A Comprehensive Technological Survey on the Dependable Self-Management CPS: From Self-Adaptive Architecture to Self-Management Strategies

 ,
, 
Abstract
:1. Introduction
1.1. Motivation and Goal of This Survey
1.2. Literature Search Rule
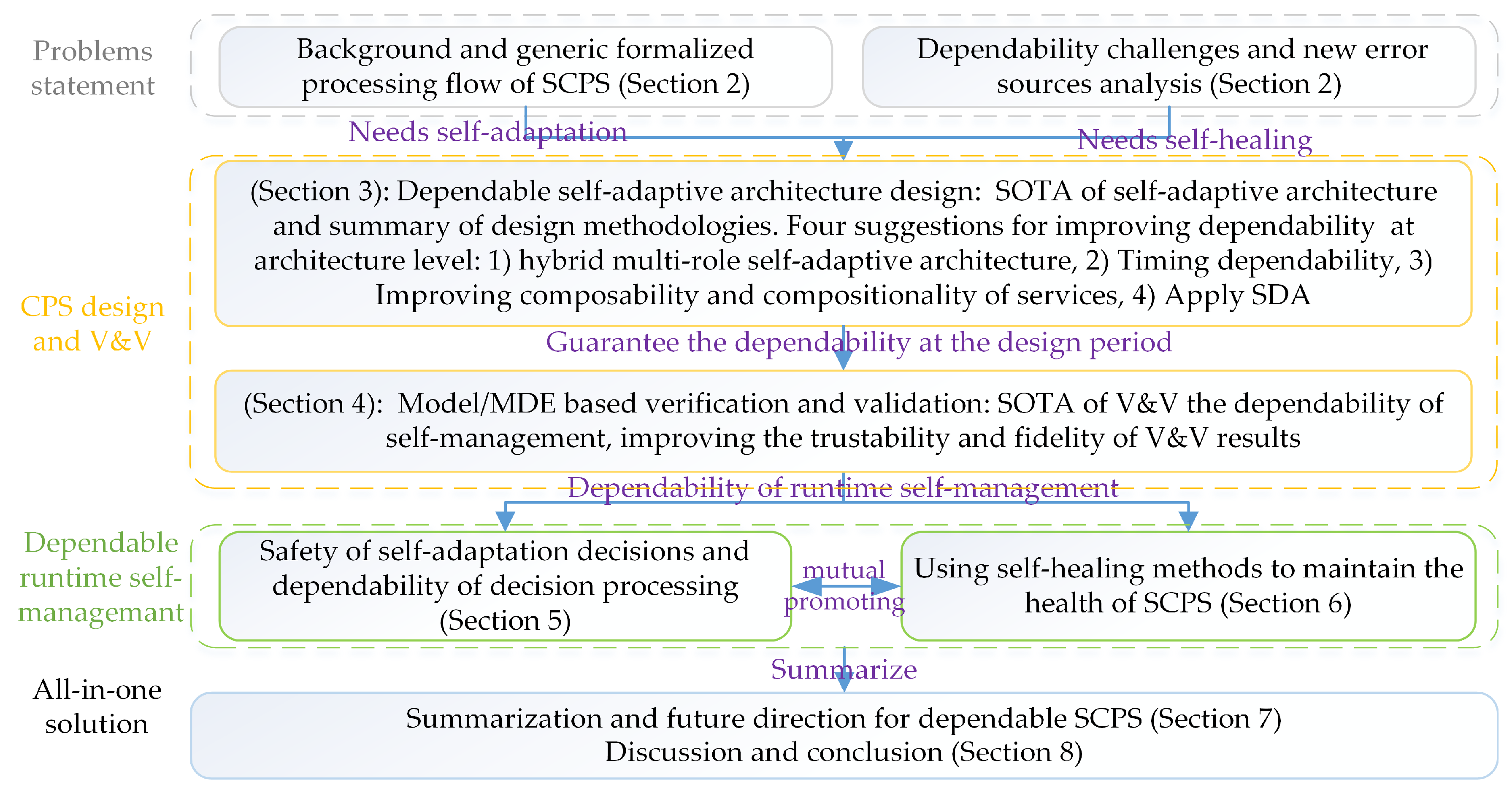
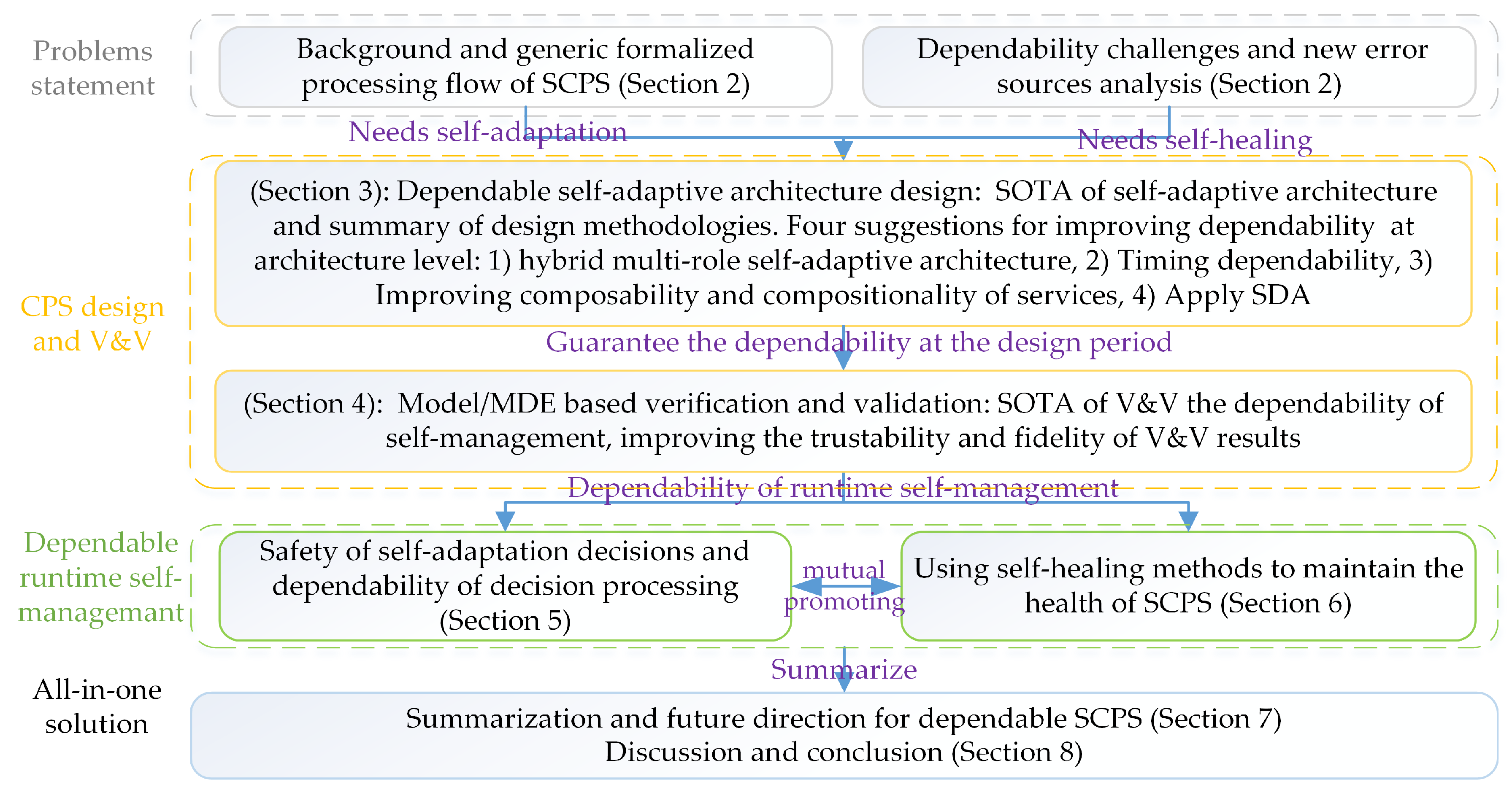
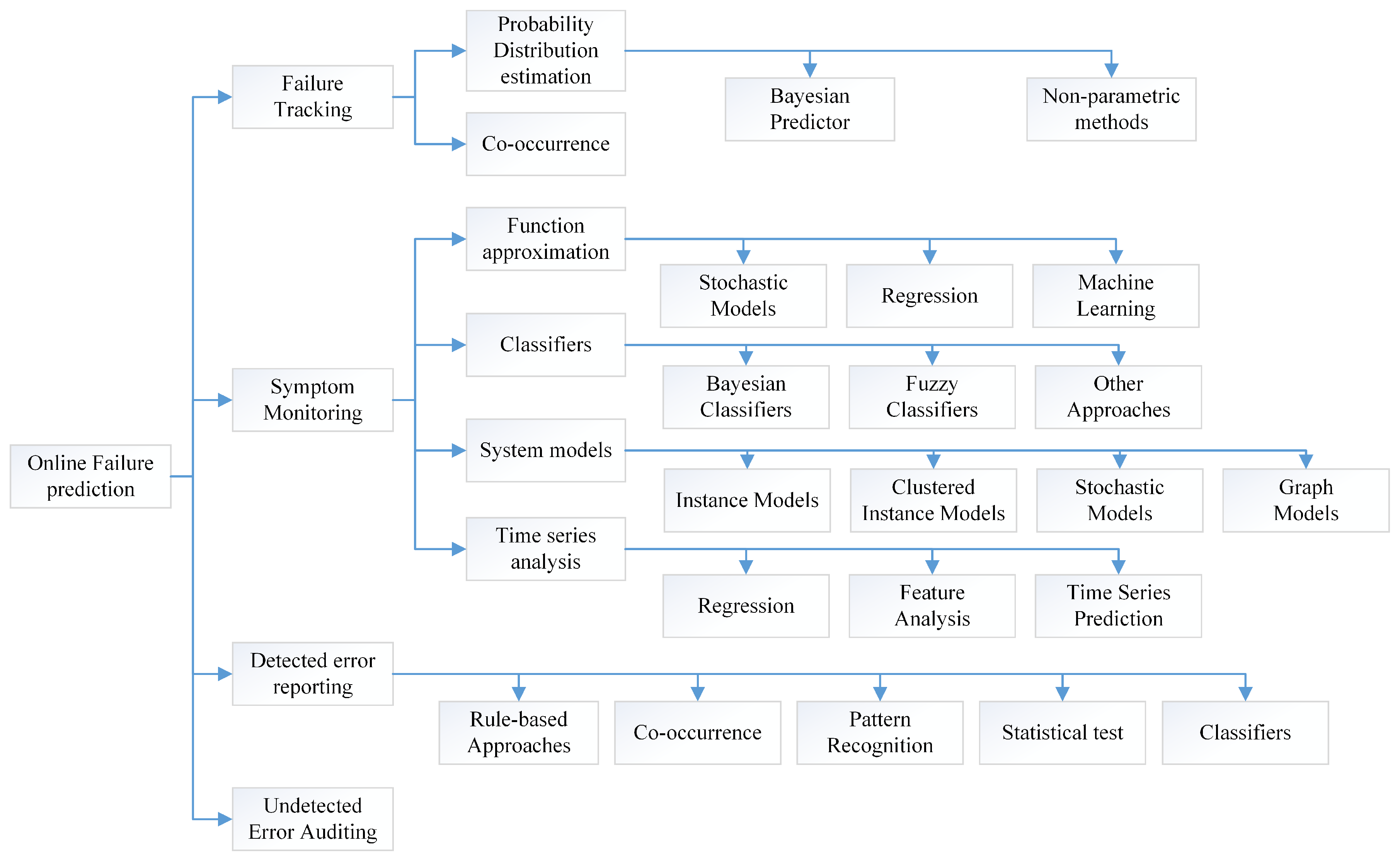
1.3. Structure of This Survey
2. Background and Overview of Challenges of Dependable SCPS
2.1. The Methodology for Dependable SCPS Engineering
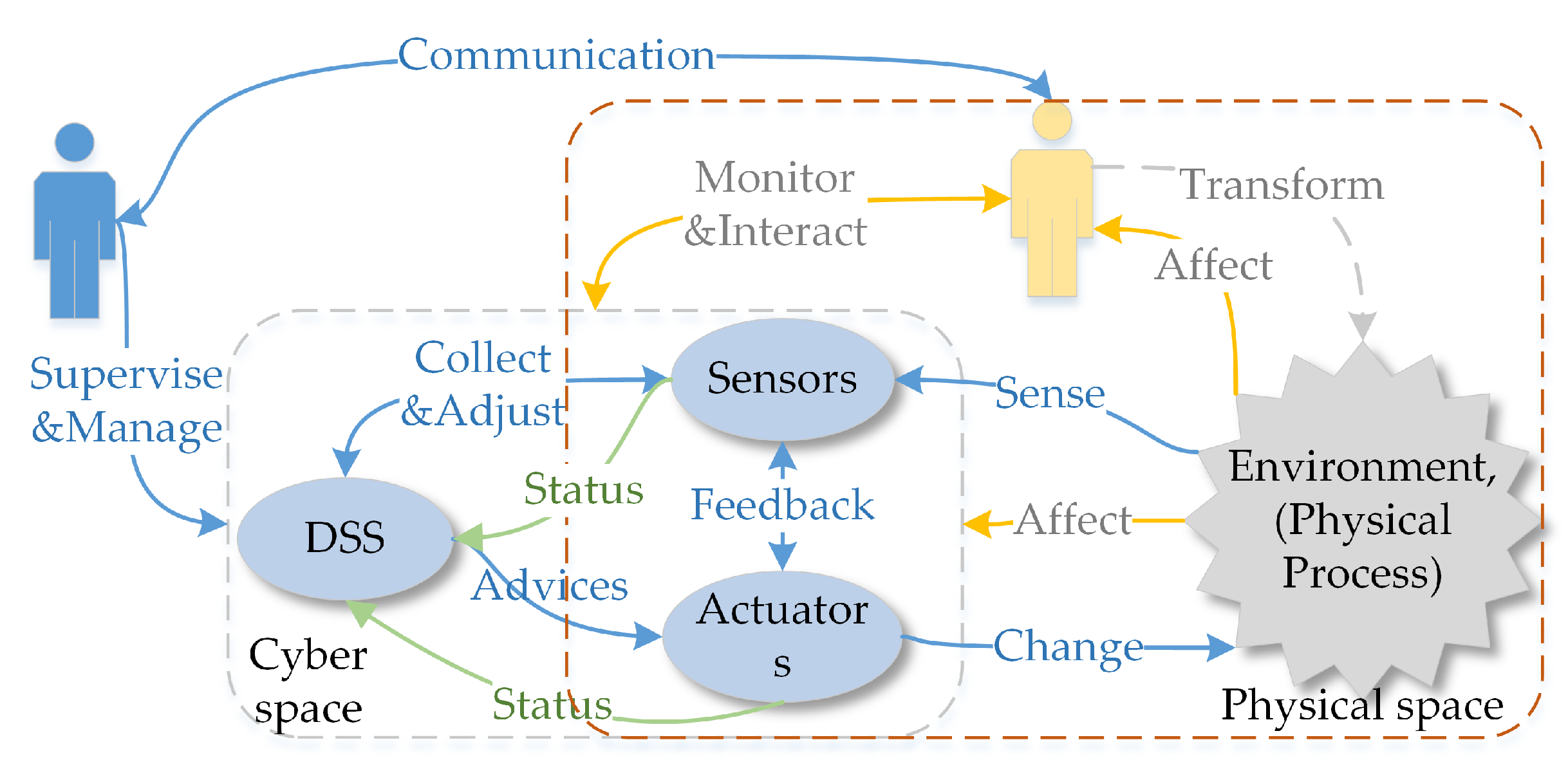
2.2. The Process Flow of Dependable SCPS
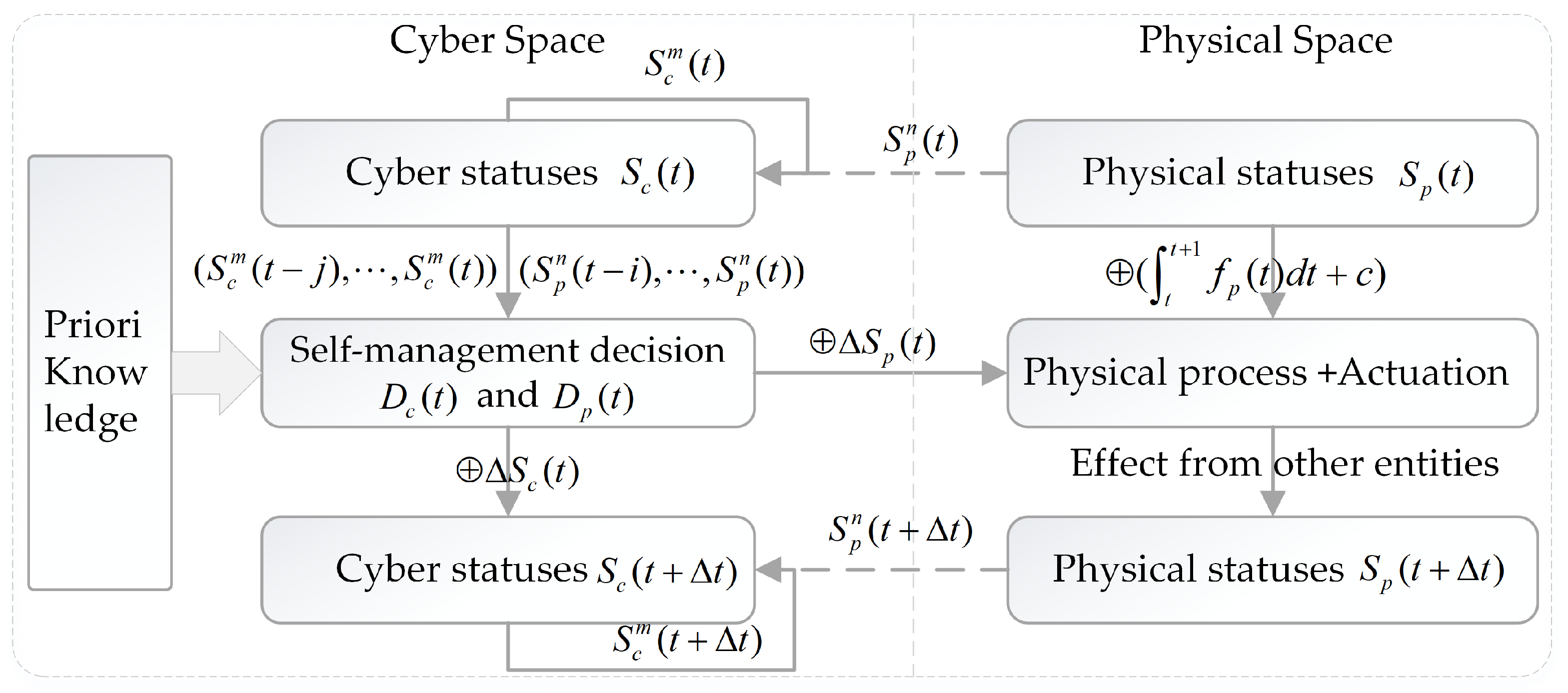
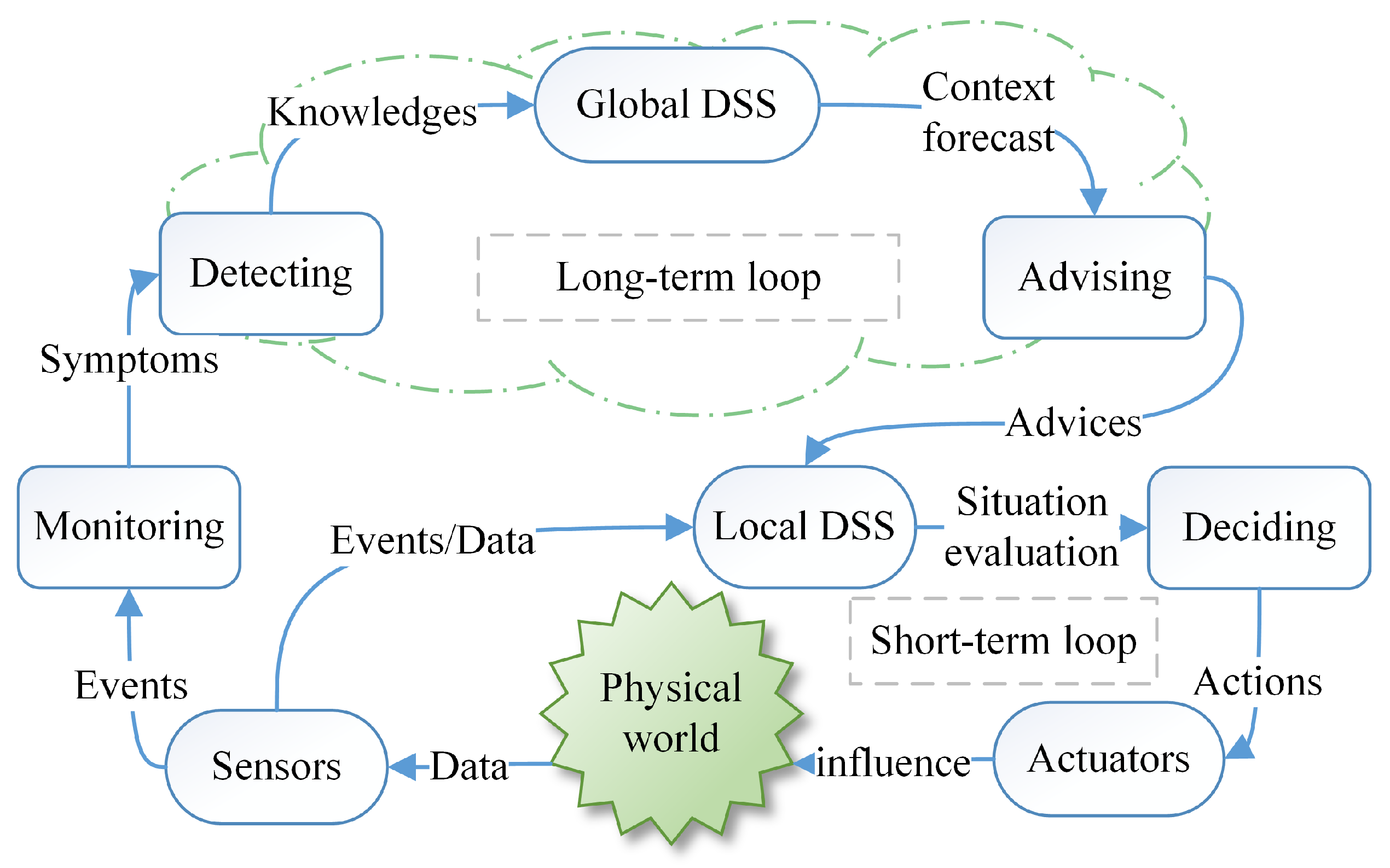
2.3. Formal Processing Flow of Self-Management and Error Sources
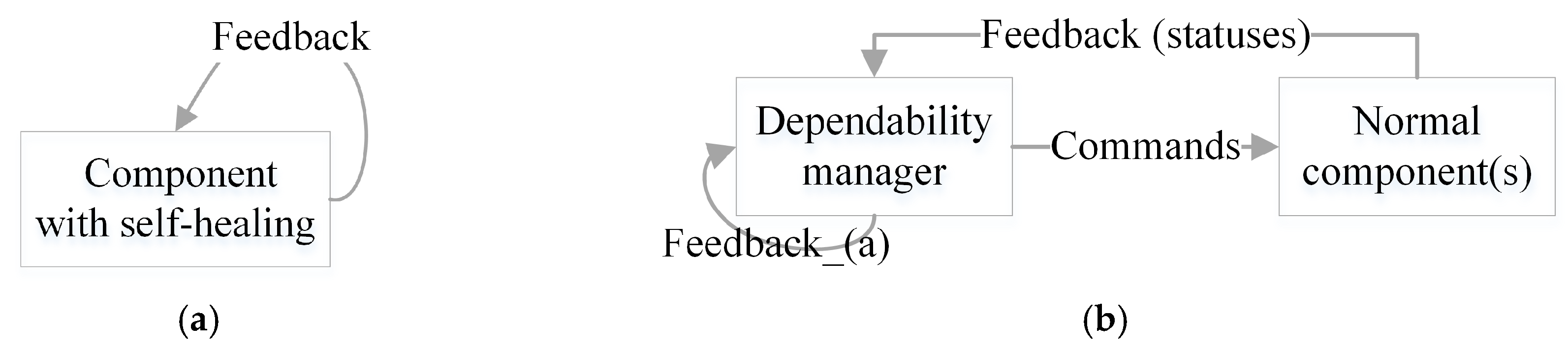
2.4. The Schemas of Feedback Loop for Self-Healing and Self-Reference Problem
2.5. The Challenges of Guarantee the Dependability of SCPS
2.5.1. The Legacy Issues
2.5.2. Technical Challenges of CPS Modeling and Dependability Analysis
2.5.3. Technical Challenges of Runtime Dependability Management of SCPS
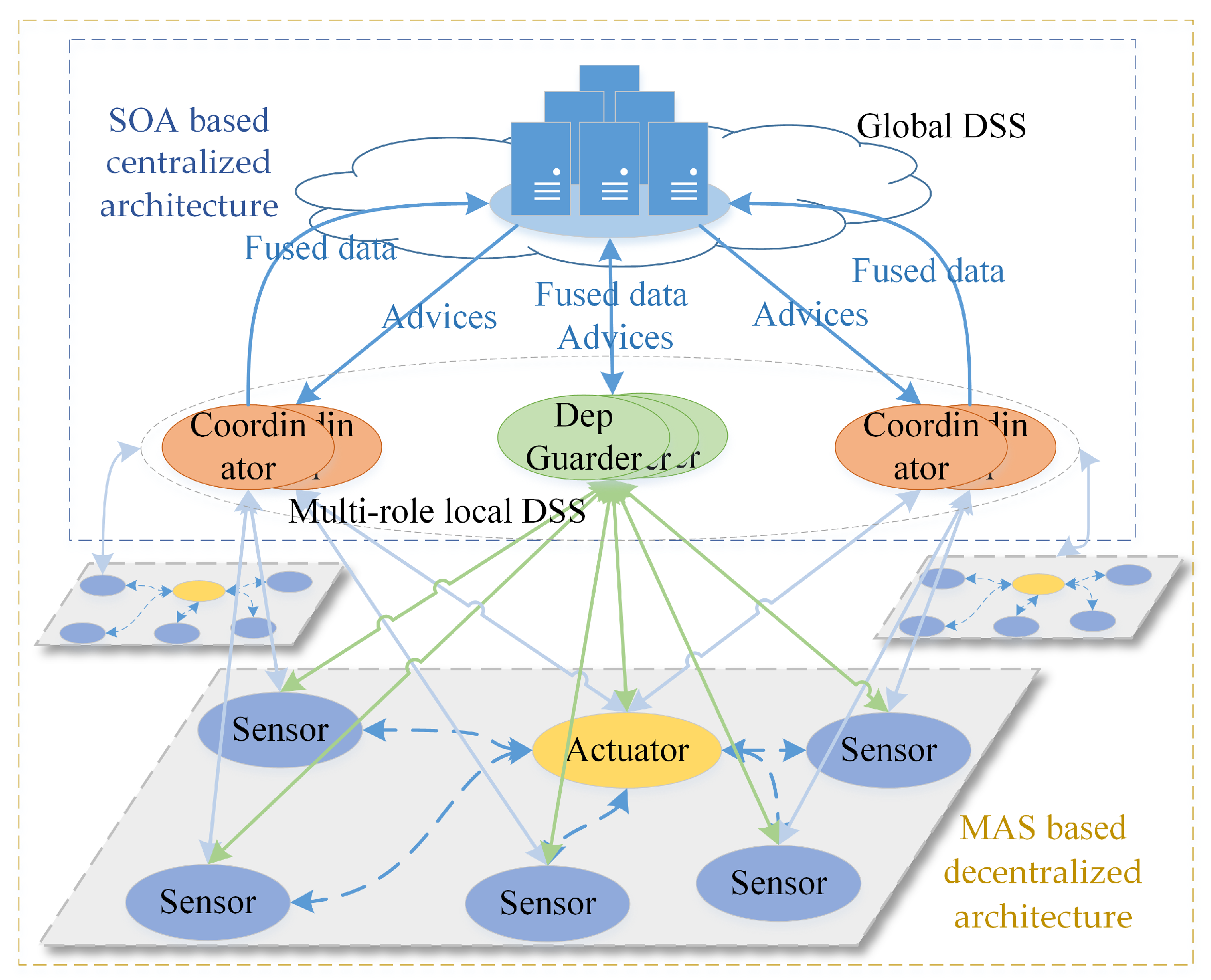
3. Dependable Self-Adaptive Architecture Design
3.1. State of the Art of CPS Architecture Design and the Key Technologies
3.2. The Methodologies to Design a Dependable SCPS
3.2.1. Reducing the Complexity (Benefit for MQ3, RQ1, RQ3, and RQ4)
3.2.2. Isolation and Migration at Task Set Level (for MQ2 and RQ4)
3.2.3. Enhancing the Dependability at Architecture Level (for RQ5 and RQ6)
3.2.4. Improving the Quality with Formal Model and Formal Analysis Methods (for MQ1 to MQ5, and RQ2 to RQ4)
3.3. Improve the Dependability of Self-Adaptive Architecture
3.3.1. Simplify Self-Management with Hybrid Self-Adaptive Architecture
3.3.2. Guarantee the Timing Dependability of Events for Reasoning (for RQ1)
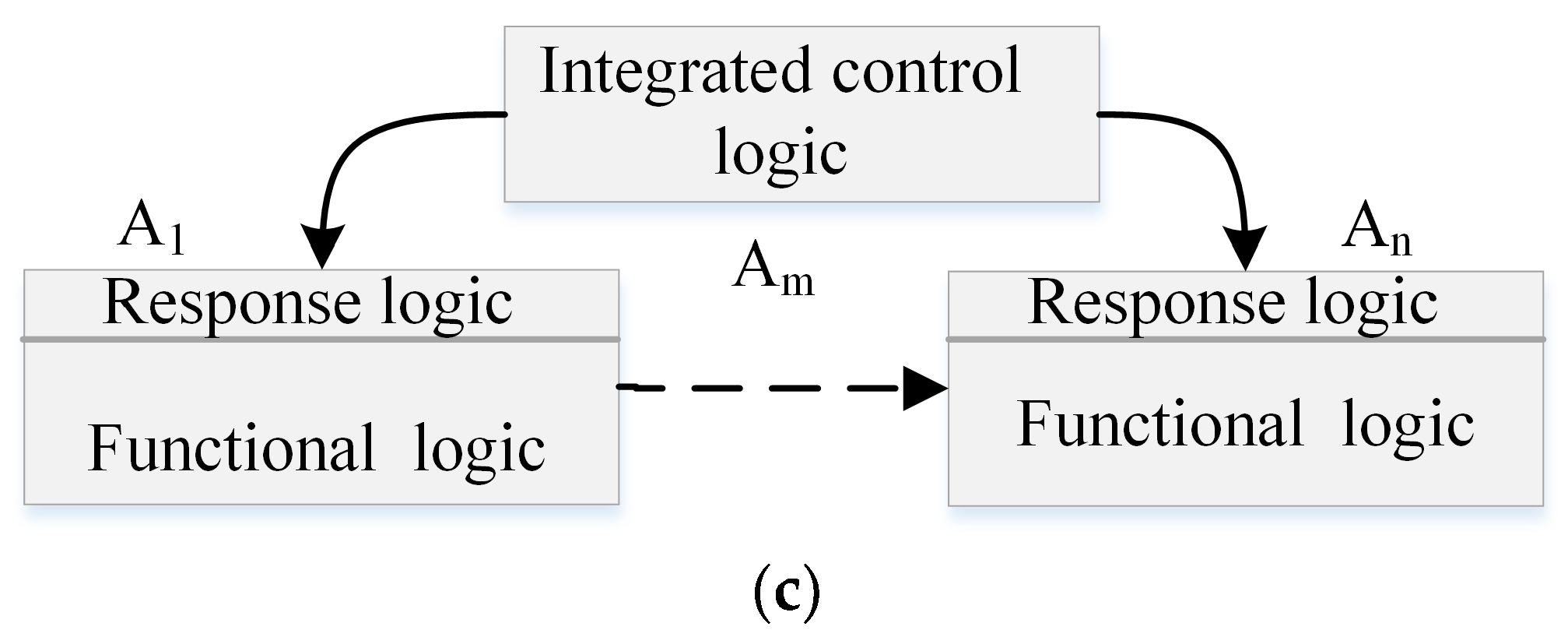
3.3.3. Improving Composability and Compositionality of Services (for RQ1 to RQ6 and MQ1 to MQ5)
3.3.4. Improve the Dependability with SDA (for MQ3 and Reducing Complexity)
3.4. Summary of the Dependable SCPS Architecture and Organization
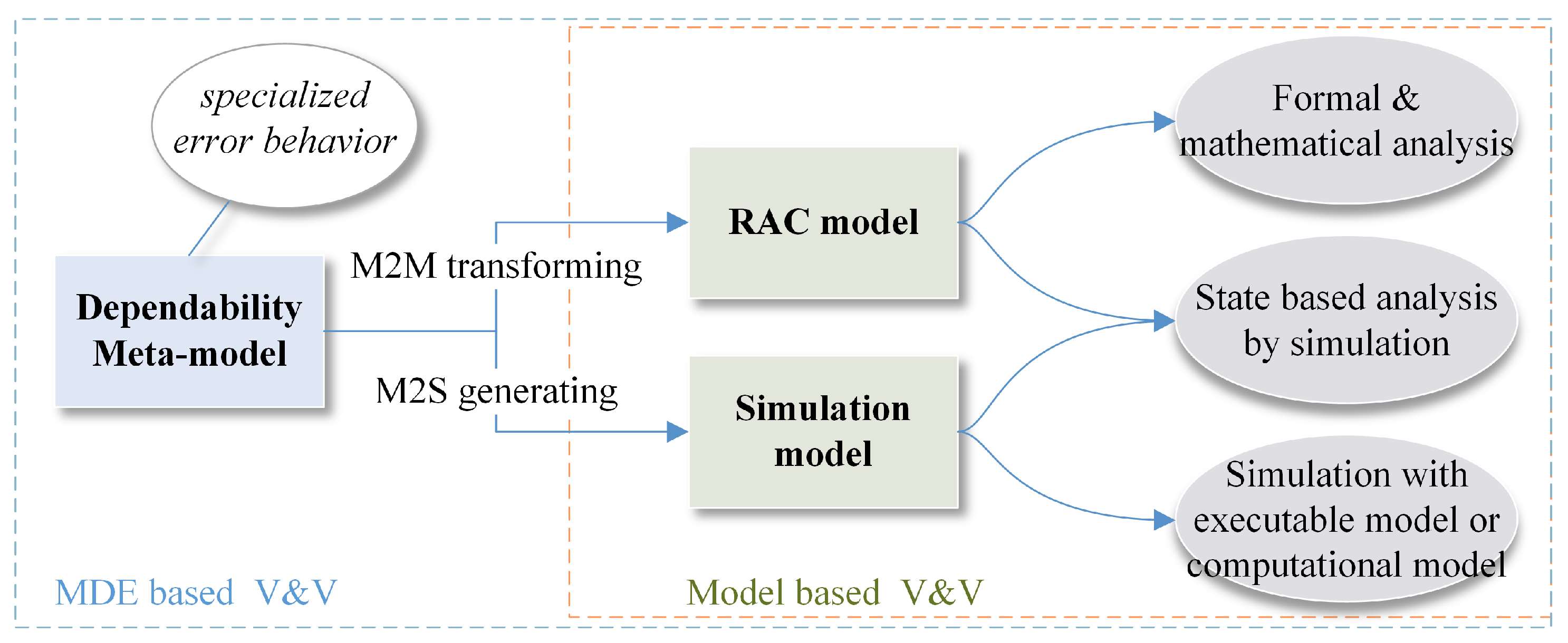
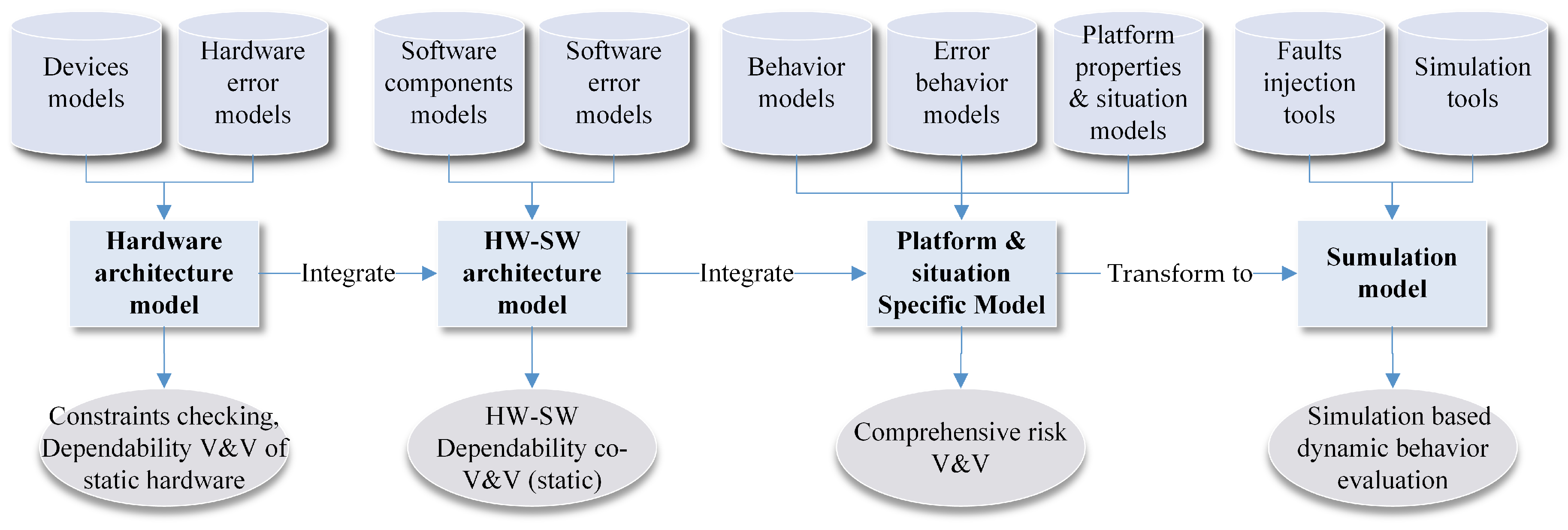
4. Guarantee the Dependability of the Design with Model Based V&V
4.1. Current Researches on Model Based Dependability V&V for SCPS
4.2. Improving the Trustability of the Dependability V&V Results with Cross Validation
4.3. The Challenges of Model Based Dependability V&V
4.4. Brief Summary and Discussions
5. The Safety of Self-Adaptation Strategies and the Dependability of Real-Time Decision Process
5.1. Brief Overview of the State of the Art Self-Adaptation for CPS
5.2. Improve the Fitness and Safety of the Prophetic Self-Adaptation Decisions and Strategies
5.2.1. Safety Aware Self-Adaptation Decision-Making
5.2.2. The Safety V&V Methods at Design Period and at Decision Making Period
5.2.3. Brief Summary and Discussion
5.3. Guarantee the Safety of Decision Processing with [email protected] Methods
5.4. Guaranteeing the Dependability of Real-Time Self-Adaptation (Decision Process)
5.4.1. Guarantee the Dependability of Self-Adaptation with Multi-Object Optimization Methods
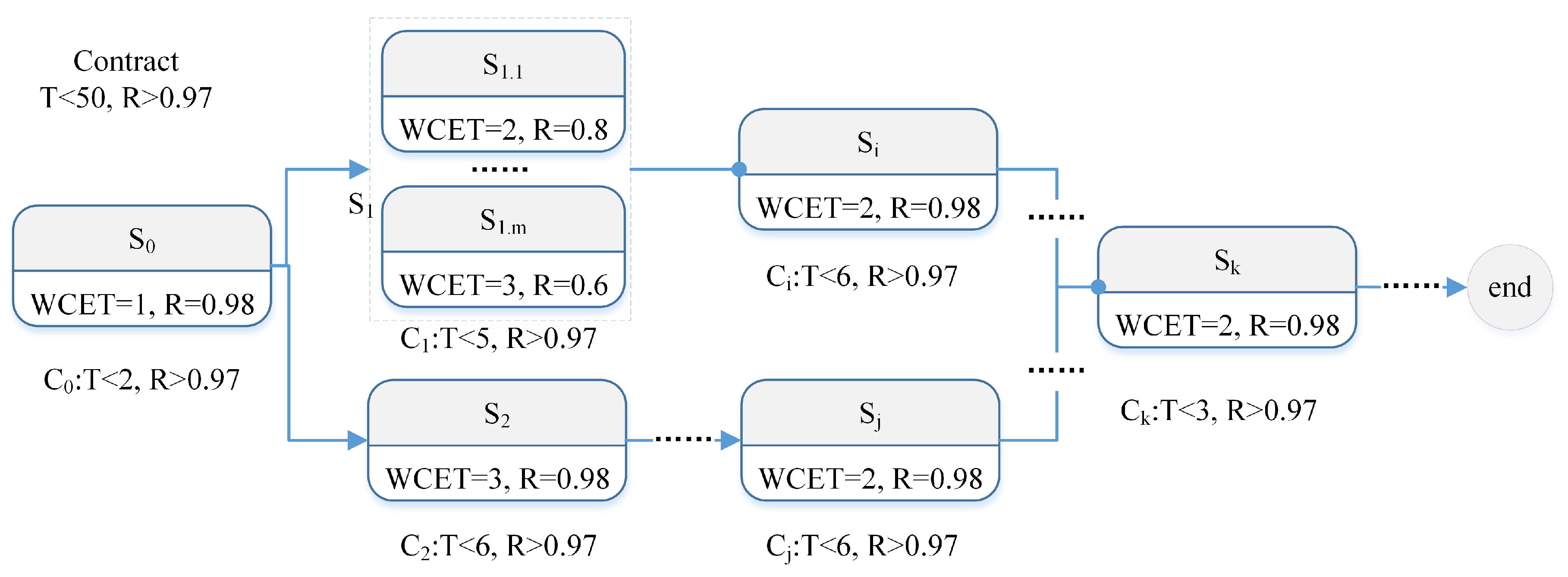
5.4.2. Guaranteeing the Dependability with Goal/Contract Based on Decomposable Self-Adaptation Decision (the [email protected] Approach)
5.5. Brief Summary and Discussions of Dependable Self-Adaptation
6. Self-Healing Solution for SCPS
6.1. Traditional Solutions to Improve the Dependability of Infrastructures
6.2. Modern Methods for Fault Tolerance
6.2.1. Data Driven Fault Detection/Diagnosis
6.2.2. Virtualization Based Fault Isolation
6.2.3. Modern Fault Recovery/Tolerance Solution
6.2.4. Brief Summary of Fault Tolerance Methods
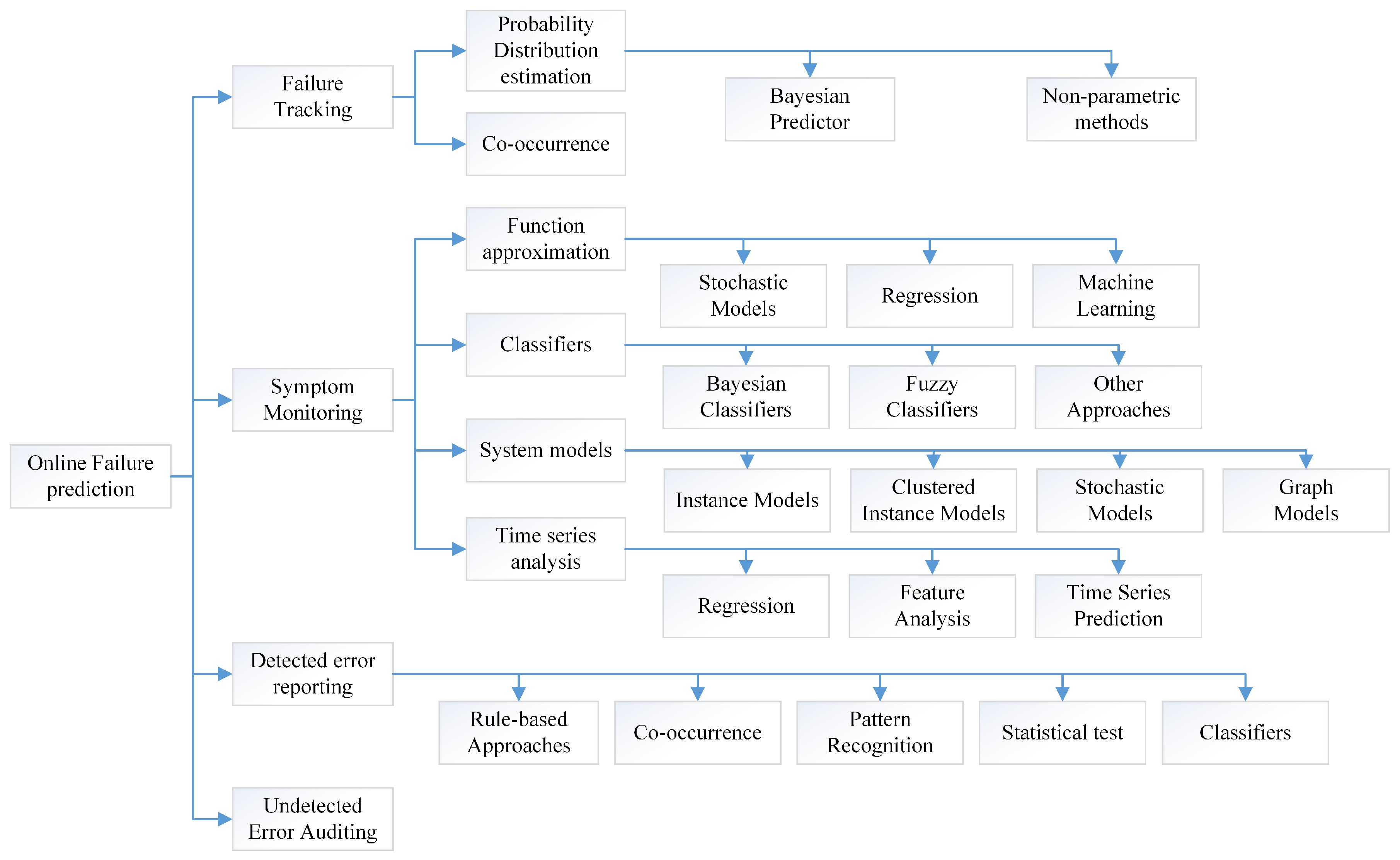
6.3. Modern Methods for Fault Prediction and Prevention
6.4. Simplify the Manual Maintenance
6.5. Brief Summary and Discussion
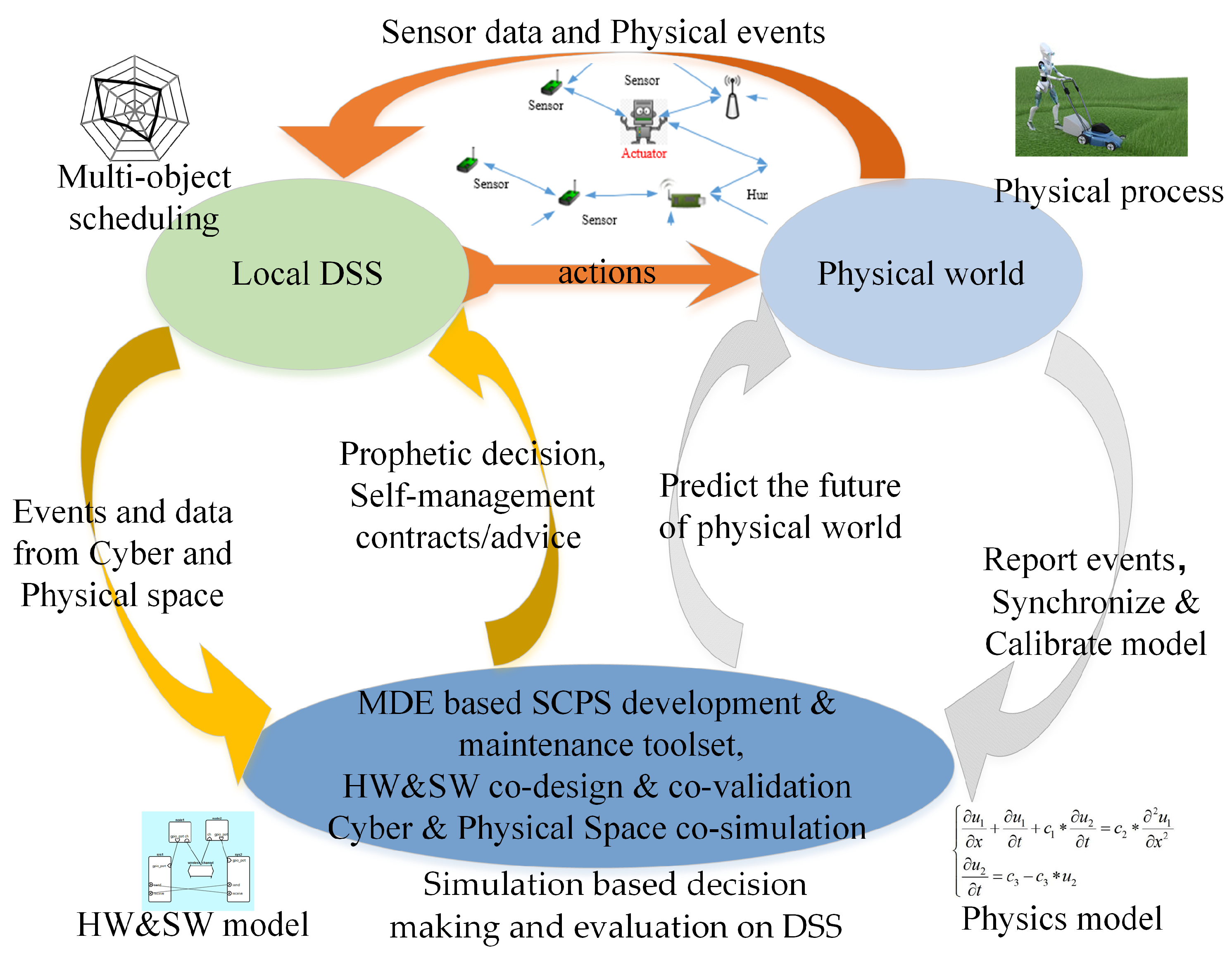
7. The Missing Pieces of the Technology Puzzle and the Future Directions of SCPS
7.1. The Available and Missing Measures
7.2. Technical Challenges and Directions
7.3. Future Direction: a Concept of All-in-One Solution
8. Discussions and Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
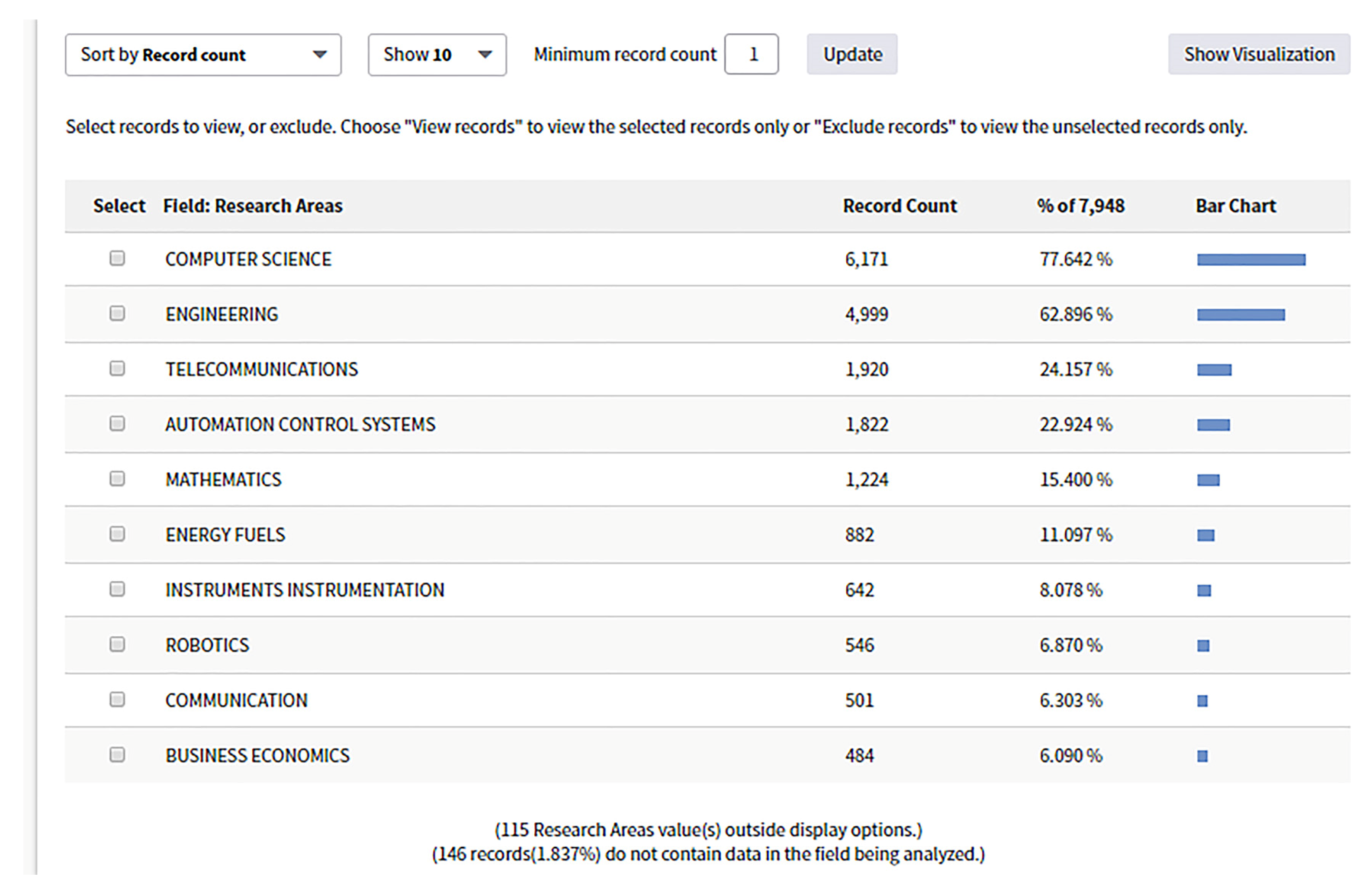
| Keywords | Web of Science | IEEE Xplore | ACM | ScienceDirect |
|---|---|---|---|---|
| CPS | 7948 (Topic) | 7902 (metadata only) | 9470 (full text) | 11,061 (all items) |
| 2207 (keyword) | 545 (keyword) | 1227 (keyword) | ||
| Dependability & CPS | 36 (Topic) | 99 (metadata only) | 5989 (full text) | 701 (all items) |
