Abstract
Deep learning is an effective feature extraction method widely applied in fault diagnosis fields since it can extract fault features potentially involved in multi-sensor data. But different sensors equipped in the system may sample data at different sampling rates, which will inevitably result in a problem that a very small number of samples with a complete structure can be used for deep learning since the input of a deep neural network (DNN) is required to be a structurally complete sample. On the other hand, a large number of samples are required to ensure the efficiency of deep learning based fault diagnosis methods. To solve the problem that a structurally complete sample size is too small, this paper proposes a fault diagnosis framework of missing data based on transfer learning which makes full use of a large number of structurally incomplete samples. By designing suitable transfer learning mechanisms, extra useful fault features can be extracted to improve the accuracy of fault diagnosis based simply on structural complete samples. Thus, online fault diagnosis, as well as an offline learning scheme based on deep learning of multi-rate sampling data, can be developed. The efficiency of the proposed method is demonstrated by utilizing data collected from the QPZZ- II rotating machinery vibration experimental platform system.
1. Introduction
The structure of automation equipment is becoming more and more complex. Once a component fails, the whole system will be paralyzed. Therefore, fault diagnosis has received increasing attention [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32]. In general, three fault diagnosis methods are now taken into consideration by scholars: fault diagnosis methods based on a physical model [1,2], fault diagnosis methods based on knowledge [3,4,5,6] and data-driven methods [7,8,9,10]. Model-based methods require an accurate analytical model, which limits its application in the field of fault diagnosis [9,10]. Fault diagnosis methods based on knowledge rely on artificial experience. Because of the complexity of the system and the limitation of expert experience, it is hard to ensure the accuracy of knowledge-based diagnosis [10]. In contrast, data-driven methods rely on neither expert experience nor accurate physical model. Data-driven methods can obtain useful information by data mining technologies and have become practical diagnosis technologies at present [11,12,13].
In recent years, deep learning methods have grown rapidly in academia and industry as a kind of data-driven methods. Deep learning methods are widely used in fault diagnosis, such as deep belief networks (DBN) [14,15,16,17,18], stacked auto-encoders (SAE) [14,19,20,21,22,23,24], long short-term memory neural networks (LSTM) [25] and convolutional neural networks (CNN) [26,27]. However, despite the marvellous success of deep learning methods, the above proposed methods have great limitations: structurally complete samples are used for data analysis, feature extraction and fault diagnosis. The accuracy of fault diagnosis methods based on deep learning depends on the quantity and quality of samples. In practical engineering, the sampling rates of sensors are different, resulting in a small number of samples with complete structure and a large amount of missing data. Missing data means that there are one or more incomplete data for the observed variables in a database [33]. Random data packet dropout in the network, the multi-rate sampling of sensors, sensor failure and other reasons would lead to the phenomenon of missing data. For example, if there are two sensors with the sampling frequency of one ten times that of another, then structurally complete samples which have two sensor data at the same time account for only 10%. That is to say, 90% of the data is missing. Missing data will inevitably affect the accuracy of fault feature extraction, which cannot guarantee the accuracy of the fault diagnosis model and the validity of diagnosis methods. Reference [34] demonstrated that when there was not much training data, deep neural network (DNN) models may perform worse than other shallow models.
To address the problem of missing data, there are two common strategies: listwise deletion and imputation [33]. The listwise deletion removes all data for a case that has one or more missing values. The deletion is thus always the last choice, for it may lead to significant information loss. Data imputation includes mean substitution, regression substitution and K-nearest neighbour substitution. Mean substitution is an approach to fill the missing values by calculating the complete data mean. Mean substitution is mainly suitable for data sets with a normal distribution. Regression substitution establishes regression equations for missing attributes and other non-missing attributes to fill the missing values of missing attributes. The establishment of regression models depends on the linear correlation between attributes but there may not be a linear relationship between attributes. K-nearest neighbour substitution is to find K instances nearest to incomplete instance objects in complete data sets to fill missing attributes. Because each filling needs to traverse the instance space, dimensional disasters easily occur for large data sets. The filling method therefore has its own limitations as well. It utilizes the information of complete data sets so it can only be applied to data sets with random missing and small missing proportion. Moreover, because missing data can be filled at first and then fault diagnosis can be carried out, the imputation method cannot be used for real-time online fault diagnosis. When the proportion of missing data is relatively high, the performance of data imputation is intolerable.
The sampling rates of sensors are different resulting in a very small number of samples with complete structure and a large amount of missing data. A small number of complete samples cannot ensure the efficiency of deep learning based fault diagnosis methods. A large number of missing data is not suitable for data imputation. So this paper uses transfer learning to make full use of a large amount of missing data to improve the accuracy of fault diagnosis. Transfer learning aims to recognize and apply knowledge learned from previous tasks to novel tasks [35,36] and has made great progress in the areas of images [37,38,39], natural language processing [40,41] and medical health [42,43,44]. Reference [45] presented a multitask fuzzy system modelling method, which makes the most of the independent information of each task and correlation information captured by the common hidden structure among all tasks. Reference [46] proposed both online and offline weighted adaptation regularization algorithms to minimize the amount of labeled subject specific EEG data in BCI calibration in order to improve the utility of BCI system. Reference [47] presented a TL-SSL-TSK model which combines transfer learning, semi-supervised learning, and TSK fuzzy system models to enhance the robustness, accuracy and interpretability of EEG signal classifier. However, the research of transfer learning in the field of fault diagnosis is little yet [29,30,31,32]. Reference [29] proposed a deep transfer network based on a domain adaptation method for fault diagnosis but it only considers marginal distribution without taking into account conditional distribution. Reference [30] presented a fault diagnosis framework with joint distribution adaptation which can decrease the discrepancy in both marginal distribution and conditional distribution. Reference [31] proposed a transfer learning method for gearbox fault diagnosis based on a convolutional neural network. The proposed transfer learning architecture consists of two parts: the first part is constructed with a pre-trained convolutional neural network that serves to extract the features automatically from natural images; the second part trains the full connection layer by using gearbox fault experiment data. Reference [32] presented a transfer learning approach to fault diagnosis with a neural network in a variety of working conditions. Missing data is an important issue but existing articles do not deal with fault diagnosis of missing data based on transfer learning. In the paper, we present a transfer learning framework for fault diagnosis of missing data. A detailed comparison between References [29,30,31,32,46,47] and this paper is shown in Table 1.

