1. Introduction
The traditional environmental perception of indoor service robots mainly solves the problems of localization, navigation, and obstacle avoidance in order to carry out autonomous movement. However, most of these studies focus on the description of the geometric information of an environment. The high-level perception of the environment for the indoor service robots requires more abstract information, such as semantic information like objects and scenes. With the rapid development of computer vision and artificial intelligence, many intelligent detection technologies have emerged, such as image-based object detection and scene recognition. If the service robot can recognize the common objects in the environment, it will greatly improve the environmental perception ability and the robustness of the robot, and provide a better way for human-robot interaction. However, image-based 2D object detection cannot provide the spatial position and size information of an object. Thus, it cannot satisfy the requirement of a service robot to operate in an indoor environment. Therefore, it is necessary to develop a 3D object detection technique in an indoor environment and to simultaneously recognize the object’s class, spatial position, and 3D size.
In recent years, research on convolutional neural networks has been achieved remarkable progress in the field of visual recognition. In the ImageNet Challenge, there are a large amount of emerging algorithms for image classification, such as AlexNet [
1], GoogLeNet [
2], and ResNet [
3]. Subsequently, the R-CNN [
4] algorithm is the first to apply the convolutional neural network algorithm to the object detection field in an image. Later, Fast R-CNN [
5] and Faster R-CNN [
6] have greatly improved the precision and efficiency of the object detection. In these algorithms, a feature map is obtained through convolutional neural network and spatial pyramid pooling [
7] is employed to generate the fixed dimension vector of the proposal region in the feature map. Then, the classification and object position regression are realized by the classifier and the regressor.
2D object detection algorithms based on region proposals have matured recently. In the aspect of 3D object detection, 3D vehicle and pedestrian detection in the autonomous driving field have been extensively studied. An unmanned vehicle collects the outdoor environmental information through various sensors (3D laser, cameras, and so on) and recognizes vehicles, and pedestrians. The 3D bounding box is utilized to express the precise spatial position, direction, and 3D size. On the open dataset KITTI’s website [
8,
9] for autonomous driving, there are already hundreds of algorithms that have achieved good results in terms of detection accuracy and efficiency, such as the F-PointNet [
10] algorithm, which can detect vehicles with a precision of 90% at moderate difficulty and a detection time of 0.17 s. F-PointNet [
10] and VoxelNet [
11] directly process input point cloud data through a convolutional neural network, which solves the problem of encoding and the feature extraction of disordered point clouds and obtains the end-to-end regression of a 3D bounding box. 3DVP [
12], Mono3D [
13], and 3DOP [
14] extract only 3D proposal frames directly from a monocular image and estimate a 3D bounding box. MV3D [
15], AVOD [
16], and some other algorithms combine a laser point cloud with visual information and project the point cloud to a bird’s eye view (BEV) image. The information is entered into the convolutional neural network and multiple information is fused together to estimate a 3D bounding box.
However, there are fewer studies on 3D object detection for indoor environments compared to the autonomous driving field and a mature algorithm framework has not yet been formed. The dataset for indoor 3D object detection mainly includes NYU V2 [
17] and SUN RGB-D [
18] datasets, which consist of some common indoor objects, such as tables, chairs, beds, and so on, with the labeled 3D bounding boxes for objects. In an indoor environment, image and depth information are usually acquired by using RGB-D sensors such as Kinect. Currently, most algorithms employ RGB images or point clouds for object detection [
19,
20]. Since the BEV image provides information perpendicular to the camera viewpoint, the spatial distribution of the object can be clearly expressed. According to the authors’ knowledge, there is no such a method that utilizes the BEV image as the input information among the current indoor object 3D detection methods. Therefore, this paper proposes a multi-channel neural network system that combines the RGB, depth, and BEV images to achieve the 3D indoor object detection.
The main contributions of this paper are as follows: a multi-channel convolutional neural network-based 3D object detection for indoor robot environmental perception, which combines RGB, depth, and BEV imagesas the input. The BEV image is generated using point cloud projection and it is used as an input to the neural network to enhance the object detection accuracy. To the best of our knowledge, this is the first algorithm that combines the BEV image for 3D indoor object detection. In addition, a 3D proposal generation algorithm based on image semantics is proposed. Based on 2D image proposals, the category with the maximum probability is determined using statistical pixel semantic information, and the 3D proposal bounding box is determined according to the a priori size of the object.