| 35 (keyword) | 32 (keyword) | 21 (keyword) | ||
| Reliability & CPS | 343 (Topic) | 854 (metadata only) | 914 (full text) | 3806 (all items) |
| 101 (keyword) | 89 (keyword) | 61 (keyword) | ||
| Availability & CPS | 109 (Topic) | 225 (metadata only) | 819 (full text) | 8981 (all items) |
| 79 (keyword) | 11 (keyword) | 114 (keyword) | ||
| Safety & CPS | 335 (Topic) | 827 (metadata only) | 699 (full text) | 4022 (all items) |
| 268 (keyword) | 157 (keyword) | 107 (keyword) | ||
| Real-time & Adaptation 1 | 242 (Topic) | 176 (metadata only) | 350 (full text) | 1745 (all items) |
| 3 (keyword) | 125 (keyword) | 27 (keyword) | ||
| Rt & adp* & dep* 2 | 14 (Topic) | 0 (metadata only) | 26 (full text) | 702 (all items) |
| 0 (keyword) | 0 (keyword) | 1 (keyword) | ||
| Rt &CPS & adp* & dep* 3 | 0 (Topic) | 0 | 25 (full text) | 48 (all items) |
| 0 | 0 | 0 |
References
- Mosterman, P.J.; Zander, J. Industry 4.0 as a cyber-physical system study. Softw. Syst. Model. 2016, 15, 17–29. [Google Scholar] [CrossRef]
- Derler, P.; Lee, E.A.; Vincentelli, A.S. Modeling cyber–physical systems. Proc. IEEE 2012, 100, 13–28. [Google Scholar] [CrossRef]
- Webinar, K. NIST Cyber-Physical Systems Public Working Group (CPS PWG). Available online: https://www.nist.gov/sites/default/files/documents/el/CPS-PWG-Kickoff-Webinar-Presentation-FINAL.PDF (accessed on 26 February 2019).
- Rajkumar, R.R.; Lee, I.; Sha, L.; Stankovic, J. Cyber-physical systems: The next computing revolution. In Proceedings of the 47th Design Automation Conference, Anaheim, CA, USA, 13–18 July 2010; pp. 731–736. [Google Scholar]
- Gunes, V.; Peter, S.; Givargis, T.; Vahid, F. A Survey on Concepts, Applications, and Challenges in Cyber-Physical Systems. KSII Trans. Internet Inf. Syst. 2014, 8, 4242–4268. [Google Scholar]
- Leitão, P.; Colombo, A.W.; Karnouskos, S. Industrial automation based on cyber-physical systems technologies: Prototype implementations and challenges. Comput. Ind. 2016, 81, 11–25. [Google Scholar] [CrossRef] [Green Version]
- De Brito, M.S.; Hoque, S.; Steinke, R.; Willner, A. Towards Programmable Fog Nodes in Smart Factories. In Proceedings of the 2016 IEEE 1st International Workshops on Foundations and Applications of Self* Systems (Fas*W), Augsburg, Germany, 12–16 September 2016; pp. 236–241. [Google Scholar]
- Wan, J.; Chen, M.; Xia, F.; Di, L.; Zhou, K. From machine-to-machine communications towards cyber-physical systems. Comput. Sci. Inf. Syst. 2013, 10, 1105–1128. [Google Scholar] [CrossRef]
- Ceccarelli, A.; Bondavalli, A.; Froemel, B.; Hoeftberger, O.; Kopetz, H. Basic Concepts on Systems of Systems. In Cyber-Physical Systems of Systems: Foundations—A Conceptual Model and Some Derivations: The AMADEOS Legacy; Bondavalli, A., Bouchenak, S., Kopetz, H., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 1–39. [Google Scholar]
- Lu, C.; Saifullah, A.; Li, B.; Sha, M.; Gonzalez, H.; Gunatilaka, D.; Wu, C.; Nie, L.; Chen, Y. Real-time wireless sensor-actuator networks for industrial cyber-physical systems. Proc. IEEE 2016, 104, 1013–1024. [Google Scholar] [CrossRef]
- Zhang, X.-M.; Han, Q.-L.; Yu, X. Survey on Recent Advances in Networked Control Systems. IEEE Trans. Ind. Inform. 2016, 12, 1740–1752. [Google Scholar] [CrossRef]
- Gubbi, J.; Buyya, R.; Marusic, S.; Palaniswami, M. Internet of Things (IoT): A vision, architectural elements, and future directions. Future Gener. Comput. Syst. 2013, 29, 1645–1660. [Google Scholar] [CrossRef] [Green Version]
- Giordano, A.; Spezzano, G.; Vinci, A. Smart Agents and Fog Computing for Smart City Applications. In International Conference on Smart Cities; Springer: Cham, Switzerland, 2016; pp. 137–146. [Google Scholar]
- Zhang, Y.; Qian, C.; Lv, J.; Liu, Y. Agent and cyber-physical system based self-organizing and self-adaptive intelligent shopfloor. IEEE Trans. Ind. Inform. 2016, 13, 737–747. [Google Scholar] [CrossRef]
- Eliasson, J.; Delsing, J.; Derhamy, H.; Salcic, Z.; Wang, K. Towards industrial Internet of Things: An efficient and interoperable communication framework. In Proceedings of the 2015 IEEE International Conference on Industrial Technology (ICIT), Seville, Spain, 17–19 March 2015; pp. 2198–2204. [Google Scholar]
- Agirre, A.; Parra, J.; Armentia, A.; Estévez, E.; Marcos, M. QoS Aware Middleware Support for Dynamically Reconfigurable Component Based IoT Applications. Int. J. Distrib. Sens. Netw. 2016. [Google Scholar] [CrossRef]
