RESPOnSE—A Framework for Enforcing Risk-Aware Security Policies in Constrained Dynamic Environments

 , and
, and
Abstract
:1. Introduction
- We present RESPOnSE, an efficient and scalable policy enforcement framework, which is designed for environments with inherent constraints, such as IoT which includes edge nodes with limited resources. The proposed framework presents an innovative way of performing an access control procedure by dividing the operational workflow into two distinct phases. The initialization phase which can run in nodes with more computational power and the run-time enforcement of the policies, which can be handled by the constrained nodes of the network, providing thus a way of overcoming existing limitations and implementing fine-grained policy enforcement.
- The framework combines the ABAC and the RBAC models, utilizing the expressiveness of ABAC, during the initialization phase, by considering and evaluating the full set of subject and environmental attributes in order to extract and assign a role to the subject performing an access request. Following, during the run-time phase we use the extracted role in order to enforce RBAC policies for making the final access decision.
- For the extraction of the role the framework utilizes a modified version of the well known Multi-Criteria Decision Making (MCDM) algorithm, TOPSIS. In general, these kinds of algorithms rely on a Decision Matrix, which is constructed by a decision maker who gives a level of preference to each alternative with regard to each defined criterion. Instead, in this modified version, the Decision Matrix consists of the exact values of the attributes as they are defined in the security policy. Thus, the Decision Matrix can be generated automatically from the policy and the defined permissible roles and does not include the subjectiveness, which could be present if a decision-maker was setting the values. Moreover, a Current Value matrix is introduced, including the values of the attributes at the moment of the request or any upcoming re-evaluation. Hence, the best alternative, which in the proposed framework represents the role to be given to the subject, is considered the one which has the minimum geometric distance from the aforementioned matrix.
2. Related Work
3. Risk-Aware Security Policies Enforcement Mechanism (RESPOnSE)
- Policy rules capture multiple attributes that are mutable in run-time and can be related to the subject, the object or the environment. Examples of those attributes could be the time, the location, the status of the network, the risk level of the subject, etc.
- Each attribute is associated with a criticality metric. Thus, the impact of an attribute in the final decision can be more or less significantly lower depending on the resource that the security policy protects.
- Each attribute is associated with a freshness metric. Since, as mentioned above, the policy rules may capture mutable attributes, a freshness metric is associated with each one of them in order to designate how often a retrieval of the attribute values will take place.
