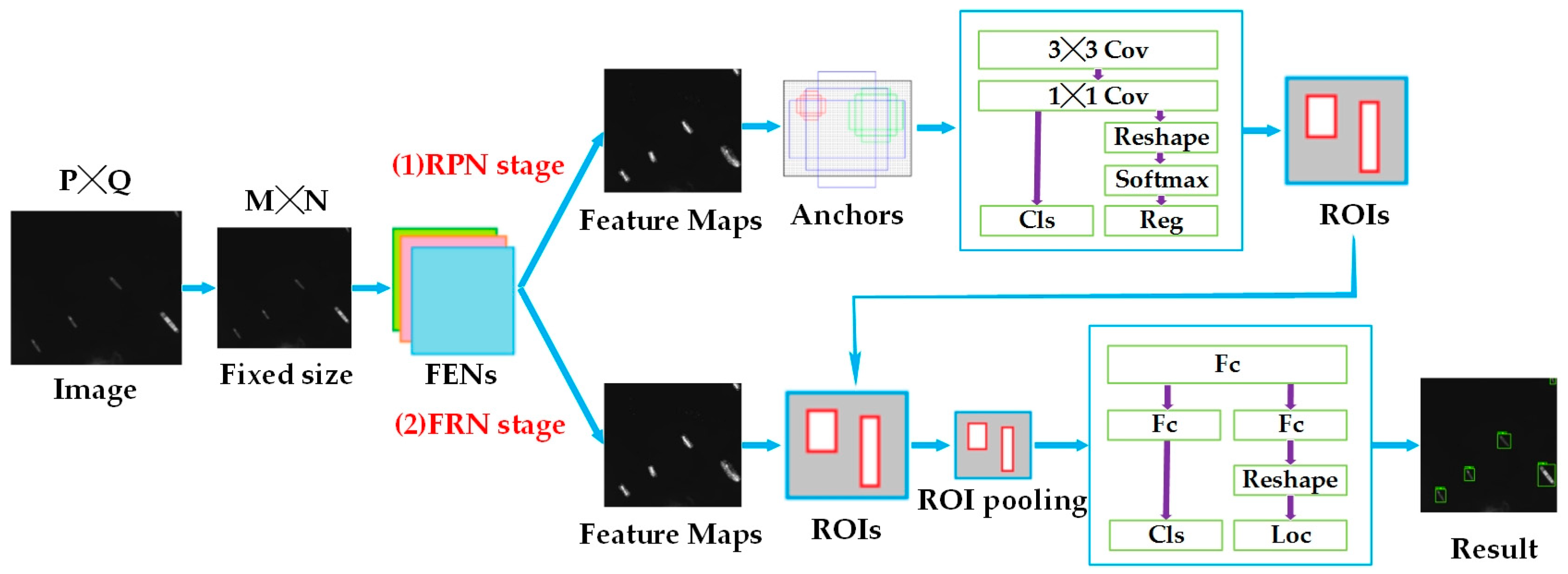
Deep learning-based ship detection in high-resolution optical images has attracted the attention of researchers in recent years and achieved a significant improvement. Zhang et al. designed a shallow neural network for ship detection based on a convolutional neural network (CNN) called S-CNN, which combines CNN with the ship head model and the ship body model [
18]. Some researchers also designed new methods based on the combination of multiscale rotation region detection and deep learning [
19,
20], which had a good effect in the task of detecting densely arranged ships, but it also caused more false alarms. The current target detection method based on deep neural networks can be roughly divided into two types. One is the method of region proposal methods [
21,
22] represented by Faster R-CNN [
21], which generates a set of potential bounding boxes then run classifiers to determine whether they contain targets. The other one reframes object detection as a regression problem and predicts coordinates of bounding boxes and class probabilities directly from the image features, such as You Only Look Once (YOLO) [
7] and Single Shot MultiBox Detector (SSD) [
23]. The major advantage of the second type of method is fast detection, yet the limitations are also obvious in which it may output incorrect localizations and it is hard to detect small targets. Unlike the general objects in the natural scene images, the size of ships in the remote sensing images is relatively small. Given that Faster R-CNN is more suitable for small target detection, the study of the detection of ships presented in this paper is based on Faster R-CNN. Inspired by Faster R-CNN, Yao et al. proposed a method which used CNN and region proposal network (RPN), in which the anchors were designed by intrinsic shape of ship targets [
24]. However, this method only analyzes the situation of ships on the sea, and does not consider the complexities of land or harbors.