- Salehie, M.; Tahvildari, L. Self-Adaptive Software: Landscape and Research Challenges. ACM Trans. Auton. Adapt. Syst. 2009, 4, 14. [Google Scholar] [CrossRef]
- Kephart, J.O. Research challenges of autonomic computing. In Proceedings of the ICSE 05: 27th International Conference on Software Engineering, Proceedings, Saint Louis, MO, USA, 5 May 2005; pp. 15–22. [Google Scholar]
- Krupitzer, C.; Roth, F.M.; VanSyckel, S.; Schiele, G.; Becker, C. A survey on engineering approaches for self-adaptive systems. Pervasive Mob. Comput. 2015, 17, 184–206. [Google Scholar] [CrossRef]
- Alegre, U.; Augusto, J.C.; Clark, T. Engineering context-aware systems and applications: A survey. J. Syst. Softw. 2016, 117, 55–83. [Google Scholar] [CrossRef] [Green Version]
- Kang, H.S.; Lee, J.Y.; Choi, S.; Kim, H.; Park, J.H.; Son, J.Y.; Kim, B.H.; Do Noh, S. Smart manufacturing: Past research, present findings, and future directions. Int. J. Precis. Eng. Manuf. Green Technol. 2016, 3, 111–128. [Google Scholar] [CrossRef]
- Sanislav, T.; Miclea, L. Cyber-physical systems-concept, challenges and research areas. J. Control Eng. Appl. Inform. 2012, 14, 28–33. [Google Scholar]
- Broy, M.; Cengarle, M.V.; Geisberger, E. Cyber-physical systems: Imminent challenges. In Monterey Workshop; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1–28. [Google Scholar]
- Crnkovic, I.; Malavolta, I.; Muccini, H.; Sharaf, M. On the Use of Component-Based Principles and Practices for Architecting Cyber-Physical Systems. In Proceedings of the 2016 19th International ACM Sigsoft Symposium on Component-Based Software Engineering, Venice, Italy, 5–8 April 2016; pp. 23–32. [Google Scholar]
- Völp, M.; Asmussen, N.; Härtig, H.; Nöthen, B.; Fettweis, G. Towards dependable CPS infrastructures: Architectural and operating-system challenges. In Proceedings of the 2015 IEEE 20th Conference on Emerging Technologies & Factory Automation (ETFA), Luxembourg, 8–11 September 2015; pp. 1–8. [Google Scholar]
- Avižienis, A.; Laprie, J.-C.; Randell, B. Dependability and its threats: A taxonomy. In Building the Information Society; Springer: Berlin/Heidelberg, Germany, 2004; pp. 91–120. [Google Scholar]
- Warriach, E.U.; Ozcelebi, T.; Lukkien, J.J. Self-* Properties in Smart Environments: Requirements and Performance Metrics. In Proceedings of the Intelligent Environments (Workshops), Shanghai, China, 30 June–1 July 2014; pp. 194–205. [Google Scholar]
- Psaier, H.; Dustdar, S. A survey on self-healing systems: Approaches and systems. Computing 2011, 91, 43–73. [Google Scholar] [CrossRef]
- Sha, L. Using simplicity to control complexity. IEEE Softw. 2001, 4, 20–28. [Google Scholar]
- Benosman, M. A survey of some recent results on nonlinear fault tolerant control. Math. Probl. Eng. 2010, 2010, 586169. [Google Scholar] [CrossRef]
- Turing, A.M. On computable numbers, with an application to the Entscheidungsproblem. Proc. Lond. Math. Soc. 1937, 2, 230–265. [Google Scholar] [CrossRef]
- Ohmann, P.; Brown, D.B.; Neelakandan, N.; Linderoth, J.; Liblit, B. Optimizing Customized Program Coverage. In Proceedings of the 2016 31st Ieee/Acm International Conference on Automated Software Engineering, Singapore, 3–7 September 2016; pp. 27–38. [Google Scholar]
- Tsigkanos, C.; Kehrer, T.; Ghezzi, C. Architecting dynamic cyber-physical spaces. Computing 2016, 98, 1011–1040. [Google Scholar] [CrossRef]
- Broman, D.; Derler, P.; Eidson, J. Temporal issues in cyber-physical systems. J. Indian Inst. Sci. 2013, 93, 389–402. [Google Scholar]
- Novoa-Hernández, P.; Corona, C.C.; Pelta, D.A. Self-adaptation in dynamic environments-a survey and open issues. Int. J. Bio-Inspir. Comput. 2016, 8, 1–13. [Google Scholar] [CrossRef]
- Alho, P.; Mattila, J. Service-oriented approach to fault tolerance in CPSs. J. Syst. Softw. 2015, 105, 1–17. [Google Scholar] [CrossRef]
- Pfrommer, J.; Stogl, D.; Aleksandrov, K.; Navarro, S.E.; Hein, B.; Beyerer, J. Plug & produce by modelling skills and service-oriented orchestration of reconfigurable manufacturing systems. Automatisierungstechnik 2015, 63, 790–800. [Google Scholar]
- Dai, W.; Huang, W.; Vyatkin, V. Knowledge-Driven Service Orchestration Engine for Flexible Information Acquisition in Industrial Cyber-Physical Systems. In Proceedings of the 2016 IEEE 25th International Symposium on Industrial Electronics, Santa Clara, CA, USA, 8–10 June 2016; pp. 1055–1060. [Google Scholar]
- Leitao, P.; Karnouskos, S.; Ribeiro, L.; Lee, J.; Strasser, T.; Colombo, A.W. Smart Agents in Industrial Cyber–Physical Systems. Proc. IEEE 2016, 104, 1086–1101. [Google Scholar] [CrossRef]
