Development of an Active High-Speed 3-D Vision System †


Abstract
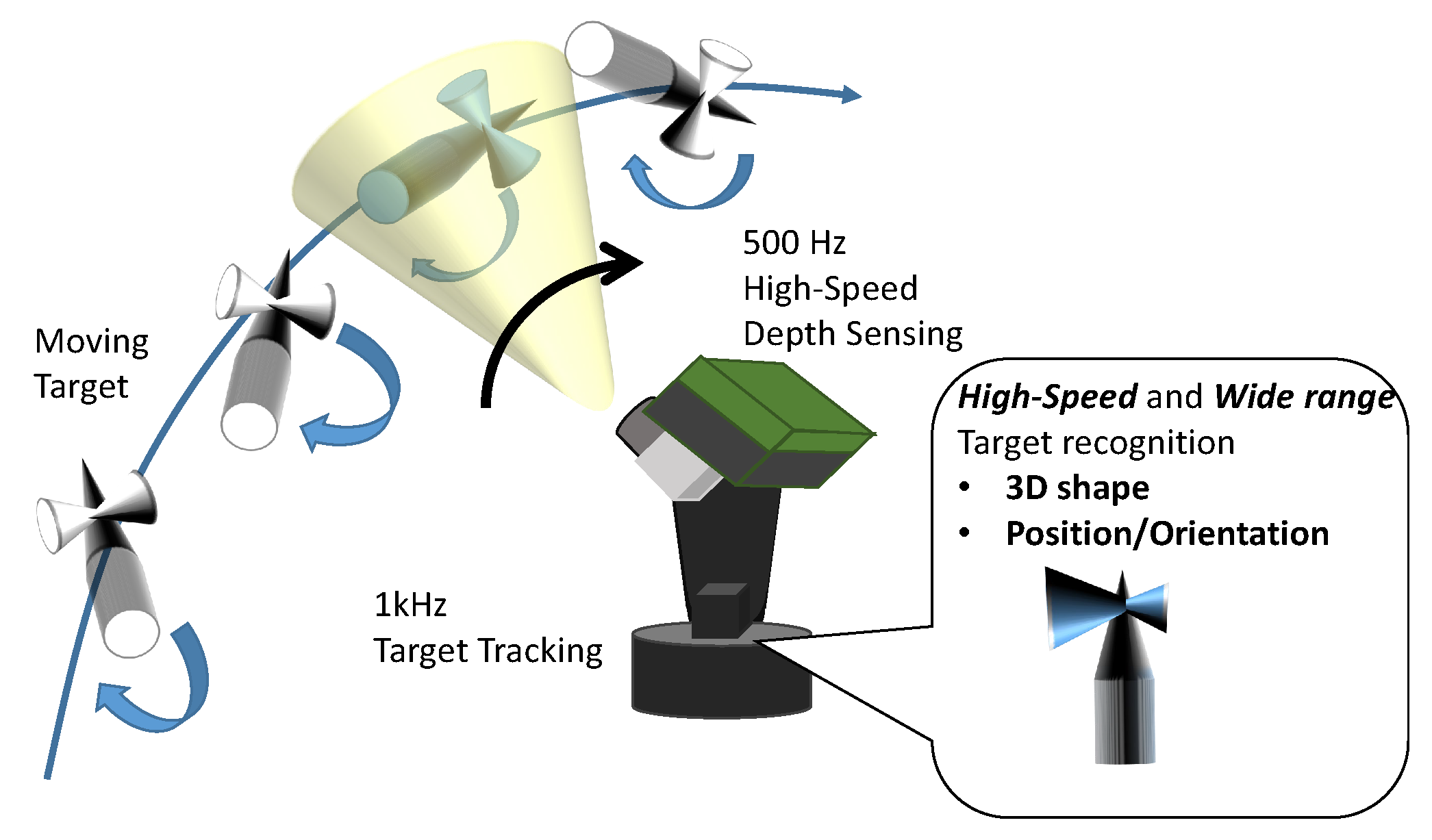
:1. Introduction
2. Related Work
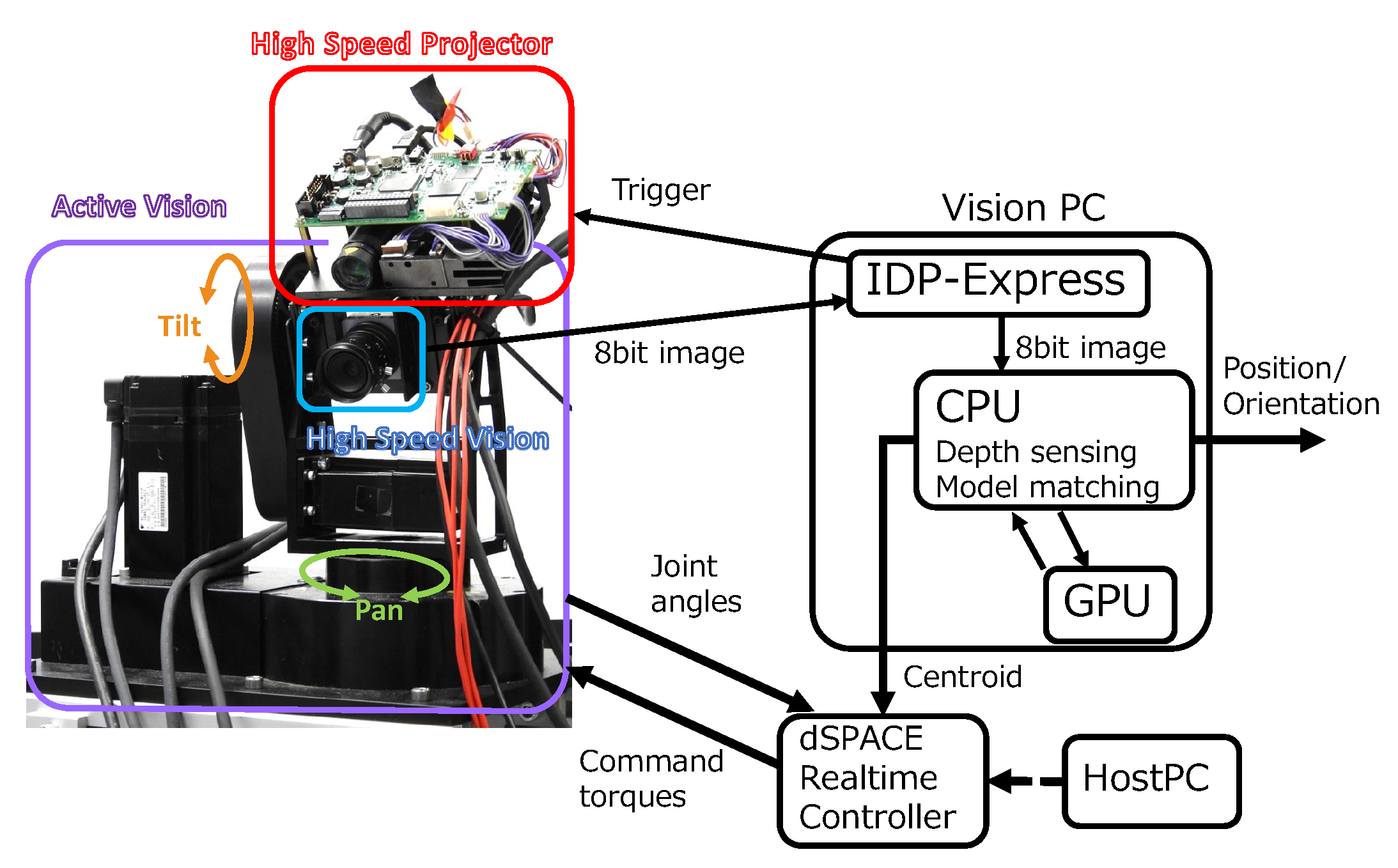
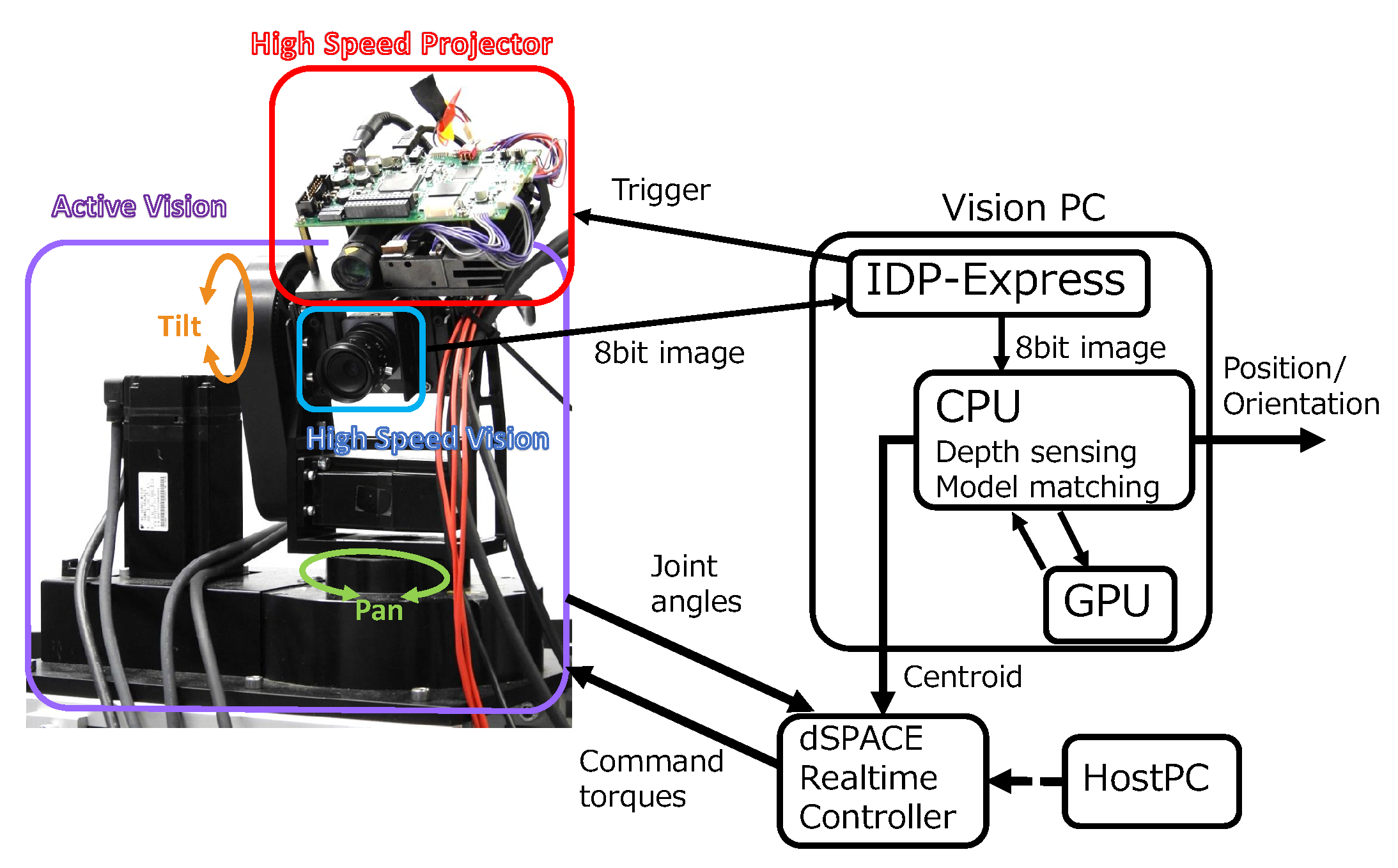
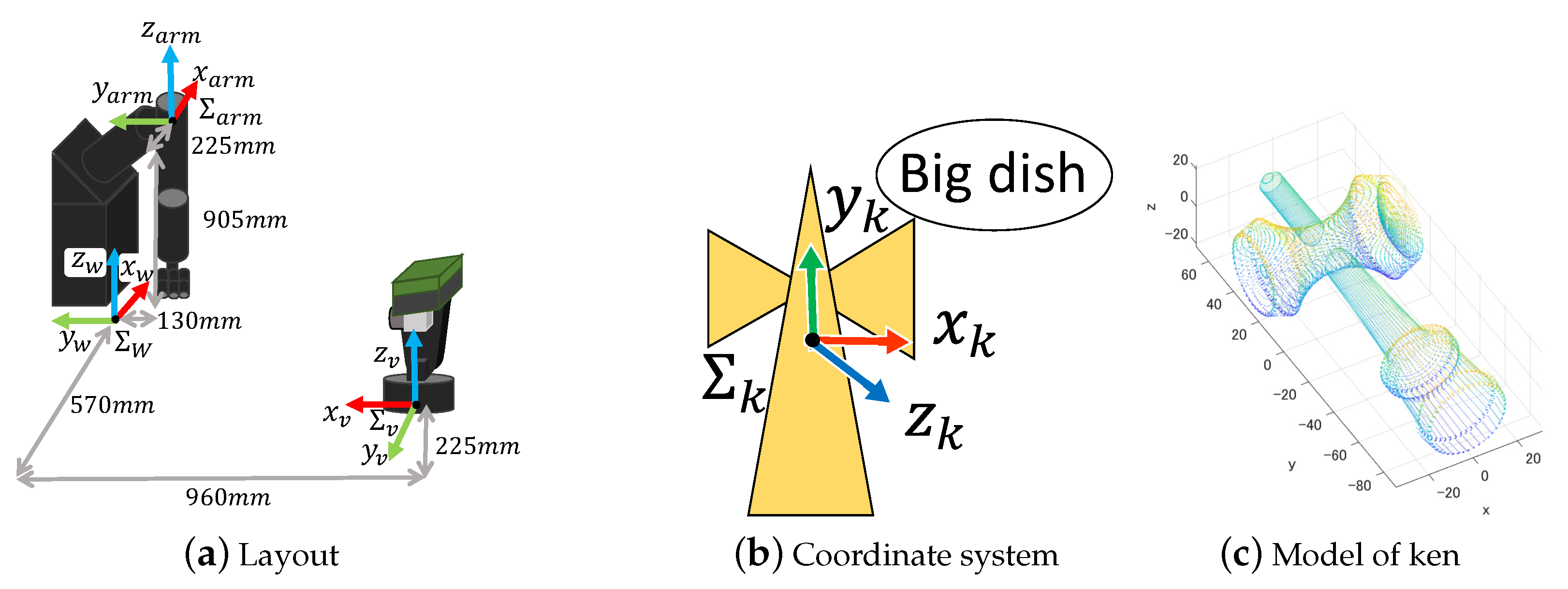
3. System
3.1. High-Speed Depth Sensor
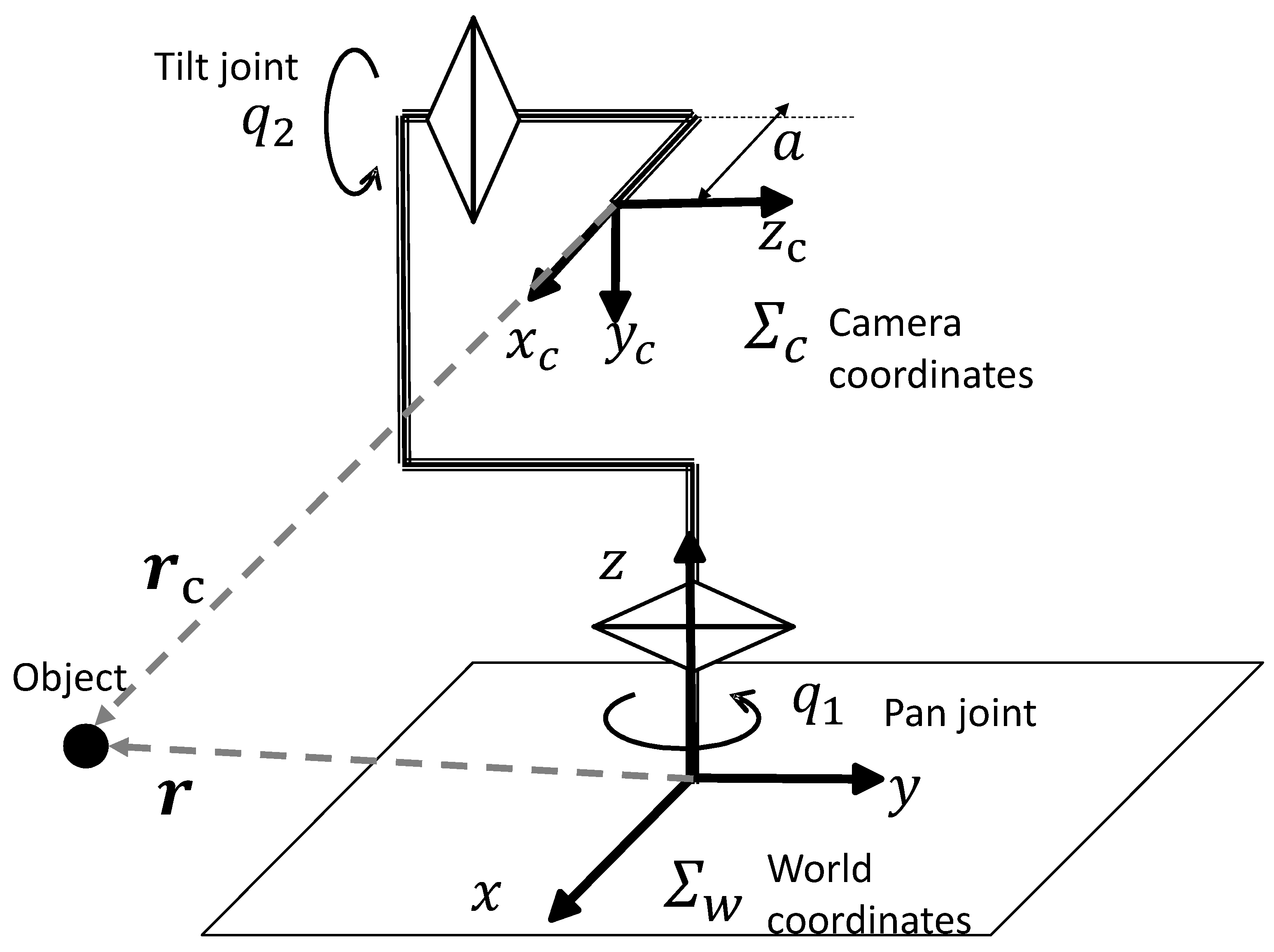
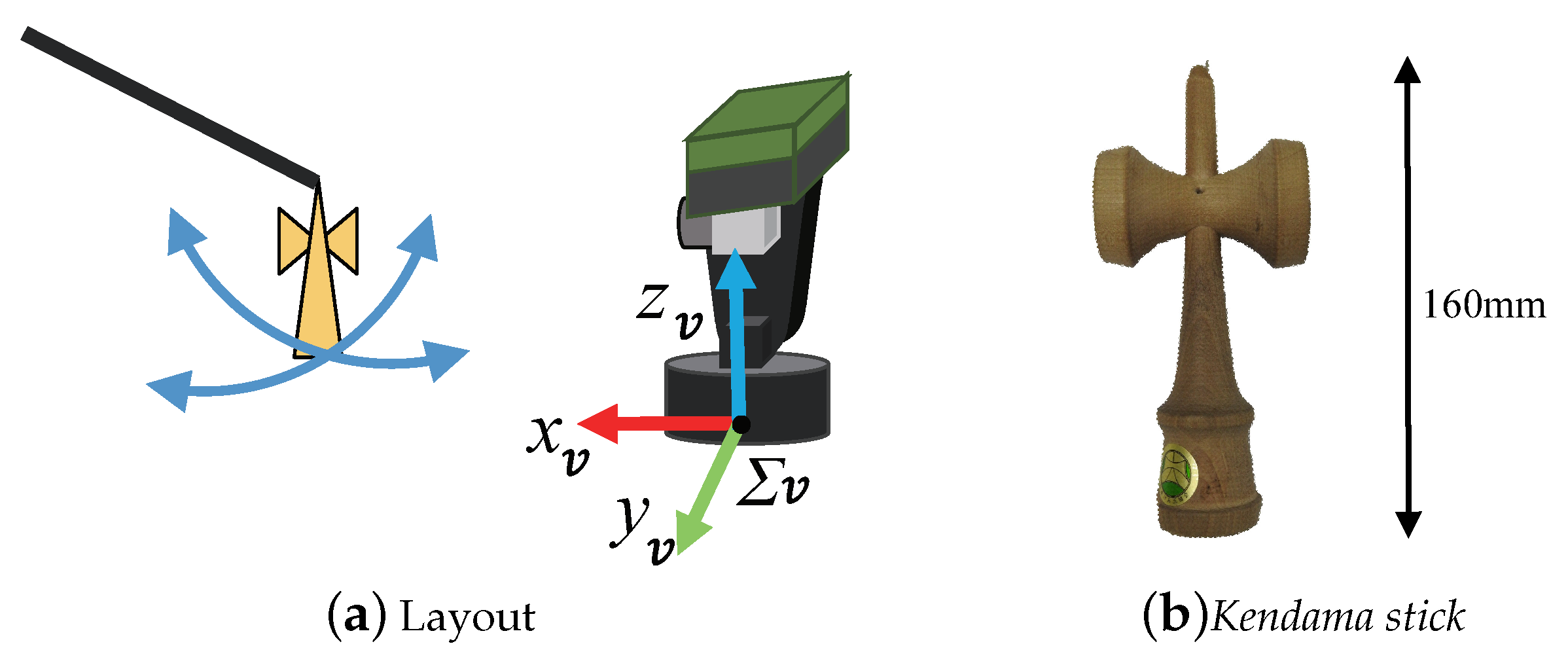
3.2. Active Vision
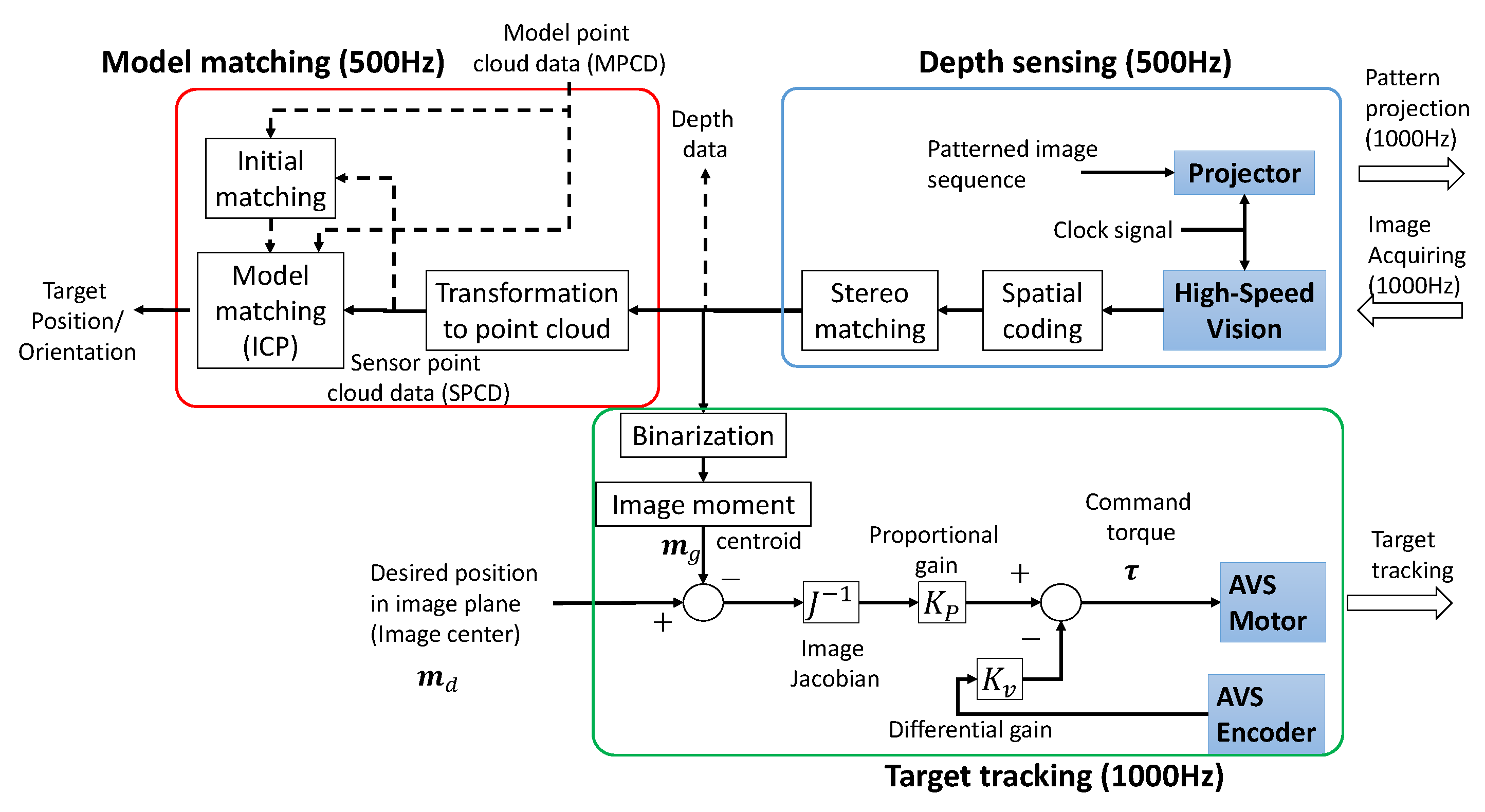
3.3. Overall Processing Flow
4. High-Speed Depth Image Sensing
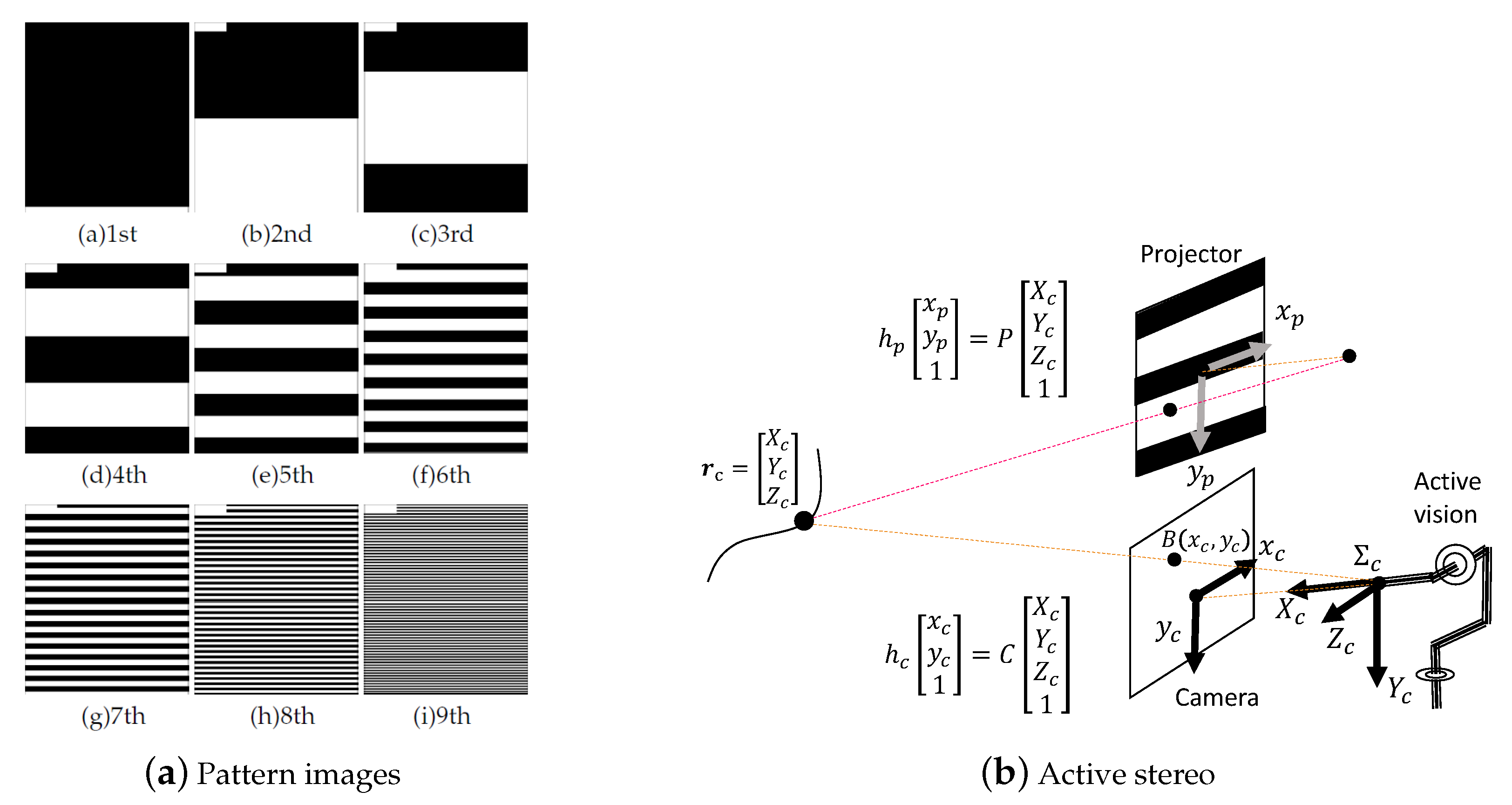
4.1. Spatial Coding
4.2. Stereo Calculation
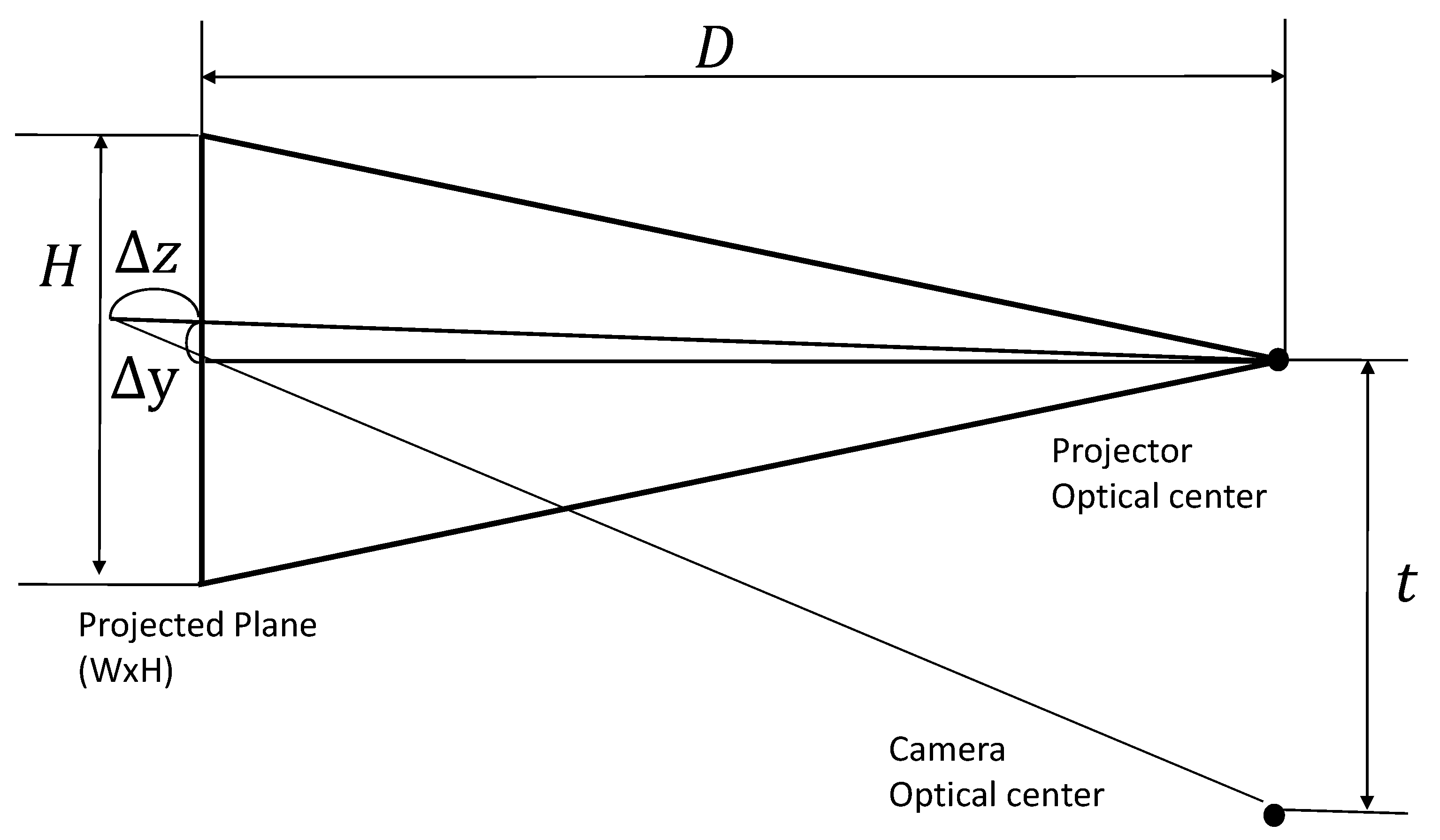
4.3. Accuracy of Measurement
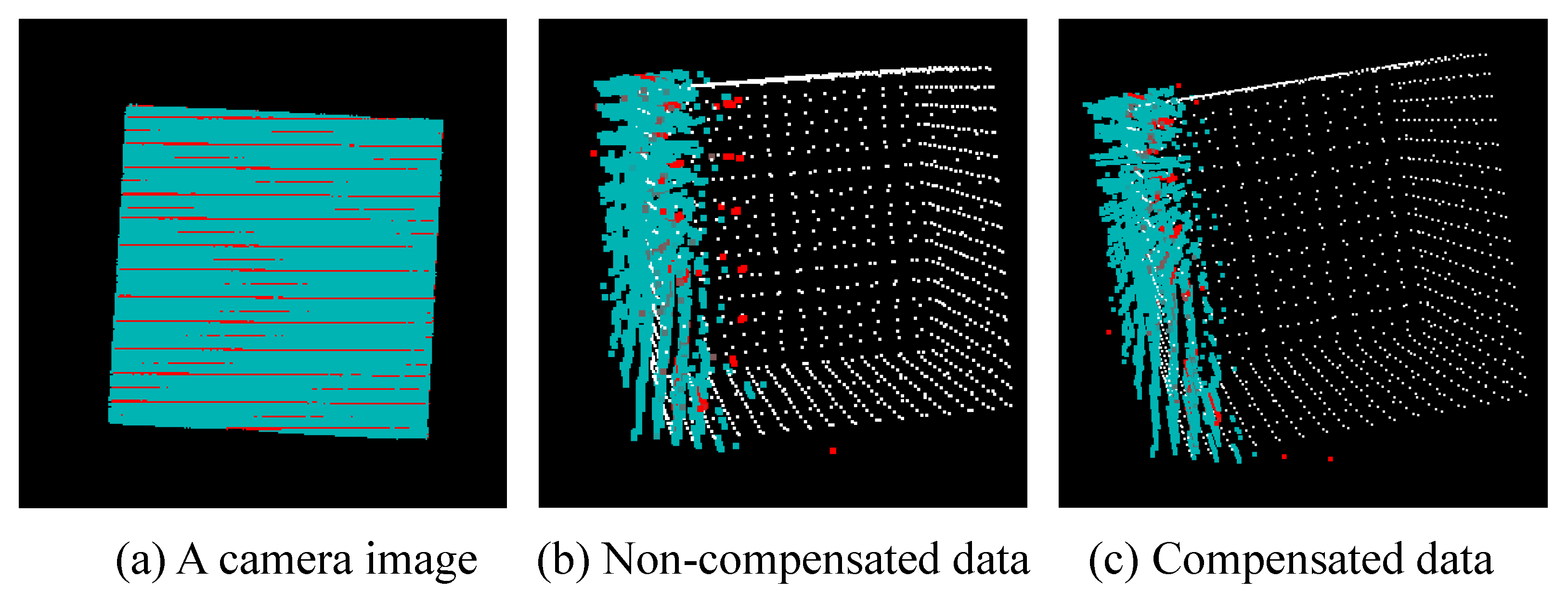
4.4. Correction of Spatial Code
| Algorithm 1: Correction of spatial code. |
| if is changed to or then |
| end if |
5. Visual Tracking
5.1. Image Moment for Tracking
5.2. Visual Servoing Control
6. Realtime Model Matching
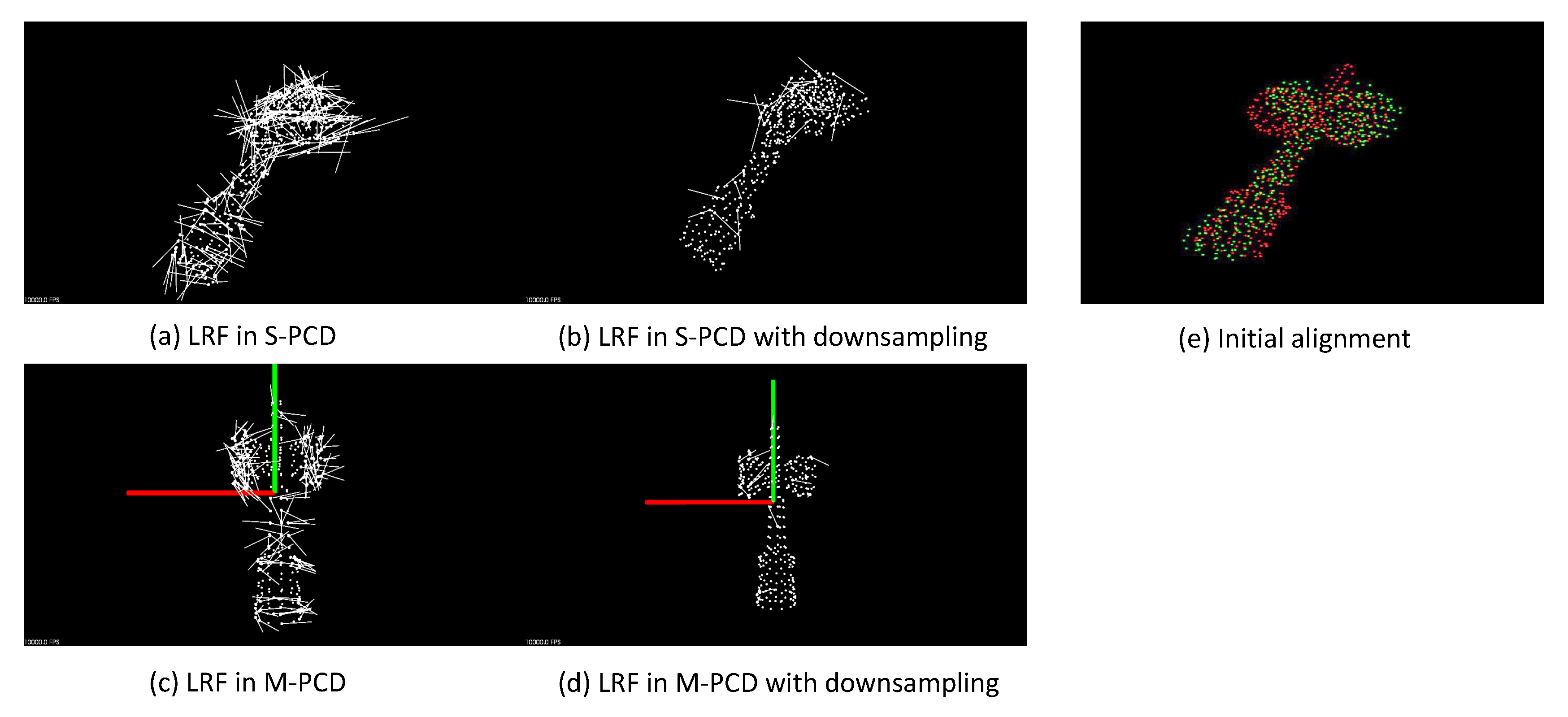
6.1. Initial Alignment
6.2. ICP Algorithm
6.3. Down-Sampling
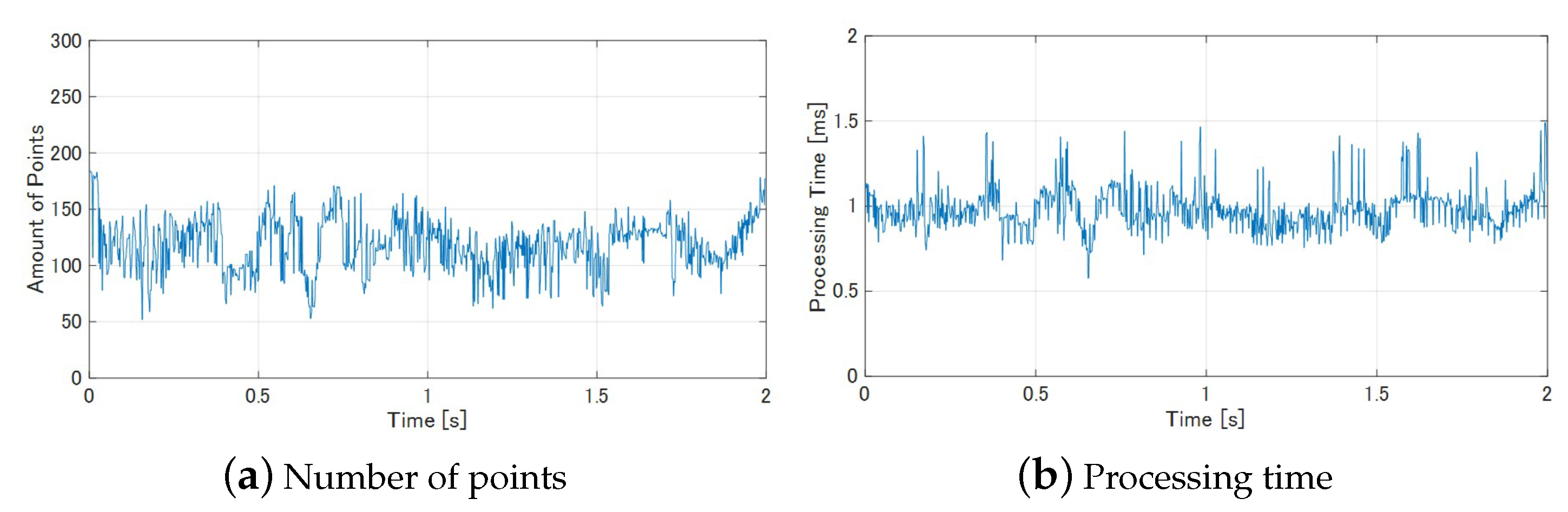
7. Experiment
7.1. High-Speed Depth Image Sensing
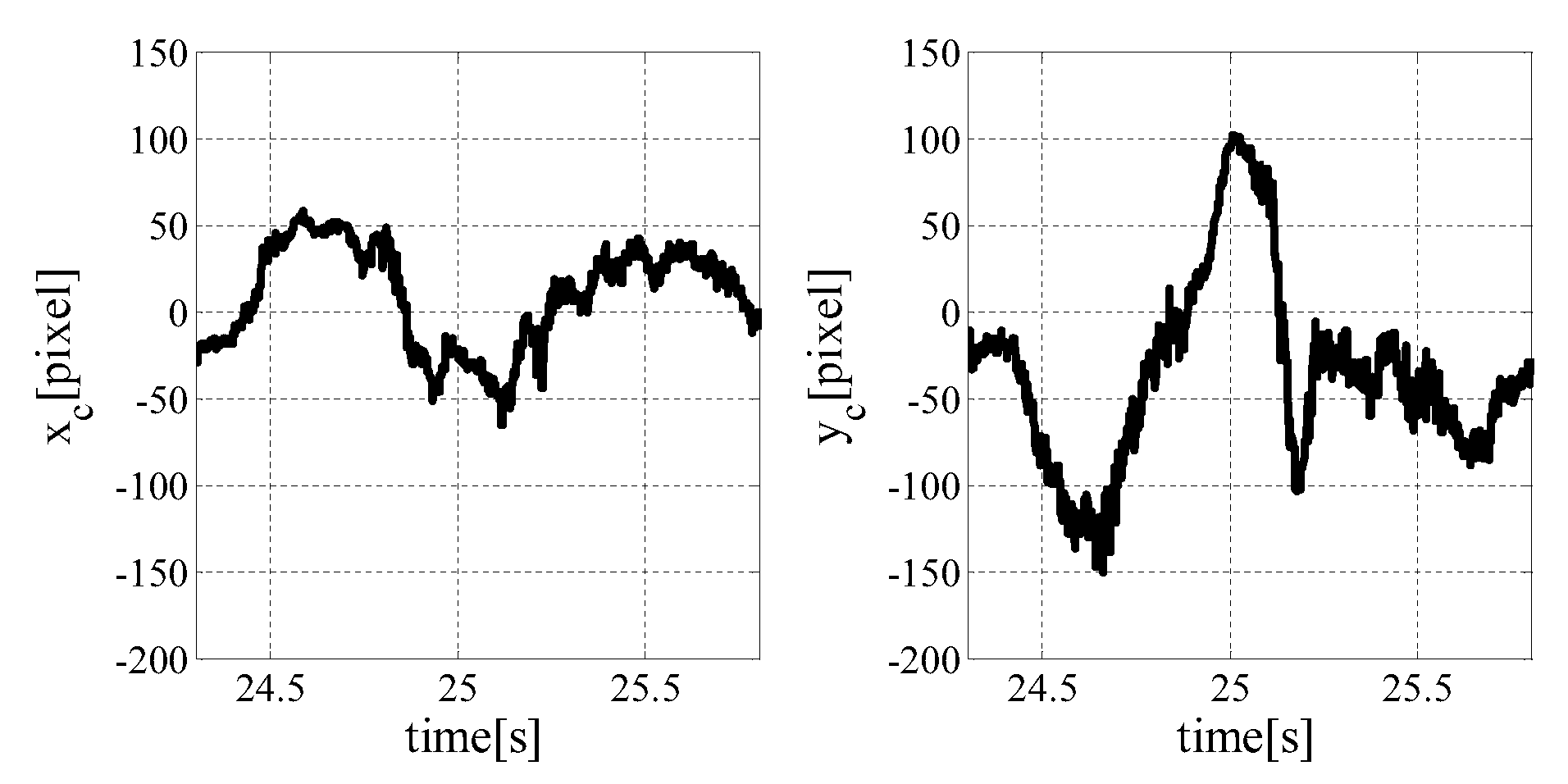
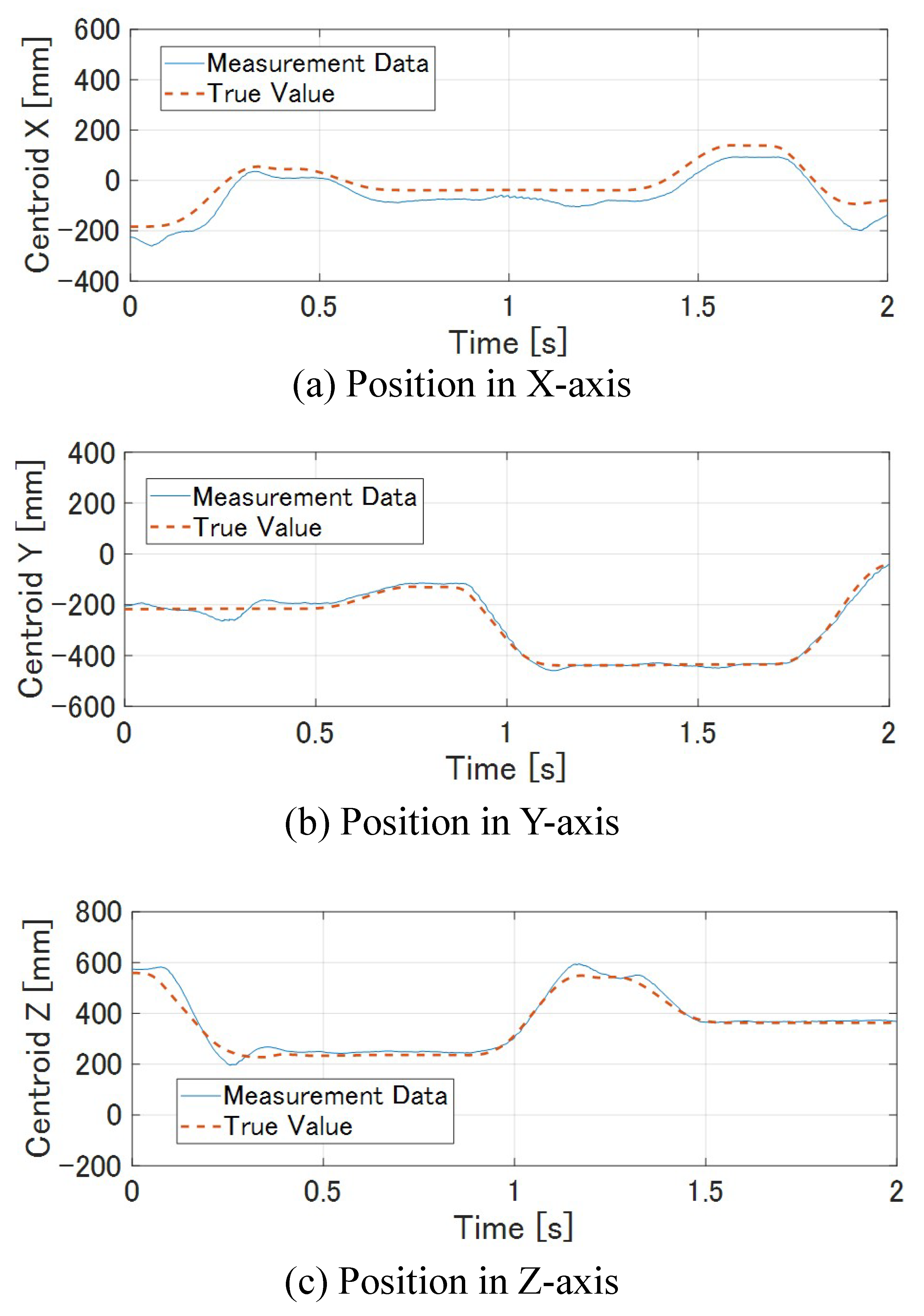
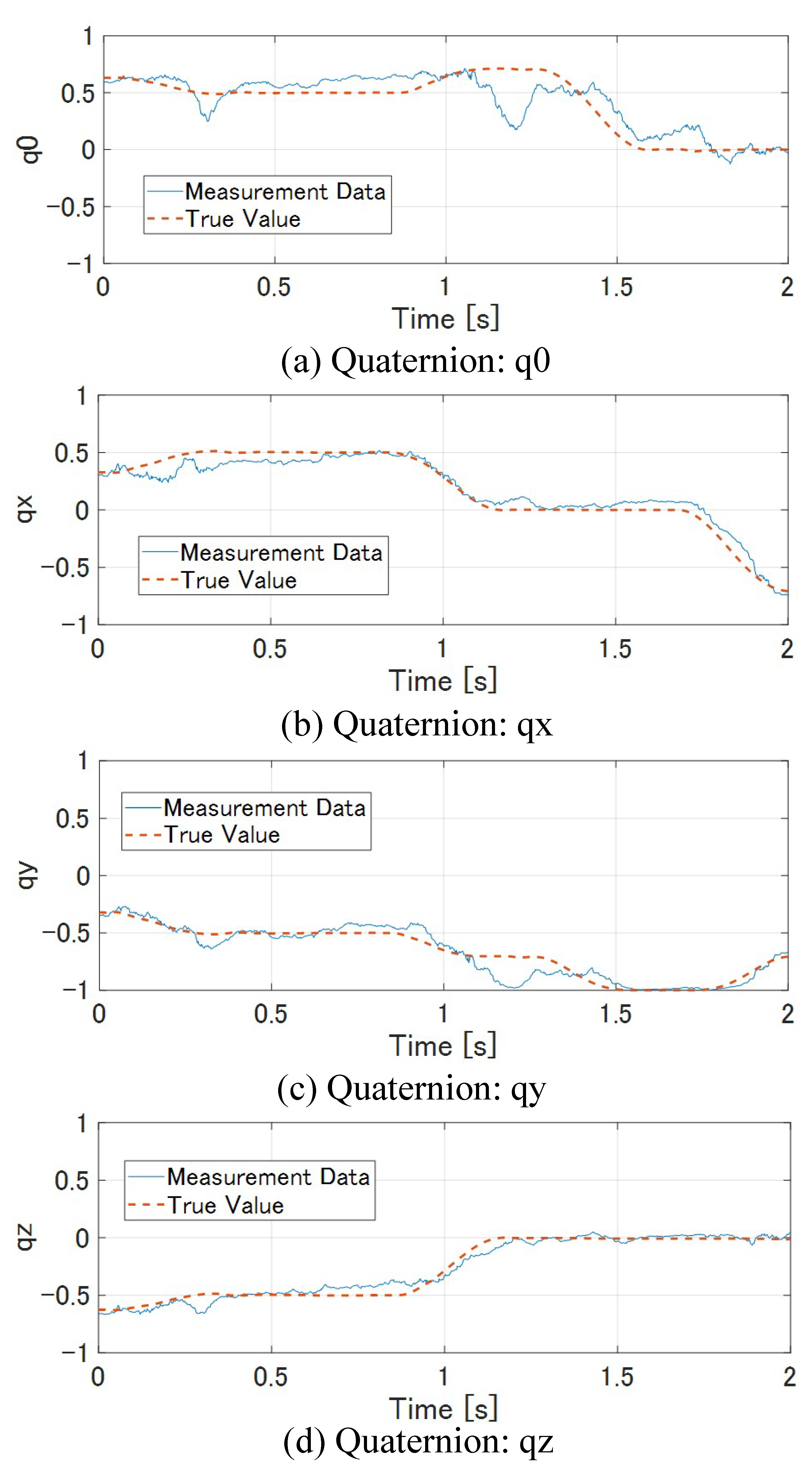
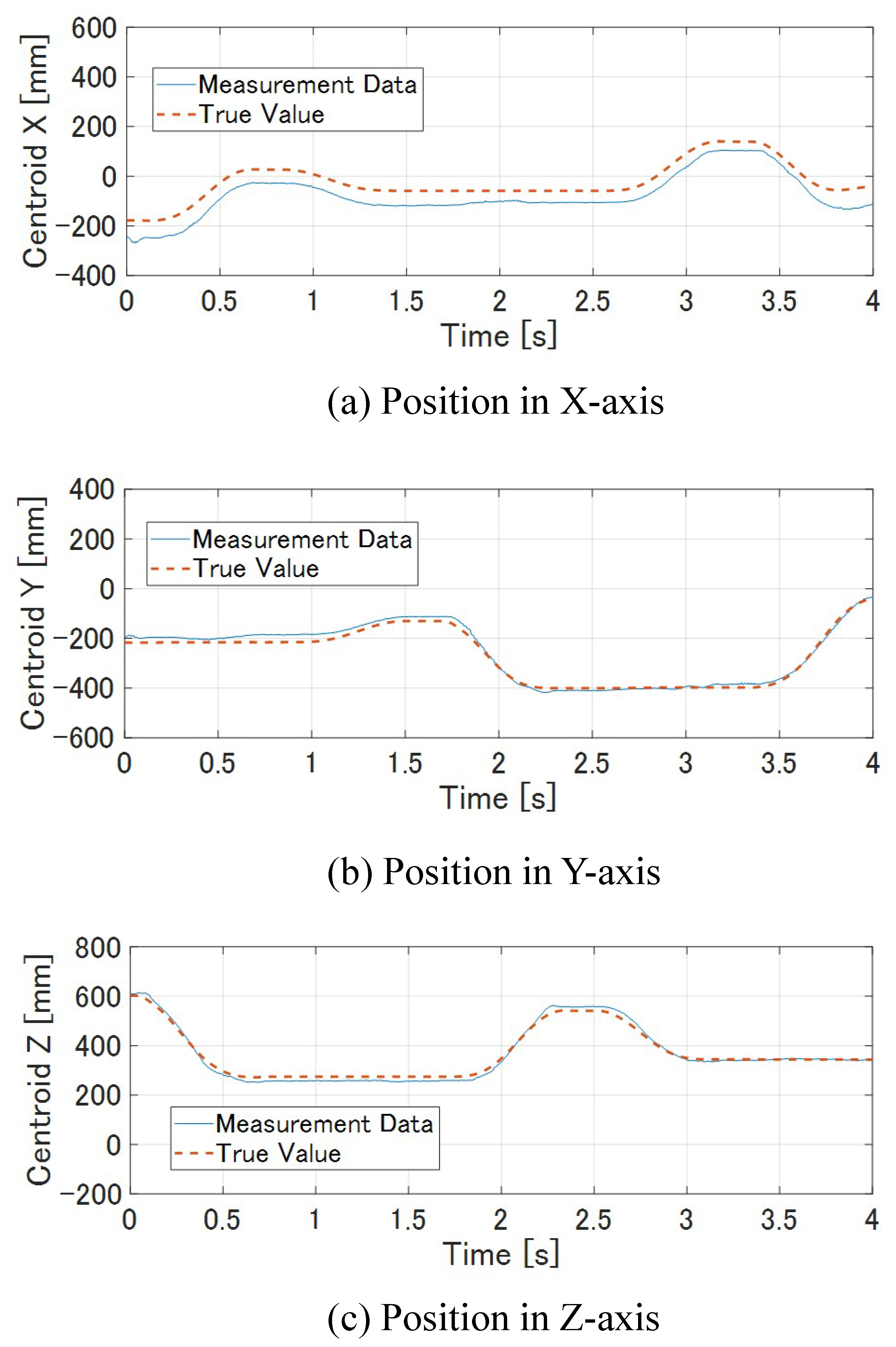
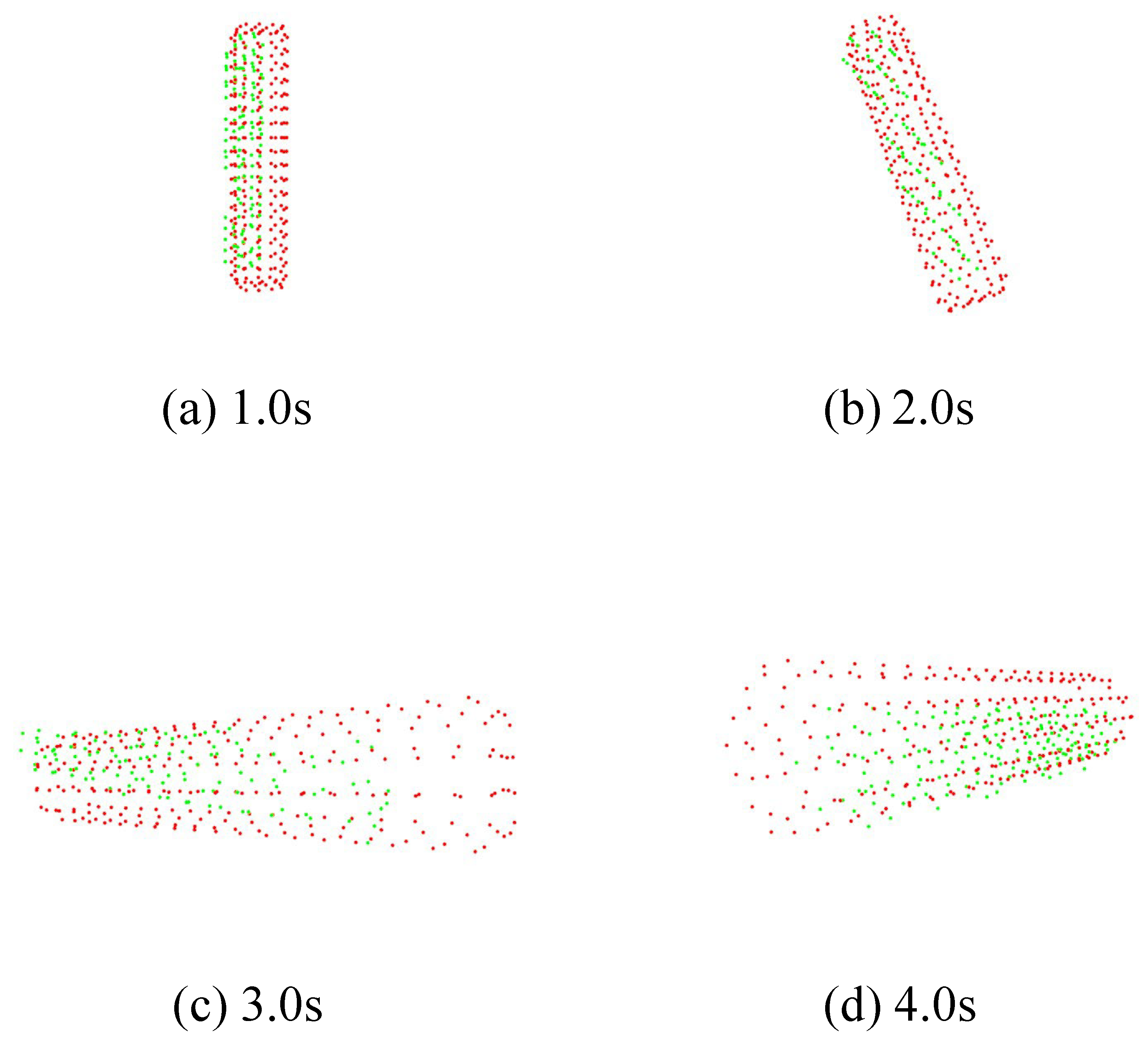
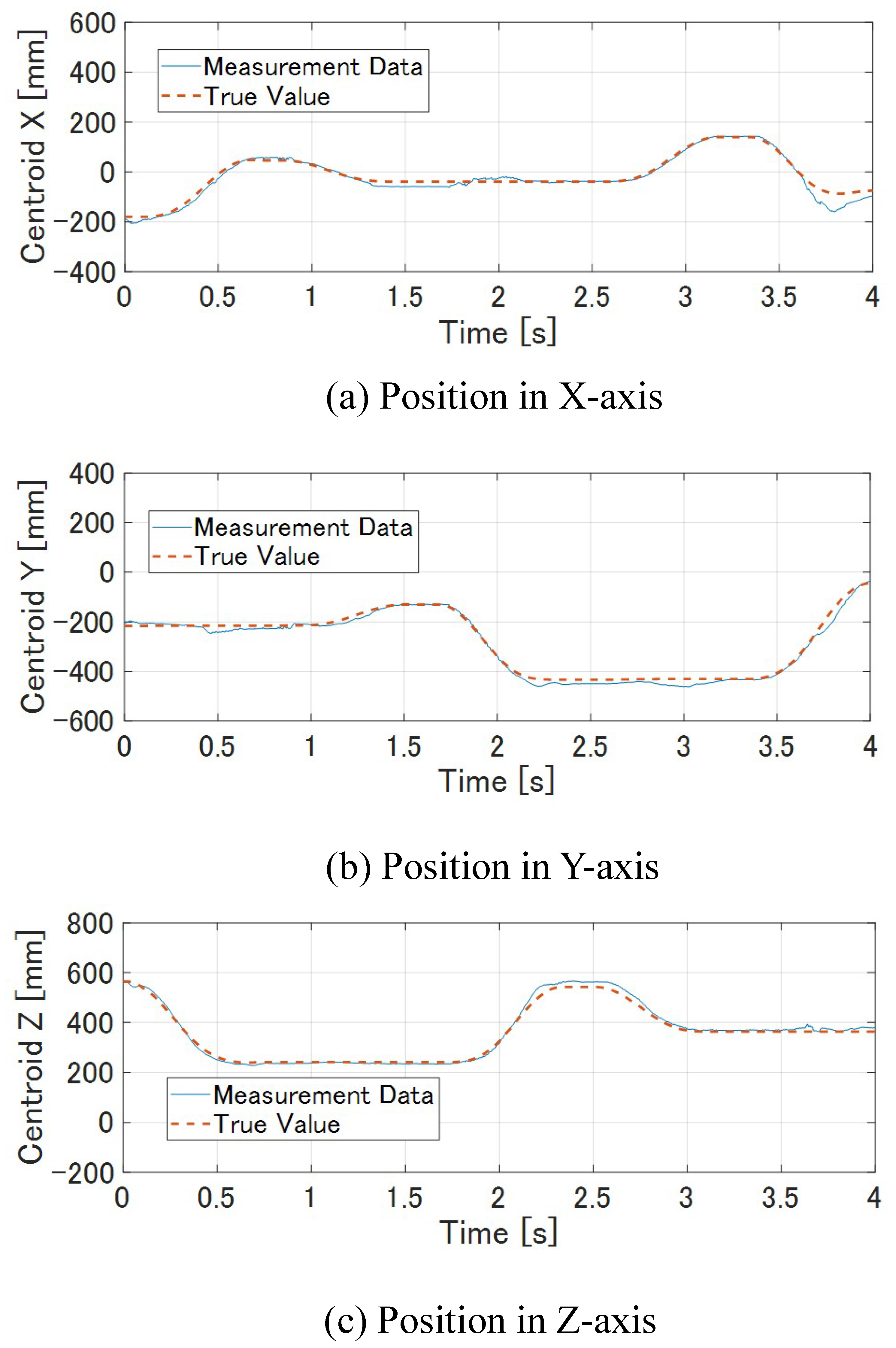
7.1.1. Result with Target Tracking Control
7.1.2. Result without Tracking Tracking Control