The deep learning-based methods mentioned above were applied to small images of the harbors or the sea surface. The majority of traditional ship detection methods were developed using a small number of images, and mostly the images taken in a calm sea state [
1]. Here, it should be noted that two problems in ship detection for large-scale high-resolution remote sensing images are remained: the false alarm caused by a large area of nearby land and heterogeneous background of the land [
1]. As some land areas share similar intensity and texture distributions to ships, there will be a large number of false alarms when we detect ships from large-scale remote sensing images [
25].
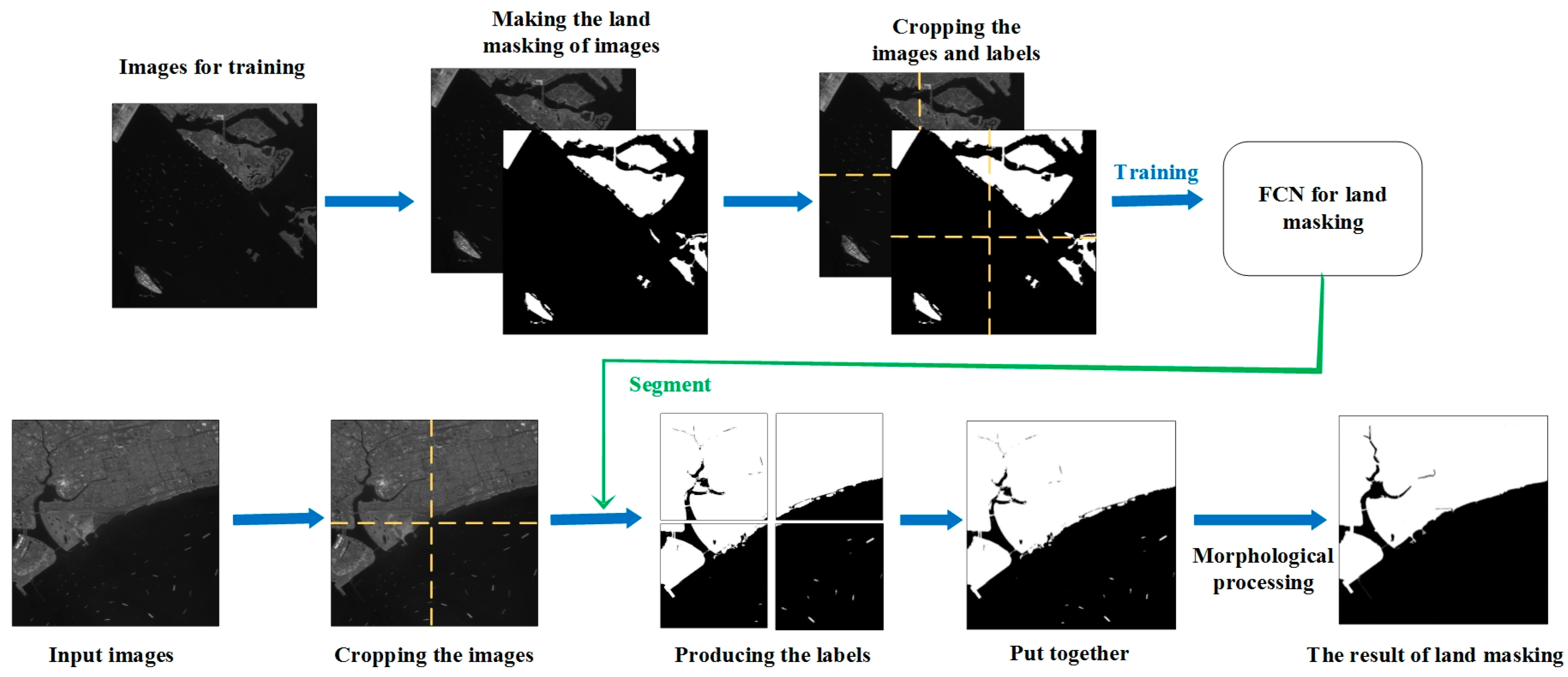
Current ship detection methods usually conduct sea–land segmentation before extracting ship features [
25,
26,
27,
28,
29] to solve these problems. Following the segmentation, we can use deep network to extract features of ships. Sea–land segmentation generally has two solutions: using available GIS layers of coastline and using grayscale and texture information of the images [
29]. However, these two methods have some disadvantages, respectively. When GIS layers is used for segmentation, they may not be up to date, as the layout of port is constantly adjusted, and the coastline changes with the seasons. With the improvement of the resolution of optical remote sensing images, the limited spatial resolution of the existing geo-location information database can no longer meet the demand for fine sea–land segmentation. Segmentation based on grayscale and texture [
30,
31,
32] is not only sensitive to the parameters selected, but also prone to misclassification. Also, segmentation using grayscale and texture information needs to be performed on the entire image. When we process an entire image, a large amount of calculate resources and time will be sacrificed. In recent years, the method of sea–land segmentation based on deep learning also emerges. It can avoid handcrafted extraction of features, but the detection of the parked ship and the large ship is still challenging [
33]. Moreover, the preprocessing steps of sea–land segmentation increase the complexity of the algorithm.