- Lee, J.; Ardakani, H.D.; Yang, S.; Bagheri, B. Industrial big data analytics and cyber-physical systems for future maintenance & service innovation. Procedia Cirp 2015, 38, 3–7. [Google Scholar]
- Wang, L.; Haghighi, A. Combined strength of holons, agents and function blocks in cyber-physical systems. J. Manuf. Syst. 2016, 40, 25–34. [Google Scholar] [CrossRef]
- Pautasso, C.; Zimmermann, O.; Leymann, F. Restful web services vs. big’web services: Making the right architectural decision. In Proceedings of the 17th international conference on World Wide Web, Beijing, China, 21–25 April 2008; pp. 805–814. [Google Scholar]
- Qin, J.; Ma, Q.; Shi, Y.; Wang, L. Recent Advances in Consensus of Multi-Agent Systems: A Brief Survey. IEEE Trans. Ind. Electron. 2017, 64, 4972–4983. [Google Scholar] [CrossRef]
- Ye, L.; Qian, K.; Zhang, L. S-PDH: A CPS Service Contract Framework for Composition. In Service-Oriented Computing–ICSOC 2015 Workshops; Norta, A., Gaaloul, W., Gangadharan, G.R., Dam, H.K., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9586, pp. 79–90. [Google Scholar]
- Brizzi, P.; Conzon, D.; Khaleel, H.; Tomasi, R.; Pastrone, C.; Spirito, A.; Knechtel, M.; Pramudianto, F.; Cultrona, P. Bringing the Internet of Things along the manufacturing line: A case study in controlling industrial robot and monitoring energy consumption remotely. In Proceedings of the 2013 IEEE 18th Conference on Emerging Technologies & Factory Automation (ETFA), Cagliari, Italy, 10–13 September 2013; pp. 1–8. [Google Scholar]
- Wang, S.; Wan, J.; Zhang, D.; Li, D.; Zhang, C. Towards smart factory for Industry 4.0: A self-organized multi-agent system with big data based feedback and coordination. Comput. Netw. 2016, 101, 158–168. [Google Scholar] [CrossRef]
- Shu, Z.; Wan, J.; Zhang, D.; Li, D. Cloud-Integrated Cyber-Physical Systems for Complex Industrial Applications. Mob. Netw. Appl. 2016, 21, 865–878. [Google Scholar] [CrossRef]
- Perez, H.; Javier Gutierrez, J.; Peiro, S.; Crespo, A. Distributed architecture for developing mixed-criticality systems in multi-core platforms. J. Syst. Softw. 2017, 123, 145–159. [Google Scholar] [CrossRef]
- Jablkowski, B.; Gabor, U.T.; Spinczyk, O. Evolutionary planning of virtualized cyber-physical compute and control clusters. J. Syst. Archit. 2017, 73, 17–27. [Google Scholar] [CrossRef]
- Wan, J.; Tang, S.; Shu, Z.; Li, D.; Wang, S.; Imran, M.; Vasilakos, A.V. Software-Defined Industrial Internet of Things in the Context of Industry 4.0. IEEE Sens. J. 2016, 16, 7373–7380. [Google Scholar] [CrossRef]
- Bruton, K.; Walsh, B.P.; Cusack, D.O.; O’Donovan, P.; O’Sullivan, D.T.J. Enabling Effective Operational Decision Making on a Combined Heat and Power System using the 5C Architecture. Procedia CIRP 2016, 55, 296–301. [Google Scholar] [CrossRef]
- Camara, J.; Correia, P.; de Lemos, R.; Garlan, D.; Gomes, P.; Schmerl, B.; Ventura, R. Incorporating architecture-based self-adaptation into an adaptive industrial software system. J. Syst. Softw. 2016, 122, 507–523. [Google Scholar] [CrossRef] [Green Version]
- Cámara, J.; de Lemos, R.; Laranjeiro, N.; Ventura, R.; Vieira, M. Robustness evaluation of the rainbow framework for self-adaptation. In Proceedings of the 29th Annual ACM Symposium on Applied Computing, Gyeongju, Korea, 24–28 March 2014; pp. 376–383. [Google Scholar]
- Kit, M.; Gerostathopoulos, I.; Bures, T.; Hnetynka, P.; Plasil, F. An architecture framework for experimentations with self-adaptive cyber-physical systems. In Proceedings of the 2015 IEEE/ACM 10th International Symposium on Software Engineering for Adaptive and Self-Managing Systems, Florence, Italy, 18–19 May 2015; pp. 93–96. [Google Scholar]
- Bures, T.; Hnetynka, P.; Plasil, F. Strengthening architectures of smart CPS by modeling them as runtime product-lines. In Proceedings of the 17th International ACM Sigsoft Symposium on Component-Based Software Engineering, Bordeaux, France, 8–12 December 2014; pp. 91–96. [Google Scholar]
- Masrur, A.; Kit, M.; Matěna, V.; Bureš, T.; Hardt, W. Component-based design of cyber-physical applications with safety-critical requirements. Microprocess. Microsyst. 2016, 42, 70–86. [Google Scholar] [CrossRef]
- Gerostathopoulos, I.; Bures, T.; Hnetynka, P.; Keznikl, J.; Kit, M.; Plasil, F.; Plouzeau, N. Self-adaptation in software-intensive cyber-physical systems: From system goals to architecture configurations. J. Syst. Softw. 2016, 122, 378–397. [Google Scholar] [CrossRef]
- Iarovyi, S.; Mohammed, W.M.; Lobov, A.; Ferrer, B.R.; Lastra, J.L.M. Cyber-Physical Systems for Open-Knowledge-Driven Manufacturing Execution Systems. Proc. IEEE 2016, 104, 1142–1154. [Google Scholar] [CrossRef]