Table 1.
A comparison between the relevant literature and this paper.
In this paper, we propose a fault diagnosis framework of missing data based on transfer learning. Structurally incomplete samples may lose some key information but contain other useful information. It is necessary to transfer them to the structurally complete fault diagnosis model. In turn, the number of structurally complete samples is small but structurally complete samples contain all the information monitored. Therefore, the data with a complete structure are also transferred to the model with missing data to optimize fault diagnosis performance of missing data.
The remainder of this paper is organized as follows: Section 2 provides a literature review of deep neural networks. Section 3 describes a fault diagnosis framework with missing data based on transfer learning. In Section 4, the validity of the proposed fault diagnosis method is verified through a case study. Finally, the main conclusions are provided in Section 5.
2. Review of Deep Neural Network
A deep neural network (DNN) can be composed of multiple automatic encoders. It uses bottom-up unsupervised learning to extract features layer by layer and uses a supervised learning method to fine-tune the parameters of the whole network. DNN can extract the essential features from the original data. The autoencoder is a feedforward neural network which has an input layer, a hidden layer and an output layer. The output layer has the same number of nodes as the input layer in order to reconstruct its input and the hidden layer is taken as the learned feature. The autoencoder consists of encoding and decoding. The encoding is the mapping from the input layer to the hidden layer and the decoding is the mapping from the hidden layer to the output layer.
There is an unlabeled data set , containing P variables and M samples. The encoding process is
where is encoding function, is the tansig activation function, W is the weight matrix between input layer and hidden layer, is bias vector of encoding and is a set of weight matrix and bias between input layer and hidden layer. Similarly, the decoding process is
where is decoding function, is the tansig activation function, is the weight matrix between hidden layer and output layer, is bias vector of decoding and is a set of weight matrix and bias between hidden layer and output layer.
The reconstruction error function is
The aim of network training is to minimize the reconstruction error function by gradient descent and back propagation. The updating rules of parameters are
In order to realize classification, this paper uses the Softmax classifier as the output layer of DNN. The training data set is . is the label. The probability of each type can be calculated by the following hypothesis function,
where is the parameter of Softmax. The loss function is
Finally, the DNN performs supervised fine-tuning by back propagation. The process of updating parameters can be written:
where is predicted output, is the set of parameters and is updated by back propagation algorithm.
3. A Fault Diagnosis Framework with Missing Data Based on Transfer Learning
In practical engineering, the sampling rates of different sensors may be different, which will lead to a rather small number of samples with a complete structure. For example, there are five sensors with different sampling rates in Figure 1. The sampling rate of sensor 1 is two times that of sensor 2, four times that of sensor 3, eight times that of sensor 4 and sixteen times that of sensor 5. Thus, only 6.25% of the samples are structurally complete while 93.75% of the samples are incomplete. Considering that only structurally complete samples can be applied as the input of the DNN, the structurally complete sample size is too small to train an accurate fault diagnosis model. To address this problem, this paper presents a fault diagnosis framework of missing data based on transfer learning, which makes full use of a large number of structurally incomplete samples. To introduce the proposed framework comprehensively and systematically, this section is divided into three parts as follows: transfer from the fault diagnosis model of missing data to the model of structurally complete data, transfer from the fault diagnosis model of structurally complete data to the model of missing data and the real-time online diagnosis of multi-rate sampling data.
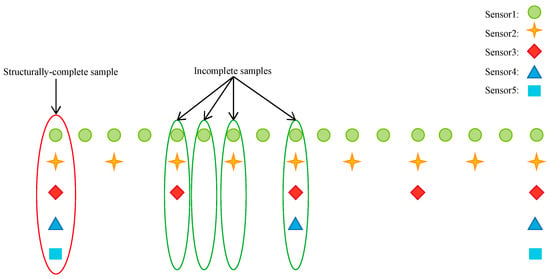
Figure 1.
Different sampling rates of sensors.
3.1. Transfer from Fault Diagnosis Model of Missing Data to the Model of Structurally Complete Data
Samples with incomplete structures may lose some information but contain other useful information. It is necessary to migrate them to a structurally complete fault diagnosis model. This section explains how to learn and extract fault features from a huge number of incomplete data and then migrate these extracted features from an incomplete data model to a structurally complete data model to enhance the fault diagnosis accuracy of the latter model. The fault diagnosis framework with missing data is shown in Figure 2. The algorithm is as follows:
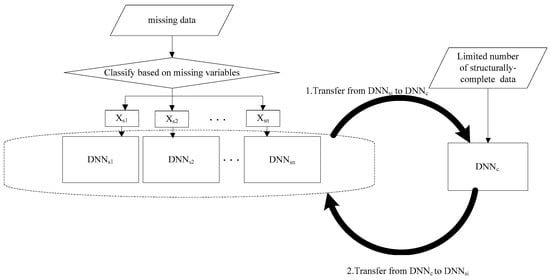
Figure 2.
