4.1. Feature Importance
Feature importance obtained from Random Forest (RF-I) is commonly used to reduce the dimensionality of the model input. It is also interpreted to understand connections between the input and the output data, however, there are certain caveats such as that there is a bias against variables with only few categories [
30] as well as a bias when variables are highly correlated [
31]. This is why Sequential Forward Selection (SFS) was used as an iterative approach to reduce the feature set to its final size for model training and classification. Here, because only the feature that increases the applied measure (here: Matthews Correlation Coefficient, MCC) the most, non-correlated variables are favored. MCC was chosen because it takes into account all parts of the contingency table and thus is suited and recommended for imbalanced classification problems [
20]. The advantage of this feature selection method is that it retains interpretability of the models for the farmer, which is not possible when using other methods such as Principal Component Analysis and Deep Learning, where the feature importance is harder to interpret. In practical applications, models that show the correlations between an alarm and the input variables could offer additional help for the farmer. Random Forest feature selection is suitable for reducing the number of input variables to the most important ones while retaining the interpretability of the final models.
For mastitis treatments classification, the SCC of the last monthly milk recording highlighted as the most important predictor with an RF-I of 0.039 and r = 0.176, despite the fact that time gaps between the last measurement and treatments could be as large as a month. An elevated SCC is a direct indicator for both subclinical and clinical mastitis, which also explains the comparably high positive correlation with the treatments. Former studies also showed that including SCC as a feature improved classification: On-line measured SCC improved the positive predictive value for clinical mastitis from 0.11 to 0.32 compared to electrical conductivity alone [
32]. The incorporation of cow information that included previous SCC from milk recording also improved AUC of mastitis alerts from 0.62 (only information from AMS) to 0.78 [
3]. The knowledge of the last SCC could have influenced the decision to conduct a mastitis treatment, but there was no systematic accumulations of treatments in the week after milk recording results were received. The on-farm protocol is that for a cow to be treated there have to be signs of abnormal milk, detected by visual observation or with the California mastitis test. Compared to the importance of the other features (for mastitis as well as lameness treatments) the RF-I of monthly SCC is by far the highest. Because it can be assumed that SCC is a predictor with a direct relationship to udder health, it is questionable whether the features with RF-I < 0.014 should be viewed as having only an indirect relationship to the target variable. A raise in milk conductivity is also an indicator commonly used to detect mastitis, although the correlation to SCC is low (r = 0.48) [
32] and the absolute value is dependent on the animal [
33]. This explains the occurrence of two conductivity variables that capture the change over time in the 20 most important features for mastitis treatment classification. The somatic cell count from the monthly milk recordings is by far the most important predictor for the classification of udder treatments, as it is directly related to mastitis.
Other important features for mastitis treatments classification were derived from feeding data (concentrate and roughage intake, and feeding visits). Concentrate intake slope and deviation from allowance seemed to be important with RF-I of 0.014 and 0.010, respectively, but are dependent on the cow’s milk yield, since maximum daily allowance is automatically adjusted by milk kg and days in milk. The features for roughage intake included the current and previous rolling means and were positively correlated with treatments (RF-I = 0.008–0.011, r = 0.052–0.068). This might be the result of cows with a high milk yield (and thus a higher feed intake) being at an up to 1.44 times higher risk for mastitis compared to cows with low milk yield [
34]. Feeding data are not highly correlated with mastitis treatments. Therefore they are less suitable as predictors for classifying udder treatments.
Features derived from pedometer activity and behavior are most commonly used as predictors for lameness, e.g., differences in average activity between days [
7,
10], and accelerometer data like number and duration of lying and standing events [
35]. The mean number of step impulses of lame cows is supposed to be lower than for healthy cows [
6]. This is expected and also shown in then own study: The activity features from the data all had a negative correlation with the lameness treatments, although this effect was small (r = −0.072). Pedometer activity has a significant, albeit small, correlation with lameness treatments.