The structure of this paper is organized as follows:
Section 2 summarizes the recent research in the area of 3D object detection;
Section 3 describes the proposed multi-channel CNN for 3D object detection in detail;
Section 4 presents experimental results of the algorithm; and finally,
Section 5 summarizes the content of the article.
3. Multi-Channel 3D Object Detection CNN
Since an image is a 3D projection in two dimensions, it is quite difficult to fully express 3D information. A depth image expresses the distance of an object to a camera plane, and a BEV image describes the distribution of the spatial object from a perspective perpendicular to the camera’s viewpoint. Therefore, the fusion of multiple kinds of information is beneficial for the better detection of objects in 3D space. In this paper, a 3D object detection CNN combining three-channel information is designed. RGB image, depth, and BEV images are used as the input of the network, and the object’s category, 3D size, and spatial position are regressed, respectively.
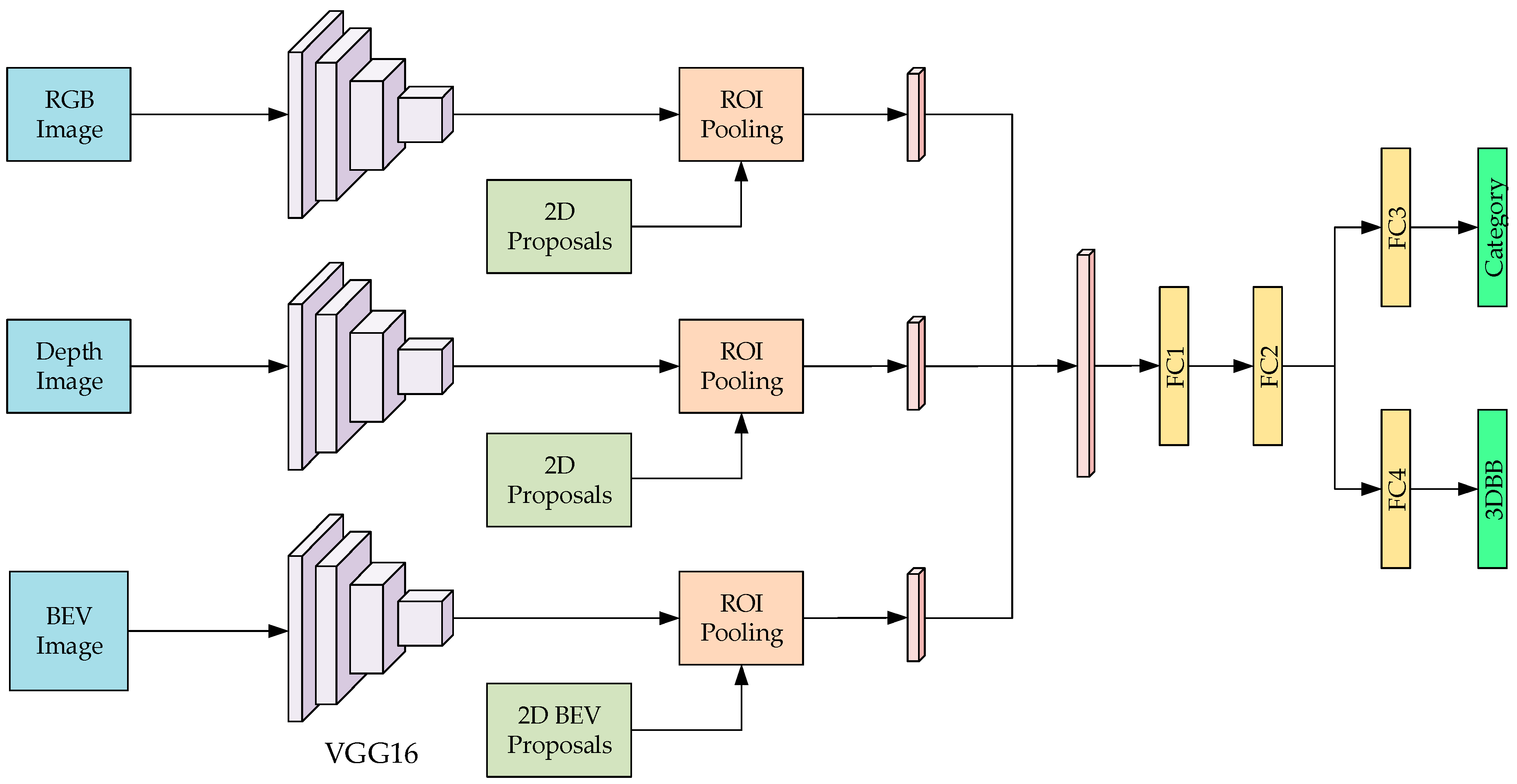
The designed multi-channel object detection neural network system is shown in
Figure 1. The Fast R-CNN is employed as the basic network structure to extend the 2D image object detection to the 3D object detection. The input is extended to three channels including an RGB image, a depth image, and a BEV image. VGG16 is utilized as the main convolutional network structure for feature extraction to enhance the learning of 3D spatial information. We employ the multiscale combinatorial grouping (MCG) [
35] algorithm to generate many 2D proposals in the RGB image. As the depth image is the same view angle with the RGB image, it shares the same 2D proposals in the depth image. Then, we combine the 2D proposals with the depth information and semantic prior knowledge to generate 3D proposals, and then project them to the BEV plane. Finally, we can obtain 2D proposals for each channel. Then, the pre-obtained 2D proposals in each channel are