NLP-Based Approach for Predicting HMI State Sequences Towards Monitoring Operator Situational Awareness


Abstract
:1. Introduction
2. Background and Related Work
2.1. Situational Awareness
2.2. Validation Using Naturalistic Data
2.3. Word Embedding for HMI State Encoding
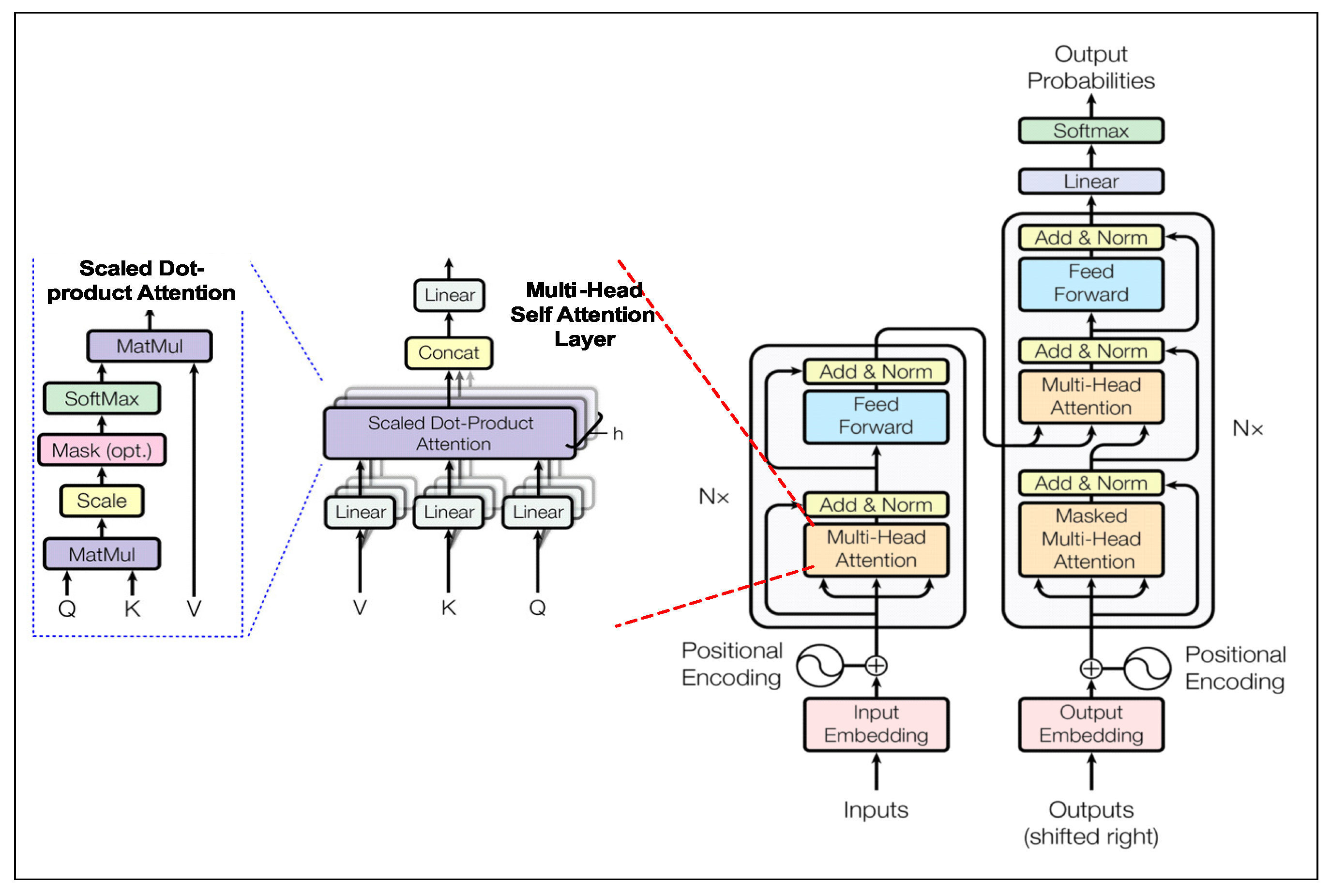
2.4. Attention for NLP Models
2.5. NLP Models
2.5.1. Transformer
- m,n—source and target sequence length containing words (tokens) respectively,
- —word (token or state) embedding dimension,
- —Query (decoder input) target sequence hidden vector shape,
- , —Key/Value (encoder input) source sequence hidden vector shape.
