1. Introduction
Image super-resolution (SR) has become a hot research topic to improve the image resolution by means of software algorithm. The key is to obtain an estimation of a High Resolution (HR) image from the Low Resolution (LR) input. Usually, Infrared (IR) detectors can be used for night video monitoring, biomedicine, forest fire fighting and safe driving. However, IR images captured by infrared imaging devices always suffer from low resolution, low contrast and blur details. Therefore, it is more difficult to extract information of interesting objects from IR images than that of color images.
Traditional research on image super-resolution mainly focuses on two aspects. One is trying to find the mapping relationship between HR and LR images with respect to pixels or local patches, which always involves Neighbor Embedding (NE) and Anchored Neighborhood Regression (ANR). Hong Chang introduced Neighbor Embedding [
1], which can be reconstructed by its neighbors in the feature space and not highly depend on sample. Howerver, the number of fixed neighborhoods would cause overfitting or under-fitting problems. Radu Timofte, et al. proposed Anchored Neighborhood Regression [
2,
3] which takes the dictionary atom as the neighborhood to reduce the operational complexity and running time, but it loses flexibility. The other kind of method is sparse coding, which aims to learn the similarity between LR and HR patches via large datasets. Jianchao Yang presented the sparse coding algorithm [
4,
5] via patch-based sparse coding and two dictionaries to achieve the image super resolution, which has great improvement in SR (super-resolution) quality. However, the dictionary is not complete and the image edge quality is not high. In summary, the traditional algorithm has limited SR effect on image super-resolution, and its speed is not fast.
Recently, end-to-end learning methods were successfully applied into the field of SR, object detection, obstacle recognition [
6]. Dong et al. firstly combined the Convolutional Neural Network (CNN) method with SR, and proposed the Super Resolution Convolution Neural Network (SRCNN [
7]) algorithm and Fast SRCNN (FSRCNN [
8]), with better performance than traditional algorithms. J. Kim et. al proposed the Very Deep Convolutional Networks (VDSR [
9]), which has 20 convolution layers to further exploit context information. To avoid the overfitting of deep networks, J. Kim et al. introduced the Deeply-Recursive Convolutional Network (DRCN [
10]) with residual structure and skip-connections. In the last two years, many modules were dated to solve low resolution problems. Jiayi Ma [
11] presented a dense discriminative network that is composed of several aggregation modules (AM) and aggregate features progressively in an efficient way. Still, the above algorithm deep learning network can only process a single data source, and can only use the characteristics of a single sensor. There are certain limitations to enhancing details. There are also some limitations can only handle a single sensor image.
Meanwhile, various approaches via multi-source data (infrared image and color image) were proposed to increase the image high-frequency information as much as possible [
12]. To solve the problems of lighting, T. Y. Han [
13] proposed a method which fuses multiple LR images taken at different camera positions to synthesize a HR image. C. W. Tseng [
14] proposed a network in which infrared images and color images are concatenated as input to construct a high-resolution IR image. However, as single-input networks, these algorithms ignore the high-frequency information of visible images captured by visible detectors. In addition, most networks have not got trained network models that take paired infrared and visible images. To solve this problem, we propose a network to mine information of visible image for high-resolution images reconstruction. The network has multi-modal input of infrared and visible light images to make full use of the feature information of multiple sensors.
Infrared detectors can clearly display target images at night or partially occluded. In the limitation to the hardware system of Infrared detectors, the infrared images have a few problems: low resolution, blurring, and random noise. Apart from training convolutional networks with multi-sensors images as input, the key to achieving infrared image super-resolution is the removal of infrared noise. In this paper, we applied guided filter [
15] to suppress the noise in IR images.
The structure of our RGB-IR cross input and sub-pixel up-sampling network is shown in
Section 3. The main contributions are listed as follows: (1) Paired IR and RGB images are used as inputs, unlike most existing works which only take single-sensor images. (2) Sub-pixel convolution is applied to extract multi-channel features from RGB images, which is used to enhance the IR image. (3) Guided filter layer is adopted to reduce the influence of noise in IR images, which makes the IR image reconstruction effective. (4) Dataset of IR-COLOR2000 is captured by ourselves for training ideal network.