- Park, J.; Lee, S.; Yoon, T.; Kim, J.M. An autonomic control system for high-reliable CPS. Clust. Comput. 2015, 18, 587–598. [Google Scholar] [CrossRef]
- Axelsson, J.; Kobetski, A. Architectural Concepts for Federated Embedded Systems. In Proceedings of the 2014 European Conference on Software Architecture Workshops, Vienna, Austria, 25–29 August 2014; p. 25. [Google Scholar]
- Gang, L.; GuPing, Z. Self-Reconfiguration Architecture for Distribution Automation System Based on Cyber-Physical. In Proceedings of the 2012 Asia-Pacific Power and Energy Engineering Conference (APPEEC), Shanghai, China, 27–29 March 2012; pp. 1–4. [Google Scholar]
- Pajic, M.; Chernoguzov, A.; Mangharam, R. Robust Architectures for Embedded Wireless Network Control and Actuation. ACM Trans. Embed. Comput. Syst. 2012, 11, 82. [Google Scholar] [CrossRef]
- Lee, E.A.; Seshia, S.A. Introduction to Embedded Systems: A Cyber-Physical Systems Approach; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Qadir, J.; Ahmed, N.; Ahad, N. Building programmable wireless networks: An architectural survey. Eurasip J. Wirel. Commun. Netw. 2014, 2014, 172. [Google Scholar] [CrossRef]
- Saha, I.; Roy, S.; Ramesh, S. Formal Verification of Fault-Tolerant Startup Algorithms for Time-Triggered Architectures: A Survey. Proc. IEEE 2016, 104, 904–922. [Google Scholar] [CrossRef]
- Kharchenko, V. Diversity for safety and security of embedded and cyber physical systems: Fundamentals review and industrial cases. In Proceedings of the 2016 15th Biennial Baltic Electronics Conference (BEC), Tallinn, Estonia, 3–5 October 2016; pp. 17–26. [Google Scholar]
- Sterbenz, J.P.G.; Hutchison, D.; Cetinkaya, E.K.; Jabbar, A.; Rohrer, J.P.; Schoeller, M.; Smith, P. Redundancy, diversity, and connectivity to achieve multilevel network resilience, survivability, and disruption tolerance invited paper. Telecommun. Syst. 2014, 56, 17–31. [Google Scholar] [CrossRef]
- Rodriguez, M.; Kwiat, K.A.; Kamhoua, C.A. On the use of design diversity in fault tolerant and secure systems: A qualitative analysis. In Proceedings of the 2015 IEEE Symposium on Computational Intelligence for Security and Defense Applications (CISDA), Verona, NY, USA, 26–28 May 2015; pp. 1–8. [Google Scholar]
- Rodriguez, M.; Kwiat, K.A.; Kamhoua, C.A. Modeling fault tolerant architectures with design diversity for secure systems. In Proceedings of the Military Communications Conference, MILCOM 2015, Tampa, FL, USA, 26–28 October 2015; pp. 1254–1263. [Google Scholar]
- Lien, S.-Y. Resource-optimal heterogeneous machine-to-machine communications in software defined networking cyber-physical systems. Wirel. Pers. Commun. 2015, 84, 2215–2239. [Google Scholar] [CrossRef]
- Iftikhar, M.U.; Weyns, D. Activforms: Active formal models for self-adaptation. In Proceedings of the 9th International Symposium on Software Engineering for Adaptive and Self-Managing Systems, Hyderabad, India, 2–3 June 2014; pp. 125–134. [Google Scholar]
- Uddin, I.; Rakib, A.; Ul Haque, H.M. A Framework for Implementing Formally Verified Resource-Bounded Smart Space Systems. Mob. Netw. Appl. 2017, 22, 289–304. [Google Scholar] [CrossRef] [Green Version]
- Zhou, P.; Zuo, D.; Hou, K.-M.; Zhang, Z. A Decentralized Compositional Framework for Dependable Decision Process in Self-Managed Cyber Physical Systems. Sensors 2017, 17, 2580. [Google Scholar] [CrossRef] [PubMed]
- Musil, A.; Musil, J.; Weyns, D.; Bures, T.; Muccini, H.; Sharaf, M. Patterns for Self-Adaptation in Cyber-Physical Systems. In Multi-Disciplinary Engineering for Cyber-Physical Production Systems; Springer: Cham, Switzerland, 2017; pp. 331–368. [Google Scholar]
- Conti, S.; La Corte, A.; Nicolosi, R.; Rizzo, S. Impact of cyber-physical system vulnerability, telecontrol system availability and islanding on distribution network reliability. Sustain. Energy Grids Netw. 2016, 6, 143–151. [Google Scholar] [CrossRef]
- Broman, D.; Zimmer, M.; Kim, Y.; Kim, H.; Cai, J.; Shrivastava, A.; Edwards, S.A.; Lee, E.A. Precision timed infrastructure: Design challenges. In Proceedings of the Electronic System Level Synthesis Conference (ESLsyn), Austin, TX, USA, 31 May–1 June 2013; pp. 1–6. [Google Scholar]
- Lee, E.A. Computing needs time. Commun. ACM 2009, 52, 70–79. [Google Scholar] [CrossRef]
- Patel, H.D.; Lickly, B.; Burgers, B.; Lee, E.A. A Timing Requirements-Aware Scratchpad Memory Allocation Scheme for a Precision Timed Architecture; DTIC Document; DTIC: Lincoln, NE, USA, 2008.