- = ,
- —are parameter matrices to be learned.
2.5.2. BERT and SNAIL
3. Problem Formulation
3.1. HMI State Space Features
3.2. HMI Model Assumptions
- with , and for all .
- , for all .
3.3. HMI DES Modelling for NLP
- , ,
- —(initial state, final marker state).
4. NLP Model Design
4.1. Seq2Seq—LSTM Encoder-Decoder
4.1.1. LSTM-EncDec—Training Phase
- , = <start> token,
- —learned parameter.
- —hidden vector, learned parameter respectively.
4.1.2. LSTM-EncDec—Inference Phase
4.1.3. RNN Attention Mechanism
- —trainable input, hidden and output layer weight matrices respectively.
4.2. Seq2Seq—CNN Encoder-Decoder
4.2.1. Trident—Encoder
4.2.2. Trident—CNN Layers
4.2.3. Trident—Attention Layer
4.2.4. Trident—Decoder
4.3. Curriculum Training
5. Experiments
5.1. Data Generation
- —Mean, Auto-regression, Moving-Average, seasonal trend resetting parameter,
- —Gaussian noise term.
5.2. Raw Data Sets
5.3. Supervised Learning—Data Framing
5.4. Baseline Model—Persistence Score
- —temporal slice size, sliding window size, total number of samples respectively.
5.5. Models and Test Cases
- LSTM E-D Teacher Forcing (TF)
- LSTM E-D Curriculum Learning (CL)
- Trident Teacher Forcing (TF)
- Trident Curriculum Learning (CL)
6. Results
6.1. Time-Series Metrics
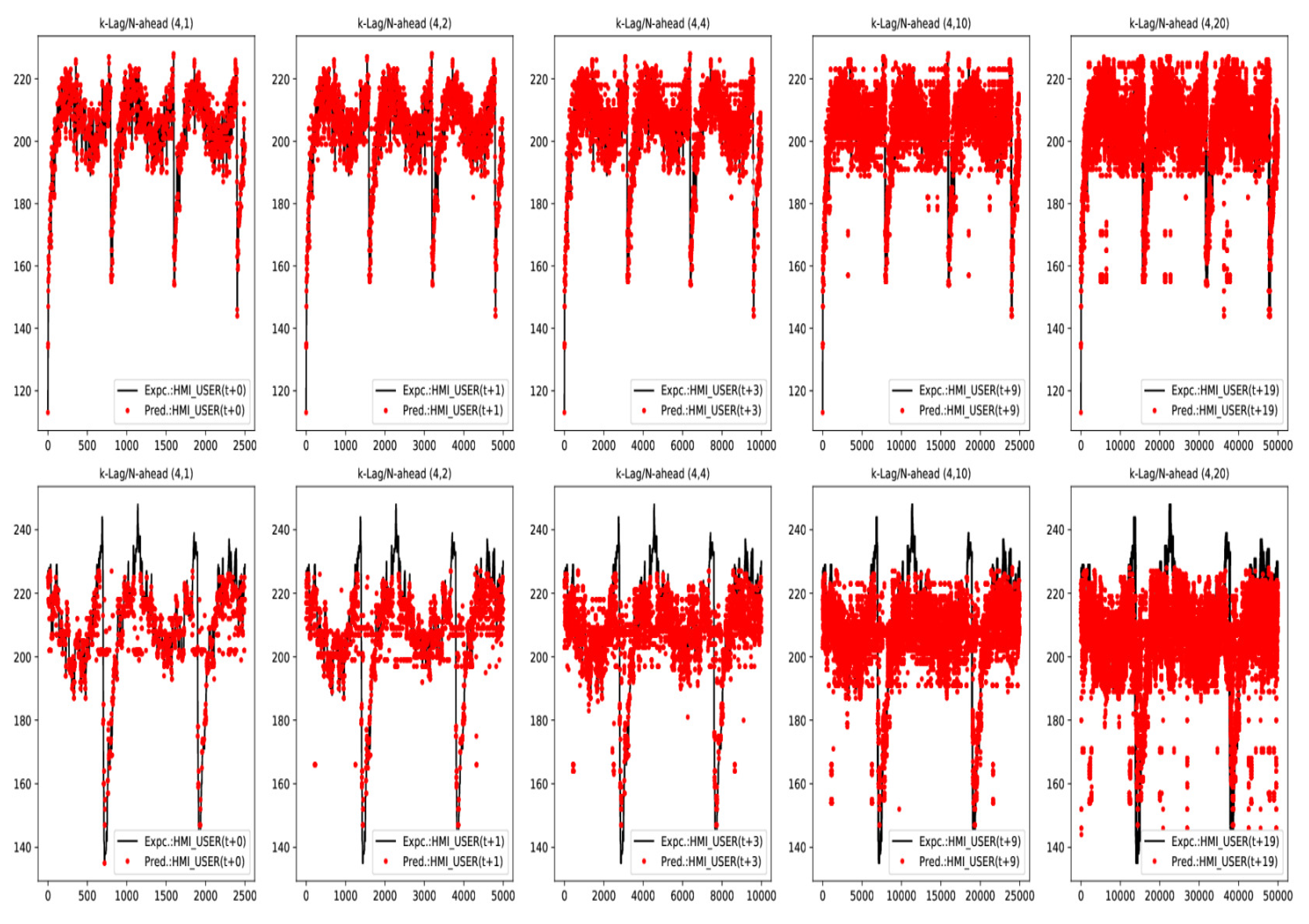
- LSTM E-D yields consistent lower rolling window RMSE () values than baseline score (Table 3) for all InS data test cases (which is desirable performance). While, Trident only yields lower rolling window RMSE () values than baseline () for shorter target sequence () cases, as long as source target sequence is . A behaviour that is directly related to keeping kernel filter size constant for various source/target lengths.
