Abstract
To fulfill the increasing demand on low-latency content distribution, this paper considers content distribution using generation-based network coding with the belief propagation decoder. We propose a framework to design generation-based network codes via characterizing them as building an irregular graph, and design the code by evaluating the graph. The and-or tree evaluation technique is extended to analyze the decoding performance. By allowing for non-constant generation sizes, we formulate optimization problems based on the analysis to design degree distributions from which generation sizes are drawn. Extensive simulation results show that the design may achieve both low decoding cost and transmission overhead as compared to existing schemes using constant generation sizes, and satisfactory decoding speed can be achieved. The scheme would be of interest to scenarios where (1) the network topology is not known, dynamically changing, and/or has cycles due to cooperation between end users, and (2) computational/memory costs of nodes are of concern but network transmission rate is spare.
1. Introduction
1.1. Background and Motivation
Low-latency content distribution to multiple users over a lossy and dynamic network is an important requirement in many emerging wireless applications. For example, in disaster recovery efforts, it is commonly required to disseminate content to a number of wearable devices or protective equipment in a timely and robust manner [1,2,3]. In these scenarios, random linear network coding (RLNC) [4] has potential as its coding nature enables fountain-like packet transmissions. Over a lossy network, RLNC can achieve reliable transmission without the need of packet acknowledgment. For example, RLNC can work atop user datagram protocol (UDP) similar to the quick UDP Internet connection (QUIC) protocol [5], which would considerably reduce the feedback cost and latency. Compared to conventional fountain codes such as the Raptor code [6], RLNC can further increase the throughput by allowing intermediate nodes of the network to recode packets. These benefits make RLNC quite attractive for fast content distribution.
One drawback of RLNC is its decoding computational/memory cost. When the number of source packets involved in coding, , is large, the cost of using Gaussian elimination (GE) for decoding can be prohibitive, especially for wireless nodes. For in the order of tens or several hundreds, straightforward sparse RLNC such as [7,8,9,10] where many encoding coefficients are zero can be used. For larger of more than tens of thousands, which are commonly seen in content distribution, however, the decoding of the above schemes may again suffer performance deterioration because the number of nonzero encoding coefficients is still large. By splitting the packets into small generations of sizes much smaller than , generation-based network coding (GNC) [11] can partly resolve this issue by only performing RLNC in the generation, and the multiple generations can be scheduled randomly throughout the distribution process (to avoid generation-by-generation notification). The coupon collector’s problem due to randomly scheduling the disjoint generations, which would cause many non-innovative (i.e., not linearly independent) coded packets being received by the users, can be alleviated by using overlapping generations [12,13]. Various overlapping GNC schemes have been proposed, including [14,15,16,17,18,19].
Two major decoding methods exist for GNC. One direction of research is to treat the encoding vector (EV) of each coded packet (from a generation) as a sparse vector over the original source packets (which is the same as in the straightforward sparse RLNC schemes), and then use sparse variants of GE to decode. This approach would succeed as soon as innovative packets (across all the generations) are received. However, the approach usually requires to pivot a sparse matrix of columns to exploit the sparseness of GNC, e.g., [8,20]. This, in programming implementation, still imposes high memory requirement for efficient random access of sparse matrix elements [21], otherwise the pivoting speed is significantly sacrificed. In practice, even for a moderate as a few hundreds, the decoding speed of sparse GE can be unsatisfactory [22].
The other general decoding method of GNC is belief propagation (BP) decoding, which was originally proposed in [12]. BP decoding only performs GE within each generation, and the decoded packets are subtracted from the remaining overlapping generations to help. The computational/memory requirement is significantly reduced as it is only in the magnitude of the generation size . The penalty is the overhead that the decoding may not succeed as soon as innovative packets are received because generations are not jointly decoded. However, this trade of overhead for computational/memory costs may be desirable in some scenarios, in particular where such costs are constrained but network transmission rate is spare, as commonly seen in the rapidly-growing Internet-of-Things (IoT) applications. This scenario is the main focus of the present paper.
With BP decoding, one major objective is to suppress the overhead. In this paper, we make the following contributions addressing this problem: (1) We propose a framework to design the GNC code via characterizing it as building an irregular bipartite graph, where the and-or tree evaluation technique [23] is extended to analyze its BP decoding performance, and (2) by allowing for non-constant generation sizes, we formulate optimization problems to design degree distributions from which generation sizes are drawn. Through extensive performance evaluations, we show that the code may achieve both low decoding costs and transmission overhead, as compared to using constant generation sizes [14,24].
1.2. Related Works
Using packet-level coding for content distribution has been widely studied in several previous works. One well-known work is the application of the Raptor codes for multimedia broadcast/multicast [25], which has been standardized in [26]. The Raptor code, however, is end-to-end. Since it does not support recoding at intermediate nodes, the throughput may not achieve the max-flow capacity over multi-hop links. In several recent works, e.g., [27,28,29], RLNC has been considered in content distribution in IoT scenarios. The works show that RLNC, possibly enhanced by recoding at intermediate nodes or via device-to-device communication links, can be effective for reducing content completion time. However, as mentioned, the supported number of packets is no more than several hundreds due to the high computational cost of RLNC.