The specific operation is as follows. First, a guided filter layer is introduced to suppress the noise in IR images. Then, the RGB image is convoluted by sub-pixel convolution filter to obtain feature images, and the HR image is represented by the sum of the RGB image feature and IR upsampling image feature. In addition, we take our dataset, called IR-COLOR2000, as the dataset for training the ideal network. Finally, experimental results show that the proposed algorithm is superior to several comparison algorithms.
The remainder is organized as follows.
Section 2 mainly contains the convolutional neural network for image SR, the existing datasets for super SR domain, and infrared image denosing algorithm.
Section 3 presents the RGB-IR cross input and sub-pixel upsampling model, the importance of guided filter layer and sub-pixel convolution model.
Section 4 follows the algorithm simulation for IR image and RGB image, respectively. Finally, conclusions are drawn in
Section 5.
3. The Proposed Algorithm
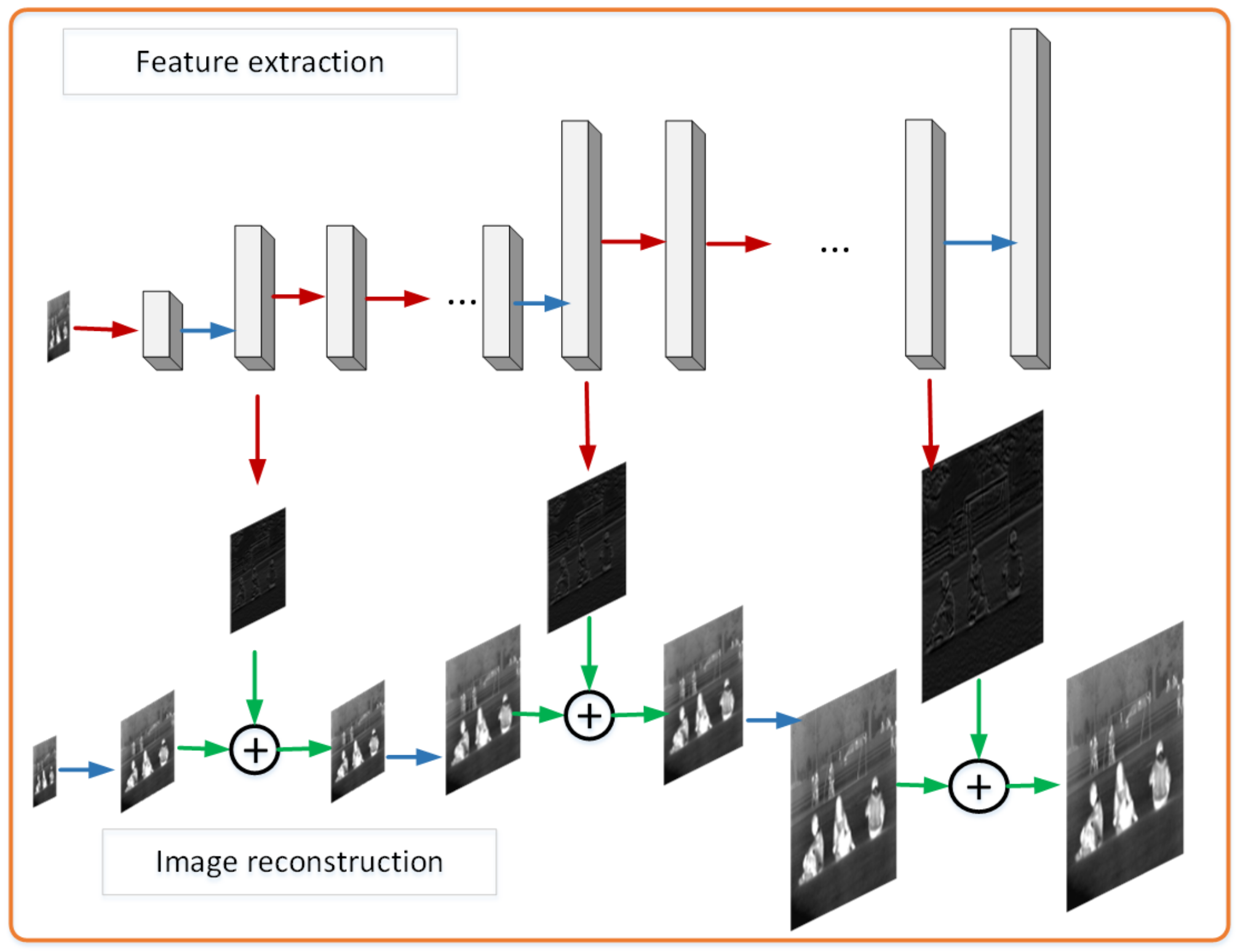
In this section, based on LapSRN, this paper improves the LapSRN in three aspects for the characteristics of infrared images. we describe the proposed RGB-IR cross input and sub-pixel upsampling network. In the proposed network (
Figure 3), pairs of IR and RGB images are used as input together, sub-pixel convolution is applied to optimize feature extraction network and a guided filter layer is adopted to reduce the influence of noise in IR images.