As deep learning is suitable for a large number of images to extract features, it provides high generality and capacity in target detection [
9,
19]. Deep learning network uses nontarget objects as negative samples to learn their texture features. Thus, when nontarget objects of the same category are subsequently detected, the network is trained to recognize them as background area. Therefore, another way to remove false alarms is to use the nonship objects that look like ship as negative samples to train the network. In the previous methods, docks, small islands, and other ship-shaped coastal buildings were used as negative samples to extract their features to remove false alarms [
4,
5,
28]. To improve the performance of Faster R-CNN, Li et al. proposed hard negatives, which were prone to be detected falsely by the detector [
22]. However, these methods need to specifically select and label the sensitive negative samples.
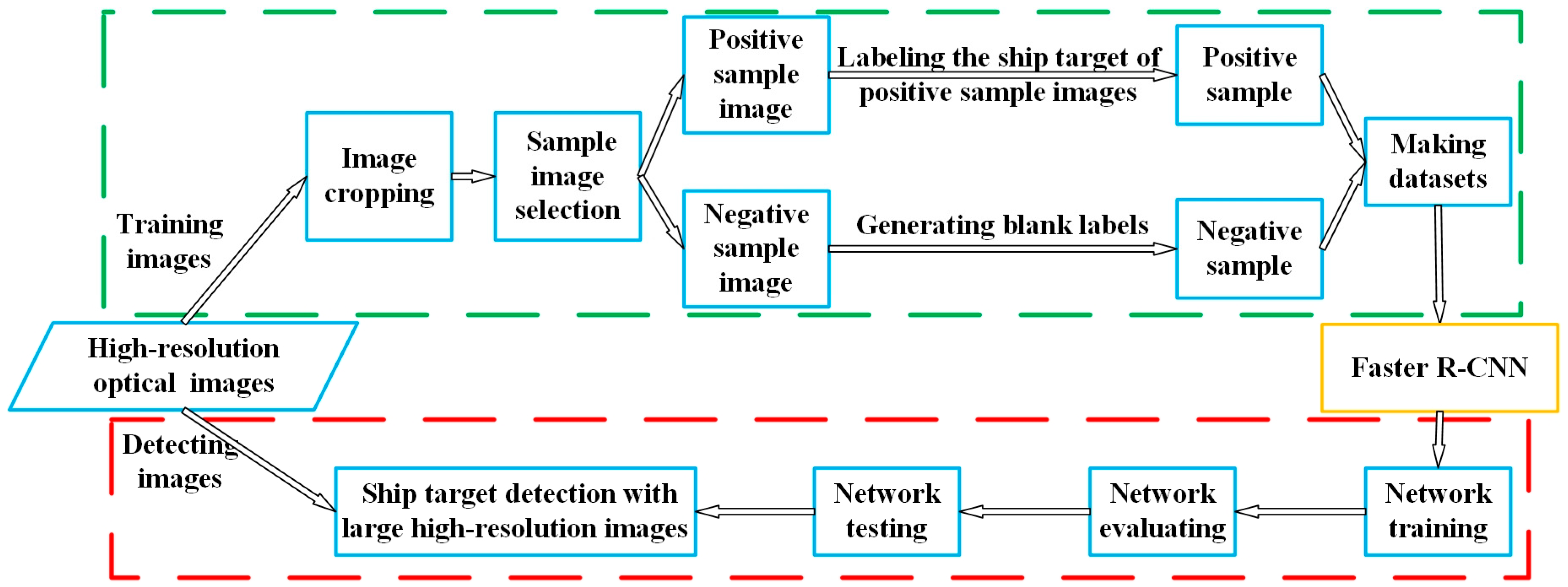
To solve the problems mentioned above, this paper proposes a ship detection method which incorporates negative sample training based on Faster R-CNN for large-scale optical images without sea–land segmentation. To avoid the false alarm on land, it adds a large number of random negative sample images (patches) containing only land area to train the network. It is different from the selection of negative samples by targeted way in other deep learning-based ship detection methods, such as the method proposed by Jianwei Li et al. [
22]. Due to the strong ability of deep learning to extract features from massive images and convert them into useful information, the false alarm caused by the land area in the large images can be avoided without the preprocessing of sea–land segmentation. The proposed method of incorporating negative sample training makes the avoidance of false alarms not limited to certain types of objects that are more prone to produce false alarms, but all terrestrial objects.