It is noteworthy that in networks with known topologies, e.g., (parallel) line networks, there exists sparse RLNC schemes with low decoding costs and almost zero overhead, e.g., [17,30,31,32,33,34]. However, we note that these schemes do not apply to our interested scenarios where the network topology may be not known a priori, dynamically changing, and/or has cycles.
1.3. Organization
The remainder of the paper is organized as follows: Section 2 presents the system model and describes the encoding, recoding, and decoding operations. Section 3 models GNC schemes using irregular bipartite graphs. The and-or tree analysis technique is extended to study the BP decoding process on such graphs. In Section 4, a framework is presented that uses the analysis results for designing generation size distributions. The code design is evaluated in Section 5, and Section 6 concludes the findings.
2. System Model
We consider a network where a file consisting of packets are to be distributed from a source node s to a set of destination users via a lossy network. Each packet consists of K symbols from a finite field of size q. Links are modeled as Bernoulli erasure channels and the erasure probabilities are assumed to be fixed throughout the transmission. The system is discrete-time. At each transmission time, each node may send a packet to each of its downstream nodes. If no erasure occurs, the packet is received immediately by the neighboring node. Nodes are assumed to have no knowledge of the global network topology and do not exchange their buffer states information with other nodes. We assume that the destinations only acknowledge the source node upon the successful recovery of all source packets.
2.1. Precoding and Generation Constructions
Source packets are first precoded using a conventional fixed-rate erasure correction code. A total of intermediate packets, denoted as , are generated from the source packets supposing that a precode of rate is applied. The intermediate packets are then grouped into generations. For convenience, below we refer to packets in generations as intermediate packets even if the source packets are not precoded. Each generation is a subset of . Assume that we construct L generations, , , in which for some j. We assume that . We define , , and , where is the average generation size and is assumed to be an integer. The generations are said to be equal-sized if , or unequal-sized if for some . The generations are said to be disjoint if , or overlapping if there exists for some . For overlapping generations we have .
In a GNC code, we assume that the intermediate packets in each generation could be chosen at random from as follows. With the generation sizes specified, the N intermediate packets are randomly permuted and then evenly partitioned into L disjoint subsets (we assume L to be a divisor of N throughout the paper; if that is not the case, we can append some null packets), one per generation, i.e., . Therefore, . Such a partition ensures that each intermediate packet is present in at least one generation. After that, the remaining spots of is filled up by a random selection of packets from , where \ denotes set-minus.
2.2. Encoding and Recoding
The source node sends coded packets from generations on its outgoing links. For each transmission opportunity, one generation may be selected randomly or in a round-robin manner. The coded packet is then formed by combining packets belonging to the generation using RLNC over . For , a coded packet is in the form of , where is the coding coefficient uniformly randomly chosen from . is referred to as the encoding vector (EV), and is delivered in the header of .
At each node j other than the source node, L queues , are maintained to buffer received packets for each generation. A received packet is said to be innovative within if its EV is not in the span of the EVs of the existing packets in . We assume that received packets are processed such that non-innovative packets are discarded. In practice this may not be necessary, but the assumption simplifies the model.
Let be the number of buffered packets in queue l at time n. When a transmission opportunity is presented on an outgoing link of node j to one of its neighboring nodes i at time n, a queue is chosen according to a scheduling strategy. We denote the index of the scheduled queue as . A packet from is then recoded using RLNC and sent to i. Since the recoding is linear, the recoded packet is still a linear combination of the intermediate packets of the selected generation, just with the EV updated. An array is maintained for each , where indicates the numbers that has been scheduled for sending coded packets on so far. We denote as the local potential innovativeness of the queue on the link. Here terms “local” and “potential” are used because the innovativeness is only from the sending-node’s perspective and does not incorporate knowledge of packet loss and reception events downstream from node j. We refer to arrays , as the buffer states of node j at time n. If queue l is chosen, the value of is increased by one.
In this work, the following maximum local potential innovativeness (MaLPI) scheduling strategy [35] is adopted, which chooses the queue:
on at time n. If more than one queue attains the maximum, one of them is randomly chosen.
An overview of the system is summarized in Figure 1.
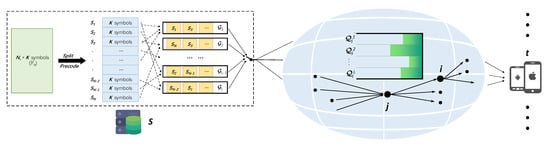
Figure 1.
An overview of the system.
2.3. Belief Propagation GNC Decoding
The BP decoding is used at each destination node to recover the source packets from the received (re)coded packets, which are random linear combinations of the intermediate packets. The algorithm consists of two parts: The inner decoding, which recovers the intermediate packets and the outer decoding, which recovers the source packets from the intermediate packets. This paper focuses on the inner decoding.
The inner decoder decodes intermediate packets of each generation by solving a linear system of equations using GE, where successive rows of and are the EVs and the coded K information symbols of the received packets that originate from , respectively. In practice, on-the-fly GE [36] can be used for this task, which would progressively process packets and know immediately when becomes full-rank.
