Computationally Efficient Wildfire Detection Method Using a Deep Convolutional Network Pruned via Fourier Analysis



Abstract
:1. Introduction
- We prune and slim the convolutional and dense layers according to frequency response of kernels using Fourier analysis in order to accelerate the inference of the neural network and save storage. Details of this aspect are provided in Section 3.1 and Section 3.2.
- We detect wildfire in overlapping windows so we can easily detect smoke even if it exists near the edge of a frame. We achieve this by dividing the frame in many blocks and detecting the smoke block-by-block. Details of this aspect are provided in Section 4.
- Compared to R-CNN [30,31], and YOLO method [34,35], our block-based analysis makes the building of testing and training datasets easy because we mark only the blocks containing fire. We only need to label each block as fire or no-fire instead of marking the region of fire and smoke in a given frame using several bounding boxes. Making and updating the dataset in our method is much easier compared to R-CNN and YOLO method. In wildfire surveillance task, knowing the fire in which image block is sufficient for fire departments to take action. In addition, compared to frame-based methods, block-based analysis allows us to determine capture very small fire regions and smoke.
- The input of our system is in 1080P and it can also be adjusted for higher resolution. Thus, our method matches common surveillance cameras, since down-sampling always causes information loss and may make small regions of smoke invisible. According to our experimental results, our method works well even if the smoke region is very small.
