1. Introduction
Over the estimated new cases of cancer in the USA for 2020, breast cancer is observed as the first leading cancer type in the female. In developing countries [
1], there is a lack of early detection schemes, tolerable diagnosis, and cure facilities for breast cancer cases, so the survival rate is low compared with developed countries. Breast cancer needs to be detected at an early stage so that proper treatment can be given to reduce the rate of mortality. Small-sized calcium deposits are known as micro-calcification, and they are an indication of malignancy. Mammography is one of the best reliable diagnostics over other methods like Ultrasound, Positron emission tomography (PET), and Magnetic Resonance Imaging (MRI) [
2]. Mammograms are unusual to determine the presence of benign or malignant disease with conviction. The radiologists recommend a patient to go for the next diagnosis in the cases of uncertainty. Opaque regions are typically noisy in digital mammogram images, and have poor contrast. For this reason, it is a challenging responsibility for the radiologist to detect and diagnose a cancerous region. The noise must also be eliminated before a mammogram is processed [
3]. A significant amount of noise reduction algorithms have been developed in the last two decades. The Mammography Image Analysis Society (MIAS) Mini Mammographic Database is normally a database of mammograms used in such research work [
4,
5].
The literature shows that the detection of viruses in breast cancer is highly inconsistent [
6].
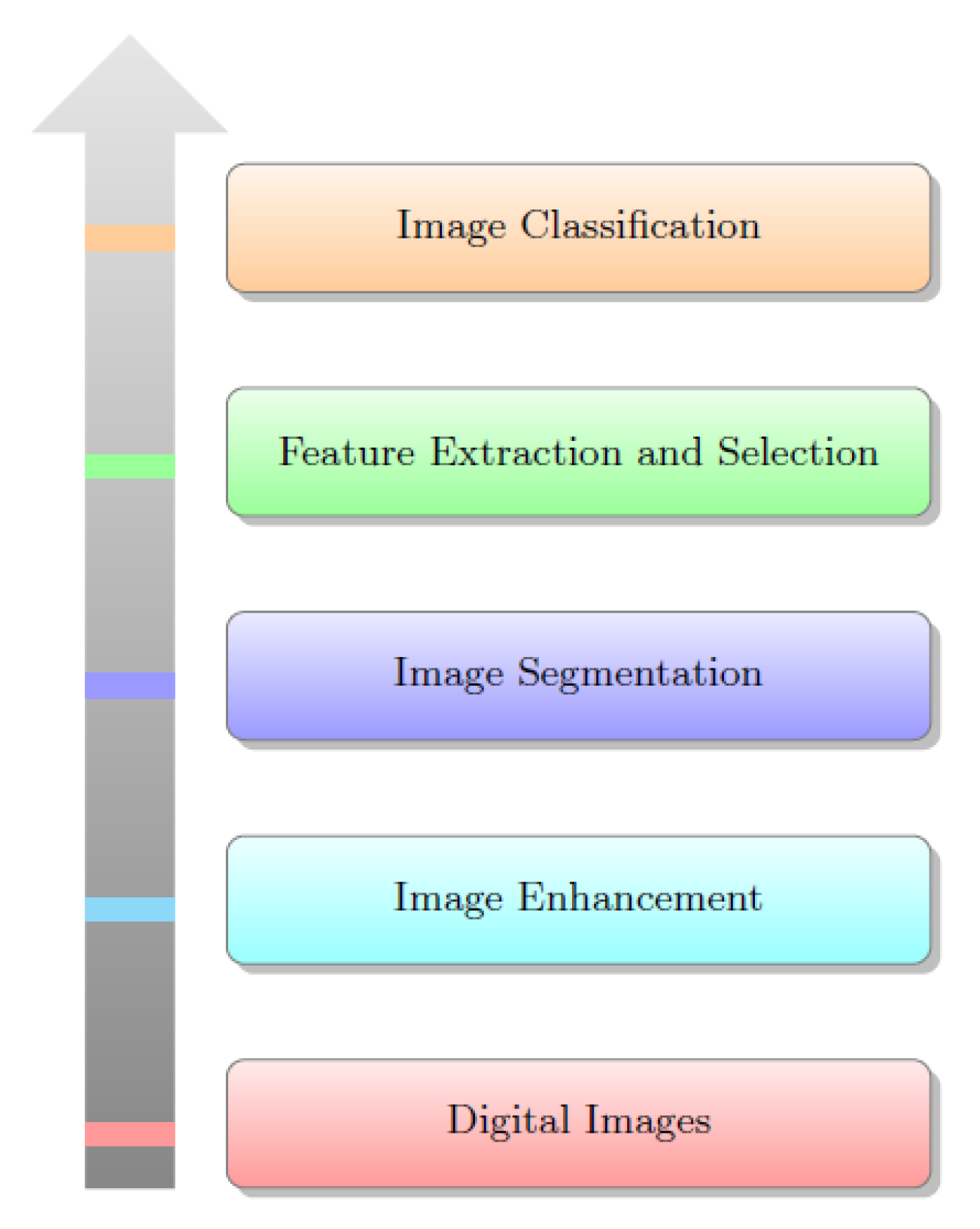
Figure 1 presents basic breast cancer detection procedures. The breast cancer detection method can be divided into five main approaches: (a) traditional image acquisition techniques; (b) Image enhancement model, especially for noise removal; (c) Find cancer affected area by detecting the suspicious region-of-interest (ROI) on medical images by using suitable segmentation method; (d) feature extraction; and (e) classification of benign or malignant from ROI. Proper segmentation is required for better feature extraction and classification. References [
7,
8,
9] addresses many algorithms for the early detection of breast cancer detection. The evaluation of segmentation based on detection rate and accuracy gave the result of breast cancer detection cases [
10,
11,
12]. The segmentation leads to feature extraction—the calculation of features based on density, texture, morphology, shape, and size of regions [
13,
14,
15]. In the case of large and complex feature space with redundant and excessive features, there is a possibility to take excess time with a tendency to reduce accuracy in classification. It requires redundancy removal for performance improvement.
There are some cases where cancer is erroneously diagnosed among several patients. Osmanovic et al. [
11] suggested a diagnostic method to resolve these cases by distinguishing between patients with and without breast cancer by defining the characteristics of cell nuclei present in an exceptional needle aspiration picture. Khwairakpam et al. [