When one generation is decoded by on-the-fly GE, the decoded packets are subtracted from the received packets of other not-yet decoded generations that also contain the decoded packets. This process is referred to as belief propagation. If no decodable generations can be found after the subtraction, the node continues to collect packets until another decodable generation is found. When the number of decoded intermediate packets reaches a threshold, which depends on the precode rate, outer decoding begins and all the source packets are recovered using conventional erasure correction techniques.
Suppose that packets need to be received to completely recover source packets, we define the overhead . The GNC code should be designed to achieve low .
3. Irregular Graph Based GNC and BP Decoding Analysis
3.1. Graph Representation of GNC Code
Generation construction with N intermediate packets resulting in L generations is modeled as constructing a bipartite graph. The packets and generations correspond to two independent sets of vertices on the graph, referred to as packet nodes and generation nodes, respectively. An edge is created to connect a pair of packet and generation nodes if the packet is contained in the generation, so the total number of edges . A node is said to be of degree i if i edges are directly connected to the node. We say an edge is of packet-side degree i if its connected packet node is of degree i and of generation-side degree i if its connected generation node is of degree i, respectively. We denote, as a fraction of the E edges, the packet-side and generation-side degree i of the resultant bipartite graph as and , respectively.
Since generations are constructed at random, a GNC code can be viewed as a random graph drawn from an ensemble of graphs consisting of all bipartite graphs with the fractions of edges of packet-side and generation-side degree i being , and , respectively. We refer to sequences and as the packet-side edge and generation-side edge degree distribution, or by their generator polynomials and , respectively. Equivalently, the graph can also be described by the packet-diversity distribution and generation-size distribution , where and denote the probability that a packet node is of degree k and a generation node is of degree d, respectively; and on the graph, where and are derivatives of and with respect to x, respectively. We see that is equal to the average generation size .
3.2. Belief Propagation Decoding Analysis
The decoding of GNC codes includes two types of operations: The GE decoding of a generation and the subtraction of the decoded packets from other generations. Based on the graph representation, the BP decoding can be viewed as message passing between graph nodes. We use a modified and-or-tree technique of [23] to analyze the process, where the modification is due to the GE decoding of the generation nodes.
The graph is fixed throughout the transmission after generation construction. At the decoder side, each generation node is associated with a random number of received packets. We denote the probability that a generation node with received packets contains k innovative encoded packets as , where and we refer to as the received ranks. When RLNC is used, is equivalently the probability that a matrix () with elements uniformly randomly chosen from has rank k. The probability is [37]:
The term is the probability that the first column of matrix is not all-zero and is probability that i-th column is not a linear combination of the previous columns. We have and for .
We define a binary message alphabet , where 0 and 1 stand for unknown (not decoded) and known (decoded) of a node on the graph, respectively. At the beginning of the decoding, every node on the graph sends unknown messages to its neighbors along the edges. Each generation node is associated with a received rank . The number of adjacent edges of a node carrying inputting unknown messages is referred to as the unknown degree of the node, denoted as and for packet nodes and generation nodes, respectively. Corresponding to the decoding process in Section 2.3, the message mapping rules on the graph is as follows: A generation node sends a known message on an adjacent edge if and only if its received rank k is larger than , which means that the generation can be decoded by GE because there are k innovative packets while there are only unknown packets therein. A packet node sends known messages on its adjacent edges if and only if is smaller than its node degree, which means that at least one generation that contains the packet has been decoded.
The decoding is more easily explained and analyzed by the and-or tree evaluation technique [23]. By randomly choosing one edge of the bipartite graph that is uniformly sampled from the ensemble of graphs that are characterized by and , and expanding the graph starting from its connected generation node, we can obtain a subgraph being a tree with high probability [23]. We denote this subgraph as , which is assumed to be obtained by expanding from a generation node to within distance . Packet and generation nodes are at depths and , respectively.
Let us consider the decoding of the root node of the . Suppose that the subgraph was obtained by expanding from a generation node of degree m that has received packets. Let denote the probability that it is not decodable. For , we have because generations can be decoded immediately if the number of their received innovative packets are larger than their degrees. We refer to this as self-decodable. For , is given in (2), where denotes the probability that an arbitrary packet node contained in the generation is sending an unknown message.
where
The first term in (2) is the probability that the number of received packets of the generation node is larger than or equal to its unknown degree but the received rank is not equal to the unknown degree; the second term is the probability that the number of received packets is smaller than the unknown degree of the generation node.
Take all possible into account. Let denote the probability that the chosen root node is of degree m and associated with received packets. Note that is related to and the number of received packets for each generation. Let denote the probability that an arbitrarily chosen root node is not decodable by evaluating to within distance on the bipartite graph, we have:
where the summations are over all possible pairs and A is a placeholder matrix consisting of probabilities . The exact form of A will be specified in later sections when we design code.