- The possible types and ranges of the attributes are only limited by the specification language.
- High-tier nodes have the required resources for the enforcement of fine-grained security policy management, in accordance with the traditional Conditions → Rules → Capabilities paradigm.
- Low-tier nodes, which lack in computational power, size of memory, battery life, such as for example IoT devices, enforce risk-aware security policies, based on the following assumptions:
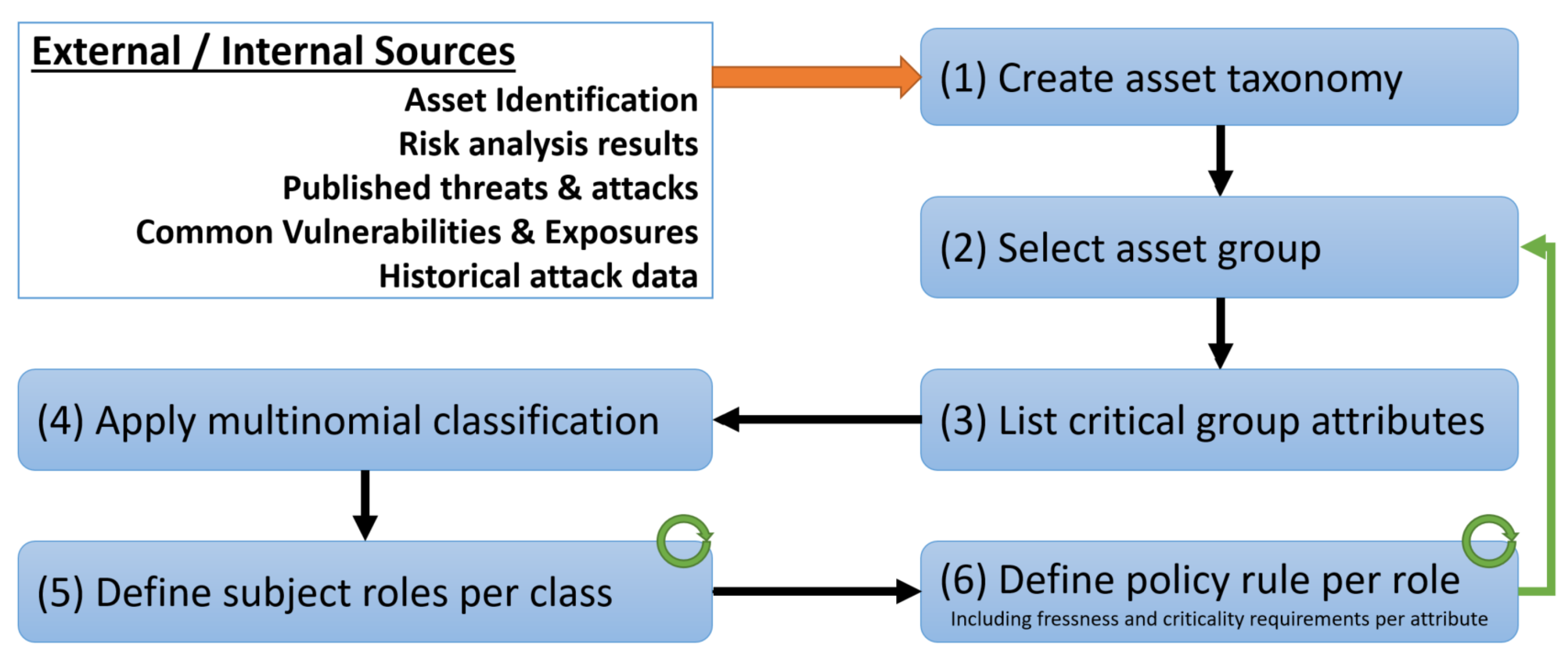
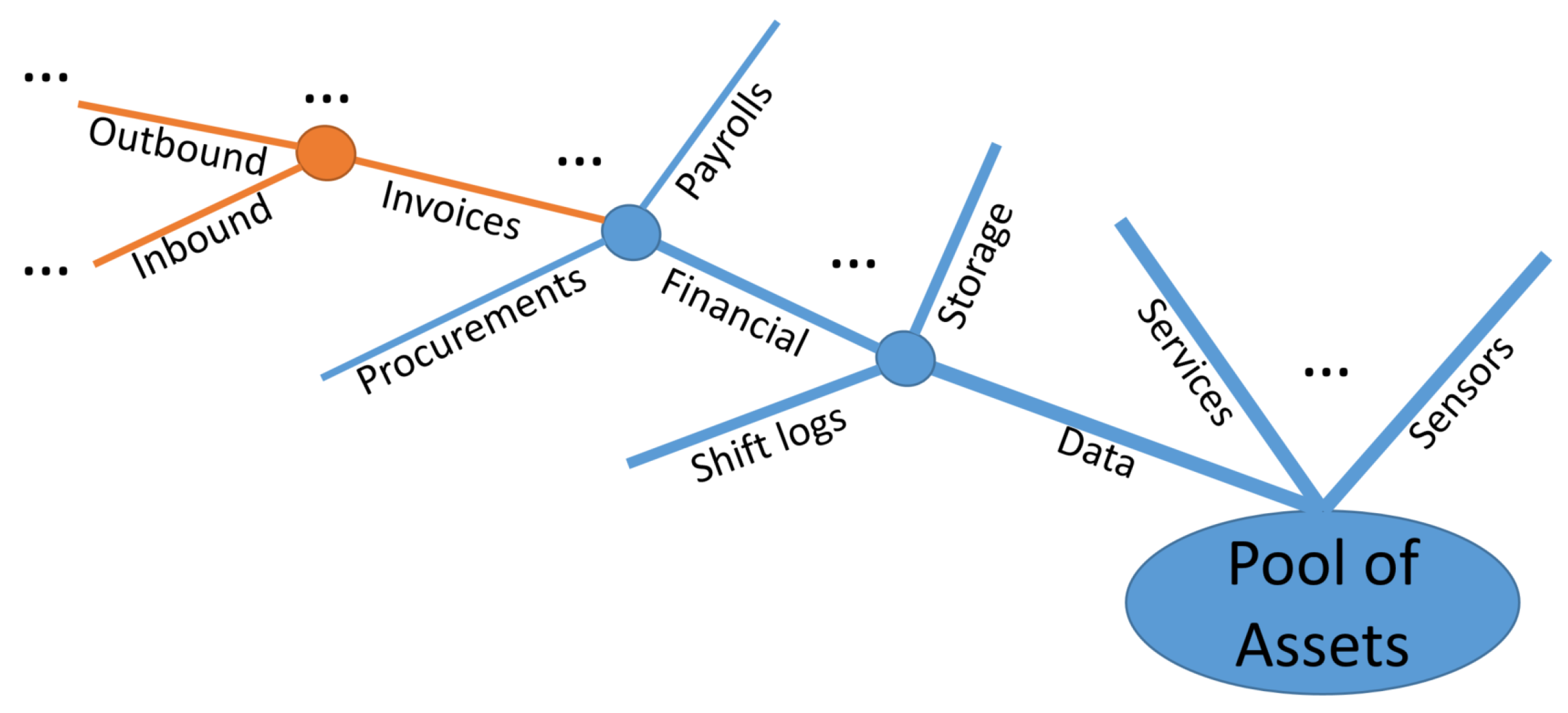
- Assets can be classified into a predefined number of classes in accordance with a delimited number of axioms and their specific data/object-property values. Assets can be identified as the resources that the security policy is meant to protect, as for example a set of classified documents, military operational documents, personal information of the users, etc. The axioms are defined in order to establish the attributes of those assets, allowing their classification in accordance with the similarities of the preconditions governing their specific action requirements.
- Each subject can be assigned a dynamic role for each asset class in accordance with the real-time values of its relevant attributes. The role is inferred at high-tier nodes (who in run-time enforce Dynamic ABAC per asset), and it is delivered to low-tier nodes (who in run-rime enforce risk-aware Dynamic RBAC per asset class).
- The utilized classification mechanism must provide membership functions for the classification of new assets, or reclassification of assets with mutable attributes, without requiring continuous retraining for minor changes in addition to the periodic maintenance.
- The utilized classification mechanism must allow the forced assignment of a specific asset within a predetermined class (even a singular class) based on a criticality metric, in order to support tailored security policy-based management for specific assets.
- The assigned subject role must be able to be reinferred in run-time, both as a periodic process and as an event-triggered process.
- The security administrators must be allowed to precisely define the permissible margins for subject role assignment.
- Grouping assets into classes.
- Assigning roles to subjects in accordance with the run-time values of mutable attributes, allowing for constrained elasticity to the exact permissible values.
- Defining security policies in a per-class/per-role basis.
3.1. Initialization Phase
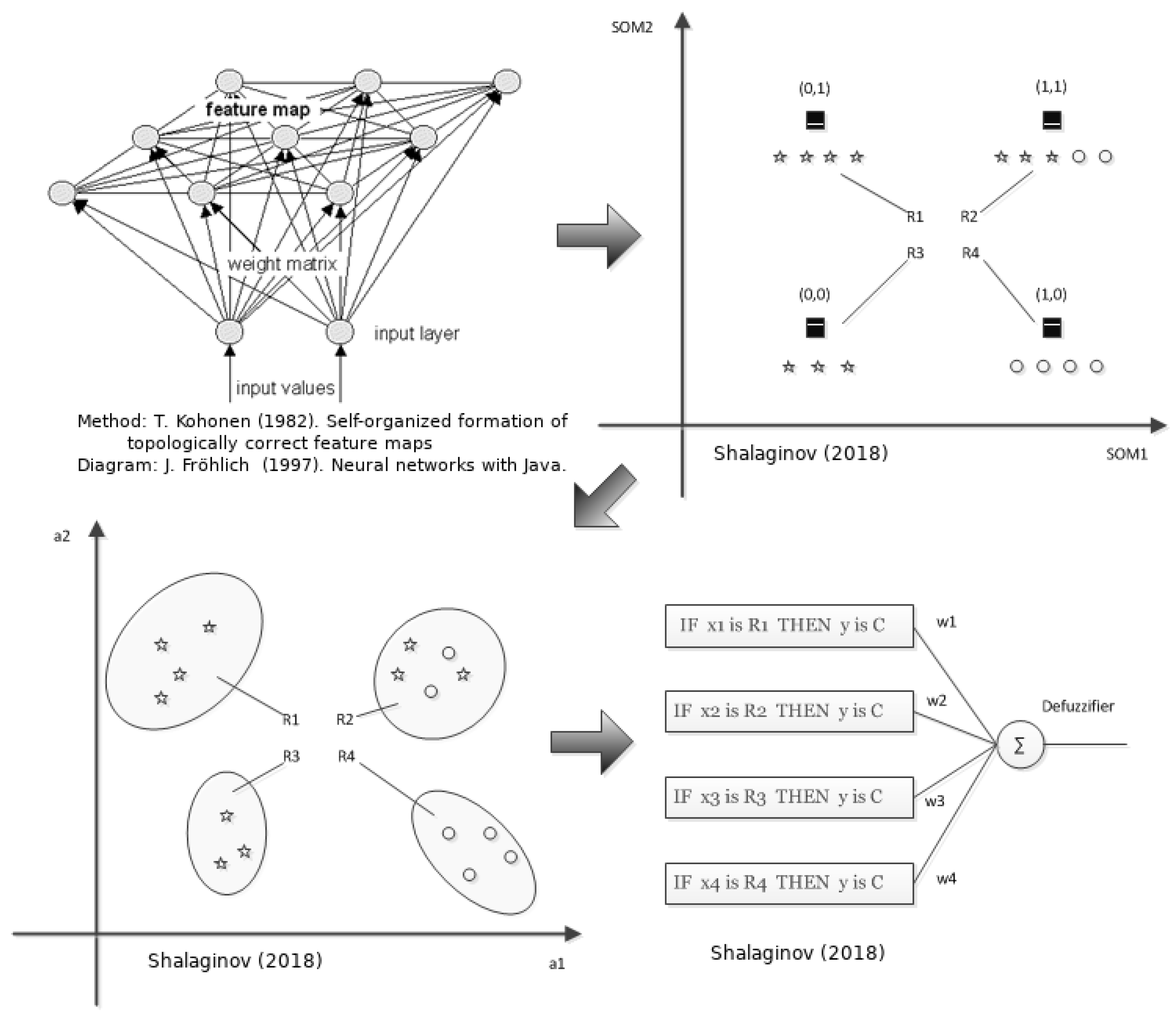
- Clustering based on the features similarities. The input data sample is a real-valued vector with a corresponding set of features and characterizes a point in M-dimensional features space. Once SOM is trained, this will result in a set of groups containing very similar samples.