16] used fuzzy rules to identify the noise of images and filtered them using fuzzy weighted mean. They used genetic algorithm (GA) to optimize the parameters for fuzzy membership function. To evaluate the proposed filter edge-preserving factor and peak signal-to-noise ratio were used. Dutta et al. [
17] proposed an approach to predict breast cancer by data mining methodologies, inference systems, and fuzzy logic. A novel prediction was proposed comprising of a fuzzy inference system with images collected from local clinics. This method performed better than other approaches like Logitboost [
18], Locally Weighted Regression(LWL) [
19], REP Tree [
20], and so forth. Using deep learning algorithms, Khan et al. [
21] used transfer learning methods for the classification and detection of breast cancer images. The feature extraction was executed with convolutional neural network (CNN) approaches like Residual Networks (ResNet), Visual Geometry Group Network (VGGNet), and GoogLeNet by feeding into a fully connected layer where malignant and benign cells are classified. Some researchers applied their work on classification and control problems by developing a fuzzy brain emotional learning neural network. Robio et al. [
22] worked on self-organizing fuzzy modified least-square network. In References [
23,
24], the authors used discrete wavelet transform to analyze sub-bands within the Electroencephalography (EEG) parameter for creating model for epilepsy diagnosis. In References [
25,
26], the authors worked on parametric uncertainties and noisy outputs. Later they tested it for breast tumor classification and the chaotic system synchronization [
27,
28].
Figure 2 shows a classification task related to the medical images as output. Classifiers methods like rough set data analysis, support vector machine (SVM), decision tree, neural network and linear discriminant analysis (LDA) were extensively used for medical image detection approaches [
3,
7,
29,
30].
The major contributions of the proposed method are the following:
In this paper, we considered the MIAS dataset for breast cancer detection.
For the detection of cancer in an image, we applied the existing segmentation techniques such as the Otsu algorithm, FCM (fuzzy c-mean) clustering, IFCM (ntuitionist fuzzy c-mean) clustering, and PFCM (possibilistic7fuzzy c-mean). After that, we propose a segmentation model, that is, IPFCM clustering. In addition to this, statistical Feature extraction techniques are also taken into account.
The simulation results are investigated with four classification models such as DT (decision tree), RSDA (rough set data analysis), FCM and Fuzzy SVM. Besides this, we considered IPFCM (intuitionistic possibilistic7fuzzy c-mean) clustering model and Fuzzy SVM classification model resulting in a more promising accuracy than state-of-the-art studies.
This paper presents the evaluation criteria of specificity, sensitivity, MCC (Matthew’s correlation coefficien), PPV ( positive predictive value), accuracy, and NPV (negative predictive value) for classification measurements.
Finally, simulation results of the proposed approach is fast and accurate recognition over existing results from the MIAS dataset.