- After testing the performance on daytime surveillance and obtaining a very good result, we further tested our system system with night events, and it works on many video clips.
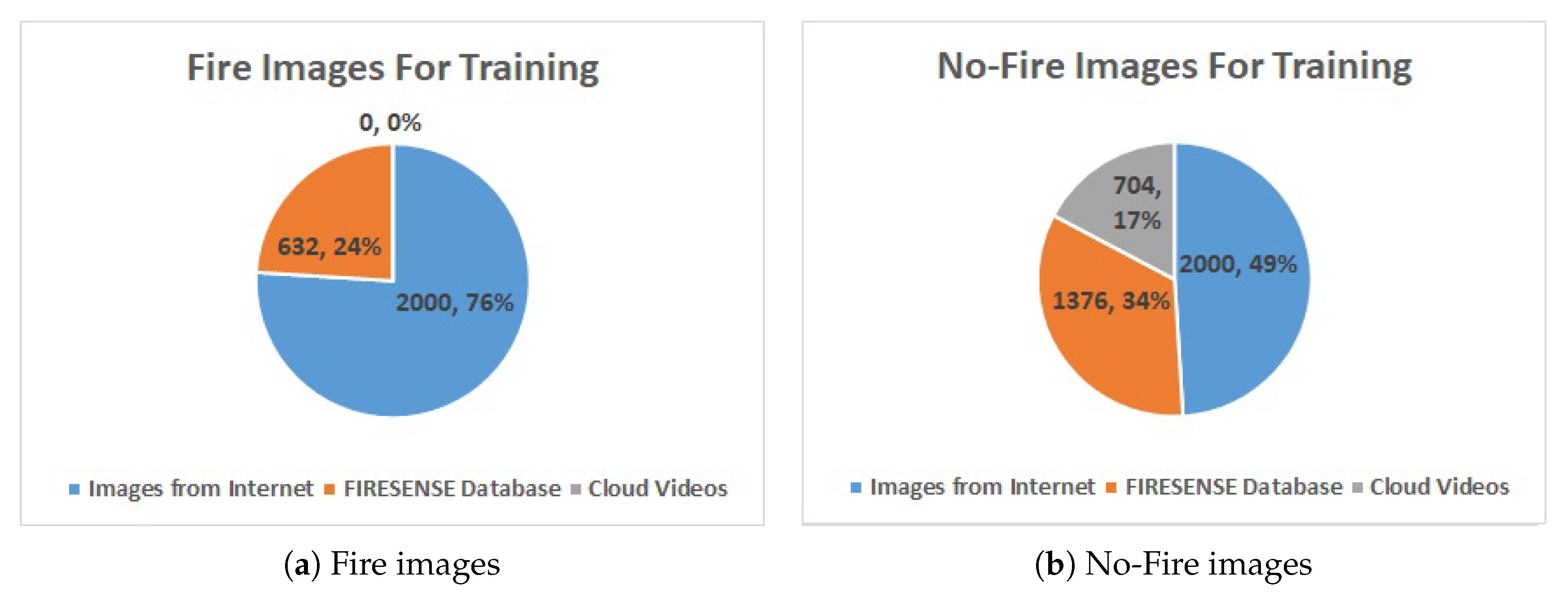
2. Dataset for Training
3. Fourier Transform Based Pruning the Network
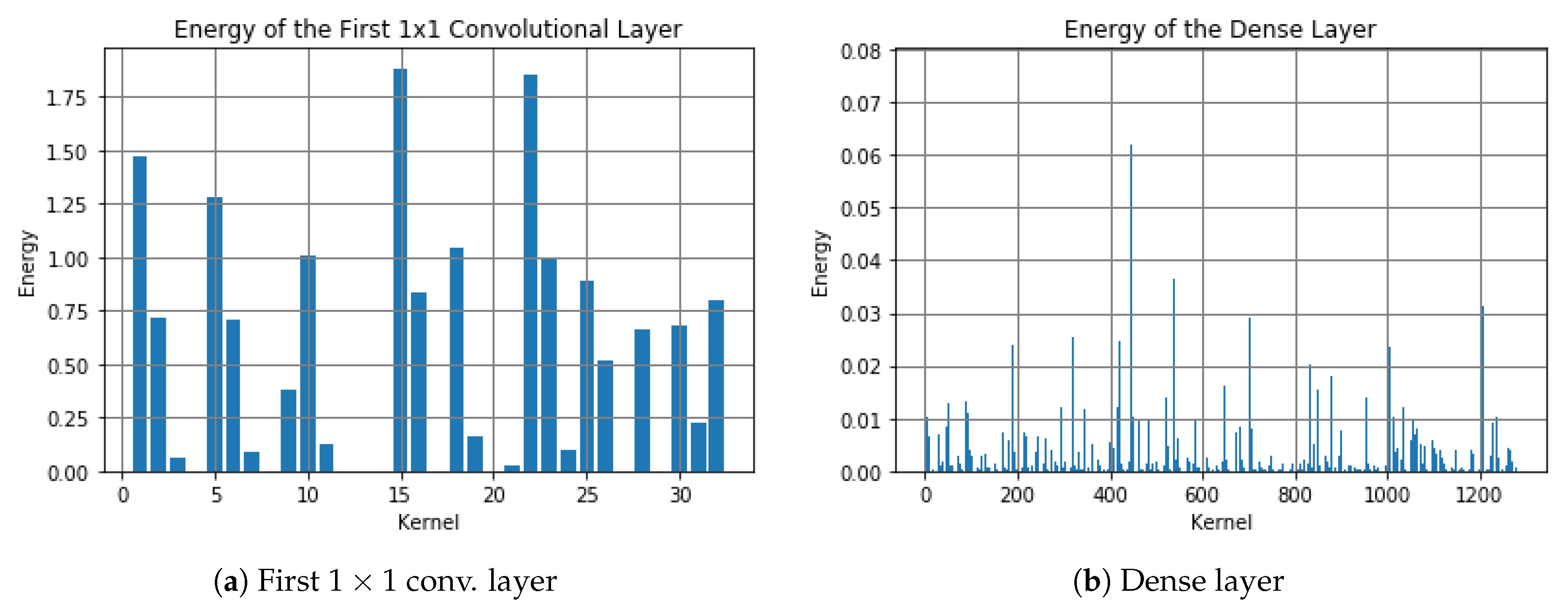
3.1. Pruning Low-Energy Kernels
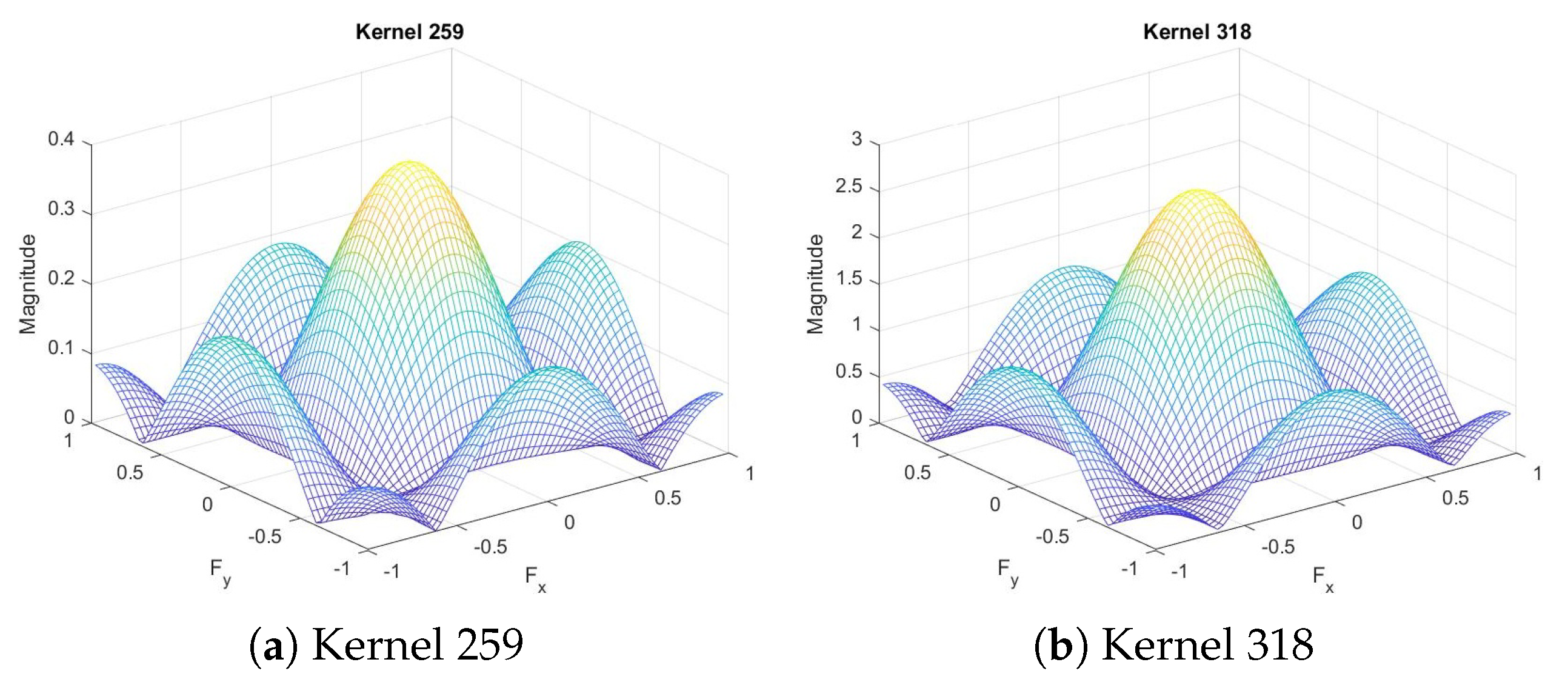
3.2. Slimming Similar Kernel Pairs
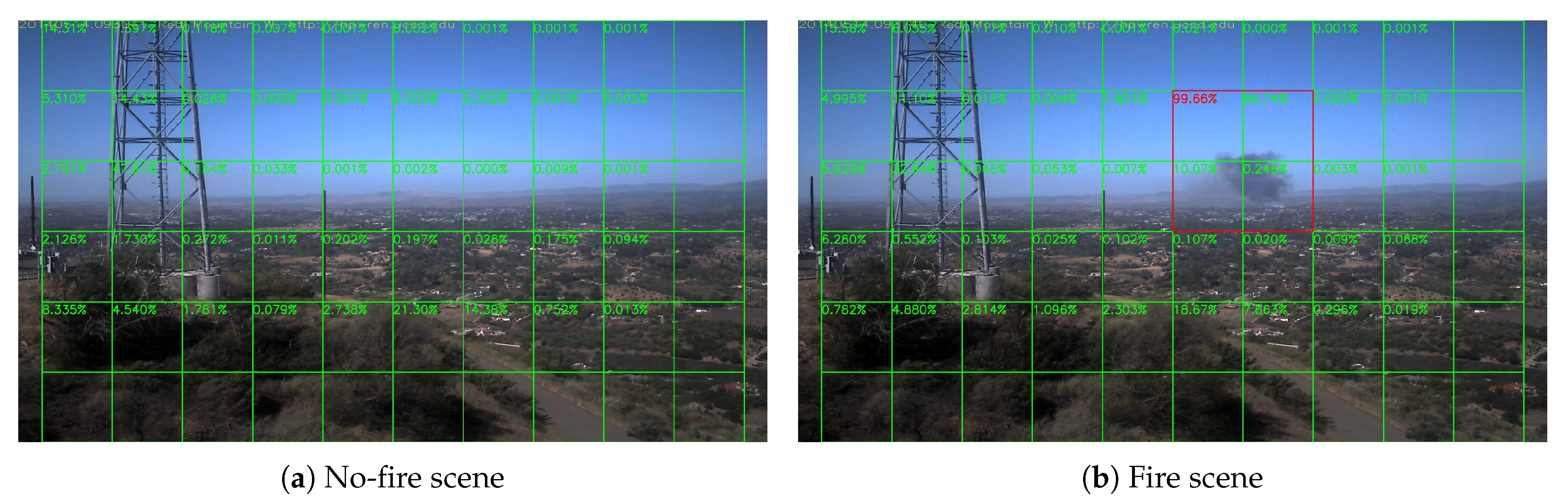
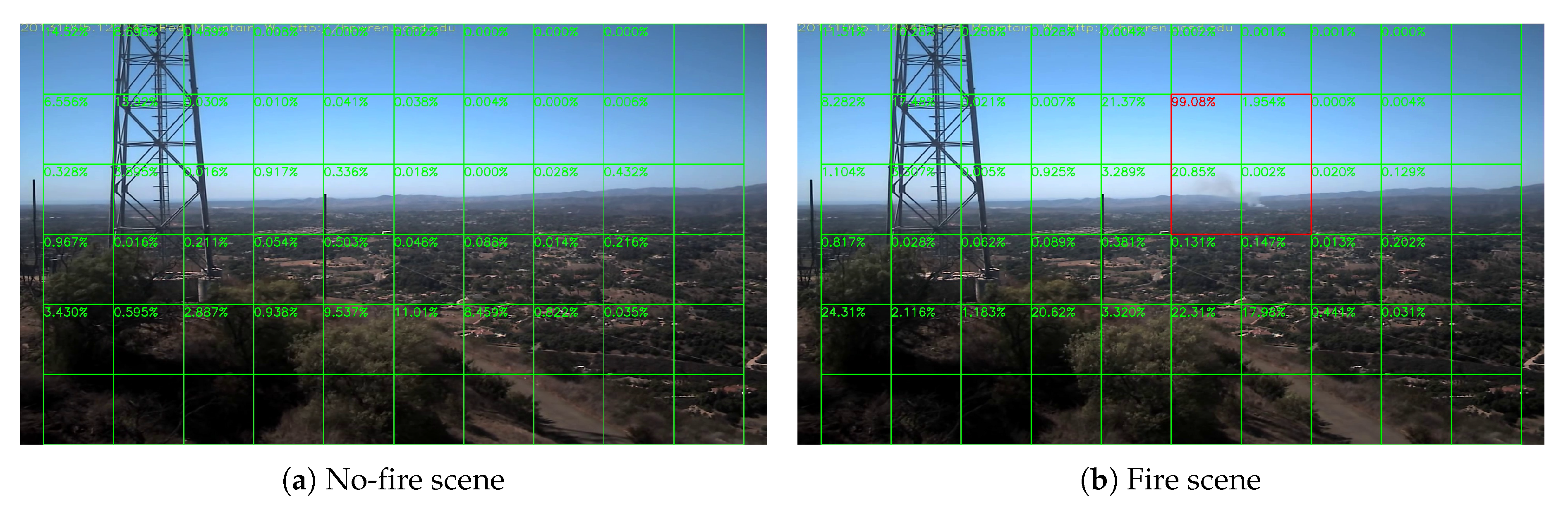
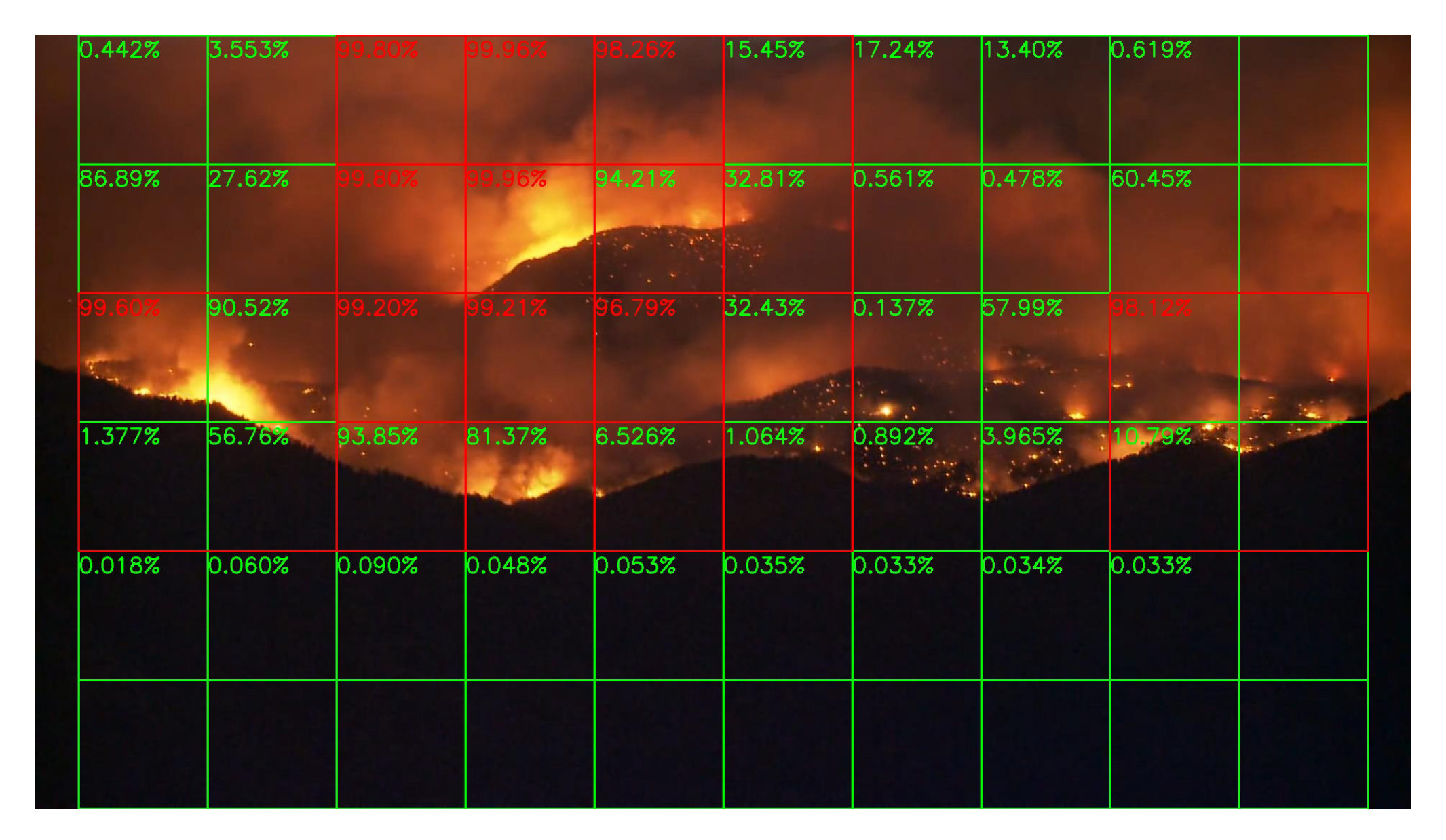
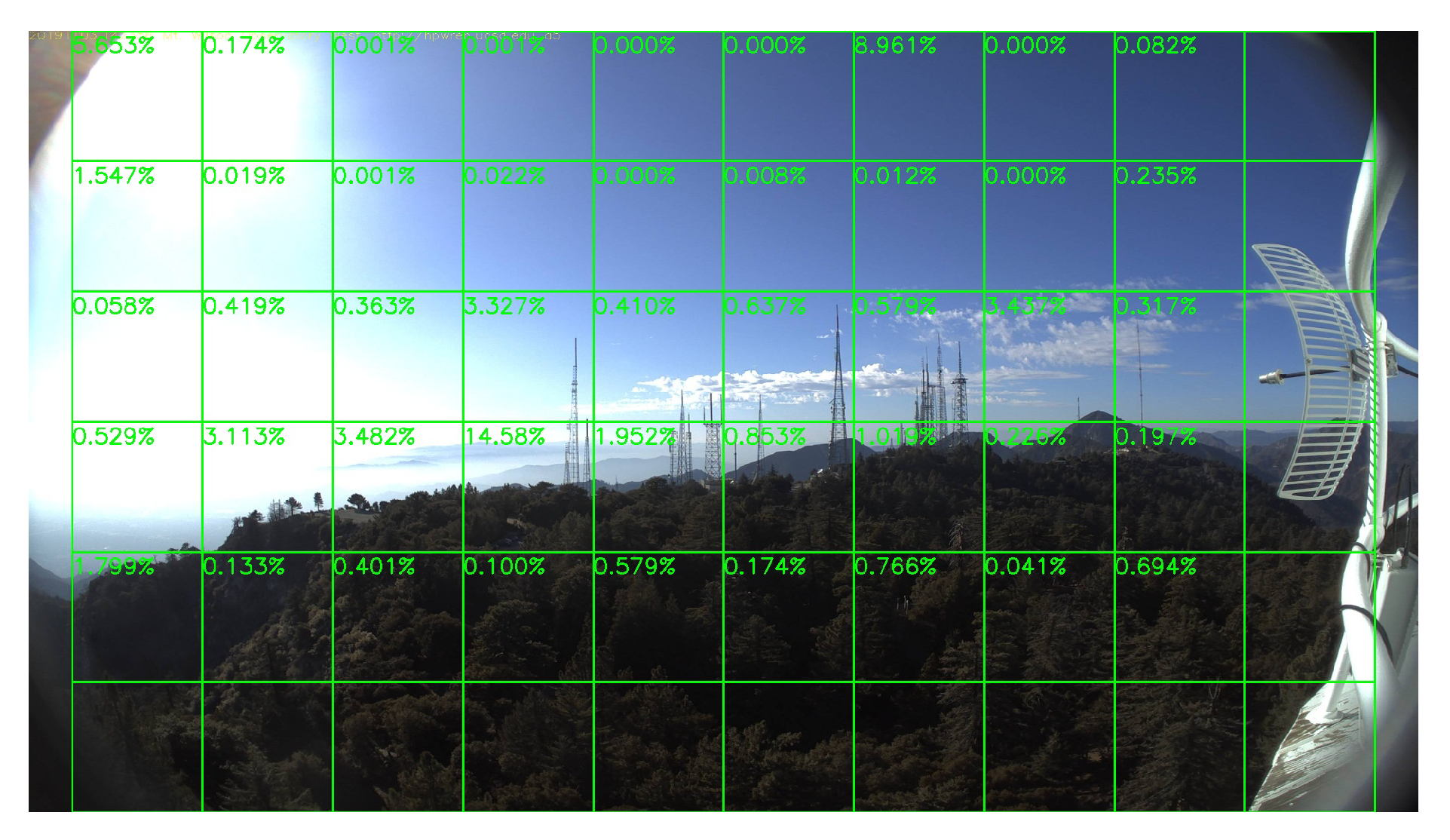
4. Block-Based Analysis of Image Frames
5. Network Performance
5.1. Speed Test
5.2. Daytime Fire Surveillance Test
5.3. Night Fire Surveillance Test
5.4. Performance on No-Fire Videos
5.5. Comparison with Other Methods
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| UAV | Unmanned Aerial Vehicle |
| CNN | Convolutional Neural Network |
| DFT | Discrete Fourier transform |
| MP | Million Pixels |
References
- Töreyin, B.U.; Dedeoğlu, Y.; Güdükbay, U.; Çetin, A.E. Computer vision based method for real-time fire and flame detection. Pattern Recognit. Lett. 2006, 27, 49–58. [Google Scholar] [CrossRef] [Green Version]
- Töreyin, B.U.; Dedeoğlu, Y.; Cetin, A.E. Wavelet based real-time smoke detection in video. In Proceedings of the IEEE 2005 13th European Signal Processing Conference, Antalya, Turkey, 4–8 September 2005; pp. 1–4. [Google Scholar]