Several defects in IR image reconstruction, such as background noise, low contrast, and blur, result in bad performance. Therefore, an improved LapSRN based on IR-RGB images is presented to deal with IR image SR. RGB-IR cross input and sub-pixel upsampling network is also made up of RGB image feature extraction and IR image reconstruction. Sub-pixel convolution excels deconvolution in image upsampling to optimize feature extraction network especially. Moreover, the guided filter layer plays an important role in infrared image denoising and edges preserving.
3.1. RGB-IR Cross Input and Sub-Pixel Upsampling Network
Not to increase the depth of the network, the multi-modal image is used as input in our network for more details. That is, features of the visible image are add in infrared image reconstruction.
It is superior to other networks in that the proposed model includes sub-pixel layer for upsampling and a guided filtering layer for infrared image denoising. As
Figure 3 shows, the features from RGB image is extracted by feature extraction group which concatenates the feature from “convolution” → “Relu” → “convolution” → “Relu” →⋯→ “sub-pixel convolution” → “convolution”. Then, the features from RGB images are added to the reconstruction of infrared images that go through “guided filtering” and “Deconvolution” to up-sampling processing. In this way, each image feature and infrared feature combination will enlarge the image scale by two times. Multi-scales
image super-resolution needs to pass the feature to the next level for
N feature extraction, and the infrared feature upsampling process, finally completes the reconstruction convolution. The detail information such as the kernel functions, depths and I/O dimensions of all “convs” in “Feature Extraction” and “Image Reconstruction” branches are shown in
Table 2.
Network-intermediate layer images include feature image ×2, feature image ×4, and denoising results. Two sets of images are listed in
Figure 4 which are the images of the middle layer in the proposed network at ×4 scale.
Residuals output of different scales and corresponding scale reconstruction results are obtained through cascade learning. The branch of image feature extraction takes RGB image as input to extract detailed features for the reconstruction of infrared image, and gradually samples and adds feature images of the same scale in the process of image reconstruction.
The feature extraction network extracts the visible image features, and upsamples the feature image through the sub-pixel convolution layer, and upsamples infrared image via the transposed convolution in the infrared image reconstruction, and the output image size is twice than the input image. When the super-resolution reconstruction scale is ×2, ×4, and ×8, the sub-pixel upsampling network feature extraction and the infrared image reconstruction upsampling operation are repeated m times (m = 1, 2, 3 ). The upsampling layer extracts image feature via a sub-pixel convolution layer. In each sub-pixel convolution part, the upsampled feature image is twice the size of its former feature image. It is worth noting that the input in the upsampling layer is IR images, and the RGB image is another input in the part of the feature extraction, which gives more detail information compared to handle SR.
3.2. Sub-Pixel Convolution
Taking into account that direct interpolation of deconvolution upsampling causes image blur, we have to use progressive upsampling for network upsampling and use subpixel convolution instead of deconvolution to reduce the loss of detail in the upsampling process. Sub-pixel convolution combines pixel values of multiple channels into one feature map, thus adding features in the network and changing the feature image size.