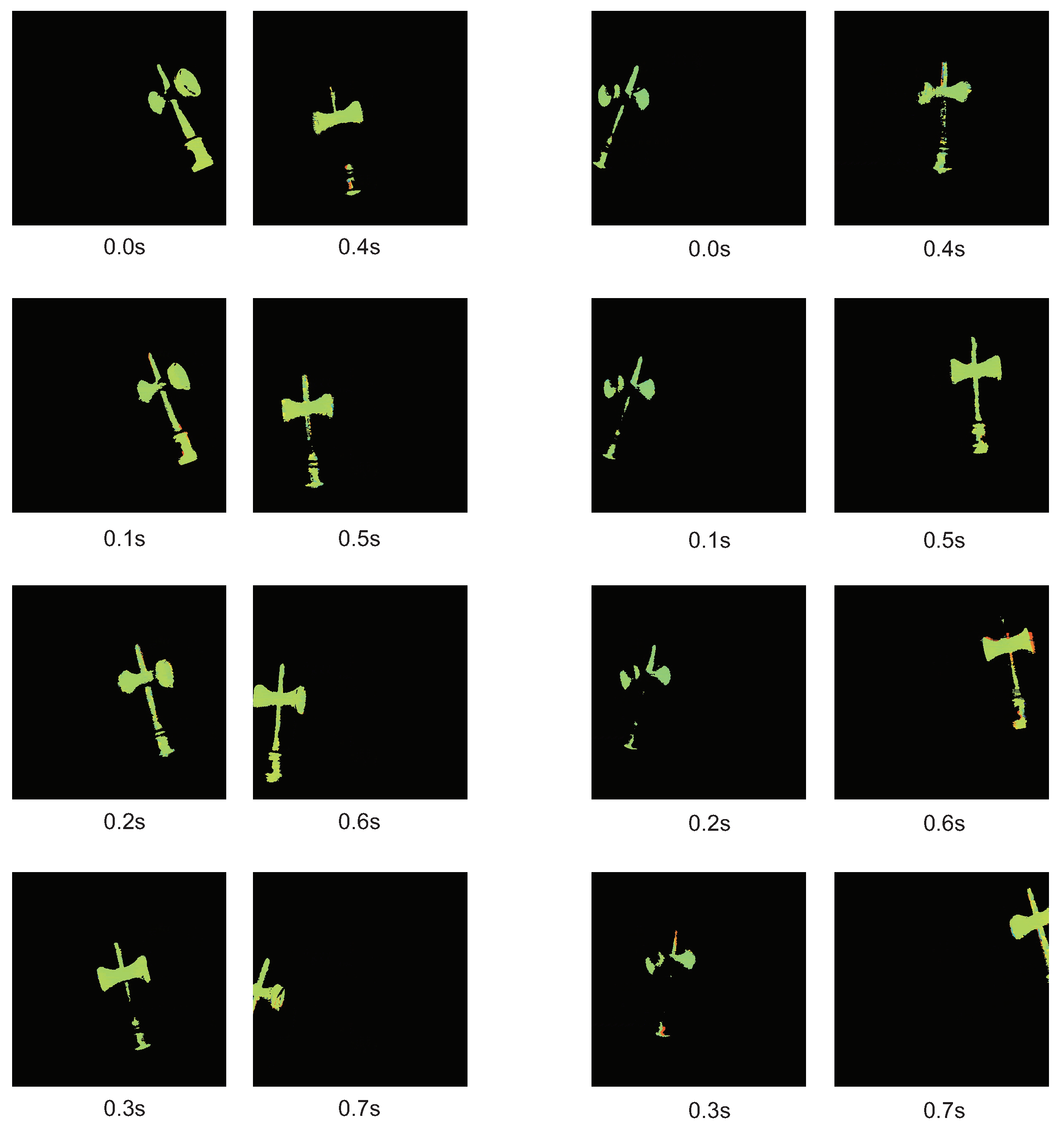
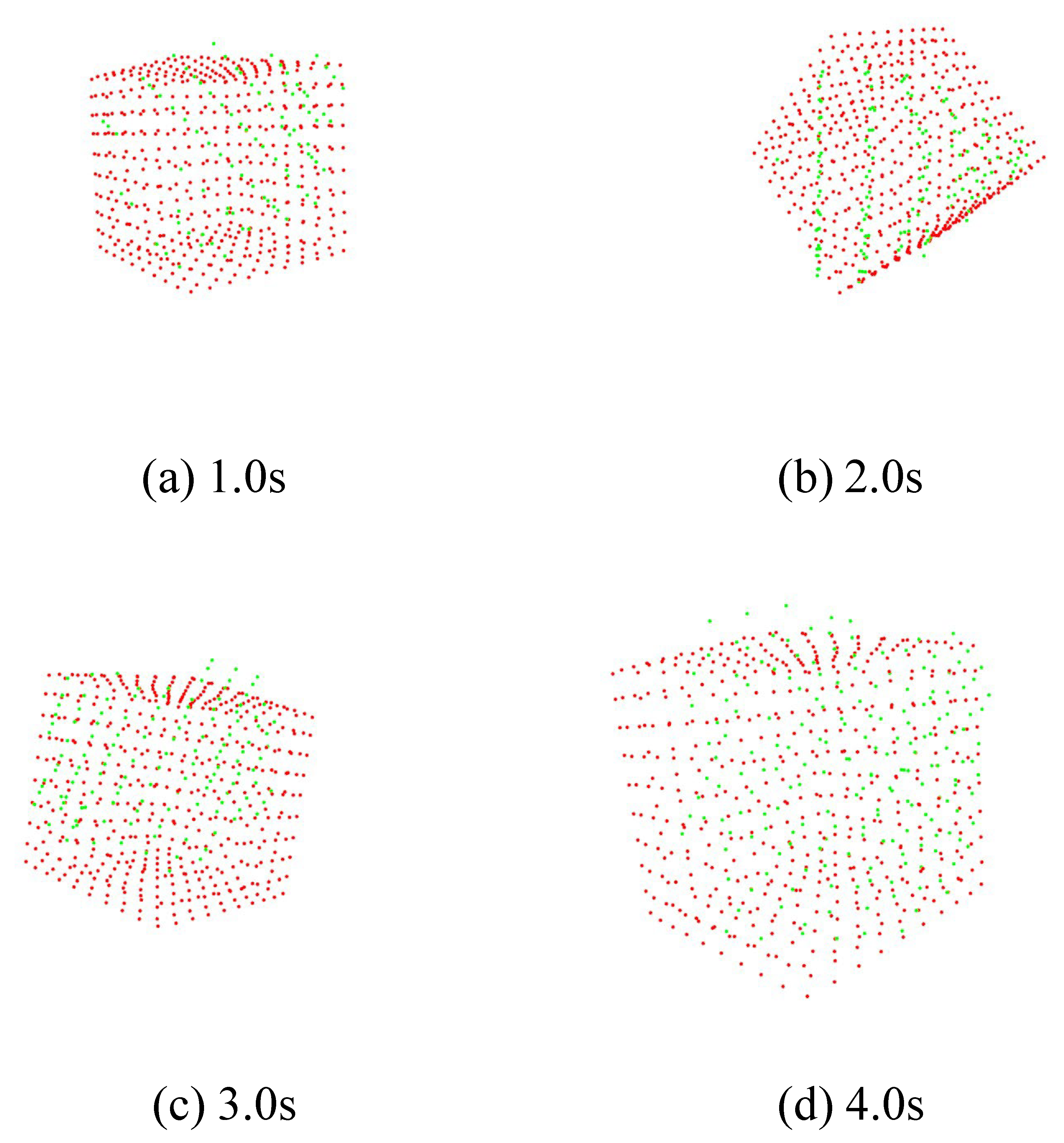
7.2. Model Matching
7.2.1. Ken
7.2.2. Cube
7.2.3. Cylinder
7.3. Verification of Correction of Spatial Code
7.4. Verification of Initial Alignment
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Posdamer, J.L.; Altschuler, M.D. Surface measurement by space-encoded projected beam systems. Comput. Graph. Image Process. 1982, 18, 1–17. [Google Scholar] [CrossRef]
- Nakabo, Y.; Ishii, I.; Ishikawa, M. 3-D tracking using two high-speed vision systems. In Proceedings of the 2002 IEEE/RSJ IEEE International Conference Intelligent Robots, Lausanne, Switzerland, 30 September–4 October 2002; pp. 360–365. [Google Scholar]
- Ishii, I.; Tatebe, T.; Gu, Q.; Moriue, Y.; Takaki, T.; Tajima, K. 2000 fps real-time vision system with high-frame-rate video recording. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–8 May 2010; pp. 1536–1541. [Google Scholar]
- Namiki, A.; Nakabo, Y.; Ishii, I.; Ishikawa, M. 1 ms Sensory-Motor Fusion System. IEEE Trans. Mech. 2000, 5, 244–252. [Google Scholar] [CrossRef]
- Ishikawa, M.; Namiki, A.; Senoo, T.; Yamakawa, Y. Ultra High-speed Robot Based on 1 kHz Vision System. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 5460–5461. [Google Scholar]
- Okumura, K.; Yokoyama, K.; Oku, H.; Ishikawa, M. 1 ms Auto Pan-Tilt-video shooting technology for objects in motion based on Saccade Mirror with background subtraction. Adv. Robot. 2015, 29, 457–468. [Google Scholar] [CrossRef]