- LSTM E-D generally yields lower than Trident model. Trident models needs to be tuned to work with a particular combination of K−Lag/N−Step source/target sequence lengths.
- LSTM E-D and Trident model yield comparable Accuracy(tolerance) values for all test cases. Therefore, both models are adept are modeling the general trend of expected future patterns (within a tolerance).
- LSTM E-D shows lower () validation accuracy than Trident. Suggests Trident achieves less over-fitting with the same amount of available training data.
- Out-of-sample scores are higher than (Table 4) for all models, but show consistent trends of values for same K−Lag/N−Step InS test cases. Therefore, InS performance is a good indicator for estimating the performance for OuS datasets.
6.2. Prediction Accuracy
- Accuracy(hard) measure for LSTM E-D is higher approximately (25%) compared to custom design Trident model.
- Accuracy(hard) measure for LSTM E-D is lower (approx. < 20%) for curriculum learning than for Teacher Forcing, but former is achieved via faster learning ( vs. ).
- BLEU scores generally validate Accuracy(hard) measure, that is, higher Accuracy(hard) value will yield higher BLEU n-gram scores.
- Curriculum learning seems to help Trident model more (approximately by factor of 1.06) than it does to LSTM E-D model.
7. Conclusions and Future Work
7.1. Conclusions
7.2. Future Work
Author Contributions
Funding
Conflicts of Interest
References
- IAEA. International Nuclear Event Scale (INES). Available online: https://www.iaea.org/resources/databases/international-nuclear-and-radiological-event-scale (accessed on 27 March 2020).
- IAEA. INSAG-7 Safety Report The Chernobyl Accident (circa 1992). Available online: http://www-pub.iaea.org (accessed on 27 March 2020).
