Wireless Sensor Networks Fault-Tolerance Based on Graph Domination with Parallel Scatter Search



Abstract
1. Introduction
2. Related Works
2.1. Network Models Using Graphs
2.2. Virtual Backbone Network Fault-Tolerance
2.3. Network Lifetime
3. Parallel Scatter Search Algorithm with Elite and Featured Cores
- The parallel Scatter Search with Elite and Featured cores (pSSEF) method: finds optimal or near-optimal VBs,
- the FT-pSSEF method: adapts the obtained VBs to control the network VB fault-tolerance, and
- the SC-pSSEF method: adapts the obtained VBs to control the network VB scheduling.
3.1. Solution Representation
3.2. Fitness Evaluation
- The first objective is the extent to which the solution covers the graph, which represented by the term
- The second objective is to measure the solution connectivity which is given by the second term
- The third objective is the relative number of nodes in the solution which can be measured by the term
3.3. Scatter Search Procedures
3.3.1. Diversification Generation
3.3.2. Improvement
3.3.3. Reference Set Update
- RefSet that contains b elite solutions, and
- RefSet that contains diverse solutions.
3.3.4. Subset Generation
3.3.5. Solution Combination
3.4. Intensification Procedures
3.4.1. Local Search
3.4.2. Final Intensification
3.5. Parallel Procedures
3.5.1. Elite and Featured Cores
3.5.2. Migration
3.6. The pSSEF Algorithm
- How each worker selects and updates its reference set.
- How the migration process is applied.
3.6.1. The First Version pSSEF1
3.6.2. The Second Version pSSEF2
- The initial is generating by selecting 20% of its members from the best connected dominating solutions among all workers sub-populations. Then, the Featured Core computes the minimum hamming distances between each of the rest of unselected solutions and the selected connected dominating ones. Solutions with the largest distances are chosen to complement the remaining 80% of the members.
- At the beginning of each migration interval, the is updated in the same way that it was initialized.
- At the end of each migration interval, a refinement process is applied by calling the final intensification procedure to improve the obtained solutions in the CD solution set.
4. Algorithmic Implementations to Network Virtual Backbone Fault-Tolerance and Scheduling
4.1. Virtual Backbone Fault-Tolerance
4.1.1. Solution Reconnecting
| Algorithm 1 Solution Reconnecting. |
|
4.1.2. Solution Coverage
| Algorithm 2 Solution Coverage. |
|
4.1.3. The FT-pSSEF Algorithm
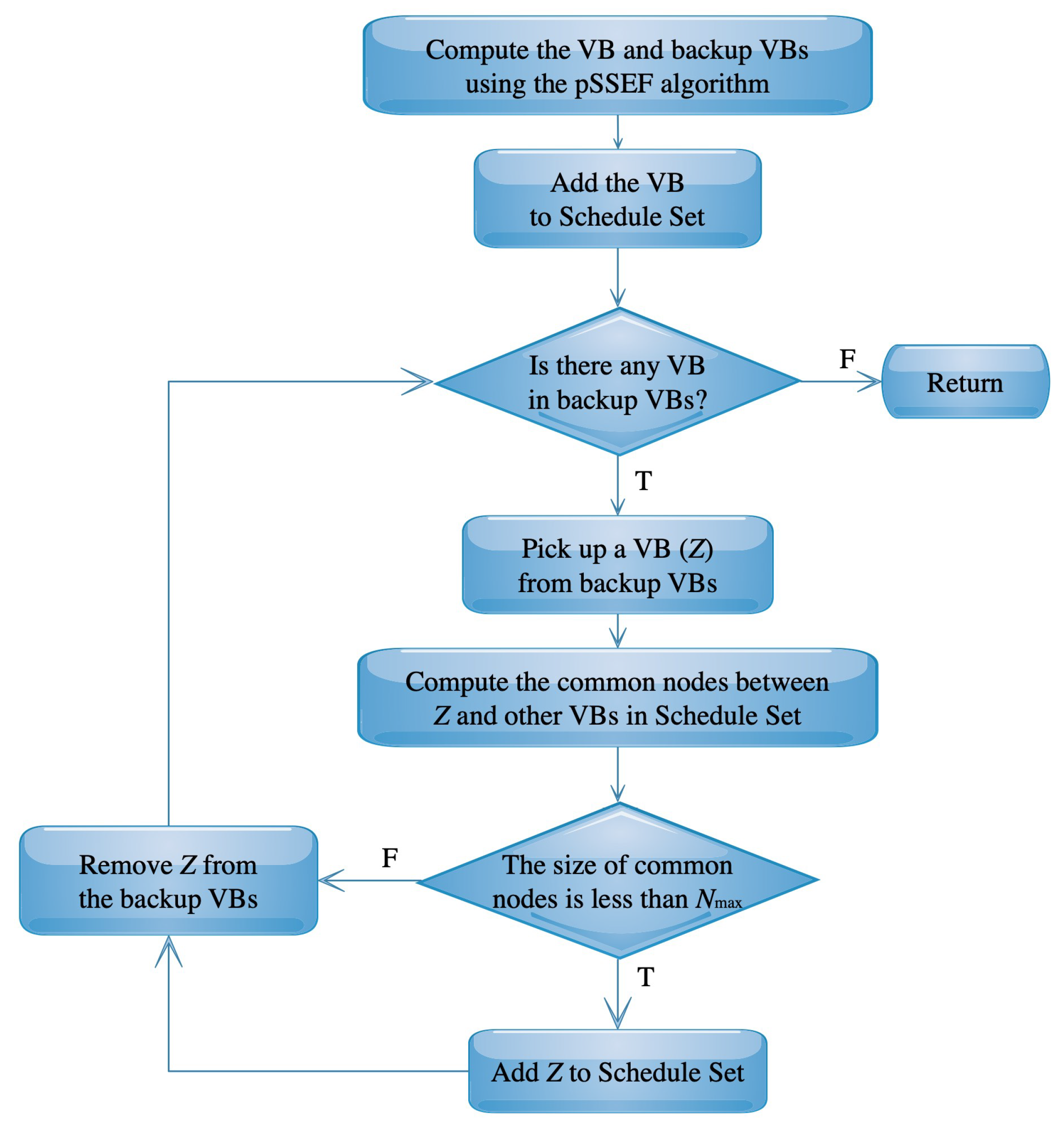
4.2. Virtual Backbone Scheduling
5. Numerical Results