The sub-pixel layer plays a role as upsampling achieved by sub-pixel convolution in the extraction network. In contrast with upsampling, sub-pixel convolution combines feature images from multiple channels into one image. Pixel values in feature images are multiple channels value at the same position. The sub-pixel convolution layer can upscale the final LR feature maps into the HR output in the paper [
34]. The feature map
is the input of sub-pixel upsampling layer;
is the output of sub-pixel upsampling layer;
and
is sub-pixel upsampling layer parameters. The implementation of sub-pixel convolution can be expressed as where
( ) is sub-pixel convolution operation, called shuffle. That operation changes the feature shape from
tensor to
. The effects of sub-pixel convolution operation are shown in
Figure 5. Sub-pixel convolution combines a single pixel on a multi-channel feature into a single pixel on a feature.
Figure 5 shows the operation of sub-pixel convolution intuitively. To upsample the feature map of
r times size, we need to generate
feature maps of the same size. The operation of sub-pixel convolution is to assemble
same size feature maps into a larger
r times map.
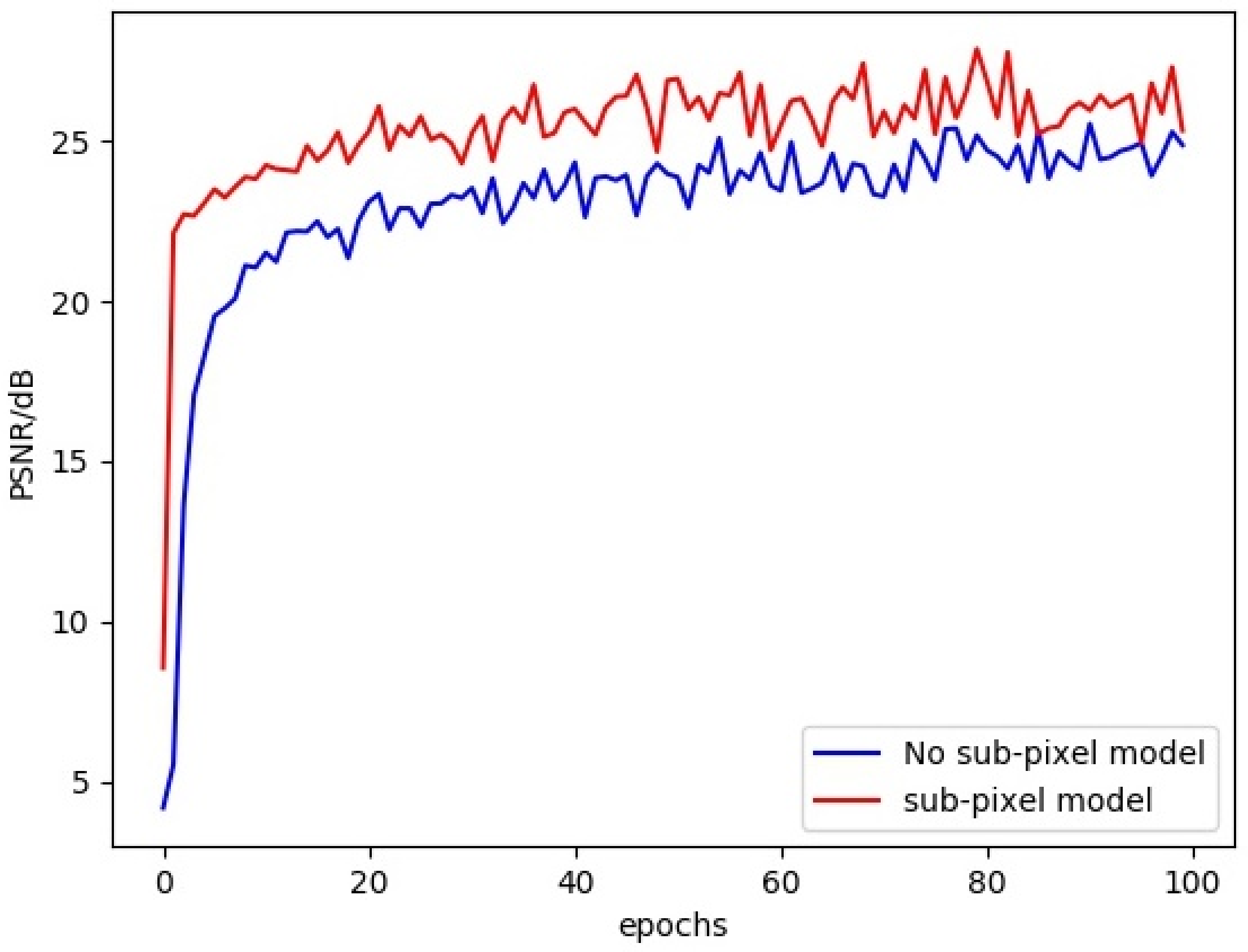
For the sake of improving and optimizing the network, sub-pixel convolution is used instead of deconvolution for image upsampling. Sub-pixel convolution avoids the danger of large numbers of zeros in general deconvolution. Besides, As can be seen from the comparison training in
Figure 6, the sub-pixel convolution module has always had an absolute advantage over the simple upsampling in training 100 epochs on the dataset of IR-COLOR2000 for ×4 SR.