Now we need to determine . For , since the subgraph is a tree, as explained in [23] we can evaluate based on subgraphs of , . The probability that a d-degree packet node beneath the root of sends unknown is as follows:
where is the probability that the root node in a subgraph is not decodable. The two cases in (5) correspond to (1) the packet node connecting to only one generation node (i.e., the root node of ), which is definitely not decoded, and (2) all other generation nodes connecting this packet node are not decodable, respectively. Therefore,
Substituting (6) into (4), we have:
This shows that, given fixed , and the number of received packets of each generation, the evolution of , or in other words the decodability of each generation can be predicted. For , the subgraph only contains the root generation node and its packet nodes. So and corresponds to the probability that a randomly chosen generation is not self-decodable. The final value of , denoted as , corresponds to the smallest probability that the decoder can reach after going through all generations, or in other words, the fraction of generations that are not recoverable at the end of the BP decoding process.
For sources that are not precoded, all generations have to be recovered, so we need . This is infeasible because (7) is positive, which means that a not-precoded source is not guaranteed to be completely recovered given a fixed number of received packets. Interestingly, from another perspective this confirms that not-precoded GNC code would be affected by the “curse of coupon collector” [11].
For precoded GNC, choice of is straightforward because it is related to the precode rate . If there is a fraction intermediate packets that are not recovered by inner decoding, the packets ought to be recovered by outer decoding. This means that source packets are to be recovered from any intermediate packets. Therefore we have . In the following we focus exclusively on precoded GNC codes.
For the sake of simplicity, we now omit the index h and denote the probability that a generation node is not decodable at any time as y, . To ensure that the decoding process continues, we require:
which means that the probability that a generation node is not decodable should be strictly decreasing until a fraction of generations are decoded. This inequality will be used in the rest of the paper.
3.3. Derivation of and
According to Section 3.1, we observe that and only depend on and . The probability that a packet node connects to k generations using the generation construction of Section 2.1 is:
Therefore by some algebraic manipulations, we have:
and using , we have:
where the approximation is due to .
3.4. Computational Complexity
The encoding complexity of the GNC code is operations per encoded packet, where K is the number of symbols in the packet. For equal-size GNC codes, the decoder solves generations of equal-size by GE, so the decoding complexity is to recover all generations, where , and is per decoded packet. The GNC code is therefore linear in N for fixed , , and K. For unequal-size GNC with average generation size , some generations are larger than . However, we show later that by carefully designing the generation-size distribution, the resultant GNC code may be decoded by only solving generations of an unknown degree of no more than . Therefore, the decoding complexity of unequal-size GNC is upper bounded by equal-size GNC.
4. Irregular Graph Based GNC Design
4.1. Generation-Size Distribution Design
Based on the analysis of Section 3, we now design or , from which generation sizes are drawn. From (7) and (4) we see that are encapsulated in a joint distribution . For convenience, we denote . Unfortunately, is not easy to characterize because it also involves intermediary scheduling and erasures.
In this work, we resort to a heuristic simplification of to isolate . That is, we only allow for non-zero at a specific to design . We desire that such is smaller than , so that the decoding cost can be reduced compared to if a fixed generation size of were used. The resulting problem corresponds to minimizing overhead for the case of when all generations receive the same number of packets. We note that this assumption may not be realistic given that the number of packets received per generation can hardly be equal due to random erasures. However, minimizing such can be seen as an approximation of minimizing the expected overhead. By applying the simplifications, we can rewrite (8) as:
where,
and is specified in (10).
Given fixed , can be optimized as the solution to the following problem:
This problem can be solved by evenly discretizing the interval to generate multiple (e.g., ) inequalities in place of the single continuous one. For each point y at some multiples of , the inequality needs to be satisfied.
Denote the solution of as . Since , we can obtain by testing the problem feasibility with different , starting from the minimum possible value (i.e., ) up until the first feasible value of . It is observed that given and , is a linear combination of for each y in , so (13) is a linear programming problem and can be solved using standard techniques.
4.2. Refinements to Generation-Size Distribution
For , the obtained is supposed to be sufficient to ensure that the decoding is successful on average. However, some refinements still need to be made to ensure that the distribution works well in practice. The first refinement, similar to the design of ripple size in raptor codes [6], is to generalize constraints (11) by including a parameter , which represents the increment of decodabilities of other generations when a generation is decoded. Again, we can greedily search for the largest from the initial value such that (13) is feasible with known , i.e., enforce the probability increase as quickly as possible. Note that now the last inequality constraint is , and is still linear in . Therefore, the optimal , which is denoted as , is also the solution to a linear programming problem.
After obtaining , an objective function can also be chosen to find a better . A function that works well is the sum of on values of y discretized to generate the constraints. On one hand, from a performance point of view, minimizing corresponds to maximizing the gap area between and , the latter is the upper-bound probability that a generation is not decodable at each stage of decoding. The larger the area is, the larger the portion of newly decodable generations we would have. On the other hand, the minimization is a least -norm problem on , which produces a with a large number of zero components [38]. This is a good property because it would simplify generation construction in that only several generation sizes are possible even when the degree spread (i.e., ) is large. The generation-size distribution is then expressed in terms of using the fact that .