- Minimum approximate domination number (Min) which is the number of nodes in the best connected dominating solution found in all independent runs.
- Average approximate domination number (Avg) which is the average number of nodes in the best connected dominating solution found in each independent runs.
- Processing time in seconds which is the average of the code running time over independent runs.
5.1. Test Bed and Parameter Setting
5.2. Performance Analysis
5.2.1. Performance Comparison between the pSSEF1 and pSSEF2 Versions
5.2.2. Performance Comparison between Sequential and Parallel Scatter Search
5.2.3. Parallel Performance of the pSSEF Method
- pSSEF: 2 Worker cores.
- pSSEF: 6 Worker cores.
- pSSEF: 10 Worker cores.
- pSSEF: 14 Worker cores.
- pSSEF: 18 Worker cores.
5.3. Results and Discussion
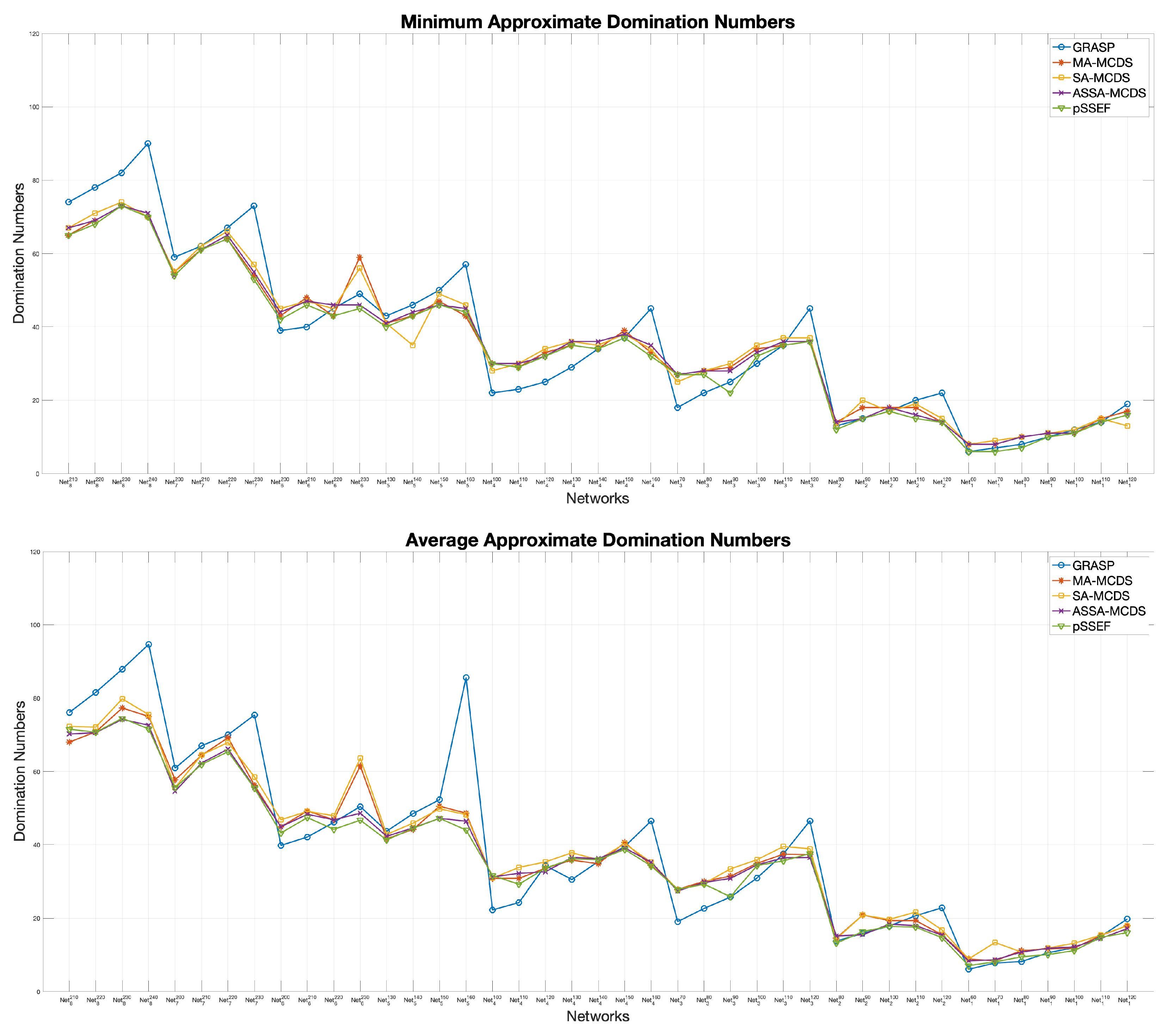
5.3.1. Performance Comparison of the pSSEF and Other Benchmark Methods
- GRASP: A greedy randomized adaptive search procedure for connected dominating set problems [27].
- MA-MCDS: Memetic algorithm for minimum connected dominating set [46].
- SA-MCDS: Simulated annealing for minimum connected dominating set [46].
- ASSA-MCDS: Adaptive scatter search algorithm for the minimum connected dominating set [45].
5.3.2. Virtual Backbone Fault-Tolerance Results
5.3.3. Virtual Backbone Scheduling Results
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fu, D.; Han, L.; Yang, Z.; Jhang, S.T. A Greedy Algorithm on constructing the minimum connected dominating set in wireless network. Int. J. Distrib. Sens. Netw. 2016, 12, 1703201. [Google Scholar] [CrossRef]
- He, J.S.; Ji, S.; Pan, Y.; Cai, Z. Load-balanced virtual backbone construction for wireless sensor networks. In Proceedings of the International Conference on Combinatorial Optimization and Applications, COCOA 2012, Banff, AB, Canada, 5–9 August 2012; pp. 1–12. [Google Scholar]
- Mnif, K.; Rong, B.; Kadoch, M. Virtual Backbone Based on Mcds for Topology Control in Wireless ad Hoc Networks; Association for Computing Machinery: New York, NY, USA, 2005; pp. 230–233. [Google Scholar]
- Asgarnezhad, R.; Torkestani, J.A. Connected dominating set problem and its application to wireless sensor networks. In Proceedings of the First International Conference on Advanced Communications and Computation, INFOCOMP 2011, Barcelona, Spain, 23–29 October 2011; pp. 46–51. [Google Scholar]
- Kar, A.K. Bio inspired computing–A review of algorithms and scope of applications. Expert Syst. Appl. 2016, 59, 20–32. [Google Scholar] [CrossRef]
- Wang, J.; Hedar, A.R.; Wang, S. Scatter Search for Rough Set Attribute Reduction. In Proceedings of the 2007 Second International Conference on Bio-Inspired Computing: Theories and Applications, Zhengzhou, China, 14–17 September 2007; pp. 236–240. [Google Scholar]