- Construction of elliptic regions. To be able to characterize extracted data groups in a common manner, the hypothesis is being set that the following multivariate distribution defines the model of the data in a particular group [46] extracted from the SOM node :In this step, we put an assumption based on the data sample set that the features distribution is a Gaussian/Norwam one. To test this, a generalized Pearson test for multidimensional data is being used. The value will reflect the probabilistic radius of the hyperellipsoid (Mahalanobis distance) from the centroid of cluster to any point in the distribution:where the represents a theoretical expectation of the particular feature and equals to sample’s mean . By means of ranging of the continuous variables, the statistics can be calculated based on degrees of freedom, taking into consideration number of features M.This statistical model defines “goodness of fit” [47] of the data samples in the hyper elliptical region by means of distribution test. It describes how well the distributed data samples fit the defined multivariate distribution. distribution roughly is a sum of the squared difference between all points in a given set. To determine the value of the based on the and degrees of freedom, a contingency table is being used. Furthermore, the squared radius of the hyperellipsoid is equal to the considering the equation above.
- Extracting the parameters of the fuzzy patches/fuzzy logic rules. A first stage of the Principle Component Analysis (PCA) is being utilized to extract the set of eigenvalues and set of eigenvectors [48]. With the help of PCA we rotate the original multidimensional distribution to remove the correlation. This is done since the distribution might have unequal deviations and directions different from the main feature axes. The aforementioned set of parameters has to be defined as the complete characteristics of the fuzzy patch. Therefore, we can specify each feature region as that defines the fuzzy patch. This is done since at the current step, it is hard to understand the heuristics behind this region formation, yet possible to understand similarities by such a fuzzy patch definition.
- Construction of membership function. Each fuzzy patch is characterized by the membership function or so-called “degree of truth” that binds an input with an output [49]:
3.2. Run-Time Phase
- Construction of the Decision Matrix (DM)The construction of the DM can be expressed as shown in Table 3, where , ,.., refer to the set of the alternatives of the given problem, ,,..., refer to the set of the criteria on which the final decision is based and finally is the level of preference for the alternative with respect to the criterion .In the proposed mechanism the DM is constructed, taking as inputs the required values of the subject and environmental attributes that are encapsulated into the policy rules specified for the roles of the examined class. Hence , , ..., represent the permissible roles for this class, ,,..., represent the attributes that need to be evaluated for the assignment of a role, and element of the matrix represents the exact required value of the subject/environmental attribute, in order to assign the specific role. All these components are specified by the security administrator during the initialization phase, following the process described earlier.
- Normalization of DMBefore initiating the comparison among the criteria, a two-step preprocessing of the data must take place. The first one is to convert the values expressed in non-numerical terms into numerical ones. This can be achieved by giving a specific range of values per attribute, based on the nature of the attribute and the needs of the application environment. The second step is to identify the appropriate normalization technique so as to establish a common scale for all the criteria and be able to compare them. In the literature, there are a number of normalization techniques which can be exploited in the TOPSIS method [59], with the most applicable being the Vector Normalization [60,61]. However, for the proposed mechanism the chosen normalization technique will also be used for normalizing the CV matrix, which contains the run-time values of the attributes. Considering that the values may not be in compliance with the values defined in the policy and can fall in any point of the permitted range (e.g., if the subject belongs to an existing department that is not anticipated within the established policy rules for the class under evaluation), the utilized normalization technique should take into account the whole range of potential values. Thus, the aforementioned technique is limited only in the values which are present at the DM; it does not serve the scope of this mechanism. Instead, the proposed methodology exploits the Linear Max-Min technique [62], were given a range of values per attribute , the normalized values of the DM are calculated by the Equation (4), which considers both the current value of the DM and the full range of values that the specific element can acquire.
- Definition of the weightsThe relative importance of each criterion can be established using a set of weights whose sum equals to one. Such a set can be defined as , where is the weight assigned to criterion . Even though appointing the appropriate values to the weights will not be investigated in this study, in the current literature and mostly in the field of Artificial Intelligence, this problem has already been addressed and a number of solutions are available. For instance, a relevant method is the backpropagation [63] which, given an initial set of weights and the error at the output, updates each of the weights in the network so that they cause the actual output to be closer to the target output over multiple training iterations. This procedure continues until an optimal solution is achieved. Another widely used way of solving the aforementioned problem is the genetic algorithms [64] which have been proven to be very effective as global optimization processes and not just finding local minima/maxima solution.
- Calculation of the weighted normalized DM (WDM)The WDM is derived by the multiplication of each element of each column of the normalized DM with the relative weights derived from the previous step.
- Identification and normalization of the CVIdeal Solution is considered a matrix which can be defined as = [,, ...,] and contains the run-time values of the evaluated criteria (i.e., subject/ environmental attributes). Therefore, the element of the matrix represents the value of the criterion at the time of the evaluation.As previously stated, in order to be able to compare these values with the one of the WDM, the same normalization technique of step 2 will be applied to the CV matrix. Hence, using the Equation (4) we calculate the normalized CV as .
- Calculation of the weighted normalized CV (WCV)Since both the DM and the CV matrices represent the values of the attributes, they have to be expressed with common terms. Thus, the same set of weights will be applied also in the CV matrix resulting in a (WCV) matrix.
- Calculation of the distance of each alternative from the WCVThe distance is calculated using the Euclidean distance.Accordingly, this step provides the divergence of the current subject/environmental attribute values from those required for the assignment of each of the permissible roles.