In data from 118 cows (44 with a lameness-related treatment within a period of 10 months), activity variables (e.g., sum, mean and standard deviation of 12 daily 2 h-activity values, deviation from previous day, difference between previous weeks) showed a correlation of r = 0.23 ± 0.06 on average [
8]. Here, neck collars were used that delivered activity indices based on number, intensity and direction of impulses. The resulting sensor data might have a more direct correlation to lameness than impulses measured by a leg pedometer. But [
8] built their database by strictly excluding cows with treatments other than lameness, which also contributed to a higher correlation with lameness treatments because there was less noise in the data from other treatments. In the own study, the aggregated impulse data from leg pedometers was used, because this sensor is available on most practical farms nowadays. As expected, the results show that they cannot be considered a sensor with a direct correlation to lameness treatment, unlike the monthly SCC for mastitis. This can be explained with a high variance between individual lameness events and their impact on sensor variables [
9]. Additionally, there are more different underlying conditions for lameness (e.g., sole ulcers, sole hemorrhages, or digital dermatitis), which have a different impact on a cow’s gait [
36]. Other sensors like automatic gait score assessment with cameras, or leg weight distribution can potentially improve classification, as seen in [
37] where lameness (based on scores) was detected from leg weight distributions on a weighing platform, with an AUC of up to 0.88. This value cannot be compared to the own study though, because the underlying data set consisted only of 7 d and a single classification, based on clinical examinations of all cows. These advanced sensor systems are not widely available in practice. This emphasizes the need for sensors that are more directly related to lameness treatments than just the number of activity impulses.
Data of roughage and water intake and visits is obtained from weighing troughs that are only used in experimental dairy farms, but not usable in practice. Information about a cow’s feeding and drinking visits can be approximated with the use of tracking [
38] and accelerometer systems [
39], but the amount of roughage and water intake of individual cows remains unknown. When excluding all features derived from the weighing trough data in the own study, a mean AUC of only 0.55 was obtained for lameness classification, confirming the importance of those features. Two features from water troughs, drinking time (RF-I = 0.009, r = −0.065) and rolling mean of the number of drinking visits (RF-I = 0.006, r = −0.059) were found among the 20 most important features. This indicates a potential for water trough visits as a feature for lameness classification. From a technical point of view, it is conceivable that in the future these characteristics could be recorded with the help of sensors. Data from feeding and water troughs improve the classification of lameness treatments, but are not available as such in practice.
4.3. Interpretation of the Final Classification Models
Due to differences in the study design and the composition of the data, a direct comparison of the own results of the classification models with those of other studies dealing with the classification of dairy cows in need of treatment is only possible to a certain extent, even if the statistical methods are the same [
42].
Studies that have also developed models to classify lameness or mastitis treatments as target variables differ in the independent variables (features) used. Studies that have classified cows for lameness treatment have either focused on feeding related variables such as feed intake, trough time or number of visits [
43], or only on ALT pedometer data such as number of impulses and resting time [
6] with a resulting accuracy of 0.76, or used multiple data sources (live weight, pedometer activity, milk yield) and additional individual animal information [
10] to obtain an AUC of 0.74 compared to models with only a single parameter that yielded AUCs of 0.60–0.66. The own models used sensor data that are widely available in practice (pedometer activity, milking parlor data, concentrate intake, live weight, climate data, and monthly milk recordings) as well as data from feeding and drinking troughs (visits and intake). The classification for mastitis treatments in previous studies was based on activity and rumination time [