- Habiboğlu, Y.H.; Günay, O.; Çetin, A.E. Covariance matrix-based fire and flame detection method in video. Mach. Vis. Appl. 2012, 23, 1103–1113. [Google Scholar] [CrossRef]
- Habiboglu, Y.H.; Gunay, O.; Cetin, A.E. Real-time wildfire detection using correlation descriptors. In Proceedings of the IEEE 2011 19th European Signal Processing Conference, Barcelona, Spain, 29 August–2 September 2011; pp. 894–898. [Google Scholar]
- Töreyin, B.U. Smoke detection in compressed video. In Applications of Digital Image Processing XLI; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; Volume 10752, p. 1075232. [Google Scholar]
- Aslan, S.; Güdükbay, U.; Töreyin, B.U.; Çetin, A.E. Early Wildfire Smoke Detection Based on Motion-based Geometric Image Transformation and Deep Convolutional Generative Adversarial Networks. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8315–8319. [Google Scholar]
- Borges, P.V.K.; Izquierdo, E. A probabilistic approach for vision-based fire detection in videos. IEEE Trans. Circuits Syst. Video Technol. 2010, 20, 721–731. [Google Scholar] [CrossRef]
- Çelik, T.; Özkaramanlı, H.; Demirel, H. Fire and smoke detection without sensors: Image processing based approach. In Proceedings of the IEEE 2007 15th European Signal Processing Conference, Poznan, Poland, 3–7 September 2007; pp. 1794–1798. [Google Scholar]
- Celik, T.; Demirel, H. Fire detection in video sequences using a generic color model. Fire Saf. J. 2009, 44, 147–158. [Google Scholar] [CrossRef]