The reminder of this paper is organized as follows. In
Section 2, two detection methods based on deep learning and two sea–land segmentation methods used in this paper for comparison are detailed. In
Section 3, the processing steps of ship detection based on Faster R-CNN incorporating negative sample training proposed in this paper are presented in detail.
Section 4 presents the data and experiment settings and experimental results.
Section 5 discusses the effectiveness of the proposed negative sample training method based on deep learning with different backgrounds for detection, and its quantitative comparison with sea–land segmentation.
Section 6 draws the conclusions.
4. Results
In this part, we present the experimental results of our paper in three parts. In
Section 4.1, we present the results of comparative experiments of three deep learning-based detection networks. In
Section 4.2, we combined Faster R-CNN, which shows the best performance in the
Section 4.1, with the negative sample training proposed in this paper to achieve ship detection for large-scale images without the sea–land segmentation. We also show comparative experimental results of the proposed method with the FCN sea–land segmentation-based method.
Section 4.3 shows a detailed analysis of different test results for different images.
We used i5-7500 CPU, 16 GB RAM hardware, 6 GB Graphics card of NVIDIA 1060 and the TensorFlow framework under Linux to carry out these experiments.
4.1. Comparative Experiments of Detection Networks
To the best of our knowledge, there is no public ship dataset available for the methods test. To facilitate the research, We collected and cut some Gaofen-1 (GF-1) and Gaofen-2 (GF-2) satellite images to small size and then built them into a dataset including training, evaluating, and test datasets (as shown in
Table 1).
Figure 4 shows some images as an example.
The detection results of SSD, FPN, and Faster R-CNN on our dataset described above are shown in
Table 2. The migration learning method is used on SSD to train sufficient on our dataset.
Since FPN and Faster R-CNN have similar structures, Res101 network are used in both, and other training parameters are also the same, for example, batch size (the number of image processed each time) is 2, learning rate (determine the convergence effect of the model) is 3, and max epochs (the round numbers of calculate, the larger the value, the easier it is to converge) is 12.
The indicator of the evaluation performance is mAP (the mean average precision) [
21]. It can be seen from the comparison results that although the Faster R-CNN method has a slower detection speed, the detection performance is the best. Therefore, we choose Faster R-CNN as the basic network to incorporate negative sample training for ship detection in this paper.
4.2. Results of Negative Sample Training for Faster R-CNN-Based Ship Detection
In order to analyze the influence of different proportions of positive and negative samples on the detection performance, we used Faster R-CNN, which attained the best detection performance in the previous comparison, combined with the negative sample training to train four networks with different proportions of positive and negative samples (as shown in
Table 3).
Sample images which are shown in the previous section including positive sample images and a certain amount of negative sample images (as shown in
Figure 4b) are used to train the networks. The four networks are trained until the parameters are close to optimal, that is, the network loss values are not significantly reduced. The training parameters are introduced in
Table 3.
In order to test whether incorporating the negative samples training method proposed in this paper can reduce the false alarm on land for large images, we collected five large images taken by GF-1, GF-2, and Jilin-1 (JL-1) satellites.
Table 4 and
Figure 6 show the information of images.
