A Robust Fabric Defect Detection Method Based on Improved RefineDet


Abstract
:1. Introduction
- Powerful feature extraction capability. Object detection uses deep convolutional neural networks as the backbone [23], which can automatically extract the defect features of the input image.
- Efficient neck structure (feature pyramid and feature fusion) structure. Most object detection models have a neck (i.e., feature pyramid and feature fusion), which can detect defect areas with different sizes in the image. These feature pyramid structures are roughly divided into the following categories [24,25]: (1) SSD-style, (2) FPN-style, (3) STDN-style, (4) M2Det-style, (5) PAN-style. Some recent studies have made improvements on the neck structure and achieved a good detection result [19,26].
- Flexible selection of the model. Pre-existing object detection models usually can be divided into two categories, the one-stage object detection models and the two-stage object detection models. In general, the two-stage object detection models have higher localization and object classification accuracy and the one-stage object detection models are time-efficient and can be used for real-time detection [27]. According to the needs of different application scenarios, we can choose an appropriate model for training. In the field of fabric defect detection, the one-stage object detector can be selected as the base model to meet the needs of real-time detection.
- Classification and localization results based on image patch level. The object detection model generates candidate object bounding boxes (i.e., image patches with defect area or background area) from the feature maps and sends them to the classification subnetwork and regression subnetwork, respectively. After Non-Maximum Suppression (NMS), we can directly get the defect categories and location of each predicted defect image patch.
- Various general optimization methods. In the whole training and testing stages of the object detection model, many researchers proposed various general optimization methods [25,27,28], including data augmentation method, attention mechanism, learning rate scheduling strategy, activation function selection, loss function optimization, and post-processing method improvements. These optimization methods can boost the performance of all popular object detection models without introducing extra computational cost during inference [28].
- Good generalization ability. The object detection model mainly learns the feature of defect objects, rather than the background. Therefore, when there are enough training images with defect objects, it can be suitable for fabric defect detection under different texture backgrounds. Meanwhile, some state-of-the-art data augment [25,29,30,31], and Weakly Supervised Object Localization (WSOL) [32,33] methods can alleviate the problems of insufficient training samples and expensive manual labeling to a certain extent.
- We use RefineDet as the base model of defect detection. To the best of our knowledge, this is the first time that RefineDet has been used for fabric defect detection. Using the special two-step classification and regression structure of RefineDet, the proposed method can better detect the defect area compared with other common object detectors.
- We design an improved head structure. This improved head structure consists of Fully Convolutional Channel Attention-based Anchor Refinement Module (FCCA-ARM), BA-TCB, and Object Detection Module (ODM). By adding the channel attention mechanism (i.e., FCCA block) and designing the bottom-up path augmentation structure (i.e., BA-TCB), the detection accuracy of the proposed method is further improved.
- We research and verify the influence of many general optimization methods in the field of fabric defect detection. The state-of-the-art general optimization methods, such as attention mechanism, DIoU-NMS, and cosine annealing scheduler, are successfully applied to our detection model, which is an important reference for researchers in the fabric defect detection field.
2. Related Work
2.1. The Structure of The Object Detection Model
- Acquisition of input images. The raw images used for recent research were mainly from public datasets or collected by textile factories and laboratories. Some typical public defect detection datasets are TILDA dataset (https://lmb.informatik.uni-freiburg.de/resources/datasets/tilda.en.html), DAGM2007 dataset (https://hci.iwr.uni-heidelberg.de/content/weakly-supervised-learning-industrial-optical-inspection), and Hong Kong patterned texture database (https://ytngan.wordpress.com/codes/); and some self-built datasets are DHU-FD-500 [7], DHU-FD-1000 [7], lattice [8], FDBF dataset [19], etc.
- Image preprocessing. Insufficient of defect samples is a challenge in the research of fabric defect detection methods. To address this problem, the techniques of image pyramid [35] or sliding window [9] are introduced in the stage of image preprocessing. Particularly, many data augmentation methods based on photometric distortion and geometric distortion are widely used to increase the variability of the input images, including adjusting the brightness, contrast, hue, saturation, and noise of input images, image scaling, cropping, flipping, and rotating.