- Gao, H.; Takaki, T.; Ishii, I. GPU-based real-time structured light 3-D scanner at 500 fps. Proc. SPIE 2012, 8437, 8437J. [Google Scholar]
- Shimada, K.; Namiki, A.; Ishii, I. High-Speed 3-D Measurement of a Moving Object with Visual Servo. In Proceedings of the IEEE/SICE International Symposium on System Integration, Sapporo, Japan, 13–15 December 2016; pp. 248–253. [Google Scholar]
- Kin, Y.; Shimada, K.; Namiki, A.; Ishii, I. High-speed Orientation Measurement of a Moving Object with Patterned Light Projection and Model Matching. In Proceedings of the 2018 IEEE Conference on Robotics and Biomimetics, Kuala Lumpur, Malaysia, 12–15 December 2018; pp. 1335–1340. [Google Scholar]
- Klank, U.; Pangercic, D.; Rusu, R.B.; Beetz, M. Real-time cad model matching for mobile manipulation and grasping. In Proceedings of the 9th IEEE-RAS International Conference on Humanoid Robots, Paris, France, 7–10 December 2009; pp. 290–296. [Google Scholar]
- Rao, D.; Le, Q.V.; Phoka, T.; Quigley, M.; Sudsang, A.; Ng, A.Y. Grasping novel objects with depth segmentation. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 2578–2585. [Google Scholar]
- Arai, S.; Harada, T.; Touhei, A.; Hashimoto, K. 3-D Measurement with High Accuracy and Robust Estimation for Bin Picking. J. Robot. Soc. Jpn. 2016, 34, 261–271. (In Japanese) [Google Scholar] [CrossRef]