As shown in
Figure 6, the test images we used include GF-2 images sheltered by thin clouds with the same proportion of the land and sea area, GF-1 images with a large proportion of land areas, and JL-1 images where the sea area accounts for a large area and the layout of harbors are more complex.
Afterwards, using the trained networks, we design experiments to compare the method of negative sample training with a method that uses the same networks to detect ships after preprocessing of sea–land segmentations of five large images with different resolutions, different sizes, and different background, including one GF-1 image, two GF-2 images, and two JL-1 images (
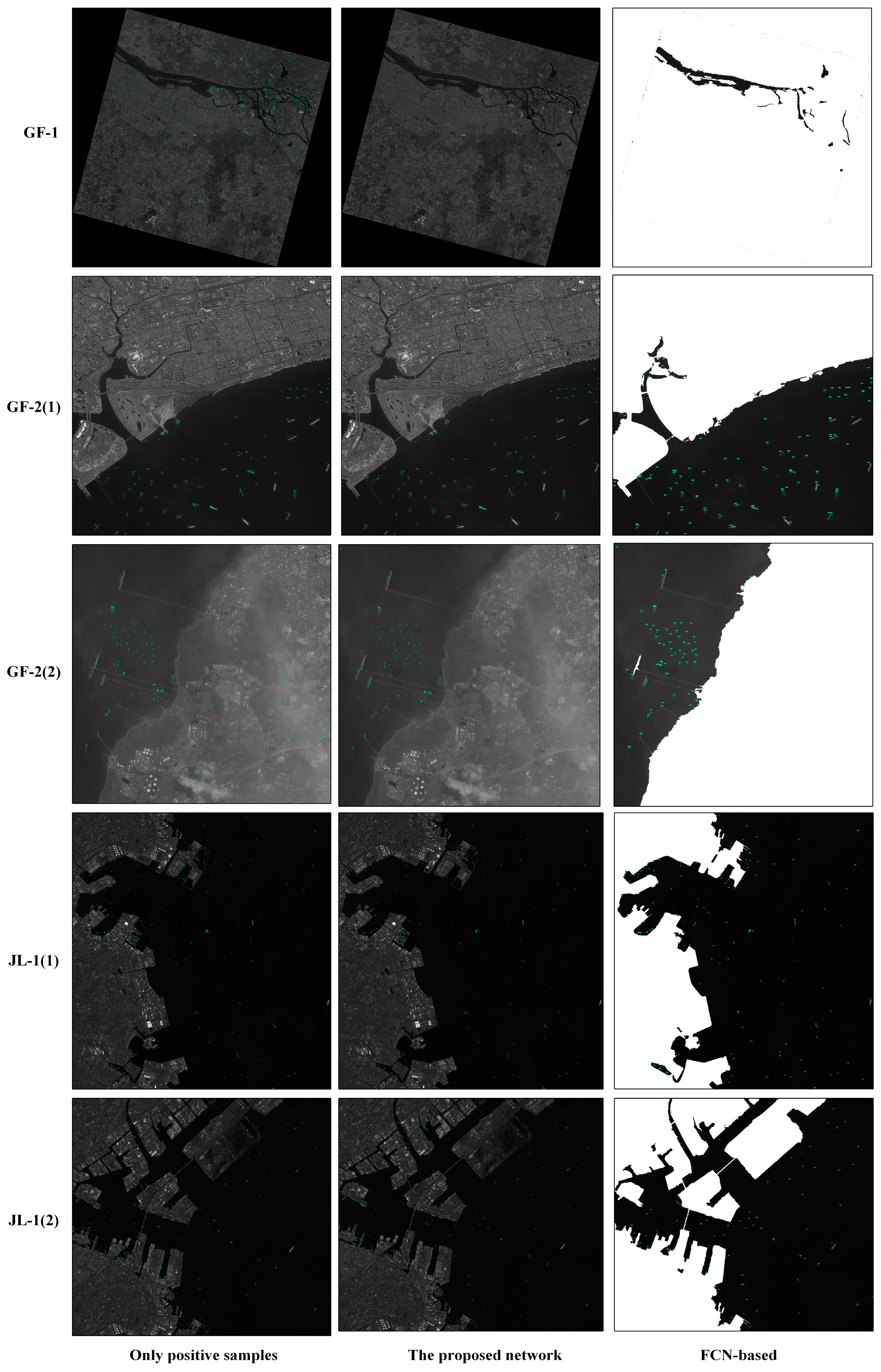
Figure 7 shows the experimental results).