- Backbone. The backbone as the basic feature extractor of the object detection task is used to generate the output feature maps of the corresponding input images. The common backbones are VGG-16 [34,36], ResNet [37,38], ResNeXt [39], DarkNet-19 [15,21], DarkNet-53 [8,16], MobileNet [40,41], and ShuffleNet [42].
- Neck structure. Object detection model developed in recent years often insert the neck structure between the backbone network and the head structure, and the neck structure is usually used to collect feature maps from different layers with different resolutions of the backbone [25]. Common neck structures in recent research are Feature Pyramid Network (FPN) [43] with its variants CI-FPN [19], BI-FPN [26], NAS-FPN [44], and Path Aggregation Network (PAN) [45].
- Head. The head is used to predict classes and bounding boxes (detection results in image patch level) of defect objects. In this stage, one-stage object detectors directly predict class and bounding boxes from dense candidate boxes. Two-stage object detection models first filter out sparse refined boxes from dense boxes and then predict the results from the refined boxes. Therefore, the two-stage models have higher accuracy, and the one-stage models are time-efficient.
- Post-processing. In the testing stage, the post-processing step deletes any weak detecting results [23]. For example, NMS is a widely used method that only remains the object boxes with the highest classification score in predicted results. The common NMS methods are greedy-NMS [46], soft-NMS [47], adaptive-NMS [48].