The rest of paper is organized as follows.
Section 2 discusses pre-processing (
Section 2.1), segmentation (
Section 2.2), clustering (
Section 2.3) and feature extraction (
Section 2.4).
Section 3 highlights the overview of classifications methods and evaluation criterion.
Section 4 describes the proposed Intutionistic possibilistic fuzzy clustering algorithm.
Section 5 explains the setup used in the design of the experiment and the obtained results with respect to state-of-the-art methods. Finally, the paper is concluded in
Section 6.
3. Overview of Classifications Methods
Our proposed work is on noise removal in the preprocessing stage; Intuitionistic possibilistic Fuzzy c-mean clustering performed in the segmentation stage; significant features extraction by using statistical feature extraction methods; and final stage as Classification stage. Later classification results of SVM, decision tree, RSDA, and Fuzzy SVM are tested, optimized, and compared. These classification methods are as discussed below:
3.1. Decision Tree (DT)
A decision tree takes several correlations in factual lifespan, and it can be used in a range of machine learning applications [
42,
56], covering both classification and regression. The decision tree is aimed at visually and unambiguously representing decisions and decision making for decision analysis. A decision tree classification has three types of nodes—(1) root node, (2) splitting node, and (3) terminal node. Recently, the datasets are classified through the decision summary, well-defined via the tree in order. Then the respective class label is dispensed on the analysis with the terminal nodes, wherein the analysis cascades. A simple decision tree is shown in
Table 3.
3.2. Rough Set Data Analysis (RSDA)
Rough set data analysis generates a set of rules from a system of decisions. A significant number of rules must be minimized. To get a minimum number of rules, it is essential to abstract the conditional attributes which are superfluous. Significant steps associated with rough set data analysis are core and reduct computation, finding the significance of attributes, constructing a decision table, producing rules, followed by classifying data [
30]. To remove the more essential features, the core and the reduct are determined. Decision and core form the decision-making framework. A set of minimum rules can be created based on the decision system, and those rules are the basic building blocks of the classification model [
27,
38].
3.3. Support Vector Machine (SVM)
Vapnik proposed support vector machine concepts in Vapnik-Chervonenkis’ learning theory and structural risk minimization (SRM) inductive principle [
8]. The SVM theory has attained abundant deliberation in earlier years.
Support Vector Machine provides a better performance in orthodox machine learning applications, pattern recognition for solving classification glitches. SVM is a valuable method for a nonlinear efficient approximation trick [
39]. The support vector machine is primarily plotted to a high-dimensional feature space with the input data and leads to creating a spreadable hyperplane that exploits the margin in that space between two groups. The maximization of a margin between two groups can be assumed as a quadratic system designed to solve Lagrangian multipliers [
40]. SVM uses the dot product functions to show the optimal hyperplane in the high-dimensional feature space known as kernels. For example, the optimal hyperplane elucidation is known as a combination of approximately input points, and they are called support vectors [
41,
57].
The inadequacy of the support vector machine is the sensitivity of the training procedure to the noises or outliers in the training datasets because of overfitting. Such uncertainty points are crucial to making decisions and creating an overfitting problem. The improved Fuzzy SVM is discussed in the subsequent sub-section.
3.4. Fuzzy SVM (FSVM)
Support vector machine classification has some drawbacks. Those drawbacks can be overcome by using fuzzy logic in SVM. FSVM [
9] is a classification technique based on SVM exemplary for the classification of outliers or noise. The most challenging part of FSVM is acquiring the fuzzy membership of the training data. Lin and Wang projected a design process [
9] for finding the fuzzy membership. The distance between the sample and its class center in the high-dimensional function space is used by a kernel extension development to measure a new fuzzy member.
Researchers suggested the
-margin nonlinear classification prototype on the base of FCM clustering in the creative input space and the fuzzy
rules.
rule statements are used to formulate the conditional statements that comprise fuzzy logic. Another method proposed is a joint weight-based Fuzzy-SVM system [
9], which reflects an identical training sample with various classes. The weight-based FSVM has difficulty in setting fuzzy membership values and diminishing computational complexity.
The basic theory is support vector machine [
49] which is followed by a fuzzy support vector machine algorithm. Let
S to be set of label
head training points for a binary classification delinquent is
thru
inclines to. Their contribution data was obtainable by
accordingly specified a binary class label as
and the fuzzy membership degree was
anywhere
belongs to
. The binary classification delinquent model for a fuzzy support vector machine algorithm is essentially a discrimination restriction based quadratic programming problem which is given in Equations (
10) and (
11):
This quadratic-optimization problem is solved by building Lagrangian description and transforming it into the corresponding dual problem (Equations (
12) and (
13)):
subject to
Consider as a Langrange multiplier through a value which is not equal to 0 when data point m is a support vector, and is a kernel function.
