1. Introduction
In the field of face recognition, many different dimensional recognition approaches have been developed in recent times [
1,
2,
3]. Dimensionality reduction is a main problem in numerous recognition techniques, caused by the great amount of data with high dimensions in many real-world utilizations [
4,
5,
6]. In fact, dimensionality reduction techniques have been recommended by researchers to avoid “the cure of dimensionality,” so as to amend the computational efficiency of image recognition [
7,
8]. Generally, dimensionality reduction techniques can be classified into two main groups: i.e., linear and nonlinear. In linear methods, a significant low-dimensional subspace is intended to be discovered in the input data with high-dimensional space, where the embedded data in the input space has a linear structure [
9,
10,
11,
12]. Principle component analysis (PCA) is one of the most famous linear methods [
13,
14,
15]. PCA aims to retain global geometric information for data representation through enhancing the trace of the feature covariance matrix [
13,
16,
17]. Linear discriminant analysis (LDA) is a linear technique that seeks to find out the discriminant information for data classification by enhancing the ratio between inter-class and intra-class scatters [
16,
18]. Some of the limitations of both PCA and LDA are that they could suffer from the small sample size (SSS) [
15] issue, and that they may fail to recognize many important data structures that are nonlinear [
19,
20].
Scholars have developed abundant practical nonlinear dimensionality reduction strategies [
21] to address these problems. They can be classified into two types: manifold-learning-based and kernel-based techniques [
22,
23]. Manifold learning directly aims to discover principal nonlinear data with low-dimensional structures that are concealed in the input space. Isometric feature mapping (ISOMAP) [
24,
25] and local linear embedding (LLE) [
26,
27] are the most well-known manifold-learning-based techniques to find inherent low-dimensional embedding of data [
28]. Based on some experiments carried out using these techniques, it is illustrated that these methods can discover meaningful embedded nonlinear data structures for face images adequately.
However, manifold-learning-based techniques could suffer from two issues in terms of pattern recognition [
15]. The first one is called “overlearning of locality,” [
29] since manifold learning keeps locality data structures but there is no straight connection with classification. Out-of-sample is another issue that shows why most manifold-learning-based techniques are not appropriate for image recognition tasks [
30,
31]. These techniques can yield an embedding directly from a training data set, but they are often not able to find the sample’s image in the embedding space when it is implemented to a new point. These problems cannot be overcome by the currently proposed manifold learning methods. Although a few supervised forms have been proposed, they still suffer from these problems [
30,
31,
32] because they are all founded based on “locality” characterization. The local quantity is sufficient for one manifold modeling, but it does not work well for classification tasks in multi-manifold modeling [
17].
In contrast to manifold-learning-based techniques and in order to indirectly represent observed patterns into possibly much larger dimensional feature vectors, kernel-based techniques have been proposed by applying a kernelized nonlinear representation method. In this approach, the nonlinear data structure can be more separable in the observation space and become linear in the feature space. The representative strategies include kernel Fisher discriminant (KFD) [
23,
33] and kernel principal component analysis (KPCA) [
34,
35]. Both have shown that they can be practical in many real-world functions, such as face recognition, to preserve the nonlinear data structure [
36]. However, these kernel-based methods cannot directly consider the local data structure, which results in classification performance degradation.
Recently, the locality preserving projections (LPP) method has been proposed as a linear subspace learning method to address the out-of-sample problem [
37]. LPP is an unsupervised linear subspace technique that has the remarkable advantage of being able to generate an explicit map. Similar to the one belonging to PCA and LDA, this map is linear and easy to compute, and is also effective for many face recognition tasks. Although LPP is designed based on “locality,” like most manifold learning methods, it still suffers from the “over learning of locality” problem, because there is no direct connection with classification in its algorithm. Therefore, on some occasions, it cannot be guaranteed to map an appropriate projection for classification purposes [
37].
Subsequently, in order to address this issue and delve into more influential projections for classification tasks, the unsupervised discriminant projection (UDP) method was developed as a simple version of LPP [
38]. UDP is considered a linear estimation of multi-manifold-based learning because it considers both the local and nonlocal scatters of data. In both LPP and UDP, the data class label information is not considered, which may degrade their pattern classification performance. Furthermore, the discriminant neighborhood embedding (DNE) method has been presented with the idea of using data class label information [
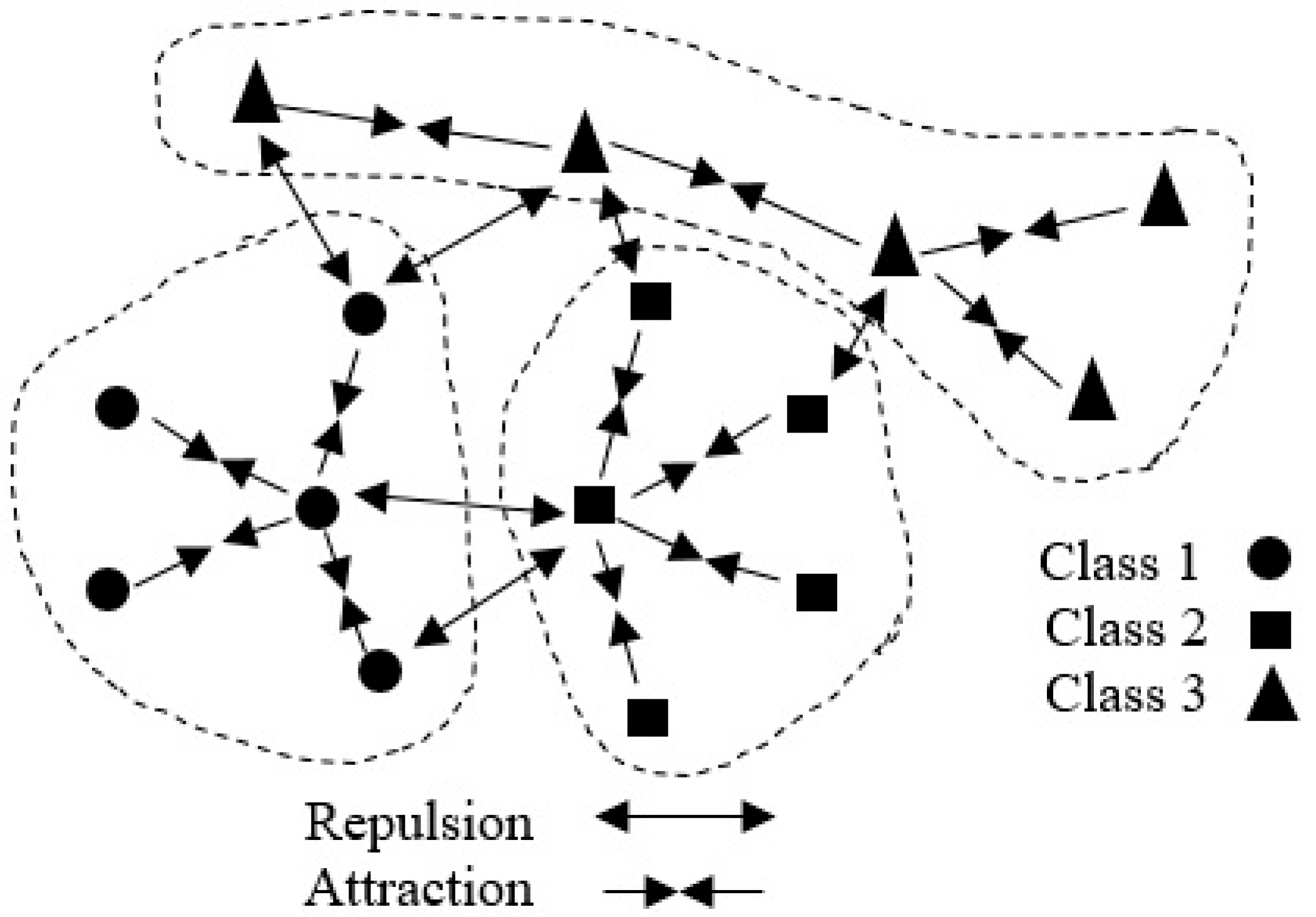
39]. DNE can find a good embedding for classification, considering intra-class absorption and inter-class class expulsion. The main characteristic of DNE is called “discrimination,” meaning the ability to distinguish the same class from distinct classes. This specification of DNE can deal well with “out-of-sample” and “small training sample size” problems. Nevertheless, DNE cannot correctly preserve local information of data because it only concedes +1 and −1 to intra-class and inter-class neighbors [
15]. Thus, much of the important geometrical structure information of data may be lost, and it might fail to find out the most significant sub-manifolds for pattern recognition. The locality-based discriminant neighborhood embedding method (LDNE) has recently been proposed to tackle the problems existing in LPP and DNE [
15]. This method takes into account both the “locality” and the “discrimination” in a united modelling environment. However, many important non-linear data might be lost during the dimensionality reduction process, which dramatically influences classification accuracy.