utilized to generate the feature vectors with the same dimension using a single-layer spatial pyramid pooling layer, and then all vectors are connected as a whole vector. Finally, a multi-task regression is performed through two layers of fully connected layers to predict the object category and the 3D bounding box.
3.1. Input Data Generation for Convolutional Neural Network
In order to increase the network’s ability to perceive 3D information, a BEV image is generated from the RGB and depth images and it is used as an additional input to the convolutional neural network. Based on the processing methods of an RGB image as an input to a convolutional neural network, the depth and BEV images are quantized into the pixel range of [0,255], and then they are used as the input of the network.
The depth image acquired by the RGB-D sensor stores distance information, and the defined maximum depth is
, and the depth value
was quantized to the image range
as:
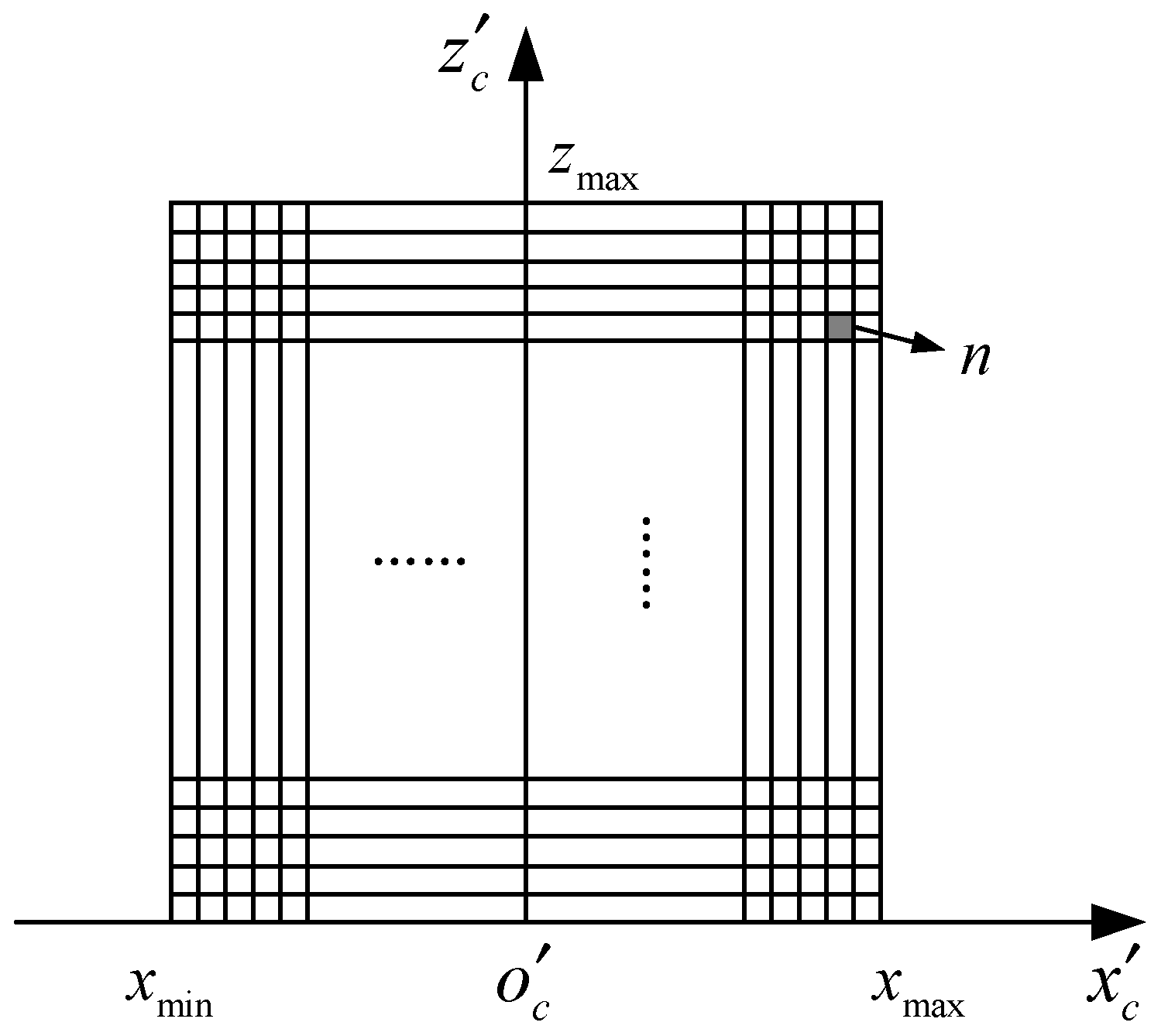
A point cloud is generated from the RGB and depth images, and it is projected onto the ground and rasterized to generate a BEV image. The BEV image is represented by the number of point clouds in each 2D grid cell. In a typical indoor environment, the range of depth images acquired by the RGB-D sensor is limited, so the range of the point cloud is limited to generate a BEV image of the same size. To illustrate it clearly, we provide the projected coordinate system of the camera to the BEV plane, as shown in
Figure 2. The origin point
is projected from the one of camera coordinate system and the orientations of
and
are oriented according to the ones of camera coordinate system. Let the coordinate system have a range of
in the
x-axis direction,
in the
z-axis direction, and
is the resolution of the grid, then the size of the BEV image is
. Due to the different spatial point cloud density, the number of point clouds projected into each cell is very different, which is not conducive to data processing. Therefore, it is logarithmically transformed and converted to the image pixel range. Let the number of points in one cell of the BEV image be