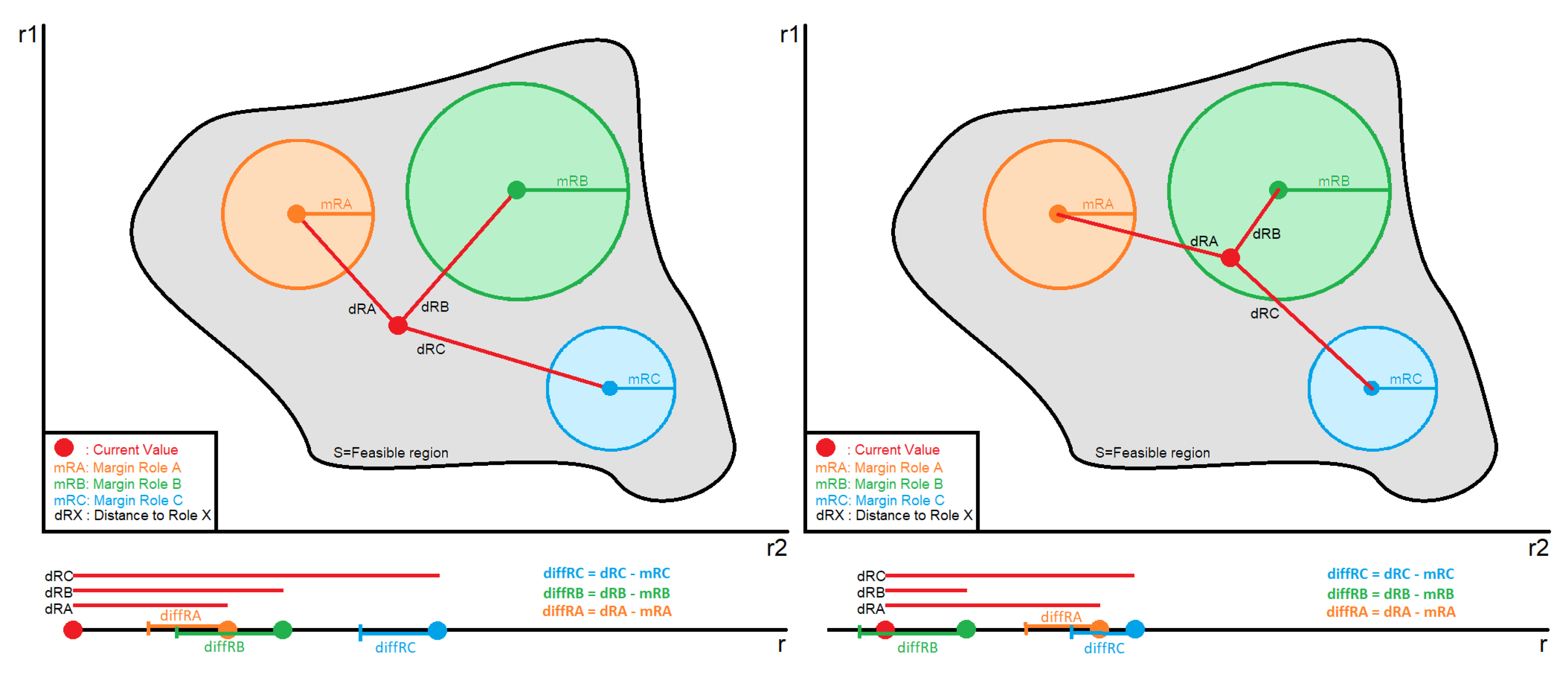
- Ranking of the alternatives and final decisionThe outcome of the previous steps will be the ranking of the given alternatives based on their distance from the CV, where the optimal alternative is the one with the shortest distance. Nonetheless, assigning the role with the shortest distance may introduce unacceptable risks. Although this can be partially mitigated by increasing the quantization resolution (i.e., by increasing the number of permissible roles), this is not an efficient solution and in most cases not desirable or permitted. Accordingly, the system administrator should be able to define ranges in order to quantify the acceptable distance for assigning a role. The threshold of these ranges will be based on the criticality of the asset, meaning that for very critical assets the maximum acceptable distance should be very close to CV, even 0. For assets which are not so critical, the margins can be extended, giving thus a higher level of freedom and more chances for a role to be chosen. Moreover, the closeness amongst the ranges is also configurable, so as to give the possibility to the security administrator to define, in a fine-grained way, the accepted margins of uncertainty when transitioning between roles. For example, if a subject by acquiring Role A is entitled to a set of privileges which provide full autonomy over the asset, then segueing into this role must be challenging. This can be achieved both by limiting the acceptable distance range of this role and at the same time by drifting apart the roles.Nevertheless, the procedure of choosing the correct values of the threshold is a challenging task, and it is discussed a lot in the research community. Thus, in this study, we refer to some methods which can be exploited to tackle this problem. The first one is the REINFORCE algorithm presented by Williams [65] based on which the authors of [66] extracted a learning rule which combined with an appropriate policy is able to set the most suitable thresholds for an optimal decision making. The second methodology depends on the use of Bayesian optimization [66]. This method relies on the mean reward and the variance of it applying a threshold, and then maximizing these gives a guide for selecting the appropriate threshold values in the future.Figure 4 depicts the assignment of the role to a subject considering the given margins from the security administrator. Each role can be represented as a circle, where the radius is the defined margin for this role. Moreover, the calculated values of distance matrix S in step 7 are denoted as the distance of the center of each role to the CV. Hence, we can calculate the difference between the distance of the role and the corresponding margin. If none of these differences is less or equal to zero (left graph), that means that none of the roles presents an acceptable distance from the CV so as to be assigned to the subject. In this case, the role is characterized as undefined and a default action defined by the administrator is performed (i.e., “Deny by default”, “Permit by default”). On the other hand, if one or more of the roles present a negative or equal to zero difference (right graph), the CV lies within the given margins of the role, meaning that the role presents an acceptable distance. Therefore, this role is the one assigned to the subject. It is worth mentioning that in case of an overlap, meaning that the CV lies within two or more circles, the role to be assigned is the one whose value in the distance matrix S is the smallest.
- Low to High tier node communication: an access request is received from a subject with no active sessions (therefore no role assignment) for an asset class.
- High to low tier node communication: the freshness values of the attributes based on which the role of any given subject has been inferred have expired and require re-evaluation.
- Low to High tier node communication: Some policy violation event (trigger event by the security administrator) triggers a role re-evaluation for a subject’s role.
4. An Example Use Case
- preliminary data analytics through looking at the distribution and correlation
- results of SOM training listing numerical ID of data samples assigned to each SOM node
- regressional performance evaluation of the method and given dataset and finally
- classification confusion matrix, showing how well the model actually can predict the data class and its actual class
- SOMnode(0,0): 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 22 23 24 25 27 29 30 32 34 36 38 39 45 47 51 52 54 64 67 68 78 83 86 87 100 101 103 106 109 113 124 138 144 145
- SOMnode(0,1): 20 42 48 50 57 60 61 62 71 72 73 75 88 89 94 95 99 114 115 127 131 136 139 146 147
- SOMnode (1,0): 21 41 43 70 79 92 105 119 122 129 133 142
- SOMnode(1,1): 18 93 118 120 128 132
- SOMnode(2,0): 26 31 33 55 63 81 96 110 116
- SOMnode(2,1): 19 28 35 37 40 44 49 58 59 98 108 111 121 134
- SOMnode(3,0): 66 69 74 76 82 97 104 123 125 141 148
- SOMnode(3,1): 46 53 56 65 77 80 84 85 90 91 102 107 112 117 126 130 135 137 140 143
- Rule 1: If the subject belongs to the Accounting and Finance Department, his identifier is within the 4893XXXX range, the time of the request is between 6 and 9 am and the connection type is through an Ethernet cable then the role of the subject is Manager.
- Rule 2: If the subject belongs to the Marketing Department, his identifier is within the 8849XXXX range, the time of the request is between 5 and 7 pm and the connection type is through an Ethernet cable then the role of the subject is Employee.
- Rule 3: If the subject belongs to the Production Department, his identifier is within the 5634XXXX range, the time of the request is between 12 and 2 am and the connection type is wireless with WEP encryption then the role of the subject is Intern.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ersue, M.; Romascanu, D.; Schoenwaelder, J.; Herberg, U. Management of Networks with Constrained Devices: Problem Statement and Requirements. Internet Eng. Task Force 2015. [Google Scholar] [CrossRef] [Green Version]
- Bormann, C.; Ersue, M.; Keranen, A. Terminology for Constrained-Node Networks; Internet Engineering Task Force (IETF): Fremont, CA, USA, 2014. [Google Scholar] [CrossRef]
- F-Secure. Attack Landscape H12019. Available online: https://blog-assets.f-secure.com/wp-content/uploads/2019/09/12093807/2019_attack_landscape_report.pdf (accessed on 15 April 2020).
