This section describes the setup of the experimental environment, the construction of the dataset (including collection from the experimental environment), model training methods, results, and discussion.
4.2. Datasets
As the basis for training and testing our FD-DNN model, we construct a new Joint-Dataset. Firstly, we cleaned up and extracted some data from two open datasets—SisFall [
28] and MobiFall [
29], respectively. Furthermore, through our well-designed experimental environment described in the previous section, we collected 1600 extra samples for eight different activities.
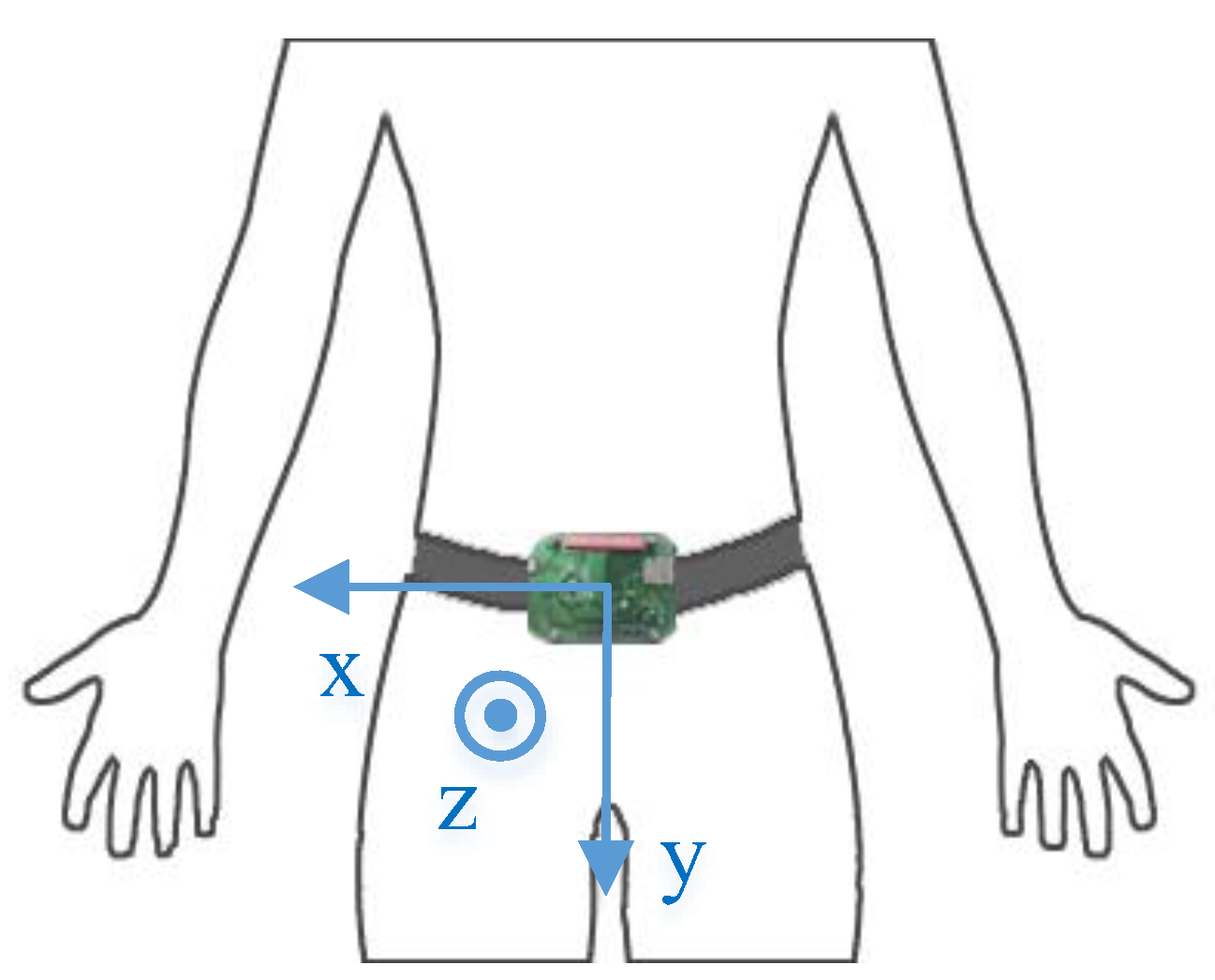
The SisFall dataset includes 19 types of ADLs and 15 types of falls. The experiment was performed by 38 adults, among whom 14 healthy and independent elderly subjects over 61 years old only performed 15 types of ADLs, and one elderly subject of 60 years old and 23 young