5] with a sensitivity of 0.55, or change in milk yield and conductivity [
44] to obtain a sensitivity of 0.48 when specificity was set to 0.98. [
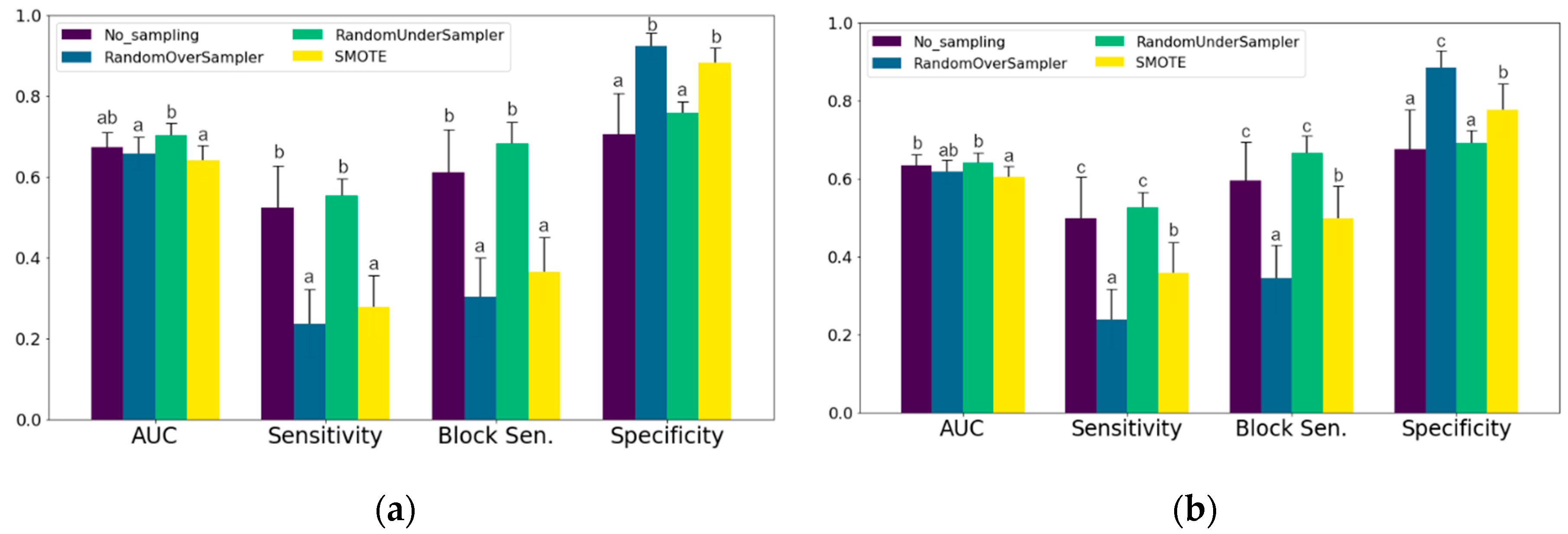
4] included both data from real-time milk analyzers (SCC, fat, protein) and non-sensory information (parity, season, and weeks in milk) in their model, which resulted in an AUC of 0.89. In the own study mainly sensor data and information were used that are already available on many farms, and we recommend this approach when developing classification models for practical application. The feed and water intake is a special case, because the data acquisition is only possible on experimental farms with weighing troughs. Therefore the evaluations were carried out also without these features. The results show that for the classification of mastitis treatments, the exclusion all features from feed and water troughs did not affect the AUC, while for the lameness treatment classification the mean AUC dropped from 0.62 to 0.55. This emphasizes the importance of those features and shows the need to develop and improve sensors that measure feeding behavior of individual cows.
The data sets also differ between the studies in terms of the different pre-selection options. This selection takes place before the separation into training and test data and therefore affects the relationship between treated and non-treated cows, which leads to a higher probability of correctly positive classifications. In the study of [
6] a total of 549 days out of 11 cows were selected, of which about half were classified as “lame” based on lameness scores. Other studies excluded unclear cases from their data: Exclusion of cows with a scoring system from 1 (non-lame) to 4 (severe lameness) [
16] or 1 to 5 [
35] and exclusion of all animals with a score of 2 in both cases, or data for cows with more than 50% missing sensor data for activity were excluded [
35]. Another possibility is to limit the test data to a certain number of days before treatment, e.g., 3 weeks, resulting in a higher proportion of days with treatment [
8]. In the studies mentioned above, it is questionable which values for sensitivity and specificity would have resulted from less selected data. In our own study, only the days after treatment were not considered in the test data, missing values were interpolated. Values for sensitivity and specificity of up to 0.79 for mastitis treatments and 0.71 for lameness treatments could be achieved on the non-sampled test data. Excluding data and thus artificially increasing the number of positive cases in the test data leads to higher values for AUC, sensitivity and specificity and is therefore not recommended. Test data sets should, as far as possible, be similar to the data that will need to be classified later in practical use on farms. Many studies pre-select both training and test data, which leads to higher AUCs, but these are not achieved in practice. In future studies, classification models from sensor data should be tested on practical data.
In addition to the above-mentioned methods of processing the test data set, it is possible to increase the number of days with treatment by also defining a certain number of days before a treatment is carried out as a “day with treatment”, i.e., as a positive target variable. In our own study, 3 days were used, as in [
7] for mastitis and lameness treatments. This allows the calculation of block sensitivity, where at least one of the three days prior to treatment must have been positively classified. In [
7] block sensitivities of 0.77 for mastitis and 0.74 for lameness treatments were achieved, but no sensitivities per day were given for comparison. The highest block sensitivities in our own experiment were 0.80 for mastitis treatments and 0.81 for lameness treatments. In a practical setting on a farm, the exact day before a necessary treatment is not important as long as the need for treatment is visible. A disadvantage is that this can lead to animals in need of treatment being detected too early without clinical signs and then incorrectly registered as healthy, as has been discussed in other literature [
9,
42]. The calculation of block sensitivity reflects the use of a model in practice better than pure sensitivity for the exact day before treatment and is therefore recommended for the evaluation of classification models for mastitis and lameness treatments.