- O’Neill, M. The Internet of Things: Do more devices mean more risks? Comput. Fraud Secur. 2014, 2014, 16–17. [Google Scholar] [CrossRef]
- Gkioulos, V.; Wolthusen, S.D. Constraint Analysis for Security Policy Partitioning Over Tactical Service Oriented Architectures. In Advances in Network Systems; Grzenda, M., Awad, A.I., Furtak, J., Legierski, J., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 149–166. [Google Scholar]
- Gkioulos, V.; Wolthusen, S.D. Reconciliation of ontologically defined security policies for tactical service oriented architectures. In Future Network Systems and Security; Efficient Security Policy Reconciliation in Tactical Service Oriented Architectures; Doss, R., Piramuthu, S., Zhou, W., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 47–61. [Google Scholar]
- Gkioulos, V.; Wolthusen, S.D.; Flizikowski, A.; Stachowicz, A.; Nogalski, D.; Gleba, K.; Sliwa, J. Interoperability of security and quality of Service Policies Over Tactical SOA. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Gkioulos, V.; Wolthusen, S.D. A Security Policy Infrastructure for Tactical Service Oriented Architectures. In Security of Industrial Control Systems and Cyber-Physical Systems; Cuppens-Boulahia, N., Lambrinoudakis, C., Cuppens, F., Katsikas, S., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 37–51. [Google Scholar]
- Hu, V.C.; Ferraiolo, D.; Kuhn, R.; Friedman, A.R.; Lang, A.J.; Cogdell, M.M.; Schnitzer, A.; Sandlin, K.; Miller, R.; Scarfone, K.; et al. Guide to attribute based access control (ABAC) definition and considerations (draft). NIST Spec. Publ. 2013, 800. [Google Scholar] [CrossRef]
- Sandhu, R.S.; Coyne, E.J.; Feinstein, H.L.; Youman, C.E. Role-based access control models. Computer 1996, 29, 38–47. [Google Scholar] [CrossRef] [Green Version]
- Greene, R.; Devillers, R.; Luther, J.E.; Eddy, B.G. GIS-Based Multiple-Criteria Decision Analysis. Geography Compass 2011, 5, 412–432. [Google Scholar] [CrossRef]
- Yoon, K.P.; Hwang, C.L. Multiple Attribute Decision Making: An Introduction; Sage Publications: Thousand Oaks, CA, USA, 1995; Volume 104. [Google Scholar]
- Articte, P.N. Raster Procedures for M ulti-Criteria/Multi-0biective Decisions. Photogramm. Eng. Remote Sens. 1995, 61, 539–547. [Google Scholar]
- Aruldoss, M.; Lakshmi, T.; Venkatesan, V. A survey on multi criteria decision making methods and its applications. Am. J. Inf. Syst. 2013, 1, 31–43. [Google Scholar] [CrossRef]
- Awasthi, A.; Chauhan, S.S.; Goyal, S.K. A multi-criteria decision making approach for location planning for urban distribution centers under uncertainty. Math. Comput. Model. 2011, 53, 98–109. [Google Scholar] [CrossRef]
- Zaeri, M.S.; Sadeghi, A.; Naderi, A.; Fasihy, A.K.R.; Shorshani, S.M.H.; Poyan, A. Application of multi criteria decision making technique to evaluation suppliers in supply chain management. Afr. J. Math. Comput. Sci. Res. 2011, 4, 100–106. [Google Scholar]
- Wu, H.Y.; Tzeng, G.H.; Chen, Y.H. A fuzzy MCDM approach for evaluating banking performance based on Balanced Scorecard. Expert Syst. Appl. 2009, 36, 10135–10147. [Google Scholar] [CrossRef]
- İç, Y.T. Development of a credit limit allocation model for banks using an integrated Fuzzy TOPSIS and linear programming. Expert Syst. Appl. 2012, 39, 5309–5316. [Google Scholar]
- Medjoudj, R.; Aissani, D.; Haim, K.D. Power customer satisfaction and profitability analysis using multi-criteria decision making methods. Int. J. Electr. Power Energy Syst. 2013, 45, 331–339. [Google Scholar] [CrossRef]
- Turskis, Z.; Goranin, N.; Nurusheva, A.; Boranbayev, S. Information Security Risk Assessment in Critical Infrastructure: A Hybrid MCDM Approach. Informatica 2019, 30, 187–211. [Google Scholar] [CrossRef]
- Syamsuddin, I. Multicriteria evaluation and sensitivity analysis on information security. arXiv 2013, arXiv:1310.3312. [Google Scholar] [CrossRef] [Green Version]
- Guan, B.C.; Lo, C.C.; Wang, P.; Hwang, J.S. Evaluation of information security related risks of an organization: the application of the multicriteria decision-making method. In Proceedings of the IEEE 37th Annual 2003 International Carnahan Conference onSecurity Technology, Taipei, Taiwan, 14–16 October 2003; pp. 168–175. [Google Scholar]
- Ou Yang, Y.P.; Shieh, H.M.; Leu, J.D.; Tzeng, G.H. A Vikor-Based MUltiple criteria decision method for improving information security risk. Int. J. Inf. Technol. Decis. Mak. 2009, 8, 267–287. [Google Scholar] [CrossRef]
- Shameli-Sendi, A.; Shajari, M.; Hasanabadi, M.; Jabbarifar, M.; Dagenias, M. Fuzzy Multi-Criteria Decision-Making for Information Security Risk Assessment. Open Cybern. Syst. J. 2012, 2012, 26–37. [Google Scholar] [CrossRef]
- Martinelli, F.; Michailidou, C.; Mori, P.; Saracino, A. Too Long, did not Enforce: A Qualitative Hierarchical Risk-Aware Data Usage Control Model for Complex Policies in Distributed Environments. In Proceedings of the 4th ACM Workshop on Cyber-Physical System Security, CPSS@AsiaCCS 2018, Incheon, Korea, 4–8 June 2018; pp. 27–37. [Google Scholar] [CrossRef]
- Eswaran, S.P.; Sripurushottama, S.; Jain, M. Multi Criteria Decision Making (MCDM) based Spectrum Moderator for Fog-Assisted Internet of Things. Procedia Comput. Sci. 2018, 134, 399–406. [Google Scholar] [CrossRef]
- Nabeeh, N.A.; Abdel-Basset, M.; El-Ghareeb, H.A.; Aboelfetouh, A. Neutrosophic multi-criteria decision making approach for iot-based enterprises. IEEE Access 2019, 7, 59559–59574. [Google Scholar] [CrossRef]
- Kao, Y.S.; Nawata, K.; Huang, C.Y. Evaluating the performance of systemic innovation problems of the IoT in manufacturing industries by novel MCDM methods. Sustainability 2019, 11, 4970. [Google Scholar] [CrossRef] [Green Version]
- Manifavas, C.; Fysarakis, K.; Rantos, K.; Kagiambakis, K.; Papaefstathiou, I. Policy-based access control for body sensor networks. In IFIP International Workshop on Information Security Theory and Practice; Springer: Berlin/Heidelberg, Germany, 2014; pp. 150–159. [Google Scholar]
- Barrera, D.; Molloy, I.; Huang, H. Standardizing IoT Network Security Policy Enforcement. In Proceedings of the Workshop on Decentralized IoT Security and Standards (DISS), San Diego, CA, USA, 18 February 2018; p. 6. [Google Scholar] [CrossRef]
- Pillay, N.; Maharaj, B.T.; van Eeden, G. AI in Engineering and Computer Science Education in Preparation for the 4th Industrial Revolution: A South African Perspective. In Proceedings of the 2018 World Engineering Education Forum—Global Engineering Deans Council (WEEF-GEDC), Albuquerque, NM, USA, 12–16 November 2018; pp. 1–5. [Google Scholar]
- Boucher, P. How Artificial Intelligence Works. 2019. Available online: http://www.europarl.europa.eu/RegData/etudes/BRIE/2019/634420/EPRS_BRI(2019)634420_EN.pdf (accessed on 15 April 2020).