- Yuan, F. A fast accumulative motion orientation model based on integral image for video smoke detection. Pattern Recognit. Lett. 2008, 29, 925–932. [Google Scholar] [CrossRef]
- Guillemant, P.; Vicente, J. Real-time identification of smoke images by clustering motions on a fractal curve with a temporal embedding method. Opt. Eng. 2001, 40, 554–563. [Google Scholar] [CrossRef]
- Vicente, J.; Guillemant, P. An image processing technique for automatically detecting forest fire. Int. J. Therm. Sci. 2002, 41, 1113–1120. [Google Scholar] [CrossRef]
- Gomez-Rodriguez, F.; Arrue, B.C.; Ollero, A. Smoke monitoring and measurement using image processing: Application to forest fires. In Automatic Target Recognition XIII; International Society for Optics and Photonics: Bellingham, WA, USA, 2003; Volume 5094, pp. 404–411. [Google Scholar]
- Krstinić, D.; Stipaničev, D.; Jakovčević, T. Histogram-based smoke segmentation in forest fire detection system. Inf. Technol. Control 2009, 38, 237–244. [Google Scholar]
- Luo, Q.; Han, N.; Kan, J.; Wang, Z. Effective dynamic object detecting for video-based forest fire smog recognition. In Proceedings of the IEEE 2009 2nd International Congress on Image and Signal Processing, Tianjin, China, 17–19 October 2009; pp. 1–5. [Google Scholar]
- Toreyin, B.U.; Cetin, A.E. Computer vision based forest fire detection. In Proceedings of the 2008 IEEE 16th Signal Processing, Communication and Applications Conference, Aydin, Turkey, 20–22 April 2008; pp. 1–4. [Google Scholar]