The fault diagnosis framework with missing data.
Step 1: Classifying samples based on missing data.
The sample set is divided into complete sample set and incomplete sample set which is further classified into n categories . Taking Figure 1 as an example, the samples are divided into five categories, among which is structurally complete sample set while and are structurally incomplete sample sets. When the sample value of sensor 5 is unavailable, is used to represent the missing data set. When the sample values of sensor 4 and 5 are unavailable, is used to represent the missing data set. When the sample values of sensor 3, 4 and 5 are unavailable, is used to represent the missing data set. When the sample values of sensor 2, 3, 4 and 5 are unavailable, is used to represent the missing data set. Supposing a structurally complete sample contains P variables, is 0 if the pth variable of sample is missing and 1 otherwise as indicated in Equation (13). thus represents the missing state of as shown in Equation (14).
If Equation (15) is true, it represents that sample is complete data while that Equation (16) is true means sample is missing data. If is true, sample and sample either are both complete data or belong to the same type of missing data as shown in Equation (17).
Step 2: Building fault diagnosis models for each type of missing data.
Let us take type i as an example and build its fault diagnosis model . is composed by stacking N autoencoders. are the neuron number of 1st, 2nd,…Nth hidden layers in , respectively. is the set of weight matrix and bias between input layer and hidden layer of in respectively and is initialized randomly. Then is the set of weight matrix and bias between hidden layer and output layer of in respectively and is randomly initialized as well. Likewise, we can build fault diagnosis models for missing data types 1, 2,…, n respectively.
Step 3: Training the models .
Taking as an example, is trained by historical missing data set and obtain the feature shown in . The model updates parameters and by Equations (5)–(8).
Step 4: Optimizing the models .
is used as input data to train Softmax model. Still taking as an example, is optimized by backpropagation algorithm and parameters are updated.
Step 5: Implementing transfer based on multi-rate sampling and building fault diagnosis model of complete data.
Although missing data is incomplete, it still contains fault information. We thus extract fault features from incomplete samples and transfer the extracted features to the structurally complete model to improve the fault diagnosis accuracy of the model. The transfer can cause the structure of to be modified due to the fact that incomplete and complete samples are different in dimension while the input layer size of the first layer should be the same as the dimensionalities of samples. This transfer process is illustrated in Figure 3. for every type of missing data is transferred to respectively. represents the model obtained through migration. Let us take the migration from to as an example. At first, the system checks every variable to see if it is missing in . If the variable is not missing, then the encoding parameter of the first layer in can be migrated to the input layer of . Otherwise the corresponding parameter of the first layer in is randomly initialized as shown in Equations (18)–(20). It is assumed that structurally-complete data has P variables while incomplete data has variables. Without loss of generality, the variables of incomplete data can be assumed to be the first variables of structurally-complete data. r represents a random number. The encoding parameters of the remaining layers in are migrated to in Equation (21). The decoding parameters of the first layer in can be similarly migrated to as shown in Equations (22)–(24). Last but not least, the decoding parameters of the remaining layers in are migrated to as indicated in Equation (25).
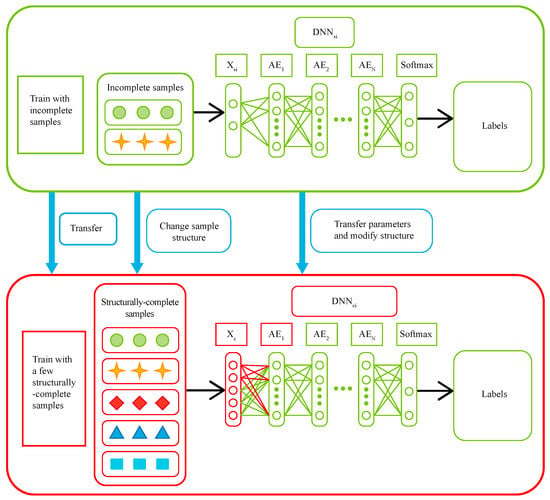
Figure 3.
The transfer process of fault diagnosis model for multi-rate sampling.
Therefore, we build fault diagnosis model of complete data by transfer learning . are also built in the similar way to .
Step 6: Training the models .
Still taking as an example, is trained by structural complete data set and features are obtained by . The model updates parameters by Equations (5) and (6).
Step 7: Optimizing the models .
is applied to train Softmax model as input data and are optimized by backpropagation algorithm respectively.
3.2. Transfer from Fault Diagnosis Model of Structurally-Complete Data to the Model of Missing Data
Although the number of structurally complete samples is small, structurally complete samples contain all the information monitored. Therefore, the structurally complete fault diagnosis model can be migrated to structurally incomplete fault diagnosis models. From all the models , we select one with the highest accuracy which is assumed to be . Then by training and optimizing the model repeatedly, a better model can be obtained and in turn migrated to .
Step 1: Transferring from fault diagnosis model of structurally-complete data to the model of missing data.
Structurally-complete data contains the overall information of the fault despite the fact that the sample size is limited. Therefore, complete samples can also be made full use of to extract fault features which are then transferred to the model of incomplete data for a higher accuracy of fault diagnosis. According to the dimensionalities of complete and incomplete samples, the input layer size of is more than . We use the migration from to as an example. Firstly, the system checks for missing any variables. Secondly, the encoding parameters of the first layer in can be migrated to the input layer of as indicated in Equation (26). Under the assumption that structurally-complete data has P variables while incomplete data has variables, the variables of incomplete data can be considered as the first variables of structurally-complete data without loss of generality. This is shown in Equations (27) and (28). Thirdly, the decoding parameters of the first layer in can be migrated to in Equation (30)–(32). Fourthly, the encoding and decoding parameters of the remaining layers in can be migrated to as indicated in Equations (29) and (33).