and the maximum number of points in one cell be
, then the quantized image pixels are:
3.2. 2D and 3D Proposals Generation Based on Semantic Prior
The main idea of Fast R-CNN for object detection is to obtain the feature map of a whole image through the convolutional neural network and to employ the spatial pyramid pooling layer to extract features from the pre-generated 2D proposals in the image. The classifier is used to judge the features extracted in the proposal belonging to which category. The position of the proposal is adjusted by the regressor. This paper draws on the detection strategy based on the region proposal to extend 2D image detection to the spatial 3D object detection. Therefore, it is necessary to first acquire the 3D proposal of the object before performing category detection, 3D position, and size regression on this basis. In addition, it is also necessary to project the obtained 3D proposal back to BEV image to get a consistent proposal with the other input channels.
3.2.1. 3D Proposal Parameter Representation
The regression of the 3D object is parameterized into a seven-dimensional vector
.
is the coordinate of the center point of the object bounding box in the camera coordinate system.
are the length, width, and height of the bounding box, respectively.
is the angle (with the range of
) between the
z-axis direction of the camera coordinate system and the longer edge of the bounding box projected on the
plane. The initial value of the object center point can be computed based on the point cloud corresponding to the proposal. Since noise always exists in measurement and data are often missed in the point cloud, the median value in the
z-axis direction is taken as the initial value
, and
and
can be solved with the camera parameters:
where
is the center point of the proposal in the image;
is the center point of the image; and
,
are the focal lengths.