- Toreyin, B.U.; Cetin, A.E. Wildfire detection using LMS based active learning. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 1461–1464. [Google Scholar]
- Günay, O.; Taşdemir, K.; Töreyin, B.U.; Çetin, A.E. Fire detection in video using LMS based active learning. Fire Technol. 2010, 46, 551–577. [Google Scholar] [CrossRef]
- Çetin, A.E.; Dimitropoulos, K.; Gouverneur, B.; Grammalidis, N.; Günay, O.; Habiboǧlu, Y.H.; Töreyin, B.U.; Verstockt, S. Video fire detection—Review. Digit. Signal Process. 2013, 23, 1827–1843. [Google Scholar] [CrossRef] [Green Version]
- Gunay, O.; Toreyin, B.U.; Kose, K.; Cetin, A.E. Entropy-functional-based online adaptive decision fusion framework with application to wildfire detection in video. IEEE Trans. Image Process. 2012, 21, 2853–2865. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huo, Y.; Lu, F.; Wu, F.; Dong, X. Multi-Beam Multi-Stream Communications for 5G and Beyond Mobile User Equipment and UAV Proof of Concept Designs. In Proceedings of the 2019 IEEE 90th Vehicular Technology Conference (VTC2019-Fall), Honolulu, HI, USA, 22–25 September 2019; pp. 1–5. [Google Scholar]
- Valero, M.M.; Verstockt, S.; Mata, C.; Jimenez, D.; Queen, L.; Rios, O.; Pastor, E.; Planas, E. Image Similarity Metrics Suitable for Infrared Video Stabilization during Active Wildfire Monitoring: A Comparative Analysis. Remote Sens. 2020, 12, 540. [Google Scholar] [CrossRef] [Green Version]
- Günay, O.; Çetin, A.E. Real-time dynamic texture recognition using random sampling and dimension reduction. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3087–3091. [Google Scholar]