subjects aged from 19 to 30 performed both ADLs and falls. The dataset was recorded with a self-developed device integrated with a three-axial accelerometer and a gyroscope. During the experiment, the device was fixed to the waist of a subject, which is demonstrated in
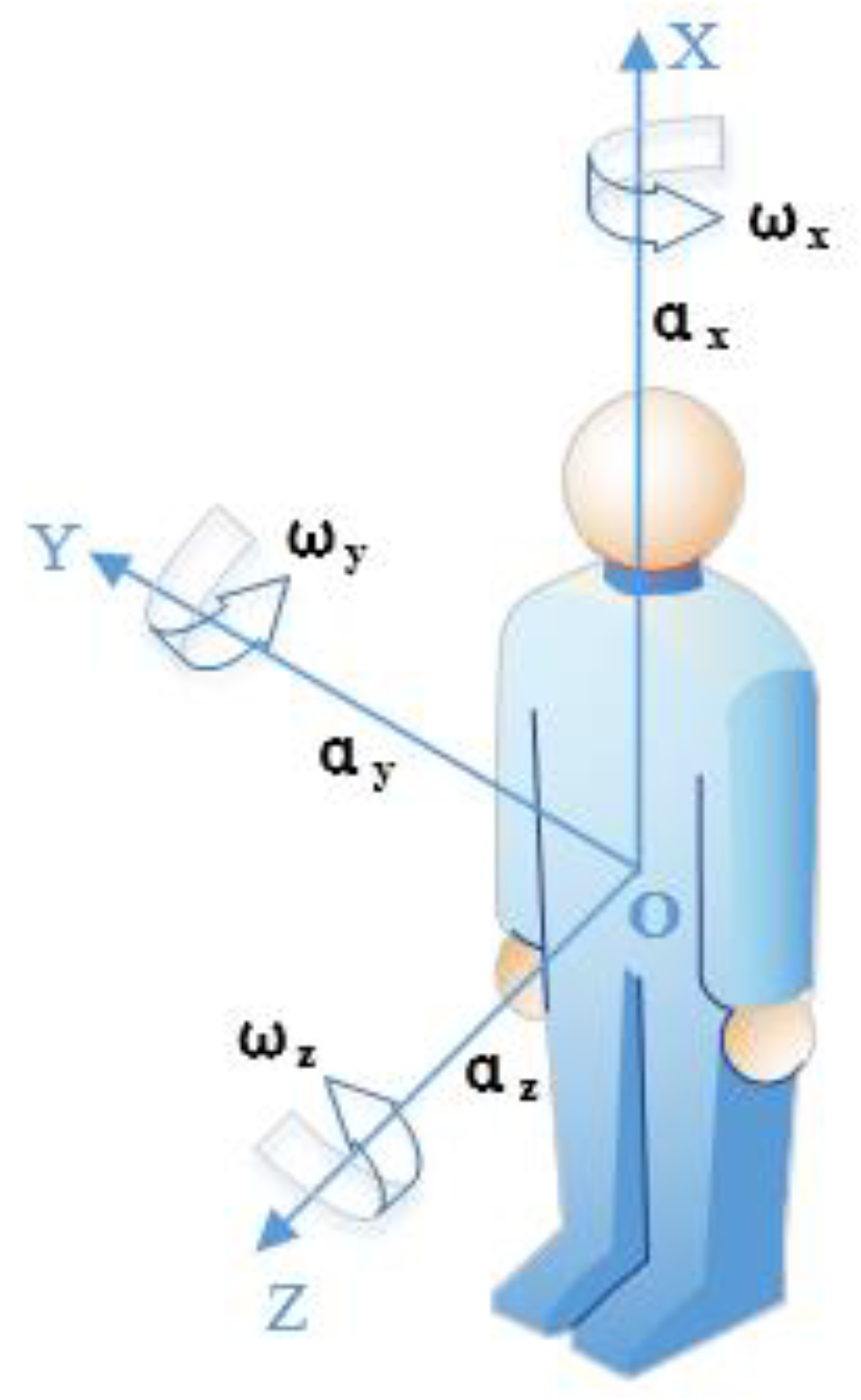
Figure 6. It can be seen that its coordinate is slightly different from the human motion model.
The MobiFall dataset directly collected the motion data of three-axial acceleration and angular velocity from a Samsung Galaxy smartphone, which was placed in the subject’s trouser pocket in a random orientation. The MobiFall dataset also included the orientation data about the subject’s smartphone. Twenty-four volunteers (22 to 42 years old) performed nine types of ADLs and four types of falls. Among them, nine subjects performed both falls and ADLs, and 15 other subjects only performed falls.
