Front-Vehicle Detection in Video Images Based on Temporal and Spatial Characteristics


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Motion-Vector Extraction Based on ORB and Spatial Position Constraint Matching
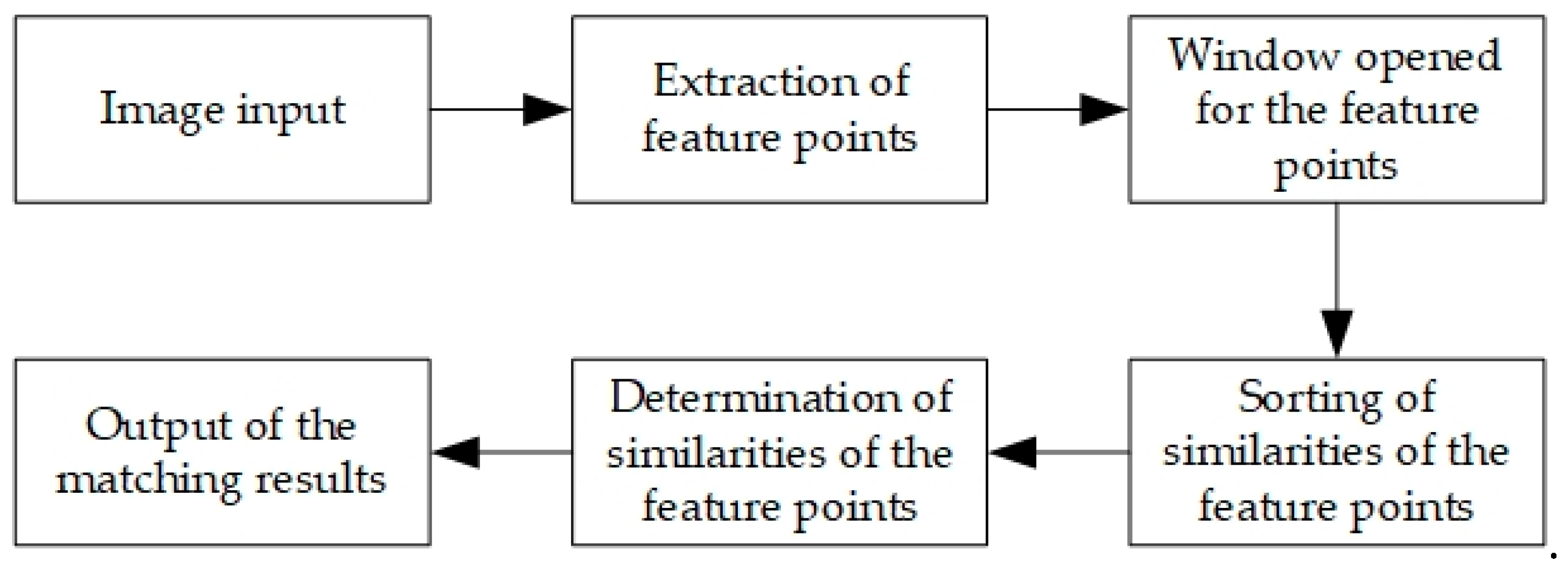
2.1. Algorithm Flow
2.2. Matching-Point Search in Opened Windows
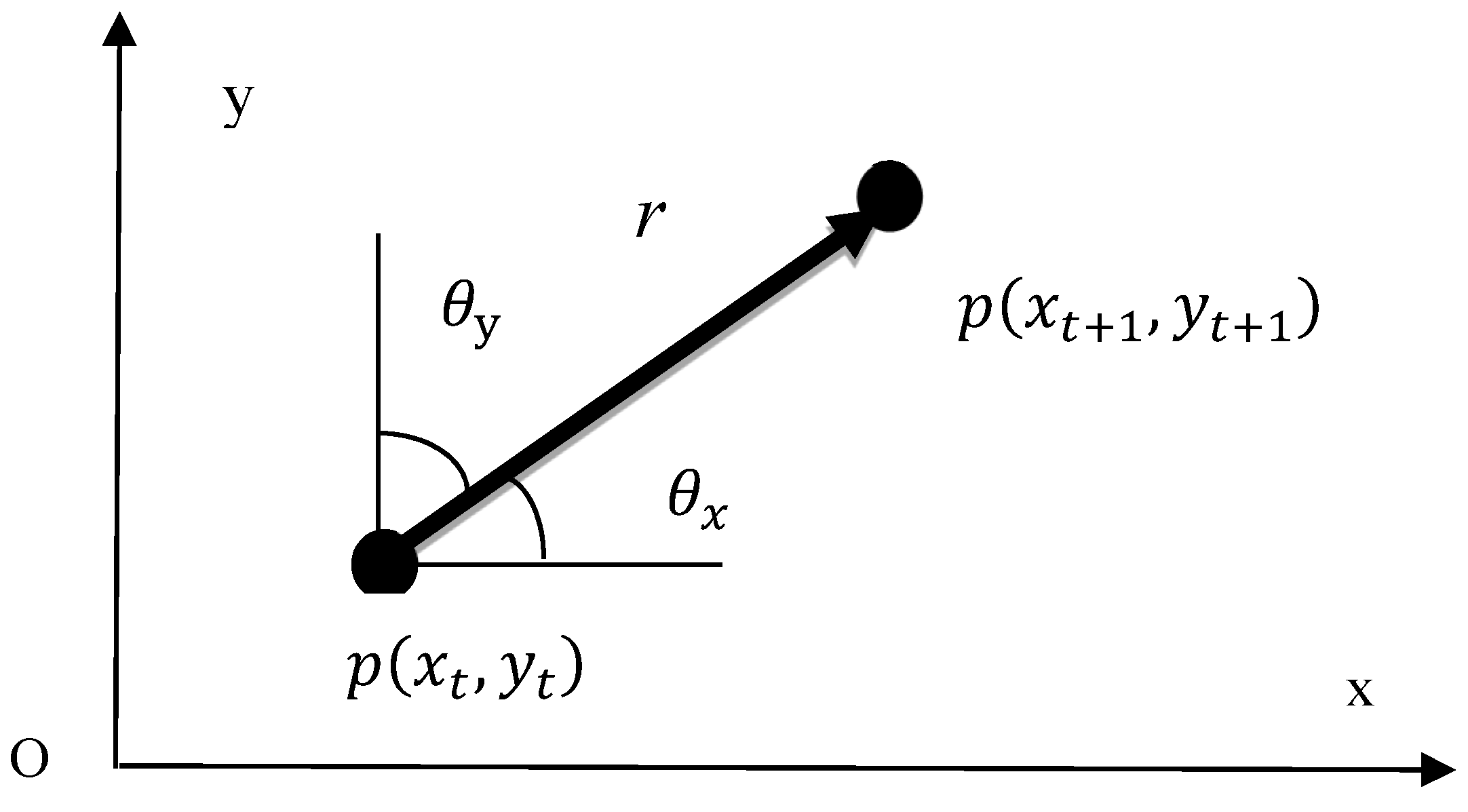
2.3. Calculation of Weighted Similarity
3. Front-Vehicle Detection Based on Temporal and Spatial Characteristics
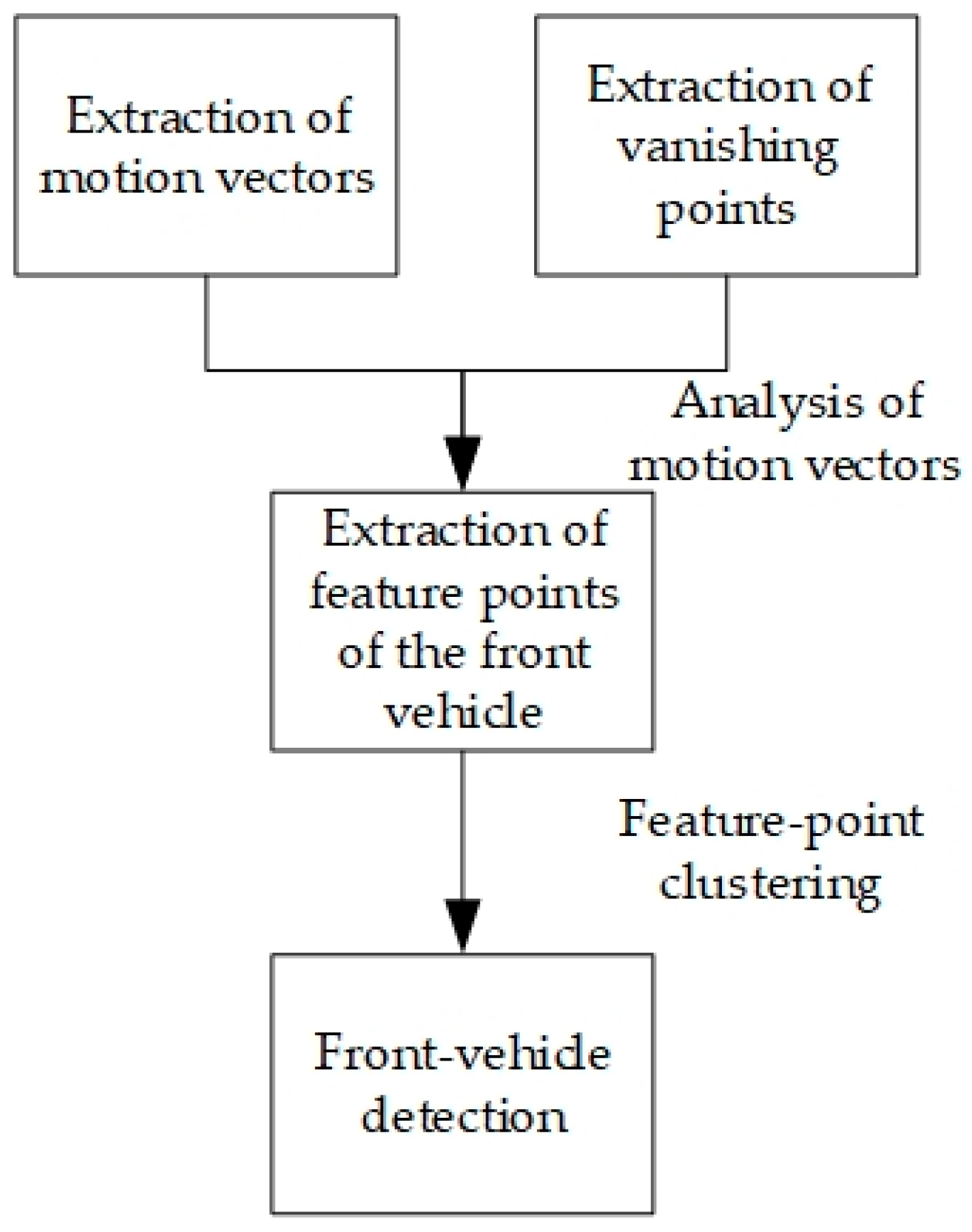
3.1. Algorithm Flow
3.2. Extraction of Vanishing Point Based on Automatic Edge Detection and Hough Transform
3.3. Extraction of Feature Point of Front Vehicle Based on Analysis of Motion Vector
3.4. Front-Vehicle Detection Based on Clustering of Spatial Neighborhood Features and Motion-Vector Characteristics
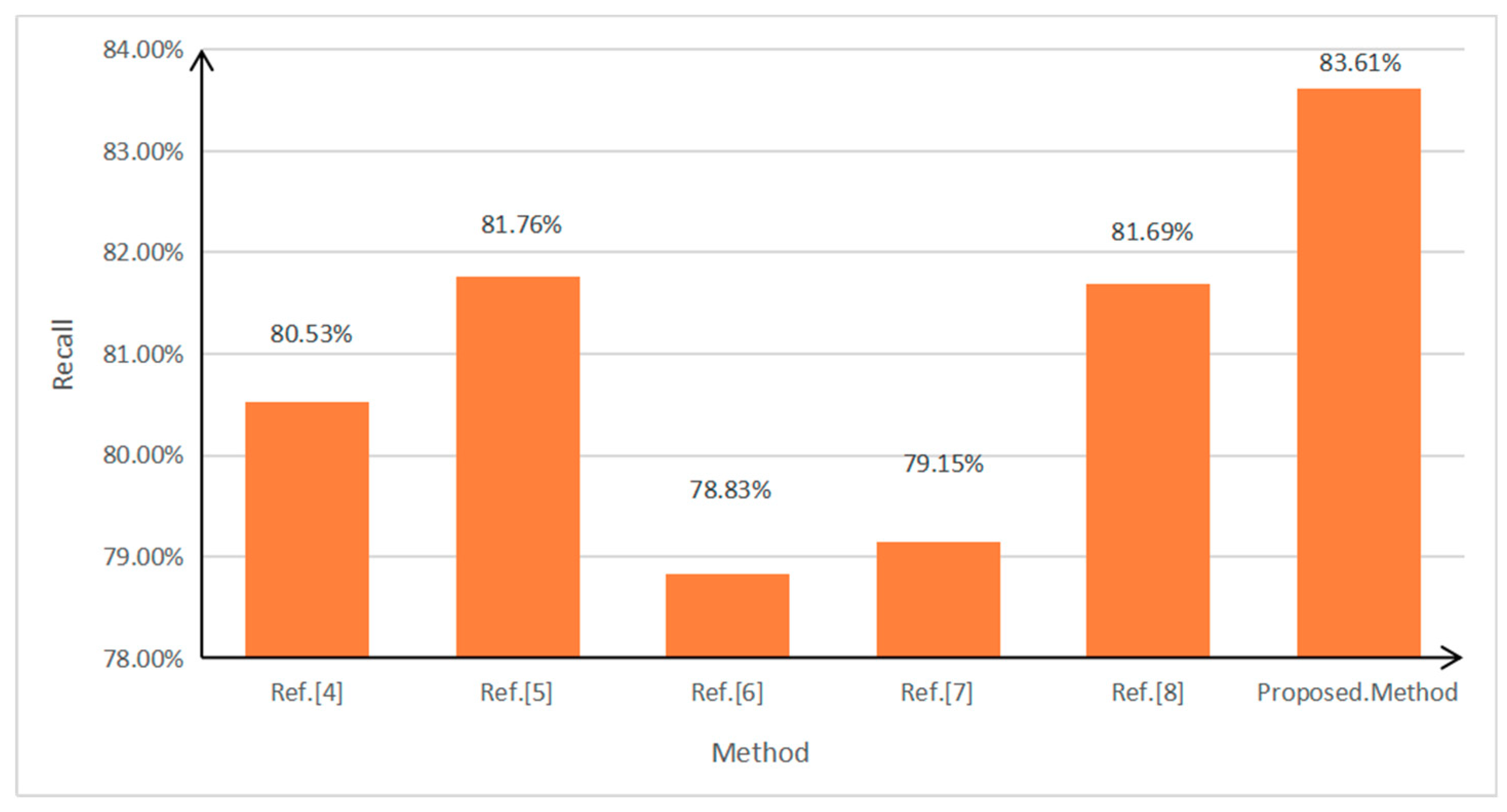
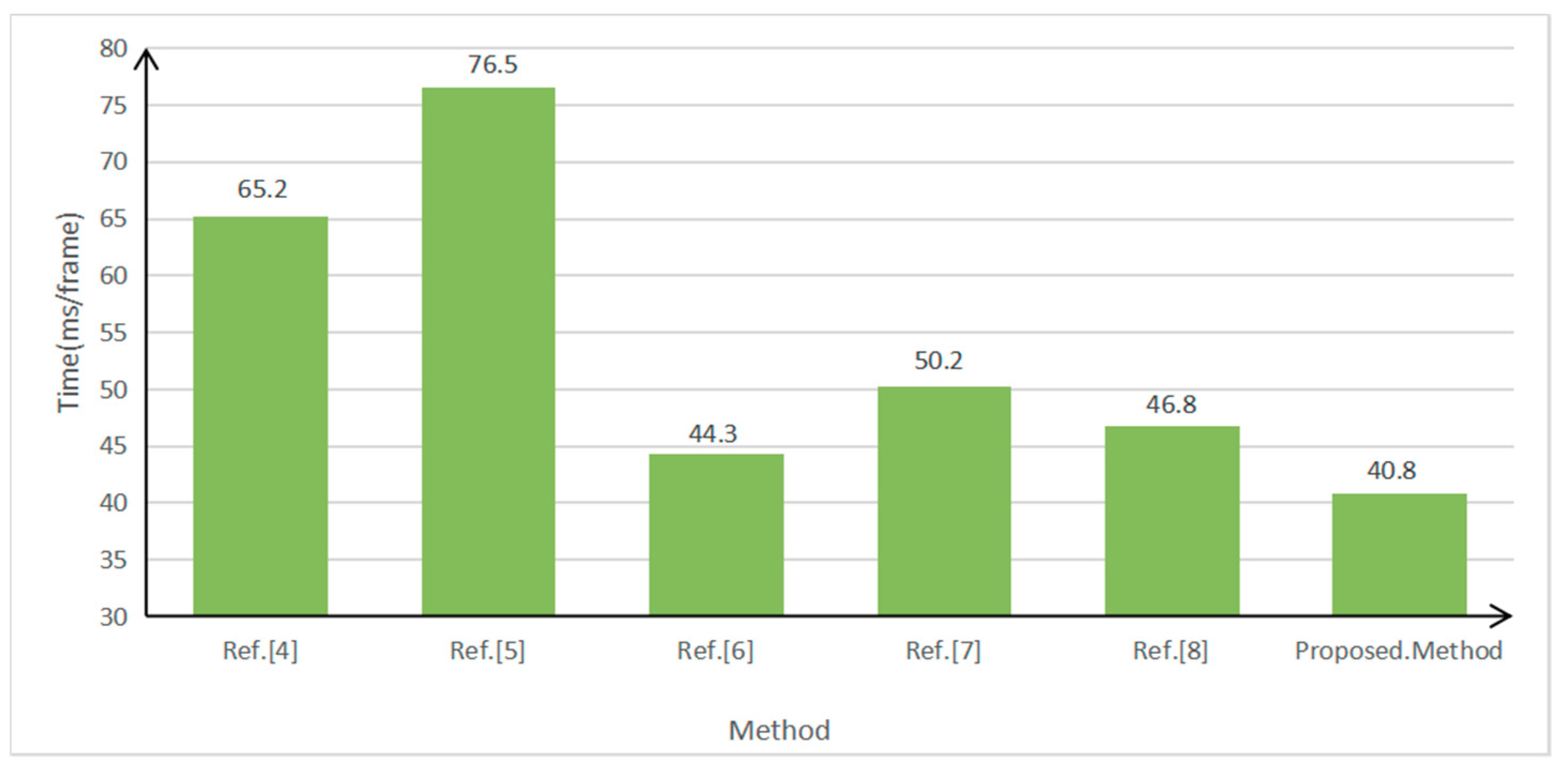
4. Results and Discussion
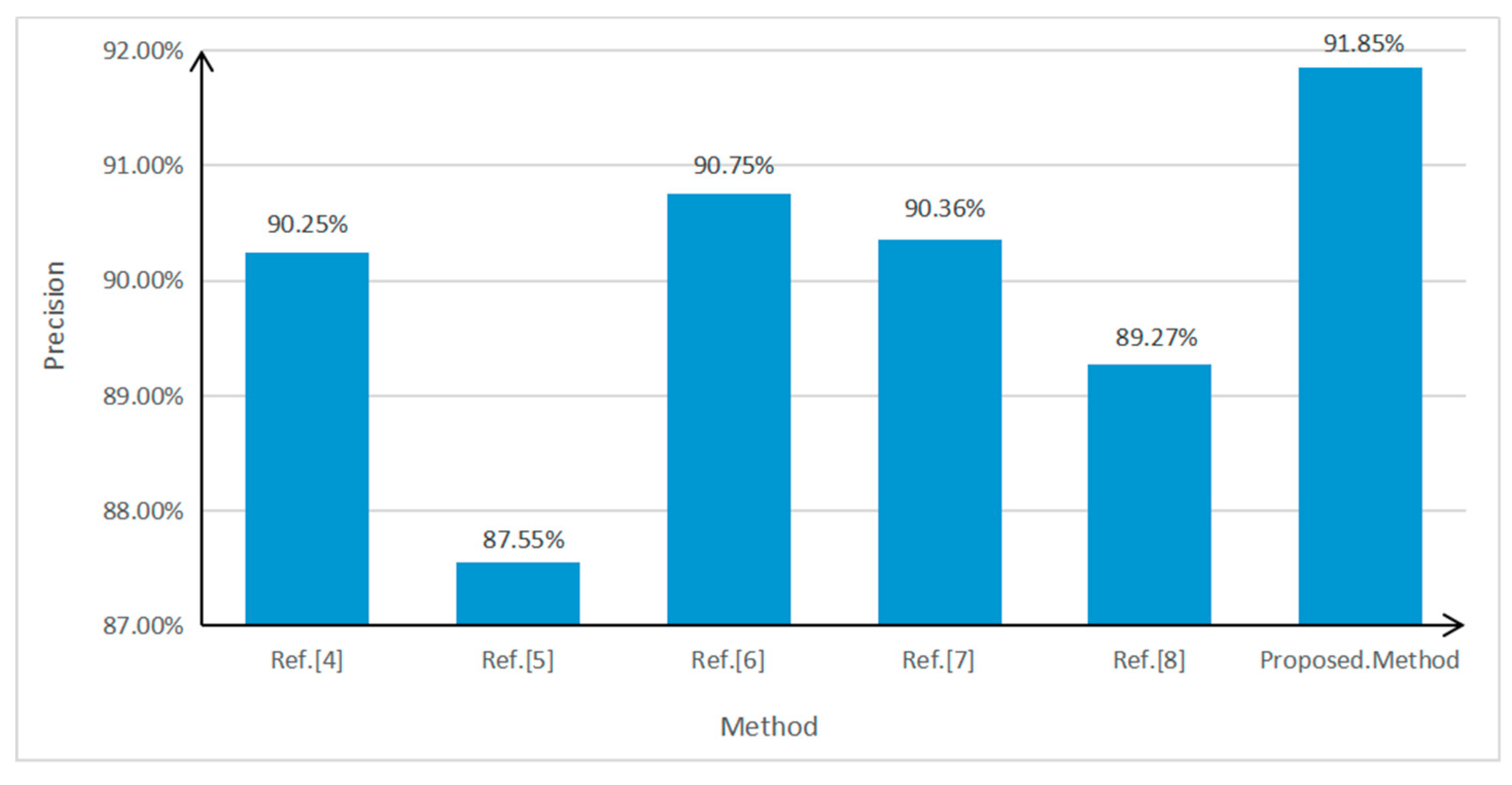