- Wu, X.; Lu, X.; Leung, H. An adaptive threshold deep learning method for fire and smoke detection. In Proceedings of the 2017 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Banff, AB, Canada, 5–8 October 2017; pp. 1954–1959. [Google Scholar]
- Zhao, Y.; Ma, J.; Li, X.; Zhang, J. Saliency detection and deep learning-based wildfire identification in UAV imagery. Sensors 2018, 18, 712. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Muhammad, K.; Ahmad, J.; Mehmood, I.; Rho, S.; Baik, S.W. Convolutional neural networks based fire detection in surveillance videos. IEEE Access 2018, 6, 18174–18183. [Google Scholar] [CrossRef]
- Yuan, F.; Zhang, L.; Xia, X.; Wan, B.; Huang, Q.; Li, X. Deep smoke segmentation. Neurocomputing 2019, 357, 248–260. [Google Scholar] [CrossRef]
- Pan, H.; Badawi, D.; Zhang, X.; Cetin, A.E. Additive neural network for forest fire detection. Signal Image Video Process. 2019, 14, 675–682. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Dimitropoulos, K.; Kaza, K.; Grammalidis, N. Fire detection from images using faster R-CNN and multidimensional texture analysis. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8301–8305. [Google Scholar]
- Huang, J.; Chao-Xia, C.; Dong, X.; Gao, Y.; Zhu, J.; Yang, B.; Zhang, F.; Shang, W. Faster R-CNN based Color-Guided Flame Detection. J. Comput. Appl. 2020, 8, 58923–58932. [Google Scholar]
- Chaoxia, C.; Shang, W.; Zhang, F. Information-Guided Flame Detection based on Faster R-CNN. IEEE Access 2020, 8, 58923–58932. [Google Scholar] [CrossRef]