- Wang, J.; Zhang, Q.; Abdel-Rahman, H.; Abdel-Monem, M.I. A rough set approach to feature selection based on scatter search metaheuristic. J. Syst. Sci. Complexity 2014, 27, 157–168. [Google Scholar] [CrossRef]
- Martins, S.L.; Ribeiro, C.C.; Rosseti, I. Applications and parallel implementations of metaheuristics in network design and routing. In Proceedings of the Asian Applied Computing Conference, AACC 2004, Kathmandu, Nepal, 29–31 October 2004; pp. 205–213. [Google Scholar]
- Shyama, M.; Pillai, A.S. Fault-Tolerant Techniques for Wireless Sensor Network—A Comprehensive Survey. In Innovations in Electronics and Communication Engineering; Springer: Singapore, 2019; pp. 261–269. [Google Scholar]
- Zhao, Y.; Wu, J.; Li, F.; Lu, S. VBS: Maximum lifetime sleep scheduling for wireless sensor networks using virtual backbones. In Proceedings of the 2010 Proceedings IEEE INFOCOM, San Diego, CA, USA, 15–19 March 2010; pp. 1–5. [Google Scholar]
- Yu, J.; Wang, N.; Wang, G.; Yu, D. Connected dominating sets in wireless ad hoc and sensor networks—A comprehensive survey. Comput. Commun. 2013, 36, 121–134. [Google Scholar] [CrossRef]
- Blum, J.; Ding, M.; Thaeler, A.; Cheng, X. Connected dominating set in sensor networks and MANETs. In Handbook of Combinatorial Optimization; Springer: Boston, MA, USA, 2004; pp. 329–369. [Google Scholar]
- Du, D.Z.; Wan, P.J. Connected Dominating Set: Theory and Applications; Springer: New York, NY, USA, 2012. [Google Scholar]
- Fukunaga, T. Adaptive Algorithm for Finding Connected Dominating Sets in Uncertain Graphs. IEEE/ACM Trans. Netw. 2020, 28, 387–398. [Google Scholar] [CrossRef]
- Liang, J.; Yi, M.; Zhang, W.; Li, Y.; Liang, X.; Qin, B. On Constructing Strongly Connected Dominating and Absorbing Set in 3-Dimensional Wireless Ad Hoc Networks. Complexity 2020, 2020, 9189645. [Google Scholar] [CrossRef]
- Cheng, X.; Ding, M.; Chen, D. An approximation algorithm for connected dominating set in ad hoc networks. In Proceedings of the International Workshop on Theoretical Aspects of Wireless Ad Hoc, Sensor, and Peer-to-Peer Networks (TAWN 2004), Chicago, IL, USA, 11–12 June 2004. [Google Scholar]
- Tang, Q.; Yang, K.; Li, P.; Zhang, J.; Luo, Y.; Xiong, B. An energy efficient MCDS construction algorithm for wireless sensor networks. EURASIP J. Wirel. Commun. Netw. 2012, 2012, 83. [Google Scholar] [CrossRef]
- Xie, R.; Qi, D.; Li, Y.; Wang, J.Z. A novel distributed MCDS approximation algorithm for wireless sensor networks. Wirel. Commun. Mob. Comput. 2009, 9, 427–437. [Google Scholar] [CrossRef]