First, the coordinates of the SisFall dataset and the MobiFall dataset are transformed into the coordinate system shown in
Figure 1. In addition, the sampling frequency of both datasets is 200 Hz, while the sampling frequency proposed in this paper is 100 Hz. Hence, both SisFall and MobiFall datasets were downsampled to 100 Hz. Taking the different ranges and precision of the sensors used in the SisFall and MobiFall datasets into account, the two datasets were normalized by Formula (2) according to the range specification of each sensor.
Since the noises among the motion data always have significant effect on fall detection accuracy, it is necessary to filter the noises [
30]. Xiao et al. [
31] used the mean filter, the moving average filter, and the Prewitt horizontal edge-emphasizing filter to filter noise in the swimming recognition. The experiments proved that the moving average filter has the best effect on filtering noise. Therefore, the moving average filter depicted in Formula (3) is introduced to filter noise. In Formula (3),
G is the original data,
M is the size of the sliding window, and
is the filtered data.
After filtering the noise, we extracted 1000 samples for each activity from the SisFall dataset and the MobiFall dataset. Among them, the samples of walking, jumping, jogging, going upstairs, and going downstairs were extracted from the MobiFall dataset. The samples of standing up and sitting down were extracted from the SisFall dataset. The samples of falling consisted of 500 copies from MobiFall and 500 copies from SisFall. Overall, there were 8000 samples. Among them, each kind of ADLs and falls had 1000 samples, respectively.
Furthermore, the experimental environment in