Since the point cloud of the proposal may contain a background point cloud other than the object, the error will be large if the initial size of the object is directly obtained by the point cloud. For common objects in the indoor environment, such as sofas and chairs, similar objects usually have similar dimensions; therefore, the average size of the objects on the dataset can be used as a priori knowledge to determine the size of the 3D proposal. In addition, since it is difficult to estimate the directional angle of the 3D proposal in the initial stage, all the initial angle values are set to zero for the sake of simplicity.
3.2.2. Proposals Generation
The 3D object detection neural network proposed in this paper is based on the Fast R-CNN network structure. The single-layer spatial pyramid is utilized to pool the object proposal of different sizes in the feature map in order to obtain the output vector with the same dimension. Therefore, it is necessary to obtain object proposals in three channels separately. Since the RGB image and the depth image are acquired under the same view angle, the same proposal can be shared. However, the BEV image is obtained using the point cloud projection and has a constraint relationship with the RGB and depth images. Thus, it is vital to solve how to generate the object proposal in all three channels.
Searching for a suitable proposal box in a 3D space is usually computationally intensive and inefficient. Since the method of extracting the proposal from a 2D image is relatively mature, the 3D information can be acquired by combining the depth image. Multiscale combinatorial grouping [
35] (MCG), which generates 2D bounding box proposals in RGB images, usually generates thousands of object proposals of different sizes. In the camera coordinate system, a depth image can be combined to generate a point cloud for each proposal box. According to the representation of the 3D proposal in
Section 3.2.1, the center point of the proposal can be computed.
During training, the proposal samples needs to be divided into positive samples and negative samples. In order to determine the possible categories of proposals, the IoU (intersection over union) is calculated between the proposal and each 2D ground truth bounding box in the image, and the category corresponding to the largest value is selected. Inspired by the image semantic segmentation, we can obtain the pixel-level semantic category in the image and count the number of pixels with the same semantic category in the 2D proposal in order to analyze the probability for the proposal to belong to a certain category. This information can be used to judge the positive and negative samples when training. In order to better select the positive and negative samples, the ground truth in the RGB image is used to comprehensively calculate the category’s probability of each proposal. Let the number of pixels in the ground truth (belonging to the same category as the ground truth) bounding box be
; the area of the bounding box be
; and the number of pixels of the category in the intersection area be