- Shalaginov, A. Advancing Neuro-Fuzzy Algorithm for Automated Classification in Largescale Forensic and Cybercrime Investigations: Adaptive Machine Learning for Big Data Forensic. Ph.D. Thesis, Norwegian University of Science and Technology, Trondheim, Norway, 2018. [Google Scholar]
- Shalaginov, A.; Franke, K. A new method for an optimal som size determination in neuro-fuzzy for the digital forensics applications. In International Work-Conference on Artificial Neural Networks; Springer International Publishing: Cham, Switzerland, 2015; pp. 549–563. [Google Scholar]
- Ghotbi, S.H.; Fischer, B. Fine-grained role-and attribute-based access control for web applications. In Proceedings of the International Conference on Software and Data Technologies, Rome, Italy, 24–27 July 2012; pp. 171–187. [Google Scholar]
- Jin, X.; Sandhu, R.; Krishnan, R. RABAC: Role-centric attribute-based access control. In Proceedings of the International Conference on Mathematical Methods, Models, and Architectures for Computer Network Security, St. Petersburg, Russia, 17–19 October 2012; pp. 84–96. [Google Scholar]
- Kuhn, D.R.; Coyne, E.J.; Weil, T.R. Adding attributes to role-based access control. Computer 2010, 43, 79–81. [Google Scholar] [CrossRef]
- Qi, H.; Di, X.; Li, J. Formal definition and analysis of access control model based on role and attribute. J. Inf. Secur. Appl. 2018, 43, 53–60. [Google Scholar] [CrossRef]
- Batra, G.; Atluri, V.; Vaidya, J.; Sural, S. Enabling the deployment of ABAC policies in RBAC systems. In Proceedings of the IFIP Annual Conference on Data and Applications Security and Privacy, Bergamo, Italy, 16–18 July 2018; pp. 51–68. [Google Scholar]
- Wang, W.; Luo, H.; Deng, H. Research on data and workflow security of electronic military systems. In Proceedings of the 2013 Fourth International Conference on Intelligent Control and Information Processing (ICICIP), Beijing, China, 9–11 June 2013; pp. 705–709. [Google Scholar]
- Chandran, S.M.; Joshi, J.B. LoT-RBAC: A location and time-based RBAC model. In Proceedings of the International Conference on Web Information Systems Engineering, New York, NY, USA, 20–22 November 2005; pp. 361–375. [Google Scholar]
- Wang, W.; Du, J.; Zhou, Z.C. Design of T-RBAC Component and its Application in Electronic Military System. Dianxun Jishu/ Telecommun. Eng. 2012, 52, 790–795. [Google Scholar]
- Ravidas, S.; Lekidis, A.; Paci, F.; Zannone, N. Access control in Internet-of-Things: A survey. J. Netw. Comput. Appl. 2019, 144, 79–101. [Google Scholar] [CrossRef]
- Beckers, K.; Schmidt, H.; Kuster, J.C.; Faßbender, S. Pattern-based support for context establishment and asset identification of the ISO 27000 in the field of cloud computing. In Proceedings of the 2011 Sixth International Conference on Availability, Reliability and Security, Vienna, Austria, 22–26 August 2011; pp. 327–333. [Google Scholar]
- Kohonen, T. Self-organized formation of topologically correct feature maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Shalizi, C.R. Advanced Data Analysis from Elementary Point of View; Technical report, Undergraduate Advanced Data Analysis; Department of Statistics, Carnegie Mellon University: Pittsburgh, PA, USA, 2013. [Google Scholar]
- Mark, L.; Berenson; David, M.; Levine, T.C.K. Basic Business Statistics, 11/E; Pearson: London, UK, 2009. [Google Scholar]
- Smith, L.I. A Tutorial on Principal Components Analysis; Technical Report; Cornell University: Ithaca, NY, USA, 2002. [Google Scholar]
- Piegat, A. Fuzzy Modeling and Control; Studies in Fuzziness and Soft Computing; Physica-Verlag: Heidelberg, Germany, 2001. [Google Scholar]
- Fraser, B. RFC2196: Site Security Handbook. Available online: https://dl.acm.org/doi/pdf/10.17487/RFC2196 (accessed on 15 April 2020).