To prove the benefits of sub-pixel convolution, comparative experiments were conducted between networks with transposed convolutions and networks with sub-pixel convolution to improve network performance and rich feature details. As can be seen from the comparison training in
Figure 6, the sub-pixel convolution module has always had an absolute advantage over the simple upsampling in training 100 epochs. The sub-pixel upsampling network in the feature extraction model makes full use of sub-pixel convolution. The experiment result shows that sub-pixel convolution is used for image feature extraction, which greatly improves the signal-to-noise ratio (PSNR) of the image.
3.3. Guided Filter Layer
Apart from training convolutional networks for more detail infrared image, the key to achieve infrared image super-resolution is the removal of infrared noise. It is necessary to enhance the infrared image and remove noise for uncooled long-wave infrared images containing noise. A denoising method is needed to eliminate noise and enhance the image in convolutional networks. Guided filtering has edge-preserving and denoising. It is through the network to train the guided filter parameters for image denoising enhancement.
The influence of noise can be reduced by the guided filter method. Furthermore, an RGB image is used as the guidance to complete IR image SR. The guided filter layer of this article is identical to the previous works in principle. The guided images we use are different. Generally, the input image is used as a guided image to maintain the edge. In this paper, the corresponding RGB image is used as a guided image to reduce the noise of the infrared image.
The guided filter process is linear translation-variant, and the output
q is obtained by the guided filtering method of the input and the guidance
I.
where,
and
are the linear coefficients with restriction of the window
;
k is the center point of
window. In the filtering calculation,
i represents the pixels of the window
.
To seek a solution of minimizing the difference between output image
q and input image
p, it can also maintain the linear model Equation (
4). The Equation (
5) is the cost function in the window
.
is a penalizing parameter.
Here, and are respectively represented as the mean and variance of I in , is the number of pixels in and is the mean of p.
The flow chart and step of the presented algorithm are shown in Algorithm 1 and
Figure 3, respectively.
| Algorithm 1 Guided Filtering Layer for image processing |
| Input: low-resolution IR image |
| low-resolution RGB image |
| Radius r and Regularization term |
| Output: Guided filtered image as output |
| 1. mean matrix calculation: |
| 2. mean matrix calculation: |
| 3. Correlation calculation: |
| 4. , Correlation calculation: |
| 5. Variance calculation: |
| 6. , Covariance calculation: |
| Calculate guided filtering parameters and according to Equations. (6-7): |
| 7. |
| 8. |
| 9. |
| /* is a mean filter |
To eliminate image noise the guided filter layer was trained in the RGB-IR cross input and sub-pixel upsampling model, then compare the SR effect on the synthetic data, such as images added salt & pepper noise. The noise image as input is illustrated in
Figure 7, to perform image super resolution simulation and check whether the model is sensitive to noise. In
Figure 7, the denoising ability of algorithms was analyzed and judged by the difference image between the noise image and the SR result. The less information contained in the difference image, the better the image SR result and the denoising effect. In
Figure 7, it can be clearly seen that the proposed method is better than the comparison algorithm. It can be seen from
Figure 7 that the proposed method has a good effect of removing noise. However, it can be seen from the value of PSNR that the salt & pepper noise has a bad influence on the image SNR.