According to the way dimensionality reduction algorithms “learn” from data to create predictions, they can be categorized into two different classes: supervised and unsupervised learning methods. Among these two, supervised machine learning is used more prevalently. In this case, the data scholar acts as a guide to instruct the algorithm regarding which results should be found by it [
40]. The most well-known supervised algorithms include supervised LPP [
39], local discriminant embedding (LDE) [
41], neighborhood discriminant projection (NDP) [
42], discriminant locality preserving projections (DLPP) [
43], locally discriminating projection (LDP) [
44], and geometry preserving projections (GPP) [
45] It is clear that the aforementioned supervised techniques generally apply class label information in order to amend the dimensionality reduction. On the other hand, the unsupervised LPP-based algorithms generally aim to improve the locality preserving and discriminating capabilities to further enhance the final performance of the classification process. Graph-optimized locality preserving projections (GOLPP) [
15,
46], orthogonal locality preserving projection (OLPP) [
47], and UDP [
38] are some examples of the unsupervised LPP-based methods.
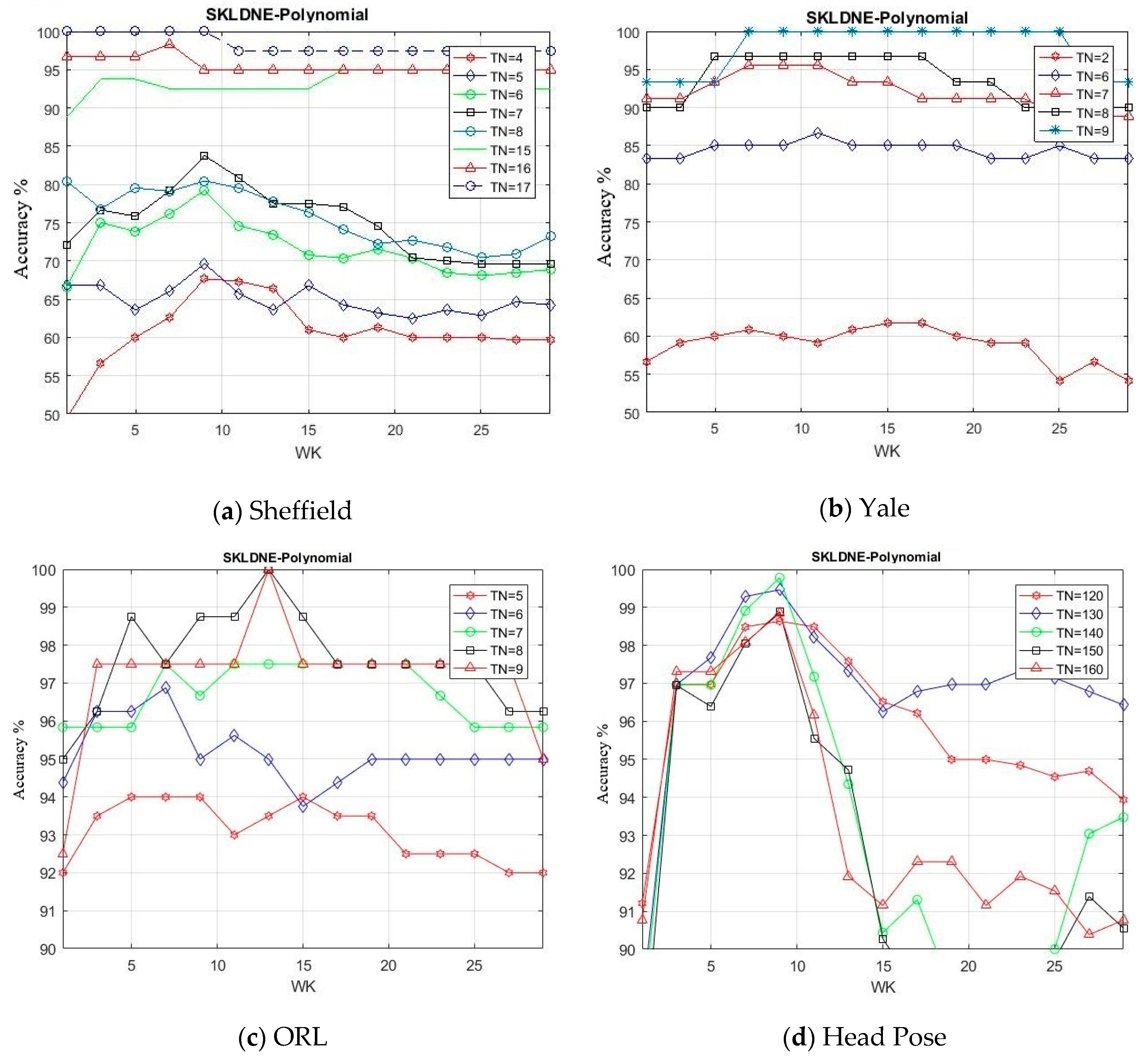
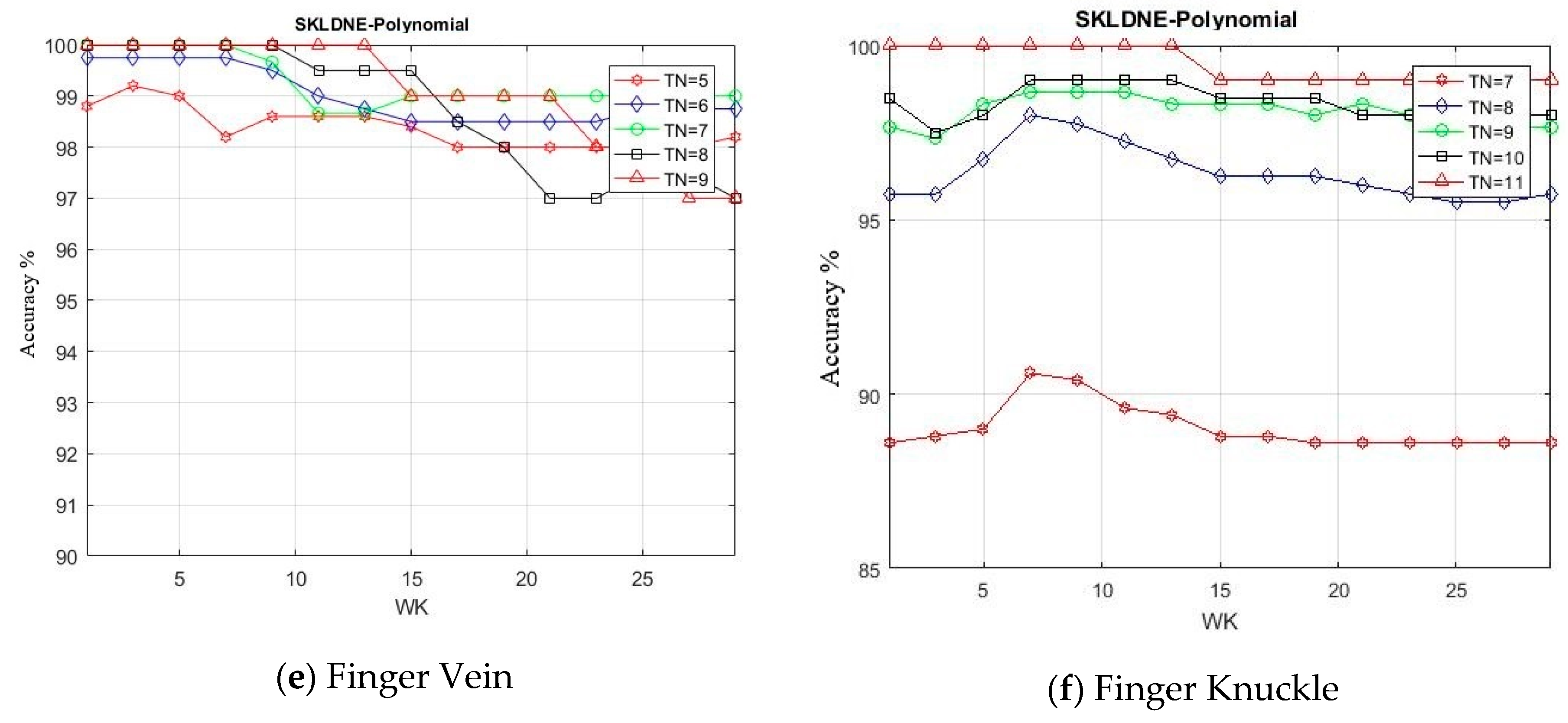
In this project, a new supervised subspace learning algorithm named “supervised kernel locality-based discriminant neighborhood embedding” (SKLDNE) is proposed. In this approach, not only can the nonlinear data structure be preserved by applying a kernelized nonlinear mapping method, but also both “locality” and “discrimination” of data in an integrated modeling environment are considered simultaneously. It should be noted that this technique is supervised through direct connection with classification in order to properly guide the procedure of dimensionality reduction. In order to have a reliable and powerful comparison, the efficiency of the proposed SKLDNE technique was compared with PCA, KPCA, LDA, UDP, LPP, DNE, and LDNE by a broad range of experiments with different publicly available face datasets, i.e., Yale face, Olivetti Research Laboratory (ORL) face, Head Pose, and Sheffield. Moreover, Finger Vein and Finger Knuckle databases were also applied to investigate the implementation of our algorithm in other types of databases rather than faces.
It is worthwhile to highlight several characteristics of the proposed approach here:
- (1)
SKLDNE has been successfully designed to retain local geometric relations of the within-class samples, which are very important for image recognition. Generally, the categorization strength of methods with a linear learning algorithm is restricted. They fail to deal with complicated problems. Many effective nonlinear data features may be lost during the classification progress using linear techniques such as LDNE, LDA, DNE, and LPP. Therefore, applying a nonlinear method can effectively improve the classification performance.
- (2)
This technique is a supervised learning method, as the data scholar acts as a guide to instruct the main algorithm whose conclusion should be found. SKLDNE considers class label information of neighbors in which there is a direct connection with classification, in order to enhance final recognition performance.
- (3)
It benefits from the advantages of “locality” in LPP in which, due to the prior class-label information, geometric relations are preserved.
- (4)
Not only can it build a compact submanifold by minimizing the distance between the same points in the same class, but it also expands the gaps among submanifolds of distinct classes simultaneously, which is called “discrimination.”
- (5)
SKLDNE can resolve the SSS problem that is mostly faced by other aforementioned techniques such as PCA, LDA, UDP, and LPP, and the “overlearning of locality” problem in the manifold learning.
- (6)
Due to its kernel weighting, it is very efficient in reducing the negative influence of the outliers on the projection directions, which effectively handles the drawbacks of linear models and makes it more robust to outliers.
The rest of this study is organized as follows:
Section 2 categorizes LPP, DNE, and LDNE.
Section 3 is devoted to describing the proposed SKLDNE method and the pertinent algorithm and mathematics.
Section 4 focuses on the experiments and analyses carried out.
