1. Introduction
Dementia is a collective symptoms attributed to loss of recent and remote memory along with difficulty in absorbing new knowledge and trouble in decision making. The most common cause of dementia is Alzheimer’s disease which contributes to 60–70% of all dementia cases worldwide. Presently there is no treatment available [
1] and recent researches focuses on early detection of dementia signs [
2,
3,
4,
5,
6,
7,
8,
9] and reducing the risk factors to slow the cognitive decline [
10,
11,
12,
13].
Preliminary diagnosis of dementia typically performed in a mental hospital by a licensed psychiatrist interviewing and performing tests to the patients [
14,
15,
16]. Occasionally, diagnosing dementia becomes a complex process, as elderly patients with major depressive disorder often has overlapping symptoms with dementia. To determine whether a patient is truly suffering from dementia, a rigorous test must be performed [
17]. A temporary decrease in mental cognition caused by mental disorders is defined as pseudodementia [
17,
18,
19,
20,
21]. The key difference of pseudodementia is the reversibility of cognitive impairment, in contrast with the progressive nature of dementia. In some cases pseudodementia also serves as biomarker of dementia [
21]. Unfortunately, most engineering researches concern only with depression severity or dementia severity [
22,
23] and almost none focused on pseudodementia.
Features commonly employed for automated mental health screening include facial features (gaze, blink, emotion detection, etc.) [
24,
25,
26], biosignals (electroencephalogram, heart rate, respiration, etc.) [
27,
28,
29,
30], and auditory features (intensity, tone, speed of speech, etc.) [
23,
31]. Although biosignals are the most reliable data source, most of biosignal measurement devices are arduous to equip, limiting their value. In the other hand, facial and acoustic features may be obtained with minimal burden to the patient. As audio feature analysis is comparatively straightforward when compared to facial image analysis, we utilized audio features in this study instead of image features.
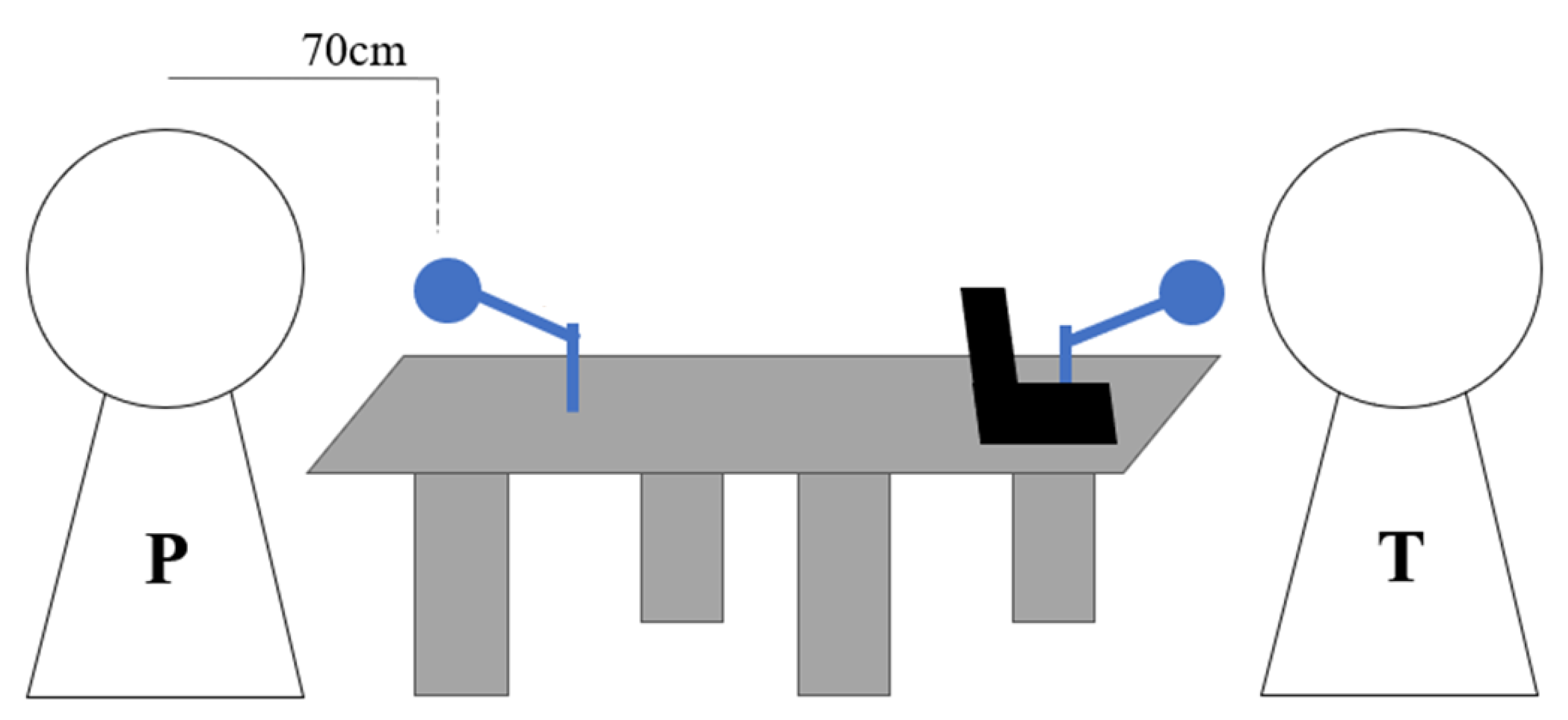
The aim of this study was to use an array microphone to record conversations between psychiatrists and depression patients and dementia patients in a clinical setting, and to investigate the differences in acoustic features