1. Introduction
In recent years, a plethora of innovative technologies and solutions are bringing intelligent transportation systems (ITSs) closer to reality. ITSs are advanced transportation systems that aim to advance and automate the operation and management of transport systems, thereby improving upon the efficiency and safety of transport. ITSs combine cutting-edge technology such as electronic control and communications with means and facilities of transportation [
1]. The development of digital image processing and computer vision techniques offers many advantages in enabling many important ITSs applications and components such as advanced driver-assistance systems (ADASs), automated vehicular surveillance (AVS), traffic and activity monitoring, traffic behavior analysis, traffic management, among others. Vehicle make and model recognition (MMR) is of great interest in these applications, owing to heightened security concerns in ITSs.
Over the years, numerous studies have been conducted to solve different challenges in vehicle detection, identification, and tracking. However, classification of vehicles into fine categories has gained attention only recently, and many challenges remain to be addressed [
2,
3,
4,
5]. The traditional vehicle MMR system relies on manual human observation or automated license plate recognition (ALPR) technique, these indirect progresses make the vehicle MMR system hardly meets the real-time constraints. Through manual observation, it is practically difficult to remember and efficiently distinguish between the wide variety of vehicle makes and models; it becomes a laborious and time-consuming task for a human observer to monitor and observe the multitude of screens and record the incoming or outgoing makes and models or to even spot the make and model being looked for. The MMR systems that rely on license plates may suffer from forging, damage, occlusion, etc., as shown in
Figure 1. In addition, there are some license-plates that can be ambiguous in terms of interpreting letters (e.g., between “0” and “O”) or license types. Moreover, in some areas, it may not be required to bear the license plate at the front or the rear. If the ALPR system is not equipped to check for license plates at both (front and rear) ends of the vehicle, it could fail. Consequently, when ALPR systems fail to correctly read the detected license plates due to the above issues, the wrong make-model information could be retrieved from the license-plates registry or database.
To overcome the aforementioned shortcomings in traditional vehicle identification systems, automated vehicle MMR techniques have become critical. The make and model of the vehicle recognized by the MMR system can be cross-checked with the license-plate registry to check for any fraud. In this dual secure way, vision-based automated MMR techniques can augment traditional ALPR-based vehicle classification systems to further enhance security.
Abdel Maseeh et al. [
6] proposed an approach to address this specific problem by combining global and local information and utilizing discriminative information labelled by a human expert. They validated their approach through experiments on recognizing the make and model of sedan cars from single view images. Jang and Turk [
7] demonstrated a car recognition application based on the SURF feature descriptor algorithm, which fuses bag-of-words and structural verification techniques. Baran et al. [
8] presented a smart camera in intelligent transportation systems for the surveillance of vehicles. The smart camera can be used for MMR, ALPR, and color recognition of vehicles. In [
9], Santos et al. introduced two car recognition methods, both relying on the analysis of the external features of the car. The first method evaluates the shape of the car’s rear, exploring its dimensions and edges, while the second considers features computed from the car’s rear lights, notably, their orientation, eccentricity, position, angle to the car license plate, and shape contour. Both methods are combined in the proposed automatic car recognition system. Ren et al. [
10] proposed a framework to detect a moving vehicle’s make and model using convolutional neural networks (CNNs). Dehghan et al. [
11] proposed a CNN-based vehicle make, model, and color recognition system, which is computationally inexpensive and provides state-of-the-art results. Huang et al. [
12] investigated fine-grained vehicle recognition using deep CNNs. They localized the vehicle and the corresponding parts with the help of region-based CNNs (RCNNs) and aggregated their features from a set of pre-trained CNNs to train a support vector machine (SVM) classifier. Gao and Lee [
13] proposed a local tiled CNN (LTCNN) strategy to alter the weight-sharing scheme of CNN with a local tiled structure, which can provide the translational, rotational, and scale invariance for MMR.
