Automatic Detection Method for Cancer Cell Nucleus Image Based on Deep-Learning Analysis and Color Layer Signature Analysis Algorithm



Abstract
:1. Introduction
2. Materials and Methods
2.1. Nucleus Image Recognition (Localization) by the YOLO Algorithm
2.2. Image Color Quantization and Region Localization
2.3. Regions without Cytoskeleton Removal and Regions of Incomplete Nucleus Images in the Boundary
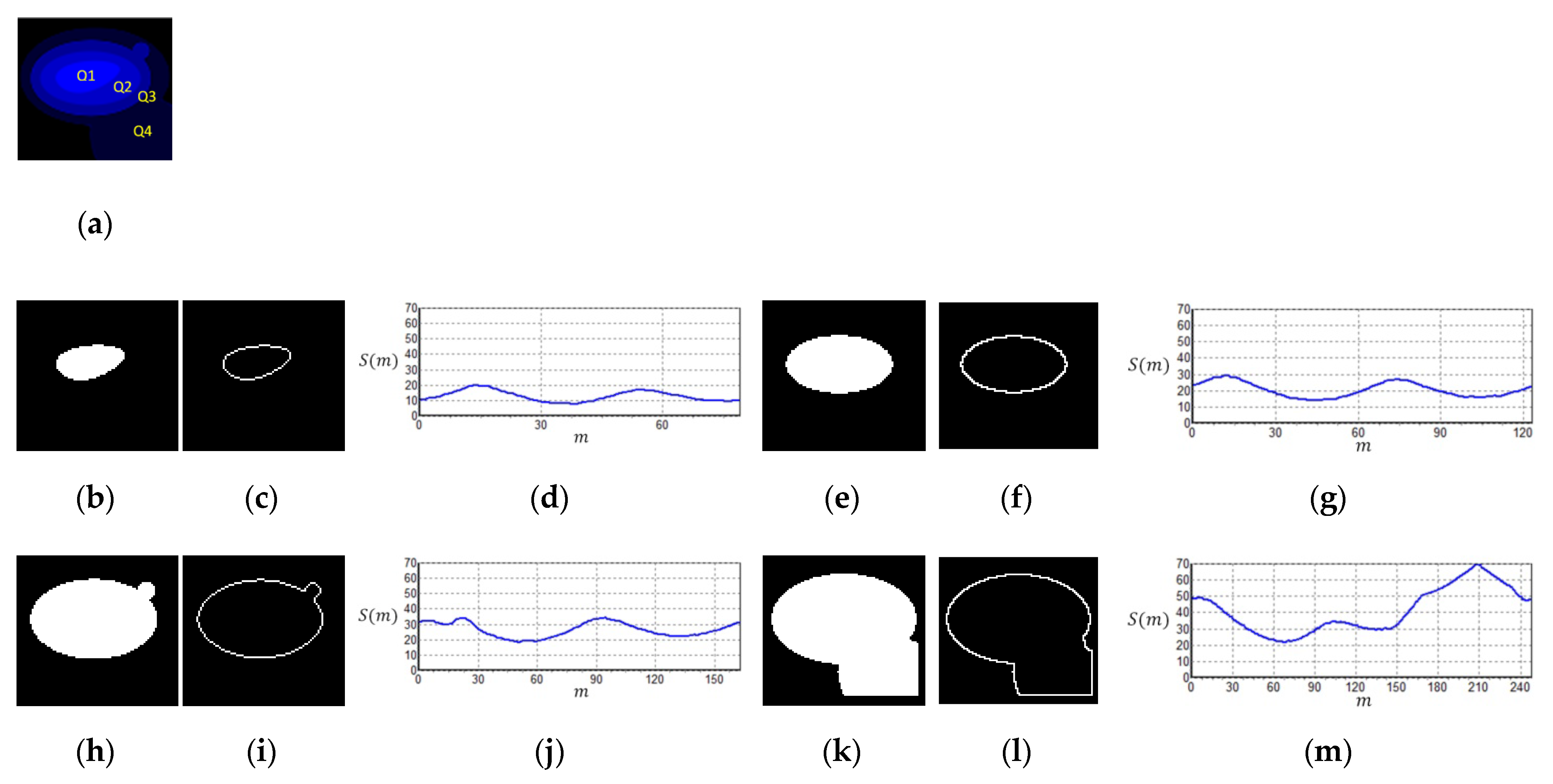
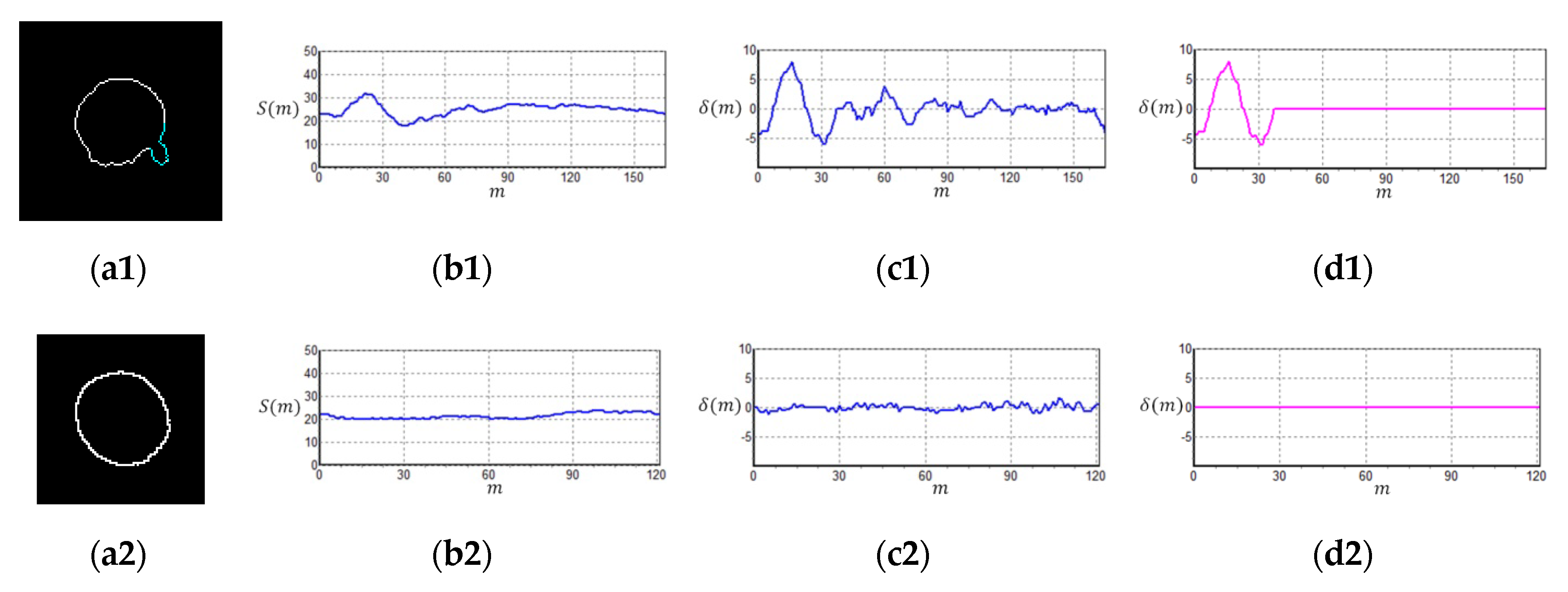
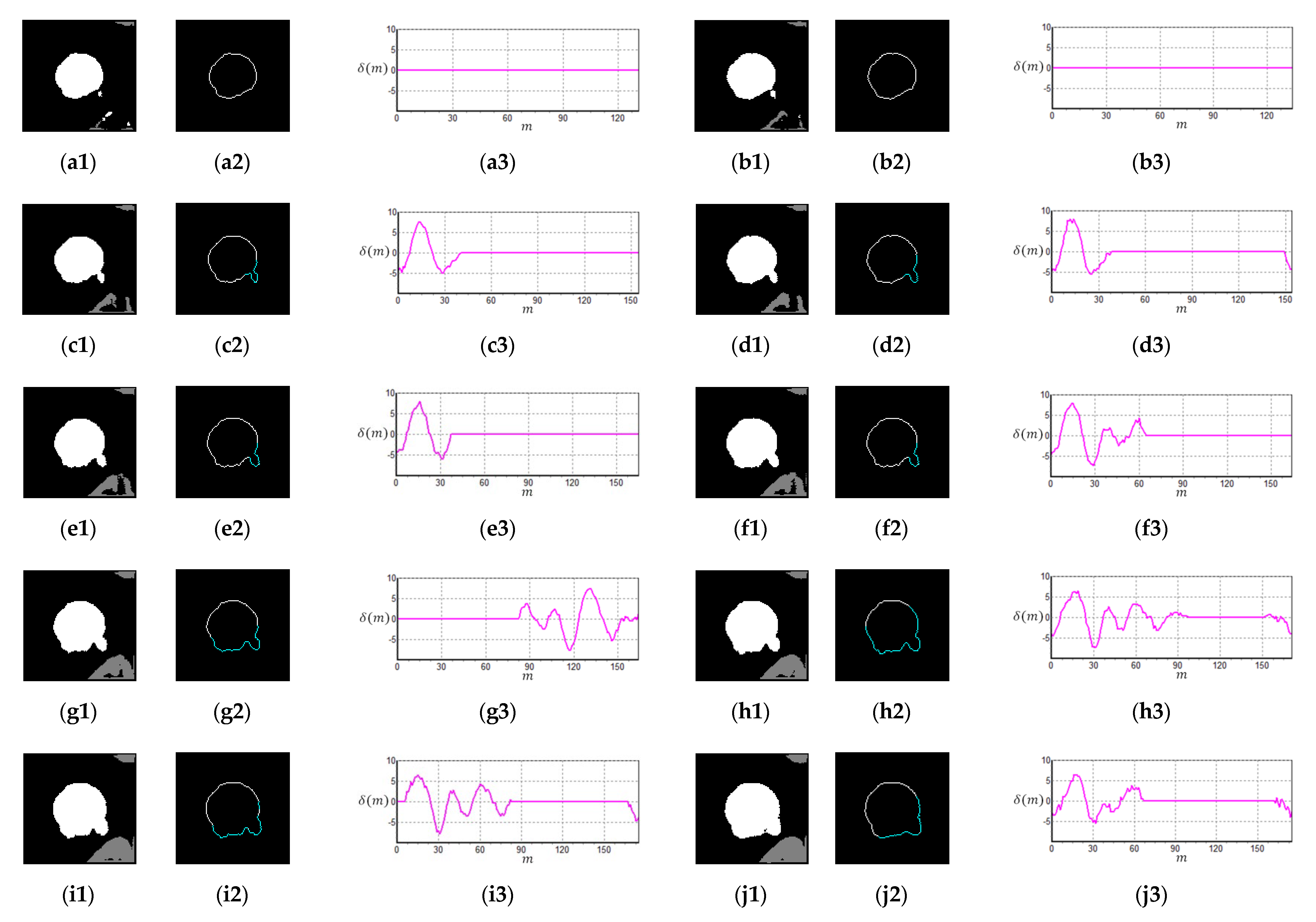
2.4. Color Layer Signature Analysis (CLSA) Algorithm
3. Results
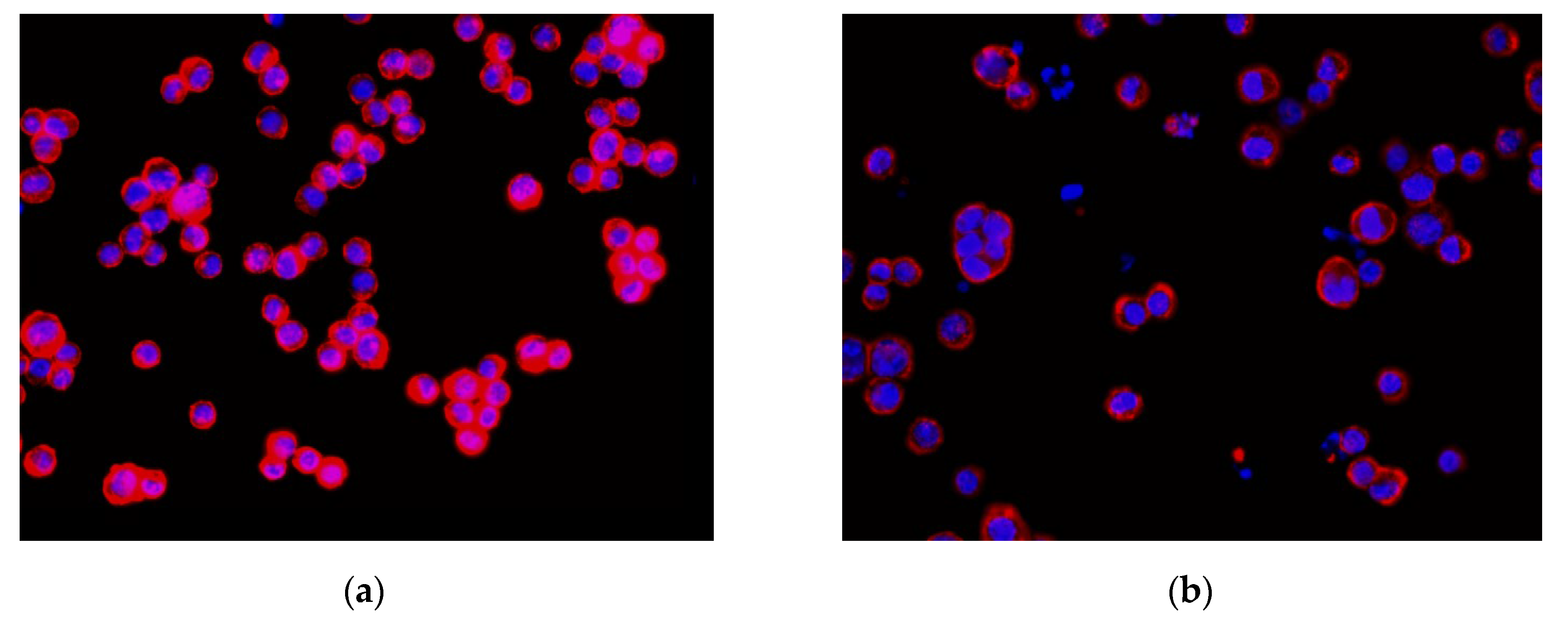