- Tang, Q.; Yang, K.; Wang, J.; Luo, Y.; Li, K.; Yu, F. Wireless sensor network MCDS construction algorithms with energy consideration for extreme environments healthcare. IEEE Access 2019, 7, 33130–33144. [Google Scholar] [CrossRef]
- Du, H.; Wu, W.; Ye, Q.; Li, D.; Lee, W.; Xu, X. CDS-based virtual backbone construction with guaranteed routing cost in wireless sensor networks. IEEE Trans. Parallel Distrib. Syst. 2012, 24, 652–661. [Google Scholar]
- Bai, X.; Zhao, D.; Bai, S.; Wang, Q.; Li, W.; Mu, D. Minimum connected dominating sets in heterogeneous 3D wireless ad hoc networks. Ad Hoc Netw. 2020, 97, 102023. [Google Scholar] [CrossRef]
- Li, R.; Hu, S.; Liu, H.; Li, R.; Ouyang, D.; Yin, M. Multi-Start Local Search Algorithm for the Minimum Connected Dominating Set Problems. Mathematics 2019, 7, 1173. [Google Scholar] [CrossRef]
- Misra, R.; Mandal, C. Minimum connected dominating set using a collaborative cover heuristic for ad hoc sensor networks. IEEE Trans. Parallel Distrib. Syst. 2009, 21, 292–302. [Google Scholar] [CrossRef]
- Pino, T.; Choudhury, S.; Al-Turjman, F. Dominating set algorithms for wireless sensor networks survivability. IEEE Access 2018, 6, 17527–17532. [Google Scholar] [CrossRef]
- Zhang, Z.; Gao, X.; Wu, W.; Du, D.Z. A PTAS for minimum connected dominating set in 3-dimensional wireless sensor networks. J. Glob. Optim. 2009, 45, 451–458. [Google Scholar] [CrossRef]
- Zhang, D.; Xu, M.; Xiao, W.; Gao, J.; Tang, W. Minimization of the redundant sensor nodes in dense wireless sensor networks. In Proceedings of the International Conference on Evolvable Systems, Wuhan, China, 21–23 September 2007; pp. 355–367. [Google Scholar]
- Li, R.; Hu, S.; Gao, J.; Zhou, Y.; Wang, Y.; Yin, M. GRASP for connected dominating set problems. Neural Comput. Appl. 2017, 28, 1059–1067. [Google Scholar] [CrossRef]
- Jovanovic, R.; Tuba, M. Ant colony optimization algorithm with pheromone correction strategy for the minimum connected dominating set problem. Comput. Sci. Inf. Syst. 2013, 10, 133–149. [Google Scholar] [CrossRef]
- Dagdeviren, Z.A.; Aydin, D.; Cinsdikici, M. Two population-based optimization algorithms for minimum weight connected dominating set problem. Appl. Soft Comput. 2017, 59, 644–658. [Google Scholar] [CrossRef]
- Hedar, A.R.; Ismail, R.; El Sayed, G.A.; Khayyat, K.M.J. Two meta-heuristics for the minimum connected dominating set problem with an application in wireless networks. In Proceedings of the 2015 3rd International Conference on Applied Computing and Information Technology/2nd International Conference on Computational Science and Intelligence (ACIT-CSI), Okayama, Japan, 12–16 July 2015; pp. 355–362. [Google Scholar]