Section 4.1 was used to collect some motion data as part of the Joint-Dataset. Twenty volunteers aged 24 to 50 participated in the data collection. 17 of them were male and three were female. There were eight activities, including walking, jogging, jumping, going upstairs, going downstairs, standing up, sitting down and falling. Each volunteer repeated each activity 10 times, so 1600 data samples were collected.
The 1600 sets of data collected by the experiment were combined with the 8000 sets of data extracted from the public datasets into a new dataset called the Joint-Dataset. The composition of Joint-Dataset is shown in
Table 2. The Joint-Dataset was used for network training and testing. 80% of the Joint-Dataset was used for training, and the remaining 20% was used for testing.
Table 3 shows the training data, validation data, and test data from the Joint-Dataset.
4.3. Methodology
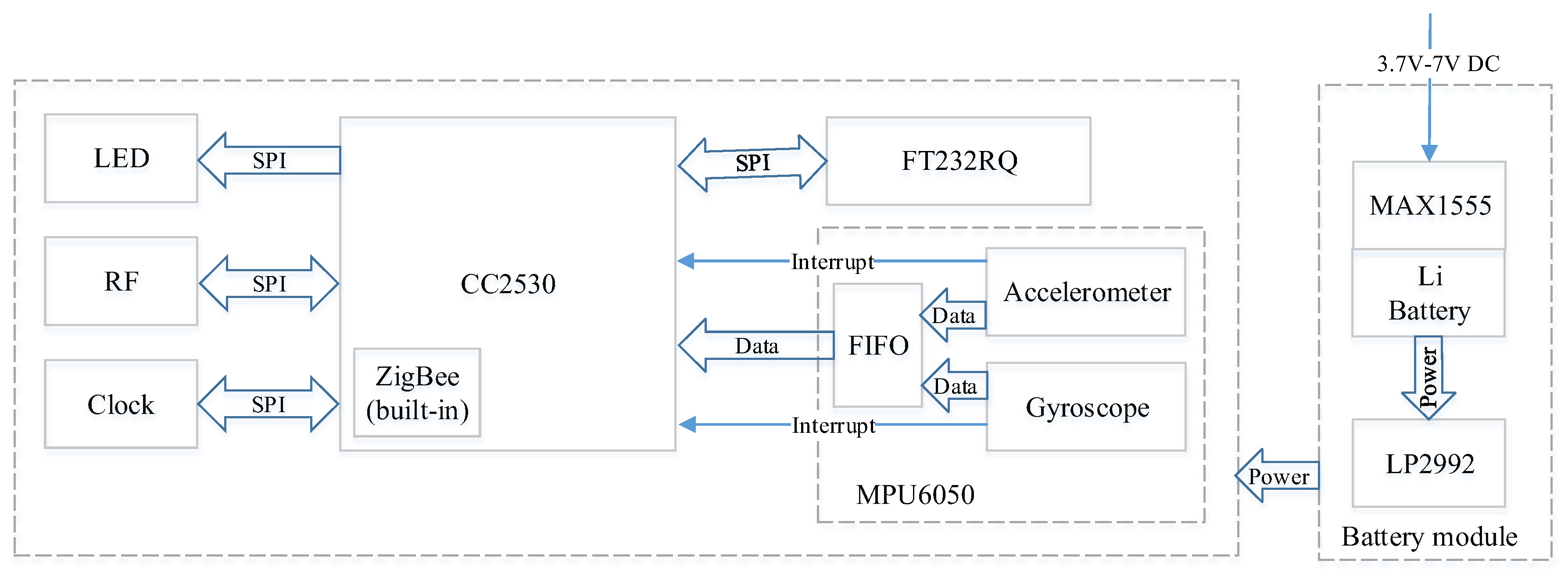
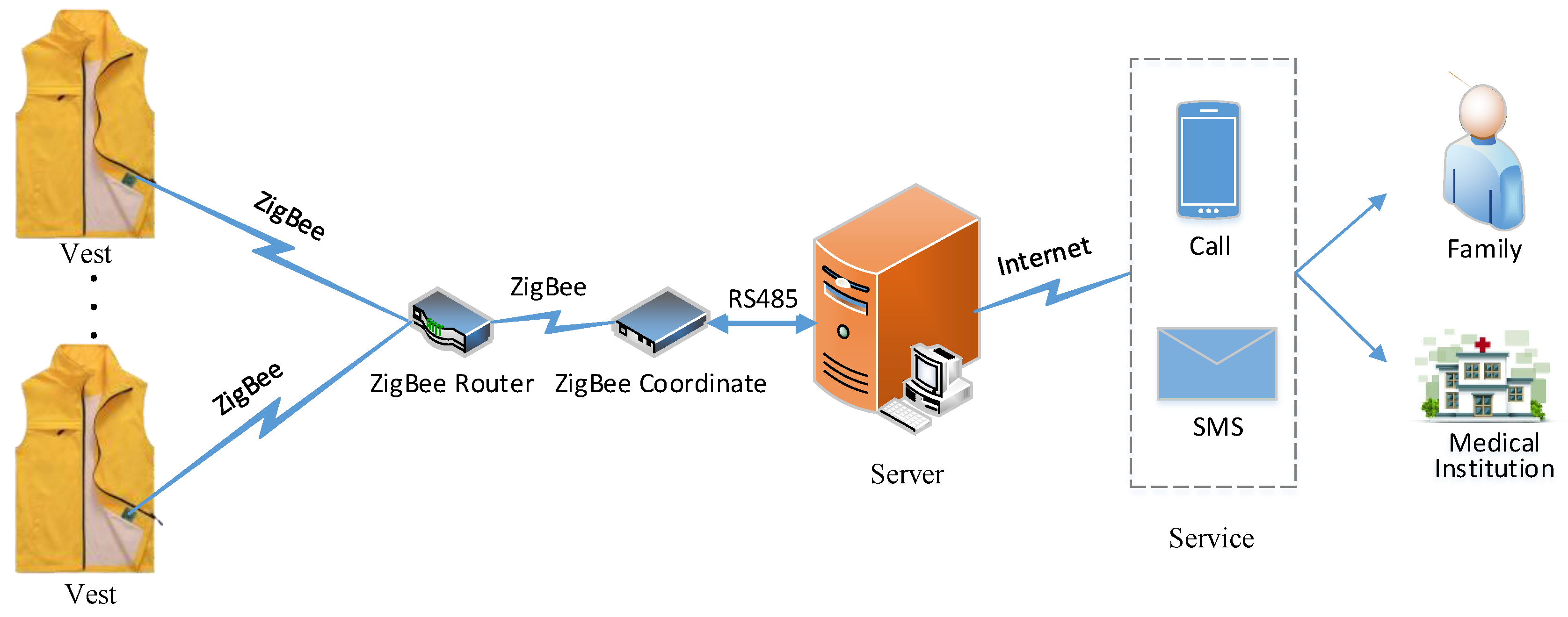
The FD-DNN was implemented with the TensorFlow framework. The training and classification of the model were carried out using the server shown in
Figure 5. Data were read and processed using the Pandas and Numpy libraries. Before training, the activity tags were one-hot encoded to simplify the logic and speed up the network calculation. The model was trained in a fully-supervised way, back propagating the gradients from the fully connected layer to the convolutional layers.
The FD-DNN network was trained by the training dataset shown in
Table 3. During the training, data were segmented into mini-batches of a size of 128 data segments, and the Adam algorithm was used to update the weights of the network. Since there were 200 data per sample, the step size of the network was set to 200. The learning rate was set to 0.001 and the number of epochs was set to 300.