2.2. The State-of-The-Art General Optimization Method
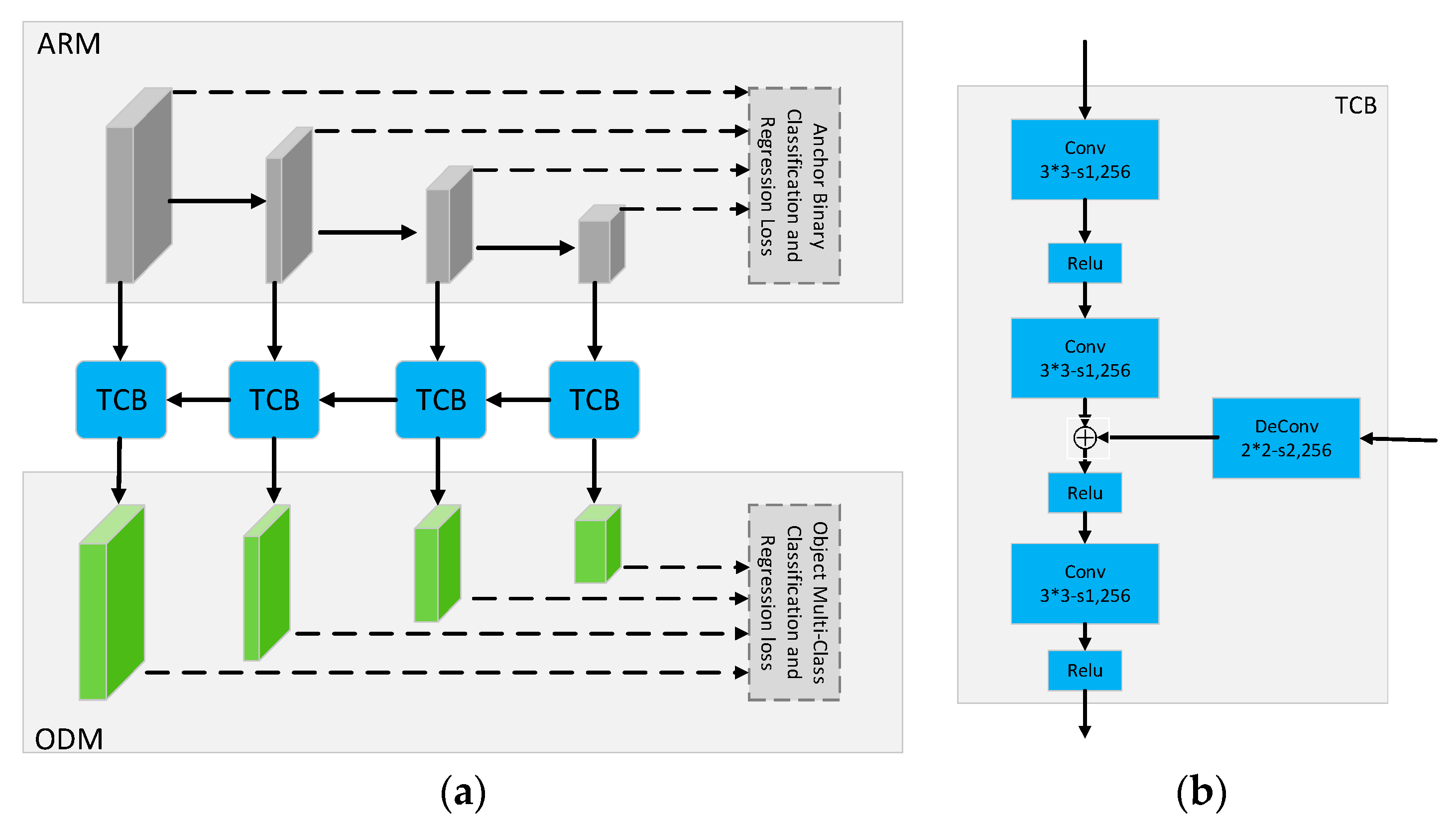
2.3. The Overview of RefineDet
- ARM. The four feature maps of ARM mainly come from different layers in the backbone. The ARM is designed to coarsely filter out refined boxes from dense candidate boxes and adjust the localizations and sizes of refined boxes (i.e., the first step classification and regression) so as to provide better initialization for the subsequent multi-class classification and regression task.
- TCB. TCB aims to transfer the refined boxes to ODM and integrate different features information (feature fusion) of shallow layers and deep layers of ARM.
- ODM. ODM takes the refined boxes as the input from the TCB and outputs predicted multi-class labels and the localizations of refined boxes (i.e., the second step classification and regression). In the testing stage, we can get the predicted results in the image patch level after NMS processing.
3. Methodology
3.1. Data Augmentation
3.2. VGG-16 Based Backbone
3.3. The Improved Head Structure
3.3.1. FCCA-ARM
3.3.2. BA-TCB
3.3.3. ODM
3.4. The Two-Step Loss Function and DioU-NMS
3.5. Leaning Rate Adjustment Method Based on Cosine Annealing Scheduler
4. Results and Discussion
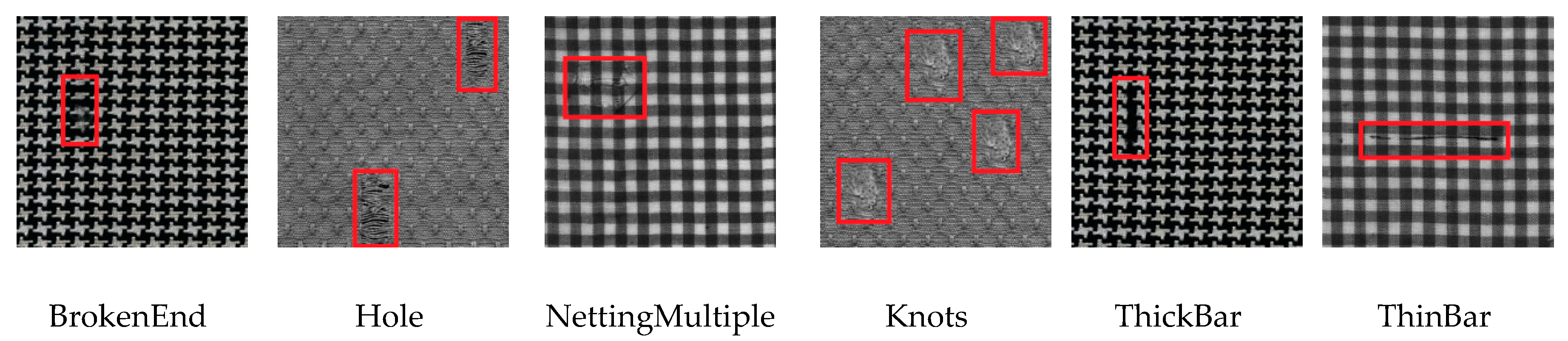
4.1. The Datasets and Evaluation Metrics
- TILDA dataset
- Hong Kong Patterned Textures Database
- DAGM2007 Dataset
- Evaluation Metrics
4.2. Experimental Results and Discussion on TILDA Dataset
4.2.1. Experimental Settings
- Faster RCNN: ResNet-50 backbone + FPN + RPN + SGD optimizer + StepLR scheduler +NMS.