- Hedar, A.R.; El-Sayed, G.A. Parallel genetic algorithm with elite and diverse cores for solving the minimum connected dominating set problem in wireless networks topology control. In Proceedings of the 2nd International Conference on Future Networks and Distributed Systems, ACM, Amman, Jordan, 26–27 June 2018; pp. 1–9. [Google Scholar]
- Mannan, M.; Rana, S.B. Fault tolerance in wireless sensor network. Int. J. Res. Appl. Sci. Eng. Technol. 2015, 5, 1785–1788. [Google Scholar]
- Liu, H.; Nayak, A.; Stojmenović, I. Fault-tolerant algorithms/protocols in wireless sensor networks. In Guide to Wireless Sensor Networks; Springer: London, UK, 2009; pp. 261–291. [Google Scholar]
- Pamarthi Swapna, B.; Neeraja, S. Fault Tolerance Review in Wireless Sensor Networks. Int. J. Res. Appl. Sci. Eng. Technol. 2017, 5, 1511–1515. [Google Scholar]
- Tiwari, R.; Thai, M.T. On enhancing fault tolerance of virtual backbone in a wireless sensor network with unidirectional links. In Sensors: Theory, Algorithms, and Applications; Springer: New York, NY, USA, 2012; pp. 3–18. [Google Scholar]
- Zhou, J.; Zhang, Z.; Tang, S.; Huang, X.; Mo, Y.; Du, D.Z. Fault-tolerant virtual backbone in heterogeneous wireless sensor network. IEEE/ACM Trans. Netw. 2017, 25, 3487–3499. [Google Scholar] [CrossRef]
- Yetgin, H.; Cheung, K.T.K.; El-Hajjar, M.; Hanzo, L.H. A survey of network lifetime maximization techniques in wireless sensor networks. IEEE Commun. Surv. Tutor. 2017, 19, 828–854. [Google Scholar] [CrossRef]
- Zhang, J.; Xu, L.; Yang, H. A novel sleep scheduling algorithm for wireless sensor networks. In Proceedings of the 2015 International Conference on Intelligent Information Hiding and Multimedia Signal Processing (IIH-MSP), Adelaide, Australia, 23–25 September 2015; pp. 364–367. [Google Scholar]
- Malini, K.; Surya, G. Connected Dominant Set Based Virtual Backbone Path Routing For Wireless Sensor Network. Int. J. 2015, 1, 186–191. [Google Scholar]
- Wei, X.; Liu, Y.; Bai, X. Maximizing Lifetime of CDS-Based Wireless Ad Hoc Networks. J. Commun. 2016, 11. [Google Scholar] [CrossRef]
- Liu, K.; Peng, J.; He, L.; Pan, J.; Li, S.; Ling, M.; Huang, Z. An active mobile charging and data collection scheme for clustered sensor networks. IEEE Trans. Veh. Technol. 2019, 68, 5100–5113. [Google Scholar] [CrossRef]
- Jin, Y.; Kwak, K.S.; Yoo, S.J. A Novel Energy Supply Strategy for Stable Sensor Data Delivery in Wireless Sensor Networks. IEEE Syst. J. 2020. [Google Scholar] [CrossRef]