Step 2: Building fault diagnosis models for each type of missing data.
Let us take type i as an example and build its fault diagnosis model .
Step 3: Training the models .
Taking as an example, is trained by historical missing data set and obtained features is shown in . is used as input data to train Softmax model and the model updates parameters .
Step 4: Optimizing the models .
Using as an example again, is optimized by backpropagation algorithm. In this way, and are trained alternately until a satisfactory accuracy of fault diagnosis is achieved.
3.3. Online Diagnosis of Multi-Rate Sampling Data
The framework proposed in this paper can carry out real-time online fault diagnosis for missing data. Because incomplete data may disappear different values of different sensors, incomplete data can be divided into a variety of missing data types. In the offline phase, a corresponding fault diagnosis model is established for each missing data type according to the algorithm in Section 3.1 and Section 3.2. In the online diagnosis stage, the first step judges whether the data at time t will be missing data or complete data.
Step 1: Judge whether the data at time t will be missing data or complete data.
If is structurally-complete data and has P values according to Equation (34), go to step 4. Otherwise move to step 2.
Step 2: Judge the type of missing data according to Equation (35).
Step 3: Fault diagnosis is carried out by using the corresponding and the model is updated. Turn to step 5.
Step 4: Fault diagnosis is carried out by using the model and the model is updated.
Step 5: Output diagnostic results and wait the next data. Turn to step 1. Fault diagnosis flowchart based on transfer learning is shown in Figure 4.
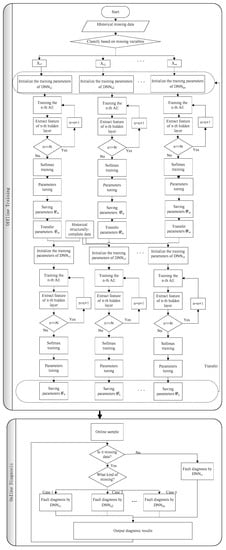
Figure 4.
Fault diagnosis flowchart with missing data based on transfer learning.
4. Experiment and Analysis
4.1. Experiment Platform
The paper applies a QPZZ-II rotating machinery vibration experimental platform system, which can simulate gear fault [48]. The main parameters include: a maximum speed of 1470 r/min, three wheels (normal, pit and worn tooth) and two pinions (normal, worn). In this experiment, wheels and pinions are used as experimental objects. Rotational speed is 1470 r/min. Nine sensors are employed to collect information as shown in Table 2. In this experiment, the complete structure of the sample includes 9 variables collected from 9 sensors. Let’s assume that the sampling rates of sensors 1, 3, 5 and 7 are two times that of sensor 6, four times that of sensor 4, eight times that of sensor 2 and sixteen times that of sensor 8 and 9. Thus, only 6.25% of the samples are structurally complete while 93.75% of the samples are incomplete. There are 5 healthy states of the gearbox and details are indicated in Table 3.
Table 2.
Details of sensors equipped on the gearbox.
Table 3.
Healthy states of the gearbox.
4.2. Transfer from Missing Data Model to Structurally-Complete Model
In order to validate the effectiveness of the proposed framework, experiments are carried out with 2 missing variables, 3 missing variables, 4 missing variables and 5 missing variables, respectively, and details are shown in Table 4. Taking incomplete data with 4 variables as an example, the incomplete data obtains four variables from sensors and the remaining five variables are missing corresponding to the sensors 2, 4, 6, 8 and 9 in Table 2, respectively.
Table 4.
Details of missing data.
The DNN represents a traditional deep neural network while the deep transfer network (DTN) represents a deep neural network with transfer learning. This paper employs a stacked autoencoder to build the DNN model. DNN has a stacked autoencoder and the Softmax layer. The stacked autoencoder consists of four autoencoders. The values of training parameters and structure parameters of DNN and DTN are listed in Table 5. To simplify the description, details of the models are shown in Table 6.
Table 5.
The values of deep neural network (DNN) and deep transfer network (DTN) parameters.
Table 6.
The names and explanations of the models.
Remark 1.
Different network parameters have different diagnostic results. On the one hand, this paper applied trial-and-error method to find the optimal values of parameters which are listed in Table 5. No matter which group of network parameters is used, on the other hand, experimental results can clearly show the effect of the method proposed in the paper is better than non-migration methods.
In order to verify the effectiveness of this method, experiments are carried out at an incomplete data to structurally-complete data ratio of 60:1, 30:1 and 20:1 respectively. The results are shown in Table 7 and Figure 5 when the ratio of incomplete data to structurally-complete data is 60:1. Incomplete data has 600 samples for each type as training data. Structurally-complete data has 10 samples for each type as training data. Test data for structurally-complete and incomplete data has 2000 samples for each type respectively. The red star denotes actual output while the blue circle denotes the label in Figure 5. The first 2000 samples represent normal data recorded as label 1 and the second 2000 samples represent wheel pit recorded as label 2, and so forth. As the results indicate, the average accuracy of DNN is 41.55% while the average accuracy of DTNs are 65.64%, 67.57%, 73.48% and 78.31% respectively. DTNs are at least 24.09% higher on average than DNN. For all labels, the classification accuracies of DTNs perform significantly better than DNN. Especially for label 3, the accuracy of DTNs are at least 48.80% higher than DNN. The average accuracy of MCDTN4 is higher than MCDTN3. The average accuracy of MCDTN3 is higher than MCDTN2. Similarly, the average accuracy of MCDTN2 is higher than MCDTN1. The more information the data has, the better the effect after migration.