- SSD: VGG-16 backbone + six layer feature pyramid + SGD optimizer + MultiStepLR scheduler + NMS.
- YOLOv3: DarkNet-53 backbone + three feature pyramid and feature fusion + Adam optimizer + NMS.
- FCOS (anchor free detector): ResNet-50 backbone + five layer FPN + NMS.
- Original RefineDet: VGG-16 backbone + four layer feature pyramid and head structure (ARM, TCB and ODM) +SGD optimizer + MultiStepLR scheduler + NMS.
- Ours: VGG-16 backbone + improved head structure (FCCA-ARM, BA-TCB and ODM) +SGD optimizer + Cosine annealing scheduler + DIoU-NMS.
4.2.2. Results and Discussion
4.3. Experimental Results and Discussion on the Hong Kong Dataset and DAGM2007 Dataset
4.3.1. Experimental Settings
4.3.2. Results and Discussion
4.4. Ablation Experiments
4.5. The Shortcomings and Outlook of The Proposed Method
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
A.1. Experimental Settings
A.2. Results and Discussion on PASCAL VOC Dataset


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | P (%) | R (%) | mAP (%) | F1-Score (%) | Parm. | Detection Time (FPS) |
|---|---|---|---|---|---|---|
| Original RefineDet (Data come from Table 1 in [34]) | - | - | 80.0 | - | - | 40.3 |
| Original RefineDet (Our reproduction in Pytorch) | 35.9 | 86.0 | 79.9 | 50.7 | 34.4 M | 37.2 |
| Ours (RefineDet + FCCA-ARM + BA-TCB + DIoU-NMS + Cosine annealing scheduler) | 37.4 | 86.3 | 80.1 | 52.2 | 43.6 M | 29.2 |
References
- Hanbay, K.; Talu, M.F.; Özgüven, Ö.F. Fabric defect detection systems and methods—A systematic literature review. Optik 2016, 127, 11960–11973. [Google Scholar] [CrossRef]
- Jia, L.; Chen, C.; Liang, J. Fabric defect inspection based on lattice segmentation and Gabor filtering. Neurocomputing 2017, 238, 84–102. [Google Scholar] [CrossRef]
- Jing, J.; Chen, S.; Li, P. Fabric defect detection based on golden image subtraction. Color. Technol. 2017, 133, 26–39. [Google Scholar] [CrossRef]
- Pan, Q.; Chen, M.; Zuo, B.; Hu, Y. The inspection of raw- silk defects using image vision. J. Eng. Fiber Fabr. 2018, 13, 78–86. [Google Scholar] [CrossRef] [Green Version]
- Zhang, B.; Tang, C. Fabric defect detection based on relative total variation model and adaptive mathematical morphology. Text. Res. J. 2017, 38, 145–149. [Google Scholar]
- Liu, L.; Zhang, J.; Liu, L.; Huang, Q.; Fu, X. Unsupervised segmentation and elm for fabric defect image classification. Multimed. Tools Appl. 2019, 78, 12421–12449. [Google Scholar] [CrossRef]
- Zhao, Y.; Hao, K.; He, H.; Tang, X.; Wei, B. A visual long-short-term memory based integrated CNN model for fabric defect image classification. Neurocomputing 2020, 380, 259–270. [Google Scholar] [CrossRef]
- Jing, J.; Zhuo, D.; Zhang, Y.; Liang, Y.; Zheng, M. Fabric defect detection using the improved YOLOv3 model. J. Eng. Fiber Fabr. 2020, 15, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Gan, X.; Lv, R.; Zhu, H.; Ma, L.; Wang, X.; Zhang, Z.; Huang, Z.; Zhu, H.; Ren, W. A fast and robust convolutional neural network-based defect detection model in product quality control. Int. J. Adv. Manuf. Technol. 2018, 94, 3465–3471. [Google Scholar]