During the use of Gaussian kernel function there is Equation (
14)):
Now, the outcome of the solution by FSVM model for the class label of testing
y can be expected as in Equation (
15).
4. Proposed Intuitionistic Possibilistic Fuzzy Clustering
Medical images are complicated to understand. Therefore, it is required to remove undesirable portions of medical images. The noise removal process enhances the quality of the image.
| Algorithm 1:IPFCM Methodology. |
Initialization Calculate PFCM which as follows:
where, Hesitation degree is initially calculated with
Intuitionistic fuzzy membership value is attained by:
where signifies the intuitionistic fuzzy membership of the data in class. Substitute Equation ( 18) to Equation ( 16) for finding IPFCM.
The improved cluster center will be: and the cluster center was modernized and instantaneously the membership matrix was also rationalized. Accomplish the conclusion of iteration. Patronize the convergence standard. In case convergence was extended, break the iteration otherwise go back to Step 2.
|
Possibilistic clustering approaches attempt to decrease the membership degree of noisy data, whereas the Intuitionist Possibilistic fuzzy clustering (IPFCM) approach assigns membership and non-membership degrees with hesitation degree. In Algorithm 1, the Intuitionist Possibilistic fuzzy c-mean methodology is written to strengthen the breast cancer detection system. Medical images are subsequently enhanced using Intuitionist Possibilistic fuzzy c-mean algorithms to form a cluster of pixels [
47,
48]. In order to improve membership assignments, a possibilistic approach has been used to overcome the noise cases. We also proposed an integrated intuitionistic fuzzy c-mean system [
48,
49] to improve the possibilistic c-mean algorithm [
47]. A medical image segmentation system referred as an intuitionistic possibilistic fuzzy c-mean (IPFCM) clustering system. The design of the proposed system is in four stages as an initiative for pre-processing, main segmentation, that is, clustering, statistical extraction and final classification (
Figure 3). The driving idea behind our proposed work is based on segmentation part that combines the possibilistic fuzzy c-mean with intuitionistic fuzzy c-mean and reduces the number of iterations to help with minimizing execution time.
5. Results and Discussion
The segmentation algorithm and classification methods are performed using MATLAB R2018a. At the classification stage, a support vector machine, decision tree, rough set data analysis, and fuzzy support vector machines are also executed to compare the accuracy of results.
5.1. Data Collection
The MIAS dataset [
58] has a total of 320 digital mammogram images. These images are categorized into three types such as malignant, benign, and normal. There are 51 images in the malignant group, while 63 are benign. The remaining 206 images are normal. The pathological images are quite well known to be malignant. The original MIAS database was digitized at 50 micron-pixel edge, but reduced to 200-micron pixel edge and clipped in such a way that each image has (1024 × 1024) pixels.
5.2. Segmentation for Medical Imaging
The selected input image is shown in
Figure 4 left. Some noise removal algorithms are applied over input images are verified with few noise removal algorithms. We examined with median filtering, max-min filter, midpoint filter, adaptive filtering, adaptive-median filtering, alpha-trimmed-mean filter, quantum-noise filtering, impulse-noise filtering, and wavelet-thresholding methods for noise removal from mammogram input images.
Figure 4 right presents a smoothened image per custom by Gaussian filter of diverse sizes
and standard deviation value 2.
A window was preferred for calculating the average value of local gray-levels. The pixels are aimed at each point of the set. An average of the resemblance value to the reference images is kept on every 32 directions, and the points were devised the maximum spatial resemblance.
The interpolation made the segmentation of the MIAS image of the 32 contour points by using a polynomial interpolating method. The accuracy of the segmentation method is considered by superposing the contours perceived inevitably and manually to compute the transformation amid them.
5.3. Average Segmentation Accuracy
With consideration of the optimal parameters for comparison of Otsu, FCM, IFCM, PFCM, and proposed IPFCM method for segmentation on the simulated MIAS breast cancer images as shown graphically in
Figure 5. We also evaluated with different noise levels.
Table 4 demonstrates the average accuracy of breast cancer segmentation for MIAS images with noise levels of 5%, 7%, and 9%. It was noted that the proposed approach with the negation function of Possibilistic is computationally inefficient compared to the negation function of Intuitionistic. The performance of the proposed IPFCM method with the hybridization of the negative function of Intuitionistic and the negative function of Possibilistic is better than the conventional segmentation methods.