- Pratt, L.Y. Discriminability-based transfer between neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 30 November–3 December 1992; pp. 204–211. [Google Scholar]
- Muhammad, K.; Ahmad, J.; Lv, Z.; Bellavista, P.; Yang, P.; Baik, S.W. Efficient deep CNN-based fire detection and localization in video surveillance applications. IEEE Trans. Syst. Man Cybern. Syst. 2018, 49, 1419–1434. [Google Scholar] [CrossRef]
- Park, M.; Ko, B.C. Two-step real-time night-time fire detection in an urban environment using Static ELASTIC-YOLOv3 and Temporal Fire-Tube. Sensors 2020, 20, 2202. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiao, Z.; Zhang, Y.; Xin, J.; Mu, L.; Yi, Y.; Liu, H.; Liu, D. A Deep Learning Based Forest Fire Detection Approach Using UAV and YOLOv3. In Proceedings of the 2019 1st International Conference on Industrial Artificial Intelligence (IAI), Shenyang, China, 23–27 July 2019; pp. 1–5. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Grammalidis, N.; Dimitropoulos, K.; Cetin, A.E. FIRESENSE Database of Videos for Flame and Smoke Detection. 2017. Available online: http://doi.org/10.5281/zenodo.836749 (accessed on 1 September 2018).
- University of California San Diego, California, America: The High Performance Wireless Research and Education Network. 2019. Available online: http://hpwren.ucsd.edu/index.html (accessed on 27 November 2019).
- Oliveira, W.D. BoWFire Dataset. Available online: https://bitbucket.org/gbdi/bowfire-dataset/downloads/ (accessed on 3 May 2020).