- Salvi, J.; Fernandez, S.; Pribanic, T.; Llado, X. A state of the art in structured light patterns for surface profilometry. Pattern Recognit. 2010, 43, 2666–2680. [Google Scholar] [CrossRef]
- Geng, J. Structured-light 3-D surface imaging: A tutorial. Adv. Opt. Photonics 2011, 3, 128–160. [Google Scholar] [CrossRef]
- Watanabe, Y.; Komuro, T.; Ishikawa, M. 955-fps realtime shape measurement of a moving/deforming object using high-speed vision for numerous-point analysis. In Proceedings of the IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007. [Google Scholar]
- Tabata, S.; Noguchi, S.; Watanabe, Y.; Ishikawa, M. High-speed 3-D sensing with three-view geometry using a segmented pattern. In Proceedings of the IEEE/RSJ International Conference Intelligent Robots and Systems, Hamburg, Germany, 28 September–2 October 2015. [Google Scholar]
- Kawasaki, H.; Sagawa, R.; Furukawa, R. Dense One-shot 3-D Reconstruction by Detecting Continuous Regions with Parallel Line Projection. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Gupta, M.; Agrawal, A.; Veeraraghavan, A.; Narasimhan, S.G. A practical approach to 3-D scanning in the presence of interreflections, subsurface scattering and defocus. Int. J. Comput. Vis. 2013, 102, 33–55. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, S.; Oliver, J.H. 3-D shape measurement technique for multiple rapidly moving objects. Opt. Express 2011, 19, 8539–8545. [Google Scholar] [CrossRef] [PubMed]