We need to identify the image block-by-block when detecting ships in a large-scale image. Thus, in order to prevent ships from being missed just on the boundary between blocks, we set a 200-pixel overlap between each block. However, this also aggravates the situation that the same ship is repeatedly detected, as shown in
Figure 8a. In this case, when we calculate the recall and precision, we considered that only one ship was detected. If there is only one exterior matrix for the parallel ships in the test results as shown in
Figure 8b, we also think that the network only detected one ship.
4.3. Comparison by Using Different Images
In our experiments, the commonly used indicators are calculated for measuring the performance of ship detection: recall (R), precision (P), and F1-measure (F) [
19]. At the same time, we recorded the time required for the experiment.
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9 show the detection performance and the time consumption of detections. From
Figure 7, we can see that there are some differences in the detection results of the five images. We will introduce them separately.
(1) Panchromatic GF-1 image with a spatial resolution of 2 m and size of 21,227 × 21,227.
Since the spatial resolution of the GF-1 image is large and the water area contained in the image is only rivers, where ships in river are relatively small, the detection performance of the image is worse (as shown in
Table 5). This image contains a large proportion of land areas, so that the method incorporating negative sample training avoids most false alarms from the land. Therefore, a Faster R-CNN-based ship detection network with negative sample training has been greatly improved compared to network which is trained without negative samples; and due to the large proportion of land area, it can be seen that networks which add more negative samples have better detection performance. As the large area of the image, a large amount of time is consumed in the sea–land segmentation process, and the detection performance of the sea–land segmentation method are not very good due to the poor separation effect between the river and the land.
Figure 9 shows the detection results of the partial region of the GF-1 image.
(2) The first panchromatic GF-2 image with a spatial resolution of 0.81 m and size of 10,000 × 10,000.
The first GF-2 image has obvious sea–land boundaries, higher resolution and small image size, and almost no ships on the coast, so that the detection performance of the image are all better than those of GF-1 (as shown in
Table 6). The method incorporating negative sample training has only a small advantage in the detection performance. In the networks training with different positive and negative sample proportions, the network with the proportion of 1:2 has advantages in the detection performance. The detecting results of the partial region of the first panchromatic GF-2 image are shown in
Figure 10. It can be seen that the sea–land segmentation method divides the coastal ship into terrestrial areas, which results in missed detection. Therefore, the method based on sea–land segmentation has a low recall.
(3) The second panchromatic GF-2 image with a spatial resolution of 0.81 m and size of 10,000 × 10,000.
The second GF-2 image is covered by large thin clouds, so that the sea-land boundary is blurred. Since the network training without negative samples lacks training of more ships’ resemblances on land, it will be judged as the ship target when encountering a misty object on the shore. Therefore, the precision of the network training without negative samples is significantly lower than other networks (as shown in
Table 7). It can be seen from the third line of
Figure 7 that the FCN-based method has a better segmentation performance around harbors. Since the sea–land segmentation method completely shields the blurred objects on land, the precision of method based on sea–land segmentation is higher. However, coastal ships are also missed because they are misclassified into land area, which causes low recall for the method based on sea–land segmentation. The detection result of the partial region of the second GF-2 image is shown in
Figure 11.
(4) Two panchromatic JL-1 images with a spatial resolution of 0.72 m and size of 16,294 × 16,970.
The two JL-1 images used in the experiment are images with complex environment around the port and high-resolution with a large proportion of the sea surface. It can be seen from the experimental results that since the land area is small; whether or not adding the negative sample to train the network has little effect on the experimental results (as shown in
Table 8 and
Table 9). Additionally, the network which adds less negative sample images can achieve better detection performance. However, due to the complicated environment around the port, too many shore ships lead to too many missed detections, which reduce its recall, using the sea–land segmentation method. The detecting results of the partial region of the two JL-1 images are shown in
Figure 12.
5. Discussion
According to
Figure 7 and
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9, we analyzed the experimental results in two parts: the first part discusses the overall comparison of proposed method and other methods for deep learning-based ship detection; the second part presents an analysis of suitable detection methods for different backgrounds.