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers Name | Kernels Num | Slimmed Num | Rate (%) |
|---|---|---|---|
| conv | 32 | 7 | 21.88 |
| expanded_conv | 32 | 7 | 21.88 |
| expanded_conv_1 | 96 | 2 | 2.08 |
| expanded_conv_2 | 144 | 0 | 0.00 |
| expanded_conv_3 | 144 | 74 | 51.39 |
| expanded_conv_4 | 192 | 6 | 3.13 |
| expanded_conv_5 | 192 | 0 | 0.00 |
| expanded_conv_6 | 192 | 112 | 58.33 |
| expanded_conv_7 | 384 | 9 | 2.34 |
| expanded_conv_8 | 384 | 2 | 0.52 |
| expanded_conv_9 | 384 | 3 | 0.78 |
| expanded_conv_10 | 384 | 17 | 4.43 |
| expanded_conv_11 | 576 | 2 | 0.35 |
| expanded_conv_12 | 576 | 1 | 0.17 |
| expanded_conv_13 | 576 | 490 | 85.07 |
| expanded_conv_14 | 960 | 17 | 1.77 |
| expanded_conv_15 | 960 | 45 | 4.69 |
| expanded_conv_16 | 960 | 825 | 85.94 |
| Slimming Overall | 7104 | 1605 | 22.59 |
| Videos Name | Resolution | Fire Starts | First Detected |
|---|---|---|---|
| Lyons Fire | 156 | 164 (164) | |
| Holy Fire East View | 721 | 732 (732) | |
| Holy Fire South View | 715 | 725 (724) | |
| Palisades Fire | 636 | 639 (639) | |
| Banner Fire | 15 | 17 (17) | |
| Palomar Mountain Fire | 262 | 277 (275) | |
| Highway Fire | 4 | 6 (6) | |
| Tomahawk Fire | 32 | 37 (37) | |
| DeLuz Fire | 37 | 48 (48) |
| Videos Name | Resolution |
|---|---|
| Barn Fire Overhaul in Marion County Oregon | |
| Prairie Fire | |
| Drone footage of DJI Mavic Pro Home Fire | |
| Cwmcarn Forest Fire | |
| Drone Footage of Kirindy Forest Fire | |
| Drone Over Wild Fire | |
| Fire in Bell Canyon | |
| Forest Fire at the Grand Canyon | |
| Forest Fire Puerto Montt by Drone | |
| Forest Fire with Drone Support | |
| Kirindy Forest Fire | |
| Lynn Woods Reservation Fire | |
| Prescribed Fire from Above | |
| Semi Full of Hay on Fire I-70 Mile 242 KS Drone | |
| Chimney Tops Fire |
| Videos Name | Frames Num | False-Alarm Num | False-Alarm Rate (%) |
|---|---|---|---|
| wilson-w-mobo-c | 10,080 | 2 | 0.01984 |
| wilson-s-mobo-c | 10,074 | 2 | 0.01985 |
| wilson-n-mobo-c | 10,024 | 3 | 0.02993 |
| wilson-e-mobo-c | 10,028 | 43 | 0.4288 |
| vo-w-mobo-c | 10,009 | 5 | 0.04996 |
| 69bravo-e-mobo-c | 1432 | 1 | 0.06983 |
| 69bravo-e-mobo-c | 1432 | 0 | 0.0000 |
| syp-e-mobo-c | 1421 | 3 | 0.2111 |
| sp-n-mobo-c | 1252 | 2 | 0.1597 |
| sp-w-mobo-c | 1282 | 1 | 0.07800 |
| sp-s-mobo-c | 1272 | 2 | 0.1572 |
| sp-e-mobo-c | 1278 | 2 | 0.1565 |
| Method | Detection Rate (%) | False-Alarm Rate (%) | Accuracy (%) |
|---|---|---|---|
| Muhammad et al. [26] | 97.48 | 18.69 | 89.82 |
| Muhammad et al. [33] | 93.28 | 9.34 | 92.04 |
| Chaoxia et al. [31] | 92.44 | 5.61 | 93.36 |
| Our Method | 91.60 | 4.67 | 93.36 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, H.; Badawi, D.; Cetin, A.E. Computationally Efficient Wildfire Detection Method Using a Deep Convolutional Network Pruned via Fourier Analysis. Sensors 2020, 20, 2891. https://doi.org/10.3390/s20102891
Pan H, Badawi D, Cetin AE. Computationally Efficient Wildfire Detection Method Using a Deep Convolutional Network Pruned via Fourier Analysis. Sensors. 2020; 20(10):2891. https://doi.org/10.3390/s20102891
Chicago/Turabian StylePan, Hongyi, Diaa Badawi, and Ahmet Enis Cetin. 2020. "Computationally Efficient Wildfire Detection Method Using a Deep Convolutional Network Pruned via Fourier Analysis" Sensors 20, no. 10: 2891. https://doi.org/10.3390/s20102891
APA StylePan, H., Badawi, D., & Cetin, A. E. (2020). Computationally Efficient Wildfire Detection Method Using a Deep Convolutional Network Pruned via Fourier Analysis. Sensors, 20(10), 2891. https://doi.org/10.3390/s20102891