- Nuclear Energy Institute. Lessons from the 1979 Accident at Three Mile Island (Circa 2019). Available online: https://www.nei.org/resources/fact-sheets/lessons-from-1979-accident-at-three-mile-island (accessed on 27 March 2020).
- Manzey, D.; Reichenbach, J.; Onnasch, L. Human performance consequences of automated decision aids: The impact of degree of automation and system experience. J. Cogn. Eng. Decis. Mak. 2012, 6, 57–87. [Google Scholar] [CrossRef]
- Singh, H.V.; Mahmoud, Q.H. EYE-on-HMI: A Framework for monitoring human machine interfaces in control rooms. In Proceedings of the 2017 IEEE 30th Canadian Conference on Electrical and Computer Engineering (CCECE), Windsor, ON, Canada, 30 April–3 May 2017; pp. 1–5. [Google Scholar]
- Singh, H.V.; Mahmoud, Q.H. Evaluation of ARIMA Models for Human–Machine Interface State Sequence Prediction. Mach. Learn. Knowl. Extr. 2019, 1, 18. [Google Scholar] [CrossRef] [Green Version]
- Shih, S.Y.; Sun, F.K.; Lee, H.Y. Temporal pattern attention for multivariate time series forecasting. Mach. Learn. 2019, 108, 1421–1441. [Google Scholar] [CrossRef] [Green Version]
- Wickens, C.D. Situation awareness: Review of Mica Endsley’s 1995 articles on situation awareness theory and measurement. Hum. Factors 2008, 50, 397–403. [Google Scholar] [CrossRef] [PubMed]
- Lundberg, J. Situation awareness systems, states and processes: A holistic framework. Theor. Issues Ergon. Sci. 2015, 16, 447–473. [Google Scholar] [CrossRef]
- McAnally, K.; Davey, C.; White, D.; Stimson, M.; Mascaro, S.; Korb, K. Inference in the Wild: A Framework for Human Situation Assessment and a Case Study of Air Combat. Cogn. Sci. 2018, 42, 2181–2204. [Google Scholar] [CrossRef] [Green Version]
- Endsley, M.R. Automation and situation awareness. Autom. Hum. Performance Theory Appl. 1996, 20, 163–181. [Google Scholar]
- Salmon, P.M.; Stanton, N.A.; Walker, G.H.; Jenkins, D.; Ladva, D.; Rafferty, L.; Young, M. Measuring Situation Awareness in complex systems: Comparison of measures study. Int. J. Ind. Ergon. 2009, 39, 490–500. [Google Scholar] [CrossRef]
- Jones, D.G.; Endsley, M.R. Examining the validity of real-time probes as a metric of situation awareness. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Diego, CA, USA, 30 July–4 August 2000; Volume 1, p. 278. [Google Scholar]
- Endsley, M.R.; Selcon, S.J.; Hardiman, T.D.; Croft, D.G. A comparative analysis of SAGAT and SART for evaluations of situation awareness. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Chicago, IL, USA, 5–9 October 1998; Volume 42, pp. 82–86. [Google Scholar]
- Li, G.; Wang, Y.; Zhu, F.; Sui, X.; Wang, N.; Qu, X.; Green, P. Drivers’ visual scanning behavior at signalized and unsignalized intersections: A naturalistic driving study in China. J. Saf. Res. 2019, 71, 219–229. [Google Scholar] [CrossRef]
- Li, G.; Lai, W.; Sui, X.; Li, X.; Qu, X.; Zhang, T.; Li, Y. Influence of traffic congestion on driver behavior in post-congestion driving. Accid. Anal. Prev. 2020, 141, 105508. [Google Scholar] [CrossRef]
- Precht, L.; Keinath, A.; Krems, J.F. Effects of driving anger on driver behavior–Results from naturalistic driving data. Transp. Res. Part Traffic Psychol. Behav. 2017, 45, 75–92. [Google Scholar] [CrossRef]
- Ghasemzadeh, A.; Ahmed, M.M. Utilizing naturalistic driving data for in-depth analysis of driver lane-keeping behavior in rain: Non-parametric MARS and parametric logistic regression modeling approaches. Transp. Res. Part Emerg. Technol. 2018, 90, 379–392. [Google Scholar] [CrossRef]
- Balsa-Barreiro, J.; Valero-Mora, P.M.; Berné-Valero, J.L.; Varela-García, F.A. GIS mapping of driving behavior based on naturalistic driving data. ISPRS Int. J. -Geo-Inf. 2019, 8, 226. [Google Scholar] [CrossRef] [Green Version]
- Mikolov, T.; Karafiát, M.; Burget, L.; Černockỳ, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Elman, J.L. Distributed representations, simple recurrent networks, and grammatical structure. Mach. Learn. 1991, 7, 195–225. [Google Scholar] [CrossRef] [Green Version]
- Levy, O.; Goldberg, Y.; Dagan, I. Improving distributional similarity with lessons learned from word embeddings. Trans. Assoc. Comput. Linguist. 2015, 3, 211–225. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008.