4.1. Experimental Data
4.2. Results and Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Liu, Y.; Wang, H.; Xiang, Y. An approach of real-time vehicle detection based on improved Adaboost algorithm and frame differencing rule. Huazhong Univ. Sci. Technol. (Nat. Sci. Ed.) 2013, 41, 379–382. [Google Scholar]
- Dickmanns, E.D. Vision for ground vehicles: History and prospects. Int. J. Veh. Auton. Syst. 2012, 1, 41–44. [Google Scholar] [CrossRef]
- Siam, M.; Elhelw, M. Robust autonomous visual detection and tracking of moving targets in UAV imagery. In Proceedings of the IEEE 9th International Conference on Signal Processing, Beijing, China, 21–25 October 2012; Volume 2, pp. 1060–1066. [Google Scholar]
- Qu, S.R.; Li, X. Research on multi-feature front vehicle detection algorithm based on vedio image. In Proceedings of the Chinese Control and Decision Conference, Yinchuan, China, 28–30 May 2016; pp. 3831–3835. [Google Scholar]
- Chen, G.; Pan, X.; Hou, Z. Preceding vehicle detection algorithm based on lane recognition and multi-characteristics. Sci. Technol. Eng. 2016, 16, 245–250. [Google Scholar]
- Chen, H.C.; Chen, T.Y.; Huang, D.Y. Front Vehicle Detection and Distance Estimation Using Single-Lens Video Camera. In Proceedings of the 2015 Third International Conference on Robot, Vision and Signal Processing, Kaohsiung, Taiwan, 18–20 November 2015; pp. 14–17. [Google Scholar]
- Li, Y.; Wang, F.Y. Vehicle detection based on and–Or Graph and Hybrid Image Templates for complex urban traffic conditions. Transp. Res. Part C 2015, 51, 19–28. [Google Scholar] [CrossRef]
- Zhang, J.M.; Zhang, L.; Liu, Z. Approach to front vehicle detection and tracking based on multiple features. Comput. Eng. Appl. 2011, 47, 220–223. [Google Scholar]
- Xu, Q.; Gao, F.; Xu, G. An Algorithm for Front-vehicle Detection Based on Haar-like Feature. Automot. Eng. 2013, 35, 381–384. [Google Scholar]