5. Performance Evaluation
5.1. Outline of Design
We first outline the code design procedure. Suppose that we want to transmit N packets in L generations given , , and q and we require that the decoding recovers at least fraction of generations directly. Given the parameters, for different choices of , we use the specified in (10) and solve the refined (13) to obtain , and the corresponding , from which we can sample generation sizes. For example, for , , , , and , we have by solving (13), and for the first refinement. The after refinements is given by the following polynomial:
In Figure 2, we plot the expected fraction of newly decodable generations () at various stages of the decoding process. This curve’s shape is typical for generation-size distributions considered here. The slowest period of the decoding process would occur at the beginning when few generations have been decoded. After that, the expected newly decodable fraction increases. This is an important feature in practice because it enables avalanche finishing when precoding is used. We will show this shortly. We note that values of N and L are not needed in the distribution design (as the analysis was on random ensembles), so is universal for the set of parameters .
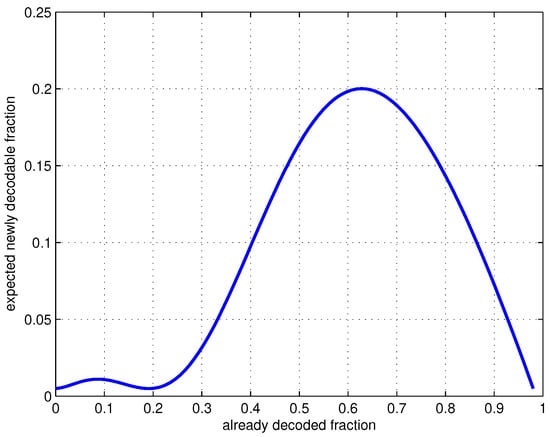
Figure 2.
Expected newly decodable fraction of generations at various stages, .
5.2. One-Hop Simulations
We now evaluate our code design in a single-hop setting by simulation and compare it with the disjoint chunking code (DCC) [11] and the random annex code (RAC) [14]. Our design is referred to as irregular GNC (iGNC) below. In single-hop networks, we do not need to consider buffer state because the source node has all its packets available. Packets are sent from each generation in a round-robin fashion to ensure that generations are scheduled evenly. Packets are erased with probability over the link. The performance metrics of interest are the overhead and the associated computational cost. The latter is measured by bookkeeping the average number of finite field operations performed to decode each symbol of a source packet. The field size throughout the following simulations.
We first consider GNC without precoding to show that the designed iGNC can achieve a better overhead-complexity tradeoff. Assume that 65,536 source packets to be transmitted, each contains symbols from , i.e., 64 megabytes (MiB) in total. We set the minimum generation size as and group packets into generations. The simulation results are summarized in Table 1, where the bold values correspond to the minimum achieved overhead of the corresponding schemes. The average overhead and the number of operations per symbol needed in successfully decoding DCC, RAC, and iGNC with different are listed. The implemented decoder finishes decoding in less than 6 s on a Raspberry Pi 4B, achieving a decoding speed of about 10 MiB/s. (The implementation is not optimized. We note that this speed can be significantly improved by turning on single instruction multiple data (SIMD) of CPU (i.e., NEON for ARM) for finite field operations according to the measurement reports in [39]. However, we do not further explore this as the implementation optimization is not the focus of this paper.) On the contrary, this scale of would be prohibitive in terms of either decoding time or memory requirement for decoders other than BP, e.g., [20]. When , RAC and iGNC reduce to DCC, in which no overlap is used. It is clear that DCC have the lowest computational cost but the largest overhead among all the configurations. For both RAC and iGNC, we see that there does exist a “sweet zone” when increasing . The lowest achievable overhead and corresponding computation cost for each configuration is highlighted in boldface. It is clear from Table 1 that iGNC has much lower overhead and computational cost at the same time for all choices of .

Table 1.
Comparison of codes at various , , and . RAC: Random Annex Code; iGNC: irregular Generation-based Network Code.
Results with precoding are also given in Table 1. When using a precode, we first encode source packets into intermediate packets using a fixed-rate erasure-correction code. The generation construction process is then applied to intermediate packets. In our decoding process, there are fraction of generations recovered directly. On average, this leaves a total of intermediate packets that are not recovered, i.e., a fraction of intermediate packets. Here the multiplier is due to the overlap between generations. As a result, our precode should be chosen such that it recovers all source packets from intermediate packets with erasure rate , i.e., . We apply the same systematic LDPC precode as in the standard raptor codes ([40], Section 5.4.2.3). For 65,536 and , parity check packets are added such that the last of packets can be recovered. It is noted that we need more generations to ensure that each intermediate packet is contained in at least one generation.
It is seen that precoding is also helpful in DCC (), and incurs almost no extra computational cost while reducing transmission overhead significantly. However, this improvement is not even competitive when compared to RAC and iGNC without precoding. By applying precoding to iGNC, we see that both overhead and computational cost can be further reduced. Specifically, for , we can achieve overhead below . The precoding is also beneficial to RAC, but its overhead and computation requirements are less favorable compared to that of iGNC for any choice of .