- Takase, S.; Okazaki, N. Positional Encoding to Control Output Sequence Length. arXiv 2019, arXiv:1904.07418. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Cheng, J.; Dong, L.; Lapata, M. Long short-term memory-networks for machine reading. arXiv 2016, arXiv:1601.06733. [Google Scholar]
- Raganato, A.; Tiedemann, J. An analysis of encoder representations in transformer-based machine translation. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018. [Google Scholar]
- Voita, E.; Talbot, D.; Moiseev, F.; Sennrich, R.; Titov, I. Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned. arXiv 2019, arXiv:1905.09418. [Google Scholar]
- Barrault, L.; Bojar, O.; Costa-jussà, M.R.; Federmann, C.; Fishel, M.; Graham, Y.; Haddow, B.; Huck, M.; Koehn, P.; Malmasi, S.; et al. Findings of the 2019 conference on machine translation (wmt19). In Proceedings of the Fourth Conference on Machine Translation (Volume 2: Shared Task Papers, Day 1), Nanchang, China, 27–29 September 2019; pp. 1–61. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Rajpurkar, P.; Jia, R.; Liang, P. Know What You Don’t Know: Unanswerable Questions for SQuAD. arXiv 2018, arXiv:1806.03822. [Google Scholar]
- Conneau, A.; Kiela, D.; Schwenk, H.; Barrault, L.; Bordes, A. Supervised learning of universal sentence representations from natural language inference data. arXiv 2017, arXiv:1705.02364. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding with Unsupervised Learning; Technical report; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Mishra, N.; Rohaninejad, M.; Chen, X.; Abbeel, P. A simple neural attentive meta-learner. arXiv 2017, arXiv:1707.03141. [Google Scholar]
- Ramadge, P.J.; Wonham, W.M. Supervisory control of a class of discrete event processes. SIAM J. Control. Optim. 1987, 25, 206–230. [Google Scholar] [CrossRef] [Green Version]
- Howard, J.; Ruder, S. Universal language model fine-tuning for text classification. arXiv 2018, arXiv:1801.06146. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Liu, Y.; Ji, L.; Huang, R.; Ming, T.; Gao, C.; Zhang, J. An attention-gated convolutional neural network for sentence classification. Intell. Data Anal. 2019, 23, 1091–1107. [Google Scholar] [CrossRef] [Green Version]
- Yin, W.; Schütze, H.; Xiang, B.; Zhou, B. Abcnn: Attention-based convolutional neural network for modeling sentence pairs. Trans. Assoc. Comput. Linguist. 2016, 4, 259–272. [Google Scholar] [CrossRef]
- Culurciello, E.; Zaidy, A.; Gokhale, V. Computation and memory bandwidth in deep neural networks. Medium 2017, 5, 1–4. [Google Scholar]