- Zhao, Y.N.; Zhou, Y.F. Distance detection of forward vehicle based on binocular vision system. Auto Mob. Sci. Technol. 2011, 1, 56–60. [Google Scholar]
- Wang, W.L.; Qu, S.R. A vehicle overtake accessorial navigation system based on monocular vision. J. Image Graph. 2008, 13, 709–712. [Google Scholar]
- Zeng, Z.H. Lane Detection and Car Tracking on the Highway. Acta Autom. Sin. 2013, 29, 450–452. [Google Scholar]
- Pi, Y.N.; Shi, Z.K.; Huang, J. Preceding car detection and tracking based on the monocular vision. Comput. Appl. 2005, 1, 220–224. [Google Scholar]
- Cai, Y.F.; Liu, Z.; Wang, H.; Chen, X.B.; Chen, L. Vehicle Detection by Fusing Part Model Learning and Semantic Scene Information for Complex Urban Surveillance. Sensors 2018, 18, 3505. [Google Scholar] [CrossRef]
- Chen, C.; Huang, C.; Sun, S. Vehicle Detection Algorithm Based on Multiple-model Fusion. J. Comput. Aided Des. Comput. Graph. 2018, 30, 2134–2140. [Google Scholar] [CrossRef]
- Li, W.J.; Hai, X.; Ye, Z.W. Design of avoiding-collide and detecting system based on ultrasonic wave. Autom. Panor. 2007, 24, 80–82. [Google Scholar]
- Yu, X.J.; Guo, J.; Xu, K.; Wang, N. An approach of front vehicle detection based on Haar-like features and AdaBoost algorithm. Softw. Algorithms 2017, 36, 22–25. [Google Scholar]
- Junghwan, P.; Jiwon, B.; Jeong, Y.J. Front Collision Warning based on Vehicle Detection using CNN. In Proceedings of the 2016 International SoC Design Conference, Jeju, Korea, 23–26 October 2016; pp. 163–164. [Google Scholar]
- Zhao, D.B.; Chen, Y.R.; Le, L.V. Deep reinforcement learning with visual attention for vehicle classification. IEEE Trans. Cogn. Dev. Syst. 2017, 9, 356–367. [Google Scholar] [CrossRef]
- Georgy, V.; Konoplich, E.; Evgeniy, O.P. Application of Deep Learning to the Problem of Vehicle Detection in UAV images. In Proceedings of the 2016 IEEE International Conference on Soft Computing and Measurements, St. Petersburg, Russia, 25–27 May 2016; pp. 4–6. [Google Scholar]