- Samuel, A.; Ghafoor, A.; Bertino, E. A Framework for Specification and Verification of Generalized Spatio-Temporal Role Based Access Control Model; Purdue University: West Lafayette, India, 2007. [Google Scholar]
- Kikuchi, S.; Tsuchiya, S.; Adachi, M.; Katsuyama, T. Policy verification and validation framework based on model checking approach. In Proceedings of the Fourth International Conference on Autonomic Computing (ICAC’07), Washington, DC, USA, 11–15 June 2007; p. 1. [Google Scholar]
- Chandramouli, R. A policy validation framework for enterprise authorization specification. In Proceedings of the 19th Annual Computer Security Applications Conference, Las Vegas, NV, USA, 8–12 December 2003; pp. 319–328. [Google Scholar]
- Abbassi, R.; Guemara, S.; Fatmi, E. Executable Security Policies: Specification and Validation of Security Policies. Int. J. Wirel. Mob. Networks (IJWMN) 2009, 1–20. [Google Scholar]
- Hwang, C.L.; Yoon, K. Multiple Attribute Decision Making: Methods and Applications a State-of-the-Art Survey; Springer Science & Business Media: Heidelberg, Germany, 2012; Volume 186. [Google Scholar]
- Ashraf, Q.M.; Habaebi, M.H.; Islam, M.R. TOPSIS-based service arbitration for autonomic internet of things. IEEE Access 2016, 4, 1313–1320. [Google Scholar] [CrossRef]
- Kannan, G.; Murugesan, P.; Senthil, P.; Noorul Haq, A. Multicriteria group decision making for the third party reverse logistics service provider in the supply chain model using fuzzy TOPSIS for transportation services. Int. J. Serv. Technol. Manag. 2009, 11, 162–181. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Mohamed, M.; Smarandache, F. A hybrid neutrosophic group ANP-TOPSIS framework for supplier selection problems. Symmetry 2018, 10, 226. [Google Scholar] [CrossRef] [Green Version]
- Chakraborty, S.; Yeh, C. A simulation comparison of normalization procedures for TOPSIS. In Proceedings of the 2009 International Conference on Computers Industrial Engineering, Troyes, France, 6–9 July 2009; pp. 1815–1820. [Google Scholar] [CrossRef]
- Vafaei, N.; Ribeiro, R.A.; Camarinha-Matos, L.M. Data normalisation techniques in decision making: Case study with TOPSIS method. Int. J. Inf. Decis. Sci. 2018, 10, 19–38. [Google Scholar] [CrossRef]
- Vafaei, N.; Ribeiro, R.A.; Camarinha-Matos, L.M. Normalization techniques for multi-criteria decision making: analytical hierarchy process case study. In Proceedings of the Doctoral Conference on Computing, Electrical and Industrial Systems, Costa de Caparica, Portugal, 11–13 April 2016; pp. 261–269. [Google Scholar]
- Jahan, A.; Edwards, K.L. A state-of-the-art survey on the influence of normalization techniques in ranking: Improving the materials selection process in engineering design. Mater. Des. (1980–2015) 2015, 65, 335–342. [Google Scholar] [CrossRef]
- Gaxiola, F.; Melin, P.; Valdez, F. Backpropagation method with type-2 fuzzy weight adjustment for neural network learning. In Proceedings of the 2012 Annual Meeting of the North American Fuzzy Information Processing Society (NAFIPS), Berkeley, CA, USA, 6–8 August 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Siddique, M.N.H.; Tokhi, M.O. Training neural networks: Backpropagation vs. genetic algorithms. Int. Jt. Conf. Neural Netw. 2001, 4, 2673–2678. [Google Scholar] [CrossRef]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef] [Green Version]
- Lepora, N.F. Threshold Learning for Optimal Decision Making. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; pp. 3763–3771. [Google Scholar]
- Gkioulos, V.; Rizos, A.; Michailidou, C.; Mori, P.; Saracino, A. Enhancing Usage Control for Performance: An Architecture for Systems. In Computer Security; Springer International Publishing: Cham, Switzerland, 2019; pp. 69–84. [Google Scholar]