- Okarma, K.; Grudzinski, M. The 3-D scanning system for the machine vision based positioning of workpieces on the CNC machine tools. In Proceedings of the IEEE 17th International Conference on Methods and Models in Automation and Robotics, Miedzyzdroje, Poland, 27–30 August 2012; pp. 85–90. [Google Scholar]
- Lohry, W.; Vincent, C.; Song, Z. Absolute three-dimensional shape measurement using coded fringe patterns without phase unwrapping or projector calibration. Opt. Express 2014, 22, 1287–1301. [Google Scholar] [CrossRef] [PubMed]
- Hyun, J.S.; Song, Z. Enhanced two-frequency phase-shifting method. Appl. Opt. 2016, 55, 4395–4401. [Google Scholar] [CrossRef] [PubMed]
- Cong, P.; Xiong, Z.; Zhang, Y.; Zhao, S.; Wu, F. Accurate dynamic 3-D sensing with fourier-assisted phase shifting. IEEE J. Sel. Top. Signal Process. 2015, 9, 396–408. [Google Scholar] [CrossRef]
- Li, B.; Liu, Z.; Zhang, S. Motion-induced error reduction by combining fourier transform profilometry with phaseshifting profilometry. Opt. Express 2016, 24, 23289–23303. [Google Scholar] [CrossRef] [PubMed]
- Maruyama, M.; Tabata, S.; Watanabe, Y.; Ishikawa, M. Multi-pattern embedded phase shifting using a high-speed projector for fast and accurate dynamic 3-D measurement. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 921–929. [Google Scholar]
- Hyun, J.S.; Chiu, G.T.C.; Zhang, S. High-speed and high-accuracy 3-D surface measurement using a mechanical projector. Opt. Express 2018, 26, 1474–1487. [Google Scholar] [CrossRef] [PubMed]