, which is the common area between the 2D proposal and the ground truth bounding box; and the proposal box area be
such that the score of the proposal belonging to the category can be calculated by the following formula:
The scores between the proposal box and each ground truth bounding box are calculated and the ground truth’s category corresponding to the maximum value is taken as the category of the proposal.
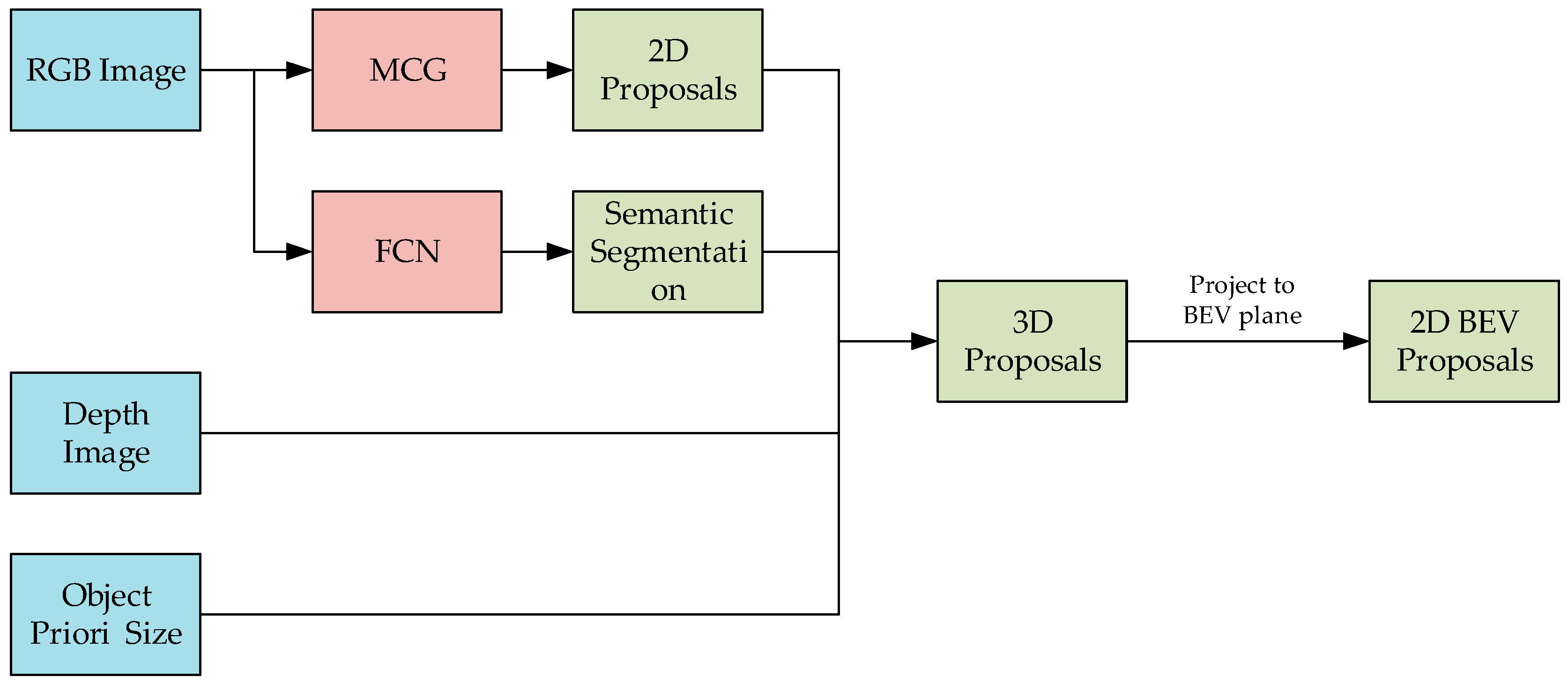
A diagram of the system to generate the 2D and 3D proposals required for training is shown in
Figure 3. First, the MCG algorithm is applied to obtain the 2D proposals in the image. The semantic segmentation of the image is obtained using the full convolutional neural network (FCN) algorithm. Then, the maximum possible category of the proposal is calculated. Finally, an initial value of the 3D proposal corresponding to each 2D proposal is obtained by combining the depth image and the a priori size of the object. In order to obtain the proposal in the BEV image, the 3D proposal is projected into the BEV image, and a BEV image proposal corresponding to each proposal in the image was obtained.
3.2.3. 3D Bounding Box Regression of Objects
The designed multi-channel convolutional neural network extracts the features of the RGB image, depth image, and BEV image. The features in 2D proposals are transformed into uniform size vectors through the RoI pooling layer and connected to a whole vector. Finally, the predicted results of the network are obtained by the classifier and the 3D bounding box regressor. For each positive sample, the output of the network is relative to the ground truth bounding box, which is a seven-dimensional vector
. For each proposal, the ground truth category of the maximum probability is obtained according to the above method, and the normal value and the 3D proposal predicted value are applied for normalization:
where
is the 3D proposal predicted value generated by the 2D proposal, and
is the ground truth of 3D bounding box corresponding to the maximum probability of the 2D proposal.
3.2.4. Multi-Task Loss Function
For joint training classification and bounding box regression, the designed multitask loss function is:
where
is the classification loss function, using the Softmax function.
is the 3D bounding box prediction-loss function, using the
smooth-loss function.
is the coefficient to balance the two loss function values.
4. Experiments
In order to verify the proposed multi-channel object detection neural network, the open source dataset NYU V2 is selected for experiments. The datasets are collected using an RGB-D camera in several indoor scenes. It consists of color and depth images and labeled 3D object bounding boxes. The training dataset contains 795 images and the test dataset contains 654 images. Zhuo et al. [
34] re-label ground truths of the partial bounding boxes in some images in order to enhance the correct rate of the positive samples in images during training. Therefore, in order to facilitate fair experimental comparison with the work by Zhuo et al. [
34], the modified NYUV2 dataset is adopted in the experiments.