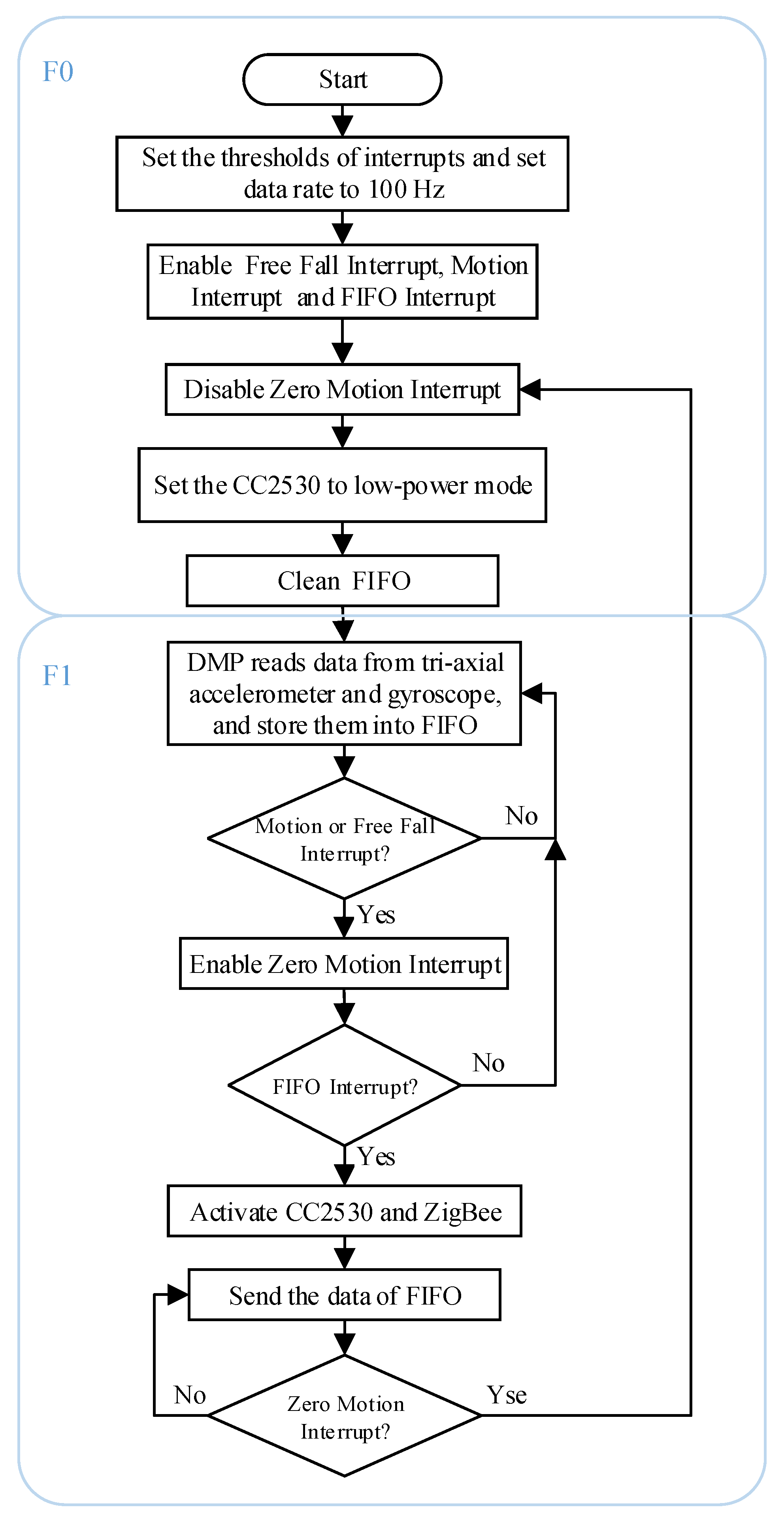
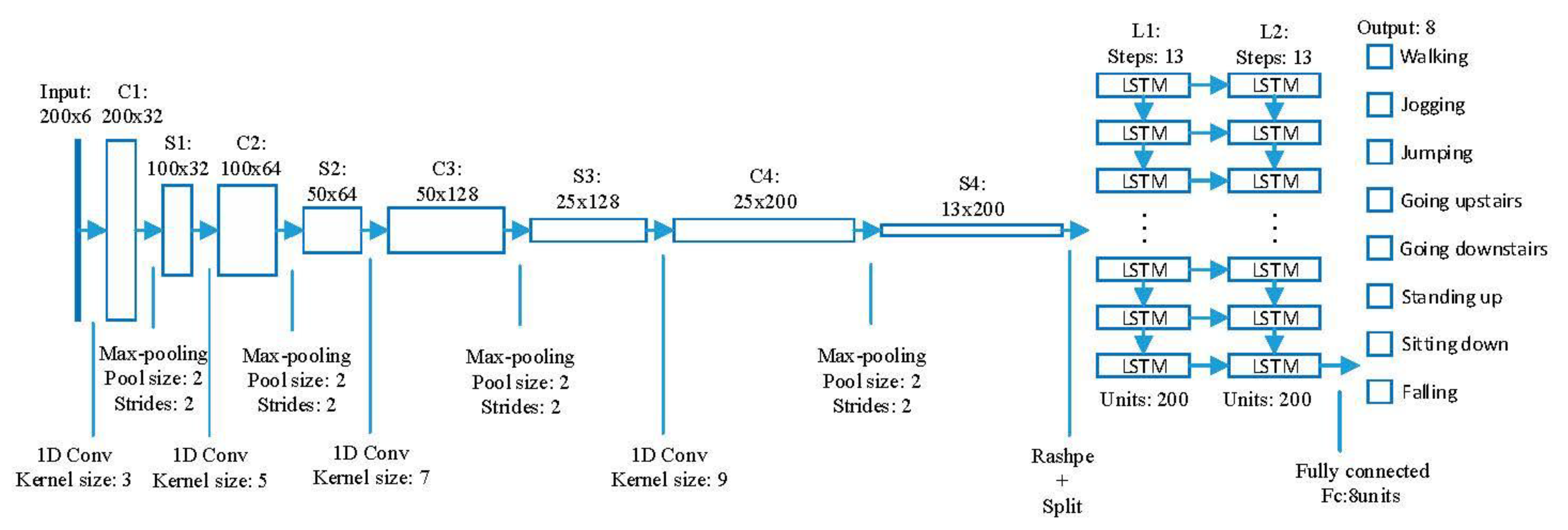
In the convolutional layers and the max-pooling layers, the parameters such as the number of filters, the size of the convolution kernel, the sliding stride, and the edge padding method were set according to
Section 3. In the two LSTM layers, the biases of the forget gate was set to 1.0 in order to reduce the scale of forgetting in the beginning of the training. The cell state and the hidden state of each LSTM layer were all initialized to zero. A dropout mechanism was added to each LSTM layer, and the activation of each randomly selected unit of each LSTM layer was set to zero with a probability of 0.5. In the full connection layer, the loss was calculated according to Formula (4). Based on the loss, the parameters were optimized.
The Adam optimizer, which combines the ability of AdaGrad [
32] to handle sparse gradients and the ability of RMSProp [
33] to handle non-stationary targets, was selected to optimize the network parameters [
34]; it calculated the adaptive learning rates for different parameters based on the estimates of the first and second moments of the gradient. For the sake of effect, the parameters were optimized with a learning rate of 1 × 10
−3 and a numerical stability variable of 1 × 10
−8. The parameters were updated according to the Adam method after each mini-batch.