5.1. Overall Comparison of Negative Sample Training and Others Based on R-CNN
As can be seen from the results section, although the deep learning-based sea–land segmentation method can avoid handcrafted extraction of features, it still has some inherent defects like traditional sea–land segmentation methods, such as the omission caused by dividing the landing ship and the large ship into terrestrial areas, the blurred coastline caused by clouds, and so on. Moreover, the preprocessing steps of sea–land segmentation increase the complexity of the algorithm. The non-negative sample method without sea–land segmentation preprocessing also degrades its detection performance due to false alarms caused by land area. This part quantitatively analyzes the experimental results with the R-CNN-based methods of negative sample training, non-negative sample training, and FCN-based sea–land segmentation for ship detection.
At the same time, a comparative experiment based on RPN with Zeiler and Fergus model (ZF) for ship detection, proposed by Kaikai et al. [
24], is added. We implement this method with same hardware, software environment, and parameters required for training (Anchor scales of [0.25, 0.5, 1.0, 2.0], IoU of 0.5), and use the migration learning method to train sufficient on our dataset. After that, we tested the five large images using this method.
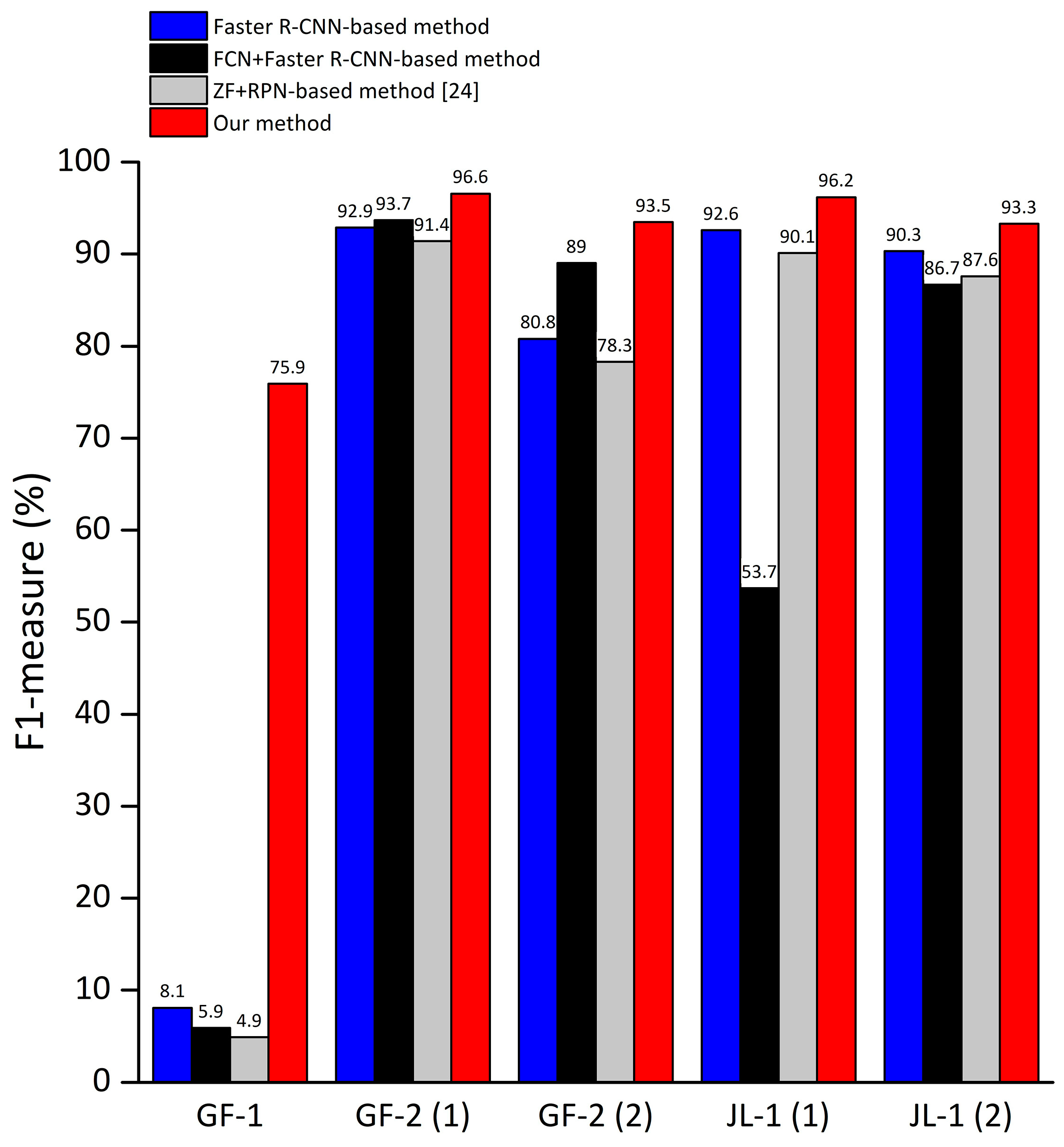
Since F1-measure is an indicator which combines the recall and precision for comprehensively reflecting the overall detection performance. For the large images used in this paper, we calculated the F1-measure and drawn into a bar graph to more intuitively demonstrate the detection capabilities (as shown in
Figure 13).