Finally, the recording, or definition, of the target variable also influences the interpretation of the results. In our own study, mastitis and lameness treatments were carried out by veterinarians and stable personnel, respectively. Also in other studies on classification models of dairy cow data, treatments of mastitis [
3,
4,
7,
43,
45] and of lameness [
7,
8,
43] were used as target variables. Although these records are made by qualified professionals and are therefore considered reliable, it was discussed to what extent this type of data collection incorrectly records cows without clinical signs as not requiring treatment [
15,
46]. Other studies have used lameness scores or clinical assessment to define lameness [
10,
35,
36] and cell count measurements or cytobacteriological tests for mastitis [
5,
14]. This type of recording potentially reflects the health status of the individual animals better, but is much more personnel and time intensive and is therefore not suitable for evaluations over periods of several years. In addition, the use and storage of treatment data collected under practice conditions allows the underlying classification models to continuously adapt and learn from newly entered data to improve the classification of future treatment events.
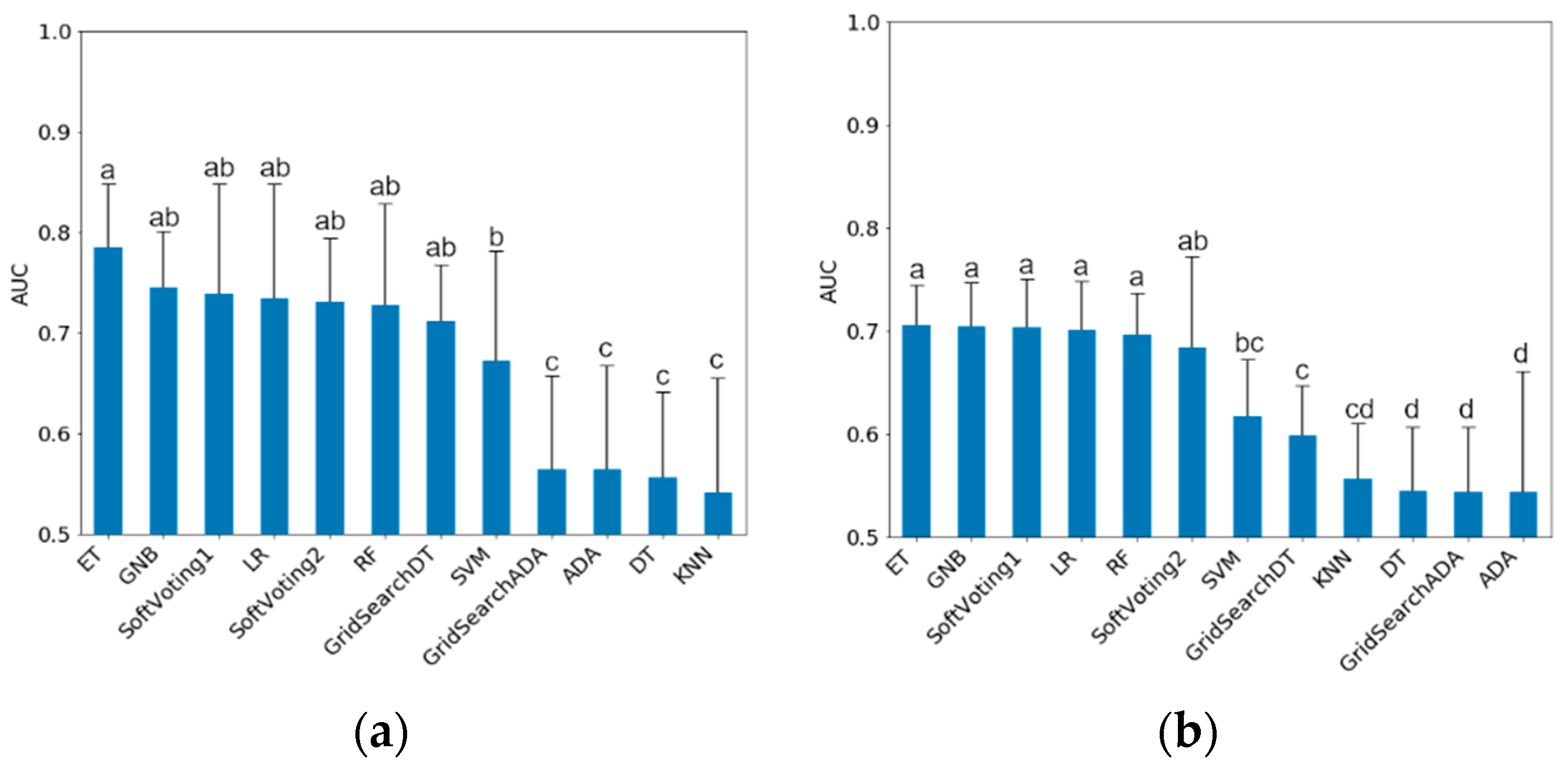
So far there are few studies that systematically compare the application of different machine learning models for the classification of farm animal data. A study by [
47] compared the methods RF, SVM, KNN and ADA for the classification of three different types of grazing behavior in sheep. There, RF gave the best results (highest accuracy of 0.92), with KNN and ADA worse by 0.05 on average. The authors particularly emphasized RF’s ability to correctly assess non-linearly related data and its robustness against statistical noise. The authors of [
48] compared different methods (NB, DT, RF, Bayesian network and bagging) to predict insemination success in Holstein dairy cows based on phenotypic and genotypic traits. Results for AUC ranged from 0.61 to 0.75, with RF showing significantly better results than all other methods tested. Two studies from other disciplines are also mentioned here, credit assessment [
41] and Alzheimer diagnostics [
12], as they also systematically compared classification models on a binary target variable. In the study by [
41] data sets with different proportions of good and bad credit scores were created and classified by means of down-sampling. Decision tree-based models (RF and gradient boosting) provided the highest AUC (up to 0.90), while other models such as LR and SVM showed only random classifications (AUC = 0.5) for the data sets with the lowest proportion of bad scores. The Alzheimer study, which used features of electrical brain activity, compared RF, SVM, LR and neural networks and found only minimal differences in AUC (0.83–0.87). The authors emphasize the advantages of models that output feature importance (RF, LR) compared to (non-linear) SVM and neural networks, whose decision making is much more difficult to interpret [