- Honnibal, M. Embed, Encode, Attend, Predict: The New Deep Learning Formula for State-Ofthe-Art NLP Models; Explosion AI: Berlin, Germany, 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wiseman, S.; Rush, A.M. Sequence-to-sequence learning as beam-search optimization. arXiv 2016, arXiv:1606.02960. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Bengio, S.; Vinyals, O.; Jaitly, N.; Shazeer, N. Scheduled sampling for sequence prediction with recurrent neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 1171–1179. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description |
|---|---|
| or | Fixed time-series window of size k, containing k-lagged samples from past time steps … . |
| or | Fixed time-series window of size n, containing n-ahead samples expected in future time steps … . |
| , | represents an HMI DES event, containing two one-hot encoded feature vectors: —HMI indication value vector, —User input value vector. Where, each , D is the fixed dimensionality (dictionary size) of HMI DES event space (currently set to 255) including the <> token is same in construction as , but is used to denote the expected HMI DES event. |
| k-lagged sequence of HMI indication () and user input () events containing samples of feature vectors used as model training input pattern. = , …, is a DES HMI state vector of . | |
| n-step ahead sequence of HMI indication () and user input () events containing samples of feature vector values used as model training target output pattern (ground truth). = , …,. is the expected output event sequence or translated HMI DES state vector of . |
| n-Lag | RMSEp | RMSEp (roll.Win.) |
|---|---|---|
| 1 | 3.75 | 3.75 |
| 2 | 5.69 | 3.56 |
| 10 | 9.48 | 6.62 |
| 20 | 11.08 | 7.21 |
| 50 | 14.16 | 9.61 |
| Test Cases/Metrics | k-Lag | n-Step | RMSEp (roll.Win) | Epocs | RMSErw (rollWin) | Accuracy (Hard) | Accuracy (Tolerance) | BLEU 1 | BLEU 2 | BLEU 3 | BLEU 4 | TRN (acc) | VAL (acc) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 1 | 3.75 | 158 | 1.153 | 79.76% | 99.88% | 1 | 0 | 0 | 0 | 69.10% | 32.10% | |
| 4 | 20 | 7.21 | 164 | 3.529 | 72.25% | 99.36% | 1 | 0.98 | 0.92 | 0.77 | 85.90% | 25.40% | |
| LSTM E-D | 8 | 1 | 3.75 | 188 | 4.98 | 67.04% | 98.90% | 1 | 0 | 0 | 0 | 94.20% | 18.20% |
| Teacher Forcing | 8 | 20 | 7.21 | 135 | 1.925 | 93.81% | 99.74% | 1 | 1 | 1 | 0.99 | 99.40% | 11.00% |
| 16 | 20 | 7.21 | 149 | 0.019 | 99.88% | 100.00% | 1 | 1 | 1 | 1 | 99.90% | 10.60% | |
| 32 | 20 | 7.21 | 148 | 0 | 100.00% | 100.00% | 1 | 1 | 1 | 1 | 100.00% | 9.50% | |