between the two patient groups and not against healthy volunteers, differing from other conventional studies. Additionally, we are using dataset labelled from licensed psychiatrist to reduce the subjectivity. We revealed the features contributing for pseudodementia screening. In addition, we examined the possibility of utilizing machine learning for automatic pseudodementia screening.
4. Discussion
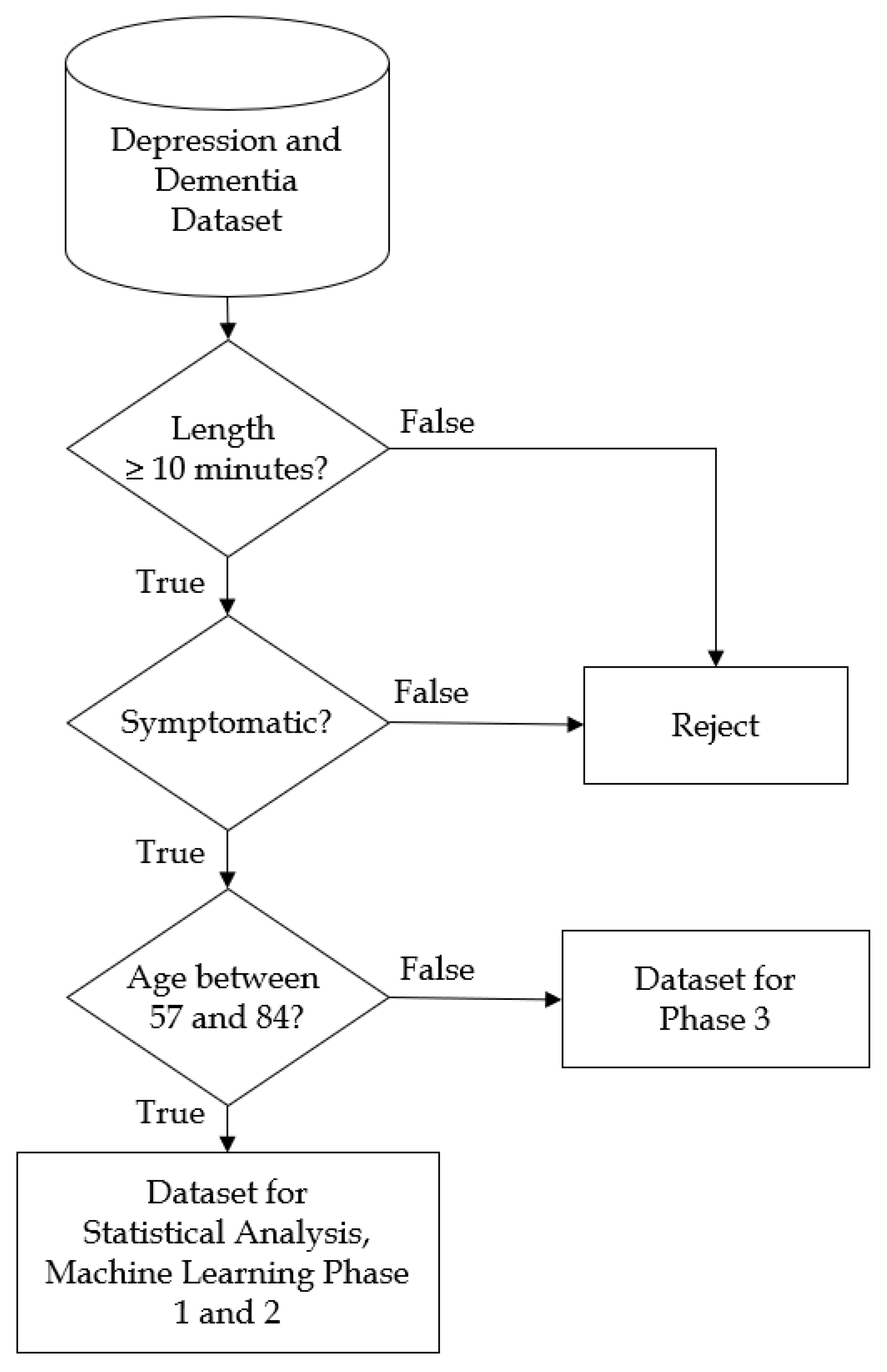
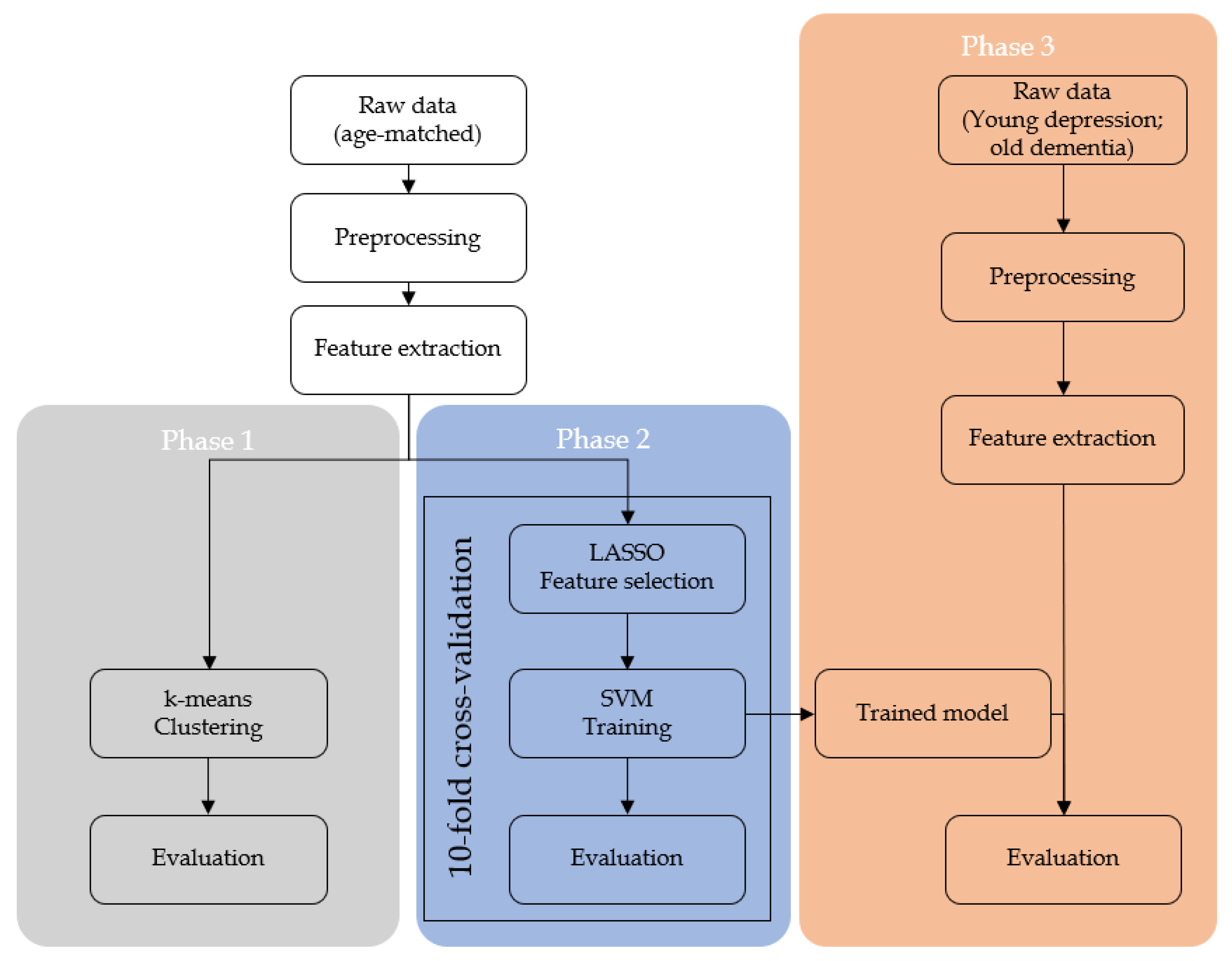
In the present study, we obtained the audio recordings from clinical interviews of depression and dementia patients. Then, the recordings were filtered according to the analysis criteria. Preprocessing and acoustic feature extraction was then performed to the qualifying datasets. Statistical analysis and machine learning were performed to the acoustic features.
This study has potential limitations. First, although subtle, the recordings were contaminated with the doctor’s voice. This naturally reduces the quality of the acoustic features. Next, there is no removal of silence between the dialogues. We hypothesized that long silences correspond to low motivation and therefore useful for predicting depression. Third, we did not consider real-time appliances. We utilized the full length of the recordings for predicting dementia versus depression. Finally, all the experiments were conducted in Japanese hospital, with Japanese doctors, and with Japanese patient. The speech features we extracted might be specific to the Japanese. Needless to say, these limitations imply potential bias in our study and the results of our study must be interpreted with attention to the limitations.
As a result, we found that GTCC coefficients 1, 3, and 12 along with MFCC coefficients 1, 3, 4, 7, 12 showed significant correlation with both clinical assessment tools: HAMD and MMSE, as shown in
Table 4. Interestingly, the sign of Pearson’s correlation coefficient were different; negative correlation was observed for HAMD and positive correlation was observed for MMSE. This suggests that although the features were important for both depression and dementia, they correlated differently. Another thing to note that the highest absolute correlation value with significance (
p < 0.05) was 0.346 for HAMD and 0.400 for MMSE, suggesting a weak to moderate correlation between the audio features and clinical rating scores.