- Mei, S.; Wang, Y.; Wen, G. Automatic fabric defect detection with a multi-scale convolutional denoising autoencoder network model. Sensors 2018, 18, 1064. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Hu, Q.; Zhai, B.; Chen, H.; Liu, K. A robust weakly supervised learning of deep Conv-Nets for surface defect inspection. Neural Comput. Appl. 2020. [Google Scholar] [CrossRef]
- Hu, G.; Huang, J.; Wang, Q.; Li, J.; Xu, Z.; Huang, X. Unsupervised fabric defect detection based on a deep convolutional generative adversarial network. Text. Res. J. 2020, 90, 247–270. [Google Scholar] [CrossRef]
- Ren, S.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–9 December 2015; pp. 91–99. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 10–16 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, HI, USA, 25–30 June 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, Z.; Liu, X.; Li, C.; Li, B.; Wang, B. Fabric Defect Detection Based on Faster R-CNN. In Proceedings of the 9th International Conference on Graphic and Image Processing, Qingdao, China, 14–16 October 2017; pp. 1–9. [Google Scholar]
- Liu, Z.; Guo, Z.; Yang, J. Research on Texture Defect Detection Based on Faster-RCNN and Feature Fusion. In Proceedings of the 11th International Conference on Machine Learning and Computing, Zhuhai, China, 22–23 February 2019; pp. 429–433. [Google Scholar]
- Wu, Y.; Zhang, X.; Fang, F. Automatic Fabric Defect Detection Using Cascaded Mixed Feature Pyramid with Guided Localization. Sensors 2020, 20, 871. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Liu, S.; Li, C.; Ding, S.; Dong, Y. Fabric Defects Detection Based on SSD. In Proceedings of the 2nd International Conference on Graphics and Signal Processing, Sydney, Australia, 6–8 October 2018; pp. 74–78. [Google Scholar]
- Zhang, H.; Zhang, L.; Li, P.; Gu, D. Yarn-Dyed Fabric Defect Detection with YOLOV2 Based on Deep Convolution Neural Networks. In Proceedings of the IEEE 7th Data Driven Control and Learning Systems Conference, Enshi, China, 25–27 May 2018; pp. 170–174. [Google Scholar]
- Wei, J.; Zhu, P.; Qian, X.; Zhu, S. One-Stage Object Detection Network for Inspecting the Surface Defects of Magnetic Tiles. In Proceedings of the 2019 IEEE International Conference on Imaging Systems and Techniques, Abu Dhabi, UAE, 9–10 December 2019; pp. 1–6. [Google Scholar]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A Survey of Deep Learning-Based Object Detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Zhao, Q.; Sheng, T.; Wang, Y. M2det: A Single-Shot Object Detector Based on Multi-Level Feature Pyramid Network. In Proceedings of the 33th AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 9259–9266. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. arXiv 2020, arXiv:1911.09070. [Google Scholar]