Two points need to be highlighted here. First, we note that the benefit of precoding is only feasible when is smaller than the value at which the best overhead and computational cost is achieved in the non-precoding setting, i.e., 42 for RAC and 44 for iGNC in this example, respectively. It is because generation overlap can be viewed as a special type of zero-computation precoding in which we simply duplicate some packets. However, there exists an optimal amount of redundancy in combating coupon collector’s phenomenon. When the amount of redundancy from solely using overlapping has achieved its best overhead performance, adding more redundancy by applying precoding helps nothing but needs more generations to cover the check packets, which deteriorates the performance. Second, it is noted that the performance gap between RAC and iGNC with precodings is very small at the best . The reason is essentially the same. Combining overlapping with LDPC precoding, a cascaded precoding design is actually obtained that is able to reduce much of the overhead caused by the coupon collector’s phenomenon. We emphasize that, as seen in Table 1, RAC is only comparable to iGNC when the best is known, which unfortunately is non-trivial to estimate. For any chosen value of , however, iGNC tends to have lower overhead and computational cost all the time, which is a decisive advantage of it.
In Figure 3, we plot the decoding curves showing the number of collected packets versus the number of decoded packets for one decoding instance of precoded and not-precoded iGNC, respectively. Both numbers are normalized against the number of source packets. Parameters are chosen according to Table 1 such that iGNC achieves the lowest overhead. We see that the decoding curve of matches with the expected newly decodable fraction of generations during the decoding as shown in Figure 2. The code has spent most of its time collecting packets for recovering the first of the source, and almost all packets are immediately recovered after that. In the case where no precoding is used, the decoding gets stuck when it is close to finishing and incurs a long tail in recovering the last few packets.
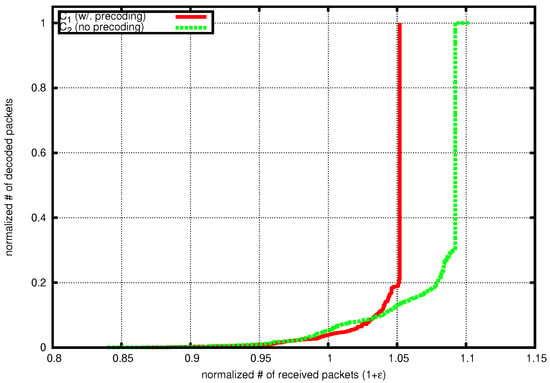
Figure 3.
Example of decoding curve, , .
5.3. Network Simulations
We now evaluate the iGNC in two simple networks, namely the two-hop line network and the well-known butterfly network. Each hop of the two-hop link has equal erasure probability , and each link of the butterfly network has equally . The max-flow capacities of the two networks are known to be and , respectively. Generations are scheduled in a round-robin fashion at the source node and MaLPI is used at intermediate nodes when recoding. source packets are transmitted. The same code parameters as in Section 5.2 are used. We examine the throughput rate, defined as the ratio of to the number of network uses, where each network use corresponds to that each link of the network transmits one packet. We compare the rates and computational costs of iGNC when RS and MaLPI are used, respectively. The results are shown in Table 2, where the highest achieved rates are marked as bold.
Table 2.
Performance of iGNC in networks , . RS: Random Scheduling; MaLPI: Maximum Local Potential Innovativeness.
When , the code reduces to DCC. It is clear from Table 2 that MaLPI achieves a higher rate. It is noted that the resulting throughput rate at best only achieves about and of the max-flow capacities of the two-hop and the butterfly network, respectively. The rate loss mostly comes from only making use of a local buffer state of each node in scheduling. As mentioned, a packet that is innovative from a sending-node’s point of view is not necessarily innovative for its downstream nodes, especially in networks where downstream nodes have multiple paths receiving packets. The proposed MaLPI scheme, however, is unaware of the issue because no coordination between nodes is available.
6. Conclusions
This paper has proposed using GNC codes with BP decoding for content distribution over lossy and dynamic networks. It was showed that GNC codes can be modeled as an irregular bipartite graph and its BP decoding performance can be analyzed through an extended and-or tree analysis. Using the analysis as the design tool, we managed to design degree distributions from which generation sizes are drawn through solving an optimization problem. Based on extensive performance evaluations, it was demonstrated that using non-constant generation sizes may achieve both a low decoding cost and transmission overhead compared to existing schemes where equal-size generations are used. We believe that the scheme has good potential in emerging wireless applications where end users of content distribution have limited computational/memory capacities.
For future works, it is of a great interest to evaluate the scheme in emulated/real-world network environment where links may have congestion and/or different propagation delays. Another interesting direction is to further suppress the overhead of BP decoding by incorporating more sophisticated operations such as inactivation decoding.