Table 7.
The accuracy of DNN and DTNs when the ratio of incomplete data to structurally-complete data is 60:1.
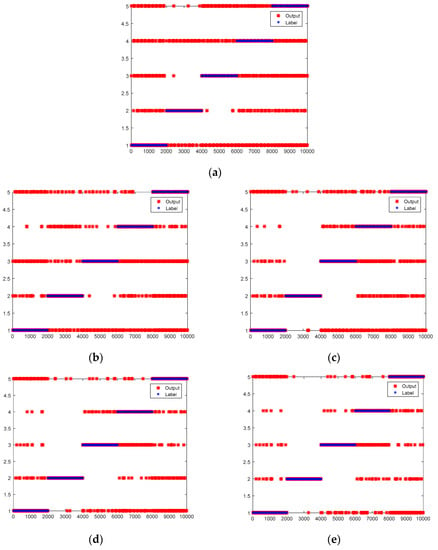
Figure 5.
Test results of DNN and DTNs when the ratio of incomplete data to structurally-complete data is 60:1. (a) CDNN; (b) MCDTN1; (c) MCDTN2; (d) MCDTN3; (e) MCDTN4.
When the ratio of missing data to structurally-complete data is 30:1, the results are indicated in Table 8. Incomplete data have 600 samples for each type as training data. Structurally-complete data have 20 samples for each type as training data. Test data for structurally-complete and incomplete data have 2000 samples for each type, respectively. Results show that the accuracy of DNN averages 53.89% while the average accuracy of DTNs are 68.58%, 73.78%, 77.67% and 82.64% respectively. On average, DTNs have at least 14.69% higher classification accuracy compared with DNN. For all labels, DTNs are higher in accuracy than DNN. For label 3, the accuracy of DTNs are at least 31.40% higher than DNN. Especially for label 2, the lowest accuracy of DTNs is 98.85% and the accuracy of DNN is 69.20%. The results of Table 8 show that MCDTN4 has the highest average accuracy, followed by MCDTN3, MCDTN2 and MCDTN1 in a descending order. It is consistent with the results of Table 7. But compared with Table 7, the average accuracy of the corresponding columns in Table 8 is higher than that of Table 7.
Table 8.
The accuracy of DNN and DTNs when the ratio of incomplete data to structurally-complete data is 30:1.
When the ratio of missing data to structurally-complete data is 20:1, the results are indicated in Table 9. The incomplete data have 600 samples for each type as training data. The structurally-complete data have 30 samples for each type as training data. Test data for structurally-complete and incomplete data have 2000 samples for each type, respectively. Results show that the accuracy of DNN averages 55.61% while the average accuracy of DTNs are 69.57%, 74.77%, 78.74% and 84.97% respectively. For all labels, DTNs are higher in accuracy than DNN. Especially for label 4, the accuracy of MCDTN4 is as high as 90.40% and the accuracy of CDNN is 35.00%. Similar to Table 7 and Table 8, the average accuracy of MCDTN4 is higher than the other three networks, following which MCDTN3 is the second and MCDTN2 is the third. MCDTN1 has the lowest average accuracy. As the number of complete samples increases, the average accuracy of the corresponding columns in Table 9 is higher than that of Table 8 and the average accuracy of the corresponding columns in Table 8 is higher than that of Table 7.
Table 9.
The accuracy of DNN and DTNs when the ratio of incomplete data to structurally-complete data is 20:1.
4.3. Transfer from Structurally-Complete Model to Missing Data Model
The accuracy of the fault diagnosis model based on missing data is not high because the missing data is incomplete. However, a well-trained fault diagnosis model of structurally complete data in the offline phase can in turn be used to diagnose the missing data. Through several migrations, training and optimization, a better structurally complete model can be obtained and in turn migrated to missing data. Incomplete data have 600 samples for each type. Test data of structurally-complete and missing data have 2000 samples for each type, respectively. Incomplete data model without transfer learning is only trained by incomplete data. A trained fault diagnosis model of structurally-complete data is transferred to an incomplete data model, in which we can get an incomplete data model with transfer learning.
The results are shown in Table 10. From the results, we can find that the average accuracy of incomplete data model with transfer learning is always higher than corresponding model without transfer learning. The accuracy of CMDTN3 reaches 95.19% and is 5.85% higher than MDNN3.
Table 10.
The accuracy of DNNs and DTNs when transferring from structurally-complete model to missing data model.
4.4. Online Diagnosis of Multi-Rate Sampling Data
The structurally complete DNN model obtained in Section 3.1 and the incomplete DNN models obtained in Section 3.2 are used in the online phase. Incomplete data with 5 missing variables, 4 missing variables, 3 missing variables and 2 missing variables accounted for 50%, 25%, 12.5% and 6.25% respectively. The results are shown in Table 11 and Figure 6. As results indicate, the average accuracy of online diagnosis models without transfer learning is 88.42% while the average accuracy of the models with transfer learning is 91.36%. For all labels, the classification accuracies of online diagnosis models with transfer learning perform better than those without transfer learning. Because incomplete data with 5 missing variables and 4 missing variables account for 75%, this result is consistent with the offline situation shown in Table 10.
Table 11.
The accuracy of online diagnosis of multi-rate sampling data without and with transfer learning.