- Tian, M.; Jiao, W.; Liu, J. The Charging Strategy of Mobile Charging Vehicles in Wireless Rechargeable Sensor Networks With Heterogeneous Sensors. IEEE Access 2020, 8, 73096–73110. [Google Scholar] [CrossRef]
- Tian, M.; Jiao, W.; Liu, J.; Ma, S. A Charging Algorithm for the Wireless Rechargeable Sensor Network with Imperfect Charging Channel and Finite Energy Storage. Sensors 2019, 19, 3887. [Google Scholar] [CrossRef]
- Hedar, A.R.; Abdulaziz, S.N.; Sewisy, A.A.; El-Sayed, G.A. Adaptive Scatter Search to Solve the Minimum Connected Dominating Set Problem for Efficient Management of Wireless Networks. Algorithms 2020, 13, 35. [Google Scholar] [CrossRef]
- Hedar, A.R.; Ismail, R.; El-Sayed, G.A.; Khayyat, K.M.J. Two Meta-Heuristics Designed to Solve the Minimum Connected Dominating Set Problem for Wireless Networks Design and Management. J. Netw. Syst. Manag. 2018, 27, 1–41. [Google Scholar] [CrossRef]
- Hedar, A.R.; Ismail, R. Simulated annealing with stochastic local search for minimum dominating set problem. Int. J. Mach. Learn. Cybern. 2012, 3, 97–109. [Google Scholar] [CrossRef]
- Hedar, A.R.; Ismail, R. Hybrid genetic algorithm for minimum dominating set problem. Prccceedings of the International Conference on Computational Science and Its Applications, Fukuoka, Japan, 23–26 March 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 457–467. [Google Scholar]
- Wang, J.; Hedar, A.R.; Wang, S.; Ma, J. Rough set and scatter search metaheuristic based feature selection for credit scoring. Expert Syst. Appl. 2012, 39, 6123–6128. [Google Scholar] [CrossRef]
- Laguna, M. Scatter search. In Search Methodologies; Burke, E.K., Kendall, G., Eds.; Springer: New York, NY, USA, 2014; pp. 119–141. [Google Scholar]
- Martí, R.; Laguna, M.; Glover, F. Principles of scatter search. Eur. J. Oper. Res. 2006, 169, 359–372. [Google Scholar] [CrossRef]
- Laguna, M.; Marti, R. Scatter Search: Methodology and Implementations in C; Springer Science & Business Media: New York, NY, USA, 2012. [Google Scholar]
- Bettstetter, C. On the minimum node degree and connectivity of a wireless multihop network. In Proceedings of the 3rd ACM International Symposium on Mobile Ad Hoc Networking Computing, Lausanne, Switzerland, 9–11 June 2002; Association for Computing Machinery: New York, NY, USA, 2002; pp. 80–91. [Google Scholar]
- Ho, C.K.; Singh, Y.P.; Ewe, H.T. An enhanced ant colony optimization metaheuristic for the minimum dominating set problem. Appl. Artif. Intell. 2006, 20, 881–903. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | No. of Vertices | Area | Range |
|---|---|---|---|
| 80 | 60–120 | ||
| 100 | 80–120 | ||
| 200 | 70–120 | ||
| 200 | 100–160 | ||
| 250 | 130–160 | ||
| 300 | 200–230 | ||
| 350 | 200–230 | ||