Author Contributions
Conceptualization, W.Y.; methodology, W.Y.; software, Y.L.; validation, Y.L.; writing—original draft preparation, W.Y.; writing—review and editing, Y.L.; funding acquisition, W.Y. and Y.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Science and Technology Fund of Nantong under Grant no. JC2018106, and by the Natural Science Foundation of the Jiangsu Higher Education Institutions under Grant no. 19KJB430028.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Kumbhar, A.; Koohifar, F.; Güvenç, İ.; Mueller, B. A Survey on Legacy and Emerging Technologies for Public Safety Communications. IEEE Commun. Surv. Tutor. 2017, 19, 97–124. [Google Scholar] [CrossRef]
- Metcalf, D.; Milliard, S.T.J.; Gomez, M.; Schwartz, M. Wearables and the Internet of Things for Health: Wearable, Interconnected Devices Promise More Efficient and Comprehensive Health Care. IEEE Pulse 2016, 7, 35–39. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Zhou, J.; Tao, G.; Alrashoud, M.; Mutib, K.N.A.; Al-Hammadi, M. Wearable 3.0: From Smart Clothing to Wearable Affective Robot. IEEE Netw. 2019, 33, 8–14. [Google Scholar] [CrossRef]
- Ho, T.; Medard, M.; Koetter, R.; Karger, D.R.; Effros, M.; Shi, J.; Leong, B. A Random Linear Network Coding Approach to Multicast. IEEE Trans. Inf. Theory 2006, 52, 4413–4430. [Google Scholar] [CrossRef]
- Langley, A.; Riddoch, A.; Wilk, A.; Vicente, A.; Krasic, C.; Zhang, D.; Yang, F.; Kouranov, F.; Swett, I.; Iyengar, J.R.; et al. The QUIC Transport Protocol: Design and Internet-Scale Deployment. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication (SIGCOMM), Los Angeles, CA, USA, 21–25 August 2017; pp. 183–196. [Google Scholar] [CrossRef]
- Shokrollahi, A. Raptor codes. IEEE Trans. Inf. Theory 2006, 52, 2551–2567. [Google Scholar] [CrossRef]
- Feizi, S.; Lucani, D.E.; Sørensen, C.W.; Makhdoumi, A.; Médard, M. Tunable sparse network coding for multicast networks. In Proceedings of the 2014 International Symposium on Network Coding (NetCod), Aalborg, Denmark, 27–28 June 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Sorensen, C.W.; Badr, A.S.; Cabrera, J.A.; Lucani, D.E.; Heide, J.; Fitzek, F.H.P. A Practical View on Tunable Sparse Network Coding. In Proceedings of the European Wireless, Budapest, Hungary, 20–22 May 2015; pp. 1–6. [Google Scholar]
- Lucani, D.E.; Pedersen, M.V.; Ruano, D.; Sørensen, C.W.; Fitzek, F.H.P.; Heide, J.; Geil, O.; Nguyen, V.; Reisslein, M. Fulcrum: Flexible Network Coding for Heterogeneous Devices. IEEE Access 2018, 6, 77890–77910. [Google Scholar] [CrossRef]
- Nguyen, V.; Tasdemir, E.; Nguyen, G.T.; Lucani, D.E.; Fitzek, F.H.P.; Reisslein, M. DSEP Fulcrum: Dynamic Sparsity and Expansion Packets for Fulcrum Network Coding. IEEE Access 2020, 8, 78293–78314. [Google Scholar] [CrossRef]
- Maymounkov, P.; Harvey, N.J.A.; Lun, D.S. Methods for Efficient Network Coding. In Proceedings of the Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 27–29 September 2006; pp. 482–491. [Google Scholar]
- Silva, D.; Zeng, W.; Kschischang, F.R. Sparse network coding with overlapping classes. In Proceedings of the Workshop Network Coding, Theory, and Applications (NetCod), Lausanne, Switzerland, 15–16 June 2009; pp. 74–79. [Google Scholar] [CrossRef]
- Heidarzadeh, A.; Banihashemi, A.H. How much can knowledge of delay model help chunked coding over networks with perfect feedback? In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Honolulu, HI, USA, 29 June–4 July 2014; pp. 456–460. [Google Scholar] [CrossRef]
- Li, Y.; Soljanin, E.; Spasojevic, P. Effects of the Generation Size and Overlap on Throughput and Complexity in Randomized Linear Network Coding. IEEE Trans. Inf. Theory 2011, 57, 1111–1123. [Google Scholar] [CrossRef]
- Tang, B.; Yang, S.; Yin, Y.; Ye, B.; Lu, S. Expander graph based overlapped chunked codes. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Cambridge, MA, USA, 1–6 July 2012; pp. 2451–2455. [Google Scholar] [CrossRef]
- Li, Y.; Chan, W.Y.; Blostein, S.D. Network coding with unequal size overlapping generations. In Proceedings of the 2012 International Symposium on Network Coding (NetCod), Cambridge, MA, USA, 29–30 June 2012; pp. 161–166. [Google Scholar]
- Yang, S.; Yeung, R. Batched Sparse Codes. IEEE Trans. Inf. Theory 2014, 60, 5322–5346. [Google Scholar] [CrossRef]
- Fiandrotti, A.; Bioglio, V.; Grangetto, M.; Gaeta, R.; Magli, E. Band Codes for Energy-Efficient Network Coding With Application to P2P Mobile Streaming. IEEE Trans. Multimed. 2014, 16, 521–532. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, J.; Bao, Z. Sparse Random Linear Network Coding With Precoded Band Codes. IEEE Commun. Lett. 2017, 21, 480–483. [Google Scholar] [CrossRef]