- Lohry, W.; Zhang, S. High-speed absolute three-dimensional shape measurement using three binary dithered patterns. Opt. Express 2014, 22, 26752–26762. [Google Scholar] [CrossRef] [PubMed]
- Ishii, I.; Koike, T.; Gao, H.; Takaki, T. Fast 3-D Shape Measurement Using Structured Light Projection for a One-directionally Moving Object. In Proceedings of the 37th Annual Conference on IEEE Industrial Electronics Society, Melbourne, Australia, 7–10 November 2011; pp. 135–140. [Google Scholar]
- Liu, Y.; Gao, H.; Gu, Q.; Aoyama, T.; Takaki, T.; Ishii, I. High-frame-rate structured light 3-D vision for fast moving objects. J. Robot. Mech. 2014, 26, 311–320. [Google Scholar] [CrossRef]
- Kizaki, T.; Namiki, A. Two ball juggling with high-speed hand-arm and high-speed vision system. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, St. Paul, MN, USA, 14–18 May 2012; pp. 1372–1377. [Google Scholar]
- Ito, N.; Namiki, A. Ball catching in kendama game by estimating grasp conditions based on a high-speed vision system and tactile sensors. In Proceedings of the 14th IEEE-RAS International Conference on Humanoid Robots, Madrid, Spain, 18–20 November 2014; pp. 634–639. [Google Scholar]
- Inokuchi, S.; Sato, K.; Matsuda, F. Range Imaging System for 3-D object recognition. In Proceedings of the International Conference on Pattern Recognition, Montreal, QC, Canada, 30 July–2 August 1984; pp. 806–808. [Google Scholar]