- Wu, X.; Sahoo, D.; Hoi, S.C.H. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; He, T.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of Freebies for Training Object Detection Neural Networks. arXiv 2019, arXiv:1902.04103. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; David, L. MixUp: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with CutOut. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Yun, S.; Han, D.; Chun, S.; Oh, S.J.; Yoo, Y.; Choe, J. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Zhang, X.; Wei, Y.; Feng, J.; Yang, Y.; Huang, T. Adversarial Complementary Learning for Weakly Supervised Object Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1325–1334. [Google Scholar]
- Zhang, C.; Cao, Y.; Wu, J. Rethinking the Route towards Weakly Supervised Object Localization. arXiv 2020, arXiv:2002.11359. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X. Single-Shot Refinement Neural Network for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4203–4212. [Google Scholar]
- Xie, H.; Zhang, Y.; Wu, Z. Fabric Defect Detection Method Combing Image Pyramid and Direction Template. IEEE Access 2019, 7, 182320–182334. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- He, K.; Georgia, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 386–397. [Google Scholar] [CrossRef]
- Xie, S.N.; Girshick, R.; Dollar, P. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Lin, T.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. arXiv 2017, arXiv:1612.03144. [Google Scholar]
- Chiasi, G.; Lin, T.Y.; Le, Q.V. NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7029–7038. [Google Scholar]
- Liu, S.; Qi, H.; Shi, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R. Soft-NMS–Improving Object Detection with One line of Code. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Adaptive NMS: Refining pedestrian detection in a crowd. arXiv 2019, arXiv:1904.03629. [Google Scholar]
- Geirhos, R.; Rubisch, P.; Michaelis, C.; Bethge, M.; Wichmann, F.A.; Brendel, W. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. arXiv 2019, arXiv:1811.12231. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Wu, E. Squeeze-and-excitation networks. arXiv 2018, arXiv:1709.01507. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for activation functions. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Misra, D. Mish: A self regularized nonmonotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Zheng, Z.H.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and better learning for bounding box regression. arXiv 2019, arXiv:1911.08287. [Google Scholar]















| Name | Layer | Output | Name | Layer | Output |
|---|---|---|---|---|---|
| Input | 320∗320∗3 | Conv4_2 | 3∗3-s1-p1, 512 | 40∗40∗512 | |
| Conv1_1 | 3∗3-s1-p1, 64 1 | 320∗320∗64 | Conv4_3 | 3∗3-s1-p1, 512 | 40∗40∗512 |
| Conv1_2 | 3∗3-s1-p1, 64 | 320∗320∗64 | Maxpool4 | 2∗2-s2-p0 | 20∗20∗512 |
| Maxpool1 | 2∗2-s2-p0 | 160∗160∗64 | Conv5_1 | 3∗3-s1-p1,512 | 20∗20∗512 |
| Conv2_1 | 3∗3-s1-p1, 128 | 160∗160∗128 | Conv5_2 | 3∗3-s1-p1,512 | 20∗20∗512 |
| Conv2_2 | 3∗3-s1-p1, 128 | 160∗160∗128 | Conv5_3 | 3∗3-s1-p1,512 | 20∗20∗512 |
| Maxpool2 | 2∗2-s2-p0 | 80∗80∗128 | Maxpool5 | 2∗2-s2-p0 | 10∗10∗512 |
| Conv3_1 | 3∗3-s1-p1, 256 | 80∗80∗256 | Conv6 | 3∗3-s1-p1,1024 | 10∗10∗1024 |
| Conv3_2 | 3∗3-s1-p1, 256 | 80∗80∗256 | Conv7 | 3∗3-s1-p1,1024 | 10∗10∗1024 |