- Zou, J.; Matic, S.; Lee, E.A. PtidyOS: A lightweight microkernel for Ptides real-time systems. In Proceedings of the 2012 IEEE 18th Real-Time and Embedded Technology and Applications Symposium (RTAS), Beijing, China, 16–19 April 2012; pp. 209–218. [Google Scholar]
- Lickly, B.; Liu, I.; Kim, S.; Patel, H.D.; Edwards, S.A.; Lee, E.A. Predictable programming on a precision timed architecture. In Proceedings of the 2008 International Conference on Compilers, Architectures and Synthesis for Embedded Systems, Atlanta, GA, USA, 23–24 October 2008; pp. 137–146. [Google Scholar]
- Bui, D.; Lee, E.; Liu, I.; Patel, H.; Reineke, J. Temporal isolation on multiprocessing architectures. In Proceedings of the 48th Design Automation Conference, San Diego, CA, USA, 5–9 June 2011; pp. 274–279. [Google Scholar]
- Dierikx, E.F.; Wallin, A.E.; Fordell, T.; Myyry, J.; Koponen, P.; Merimaa, M.; Pinkert, T.J.; Koelemeij, J.C.; Peek, H.Z.; Smets, R. White Rabbit Precision Time Protocol on Long-Distance Fiber Links. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2016, 63, 945–952. [Google Scholar] [CrossRef] [PubMed]
- Elattar, M.; Dürkop, L.; Jasperneite, J. Utilizing LTE QoS features to provide a reliable access network for cyber-physical systems. In Proceedings of the 2015 IEEE 13th International Conference on Industrial Informatics (INDIN), Cambridge, UK, 22–24 July 2015; pp. 956–961. [Google Scholar]
- Aristova, N.I. Ethernet in industrial automation: Overcoming obstacles. Autom. Remote Control 2016, 77, 881–894. [Google Scholar] [CrossRef]
- Watteyne, T.; Handziski, V.; Vilajosana, X.; Duquennoy, S.; Hahm, O.; Baccelli, E.; Wolisz, A. Industrial wireless ip-based cyber–physical systems. Proc. IEEE 2016, 104, 1025–1038. [Google Scholar] [CrossRef]
- Eidson, J.; Lee, E.A.; Matic, S.; Seshia, S.A.; Zou, J. A time-centric model for cyber-physical applications. In Proceedings of the Workshop on Model Based Architecting and Construction of Embedded Systems (ACES-MB), Aachen, Germany, 2–8 October 2010; pp. 21–35. [Google Scholar]
- Abella, J.; Hernandez, C.; Quiñones, E.; Cazorla, F.J.; Conmy, P.R.; Azkarate-askasua, M.; Perez, J.; Mezzetti, E.; Vardanega, T. WCET analysis methods: Pitfalls and challenges on their trustworthiness. In Proceedings of the 10th IEEE International Symposium on Industrial Embedded Systems (SIES), Siegen, Germany, 8–10 June 2015; pp. 1–10. [Google Scholar]
- Wilhelm, R.; Engblom, J.; Ermedahl, A.; Holsti, N.; Thesing, S.; Whalley, D.; Bernat, G.; Ferdinand, C.; Heckmann, R.; Mitra, T. The worst-case execution-time problem—overview of methods and survey of tools. ACM Trans. Embed. Comput. Syst. 2008, 7, 36. [Google Scholar] [CrossRef]
- Krishna, C. Fault-tolerant scheduling in homogeneous real-time systems. ACM Comput. Surv. 2014, 46, 48. [Google Scholar] [CrossRef]
- Nelaturi, S.; de Kleer, J.; Shapiro, V. Combinatorial Models for Heterogeneous System Composition and Analysis. In Proceedings of the 2016 11th System of Systems Engineering Conference (SoSE) 2016, Kongsberg, Norway, 12–16 June 2016. [Google Scholar]
- Gössler, G.; Sifakis, J. Composition for component-based modeling. Sci. Comput. Program. 2005, 55, 161–183. [Google Scholar] [CrossRef] [Green Version]
- Sztipanovits, J.; Koutsoukos, X.; Karsai, G.; Kottenstette, N.; Antsaklis, P.; Gupta, V.; Goodwine, B.; Baras, J.; Wang, S. Toward a science of cyber–physical system integration. Proc. IEEE 2011, 100, 29–44. [Google Scholar] [CrossRef]
- Nuzzo, P.; Sangiovanni-Vincentelli, A.L.; Bresolin, D.; Geretti, L.; Villa, T. A platform-based design methodology with contracts and related tools for the design of cyber-physical systems. Proc. IEEE 2015, 103, 2104–2132. [Google Scholar] [CrossRef]
- Attie, P.; Baranov, E.; Bliudze, S.; Jaber, M.; Sifakis, J. A general framework for architecture composability. Form. Asp. Comput. 2016, 28, 207–231. [Google Scholar] [CrossRef]
- Seshia, S.A. Combining induction, deduction, and structure for verification and synthesis. Proc. IEEE 2015, 103, 2036–2051. [Google Scholar] [CrossRef]
- Tripakis, S. Compositionality in the science of system design. Proc. IEEE 2016, 104, 960–972. [Google Scholar] [CrossRef]
- Chen, T.; Chilton, C.; Jonsson, B.; Kwiatkowska, M. A compositional specification theory for component behaviours. In European Symposium on Programming; Springer: Berlin/Heidelberg, Germany, 2012; pp. 148–168. [Google Scholar]
- Le, T.T.H.; Passerone, R.; Fahrenberg, U.; Legay, A. Contract-Based Requirement Modularization via Synthesis of Correct Decompositions. ACM Trans. Embed. Comput. Syst. 2016, 15. [Google Scholar] [CrossRef]
- Laird, L.M.; Brennan, M.C. Software Measurement and Estimation: A Practical Approach; John Wiley & Sons: New York, NY, USA, 2006; Volume 2. [Google Scholar]
- Henry, S.; Kafura, D. Software structure metrics based on information flow. IEEE Trans. Softw. Eng. 1981, SE-7, 510–518. [Google Scholar] [CrossRef]
- Halstead, M.H. Elements of Software Science (Operating and Programming Systems Series); Elsevier Science Inc.: New York, NY, USA, 1977. [Google Scholar]
- Isermann, R. Fault-Diagnosis Systems: An Introduction from Fault Detection to Fault Tolerance; Springer Science & Business Media: New York, NY, USA, 2006. [Google Scholar]
- Stapelberg, R.F. Handbook of Reliability, Availability, Maintainability and Safety in Engineering Design; Springer Science & Business Media: New York, NY, USA, 2009. [Google Scholar]
- Birolini, A. Reliability Engineering: Theory and Practice, 7th ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Hasan, O.; Ahmed, W.; Tahar, S.; Hamdi, M.S.; Simos, T.E.; Tsitouras, C. Reliability block diagrams based analysis: A survey. In AIP Conference Proceedings; AIP Publishing: New York, NY, USA, 2015; p. 850129. [Google Scholar]
- Ruijters, E.; Stoelinga, M. Fault tree analysis: A survey of the state-of-the-art in modeling, analysis and tools. Comput. Sci. Rev. 2015, 15–16, 29–62. [Google Scholar] [CrossRef]
- Kabir, S. An overview of fault tree analysis and its application in model based dependability analysis. Expert Syst. Appl. 2017, 77, 114–135. [Google Scholar] [CrossRef]
- Höfig, K.; Domis, D. Failure-dependent execution time analysis. In Proceedings of the Joint ACM SIGSOFT Conference–QoSA and ACM SIGSOFT Symposium–ISARCS on Quality of Software Architectures–QoSA and Architecting Critical Systems–ISARCS, Boulder, CO, USA, 20–24 June 2011; pp. 115–122. [Google Scholar]
- Ahmed, W.; Hasan, O.; Tahar, S. Formal dependability modeling and analysis: A survey. In International Conference on Intelligent Computer Mathematics; Springer: Berlin, Germny, 2016; pp. 132–147. [Google Scholar]
- Ma, Z.; Fu, X.; Yu, Z. Object-oriented petri nets based formal modeling for high-confidence cyber-physical systems. In Proceedings of the 2012 8th International Conference on Wireless Communications, Networking and Mobile Computing (WiCOM), Shanghai, China, 21–23 September 2012; pp. 1–4. [Google Scholar]
- Bryant, B.R.; Gray, J.; Mernik, M.; Clarke, P.J.; France, R.B.; Karsai, G. Challenges and Directions in Formalizing the Semantics of Modeling Languages. Comput. Sci. Inf. Syst. 2011, 8, 225–253. [Google Scholar] [CrossRef]
- Abbas, A.M.; Tsang, E.P.; Nasri, A.H. Depict: A high-level formal language for modeling constraint satisfaction problems. Int. J. Autom. Comput. 2008, 5, 208–216. [Google Scholar] [CrossRef]
- Feiler, P.H.; Lewis, B.A.; Vestal, S. The SAE Architecture Analysis & Design Language (AADL) a standard for engineering performance critical systems. In Proceedings of the 2006 IEEE Conference on Computer Aided Control System Design, 2006 IEEE International Conference on Control Applications, 2006 IEEE International Symposium on Intelligent Control, Munich, Germany, 4–6 October 2006; pp. 1206–1211. [Google Scholar]
- Aissa, A.B.; Abercrombie, R.K.; Sheldon, F.T.; Mili, A. Quantifying the impact of unavailability in cyber-physical environments. In Proceedings of the Computational Intelligence in Cyber Security (CICS), 2014 IEEE Symposium on, Orlando, FL, USA, 9–12 December 2014; pp. 1–8. [Google Scholar]
- Kozat, U.C.; Liang, G.; Kokten, K.; Tapolcai, J. On Optimal Topology Verification and Failure Localization for Software Defined Networks. IEEE-ACM Trans. Netw. 2016, 24, 2931–2944. [Google Scholar] [CrossRef]
- Rungger, M.; Tabuada, P. A symbolic approach to the design of robust cyber-physical systems. In Proceedings of the 2013 IEEE 52nd Annual Conference on Decision and Control (CDC), Firenze, Italy, 10–13 December 2013; pp. 3932–3937. [Google Scholar]
- Takai, S.; Kumar, R. Verification of generalized inference diagnosability for decentralized diagnosis in discrete event systems. In Proceedings of the 2015 IEEE 20th Conference on Emerging Technologies & Factory Automation (ETFA), Luxembourg, 8–11 September 2015; pp. 1–8. [Google Scholar]
- Ganin, A.A.; Massaro, E.; Gutfraind, A.; Steen, N.; Keisler, J.M.; Kott, A.; Mangoubi, R.; Linkov, I. Operational resilience: Concepts, design and analysis. Sci. Rep. 2016, 6, 19540. [Google Scholar] [CrossRef] [PubMed]
- Laibinis, L.; Klionskiy, D.; Troubitsyna, E.; Dorokhov, A.; Lilius, J.; Kupriyanov, M. Modelling Resilience of Data Processing Capabilities of CPS. In Software Engineering for Resilient Systems; Majzik, I., Vieira, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8785, pp. 55–70. [Google Scholar]
- Mashkoor, A.; Hasan, O. Formal probabilistic analysis of cyber-physical transportation systems. In Proceedings of the International Conference on Computational Science and Its Applications, Bahia, Brazil, 18–21 June 2012; pp. 419–434. [Google Scholar]
- Marashi, K.; Sarvestani, S.S. Towards comprehensive modeling of reliability for smart grids: Requirements and challenges. In Proceedings of the 2014 IEEE 15th International Symposium on High-Assurance Systems Engineering (HASE), Miami Beach, FL, USA, 9–11 January 2014; pp. 105–112. [Google Scholar]
- Han, Y.; Wen, Y.; Guo, C.; Huang, H. Incorporating Cyber Layer Failures in Composite Power System Reliability Evaluations. Energies 2015, 8, 9064–9086. [Google Scholar] [CrossRef] [Green Version]
- Hu, X.; Liu, S.; Chen, G.; Jiang, C. Dependability Modelling and Evaluation of Cyber-Physical Systems: A Model-Driven Perspective. In Proceedings of the 1st International Workshop on Cloud Computing and Information Security, Shanghai, China, 9 November–11 November 2013; Atlantis Press: Paris, France, 2013. [Google Scholar] [Green Version]
- Di Giandomenico, F.; Kwiatkowska, M.; Martinucci, M.; Masci, P.; Qu, H. Dependability Analysis and Verification for CONNECTed Systems. In Leveraging Applications of Formal Methods, Verification, and Validation; Margaria, T., Steffen, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6416, pp. 263–277. [Google Scholar]
- Sanislav, T.; Mois, G.; Miclea, L. An approach to model dependability of cyber-physical systems. Microprocess. Microsyst. 2016, 41, 67–76. [Google Scholar] [CrossRef]
- Bozzano, M.; Cimatti, A.; Katoen, J.-P.; Nguyen, V.Y.; Noll, T.; Roveri, M. Safety, dependability and performance analysis of extended AADL models. Comput. J. 2011, 54, 754–775. [Google Scholar] [CrossRef]
- Esteve, M.-A.; Katoen, J.-P.; Viet Yen, N.; Postma, B.; Yushtein, Y. Formal Correctness, Safety, Dependability, and Performance Analysis of a Satellite. In Proceedings of the 2012 34th International Conference on Software Engineering (ICSE), Zurich, Switzerland, 2–9 June 2012; pp. 1022–1031. [Google Scholar]
- Dal Lago, L.; Ferrante, O.; Passerone, R.; Ferrari, A. Dependability Assessment of SOA-based CPS with Contracts and Model-Based Fault Injection. IEEE Trans. Ind. Inform. 2018, 14, 360–369. [Google Scholar] [CrossRef]
- Ghezzi, C. Dependability of Adaptable and Evolvable Distributed Systems. In Formal Methods for the Quantitative Evaluation of Collective Adaptive Systems; Springer: Berlin, Germany, 2016; pp. 36–60. [Google Scholar]
- Tundis, A.; Buffoni, L.; Fritzson, P.; Garro, A. Model-Based Dependability Analysis of Physical Systems with Modelica. Model. Simul. Eng. 2017, 2017, 1578043. [Google Scholar] [CrossRef]
- Provan, G. A Contracts-Based Framework for Systems Modeling and Embedded Diagnostics. In Software Engineering and Formal Methods, Sefm 2014; Canal, C., Idani, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; Volume 8938, pp. 131–143. [Google Scholar]
- Hu, F.; Lu, Y.; Vasilakos, A.V.; Hao, Q.; Ma, R.; Patil, Y.; Zhang, T.; Lu, J.; Li, X.; Xiong, N.N. Robust cyber–physical systems: Concept, models, and implementation. Future Gener. Comput. Syst. 2016, 56, 449–475. [Google Scholar] [CrossRef]
- Silva, L.C.; Almeida, H.O.; Perkusich, A.; Perkusich, M. A Model-Based Approach to Support Validation of Medical Cyber-Physical Systems. Sensors 2015, 15, 27625–27670. [Google Scholar] [CrossRef] [PubMed]
- Sanislav, T.; Mois, G. A dependability analysis model in the context of cyber-physical systems. In Proceedings of the 2017 18th International Carpathian Control Conference (ICCC), Sinaia, Romania, 28–31 May 2017; pp. 146–150. [Google Scholar]
- Tundis, A.; Ferretto, D.; Garro, A.; Brusa, E.; Mühlhäuser, M. Dependability assessment of a deicing system through the RAMSAS method. In Proceedings of the 2017 IEEE International Systems Engineering Symposium (ISSE), Vienna, Austria, 11–13 October 2017; pp. 1–8. [Google Scholar]
- Jiang, Y.; Song, H.; Yang, Y.; Liu, H.; Gu, M.; Guan, Y.; Sun, J.; Sha, L. Dependable Model-driven Development of CPS: From Stateflow Simulation to Verified Implementation. ACM Trans. Cyber-Phys. Syst. 2018, 3, 1–31. [Google Scholar] [CrossRef]
- Tsigkanos, C.; Kehrer, T.; Ghezzi, C. Modeling and verification of evolving cyber-physical spaces. In Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering, Paderborn, Germany, 4–8 September 2017; pp. 38–48. [Google Scholar]
- Fritzson, P. Model-based development of sustainable cyber-physical systems including requirement formalization using the openModelica model-based development toolkit. In Proceedings of the 10th European Conference on Software Architecture Workshops, Copenhagen, Denmark, 28 November–2 December 2016; p. 1. [Google Scholar]
- Hachicha, M.; Dammak, E.; Halima, R.B.; Kacem, A.H. A correct by construction approach for modeling and formalizing self-adaptive systems. In Proceedings of the 2016 17th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Shanghai, China, 30 May–1 June 2016; pp. 379–384. [Google Scholar]
- Arcaini, P.; Riccobene, E.; Scandurra, P. Modeling and validating self-adaptive service-oriented applications. ACM SIGAPP Appl. Comput. Rev. 2015, 15, 35–48. [Google Scholar] [CrossRef]
- Brito, A.V.; Negreiros, A.V.; Roth, C.; Sander, O.; Becker, J. Development and Evaluation of Distributed Simulation of Embedded Systems using Ptolemy and HLA. In Proceedings of the 17th IEEE/ACM International Symposium on Distributed Simulation and Real Time Applications, Delft, The Netherlands, 30 October–1 November 2013; pp. 189–196. [Google Scholar]