- Li, Y.; Chan, W.Y.; Blostein, S.D. On Design and Efficient Decoding of Sparse Random Linear Network Codes. IEEE Access 2017, 5, 17031–17044. [Google Scholar] [CrossRef]
- Duff, I.S.; Erisman, A.M.; Reid, J.K. Direct Methods for Sparse Matrices, 2nd ed.; Oxford University Press: New York, NY, USA, 2017. [Google Scholar]
- Garrido, P.; Sørensen, C.W.; Lucani, D.E.; Agüero, R. Performance and complexity of tunable sparse network coding with gradual growing tuning functions over wireless networks. In Proceedings of the IEEE International Symposium Personal, Indoor, and Mobile Radio Commun. (PIMRC), Valencia, Spain, 4–7 September 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Luby, M.; Mitzenmacher, M.; Shokrollahi, A. Analysis of Random Processes via And-Or Tree Evaluation. In Proceedings of the 9th Annu. ACM-SIAM Symp. Discrete Algorithms, San Francisco, CA, USA, 25–27 January 1998; pp. 364–373. [Google Scholar]
- Li, Y.; Wang, J.; Zhang, S.; Bao, Z.; Wang, J. Efficient Coastal Communications with Sparse Network Coding. IEEE Netw. 2018, 32, 122–128. [Google Scholar] [CrossRef]
- Luby, M.; Gasiba, T.; Stockhammer, T.; Watson, M. Reliable Multimedia Download Delivery in Cellular Broadcast Networks. IEEE Trans. Broadcast. 2007, 53, 235–246. [Google Scholar] [CrossRef]
- 3GPP. Multimedia Broadcast/Multicast Services (MBMS); Protocols and Codecs (Release 12); Technical Specification (TS) 26.346; 3rd Generation Partnership Project (3GPP). Available online: http://www.3gpp.org/ftp/Specs/archive/26_series/26.346/ (accessed on 1 July 2020).
- Leyva-Mayorga, I.; Torre, R.; Pandi, S.; T Nguyen, G.; Pla, V.; Martinez-Bauset, J.; Fitzek, F. A Network-coded Cooperation Protocol for Efficient Massive Content Distribution. In Proceedings of the 2018 IEEE Global Communications Conference, Abu Dhabi, UAE, 9–13 December 2018; pp. 1–7. [Google Scholar]
- Keshtkarjahromi, Y.; Seferoglu, H.; Ansari, R.; Khokhar, A. Device-to-Device Networking Meets Cellular via Network Coding. IEEE/ACM Trans. Netw. 2018, 26, 370–383. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, J.; Wang, J.; Bao, Z.; Quek, T.Q.S.; Wang, J. On Data Dissemination Enhanced by Network Coded Device-to-Device Communications. IEEE Trans. Wirel. Commun. 2020, 19, 3963–3976. [Google Scholar] [CrossRef]
- Tang, B.; Yang, S.; Ye, B.; Guo, S.; Lu, S. Near-Optimal One-Sided Scheduling for Coded Segmented Network Coding. IEEE Trans. Comput. 2016, 65, 929–939. [Google Scholar] [CrossRef]
- Tang, B.; Yang, S. An LDPC Approach for Chunked Network Codes. IEEE/ACM Trans. Netw. 2018, 26, 605–617. [Google Scholar] [CrossRef]
- Yang, J.; Shi, Z.; Xiong, J.; Wang, C. An Improved BP Decoding of BATS Codes with Iterated Incremental Gaussian Elimination. IEEE Commun. Lett. 2019. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, S.; Wang, J.; Ji, X.; Wu, H.; Bao, Z. A Low-Complexity Coded Transmission Scheme over Finite-Buffer Relay Links. IEEE Trans. Commun. 2018, 66, 2873–2887. [Google Scholar] [CrossRef]
- Zverev, M.; Garrido, P.; Agüero, R.; Bilbao, J. Systematic Network Coding with Overlap for IoT Scenarios. In Proceedings of the 2019 International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Barcelona, Spain, 21–23 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Li, Y.; Blostein, S.D.; Chan, W.Y. Large File Distribution Using Efficient Generation-based Network Coding. In Proceedings of the IEEE Globecom Workshops, Atlanta, GA, USA, 9–13 December 2013; pp. 427–432. [Google Scholar]
- Bioglio, V.; Grangetto, M.; Gaeta, R.; Sereno, M. On the fly Gaussian elimination for LT codes. IEEE Commun. Lett. 2009, 13, 953–955. [Google Scholar] [CrossRef]
- Trullols-Cruces, O.; Barcelo-Ordinas, J.M.; Fiore, M. Exact Decoding Probability Under Random Linear Network Coding. IEEE Commun. Lett. 2011, 15, 67–69. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: New York, NY, USA, 2004. [Google Scholar]
- Paramanathan, A.; Pedersen, M.V.; Lucani, D.E.; Fitzek, F.; Katz, M. Lean and mean: Network coding for commercial devices. IEEE Wirel. Commun. Mag. 2013, 20, 54–61. [Google Scholar] [CrossRef]
- Luby, M.; Shokrollahi, A.; Watson, M.; Stockhammer, T. Raptor forward Error Correction Scheme for Object Delivery. RFC5053RFC Editor. 2007. Available online: https://tools.ietf.org/rfc/rfc5053.txt (accessed on 1 July 2020).



© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).