Section 5 elucidates conclusions and future research.
5. Conclusions and Future Research
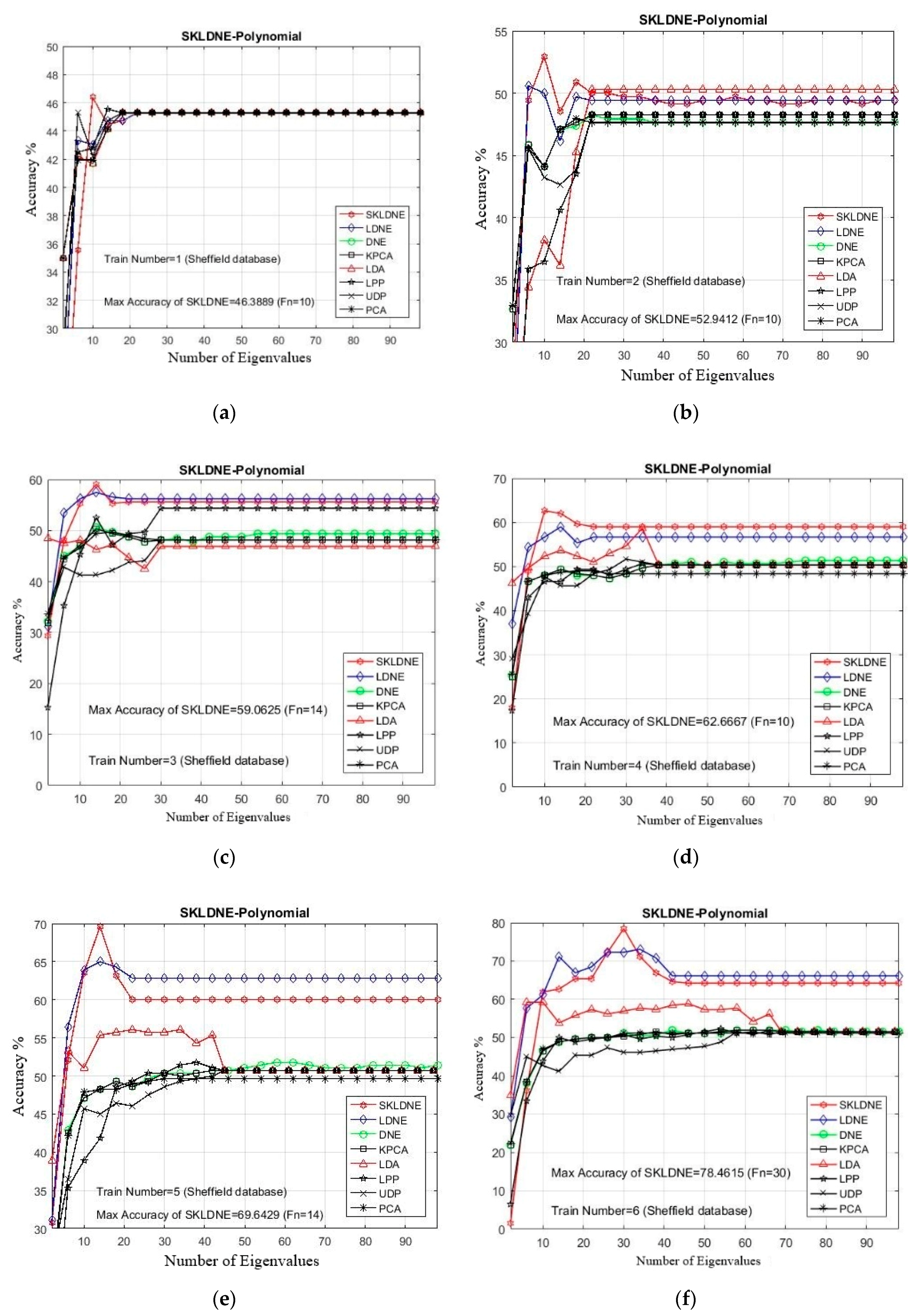
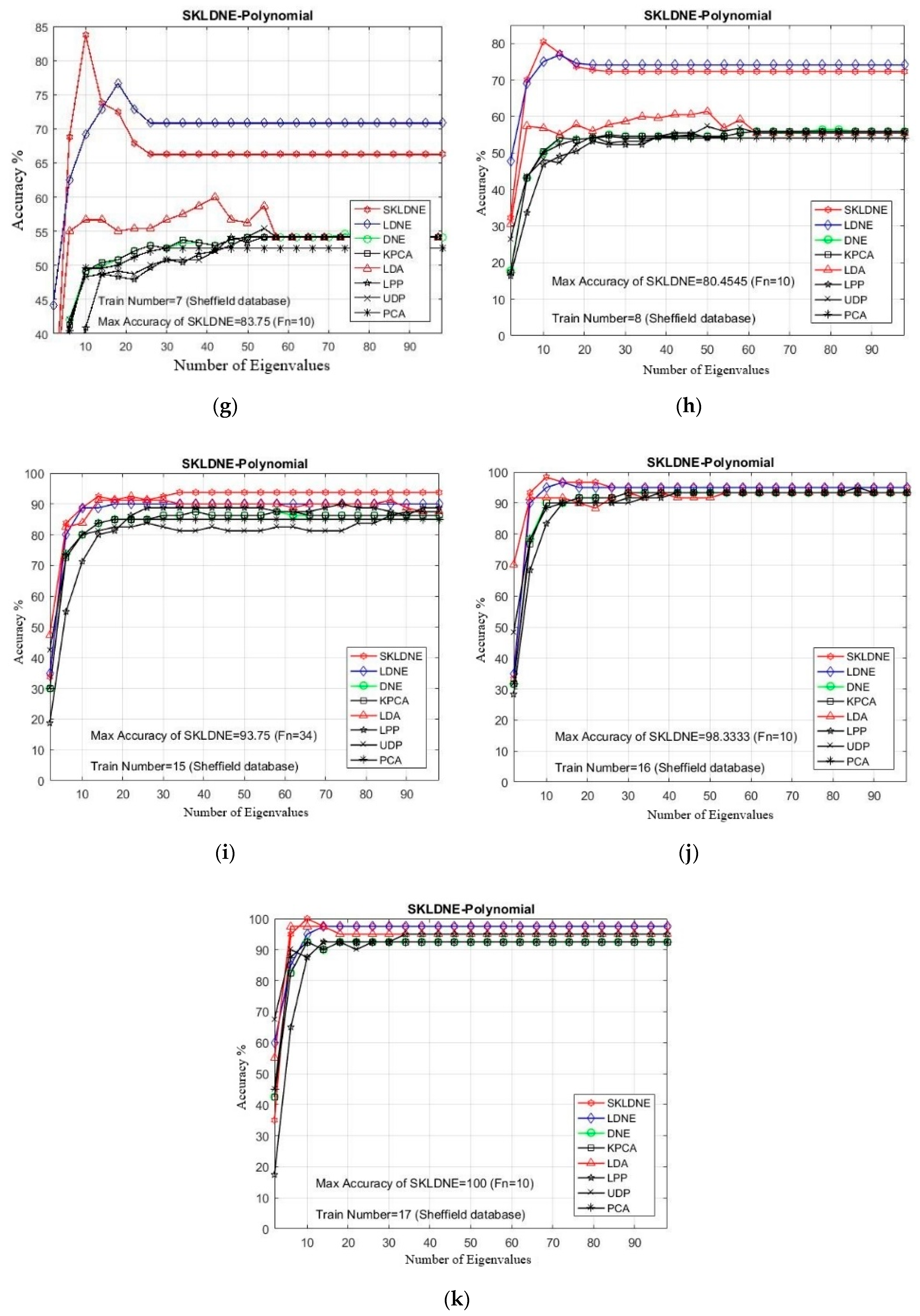
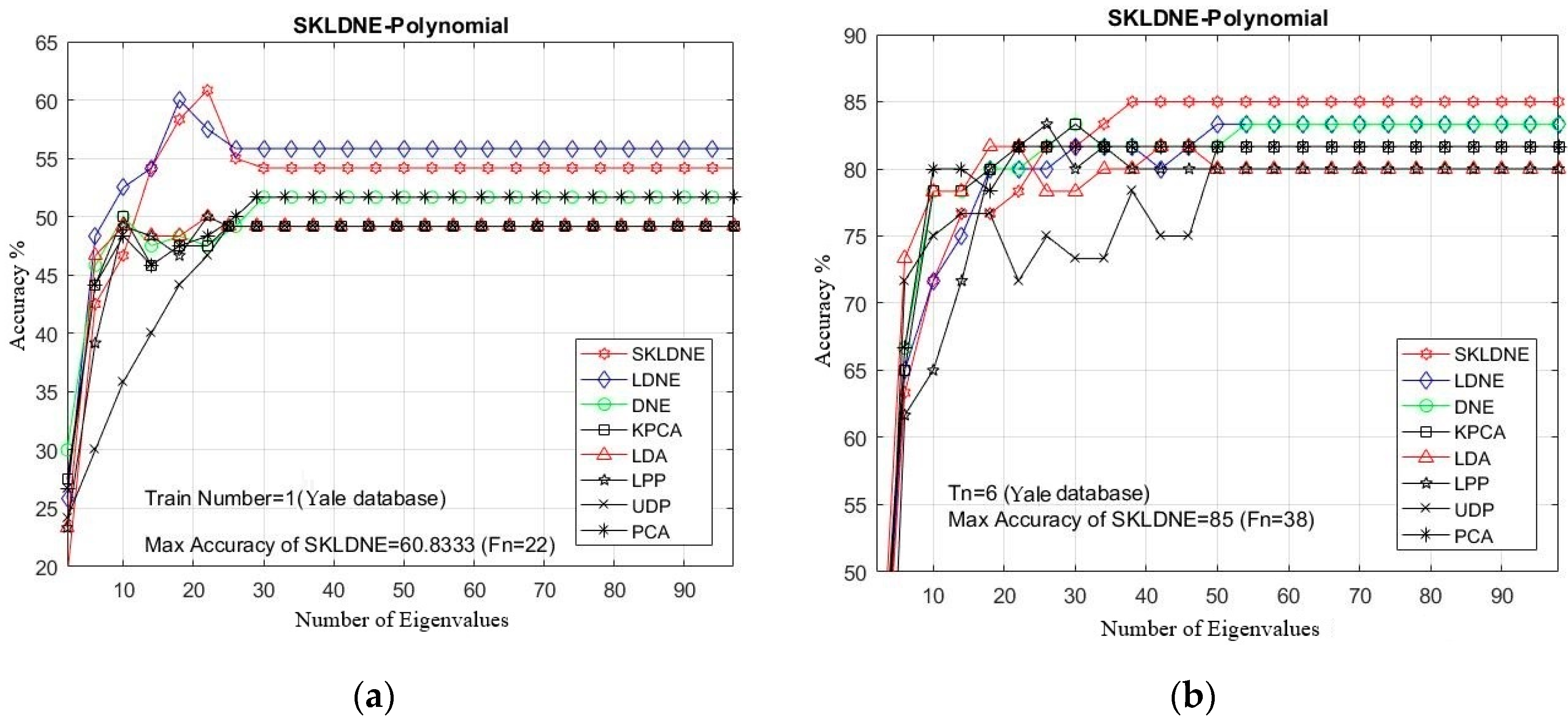
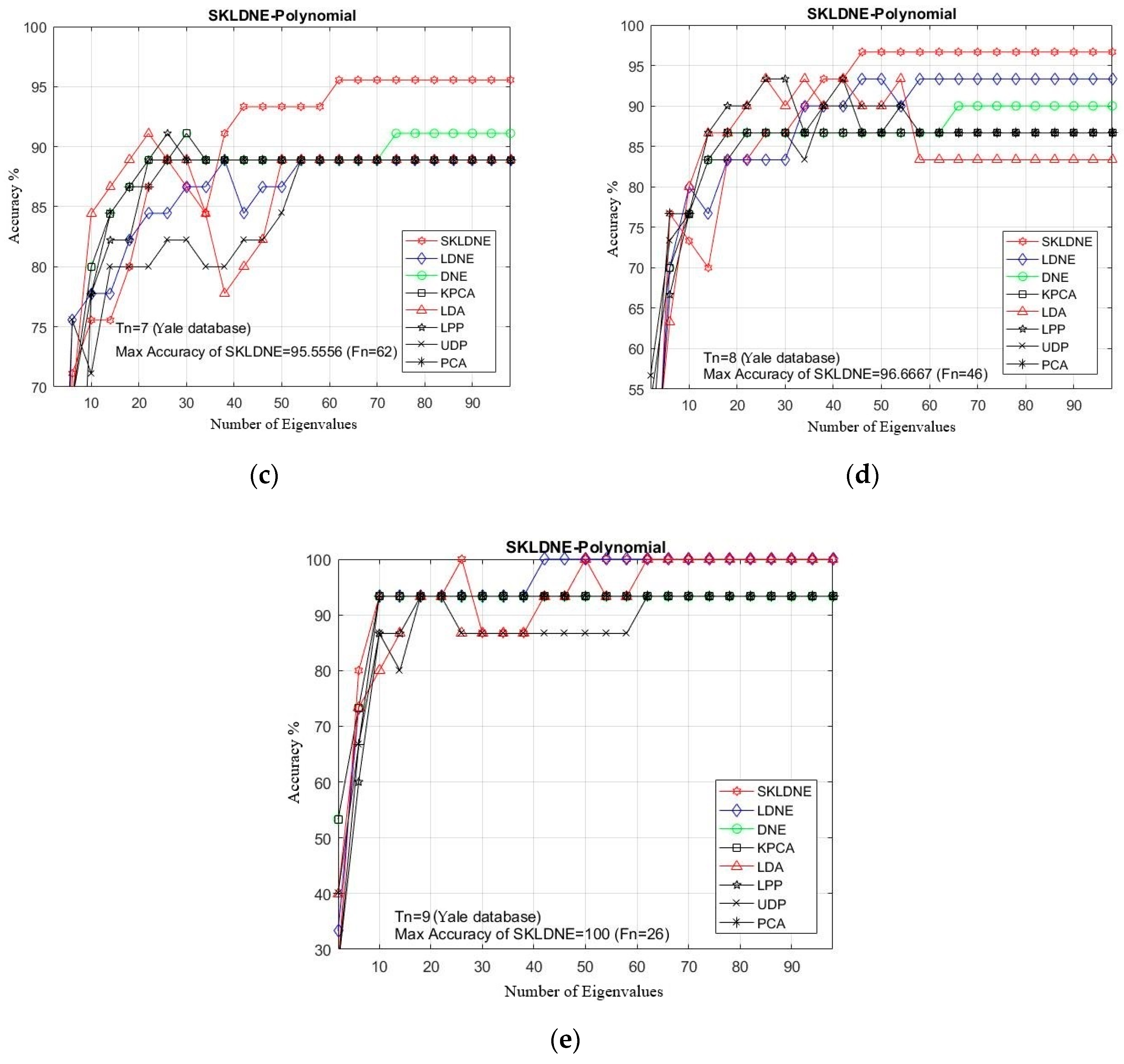
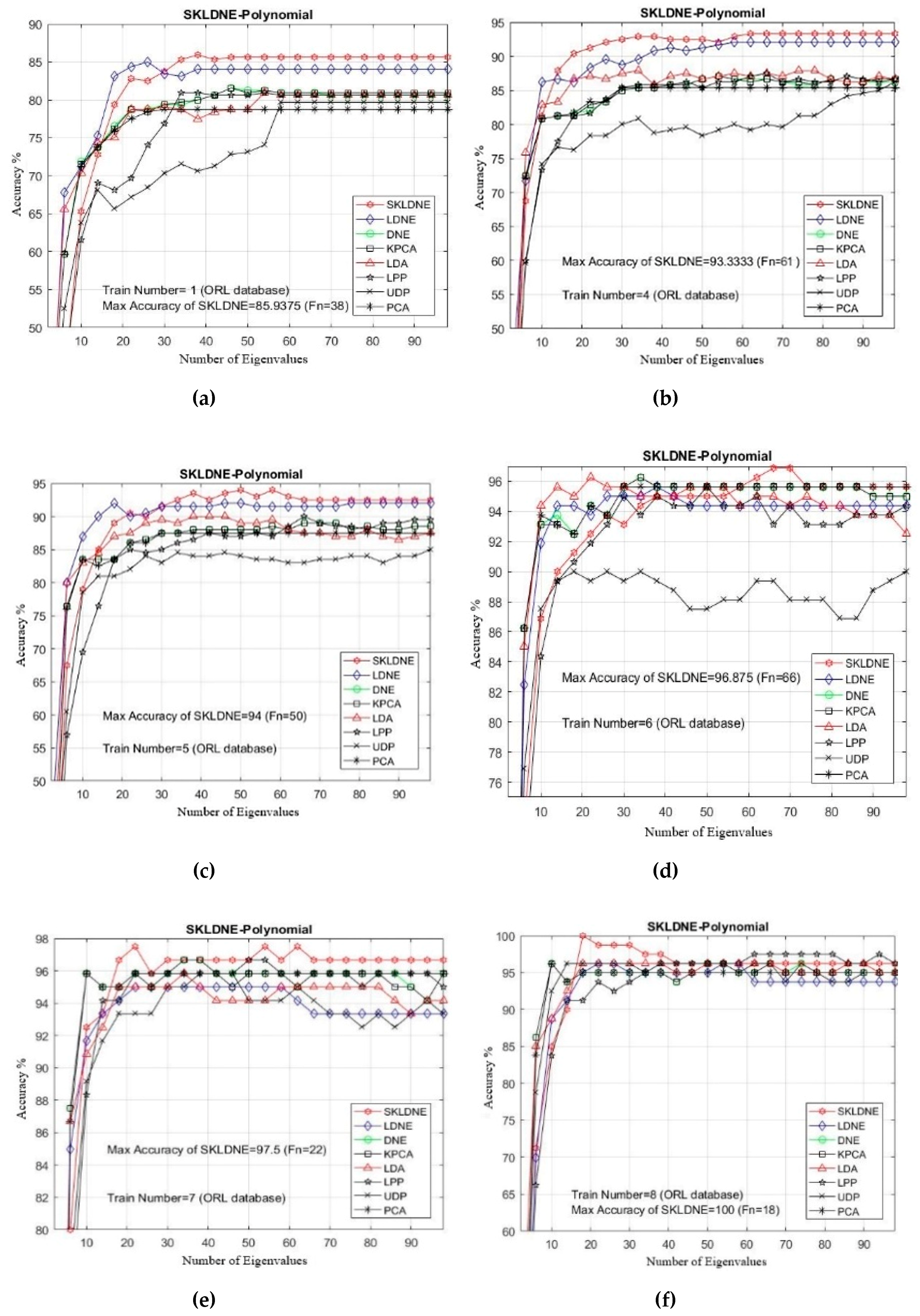
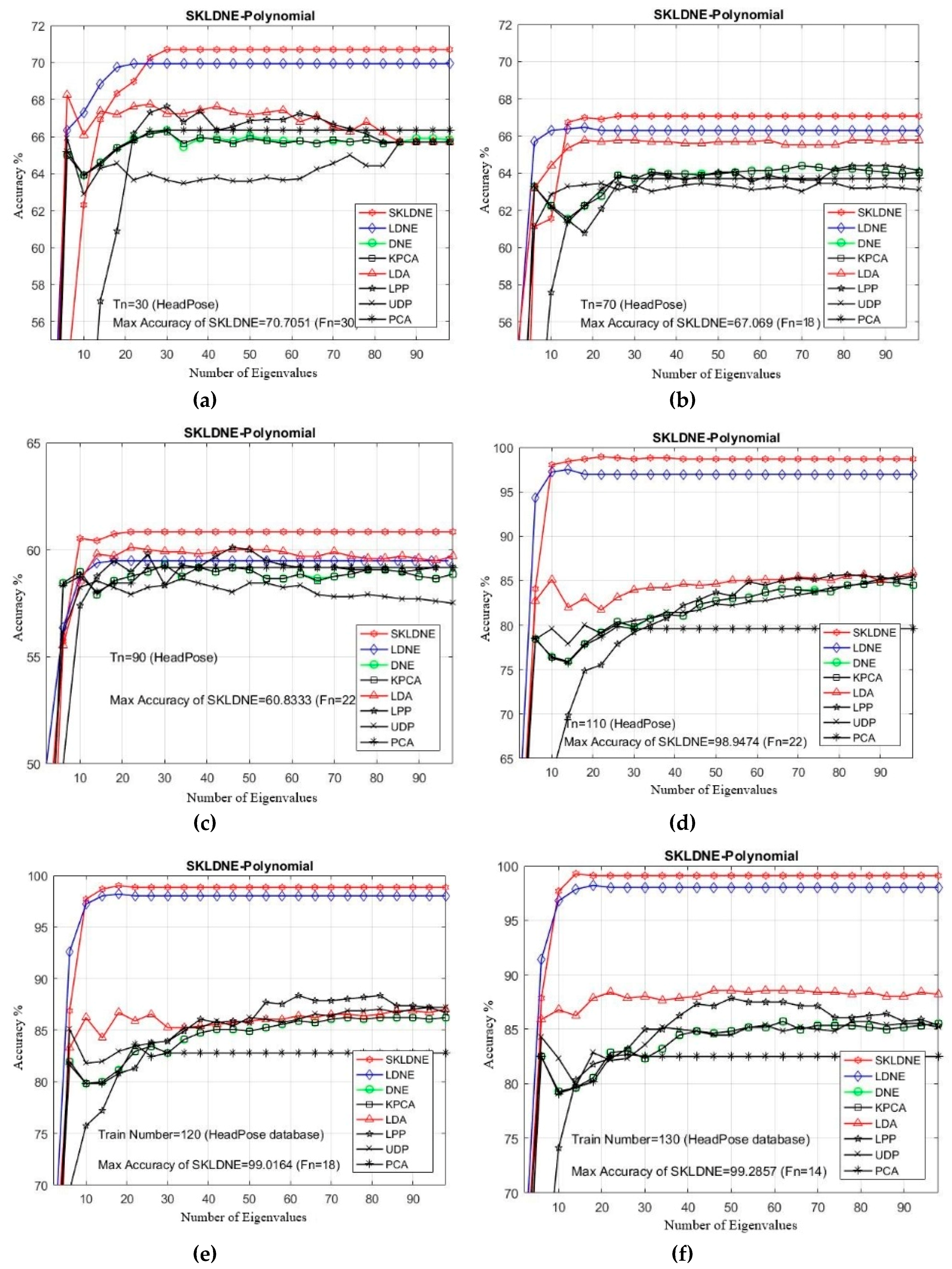
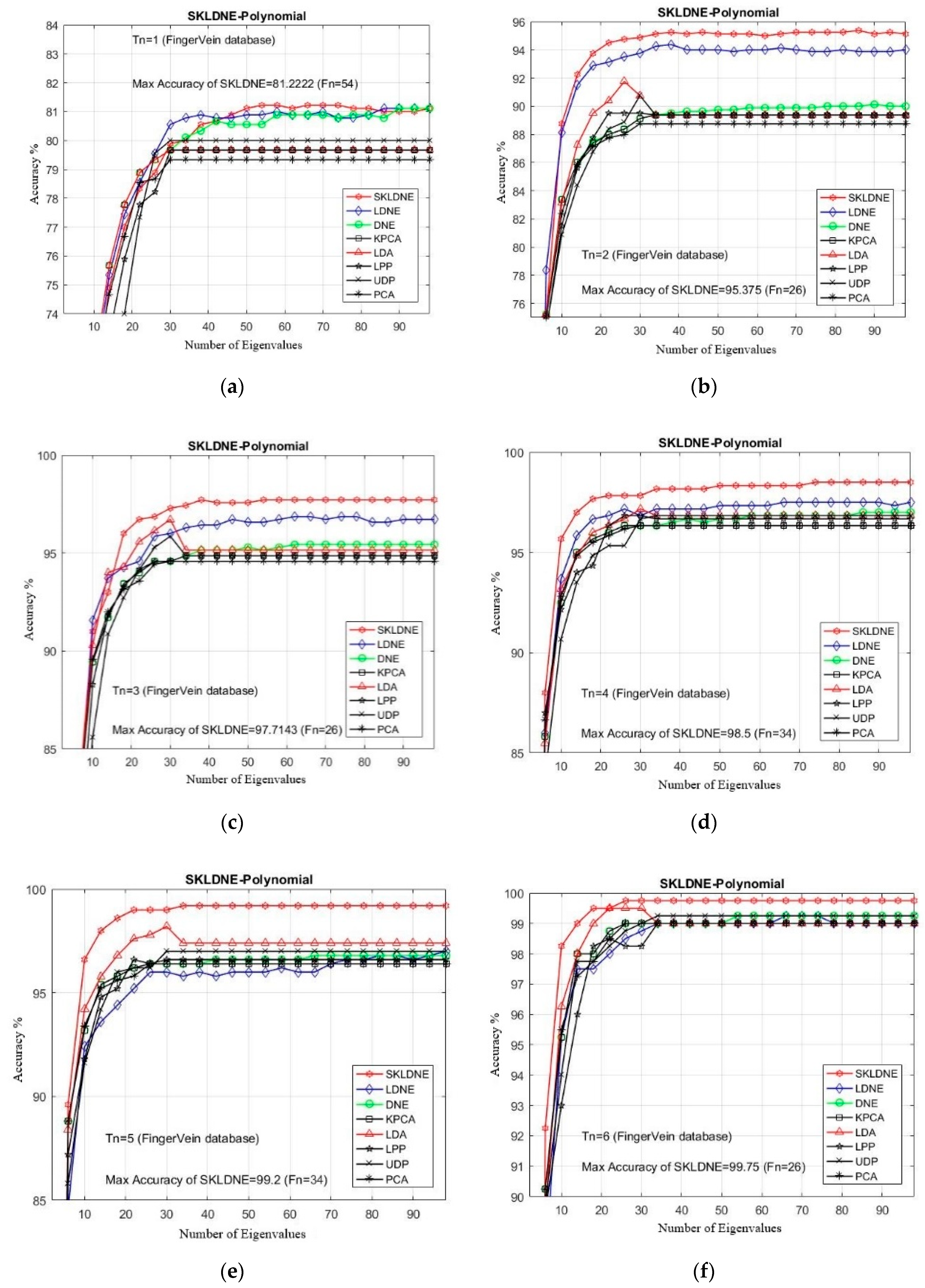
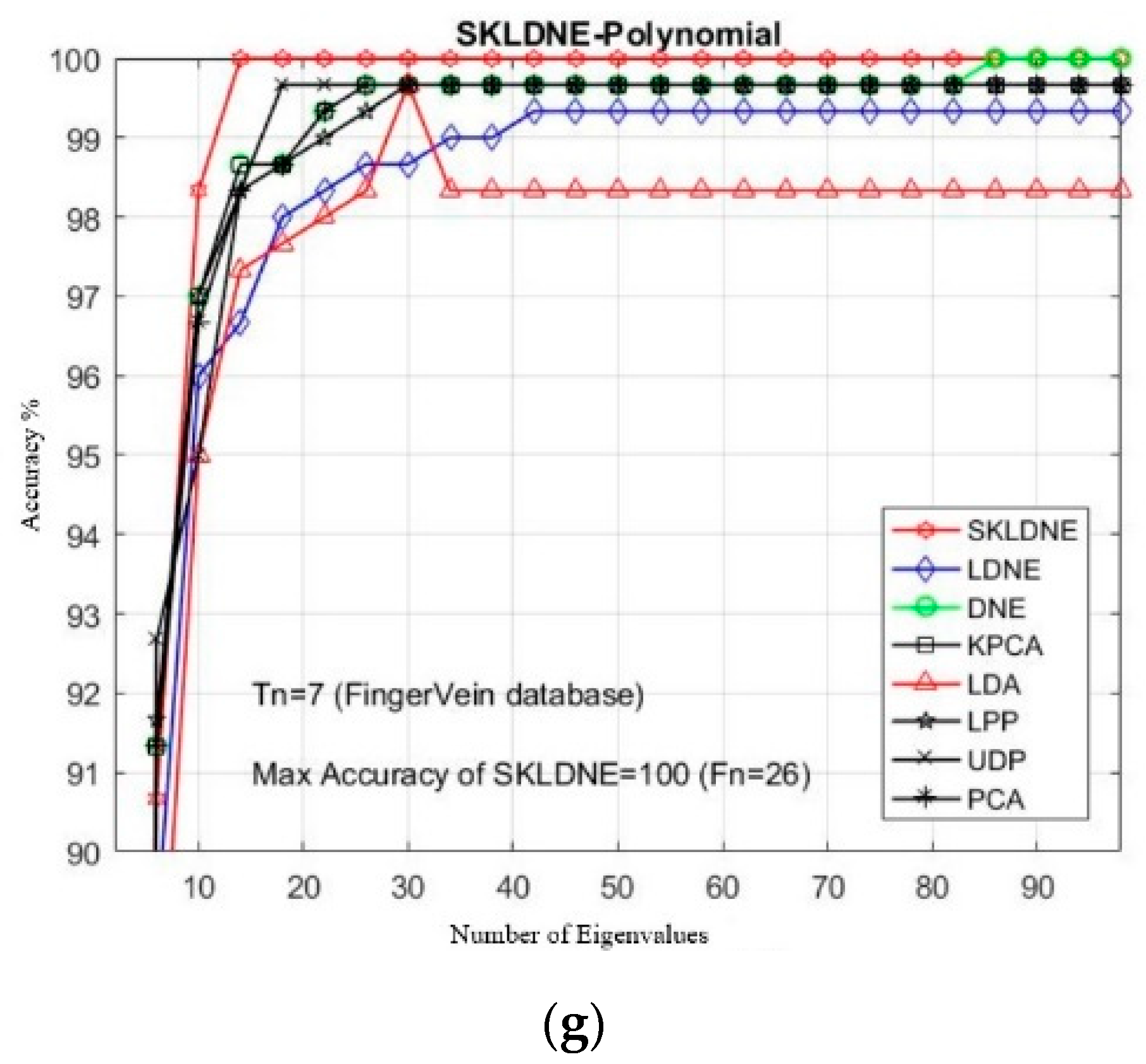
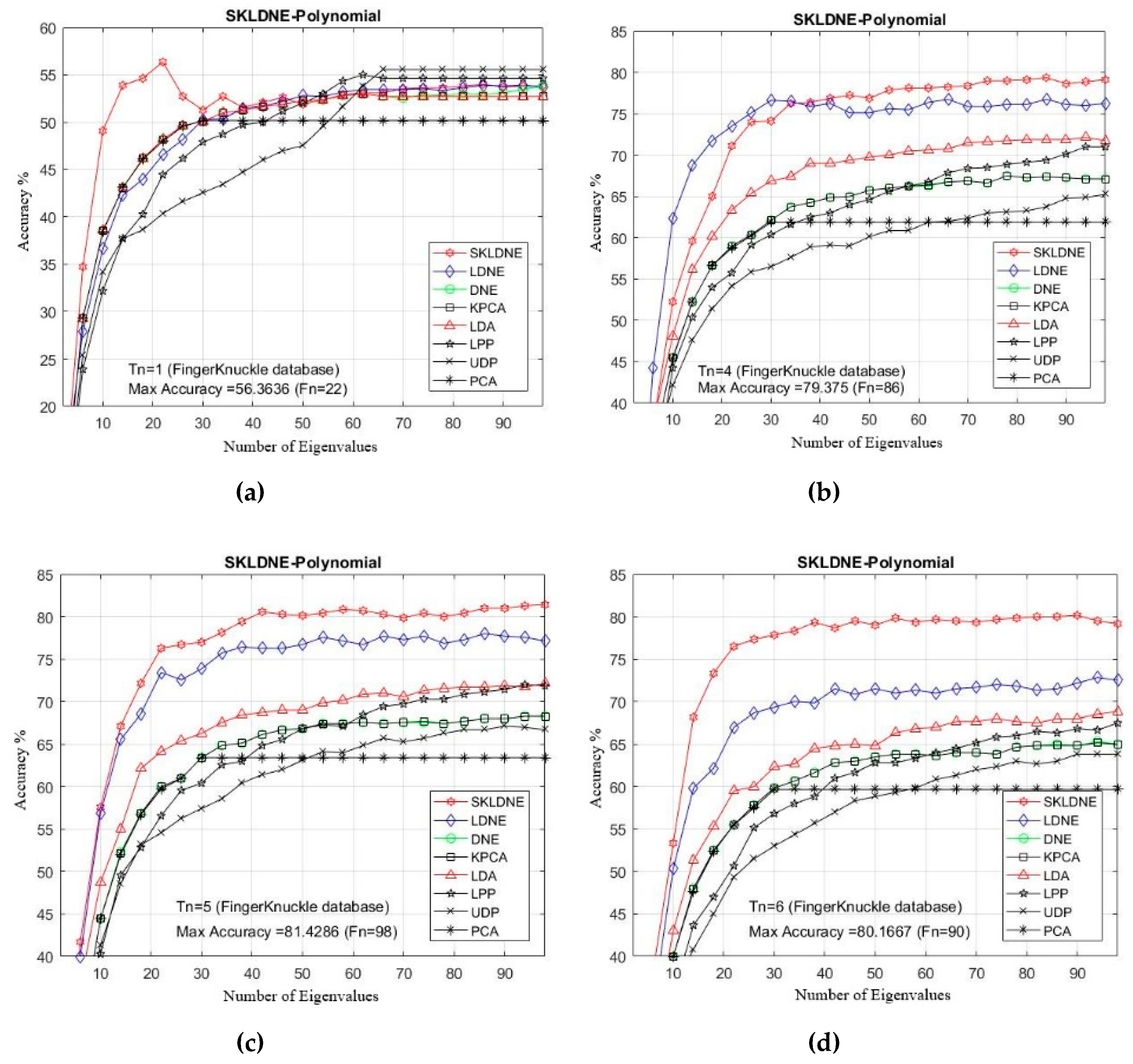
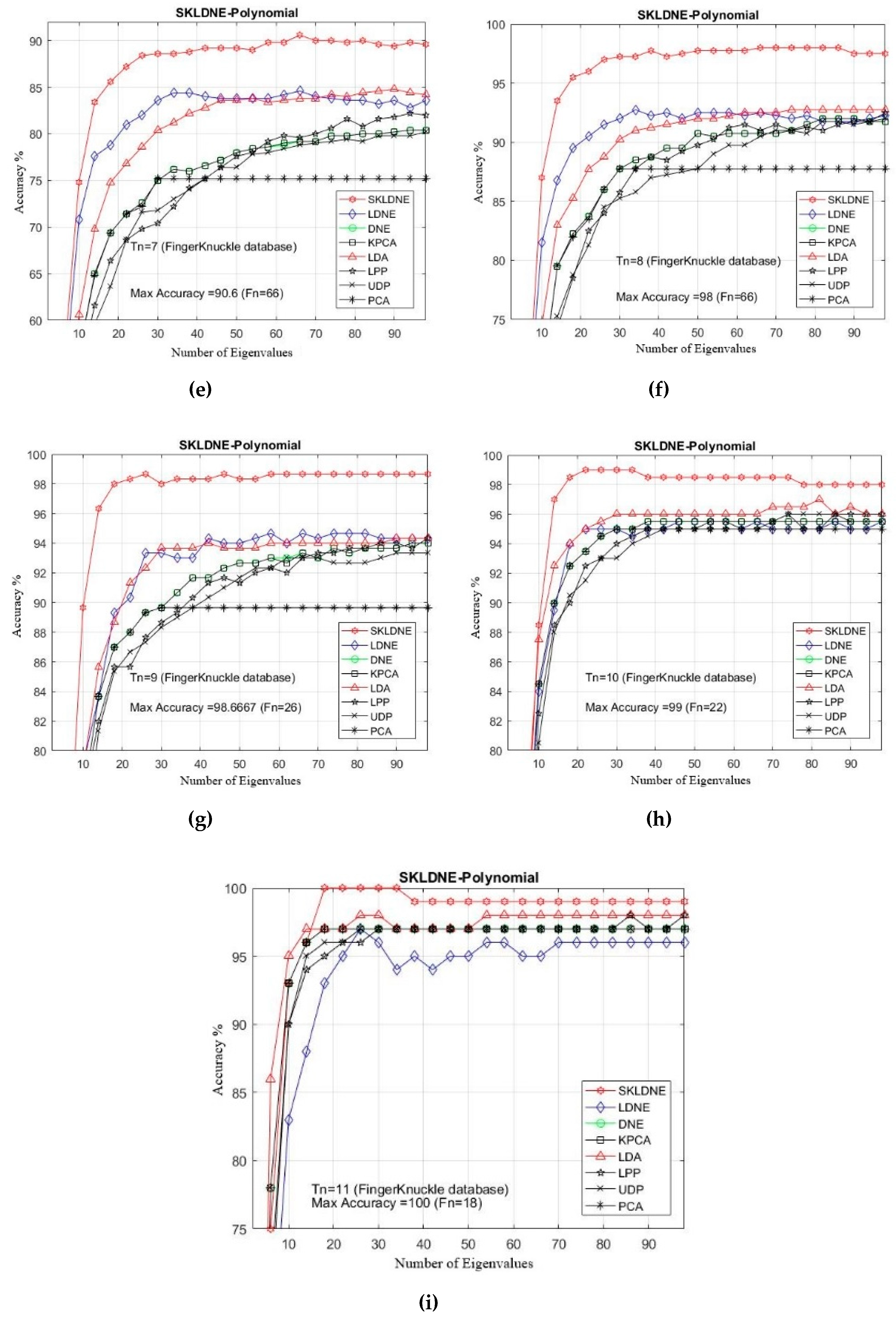
In this study, the performance of several well-known pattern recognition strategies was analyzed to clarify which techniques are best suited to be applied in face recognition. We also analyzed the weakness and robustness of each technique. As already mentioned, DNE cannot correctly preserve local information of data because it only assigns +1 to intra-class and −1 to inter-class neighbors, so it might fail to discover the most significant submanifolds for pattern classification. LPP is designed based on “locality” since it has no direct connection with classification, and