- Gkioulos, V.; Rizos, A.; Michailidou, C.; Martinelli, F.; Mori, P. Enhancing Usage Control for Performance: A Proposal for Systems of Systems (Research Poster). In Proceedings of the 2018 International Conference on High Performance Computing Simulation (HPCS), Orleans, France, 16–20 July 2018; pp. 1061–1062. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attributes → Asset Identifier ↓ | Y1 | Y2 | ... | Yn |
|---|---|---|---|---|
| X1 | F(X1,Y1) | F(X1,Y2) | ... | F(X1,Yn) |
| X2 | F(X2,Y1) | F(X2,Y2) | ... | F(X2,Yn) |
| X3 | F(X3,Y1) | F(X3,Y2) | ... | F(X3,Yn) |
| ... | ... | ... | ... | ... |
| Xk | F(Xk,Y1) | F(Xk,Y2) | ... | F(Xk,Yn) |
| Attributes → Asset Identifier ↓ | Classification | Company | ... | Department |
|---|---|---|---|---|
| Inv00013124 | Secret | E.Factory | ... | Financial.EF |
| Inv00015435 | Confidential | Warehouse | ... | Logistics.W |
| Inv00012343 | Official | Logistics | ... | Operations.L |
| ... | ... | ... | ... | ... |
| Inv00019844 | Restricted | R.M.Supplier | ... | Productions.RMS |
| ... | ||||
|---|---|---|---|---|
| ... | ||||
| ... | ||||
| ... | ... | ... | ... | ... |
| ... |
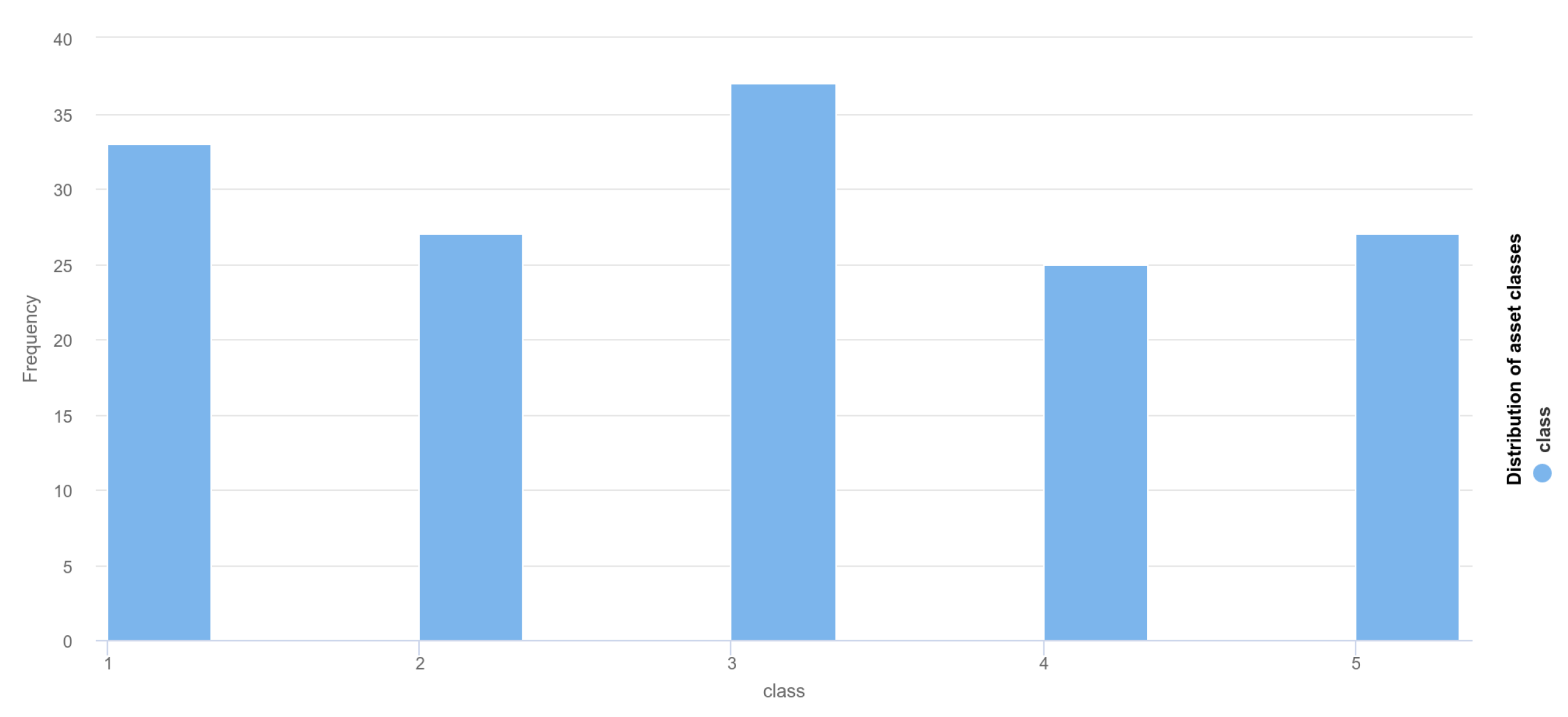
| a/p | C1 | C2 | C3 | C4 | C5 | Number of Assets |
|---|---|---|---|---|---|---|
| C1 | 33 | 0 | 0 | 0 | 0 | 33 |
| C2 | 2 | 25 | 0 | 0 | 0 | 27 |
| C3 | 2 | 0 | 35 | 0 | 0 | 37 |
| C4 | 2 | 0 | 0 | 23 | 0 | 25 |
| C5 | 1 | 0 | 0 | 0 | 26 | 27 |
| Selected Class | Role Privileges Per Role | ||
|---|---|---|---|
| Class A | Manager Read, Modify, Share | Employee Read | Intern No access |
| Class B | Manager Read, Modify, Share | Sys Admin Read, Modify, Share | Guest No access |
| Class C | Sys Admin Read, Modify, Share | Employee Read, Modify | Intern No access |
| Class D | CEO Read, Modify, Share | Employee Read, Modify | Guest Read |
| Class E | IT Read, Modify, Share | Stuff Read | Intern Read |
| Range | Policy Value | Numerical Value | |
|---|---|---|---|
| Department | 1–20 | Accounting | 6 |
| Marketing | 5 | ||
| Production | 1 | ||
| Identifier | 1–100 | 4893XXXX | 5 |
| 8849XXXX | 9 | ||
| 5634XXXX | 8 | ||
| Time | 1–8 | 6–9 a.m. | 4 |
| 12–2 p.m. | 2 | ||
| 5–7 p.m. | 3 | ||
| Connection Type | 1–10 | Ethernet | 1 |
| WiFi | 7 | ||
| 4G | 8 |
| Department | Identifier | Time | Connection Type | |
|---|---|---|---|---|
| Manager | 6 | 5 | 4 | 1 |
| Employee | 5 | 9 | 2 | 7 |
| Intern | 1 | 8 | 3 | 8 |
| Weight | 0.4 | 0.4 | 0.1 | 0.1 |
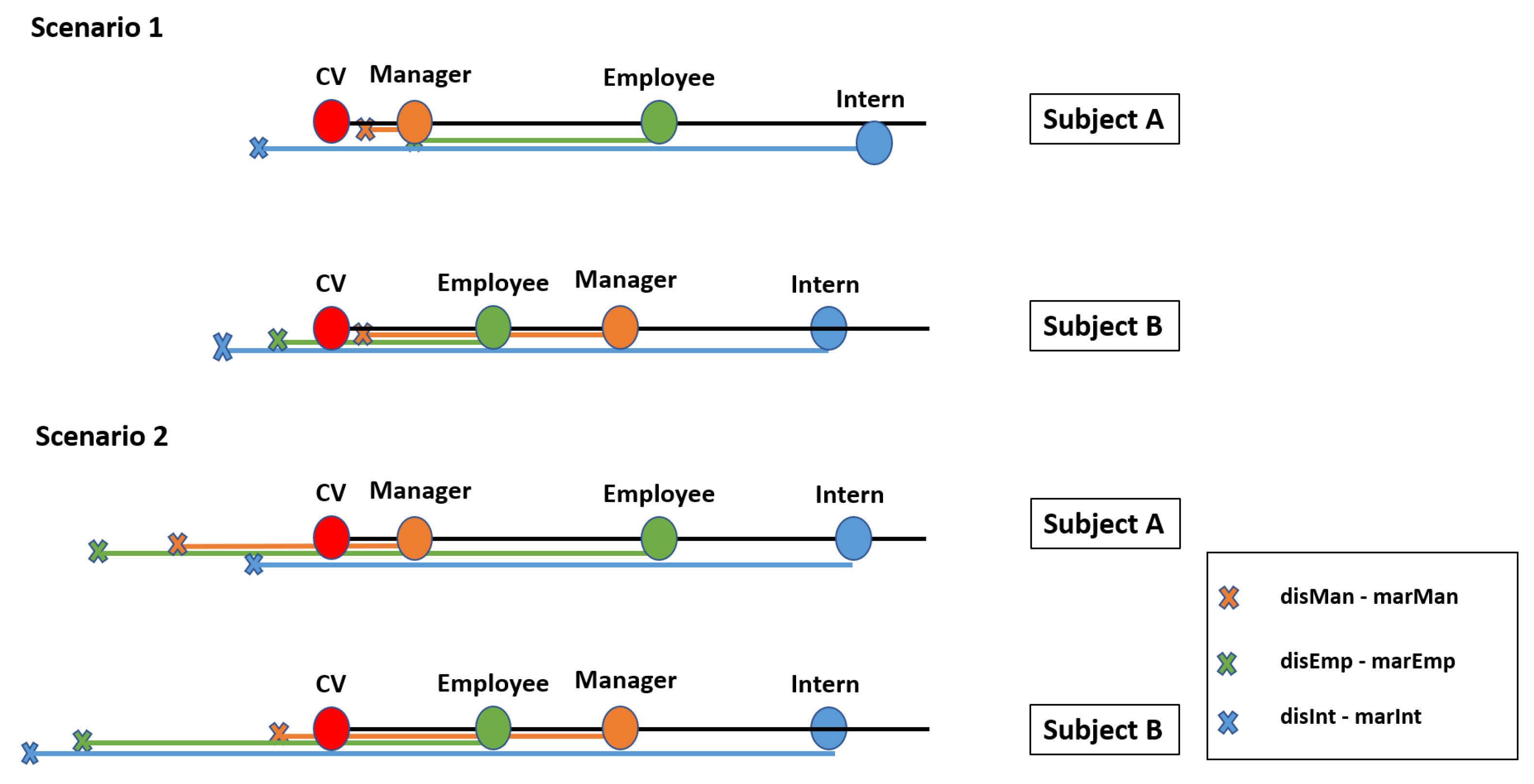
| Manager | Employee | Intern | |
|---|---|---|---|
| Scenario 1 | |||
| Scenario 2 |
| Roles | Subject A | Subject B | |
|---|---|---|---|
| Scenario 1 | Manager | 0.01 | 0.05 |
| Employee | 0.02 | −0.02 | |
| Intern | −0.04 | −0.05 | |
| Scenario 2 | Manager | −0.08 | −0.04 |
| Employee | −0.23 | −0.27 | |
| Intern | −0.04 | −0.9 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Michailidou, C.; Gkioulos, V.; Shalaginov, A.; Rizos, A.; Saracino, A. RESPOnSE—A Framework for Enforcing Risk-Aware Security Policies in Constrained Dynamic Environments. Sensors 2020, 20, 2960. https://doi.org/10.3390/s20102960
Michailidou C, Gkioulos V, Shalaginov A, Rizos A, Saracino A. RESPOnSE—A Framework for Enforcing Risk-Aware Security Policies in Constrained Dynamic Environments. Sensors. 2020; 20(10):2960. https://doi.org/10.3390/s20102960
Chicago/Turabian StyleMichailidou, Christina, Vasileios Gkioulos, Andrii Shalaginov, Athanasios Rizos, and Andrea Saracino. 2020. "RESPOnSE—A Framework for Enforcing Risk-Aware Security Policies in Constrained Dynamic Environments" Sensors 20, no. 10: 2960. https://doi.org/10.3390/s20102960
APA StyleMichailidou, C., Gkioulos, V., Shalaginov, A., Rizos, A., & Saracino, A. (2020). RESPOnSE—A Framework for Enforcing Risk-Aware Security Policies in Constrained Dynamic Environments. Sensors, 20(10), 2960. https://doi.org/10.3390/s20102960