4.1. Training Data Generation
To train the multi-channel neural network described in
Section 3, the relevant training data needs to be prepared, such as RGB images, depth images, BEV images, 2D proposals in three channels, and the corresponding 3D proposals.
RGB and depth images are already included in the dataset. However, the BEV images need to be generated. As the NYUV2 dataset is collected by using a Kinect sensor, the range of the point cloud should be limited in order to acquire the same size for the BEV image obtained by the point cloud projection. In the camera coordinate system, the range of the x-axis direction is [−2.5 m,2.5 m], and the range of the z-axis direction is [0,5 m]. The point cloud is projected onto the plane to obtain a BEV image. The resolution of the grid is set as 0.01 m, then the size of the BEV image is 500 × 500 pixels.
In the RGB image, 2D proposals are generated by using the MCG algorithm. Since the depth image and the RGB image have the same viewpoint, the proposal of the depth image is consistent with the proposal of the image. The 3D proposal is generated according to the algorithm described in the third section, and the image semantic segmentation is done by using FCN. Then, the proposal is scored according to the ground truth of the 2D bounding box in the image and the proposal category is one of the bounding boxes with the highest score. A 3D proposal is generated based on the average size of each type of object on the training set as an initial value. The 3D proposal box is projected onto the BEV image to obtain a plan view proposal box corresponding to the 2D proposal frame in the image. Data augmentation is performed during training. The progress is that the 2D proposals are flipped horizontally in the image, and the corresponding proposals in the 3D proposals and the BEV image are simultaneously flipped.
Since the categories of semantic segmentation based on FCN in the NYUV2 dataset are not completely consistent with the categories of 3D object detection, FCN lacks two categories named "garbage bin" and "monitor" compared to the object categories in Zhuo et al.’s work [
34]. Therefore, the two categories are removed and the remaining 17 categories were used.
4.2. Training Parameter Setting
The Caffe framework is applied during training, and the pre-trained VGG16 model on ImageNet is utilized to initialize the parameters of the forward channel of the network. The coefficient λ in the loss function is set to 1; the base learning rate is set to 0.0005; and the learning strategy is "step", which is multiplied by 0.1 every 10,000 iterations. The stochastic gradient descent algorithm is employed to implement 40,000 iterations. Two images are randomly selected in each batch, 128 proposals are randomly selected in each image, and the ratio of positive samples to negative samples is 1:3. It takes about 4 h to iterate 40,000 times in an NVIDIA DGX Station (Tesla V100 GPU, NVIDIA, Santa Clara, CA, USA). During the test, the forward channel average inference time is around 0.18 s.
4.3. Experimental Results and Analysis
Experiments are carried out on the modified NYUV2 dataset [
34] and they are compared with two recently related papers [
27,
34]. The experimental results are shown in
Table 1. The proposed algorithm improves the average accuracy compared with the previous works [
27,
34], and the performance of the algorithm after adding the BEV image is also verified. In most categories, the accuracy is improved by several percent, especially for objects that are relatively independent in the BEV image, such as beds, chairs, and sofas. To illustrate the details of the algorithm, we conduct an ablation study on the dataset. The results are shown in
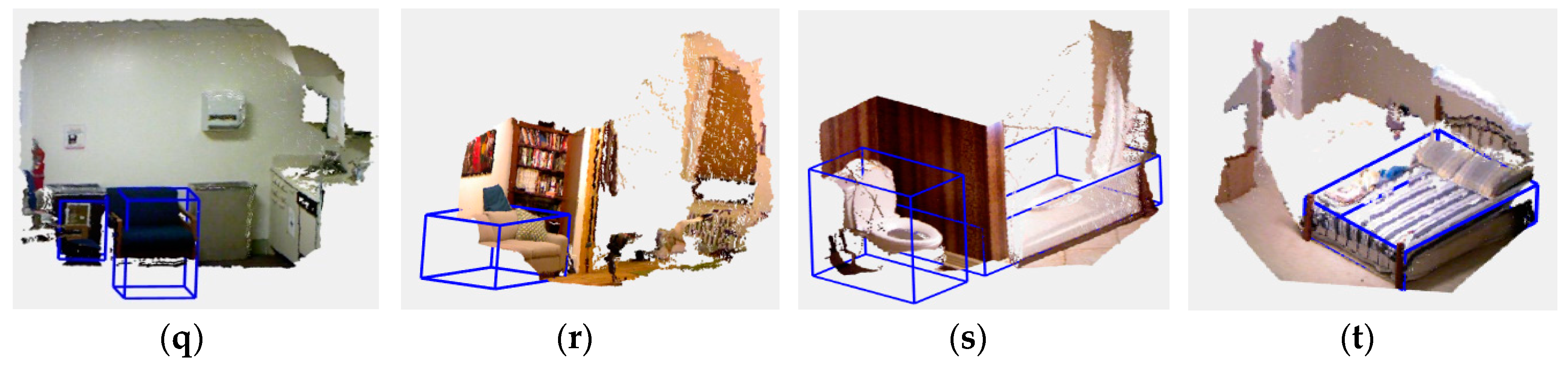