It is observed that four noise images referring to the A+ method and the SRCNN method still contain much noise and lose edge or texture information. However, both the VDSR method and the proposed method do well to reduce image noise. For further comparison, the proposed method is superior to the VDSR algorithm in a subjective visual sense. In summary, the guided filter can improve image quality and reduce IR noise effectively.
3.4. The Loss Function of Multi-scale
The network uses 2×, 4×, and 8× samples to train multi-scale super-resolution models. It is necessary to construct network structures at different scales (2, 4, 8) and reduce the differences between SR images and HR images at different scales.
We note that the is Charbonnier loss, and the scale in loss is upsampling scales for SR.
4. Experiment Results
4.1. Training & Testing
In this section, all experiments are implemented in Matlab 2016a on a PC with GPU Titan V, 12 GB RAM in ubuntu 16.04 system.
The training datasets (IR-COLOR2000), which contain 2000 pairs of images, are captured by ourselves. The images in the datasets main contain the infrared images and corresponding RGB images. Especially, we crop each input image into patches with a size of 128 × 128. The samples were generated by the operators of flipping horizontally and flipping vertically or rotating 90, 180, 270. After the training is completed, the pre-trained model will be able to make 2×, 4× SR respectively. When testing, just select the model and enter the image to be tested.
We simultaneously conduct extensive evaluations of existing super-resolution models as baselines on our IR-COLOR2000 datasets. Then, the performance of several deep models, including the proposed RGB-IR cross input and sub-pixel upsampling network are evaluated. Three sets of experiments are performed: (1) Three pairs of IR images and RGB images as input respectively, we compare the effects of SR with single image input and two image input; (2) SR performance comparisons with state-of-the-arts algorithm by the upsampling scale of 2 and 4. we introduce the datasets for training and testing as follows.
Qualitative and quantitative performance of our model in comparison with state-of-the-art ones: A+, SCSR, SCN [
35], SRCNN, VDSR, LapSRN, are presented as follows to evaluate the results. Peak Signal Noise Rate (PSNR) and Self-Similarity (SSIM) are used as the quality metric to evaluate the performance of all methods. Besides, visual comparisons on IR-COLOR2000 dataset are shown in
Figure 8,
Figure 9 and
Figure 10 with the scale factor of 2. SR quantitative results of scale ×2 and ×4 are given in
Table 3. In
Figure 8, regions highlighted by green rectangles are magnified, and the difference between SR image and ground truth is clear for easy visual inspection. The result of RGB-IR cross input and sub-pixel upsampling network performance well in image reconstruction and simulation run at high speed.
We use PSNR and SSIM to evaluate the performance of our datasets. SSIM metric indicated the pixel similarity and local structure similarity between reconstructed HR image and ground truth. In
Table 3, the performance of the proposed method is higher than A+, SCSR, SCN, SRCNN, VDSR, DRCN, LapSRN, especially on a scale of 4.
Figure 8,
Figure 9 and
Figure 10 show SR experiment results by different algorithms. Reconstructed contextual information of the proposed method including edges and textures more clear than the others such as ailing in the Building, the waistcoat of Laborer, and the head of the man in
Figure 8,
Figure 9 and
Figure 10.
4.2. Comparison to the State-of-the-Art
Since the previous image super-resolution reconstruction is pure infrared image super-resolution or visible image super-resolution. Furthermore, the existing input multi-modal data is all for image fusion, no dual input super-resolution reconstruction algorithm for images. For the sake of fairness, this paper makes more comparisons with single-input super-resolution reconstruction algorithms. Different from image fusion, this paper uses infrared and visible images for image super-resolution. Pairs of IR images and RGB images as input respectively, we compare the effects of SR with single image input and two images. To compensate for the contrast algorithm without double input, I will increase more single input super-resolution contrast experiments. Three pairs of images from the KAIST [
36] and OutdoorUrban [
37] dataset are used to test the performance of the proposed algorithm under low illumination.