| 400 | 210–240 |
| Parameter | Definition | Value |
|---|---|---|
| Population size | 150 | |
| Number of local search iterations | 10 | |
| m | Migration interval | 10 |
| Size of RefSet | 15 | |
| CD | Size of the CD set | 50 |
| Max no. of common nodes in VB scheduling | ||
| The energy of the node in units | 100 | |
| The number of iterations for VB switching | 1 |
| Networks | pSSEF-MCDS | pSSEF-MCDS | pSSEF-MCDS | pSSEF-MCDS | pSSEF-MCDS | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | R | Avg | Min | Avg | Min | Avg | Min | Avg | Min | Avg | Min |
| 60 | 16.14 | 16 | 16.12 | 16 | 16.08 | 16 | 16.02 | 16 | 16.02 | 16 | |
| 80 | 14.74 | 14 | 14.54 | 14 | 14.60 | 14 | 14.36 | 14 | 14.28 | 14 | |
| 70 | 37.64 | 36 | 37.42 | 36 | 36.80 | 36 | 36.92 | 36 | 36.56 | 36 | |
| 100 | 34.20 | 32 | 34.28 | 32 | 33.98 | 32 | 34.04 | 32 | 33.74 | 32 | |
| 130 | 44.04 | 44 | 44.06 | 44 | 44.04 | 44 | 44.02 | 44 | 44.02 | 44 | |
| 200 | 46.72 | 45 | 46.06 | 45 | 46.20 | 45 | 45.96 | 45 | 45.80 | 45 | |
| 200 | 55.44 | 53 | 55.00 | 53 | 54.28 | 53 | 54.40 | 53 | 54.04 | 53 | |
| 210 | 71.62 | 70 | 71.40 | 70 | 71.44 | 70 | 71.08 | 70 | 70.68 | 70 | |
| Networks | GRASP | MA-MCDS | SA-MCDS | ASSA-MCDS | pSSEF | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | R | Avg | Min | Avg | Min | Avg | Min | Avg | Min | Avg | Min |
| 60 | 19.8 | 19 | 18.0 | 17 | 18.0 | 13 | 17.2 | 16 | 16.1 | 16 | |
| 70 | 15.1 | 14 | 15.3 | 15 | 15.4 | 15 | 14.5 | 14 | 14.8 | 14 | |
| 80 | 12.0 | 12 | 11.9 | 11 | 13.2 | 12 | 12.2 | 11 | 11.2 | 11 | |
| 90 | 10.6 | 10 | 11.7 | 11 | 11.9 | 11 | 11.8 | 11 | 10.1 | 10 | |
| 100 | 8.2 | 8 | 11.2 | 10 | 10.8 | 10 | 10.8 | 10 | 9.5 | 7 | |
| 110 | 7.8 | 7 | 8.4 | 8 | 13.4 | 9 | 8.7 | 8 | 8.1 | 6 | |
| 120 | 6.1 | 6 | 8.9 | 8 | 8.9 | 8 | 8.4 | 8 | 7.1 | 6 | |
| 80 | 22.9 | 22 | 15.5 | 14 | 16.8 | 15 | 15.4 | 14 | 14.7 | 14 | |
| 90 | 20.7 | 20 | 19.4 | 18 | 21.7 | 19 | 18.0 | 16 | 17.6 | 15 | |
| 100 | 17.9 | 17 | 19.4 | 18 | 19.7 | 17 | 18.4 | 18 | 17.8 | 17 | |
| 110 | 15.9 | 15 | 20.9 | 18 | 20.9 | 20 | 15.5 | 15 | 16.4 | 15 | |
| 120 | 13.8 | 13 | 14.6 | 14 | 14.4 | 13 | 15.2 | 14 | 13.2 | 12 | |
| 70 | 46.5 | 45 | 37.3 | 36 | 38.9 | 37 | 36.5 | 36 | 37.6 | 36 | |
| 80 | 37.5 | 35 | 37.4 | 35 | 39.5 | 37 | 36.4 | 36 | 35.6 | 35 | |
| 90 | 30.9 | 30 | 34.9 | 34 | 35.9 | 35 | 34.5 | 33 | 34.3 | 32 | |
| 100 | 25.8 | 25 | 31.4 | 29 | 33.4 | 30 | 30.8 | 28 | 25.9 | 22 | |
| 110 | 22.7 | 22 | 30.0 | 28 | 29.4 | 28 | 29.7 | 28 | 29.2 | 27 | |
| 120 | 19.1 | 18 | 27.8 | 27 | 27.8 | 25 | 27.4 | 27 | 27.8 | 27 | |
| 100 | 46.5 | 45 | 34.4 | 33 | 35.2 | 34 | 35.2 | 35 | 34.2 | 32 | |