- Conzon, D.; Brizzi, P.; Kasinathan, P.; Pastrone, C.; Pramudianto, F.; Cultrona, P. Industrial application development exploiting IoT Vision and Model Driven programming. In Proceedings of the 2015 8th International Conference on Intelligence in Next Generation Networks, Paris, France, 17–19 February 2015; pp. 168–175. [Google Scholar]
- Whittle, J.; Hutchinson, J.; Rouncefield, M. The state of practice in model-driven engineering. Softw. IEEE 2014, 31, 79–85. [Google Scholar] [CrossRef]
- Kroiss, C.; Bures, T. Logic-based modeling of information transfer in cyber-physical multi-agent systems. Future Gener. Comput. Syst. 2016, 56, 124–139. [Google Scholar] [CrossRef]
- Xi, Z. Physically Informed Assertions for Cyber Physical Systems Development and Debugging. In Proceedings of the 2014 IEEE International Conference on Pervasive Computing and Communication Workshops (PERCOM WORKSHOPS), Budapest, Hungary, 24–28 March 2014; pp. 181–183. [Google Scholar]
- Anier, A.; Vain, J.; Tsiopoulos, L. DTRON: A tool for distributed model-based testing of time critical applications. Proc. Est. Acad. Sci. 2017, 66, 75–88. [Google Scholar] [CrossRef]
- Hou, Y.; Zhao, Y.; Wagh, A.; Zhang, L.; Qiao, C.; Hulme, K.F.; Wu, C.; Sadek, A.W.; Liu, X. Simulation-Based Testing and Evaluation Tools for Transportation Cyber-Physical Systems. IEEE Trans. Veh. Technol. 2016, 65, 1098–1108. [Google Scholar] [CrossRef]
- Slåtten, V.; Herrmann, P.; Kraemer, F.A. Model-Driven Engineering of Reliable Fault-Tolerant Systems-A State-of-the-Art Survey. Adv. Comput. 2013, 91, 119–205. [Google Scholar]
- Solé, M.; Muntés-Mulero, V.; Rana, A.I.; Estrada, G. Survey on Models and Techniques for Root-Cause Analysis. arXiv, 2017; arXiv:1701.08546. [Google Scholar]
- Völter, M.; Stahl, T.; Bettin, J.; Haase, A.; Helsen, S. Model-Driven Software Development: Technology, Engineering, Management; John Wiley & Sons: New York, NY, USA, 2013. [Google Scholar]
- Brambilla, M.; Cabot, J.; Wimmer, M. Model-driven software engineering in practice. Synth. Lect. Softw. Eng. 2012, 1, 1–182. [Google Scholar] [CrossRef]
- Kordon, F.; Hugues, J.; Canals, A.; Dohet, A. Embedded Systems: Analysis and Modeling with SysML, UML and AADL; John Wiley & Sons: New York, NY, USA, 2013. [Google Scholar]
- Wehrmeister, M.A.; Pereira, C.E.; Rammig, F.J. Aspect-oriented model-driven engineering for embedded systems applied to automation systems. IEEE Trans. Ind. Inform. 2013, 9, 2373–2386. [Google Scholar] [CrossRef]
- Lee, E.A. The Past, Present and Future of Cyber-Physical Systems: A Focus on Models. Sensors 2015, 15, 4837–4869. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weber, P.; Medina-Oliva, G.; Simon, C.; Iung, B. Overview on Bayesian networks applications for dependability, risk analysis and maintenance areas. Eng. Appl. Artif. Intell. 2012, 25, 671–682. [Google Scholar] [CrossRef]
- Francalanza, E.; Borg, J.; Constantinescu, C. A knowledge-based tool for designing cyber physical production systems. Comput. Ind. 2017, 84, 39–58. [Google Scholar] [CrossRef]
- Weyns, D.; Ahmad, T. Claims and evidence for architecture-based self-adaptation: A systematic literature review. In European Conference on Software Architecture; Springer: New York, NY, USA, 2013; pp. 249–265. [Google Scholar]
- Kakousis, K.; Paspallis, N.; Papadopoulos, G.A. A survey of software adaptation in mobile and ubiquitous computing. Enterp. Inf. Syst. 2010, 4, 355–389. [Google Scholar] [CrossRef]
- Roy, S.; Biswas, S.; Chaudhuri, S.S. Nature-inspired swarm intelligence and its applications. Int. J. Mod. Educ. Comput. Sci. 2014, 6, 55. [Google Scholar] [CrossRef]
- Mavrovouniotis, M.; Li, C.; Yang, S. A survey of swarm intelligence for dynamic optimization: Algorithms and applications. Swarm Evol. Comput. 2017, 33, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Parpinelli, R.S.; Lopes, H.S. New inspirations in swarm intelligence: A survey. Int. J. Bio-Inspir. Comput. 2011, 3, 1–16. [Google Scholar] [CrossRef]
- Muccini, H.; Sharaf, M.; Weyns, D. Self-adaptation for cyber-physical systems: A systematic literature review. In Proceedings of the 11th International Symposium on Software Engineering for Adaptive and Self-Managing Systems, Austin, TX, USA, 16–17 May 2016; pp. 75–81. [Google Scholar]
- Chen, Y.; Zhou, J.; Guo, M. A context-aware search system for Internet of Things based on hierarchical context model. Telecommun. Syst. 2016, 62, 77–91. [Google Scholar] [CrossRef]
- Li, Y.; Chai, K.K.; Chen, Y.; Loo, J. Smart Duty Cycle Control with Reinforcement Learning for Machine to Machine Communications. In Proceedings of the 2015 IEEE International Conference on Communication Workshop (ICCW), London, UK, 8–12 June 2015; pp. 1458–1463. [Google Scholar]
- Gu, S.; Holly, E.; Lillicrap, T.; Levine, S. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. arXiv, 2016; arXiv:1610.00633. [Google Scholar]
- Toser, Z.; Lorincz, A. The Cyber-Physical System Approach Towards Artificial General Intelligence: The Problem of Verification. In Artificial General Intelligence; Bieger, J., Goertzel, B., Potapov, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9205, pp. 373–383. [Google Scholar]
- Mi, M.; Zolotov, I. Comparison between multi-class classifiers and deep learning with focus on industry 4.0. In Proceedings of the 2016 Cybernetics & Informatics (K&I), Levoÿa, Slovakia, 2–5 February 2016; pp. 1–5. [Google Scholar]
- Wang, H.; Li, Q.; Yi, F.; Li, Z.; Sun, L. Influential spatial facility prediction over large scale cyber-physical vehicles in smart city. Eurasip J. Wirel. Commun. Netw. 2016, 2016, 103. [Google Scholar] [CrossRef]
- Varshney, K.R.; Alemzadeh, H. On the Safety of Machine Learning: Cyber-Physical Systems, Decision Sciences, and Data Products. arXiv, 2016; arXiv:1610.01256. [Google Scholar]
- Maier, A. Online passive learning of timed automata for cyber-physical production systems. In Proceedings of the 2014 12th IEEE International Conference on Industrial Informatics (INDIN), Porto Alegre, Brazil, 27–30 July 2014; pp. 60–66. [Google Scholar]
- Ruchkin, I.; Samuel, S.; Schmerl, B.; Rico, A.; Garlan, D. Challenges in physical modeling for adaptation of cyber-physical systems. In Proceedings of the 2016 IEEE 3rd World Forum on Internet of Things (WF-IoT), Reston, VA, USA, 12–14 December 2016; pp. 210–215. [Google Scholar]
- Macias-Escriva, F.D.; Haber, R.; del Toro, R.; Hernandez, V. Self-adaptive systems: A survey of current approaches, research challenges and applications. Expert Syst. Appl. 2013, 40, 7267–7279. [Google Scholar] [CrossRef]
- Moreno, G.A.; Cámara, J.; Garlan, D.; Schmerl, B. Proactive self-adaptation under uncertainty: A probabilistic model checking approach. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, Bergamo, Italy, 30 August–4 September 2015; pp. 1–12. [Google Scholar]
- Seshia, S.A.; Hu, S.; Li, W.; Zhu, Q. Design Automation of Cyber-Physical Systems: Challenges, Advances, and Opportunities. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2017, 36, 1421–1434. [Google Scholar] [CrossRef]
- Amodei, D.; Olah, C.; Steinhardt, J.; Christiano, P.; Schulman, J.; Mané, D. Concrete problems in AI safety. arXiv, 2016; arXiv:1606.06565. [Google Scholar]
- Seshia, S.A.; Sadigh, D.; Sastry, S.S. Towards verified artificial intelligence. arXiv, 2016; arXiv:1606.08514. [Google Scholar]
- Khan, F.; Rathnayaka, S.; Ahmed, S. Methods and models in process safety and risk management: Past, present and future. Process Saf. Environ. Prot. 2015, 98, 116–147. [Google Scholar] [CrossRef]
- Vose, D. Risk Analysis: A Quantitative Guide; John Wiley & Sons: New York, NY, USA, 2008. [Google Scholar]
- Weyns, D.; Iftikhar, M.U.; De La Iglesia, D.G.; Ahmad, T. A survey of formal methods in self-adaptive systems. In Proceedings of the Fifth International Conference on Computer Science and Software Engineering, Montreal, QC, Canada, 27–29 June 2012; pp. 67–79. [Google Scholar]
- Babaee, R.; Babamir, S.M. Runtime verification of service-oriented systems: A well-rounded survey. Int. J. Web Grid Serv. 2013, 9, 213–267. [Google Scholar] [CrossRef]
- Singh, I.; Lee, S.-W. Self-adaptive requirements for intelligent transportation system: A case study. In Proceedings of the 2017 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 18–20 October 2017; pp. 520–526. [Google Scholar]
- Camilli, M.; Gargantini, A.; Scandurra, P. Zone-based formal specification and timing analysis of real-time self-adaptive systems. Sci. Comput. Program. 2018, 159, 28–57. [Google Scholar] [CrossRef] [Green Version]
- Fu, Y.; Shuvo, M.H. An Approach to Analyzing Adaptive Intelligent Vehicle System Using SMT Solver. In Proceedings of the 2016 International Conference on Control, Decision and Information Technologies (CoDIT), St. Julian’s, Malta, 6–8 April 2016; pp. 313–319. [Google Scholar]
- Bersani, M.M.; García-Valls, M. The cost of formal verification in adaptive CPS. An example of a virtualized server node. In Proceedings of the 2016 IEEE 17th International Symposium on High Assurance Systems Engineering (HASE), Orlando, FL, USA, 7–9 January 2016; pp. 39–46. [Google Scholar]
- Klös, V.; Göthel, T.; Glesner, S. Comprehensible and dependable self-learning self-adaptive systems. J. Syst. Archit. 2018, 85, 28–42. [Google Scholar] [CrossRef]
- Cámara, J.; Moreno, G.A.; Garlan, D. Stochastic game analysis and latency awareness for proactive self-adaptation. In Proceedings of the 9th International Symposium on Software Engineering for Adaptive and Self-Managing Systems, Hyderabad, India, 2–3 June 2014; pp. 155–164. [Google Scholar]
- Koh, Y.; Her, H.; Yi, K.; Kim, K. Integrated Speed and Steering Control Driver Model for Vehicle-Driver Closed-Loop Simulation. IEEE Trans. Veh. Technol. 2016, 65, 4401–4411. [Google Scholar] [CrossRef]
- Li, J.; Zhang, Y.; Chen, Y. A Self-Adaptive Traffic Light Control System Based on Speed of Vehicles. In Proceedings of the 2016 IEEE International Conference on Software Quality, Reliability and Security Companion (QRS-C), Vienna, Austria, 1–3 August 2016; pp. 382–388. [Google Scholar]
- Perez-Palacin, D.; Mirandola, R. Uncertainties in the modeling of self-adaptive systems: A taxonomy and an example of availability evaluation. In Proceedings of the 5th ACM/SPEC International Conference on Performance Engineering, San Jose, CA, USA, 21 July 2014; pp. 3–14. [Google Scholar]
- Esfahani, N.; Kouroshfar, E.; Malek, S. Taming uncertainty in self-adaptive software. In Proceedings of the 19th ACM SIGSOFT Symposium and the 13th European Conference on Foundations of Software Engineering, Szeged, Hungary, 5–9 September 2011; pp. 234–244. [Google Scholar]
- Trapp, M.; Schneider, D. Safety assurance of open adaptive systems–a survey. In Models@ Run. Time; Springer: Berlin, Germany, 2014; pp. 279–318. [Google Scholar]
- McGee, E.T.; McGregor, J.D. Using dynamic adaptive systems in safety-critical domains. In Proceedings of the 11th International Symposium on Software Engineering for Adaptive and Self-Managing Systems, Austin, TX, USA, 16–17 May 2016; pp. 115–121. [Google Scholar]
- Bozhinoski, D. Managing safety and adaptability in Mobile Multi-Robot systems. In Proceedings of the 11th International ACM SIGSOFT Conference on Quality of Software Architectures, Montréal, QC, Canada, 4–8 May 2015; pp. 135–140. [Google Scholar]
- Klös, V.; Göthel, T.; Glesner, S. Formal Models for Analysing Dynamic Adaptation Behaviour in Real-Time Systems. In Proceedings of the IEEE International Workshops on Foundations and Applications of Self* Systems, Augsburg, Germany, 12–16 September 2016; pp. 106–111. [Google Scholar]
- Zeller, M.; Prehofer, C. Timing constraints for runtime adaptation in real-time, networked embedded systems. In Proceedings of the 2012 ICSE Workshop on Software Engineering for Adaptive and Self-Managing Systems (SEAMS), Zürich, Switzerland, 4–5 June 2012; pp. 73–82. [Google Scholar]
- Tan, L.; Du, C.; Dong, Y. Control-Performance-Driven Period and Deadline Selection for Cyber-Physical Systems. In Proceedings of the 2015 10th Asian Control Conference (ASCC), Kota Kinabalu, Malaysia, 31 May–3 June 2015. [Google Scholar]
- Kim, J.; Kim, H.; Lakshmanan, K.; Rajkumar, R.R. Parallel scheduling for cyber-physical systems: Analysis and case study on a self-driving car. In Proceedings of the ACM/IEEE 4th International Conference on Cyber-Physical Systems, Philadelphia, PA, USA, 8–11 April 2013; pp. 31–40. [Google Scholar]
- Kritikakou, A.; Marty, T.; Roy, M. DYNASCORE: DYNAmic Software COntroller to increase REsource utilization in mixed-critical systems. ACM Trans. Des. Autom. Electron. Syst. 2017, 23, 13. [Google Scholar] [CrossRef]
- Wu, S.-y.; Zhang, P.; Li, F.; Gu, F.; Pan, Y. A hybrid discrete particle swarm optimization-genetic algorithm for multi-task scheduling problem in service oriented manufacturing systems. J. Cent. South Univ. 2016, 23, 421–429. [Google Scholar] [CrossRef]
- Deb, K. Multi-objective optimization using evolutionary algorithms: An introduction. Multi-Object. Evol. Optim. Prod. Des. Manuf. 2011, 1–24. [Google Scholar] [CrossRef]
- Coello, C.C.; Dhaenens, C.; Jourdan, L. Advances in Multi-Objective Nature Inspired Computing; Springer: Berlin, Germany, 2009; Volume 272. [Google Scholar]
- Zhang, K.; Zhang, D.; de La Fortelle, A.; Wu, X.; Grégoire, J. State-driven priority scheduling mechanisms for driverless vehicles approaching intersections. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2487–2500. [Google Scholar] [CrossRef]
- Bambagini, M.; Marinoni, M.; Aydin, H.; Buttazzo, G. Energy-Aware Scheduling for Real-Time Systems: A Survey. ACM Trans. Embed. Comput. Syst. 2016, 15, 7. [Google Scholar] [CrossRef]
- Shepilov, Y.; Pavlova, D.; Kazanskaia, D. Multithreading MAS Platform for Real-Time Scheduling. Int. J. Softw. Innov. 2016, 4, 48–60. [Google Scholar] [CrossRef]
- Jiang, J.-M.; Zhu, H.; Li, Q.; Zhao, Y.; Zhao, L.; Zhang, S.; Gong, P.; Hong, Z. Analyzing Event-Based Scheduling in Concurrent Reactive Systems. ACM Trans. Embed. Comput. Syst. 2015, 14, 86. [Google Scholar] [CrossRef]
- Ruiz-Arenas, S.; Horváth, I.; Mejía-Gutiérrez, R.; Opiyo, E. Towards the maintenance principles of cyber-physical systems. Stroj. Vestn. J. Mech. Eng. 2014, 60, 815–831. [Google Scholar] [CrossRef]
- Kans, M.; Galar, D.; Thaduri, A. Maintenance 4.0 in Railway Transportation Industry. In A Data Fusion Approach of Multiple Maintenance Data Sources for Real-World Reliability Modelling; Koskinen, K.T., Kortelainen, H., Aaltonen, J., Uusitalo, T., Komonen, K., Mathew, J., Laitinen, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 317–331. [Google Scholar]