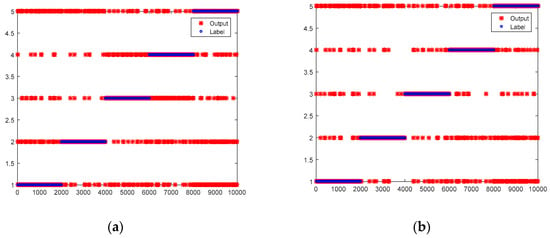
Figure 6.
Test results of online diagnosis models without and with transfer learning. (a) Online diagnosis models without transfer learning; (b) Online diagnosis models with transfer learning.
4.5. Analysis of Time Complexity
This paper employs a stacked autoencoder to build the DNN model. The DNN has a stacked autoencoder and a Softmax layer. The stacked autoencoder consists of four autoencoders. Let us suppose that an operation takes time as 1 unit. m is the number of samples; ni is the neuron number of input layer; n1, n2, n3 and n4 are the neuron number of 1st, 2nd, 3rd and 4th hidden layers respectively; s denotes the number of classifiers; is the number of iterations; nb represents batchsize; and c is the time spent in calculating gradients. As shown in Equations (36)–(39), the time complexity of AE1, AE2, AE3 and AE4 is , , and , respectively. The time complexity of Softmax and backpropagation is and , respectively. Thus, the time complexity of the traditional DNN is according to Equation (40).
The migration algorithm is summarized in three steps: 1. training source model and extracting fault features; 2. migrating these extracted features from source model to target model; and 3. training the target model based on transfer learning. The time complexity of step 1 is the same as that of a traditional DNN. The time complexity of step 2 is and the time complexity of step 3 is the same as step 1. So the time complexity of DTN is the same as that of DNN according to Equation (41).
In the offline phase, the running times of CDNN and MCDTNs are shown in Table 12 when the ratio of incomplete data to structurally-complete data is 20:1. By comparing the runtime, MCDTN runs about six times as long as CDNN. The time complexity of CDNN is in the same order of magnitude as that of MCDTNs. In the offline phase, the running time of MDNNs and CMDTNs is shown in Table 13. By comparing the runtime, CMDTN runs about three times as long as MDNN. The time complexity of MDNNs is in the same order of magnitude as that of CMDTNs. In the online phase, the running time of diagnosis models without transfer learning and with transfer learning for 10 000 online data are shown in Table 14. By comparing the runtime, diagnosis models with transfer learning run about the same time as diagnosis models without transfer learning.
Table 12.
The runtime of structurally-complete fault diagnosis model without and with transfer learning in offline.(unit: second).
Table 13.
The runtime of incomplete data fault diagnosis model without and with transfer learning in offline. (unit: second).
Table 14.
The runtime of online diagnosis models without and with transfer learning. (unit: second).
5. Conclusions and Future Work
In practical engineering, the sampling rates of different sensors may be different, which will lead to a rather small number of samples with complete structure. However, a large number of samples are required to ensure the efficiency of deep learning based fault diagnosis methods. This paper therefore proposes a fault diagnosis framework of missing data based on transfer learning. The suggested framework consists of three phases: transfer from fault diagnosis model of missing data to the model of structurally complete data, transfer from fault diagnosis model of structurally complete data to the model of missing data and real-time online diagnosis of multi-rate sampling data.
The paper utilities the QPZZ-II rotating machinery vibration experimental platform system to validate the effectiveness of the proposed framework. Results of experiments indicate that structurally-complete models with transfer learning always have higher fault diagnosis accuracy than those without transfer learning for every label when the ratios of missing data to structurally-complete data are 60:1, 30:1 and 20:1 respectively. As for the transfer from the fault diagnosis model of structurally complete data to the model of missing data, every missing data model with learning is higher in accuracy than the corresponding missing data model without learning. Therefore, we come to the conclusion that the proposed fault diagnosis framework based on transfer learning can improve the accuracy of both structurally complete and missing data models. On the one hand, the framework learns the information from the missing data and migrates obtained features from the missing data model to a structurally-complete model in order to increase the fault diagnosis accuracy of the structurally complete model. On the other hand, a well-trained structurally complete model is conversely transferred to the missing data model, which can in turn help with fault diagnosis in the case of missing data.
Finally, we need to point out that there still exists the limitation of the presented framework: negative transfer can occur when the ratio of incomplete data to structurally-complete data is 10:1. Our future research, thus, will aim to design a door mechanism to filter out negative information and further enhance the accuracy of fault diagnosis model with transfer learning.
Author Contributions
Conceptualization, D.C. and F.Z.; Methodology, D.C. and F.Z.; Project administration, F.Z.; Validation, D.C. and S.Y.; Visualization, D.C. and S.Y.; Writing—original draft, D.C.; Writing—review & editing, D.C. and F.Z.