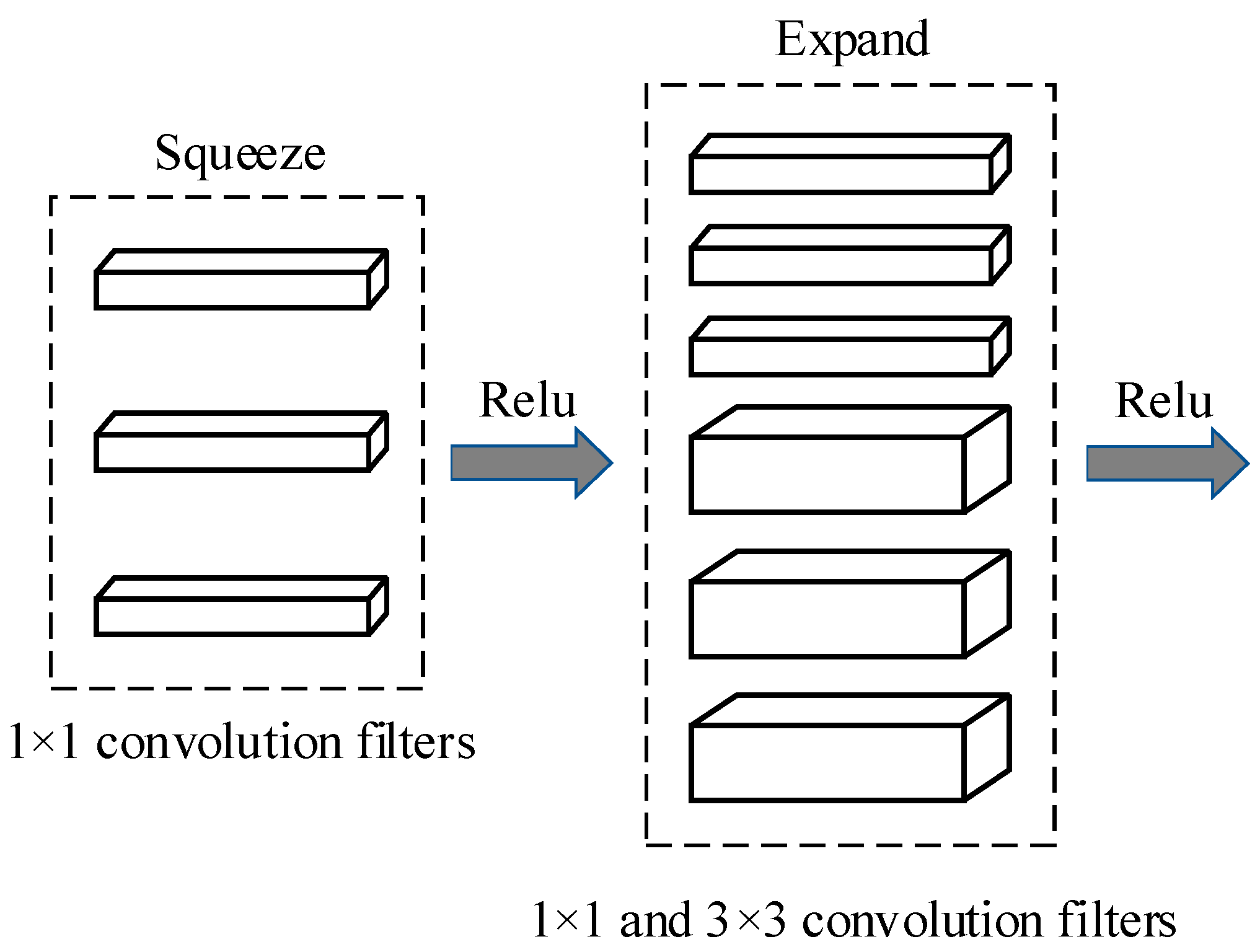
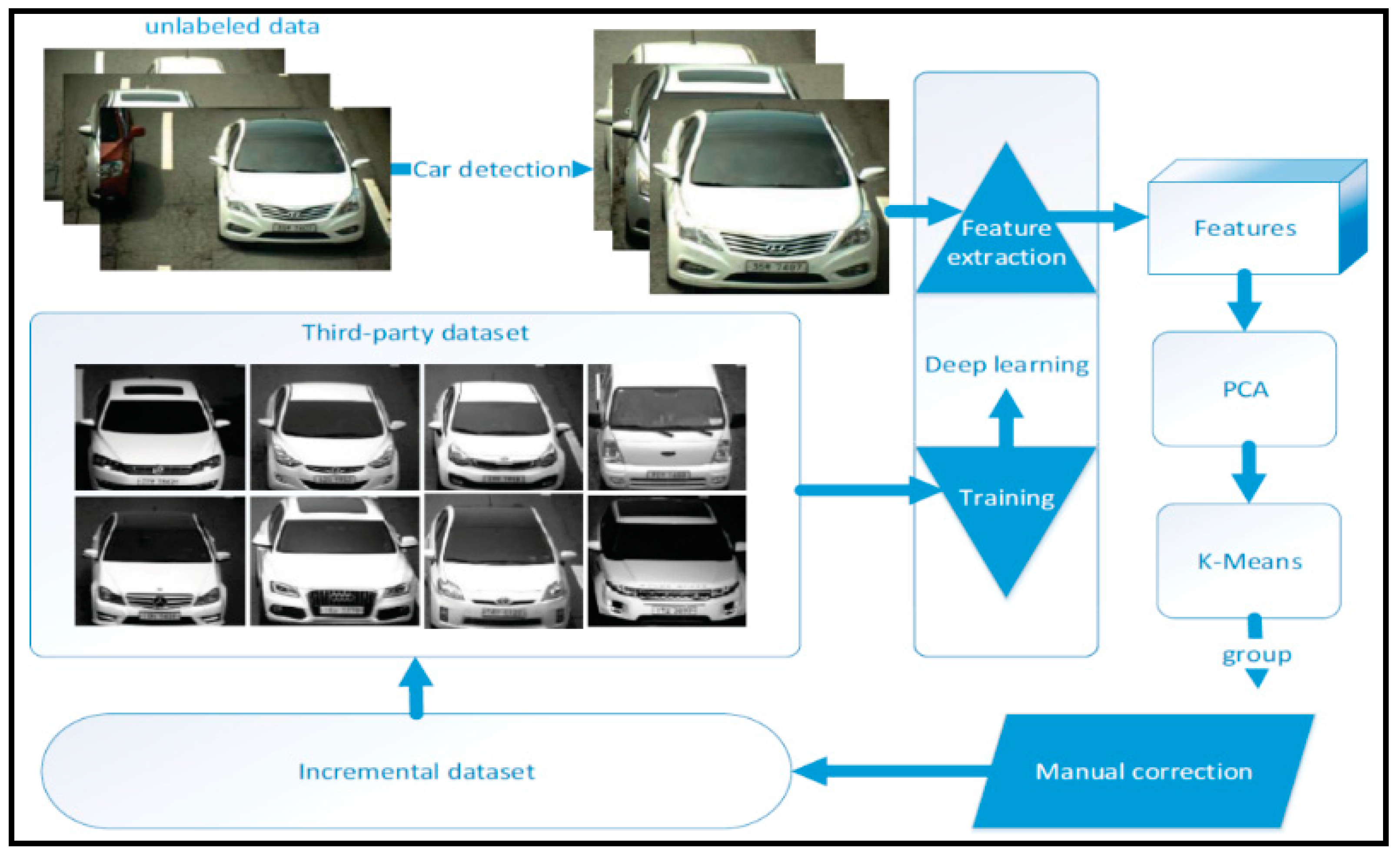
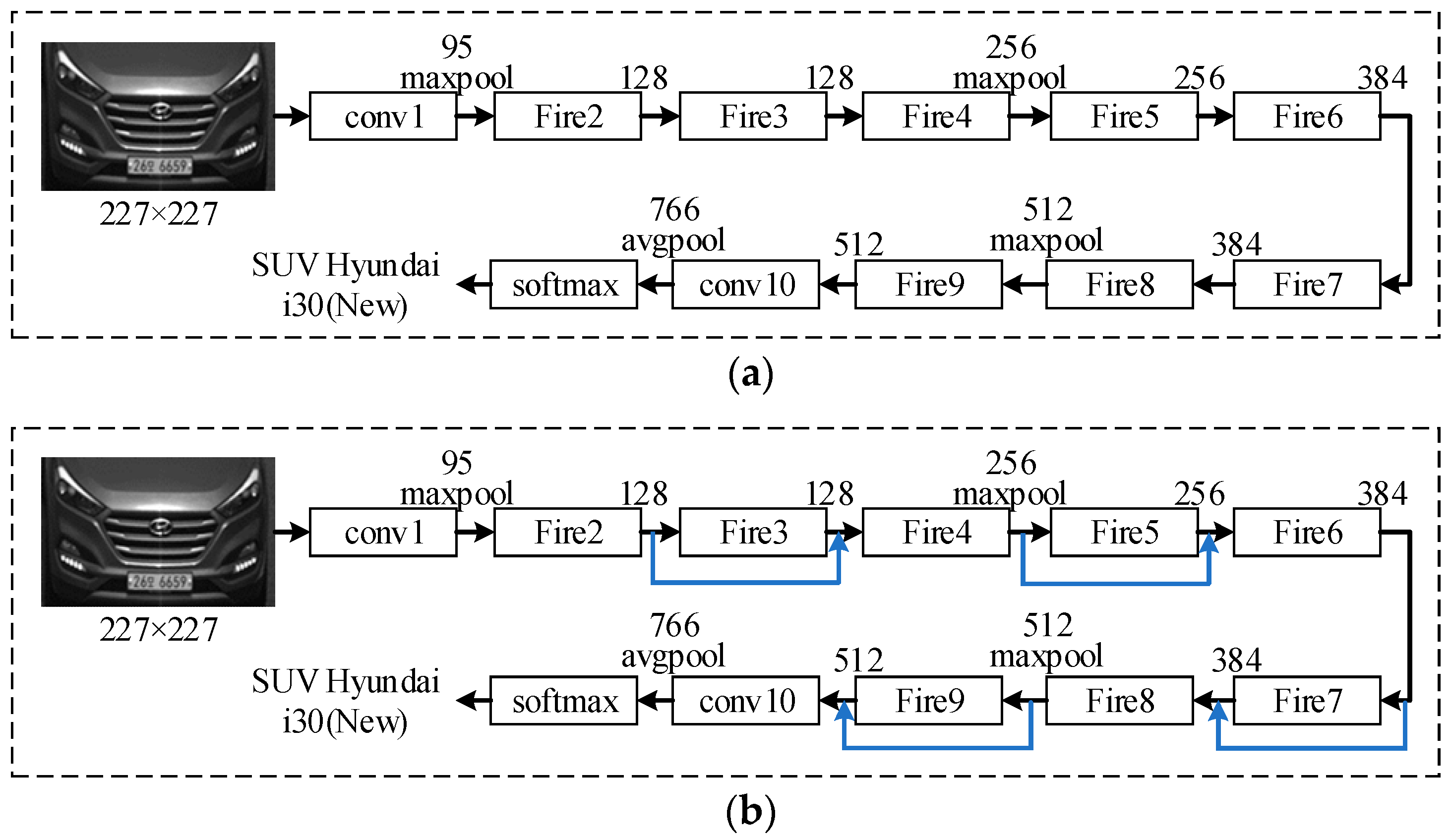
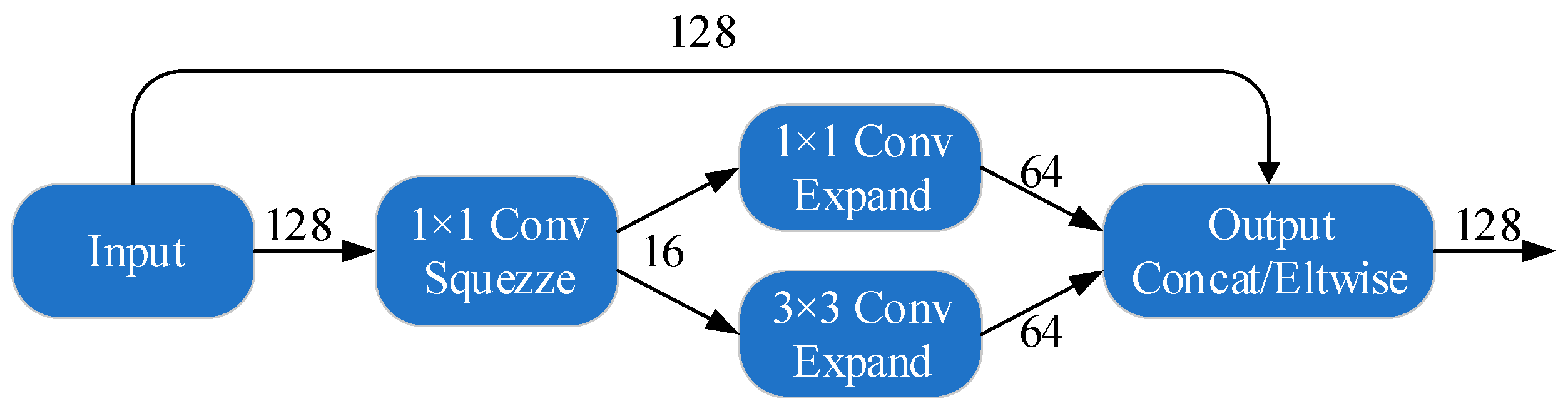
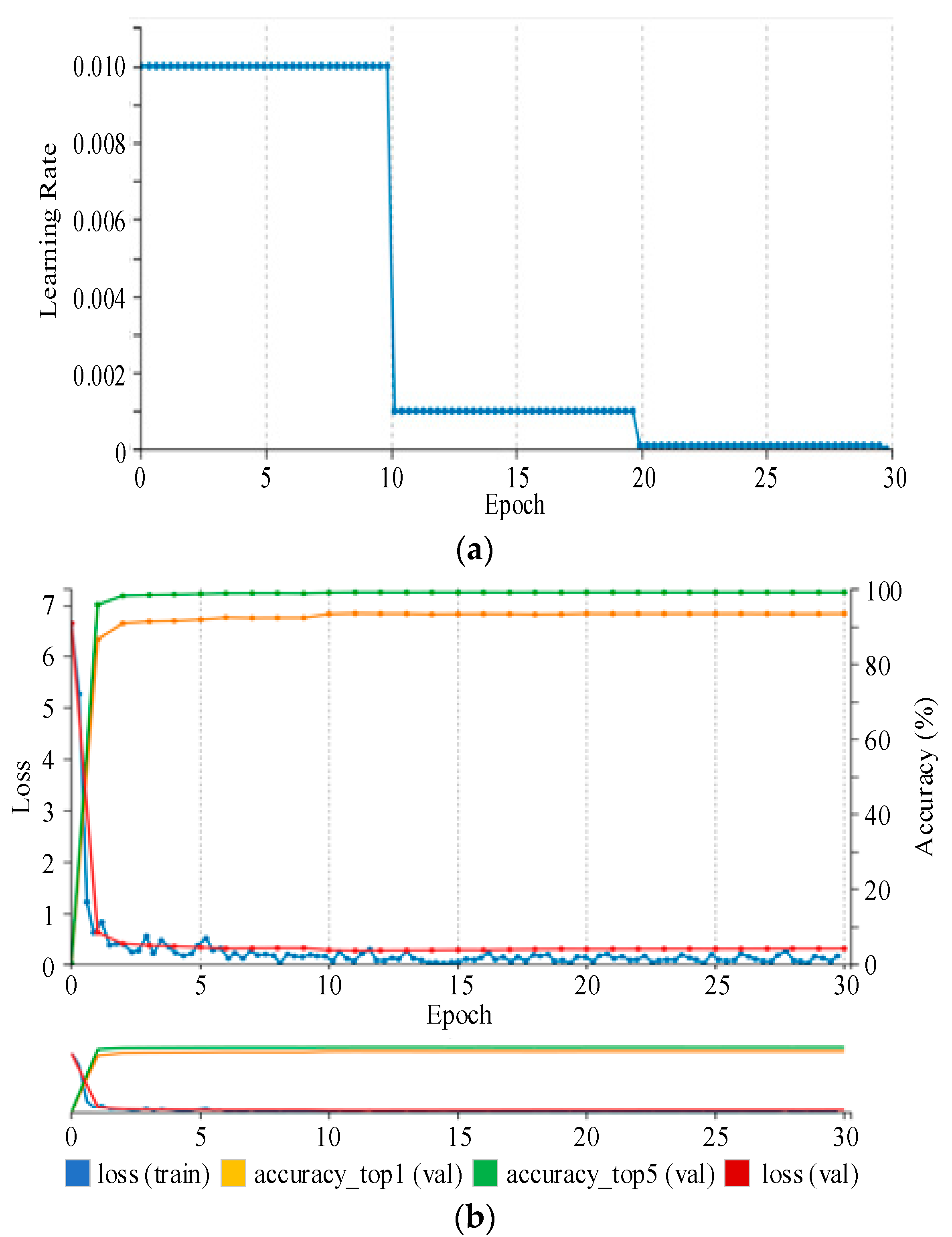
In this study, we focus on addressing the challenges in real time and automated vehicle MMR by utilizing state-of-the-art deep learning-based techniques. Vanilla CNNs have demonstrated impressive performance in vehicle MMR-related tasks. However, long training periods and large memory requirements in deployment environments often constrain the use of such models in real-time applications as well as distributed environments. Thus, in this study, a smaller CNN architecture named SqueezeNet is adopted, which requires much fewer parameters, consequently reducing memory constraints and making it suitable for real-time applications. In addition, compared to vanilla SqueezeNet, the proposed method, using a bypass connection-inspired version of SqueezeNet, demonstrates a 2.1% improvement in recognition accuracy. Further, we demonstrate the effectiveness of a data-clustering approach used in our study that considerably improves the speed of the data preparation and labelling process. The experiment results show that the proposed approach obtains higher recognition accuracy in less time and with fewer memory constraints.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}