Based on the above settings, the training was carried out. Training loss and training accuracy were computed every five iterations. Validation loss and validation accuracy were computed at every 25 iterations. The trained model is saved every 10 epochs. At the beginning of training, the accuracy of the FD-DNN network improved very quickly and fluctuated greatly. At the end of training, the accuracy improved slowly and fluctuated slightly. After 136-epochs training, the network accuracy (tested by the verification dataset) reached 99.28%, and no longer improves when training continues. Thus, the network training was stopped and the FD-DNN network model was saved. Since the FD-DNN was implemented using the TensorFlow framework, the saved model is a file with the suffix ‘.ckpt’, which can be used for various tests.
After training, the trained and saved FD-DNN model was used for offline tests. First, the test data were read and the trained model was loaded. Then, the test data were input to the loaded model. Finally, the test loss, test accuracy, and confusion matrix of the test are output. In addition, the specificity and sensitivity were calculated according to the confusion matrix. The test results were combined with the verification results during training to evaluate the performance of the network.
4.4. Results and Discussion
The test dataset was used to test the trained FD-DNN network offline. After testing, the accuracy of FD-DNN was 99.17%, and the sensitivity and specificity were 94.09% and 99.94%, respectively. In addition, the CNN and LSTN algorithms were also used to do an offline experiment with the same training and test samples.