| 4 | 1 | 3.75 | 81 | 1.262 | 79.24% | 99.76% | 1 | 0 | 0 | 0 | 70.30% | 31.40% | |
| 4 | 20 | 7.21 | 81 | 7.224 | 38.69% | 97.53% | 0.99 | 0.93 | 0.89 | 0.79 | 64.50% | 9.00% | |
| LSTM E-D | 8 | 1 | 3.75 | 81 | 0.314 | 95.48% | 100.00% | 1 | 0 | 0 | 0 | 92.90% | 26.10% |
| Curriculum Learning | 8 | 20 | 7.21 | 81 | 4.401 | 56.03% | 98.99% | 0.99 | 0.97 | 0.94 | 0.87 | 93.30% | 7.30% |
| 16 | 20 | 7.21 | 81 | 2.242 | 67.44% | 99.62% | 0.99 | 0.98 | 0.96 | 0.92 | 99.90% | 6.70% | |
| 32 | 20 | 7.21 | 81 | 2.5 | 65.65% | 99.58% | 0.99 | 0.98 | 0.96 | 0.91 | 99.40% | 7.10% | |
| 4 | 1 | 3.75 | 41 | 1.608 | 67.08% | 99.76% | 1 | 0 | 0 | 0 | 99.20% | 83.40% | |
| 4 | 20 | 7.21 | 421 | 7.165 | 46.72% | 97.71% | 1 | 0.96 | 0.94 | 0.89 | 95.20% | 20.30% | |
| Trident | 8 | 1 | 3.75 | 41 | 1.711 | 66.64% | 99.52% | 1 | 0 | 0 | 0 | 99.50% | 80.80% |
| Teacher Forcing | 8 | 20 | 7.21 | 421 | 3.559 | 79.24% | 99.37% | 1 | 0.98 | 0.97 | 0.94 | 95.20% | 15.70% |
| 16 | 20 | 7.21 | 421 | 70.872 | 41.11% | 84.50% | 0.85 | 0.74 | 0.71 | 0.62 | 98.60% | 16.00% | |
| 32 | 20 | 7.21 | 421 | 90.354 | 28.79% | 75.43% | 0.75 | 0.62 | 0.59 | 0.49 | 99.10% | 18.50% | |
| 4 | 1 | 3.75 | 81 | 2.238 | 54.80% | 99.84% | 1 | 0 | 0 | 0 | 85.70% | 71.90% | |
| 4 | 20 | 7.21 | 81 | 18.128 | 28.75% | 95.18% | 0.95 | 0.84 | 0.78 | 0.64 | 49.70% | 15.20% | |
| Trident | 8 | 1 | 3.75 | 81 | 1.902 | 56.92% | 99.88% | 1 | 0 | 0 | 0 | 86.90% | 67.10% |
| Curriculum Learning | 8 | 20 | 7.21 | 81 | 13.634 | 68.87% | 98.36% | 0.98 | 0.91 | 0.86 | 0.76 | 86.10% | 12.50% |
| 16 | 20 | 7.21 | 81 | 16.424 | 74.36% | 97.95% | 0.97 | 0.92 | 0.88 | 0.8 | 91.10% | 10.00% | |
| 32 | 20 | 7.21 | 81 | 15.051 | 65.22% | 98.14% | 0.97 | 0.91 | 0.87 | 0.78 | 92.80% | 10.40% |
| Test Cases/Metrics | k-Lag | n-Step | RMSEp (roll.Win) | Epocs | RMSErw (rollWin) | Accuracy (hard) | Accuracy (Tolerance) | BLEU 1 | BLEU 2 | BLEU 3 | BLEU 4 | TRN (acc) | VAL (acc) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 16 | 4 | 4.32 | 0 | 10.72 | 16.05% | 90.14% | 0.99 | 0.75 | 0.51 | 0.19 | 0 | 0 | |
| 16 | 10 | 6.62 | 0 | 11.544 | 12.44% | 89.27% | 0.99 | 0.78 | 0.7 | 0.44 | 0 | 0 | |
| LSTM E-D | 16 | 20 | 7.21 | 0 | 12.236 | 11.47% | 90.38% | 0.98 | 0.79 | 0.73 | 0.54 | 0 | 0 |
| Teacher Forcing | 32 | 4 | 4.32 | 0 | 11.101 | 14.59% | 90.11% | 0.99 | 0.75 | 0.51 | 0.18 | 0 | 0 |
| 32 | 10 | 6.62 | 0 | 12.103 | 12.20% | 89.18% | 0.99 | 0.77 | 0.68 | 0.41 | 0 | 0 | |
| 32 | 20 | 7.21 | 0 | 12.127 | 11.40% | 90.63% | 0.98 | 0.79 | 0.73 | 0.54 | 0 | 0 | |