- Hutchinson, S.; Hager, G.D.; Corke, P.I. A tutorial on visual servo control. IEEE Trans. Robot. Autom. 1996, 12, 651–670. [Google Scholar] [CrossRef]
- Minowa, R.; Namiki, A. Real-time 3-D Recognition of a Manipulated Object by a Robot Hand Using a 3-D Sensor. In Proceedings of the 2015 IEEE Conference on Robotics and Biomimetics, Zhuhai, China, 6–9 December 2015; pp. 1798–1803. [Google Scholar]
- Xu, F.; Zhao, X.; Hagiwara, I. Research on High-Speed Automatic Registration Using Composite-Descriptor-Could-Points (CDCP) Model. JSME Pap. Collect. 2012, 78, 783–798. (In Japanese) [Google Scholar] [CrossRef]
- Akizuki, S.; Hashimoto, M. DPN-LRF: A Local Reference Frame for Robustly Handling Density Differences and Partial Occlusions. In Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 14–16 December 2015; pp. 878–887. [Google Scholar]
- Besl, P.J.; McKay, N.D. A Method for Registration of 3-D Shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Eggert, D.W.; Lorusso, A.; Fisher, R.B. Estimating 3-D rigid body transformations: A comparison of four major algorithms. Mach. Vis. Appl. 1997, 9, 272–290. [Google Scholar] [CrossRef]
- Active High-Speed 3-D Vision System, NamikiLaboratory Youtube Channel. Available online: https://www.youtube.com/watch?v=TIrA2qdJBe8 (accessed on 17 January 2019).






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resolution (pattern sequence mode) | |