To further highlight the performance of our SR method, a set of images in low light were selected for simulation experiments in
Figure 11. OutdoorUrban dataset is images fusion datasets made by Nigel J. W. Morri in the
Statistics of Infrared Images [
37]. The contrast of the 4× scales experiment is performed by a set of dimly light images using the algorithms Bicubic, DRCN [
10], RDN [
38], SRGAN [
39], CGAN [
40] and WGAN [
41] and proposed method which embedded the visible features into the infrared image in
Figure 12. The PSNR and SSIM of
Figure 11 and
Figure 12 are shown in
Table 4.
The experiment on night images from the KAIST dataset is shown in
Figure 12. Clear RGB images is helpfuly for infrared images recovery, and improved SR results can be seen in
Figure 12h. Also, the reconstruction image makes the inconspicuous features of infrared image clearer, which is consistent with human visual features. However, when the RGB Image is not clear enough, our method hasn’t any advantages of the image SR. It is obvious that the partial brightness of the lamp in the figure is different when the super-resolution scale is four times and two times, and the effect of the proposed method is indeed better than the others especially the evaluation values in
Figure 12.
4.3. Analysis& Discussion
Six pairs of images from KAIST [
36] and OutdoorUrban [
37] dataset respectively as
Figure 13 are chosen for SR experiments on A+, SCSR, SRCNN, DRCN, SRGAN, WGAN, CGAN, and our method. Infrared images and visible images are from two datasets of OutdoorUrban and KAIST.
Figure 13a,b are in slightly weak light;
Figure 13c,d are in low light;
Figure 13e,f are in normal light. The PSNR and SSIM of
Figure 13 are in
Table 4.
Further verifying the stability of the algorithm, the data in KAIST and OutdoorUrban are chosen for quality comparison in
Table 4.
The CGAN, WGAN, SRGAN, and RDN in
Table 4 are not models for infrared images, so the experimental results are not optimal. The data in
Table 4 shows that the algorithm in this paper is more stable than RDN and GAN-based methods under weak light and normal light conditions. The Evaluation indexes of
Table 4 marked in blue are the best results of image SR. When visible light is low, the algorithm in this paper loses some advantages. In general, it can be seen from the mean signal-to-noise ratio of the six groups of experiments that the proposed algorithm is more stable than other algorithms.
To prove that infrared image noise reduction is effective for super-resolution networks, we conducted an experiment on three pairs of images from the OutdoorUrban [
37] dataset. We use the proposed algorithm to reconstruct the above three pairs of images as shown in
Figure 14 and calculate the image quality evaluation results. The results without denoising process are shown in
Figure 14a and the results with denoising are shown in
Figure 14b.
As can be seen in
Figure 14, the results of group (b) are better than that of group (a). For the evaluation values of PSNR and SSIM, it can be noticed that the PSNR of (b) is nearly 1dB higher than (a). In addition, the image similarity parameters SSIM has not decreased significantly. This indicates that our denoising scheme can improve performance.
Since RGB-IR cross input and sub-pixel upsampling network make full use of the advantage of multiple model images, the network obtained a larger receptive field and less noise infrared image. Experimental results show that the proposed algorithm is very successful and effectively to improve image resolution.
4.4. Running Time
In this work, we can design and train different pre-trained models. Also, we need not train the model with odd scales, because the proposed network could handle the upsampling rate is odd. When dealing with an odd scale such as 3×, the input image is upsampled to the nearest scale by 4×, then the super-resolution result is downsampled to the target scale. Moreover, our method is less time consumption in comparison to the methods A+, SCN, SRCNN, VDSR, DRCN, RDN [
38], SRGAN [
39], CGAN [
40] and WGAN [
41] as illustrated in
Table 5.
The running time is related to the depth and the input size of the network. The structure of SCN, SRCNN, and VDSR are relatively simple, but the input image size is larger than our proposed network because the input of that three networks are directly up-sampled to the ideal size, but our algorithm is gradually up-sampled to the ideal size. Thus the inference time of our proposed is shorter than these networks. The structure of DRCN, RDN, SRGAN, CGAN, and WGAN algorithms are deeper than our algorithm, which corresponds to longer inference time.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