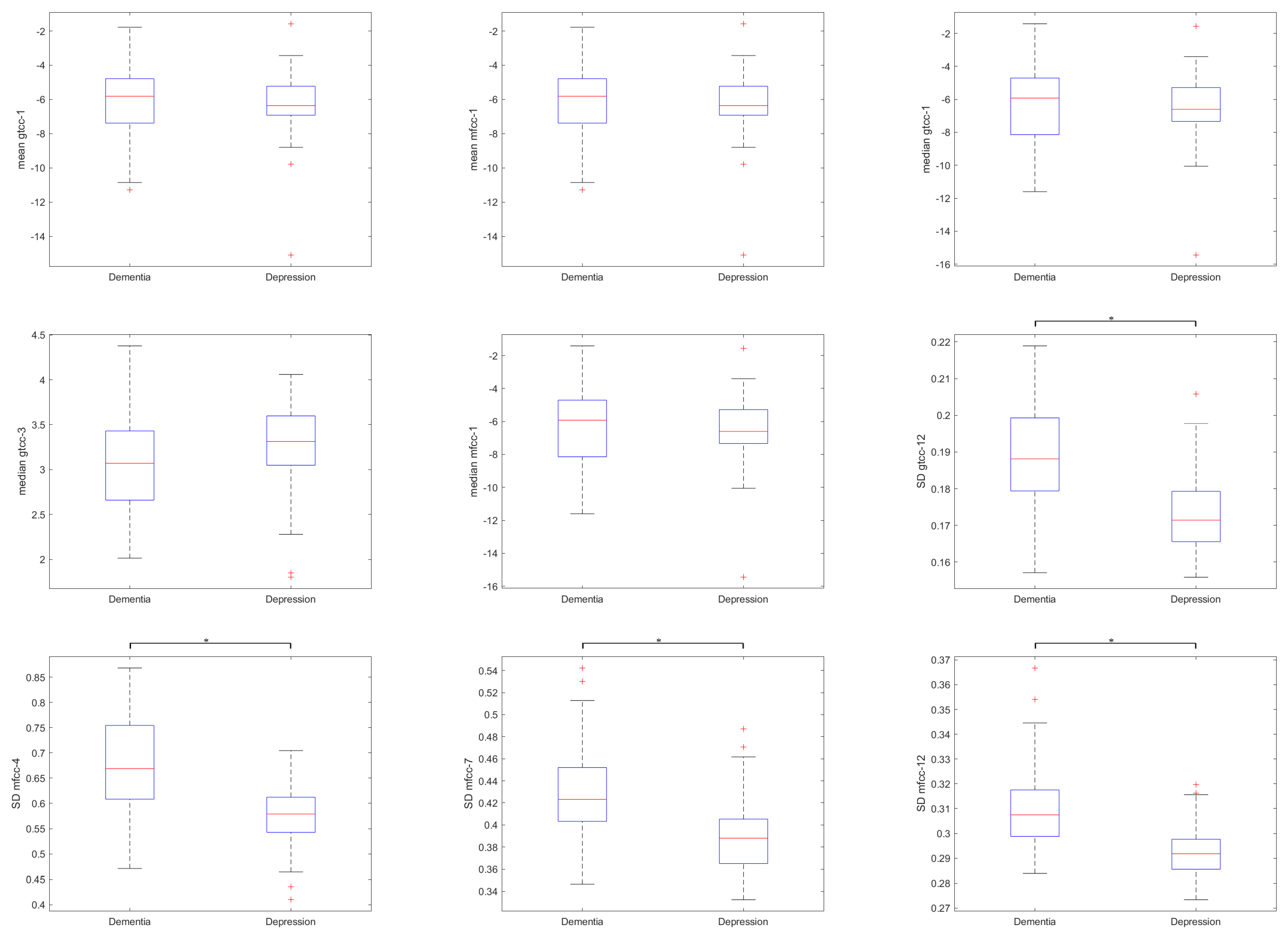
The corrected
t-test between these features in
Figure 5 showed statistical differences only in certain features. Interestingly, the standard deviation of a rather high-order MFCC coefficient showed significant difference. Normally, most of the information are represented in the lower order coefficients and their distributions were important for speech analysis. Feature contribution shown in
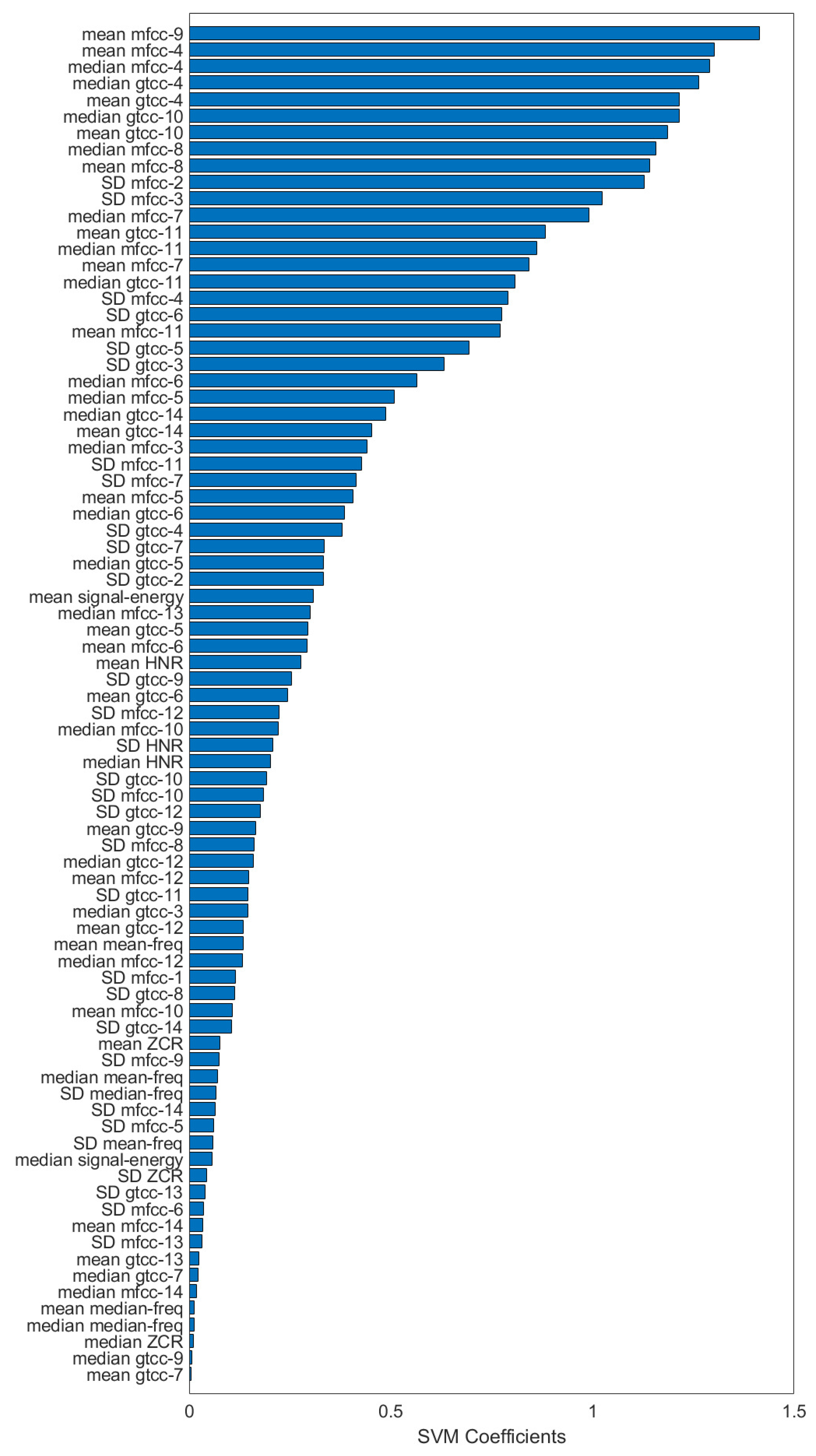
Figure 6 puts these features in the middle of the selected features, and some of the lower-order MFCC features were even removed. This might imply the shared features between dementia and depression did not contribute well for predicting them.
Statistical comparison of acoustic features between two groups found significant differences in both temporal and spectral acoustic features. No significant difference between the two groups can be found in pitch and energy, both in the family of temporal features.
Although the result from unsupervised clustering algorithm was not satisfactory, both the accuracy and inter-rater agreement show that the performance was better than chance, denoting the underlying patterns in the data. In the second part of machine learning, feature selection was performed using LASSO algorithm. Here, both pitch and signal energy features were rejected alongside with other spectral features. Considering that both pitch and signal energy also showed no statistical significance in the
t-test, it can be inferred that these features do not contribute for classification of depression and dementia. In contrast, GTCCs 4–14 and MFCCs 4–14 had statistically significant difference and were also selected by LASSO algorithm. GTCCs and MFCCs are similar features, related to tones of human speech. Although GFCCs was not developed for speech analysis, both are commonly used for speech recognition systems [
45,
46]. This finding is consistent with the fact that a person’s speech characteristics might be related with their mental health. SVM feature contributions also confirmed that the top contributing features were MFCCs and GTCCs. As the coefficients of the MTCCs and GTCCs are related to the filterbanks utilized when computing them, these coefficients have the benefits of being interpretable [
47].