Table 5 and
Figure 6 presents a comparison of the computation time it will take for various techniques for MIAS images.
5.4. Classification for Medical Imaging
We used the MIAS dataset for experimental classification. The efficiency of the SVM approach, decision tree, RSDA approach, and Fuzzy SVM approach is described in
Table 6. The accuracy of the classification is more important for the diagnosis of breast cancer, then the consequences of an incorrect diagnosis that trigger unjustified surgery or even lead to death.
The average classification accuracy rates of the methods (Otsu, FCM, IFCM, PFCM and IPFCM) for Fuzzy-SVM are 79.69%, 92.19%, 93.13%, 95.00%, and 98.45%, respectively (
Table 6). It seems one-sided by using some features for Fuzzy-SVM to differentiate between benign and malignant breast tumors; it cannot accurately provide classification accuracy for each segmented image. For segmentation, the classification accuracy has changed accordingly and later going to the highest classification accuracy for IPFCM based FSVM classification. The best achieved classification accuracy rate is 98.45%. This proposed IPFCM segmentation with Fuzzy SVM method attains the uppermost classification accuracy rate (
Figure 7).
5.5. Performance Evaluation
The specificity, sensitivity, Matthew’s correlation coefficient (MCC), positive predictive value (PPV), accuracy, receiver operating characteristic (ROC), and negative predictive value (NPV) were evaluated for classification measurements (
Table 7).
The sensitivity and specificity are two statistical measures of the performance of a binary classification test. The confusion matrix supports research taking place in the root of actual and predicted results for positive actual and negative actual aftermaths. Consider the concern of positive actual outcome and fine two chances of predicted outcomes as “True Positive (
TP)” and “False Negative (
FN)”. Another consideration is of a negative actual outcome devising two predicted outcomes as “False Positive (
FP)” and “True Negative (
TN)”.
Additionally, evaluation criterion “ROC curve” resolves the measurement for predictive accuracy for the suggested model. The “True Positive Rate (TPR)” and “False Positive Rate (FPR)” are designated in such a criterion. “AUC (Area under ROC Curve)” is castoff to compare the classifiers in two-class concerns.
The higher the values for sensitivity and specificity for the better performance of the system. In many cases, a higher sensitivity value can always be at a lower specificity value. SVM performed the worst, and the RSDA-based process performed better than SVM, which is only consistent with the parameter optimization performance. The decision tree-based method over matches the above techniques, but is still inferior to the Fuzzy SVM. The proposed approach achieves sensitivity-0.99, specificity-0.25, accuracy-0.98, PPV-0.99, NPV-0.50 and MCC-0.34, and has performed much better for Fuzzy SVM (with IPFCM segmentation) than the other classifiers (
Table 8) and as shown graphically in
Figure 8.
6. Conclusions and Future Research
Viruses can act as direct transforming agents and as triggering co-factors. Our research is conceived to detect digital mammograms. This machine conducts multiple-phase screening of breast cancer images. Noise and outliers trigger the low accuracy of the cluster analysis. In Fuzzy clustering, one data point was allocated to all clusters. As in Fuzzy’s clustering, the abnormal points were used by moving to other locations, which affected the centroids. Hence conventional fuzzy clustering like Fuzzy C-Means (FCM) is not sufficient to separate noise and outliers from typical results. But noise and outliers are not eliminated by the clustering method; hence they are forced to belong in one cluster due to general probabilistic constraint the amount of the membership degree of data across all clusters to 1. By incorporating the Possibilistic method, it enables the identification of outliers by the algorithm. In this paper, Intuitionist Possibilistic Fuzzy c-mean (IPFCM) not only minimizes the effect of outliers during the clustering process but also cesses it. These are also detected and extracted for further outlier mining. The detailed experiments show that IPFCM achieves reliable outlier detection results while maintaining the consistency of the clustering. The performance average segmentation accuracy for MIAS images with different noise levels 5%, 7%, and 9% of IPFCM is 91.25%, 87.50%, and 85.30% accordingly. The average classification accuracy rates of the methods (Otsu, FCM, IFCM, PFCM and IPFCM) for Fuzzy-SVM are 79.69%, 92.69%, 93.13%, 95.00%, and 98.85%, respectively. We conducted a comparison to compare our results with the most relevant studies, and the results are summarized in
Table 9.
In future work, the segmentation and classification of this method with deep learning applications will be studied. In this way, breast cancer detection results can be obtained quickly and the application of this research is advanced.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}