Funding
This research was funded by the Natural Science Fund of China, grant No. U1604158, U1509203, 61751304, 61673160, 61802431. And the APC was funded by U1604158.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Chen, J.; Patton, R.J. Robust model-based fault diagnosis for dynamic systems. In The International Series on Asian Studies in Computer and Information Science; Springer: New York, NY, USA, 1999; Volume 3, pp. 1–6. [Google Scholar]
- Gao, Z.; Cecati, C.; Ding, S.X. A survey of fault diagnosis and fault-tolerant techniques-Part I: Fault diagnosis with model-based and signal-based approaches. IEEE Trans. Ind. Electron. 2015, 62, 3757–3767. [Google Scholar] [CrossRef]
- Verbert, K.; Babuska, R.; de Schutter, B. Bayesian and Dempster-Shafer reasoning for knowledge-based fault diagnosis-A comparative study. Eng. Appl. Artif. Intell. 2017, 60, 136–150. [Google Scholar] [CrossRef]
- Siontorou, C.G.; Batzias, F.A.; Tsakiri, V. A Knowledge-Based Approach to Online Fault Diagnosis of FET Biosensors. IEEE Trans. Instrum. Meas. 2010, 59, 2345–2364. [Google Scholar] [CrossRef]
- Park, J.-H.; Jun, B.-H.; Chun, M.-G. Knowledge-Based Faults Diagnosis System for Wastewater Treatment. In International Conference on Fuzzy Systems and Knowledge Discovery; Springer: Berlin/Heidelberg, Germany, 2005; pp. 1132–1135. [Google Scholar]
- Gao, Z.; Cecati, C.; Ding, S.X. A Survey of Fault Diagnosis and Fault-Tolerant Techniques—Part II: Fault Diagnosis With Knowledge-Based and Hybrid/Active Approaches. IEEE Trans. Ind. Electron. 2015, 62, 3768–3774. [Google Scholar] [CrossRef]
- Shen, Y.; Ding, S.X.; Haghani, A. A comparison study of basic data-driven fault diagnosis and process monitoring methods on the benchmark Tennessee Eastman process. J. Process Control 2012, 22, 1567–1581. [Google Scholar]
- Hofmann, M.O.; Cost, T.L.; Whitley, M. Model-based diagnosis of the space shuttle main engine. Artif. Intell. Eng. Des. Anal. Manuf. 1992, 6, 131–148. [Google Scholar] [CrossRef]
- Tidriri, K.; Chatti, N.; Verron, S.; Tiplica, T. Bridging data-driven and model-based approaches for process fault diagnosis and health monitoring: A review of researches and future challenges. Annu. Rev. Control 2016, 42, 63–81. [Google Scholar] [CrossRef]
- Xu, Y.; Sun, Y.; Wan, J.; Liu, X.; Song, Z. Industrial Big Data for Fault Diagnosis: Taxonomy, Review and Applications. IEEE Access 2017, 5, 17368–17380. [Google Scholar] [CrossRef]
- Liu, F.; Shen, C.; He, Q.; Zhang, A.; Liu, Y.; Kong, F. Wayside bearing fault diagnosis based on a data-driven doppler effect eliminator and transient model analysis. Sensors 2014, 14, 8096–8125. [Google Scholar] [CrossRef]
- Liu, T.; Chen, J.; Dong, G.; Xiao, W.; Zhou, X. The fault detection and diagnosis in rolling element bearings using frequency band entropy. J. Mech. Eng. Sci. 2012, 27, 87–99. [Google Scholar] [CrossRef]
- Ng, S.S.Y.; Tse, P.W.; Tsui, K.L. A One-Versus-All Class Binarization Strategy for Bearing Diagnostics of Concurrent Defects. Sensors 2014, 14, 1295–1321. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Deng, S.; Chen, X.; Li, C.; Sánchez, Re.; Qin, H. Deep neural networks-based rolling bearing fault diagnosis. Microelectron. Reliab. 2007, 75, 327–333. [Google Scholar] [CrossRef]
- Xie, J.; Du, G.; Shen, C.; Chen, N.; Chen, L.; Zhu, Z. An End-to-End Model Based on Improved Adaptive Deep Belief Network and Its Application to Bearing Fault Diagnosis. IEEE Access 2018, 6, 63584–63596. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Zhang, H.; Liang, T. Electric Locomotive Bearing Fault Diagnosis Using a Novel Convolutional Deep Belief Network. IEEE Trans. Ind. Electron. 2018, 65, 2727–2736. [Google Scholar] [CrossRef]
- Yin, J.; Zhao, W. Fault diagnosis network design for vehicle on-board equipments of high-speed railway: A deep learning approach. Eng. Appl. Artif. Intell. 2016, 56, 250–259. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhao, J. A deep belief network based fault diagnosis model for complex chemical processes. Comput. Chem. Eng. 2017, 107, 395–407. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.; Guo, L.; Lin, J.; Xing, S. A neural network constructed by deep learning technique and its application to intelligent fault diagnosis of machines. Neurocomputing 2018, 272, 619–628. [Google Scholar] [CrossRef]
- Sun, J.; Yan, C.; Wen, J. Intelligent Bearing Fault Diagnosis Method Combining Compressed Data Acquisition and Deep Learning. IEEE Trans. Instrum. Meas. 2018, 67, 185–195. [Google Scholar] [CrossRef]
- Sohaib, M.; Kim, C.-H.; Kim, J.-M. A Hybrid Feature Model and Deep-Learning-Based Bearing Fault Diagnosis. Sensors 2017, 17, 2876. [Google Scholar] [CrossRef] [PubMed]
- Lu, C.; Wang, Z.-Y.; Qin, W.-L.; Ma, J. Fault diagnosis of rotary machinery components using a stacked denoising autoencoder-based health state identification. Signal Process 2017, 130, 377–388. [Google Scholar] [CrossRef]