It can be seen from
Figure 13 that the proposed method mostly can get better performance than others. Specifically, for images that contain large land area such as the GF-1 image, due to the proposed method reduces the false alarm caused by land and the sea–land segmentation method cannot get segmentation results with high accuracy in river region, the proposed method has a great improvement in detection performance and the absolute increment of F1-measure of our method can reach 70% compared to the ship detection method using FCN for sea–land segmentation. For images with simple coastlines and few coastal ships such as the GF-2 images, the F1-measure of our method is slightly better or equivalent to other methods. For images with complex harbors and many coastal ships, such as the JL-1 images, since methods based on sea–land segmentation are likely to cause missed detection of coastal ships, the absolute increment of F1-measure of our method can reach 42.5% compared to method based on sea–land segmentation. Moreover, the detection performance of the Faster R-CNN method using the Res101 network as the feature extraction network is better than the method using the ZF network as the feature extraction network proposed by Kaikai et al. [
24]. From the experimental results of different images, it can be concluded that the proposed method has advantages in detection performance and robustness.
From the perspective of time consumption, the sea–land segmentation process takes a lot of time. The resulting images of sea–land segmentation obtained by preliminary segmentation methods need to be filled using mathematical morphology methods, so as to obtain the final complete sea–land segmentation results. Moreover, the method of sea–land segmentation preprocessing needs to divide the ship detection into two steps: preprocessing and detection. A larger image requires not only more computing time, but also more requirements for computer storage.
Therefore, the method incorporating negative sample training has advantages in terms of algorithm complexity, robustness, detection performance, and time consumption compared to the method of using sea–land segmentation preprocessing.
5.2. Comparison of Different Backgrounds
To different backgrounds for detection, the detection performance of different methods are different, so it is important to choose a suitable and robust detection method.
(1) Harbor
As can be seen from
Figure 10 and
Figure 12, the sea–land segmentation method is disadvantageous for ships in harbor. It can easily detect the docked ship as a land area which results in missed detection. The consequence of the miss of ship detection is very serious. Therefore, it is not recommended to adopt the sea–land segmentation method for the images containing complicated harbor.
(2) Land
According to
Figure 9, in the case of a large area land of nonharbor, quantity false alarms will occur if the network training without a large number of negative samples. From
Table 5, the GF-1 image that contains the large area nonharbor land shows that the method incorporating negative sample training can greatly improve the detection precision.
(3) Sea surface
For the sea surface background, the above methods can all achieve good performance.
(4) Rivers
Due to the complicated situation near the river, the boundaries of sea–land segmentation are not obvious and the sea–land segmentation performance is not very good. The rivers usually pass through a large number of land area, therefore, for the background of river regions, the method incorporating negative sample training is till recommended.
(5) Clouds
In the case of thin cloud cover, such as
Figure 11, due to the unclear outline of the object in the land area, there will be some false alarms in the land area without sea–land segmentation. Since the sea–land segmentation method completely shields the blurred objects on land, the precision of the method based on sea–land segmentation is higher. But the sea–land segmentation method is still not good for handling the question of coastal ship. Due to the thin cloud, the coastline becomes more blurred. It increases the difficulty of sea–land segmentation and makes the performance of sea–land segmentation worse. At this time, if there is a missed detection on the coastal ship, the recall rate will be lower using sea–land segmentation. Therefore, in the case where the image is covered by thin cloud, these methods should be selectively chosen according to specific condition.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}