Table 2. We remove the BEV channel to verify the effect. Furthermore, we can observe that the average accuracy is improved by 3.1% with the BEV channel. To observe the results more intuitively, we give some examples with all the input images and results, as shown in
Figure 4. It shows the detection results in four different categories (chair, sofa, toilet, and bed). The figure shows the input three channel images (RGB, depth, and BEV images), semantic segmentation images, and point cloud images in which the detected 3D object bounding boxes are displayed. From the detected 3D bounding boxes, we can observe that the sizes and positions of different objects are estimated well.
To verify the performance of the algorithm sufficiently, we carry out another experiment on the SUN RGB-D [
18] dataset, which contains 10,335 RGB-D images and 64,595 3D bounding boxes. We train the model using our method and compares it with other previous works [
27,
36], which are also tested in the same dataset. The experimental results are shown in
Table 3 and it can be observed that our method can achieve better performance in most categories and had a certain improvement in the mean average precision.
In order to utilize the 3D object detection for indoor robot environmental perception, we conduct experiments in a service robot in three indoor scenes. A Kinect RGB-D sensor is used in the robot to collect RGB and depth images. As the robot moves in the environment, the ORB-SLAM2 [
37,
38] algorithm with a dense point cloud is employed to estimate poses of the robot and establish a dense map in our experiments. Then, the 3D object detection algorithm in this paper is implemented only in the keyframes of ORB-SLAM to decrease the computation. Because one object can be observed in several keyframes, the 3D bounding boxes of objects are transformed into the system coordinates and the average position and size of the same object’s 3D bounding boxes are calculated. The experimental results are shown in
Figure 5. 3D maps are constructed and several 3D object bounding boxes are shown in each Figure. In
Figure 5a, four chairs are detected in an office; in
Figure 5b, three sofas and a television are detected; and in
Figure 5c, a bookshelf and two sofas are detected. In order to measure the results of the algorithm quantitatively, the estimated 3D bounding boxes of objects are given and compared with the ground truth, as shown in
Table 4. To facilitate measurement, we select
Figure 5b,c to conduct the test as the 3D bounding boxes of objects in these scenes are almost parallel to each other and it is easy to measure the ground truth. The Kinect RGB-D sensor is fixed on the robot with the height of 1.2 m. We keep the sensor parallel to the object at the beginning when conducting the ORB-SLAM2 algorithm and set the coordinate system of the first keyframe as the global one (the coordinate system drawn in
Figure 5b,c). Then, we transfer the estimated results in each keyframe to the global coordinate system. In
Table 4, we give the 3D bounding box ground truth of objects and the estimated results using our method in the global coordinate system. Finally, we calculate the 3D IoU (intersection over union) of 3D bounding boxes to measure the accuracy. The average 3D IoU is 0.61 and we can observe that our method detect the sofa with higher accuracy than the bookshelf and television. During the 3D object detection, it takes about 2.2 s to regress the 3D bounding box with a Tesla V100 GPU (about 1.6 s to extract region proposals in each keyframe based on MCG, 0.42 s to obtain the semantic segmentation using FCN, and 0.18 s to run the forward inference). Experimental results verify that the proposed algorithm can benefit robot environmental perception using 3D object detection.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