12] and are therefore considered “black boxes”. In our own study, models based on decision trees (ET, RF) or containing them (Soft Voting 1), but also LR and GNB resulted in the highest average AUC (0.71–0.79 for mastitis treatments and 0.67–0.71 for lameness treatments, respectively).
Random forest models are more robust compared to single decision trees, because the tendency to overfitting and the overall variance within the model is lower [
18]. They also perform well when dealing with class imbalances [
41]. Logistic Regression has also been used for classification of treatments in other studies [
8,
10,
49] and has the key advantage of interpretability, where not only the absolute importance of each feature, but also the trend can be derived from its coefficients [
18,
23]. Based on the results of this study the use of ET, LR, RF and GNB can be recommended for further, similar studies.
An AUC of 0.75 or 0.70, as achieved by the best own models for detecting mastitis and lameness treatments with a practical data set, is within the range of studies that have worked with similar data and sensor combinations. A value of 1 would mean a perfect classification. A value above 0.70 is considered a “strong model”, while a value below 0.60 is considered a “weak model” [
28]. The more directly the features are related to the target/classification variable, the greater the AUC, as can be seen from the example of somatic cell count in relation to mastitis treatments in the own data. Sensors and features with a direct relationship to the target variable are required to achieve a higher AUC. For the detection of dairy cows with classification models no minimum requirements for AUC values are known. Various authors demand minimum sensitivity values of 0.70 or 0.80 with a specificity of 0.99 [
15], which would correspond to an AUC of more than 0.90, and cannot be achieved with practical data sets (i.e., not sampled or similar). Only a few studies critically question the practical applicability of models with lower than the required AUC (or sensitivity and specificity combinations), e.g., in a study on calving prediction, where the authors point out the model’s limited benefit resulting from a low frequency of occurrence of the target variable “calving” in the data, and the resulting low positive predictive value despite AUC values of up to 0.81 [
50]. The authors’ own AUC values also make it clear that the application of classification models from practical sensor systems on realistic data sets must be viewed critically and does not reliably lead to the identification of animals in need of treatment or similar classification events, as generally expected. Thus, limits of the use of sensors (the corresponding machine learning methods and all other associated techniques) for finding individual animals in need become apparent.







{kind=link}
{kind=link}