Table 4 shows the comparison of accuracy, sensitivity, and time consumption. As shown in
Table 4, the accuracy of the FD-DNN is about 1% higher than that of the CNN and about 2.3% higher than that of LSTM, the sensitivity is increased by about 7%, and the specificity is also improved. In addition, it only takes about 1.05 s to classify 1920 samples. It proves that FD-DNN takes advantages of CNN and LSTM.
Comparative experiments between FD-DNN and traditional classification algorithms were also performed. The Weka software integrates many traditional algorithms [
35], so the dataset shown in
Table 3 was imported into Weka to test the performance of different algorithms.
Table 5 shows the experimental result. Among the traditional classification algorithms in
Table 5, SimpleLogistic algorithm got the lowest accuracy, while it took about 0.19 s to test the model on testing data. The accuracy of FD-DNN is 19.44% higher than that of the SimpleLogistic algorithm, although the test speed of FD-DNN is 0.86 s slower than that of the SimpleLogistic algorithm. The Random Forest algorithm got the high accuracy, while it took about 1.57 s to test model on the test dataset. The accuracy and test time of FD-DNN are 4.67% higher and 0.52 s shorter than the Random Forest algorithm, respectively. The specificity of FD-DNN is higher than the other algorithms except Bayes Net, although the sensitivity is lower than the other algorithms except the Random Tree algorithm. While ensuring specificity and testing speed, the FD-DNN improved the accuracy significantly compared with the traditional classification algorithms.
The confusion matrix on the test dataset for the fall detection task is illustrated in
Table 6 for the FD-DNN approach. According to the data in
Table 6, the accuracy, sensitivity, and specificity of the fall detection can be calculated. It can be seen from
Table 6 that the FD-DNN tends to misclassify Sitting down and Standing up. In the case of activity Sitting down, four Sitting down samples were misclassified as Standing up. Similarly, there were six Standing up samples that were misclassified as Sitting down. It may be because the misclassified samples of Sitting down and Standing up are not standard, resulting in the similarity of the two kinds of misclassified samples.
10 students aged 22–30 were invited to participate in online experiments. They wore the vest and repeated each of the eight activities 10 times. The server real-time received and classified the data sent from the sensor board in the vest. The accuracy of the online fall classification reached 98.25%, while the sensitivity and specificity were 87.72% and 100.00%, respectively. This shows that the proposed algorithm and system have good performance and can meet the requirements of real-time fall detection.
In order to verify the fall detection effect of the system for people over 65 years old, eight volunteers over 65 years old were invited to participate in the experiment. Their information is shown in
Table 7. Each subject tried 10 times for each activity, so a total of 640 samples were collected. To the best of our knowledge, there are no studies to conduct fall experiments for elderly people over 65 years old due to the relatively high risk. Some emergencies also appeared during the experiments. Subject 1 suddenly had difficulty breathing during the experiments, which was relieved after taking the drug. Subject 3 sweated too much during the experiments, and the experiments had to be suspended several times. In spite of the emergencies, the volunteers persisted in completing the experiment.
The elderly data (the data of the subjects over the age of 65) were input into the previously trained FD-DNN model for testing, and the accuracy was only about 20%. The reason of low accuracy is that the motion of the elderly is slower and smaller than that of the young, and the data features are inconsistent with the features that can be recognized by the FD-DNN model trained on the young subjects’ data.
In order to enable the model to recognize the motion data of the elderly, 3/4 of the elderly data were mixed with the Joint-Dataset to retrain the model. After 140-epochs training, the accuracy and loss of FD-DNN no longer changed significantly, and the training was stopped. The test accuracy of the model was 99.22%, the specificity was 99.88%, and the sensitivity was 94.82%. In addition, the remaining 1/4 of the elderly data was used to test the newly trained model. The accuracy, specificity, and sensitivity of the test were 94.38%, 100%, and 81.63%, respectively. Too few elderly data is the reason for the low accuracy. If there are more elderly data to train the model, the test accuracy will be further improved.