| 110 | 39.5 | 37 | 40.6 | 39 | 40.3 | 38 | 39.1 | 38 | 38.7 | 37 | |
| 120 | 35.4 | 34 | 34.8 | 34 | 35.9 | 35 | 36.2 | 36 | 35.9 | 34 | |
| 130 | 30.5 | 29 | 35.8 | 35 | 37.8 | 36 | 36.5 | 36 | 36.1 | 35 | |
| 140 | 34.3 | 25 | 33.6 | 33 | 35.3 | 34 | 32.6 | 32 | 33.6 | 32 | |
| 150 | 24.3 | 23 | 30.8 | 29 | 33.8 | 30 | 32.2 | 30 | 29.2 | 29 | |
| 160 | 22.3 | 22 | 30.8 | 30 | 30.9 | 28 | 31.2 | 30 | 31.6 | 30 | |
| 130 | 85.6 | 57 | 48.6 | 43 | 48.2 | 46 | 46.4 | 45 | 44.0 | 44 | |
| 140 | 52.3 | 50 | 50.5 | 47 | 49.8 | 49 | 47.2 | 46 | 47.2 | 46 | |
| 150 | 48.5 | 46 | 44.2 | 43 | 45.9 | 35 | 44.6 | 44 | 44.5 | 43 | |
| 160 | 43.7 | 43 | 41.6 | 41 | 42.8 | 41 | 42.3 | 41 | 41.3 | 40 | |
| 200 | 50.4 | 49 | 61.5 | 59 | 63.6 | 56 | 48.6 | 46 | 46.7 | 45 | |
| 210 | 46.1 | 45 | 46.8 | 43 | 47.9 | 45 | 46.8 | 46 | 44.2 | 43 | |
| 220 | 42.1 | 40 | 49.2 | 48 | 49.1 | 47 | 48.3 | 47 | 47.4 | 46 | |
| 230 | 39.8 | 39 | 44.9 | 43 | 46.8 | 45 | 44.9 | 44 | 43.2 | 42 | |
| 200 | 75.4 | 73 | 56.2 | 54 | 58.5 | 57 | 55.6 | 55 | 55.4 | 53 | |
| 210 | 70.0 | 67 | 69.2 | 64 | 67.9 | 66 | 66.1 | 65 | 65.4 | 64 | |
| 220 | 67.0 | 62 | 64.4 | 61 | 64.5 | 62 | 62.3 | 61 | 61.9 | 61 | |
| 230 | 60.9 | 59 | 57.7 | 55 | 55.6 | 55 | 54.6 | 54 | 55.6 | 54 | |
| 210 | 94.7 | 90 | 75.0 | 70 | 75.5 | 70 | 72.6 | 71 | 71.6 | 70 | |
| 220 | 87.9 | 82 | 77.3 | 73 | 79.8 | 74 | 74.2 | 73 | 74.5 | 73 | |
| 230 | 81.6 | 78 | 70.8 | 69 | 72.1 | 71 | 70.6 | 69 | 70.7 | 68 | |
| 240 | 76.1 | 74 | 68.0 | 65 | 72.3 | 67 | 70.2 | 67 | 71.5 | 65 | |
| Overall Average | 39.2 | 36.8 | 37.6 | 35.7 | 38.5 | 36.0 | 36.6 | 35.5 | 35.9 | 34.3 | |
| No. of Beats | 27 | 24 | 33 | 24 | 37 | 35 | 30 | 28 | – | – | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hedar, A.-R.; Abdulaziz, S.N.; Mabrouk, E.; El-Sayed, G.A. Wireless Sensor Networks Fault-Tolerance Based on Graph Domination with Parallel Scatter Search. Sensors 2020, 20, 3509. https://doi.org/10.3390/s20123509
Hedar A-R, Abdulaziz SN, Mabrouk E, El-Sayed GA. Wireless Sensor Networks Fault-Tolerance Based on Graph Domination with Parallel Scatter Search. Sensors. 2020; 20(12):3509. https://doi.org/10.3390/s20123509
Chicago/Turabian StyleHedar, Abdel-Rahman, Shada N. Abdulaziz, Emad Mabrouk, and Gamal A. El-Sayed. 2020. "Wireless Sensor Networks Fault-Tolerance Based on Graph Domination with Parallel Scatter Search" Sensors 20, no. 12: 3509. https://doi.org/10.3390/s20123509
APA StyleHedar, A.-R., Abdulaziz, S. N., Mabrouk, E., & El-Sayed, G. A. (2020). Wireless Sensor Networks Fault-Tolerance Based on Graph Domination with Parallel Scatter Search. Sensors, 20(12), 3509. https://doi.org/10.3390/s20123509