it still suffers from the “over learning of locality” problem. LDNE has been proposed to overcome the problems existing in LPP and DNE; however, it does not guarantee an appropriate projection for classification purposes because many important non-linear data might be lost during its dimensionality reduction process. In addition, in some cases, LDNE cannot distinguish inter-class and intra-class neighbors well either in order to conduct projection for all points. This can degrade the classification performance. In order to address these problems, we have proposed a new supervised subspace learning algorithm named “supervised kernel locality-based discriminant neighborhood embedding” (SKLDNE). Combined with nonlinear data structures, locality, and discrimination information, SKLDNE can yield an optimal subspace that best finds the indispensable submanifolds-based structure. Six publicly available datasets, i.e., Yale face, ORL face, Sheffield, Head Pose, Finger Vein and Finger Knuckle, were used to illustrate the significance of the proposed technique. Experimental results reveal that SKLDNE outperforms and demonstrates potential to be implemented in real world systems compared to other advanced dimensionality reduction methods by obtaining the highest recognition rates in all experiments. Representing complex nonlinear variations makes SKLDNE more powerful and more intuitive than LDNE and other aforementioned techniques in terms of classification. According to the results, SKLDNE could also resolve the “small training sample size” problem, and it had the best performance compared to others at smaller numbers of projected dimensions in each number of training samples per data set. Moreover, when the given training sample size for each class grew larger, SKLDNE also achieved much better results than other techniques. The overlearning of locality problem and the out-of-sample problem in manifold learning can be avoided by applying our developed classifier. As a future plan, we will modify this classifier in order to make it directly applicable for two-dimensional data to effectively reduce the computational costs.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}