| Conv3_3 | 3∗3-s1-p1, 256 | 80∗80∗256 | Conv8_1 | 1∗1-s1-p1, 256 | 10∗10∗256 |
| Maxpool3 | 2∗2-s2-p0 | 40∗40∗256 | Conv8_2 | 3∗3-s2-p1, 512 | 5∗5∗512 |
| Conv4_1 | 3∗3-s1-p1, 512 | 40∗40∗512 |
| Method | P (%) | R (%) | mAP (%) | F1-Score (%) | Parm. | Detection Time (FPS) |
|---|---|---|---|---|---|---|
| Faster RCNN | 65.9 | 55.8 | 58.9 | 60.4 | 41.1 M | 11.1 |
| SSD | 67.5 | 63.0 | 60.4 | 65.1 | 24.2 M | 33.3 |
| YOLOv3 | 59.7 | 38.4 | 33.3 | 46.7 | 63.0 M | 19.8 |
| FCOS | 76.1 | 81.5 | 76.8 | 78.7 | 32.0 M | 8.57 |
| Original RefineDet | 74.3 | 85.0 | 77.7 | 79.3 | 34.0 M | 41.4 |
| Ours | 78.9 | 85.5 | 80.2 | 82.1 | 43.1 M | 34.0 |
| Dataset | Method | P (%) | R (%) | mAP (%) | F1-Score (%) | Parm. | Detection Time (FPS) |
|---|---|---|---|---|---|---|---|
| Hong Kong testing set (32) | Original RefineDet (baseline) | 71.2 | 87.3 | 85.9 | 78.4 | 34.1 M | 21.9 |
| Ours | 73.6 | 92.1 | 87.0 | 81.8 | 43.2 M | 18.5 | |
| Hong Kong testing set with interference (128) | Original RefineDet (baseline) | 71.0 | 83.4 | 76.7 | 78.1 | 34.1 M | 42.8 |
| Ours | 76.6 | 88.7 | 82.6 | 81.5 | 43.2 M | 30.1 | |
| DAGM2007 testing set (1054) | Original RefineDet (baseline) | 96.6 | 97.5 | 96.7 | 97.0 | 33.2 M | 45.2 |
| Ours | 97.6 | 97.9 | 96.9 | 97.8 | 43.3 M | 33.0 |
| Index | Experimental Settings | mAP (%) | F1-Score (%) | Parm. | Detection Time (FPS) |
|---|---|---|---|---|---|
| 1 | RefineDet (baseline) | 77.7 | 79.3 | 34.0 M | 41.4 |
| 2 | RefineDet + FCCA-ARM | 78.3 | 80.1 | 34.3 M | 36.8 |
| 3 | RefineDet + FCCA-ARM + BA-TCB | 79.9 | 80.2 | 43.1 M | 33.9 |
| 4 | RefineDet + DIoU-NMS | 77.7 | 80.0 | 34.0 M | 39.7 |
| 5 | RefineDet + Cosine annealing scheduler | 77.9 | 79.7 | 34.0 M | 40.9 |
| 6 | Ours (RefineDet + FCCA-ARM + BA-TCB + DIoU-NMS + Cosine annealing scheduler) | 80.2 | 82.1 | 43.1 M | 34.0 |
| Index | Experimental Settings | mAP (%) | F1-Score (%) | Parm. | Detection Time (FPS) |
|---|---|---|---|---|---|
| 1 | RefineDet (baseline) | 77.7 | 79.3 | 34.0 M | 41.4 |
| 2 | RefineDet + Mish activation function | 76.7 | 81.7 | 34.0 M | 38.8 |
| 3 | RefineDet + Swish activation function | 76.2 | 78.7 | 34.0 M | 37.6 |
| 4 | RefineDet + SAM-ARM | 77.7 | 79.1 | 34.3 M | 40.2 |
| 5 | RefineDet + SE-ARM | 78.3 | 79.6 | 34.3 M | 40.5 |
| 6 | Ours + DIoU loss | 71.5 | 68.8 | 43.1 M | 33.6 |
| 7 | Ours + GIoU loss | 70.9 | 70.8 | 43.1 M | 33.2 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, H.; Wu, Z. A Robust Fabric Defect Detection Method Based on Improved RefineDet. Sensors 2020, 20, 4260. https://doi.org/10.3390/s20154260
Xie H, Wu Z. A Robust Fabric Defect Detection Method Based on Improved RefineDet. Sensors. 2020; 20(15):4260. https://doi.org/10.3390/s20154260
Chicago/Turabian StyleXie, Huosheng, and Zesen Wu. 2020. "A Robust Fabric Defect Detection Method Based on Improved RefineDet" Sensors 20, no. 15: 4260. https://doi.org/10.3390/s20154260
APA StyleXie, H., & Wu, Z. (2020). A Robust Fabric Defect Detection Method Based on Improved RefineDet. Sensors, 20(15), 4260. https://doi.org/10.3390/s20154260