Surprisingly, the best result of the SVM was obtained in SVM with linear kernel, although the the scores were only slightly superior to the nonlinear SVMs. Additionally, the effectiveness of LASSO algorithm for feature selection was evaluated and interesting result was found. For the second phase, all the SVM models benefited from having LASSO feature selection, but for the third phase, nonlinear SVMs seemed to be the most benefited with the feature selection. This might be related by the LASSO algorithm. As LASSO regression is a linear regression with penalty and the feature selection step was basically to discard features that give zero contribution to LASSO regression, linear SVM might be similar to it and was redundant in this case.
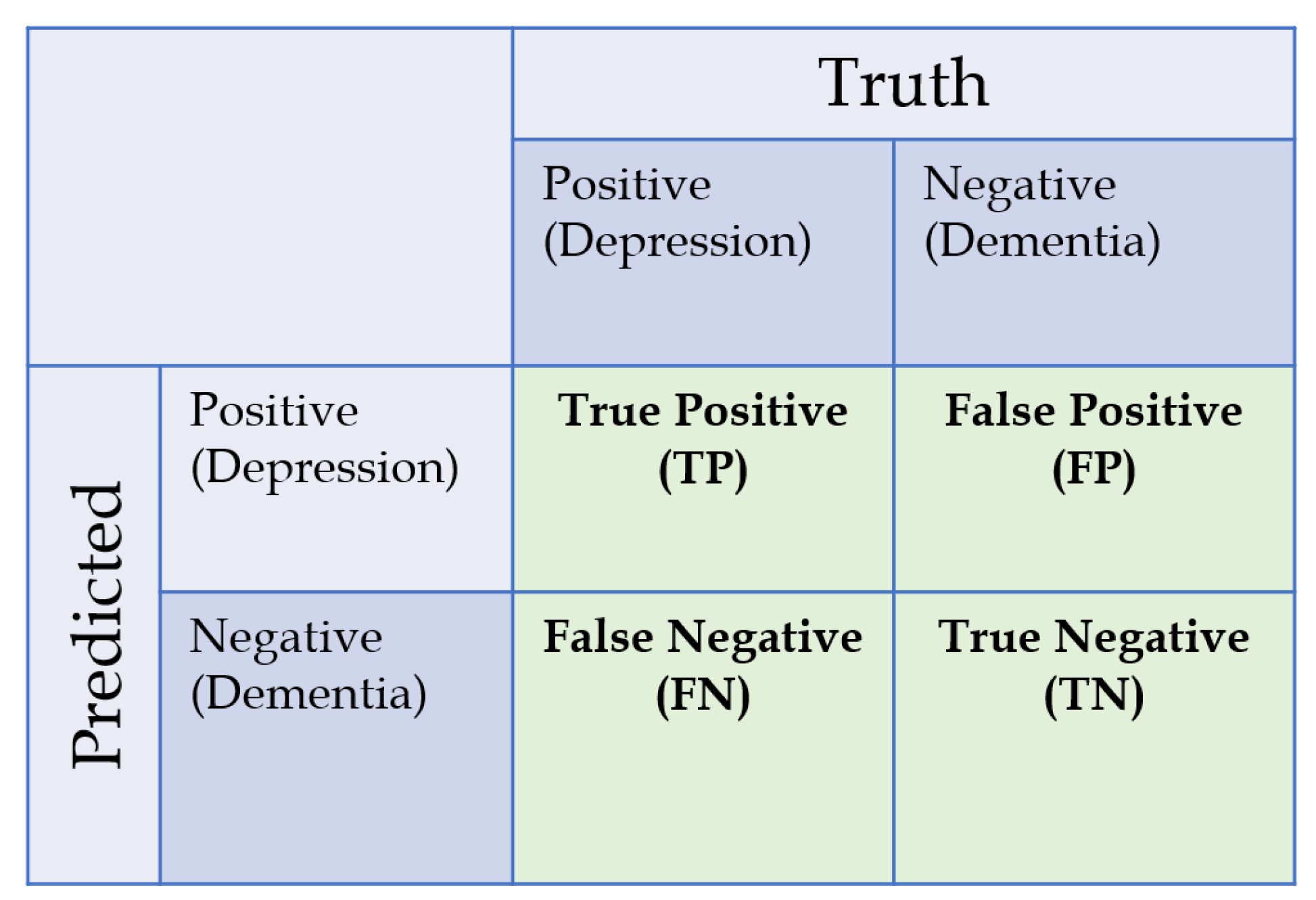
Nevertheless, high accuracy and interrater agreement were obtained from the models in both machine learning phases. For comparison, studies [
24,
25,
28,
29], and [
23] have 87.2%, 81%, 81.23%, 89.71% and 73% as accuracy for predicting depression, respectively. [
31] reports 73.6% accuracy for predicting dementia and [
30] reports 99.9% TNR and 78.8% TPR. However, most of these studies compared healthy subjects against symptomatic patients, while our study compared patients afflicted with different mental problem. Additionally, most conventional studies measure depression by questionnaire and not with clinical examination, so this cannot be said to be a fair comparison. Low NPV scores and inter-rater during the third phase maybe due to the fact that evaluation in third phase was utilized with heavily imbalanced dataset and with higher number of samples compared to the training phase. These results suggest the possibility of using audio features for automatic pseudodementia screening.
6. Future Work
Although this study has yielded considerably good results, there are still some rooms for improvements. For example, to eliminate the psychiatrist’s voice inside the recordings. Although the microphone was situated against the patient, subtle amount of the psychiatrist’s voice also included in the recordings. As such, a specific voice separation algorithm needs to be developed and applied to remove psychiatrist’s voice. This will certainly add silent parts in the recordings and the feature extraction methodology needs to be modified; instead of processing audio with 10 ms window, activity-based window might be considered. Additionally, a dynamic cardioid microphone or multichannel array microphone might be beneficial for picking sounds only from the patient’s side. In this case, room settings for suppressing reverberation and microphone placement becomes very important.