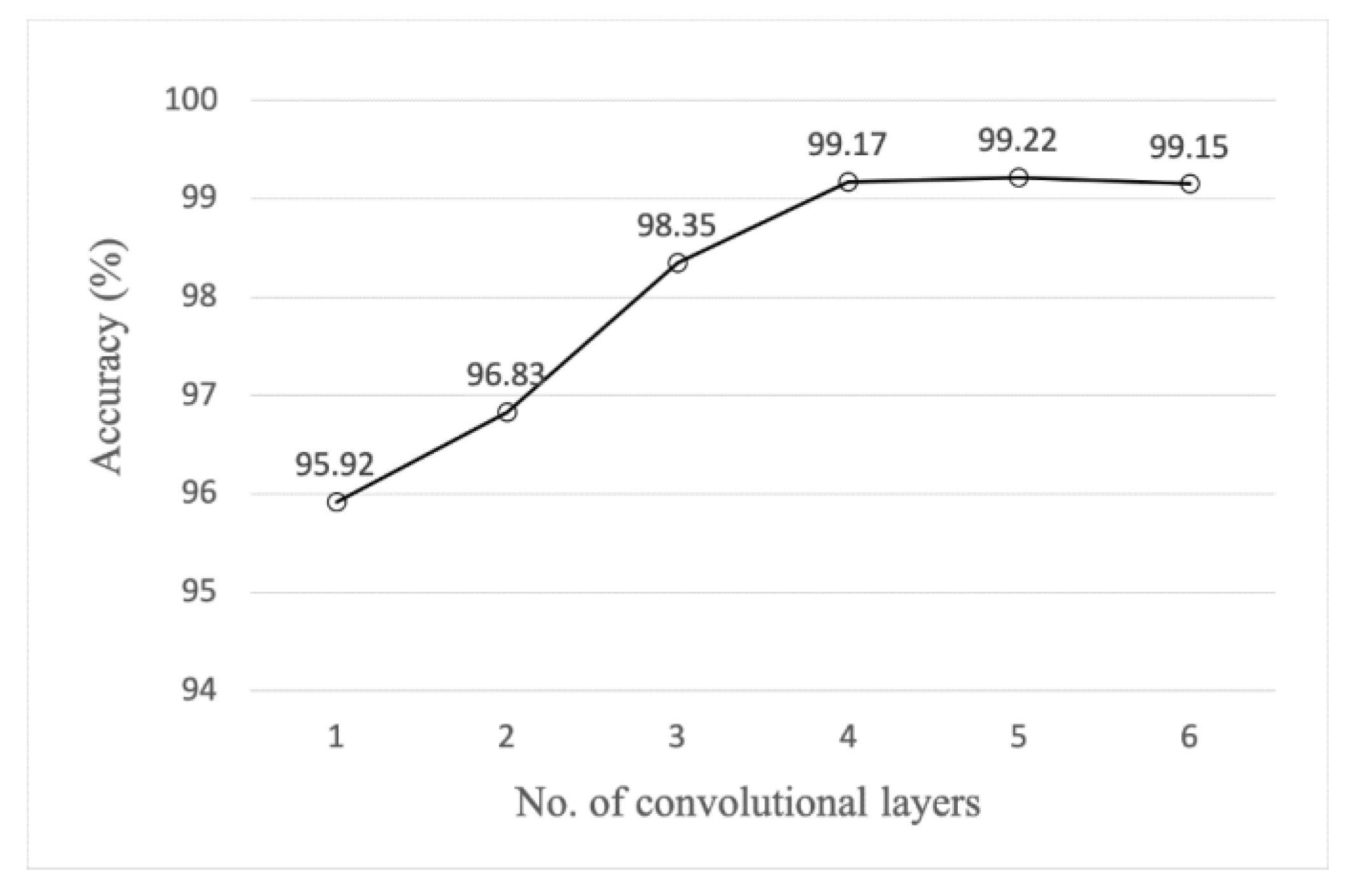
Other research showed that increasing the number of convolutional layers may be beneficial for activity recognition [
36]. Experiments were performed on the proposed FD-DNN with different number of convolutional layers. As can be seen from
Figure 7, the accuracy has a large increase when the number of convolution layers grows from one to four, and the growth rate is smaller when the number of convolution layers is greater than four. In particular, the accuracy of six convolution layers is a little smaller than that of five convolution layers. Furthermore, the growing number of convolutional layers leads to a sharp increase of trainable parameters and computational resources consumption. For example, adding a C5 layer the same as C4 will increase the parameters by 460,000 and increase the RAM consumption by 304 M when training. Therefore, the number of convolutional layers in FD-DNN is set to four.
Two experiments were designed to verify the energy saving of the sensing module. A 600 mAH battery was used to power the sensing module, and an experiment was designed to make the sensing module continuously send the data in the cache to the server every 0.8 s. The experimental results showed that the sensing module can work in this way for more than 30 h. In another real-world experiment, two experimenters wore the vests embedded with the sensing module (powered by a 600 mAH battery) to work normally in the laboratory for eight hours a day. The experimental results showed that the sensing module can work continuously for 140 h on a full charge. The power experiments show that the interrupt-driven, ZigBee-based activity sensing module has the characteristics of low power consumption and can meet the needs of elderly people to detect falls.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}