| 16 | 4 | 4.32 | 0 | 10.826 | 17.47% | 90.66% | 1 | 0.77 | 0.58 | 0.26 | 0 | 0 | |
| 16 | 10 | 6.62 | 0 | 11.422 | 14.36% | 89.89% | 0.98 | 0.83 | 0.79 | 0.64 | 0 | 0 | |
| LSTM E-D | 16 | 20 | 7.21 | 0 | 12.044 | 11.57% | 89.68% | 0.98 | 0.82 | 0.78 | 0.63 | 0 | 0 |
| Curriculum Learning | 32 | 4 | 4.32 | 0 | 11.156 | 14.35% | 89.78% | 0.99 | 0.81 | 0.62 | 0.31 | 0 | 0 |
| 32 | 10 | 6.62 | 0 | 11.359 | 13.20% | 91.27% | 0.99 | 0.81 | 0.76 | 0.56 | 0 | 0 | |
| 32 | 20 | 7.21 | 0 | 12.426 | 11.55% | 90.11% | 0.98 | 0.81 | 0.77 | 0.62 | 0 | 0 | |
| 16 | 4 | 4.32 | 0 | 11.693 | 11.66% | 88.68% | 0.99 | 0.66 | 0.39 | 0.12 | 0 | 0 | |
| 16 | 10 | 6.62 | 0 | 17.119 | 11.25% | 88.31% | 0.96 | 0.68 | 0.58 | 0.31 | 0 | 0 | |
| Trident | 16 | 20 | 7.21 | 0 | 105.867 | 8.96% | 63.64% | 0.68 | 0.45 | 0.41 | 0.27 | 0 | 0 |
| Teacher Forcing | 32 | 4 | 4.32 | 0 | 16.101 | 10.37% | 86.86% | 0.97 | 0.7 | 0.46 | 0.18 | 0 | 0 |
| 32 | 10 | 6.62 | 0 | 12.948 | 11.40% | 89.60% | 0.98 | 0.73 | 0.65 | 0.41 | 0 | 0 | |
| 32 | 20 | 7.21 | 0 | 112.988 | 6.18% | 55.60% | 0.63 | 0.43 | 0.4 | 0.29 | 0 | 0 | |
| 16 | 4 | 4.32 | 0 | 11.068 | 10.00% | 89.91% | 0.99 | 0.84 | 0.68 | 0.37 | 0 | 0 | |
| 16 | 10 | 6.62 | 0 | 15.302 | 10.29% | 84.66% | 0.9 | 0.67 | 0.6 | 0.38 | 0 | 0 | |
| Trident | 16 | 20 | 7.21 | 0 | 34.656 | 9.91% | 84.31% | 0.9 | 0.67 | 0.62 | 0.45 | 0 | 0 |
| Curriculum Learning | 32 | 4 | 4.32 | 0 | 15.779 | 10.32% | 84.65% | 0.92 | 0.75 | 0.61 | 0.39 | 0 | 0 |
| 32 | 10 | 6.62 | 0 | 14.224 | 10.64% | 87.36% | 0.95 | 0.72 | 0.66 | 0.47 | 0 | 0 | |
| 32 | 20 | 7.21 | 0 | 33.522 | 10.40% | 87.50% | 0.91 | 0.69 | 0.65 | 0.49 | 0 | 0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
V. P. Singh, H.; Mahmoud, Q.H. NLP-Based Approach for Predicting HMI State Sequences Towards Monitoring Operator Situational Awareness. Sensors 2020, 20, 3228. https://doi.org/10.3390/s20113228
V. P. Singh H, Mahmoud QH. NLP-Based Approach for Predicting HMI State Sequences Towards Monitoring Operator Situational Awareness. Sensors. 2020; 20(11):3228. https://doi.org/10.3390/s20113228
Chicago/Turabian StyleV. P. Singh, Harsh, and Qusay H. Mahmoud. 2020. "NLP-Based Approach for Predicting HMI State Sequences Towards Monitoring Operator Situational Awareness" Sensors 20, no. 11: 3228. https://doi.org/10.3390/s20113228
APA StyleV. P. Singh, H., & Mahmoud, Q. H. (2020). NLP-Based Approach for Predicting HMI State Sequences Towards Monitoring Operator Situational Awareness. Sensors, 20(11), 3228. https://doi.org/10.3390/s20113228