- Wang, H.; Yu, Y.; Cai, Y.F.; Chen, L.; Chen, X.B. A Vehicle Recognition Algorithm Based on Deep Transfer Learning with a Multiple Feature Subspace Distribution. Sensors 2018, 18, 4109. [Google Scholar] [CrossRef]
- Zeng, J.; Ren, Y.; Zheng, L. Research on vehicle detection based on radar and machine vision information fusion. Chongqing Automot. Eng. Soc. 2017, 6, 18–23. [Google Scholar]
- Xie, M.; Trassoudaine, L.; Alizon, J. Active and intelligent sensing of road obstacles: Application to the European Eureka-PROMETHEUS project. In Proceedings of the 1993 (4th) International Conference on Computer Vision, Berlin, Germany, 11–14 May 1993; pp. 616–623. [Google Scholar]
- Manuel, I.-A.; Tardi, T.; Juan, P.; Sandra, R.; Agustín, J. Shadow-Based Vehicle Detection in Urban Traffic. Sensors 2017, 17, 975. [Google Scholar]
- Jin, L.; Fu, M.; Wang, M.; Yang, Y. Vehicle detection based on vision and millimeter wave radar. J. Infrared Millim. Waves 2014, 33, 465–471. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Rosten, E.; Drummond, T. Faster and better: A machine learning approach to corner detection. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 105–119. [Google Scholar] [CrossRef]
- Calonder, M.; Lepetit, V.; Strecha, C. Brief: Binary Robust Independent Elementary Features. In Proceedings of the 11th European Conference on Computer Vision (ECCV), Heraklion, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Wang, C.; Fang, Y.; Zhao, H.; Guo, C.; Mita, S.; Zha, H. Probabilistic inference for occluded and multiview on-road vehicle detection. IEEE Trans. Intell. Transp. Syst. 2016, 17, 215–229. [Google Scholar] [CrossRef]
- Liu, H.; Zhao, W.J.; Wu, W. An Improved Multi-scale Retinex Infrared Image Enhancement Algorithm. Comput. Technol. Dev. 2011, 21, 105–107. [Google Scholar]
- Song, R.J.; Liu, C.; Wang, B.J. Adaptive Canny edge detection algorithm. J. Nanjing Univ. Posts Telecommun. (Nat. Sci. Ed.) 2018, 3, 72–76. [Google Scholar] [CrossRef]















© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, B.; Zhang, S.; Tian, Y.; Li, B. Front-Vehicle Detection in Video Images Based on Temporal and Spatial Characteristics. Sensors 2019, 19, 1728. https://doi.org/10.3390/s19071728
Yang B, Zhang S, Tian Y, Li B. Front-Vehicle Detection in Video Images Based on Temporal and Spatial Characteristics. Sensors. 2019; 19(7):1728. https://doi.org/10.3390/s19071728
Chicago/Turabian StyleYang, Bo, Sheng Zhang, Yan Tian, and Bijun Li. 2019. "Front-Vehicle Detection in Video Images Based on Temporal and Spatial Characteristics" Sensors 19, no. 7: 1728. https://doi.org/10.3390/s19071728
APA StyleYang, B., Zhang, S., Tian, Y., & Li, B. (2019). Front-Vehicle Detection in Video Images Based on Temporal and Spatial Characteristics. Sensors, 19(7), 1728. https://doi.org/10.3390/s19071728