| Pattern rate (pre-loaded) | 4225 Hz |
| Brightness | 150 lm |
| Throw ratio | |
| Focus range | 0.5–2 m |
| Image | 8-bit Monochrome |
|---|---|
| Resolution | |
| Frame rate | ∼2000 Hz |
| Image size | |
| Focal length | 6 mm |
| FOV |
| Pan | Tilt | |
|---|---|---|
| Type of servo motor | Yaskawa SGMAS-06A | Yaskawa SGMAS-01A |
| Rated output [] | 600 | 100 |
| Max torque [] | 5.73 | 0.9555 |
| Max speed [rpm] | 6000 | |
| Reduction ratio | 4.2 | |
| Digit | Gray Code |
|---|---|
| 0 | 0000 |
| 1 | 0001 |
| 2 | 0011 |
| 3 | 0010 |
| 4 | 0110 |
| 5 | 0111 |
| 6 | 0101 |
| 7 | 0100 |
| 8 | 1100 |
| 9 | 1101 |
| 10 | 1111 |
| 11 | 1110 |
| 12 | 1010 |
| 13 | 1011 |
| 14 | 1001 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Namiki, A.; Shimada, K.; Kin, Y.; Ishii, I. Development of an Active High-Speed 3-D Vision System. Sensors 2019, 19, 1572. https://doi.org/10.3390/s19071572
Namiki A, Shimada K, Kin Y, Ishii I. Development of an Active High-Speed 3-D Vision System. Sensors. 2019; 19(7):1572. https://doi.org/10.3390/s19071572
Chicago/Turabian StyleNamiki, Akio, Keitaro Shimada, Yusuke Kin, and Idaku Ishii. 2019. "Development of an Active High-Speed 3-D Vision System" Sensors 19, no. 7: 1572. https://doi.org/10.3390/s19071572
APA StyleNamiki, A., Shimada, K., Kin, Y., & Ishii, I. (2019). Development of an Active High-Speed 3-D Vision System. Sensors, 19(7), 1572. https://doi.org/10.3390/s19071572