- Bukowski, L. System of systems dependability–Theoretical models and applications examples. Reliab. Eng. Syst. Saf. 2016, 151, 76–92. [Google Scholar] [CrossRef]
- Mittal, S.; Vetter, J.S. A survey of techniques for modeling and improving reliability of computing systems. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 1226–1238. [Google Scholar] [CrossRef]
- Cecati, C. A survey of fault diagnosis and fault-tolerant techniques—part II: Fault diagnosis with knowledge-based and hybrid/active approaches. IEEE Trans. Ind. Electron. 2015, 62, 3768–3774. [Google Scholar]
- Muhammed, T.; Shaikh, R.A. An analysis of fault detection strategies in wireless sensor networks. J. Netw. Comput. Appl. 2017, 78, 267–287. [Google Scholar] [CrossRef]
- Chouikhi, S.; El Korbi, I.; Ghamri-Doudane, Y.; Saidane, L.A. A survey on fault tolerance in small and large scale wireless sensor networks. Comput. Commun. 2015, 69, 22–37. [Google Scholar] [CrossRef]
- Yang, W.; Liu, Y.; Xu, C.; Cheung, S.-C. A survey on dependability improvement techniques for pervasive computing systems. Sci. China Inf. Sci. 2015, 58, 1–14. [Google Scholar] [CrossRef]
- Li, F.; Shi, P.; Wang, X.; Agarwal, R. Fault detection for networked control systems with quantization and Markovian packet dropouts. Signal Process. 2015, 111, 106–112. [Google Scholar] [CrossRef]
- Xia, J.; Jiang, B.; Zhang, K.; Xu, J. Robust Fault Diagnosis Design for Linear Multiagent Systems with Incipient Faults. Math. Probl. Eng. 2015, 2015, 436935. [Google Scholar] [CrossRef]
- Esfahani, P.M.; Lygeros, J. A tractable fault detection and isolation approach for nonlinear systems with probabilistic performance. IEEE Trans. Autom. Control 2016, 61, 633–647. [Google Scholar] [CrossRef]
- Reppa, V.; Polycarpou, M.M.; Panayiotou, C.G. Distributed Sensor Fault Diagnosis for a Network of Interconnected Cyber-Physical Systems. IEEE Trans. Control Netw. Syst. 2015, 2, 11–23. [Google Scholar] [CrossRef]
- Dong, H.; Wang, Z.; Ding, S.X.; Gao, H. A Survey on Distributed Filtering and Fault Detection for Sensor Networks. Math. Probl. Eng. 2014, 2014, 858624. [Google Scholar] [CrossRef]
- Warriach, E.U.; Tei, K. Fault detection in wireless sensor networks: A machine learning approach. In Proceedings of the 2013 IEEE 16th International Conference on Computational Science and Engineering (CSE), Sydney, Australia, 3–5 December 2013; pp. 758–765. [Google Scholar]
- Krishnamurthy, S.; Sarkar, S.; Tewari, A. Scalable anomaly detection and isolation in cyber-physical systems using bayesian networks. In Proceedings of the ASME 2014 Dynamic Systems and Control Conference, San Antonio, TX, USA, 22–24 October 2014; p. V002T26A006. [Google Scholar]
- Sanislav, T.; Merza, K.; Mois, G.; Miclea, L. Cyber-physical system dependability enhancement through data mining. In Proceedings of the 2016 IEEE International Conference on Automation, Quality and Testing, Robotics (AQTR), Cluj-Napoca, Romania, 19–21 May 2016; pp. 1–5. [Google Scholar]
- Khalid, Z.; Fisal, N.; Rozaini, M. A Survey of Middleware for Sensor and Network Virtualization. Sensors 2014, 14, 24046–24097. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, P.; Zuo, D.-C.; Hou, K.-M.; Zhang, Z.; Shi, H.-L. A Light-weight Multilevel Recoverable Container for Event-driven System: A Self-healing CPS Approach. In Proceedings of the 3rd International Conference on Wireless Communication and Sensor Networks (WCSN 2016), Wuhan, China, 10–11 December 2016. [Google Scholar]
- Ahn, S.; Yoo, C.; Lee, S.; Lee, H.; Kim, S.J. Implementing virtual platform for global-scale cyber physical system networks. Int. J. Commun. Syst. 2015, 28, 1899–1920. [Google Scholar] [CrossRef]
- Khan, I.; Belqasmi, F.; Glitho, R.; Crespi, N.; Morrow, M.; Polakos, P. Wireless Sensor Network Virtualization: A Survey. IEEE Commun. Surv. Tutor. 2016, 18, 553–576. [Google Scholar] [CrossRef]
- Dettoni, F.; Lung, L.C.; Luiz, A.F. Using Virtualization Technology for Fault-Tolerant Replication in LAN. In New Results in Dependability and Computer Systems; Zamojski, W., Mazurkiewicz, J., Sugier, J., Walkowiak, T., Kacprzyk, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 224, pp. 131–140. [Google Scholar]
- Quattrociocchi, W.; Caldarelli, G.; Scala, A. Self-Healing Networks: Redundancy and Structure. PLoS ONE 2014, 9, e87986. [Google Scholar] [CrossRef] [PubMed]
- Hazra, A.; Dasgupta, P.; Chakrabarti, P.P. Formal assessment of reliability specifications in embedded cyber-physical systems. J. Appl. Log. 2016, 18, 71–104. [Google Scholar] [CrossRef]
- Cui, Y.; Lane, J.; Voyles, R.; Krishnamoorthy, A. A new fault tolerance method for field robotics through a self-adaptation architecture. In Proceedings of the 2014 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Hokkaido, Japan, 27–30 October 2014; pp. 1–6. [Google Scholar]
- Warriach, E.U.; Ozcelebi, T.; Lukkien, J.J. Fault-prevention in smart environments for dependable applications. In Proceedings of the 2014 IEEE Eighth International Conference on Self-Adaptive and Self-Organizing Systems (SASO), Umea, Sweden, 8–12 September 2014; pp. 183–184. [Google Scholar]
- Zheng, J.; Wang, P.; Li, C.; Mouftah, H.T. An Efficient Fault-Prevention Clustering Protocol for Robust Underwater Sensor Networks. In Proceedings of the IEEE International Conference on Communications (ICC’08), Beijing, China, 19–23 May 2008; pp. 2802–2807. [Google Scholar]
- Cooray, D.; Kouroshfar, E.; Malek, S.; Roshandel, R. Proactive self-adaptation for improving the reliability of mission-critical, embedded, and mobile software. IEEE Trans. Softw. Eng. 2013, 39, 1714–1735. [Google Scholar] [CrossRef]
- Yano, I.H.; Oliveira, V.C.; de Mello Fagotto, E.A.; Mota, A.D.A.; Mota, L.T.M. Predicting battery charge depletion in wireless sensor networks using received signal strength indicator. J. Comput. Sci. 2013, 9, 821–826. [Google Scholar] [CrossRef]
- Warriach, E.U.; Ozcelebi, T.; Lukkien, J.J. A Comparison of Predictive Algorithms for Failure Prevention in Smart Environment Applications. In Proceedings of the 2015 International Conference on Intelligent Environments (IE), Prague, Czech Republic, 14 July 2015; pp. 33–40. [Google Scholar]
- Németh, E.; Lakner, R.; Hangos, K.M.; Cameron, I.T. Prediction-based diagnosis and loss prevention using qualitative multi-scale models. Inf. Sci. 2007, 177, 1916–1930. [Google Scholar] [CrossRef]
- Lakner, R.; Németh, E.; Hangos, K.M.; Cameron, I.T. Multiagent realization of prediction-based diagnosis and loss prevention. In Proceedings of the International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Annecy, France, 27–30 June 2006; pp. 70–80. [Google Scholar]
- Priesterjahn, C.; Steenken, D.; Tichy, M. Component-based timed hazard analysis of self-healing systems. In Proceedings of the 8th Workshop on Assurances for Self-Adaptive Systems, Szeged, Hungary, 4 September 2011; pp. 34–43. [Google Scholar]
- Salfner, F.; Lenk, M.; Malek, M. A survey of online failure prediction methods. ACM Comput. Surv. 2010, 42, 10. [Google Scholar] [CrossRef]
- Verma, A.K.; Srividya, A.; Ramesh, P. A systemic approach to integrated E-maintenance of large engineering plants. Int. J. Autom. Comput. 2010, 7, 173–179. [Google Scholar] [CrossRef]
- Sleptchenko, A.; Johnson, M.E. Maintaining Secure and Reliable Distributed Control Systems. Inf. J. Comput. 2014, 27, 103–117. [Google Scholar] [CrossRef]
- Wan, K.; Alagar, V. Achieving dependability of cyber physical systems with autonomic covering. In Proceedings of the 2014 IEEE 12th International Conference on Dependable, Autonomic and Secure Computing (DASC), Dalian, China, 24–27 August 2014; pp. 139–145. [Google Scholar]
- Asplund, F. The future of software tool chain safety qualification. Saf. Sci. 2015, 74, 37–43. [Google Scholar] [CrossRef]












| Ref. | Arch | Low Complexity Self-Adaptive and Dependability 1 Means, etc |
|---|---|---|
| [36] | SOA based | Decouple, Compositional service; Heartbeat, Real-time FDIR, Middleware based fault tolerate solution; |
| [37] | SOA based | Unified Abstraction, Domain-Specific Description Schemas, Formal Semantics; |
| [38] | SOA based | Knowledge-Driven Service Orchestration, Ontology based service description; |
| [44] | SOA based | Formal contract for physical property, Dynamic physical behavior, Hybrid system behavior; |
| [45] | SOA based (ebbits) | Proxy, Virtualization, Middleware, Ontology, Semantic Knowledge, Rule base context recognition; Predictive maintenance |
| [14] | MAS based | Self-organizing & Self-adaptive models, Rules & Knowledge based Reasoning, proof-of-concept; Exception Identification Model; |
| [46] | MSA+Cloud | Data-driven self-organization, Intelligent negotiation based on contract net protocol, Deadlock prevention; |
| [41] | MSA+holons | Soft real-time MSA, Hard real-time function blocks (holons); Redundancy; |
| [47] | Cloud based | Virtualization, Multilevel smart scheduling algorithms; Redundancy, checkpoints; |
| [48] | Cloud based | Distribution middleware, Virtualized interrupt model, Spatial & temporal isolation based on partitioning; Fault isolation; |
| [49] | Cloud based | Virtualization, Task migration, Evolutionary algorithm for placement, WCET response time guarantee; |
| [50] | Software defined | Network-centered (SDN), Technology Standardization; |
| [40,51] | 5C Arch | Decouple, knowledge based; Prognostics and health management, Fault isolation & identification; |
| [13,52,53] | Rainbow | Architecture-based self-adaptation (ABSA), (Re)scheduling, Strategy based, Mutation rules robustness tests; |
| [54,55,56,57] | DEECo | DSL, Decouple, IRM 2, Knowledge, Deterministic semantics, Formal analysis; Proactive reasoning, Reliable communication; |
| [58] | Na 3 | Standardization, Open-Knowledge-Driven, Ontology; |
| [59] | Na | 8 steps comprehensive FDIR, Reliability Knowledge & Reasoning; |
| [60] | Federation Arch | Component-based, Plug-in software, Plug-in runtime environment based on VM, Federation life-cycle management; |
| [61] | Na | Fault mode, Reconfiguration, Rule based diagnosis, Reasoning; |
| [62] | EVM 4 | EVM, Virtual Component, EVM DSL 5, Formal design, Multi-level & multi-object scheduling |
| Ref | Type 1 | V&V 2 | Key Analysis Technologies |
|---|---|---|---|
| [121] | RCA | R | Markov Chain (MC) |
| [122] | RCA | R | RBD, MC, Monte-Carlo simulation |
| [123] | RCA | R, A, ST | Stochastic Petri Net |
| [124] | RCA | D | MC, Stochastic Activity Network |
| [125] | M2M | D | Dependability domain ontology, FMEA |
| [126,127] | M2M | C, D | NuSMV, FTA, FMEA, HSIA, MC |
| [128] | M2M | C, A, Rb | BDD, BMC, FTA, FMEA |
| [129] | M2M | C, SF | Probabilistic temporal logic language, MC |
| [130] | M2M | R, A, M, SF | Bayesian Belief Network |
| [56] | M2S | SF, Rb | Simulation and statistical analysis |
| [131] | M2S | C, R | Automata-based diagnosis, LTL (Linear time Temporal Logic) based contract checking |
| [132] | M2S | C, Rb, R, SC | Calculation with mathematical model & Simulation |
| [133] | M2S | SF | Simulation and statistical analysis |
| Technical Area | Challenges and Directions | Urgency | Target |
|---|---|---|---|
| HW & SW infrastructure development | Precision timed, real-time HW & SW | High | Timing |
| Standardization of subsystem (interfaces) | Medium | C&C | |
| Low power devices | Medium | Energy | |
| Network communication & management | Precision timed network transmission | High | Timing |
| Real-time (wired & wireless) communication | High | Timeliness | |
| Heterogeneous network management | Medium | Maintainability | |
| Architecture design | Atomic service & subsystem design | Low | C&C |
| C&C contract, interoperable subsystems | Medium | Self-* | |
| Discrete-continuous subsystem integration | Medium | Correctness | |
| Invariant behavior of integration | High | Correctness | |
| Theory for dynamic architecture | High | Flexibility | |
| Design methodology for dependable SCPS | Medium | Complexity | |
| Middleware | FDIR middleware & Node level self-healing | Medium | Dependability |
| Light-weight virtualization & migration | Medium | Self-* | |
| Domain ontology, Knowledge database | Medium | Self-* | |
| Service discovery & combination | High | Self-* | |
| Consistent spatial-temporal & context cognition | Global reference time for large scale CPS | High | Timing |
| Low cost clock synchronization | Medium | Correctness | |
| Global location reference for mobile CPS | Low | Correctness | |
| Consistent data and context assurance | High | Correctness | |
| Lifecycle management (self-management) | Manage dynamic & changeable architecture | High | C&D |
| Multi-objective (prophetic) adaptation | High | C&D | |
| Knowledge-driven decision making | High | C&D | |
| Decision/adaptation safety/evaluation | Medium | Safety | |
| Situation aware self-healing & notification | High | Dependability | |
| Causality analysis | High | C&D | |
| HMI for human-in-loop CPS | High | Usability, safety | |
| Modeling & validation & MDE tools | Dynamic architecture modeling | High | Fidelity |
| Multidisciplinary modeling | High | Modeling | |
| Consistent of model transforming | High | Correctness | |
| Evaluation the correctness of models | High | Correctness | |
| Holistic modeling theory or methodology | Medium | Modeling | |
| Situation based model V&V | Medium | V&V | |
| MDE toolchains (design, V&V, coding, testing) and life cycle V&V supporting | Medium | Consistency & efficiency | |
| Simulation | Discrete-continuous-probability model co-sim | Medium | V&V |
| Holistic multidisciplinary simulation | High | V&V | |
| Environment-in-loop simulation | Medium | V&V | |
| Human-in-loop simulation | High | V&V | |
| Fidelity evaluation | High | Correctness |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, P.; Zuo, D.; Hou, K.M.; Zhang, Z.; Dong, J.; Li, J.; Zhou, H. A Comprehensive Technological Survey on the Dependable Self-Management CPS: From Self-Adaptive Architecture to Self-Management Strategies. Sensors 2019, 19, 1033. https://doi.org/10.3390/s19051033
Zhou P, Zuo D, Hou KM, Zhang Z, Dong J, Li J, Zhou H. A Comprehensive Technological Survey on the Dependable Self-Management CPS: From Self-Adaptive Architecture to Self-Management Strategies. Sensors. 2019; 19(5):1033. https://doi.org/10.3390/s19051033
Chicago/Turabian StyleZhou, Peng, Decheng Zuo, Kun Mean Hou, Zhan Zhang, Jian Dong, Jianjin Li, and Haiying Zhou. 2019. "A Comprehensive Technological Survey on the Dependable Self-Management CPS: From Self-Adaptive Architecture to Self-Management Strategies" Sensors 19, no. 5: 1033. https://doi.org/10.3390/s19051033
APA StyleZhou, P., Zuo, D., Hou, K. M., Zhang, Z., Dong, J., Li, J., & Zhou, H. (2019). A Comprehensive Technological Survey on the Dependable Self-Management CPS: From Self-Adaptive Architecture to Self-Management Strategies. Sensors, 19(5), 1033. https://doi.org/10.3390/s19051033