In conjunction with psychiatrist voice removal, activity-based features might also reveal relevance in aspects we did not consider in this study. Here, we hypothesized that longer silence between answers corresponds with lower patient cognition. We assumed that these silence segments will affect the mean value of the features while minimally affecting the median value and is beneficial for differentiating dementia against depression. However, activity-based or content-based analysis might reveal the difference in features we considered irrelevant in this study, such as signal energy.
Also, this study does not consider patients with overlapping symptoms of depression and dementia. Thus, the next step of this study is to develop a multi-class classifier capable of predicting patients with overlapping symptoms. A regression model trained with clinical assessment tools for both depression and dementia is also a possibility.
In consideration of improving the accuracy, more advanced machine learning techniques such as neural network might be suitable. Although the number of available dataset is relatively small for neural networks, sub-sampling and bootstrapping techniques might help to increase the numbers of dataset. Attention must be paid during the validation such that no data leak may occur. Additionally, feature extraction methods such as the combination of numerous hybrid acoustic features, as listed in [
48] might also be beneficial. Nevertheless, the curse of dimensionality should be avoided when handling such numerous predictors.
Additionally, while this study did not consider real-time analysis, shorter audio input length should be considered. In this study we used 10 min recording of the “free talk” session and disregarded the processing time. However, in real case, it is more beneficial if the processing was complete before the patient and psychiatrist started the examination with clinical assessment tools.
Finally, in regards the dataset used for training and testing. All experiments were conducted in a Japanese hospital, with Japanese therapist, and with Japanese patient. Although the audio features relating to mental health are supposed to be independent with the language, there is a need to replicate this research outside of Japan and to evaluate the performance of our model against the publicly available databases. Utilizing other databases also have the benefit of the possibility for fair effectiveness evaluation with our model.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}