- Lv, F.; Wen, C.; Bao, Z.; Liu, M. Fault diagnosis based on deep learning. In Proceedings of the 2016 American Control Conference (ACC), Boston, MA, USA, 6–8 July 2016; pp. 6851–6856. [Google Scholar]
- Sun, W.; Shao, S.; Yan, R. Induction motor fault diagnosis based on deep neural network of sparse auto-encoder. J. Mech. Eng. 2016, 52, 65–71. [Google Scholar] [CrossRef]
- Zhao, H.; Sun, S.; Jin, B. Sequential Fault Diagnosis Based on LSTM Neural Network. IEEE Access 2018, 6, 12929–12939. [Google Scholar] [CrossRef]
- Wu, H.; Zhao, J. Deep convolutional neural network model based chemical process fault diagnosis. Comput. Chem. Eng. 2018, 115, 185–197. [Google Scholar] [CrossRef]
- Wen, L.; Li, X.; Gao, L.; Zhang, Y. A New Convolutional Neural Network-Based Data-Driven Fault Diagnosis Method. IEEE Trans. Ind. Electron. 2018, 65, 5990–5998. [Google Scholar] [CrossRef]
- Wang, T.; Wu, H.; Ni, M.; Zhang, M.; Dong, J.; Benbouzid, M.E.H.; Hu, X. An adaptive confidence limit for periodic non-steady conditions fault detection. Mech. Syst. Signal Process. 2016, 72, 328–345. [Google Scholar] [CrossRef]
- Lu, W.; Liang, B.; Cheng, Y.; Meng, D.; Yang, J.; Zhang, T. Deep Model Based Domain Adaptation for Fault Diagnosis. IEEE Trans. Ind. Electron. 2017, 64, 2296–2305. [Google Scholar] [CrossRef]
- Han, T.; Liu, C.; Yang, W.; Jiang, D. Deep Transfer Network with Joint Distribution Adaptation: A New Intelligent Fault Diagnosis Framework for Industry Application. arXiv, 2018; arXiv:1804.07265. [Google Scholar]
- Cao, P.; Zhang, S.; Tang, J. Preprocessing-Free Gear Fault Diagnosis Using Small Datasets With Deep Convolutional Neural Network-Based Transfer Learning. IEEE Access 2018, 6, 26241–26253. [Google Scholar] [CrossRef]
- Zhang, R.; Tao, H.; Wu, L.; Guan, Y. Transfer Learning With Neural Networks for Bearing Fault Diagnosis in Changing Working Conditions. IEEE Access 2017, 5, 14347–14357. [Google Scholar] [CrossRef]
- Zhu, J.; Ge, Z.; Song, Z.; Gao, F. Review and big data perspectives on robust data mining approaches for industrial process modeling with outliers and missing data. Annu. Rev. Control 2018, 46, 107–133. [Google Scholar] [CrossRef]
- Hu, Q.; Zhang, R.; Zhou, Y. Transfer learning for short-term wind speed prediction with deep neural networks. Renew. Energy 2016, 85, 83–95. [Google Scholar] [CrossRef]
- Yang, Q.; Wu, X. 10 challenging problems in data mining research. Int. J. Inf. Technol. Decis. Mak. 2006, 5, 597–604. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Han, D.; Liu, Q.; Fan, W. A new image classification method using CNN transfer learning and web data augmentation. Expert Syst. Appl. 2018, 95, 43–56. [Google Scholar] [CrossRef]
- Kaya, H.; Gürpinar, F.; Salah, A.A. Video-based emotion recognition in the wild using deep transfer learning and score fusion. Image Vis. Comput. 2017, 65, 66–75. [Google Scholar] [CrossRef]
- Ding, Z.; Fu, Y. Robust Transfer Metric Learning for Image Classification. IEEE Trans. Image Process. 2017, 26, 660–670. [Google Scholar] [CrossRef]
- Zoph, B.; Yuret, D.; May, J.; Knight, K. Transfer Learning for Low-Resource Neural Machine Translation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1568–1575. [Google Scholar]
- Yang, X.; McCreadie, R.; Macdonald, C.; Ounis, I. Transfer Learning for Multi-language Twitter Election Classification. In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2017, Sydney, Australia, 31 July–3 August 2017; pp. 341–348. [Google Scholar]
- Turki, T.; Wei, Z.; Wang, J.T.L. Transfer Learning Approaches to Improve Drug Sensitivity Prediction in Multiple Myeloma Patients. IEEE Access 2017, 5, 7381–7393. [Google Scholar] [CrossRef]
- Cao, H.; Bernard, S.; Heutte, L.; Sabourin, R. Improve the Performance of Transfer Learning Without Fine-Tuning Using Dissimilarity-Based Multi-view Learning for Breast Cancer Histology Images. In International Conference Image Analysis and Recognition; Springer: Cham, Switzerland, 2018; pp. 779–787. [Google Scholar]
- Du, Y.; Zhang, R.; Zargari, A.; Thai, T.C.; Gunderson, C.C.; Moxley, K.M.; Liu, H.; Zheng, B.; Qiu, Y. A performance comparison of low- and high-level features learned by deep convolutional neural networks in epithelium and stroma classification. Med. Imaging Digit. Pathol. 2018, 10581, 1058116. [Google Scholar]
- Jiang, Y.; Chung, K.Fu.; Ishibuchi, H.; Deng, Z.; Wang, S. Multitask TSK Fuzzy System Modeling by Mining Intertask Common Hidden Structure. IEEE Trans. Cybern. 2015, 45, 548–561. [Google Scholar]
- Wu, D. Online and Offline Domain Adaptation for Reducing BCI Calibration Effort. IEEE Trans. Hum.-Mach. Syst. 2017, 47, 550–563. [Google Scholar] [CrossRef]
- Jiang, Y.; Wu, D.; Deng, Z.; Qian, P.; Wang, J.; Wang, G.; Chung, F.-L.; Choi, K.-S.; Wang, S. Seizure Classification From EEG Signals Using Transfer Learning, Semi-Supervised Learning and TSK Fuzzy System. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 25, 2270–2284. [Google Scholar] [CrossRef]
- Available online: http://www.pudn.com/Download/item/id/3205015.html (accessed on 20 July 2018).






© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).