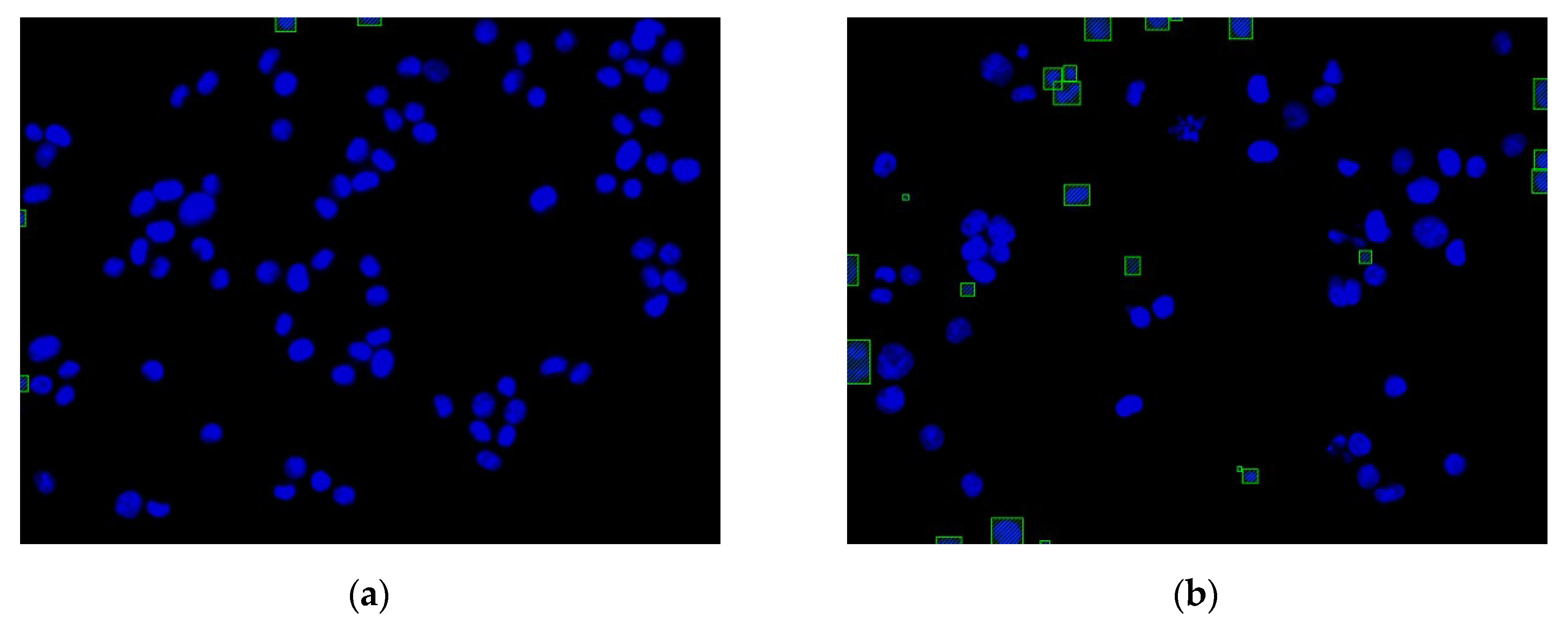
3.1. Nucleus Recognition Results with the YOLO Algorithm
3.2. Regions without Cytoskeleton Removal and Regions with Incomplete Nucleus Images in the Boundary
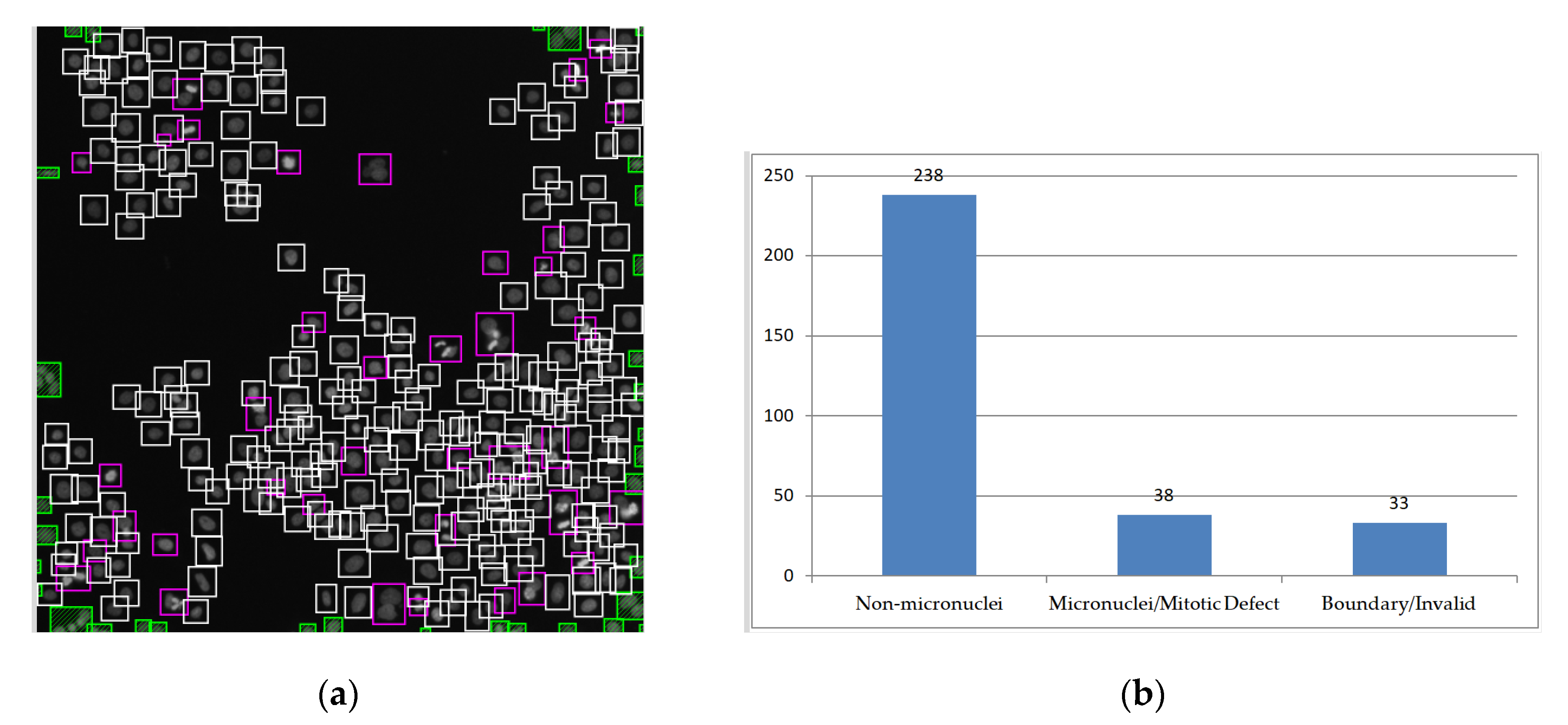
3.3. Color Layer Signature Analysis (CLSA) Algorithm
3.4. The Ratio of the Normal Cell Nuclei to Abnormal Cell Nuclei (Cell Nuclei with Mitotic Defects and Cell Nuclei with Micronuclei)
4. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tanaka, K.; Hirota, T. Chromosome segregation machinery and cancer. Cancer Sci. 2009, 100, 1158–1165. [Google Scholar] [CrossRef] [PubMed]
- Janssen, A.; Medema, R.H. Genetic instability: Tipping the balance. Oncogene 2013, 32, 4459–4470. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nam, H.J.; Naylor, R.M.; van Deursen, J.M. Centrosome dynamics as a source of chromosomal instability. Trends Cell Biol. 2015, 25, 65–73. [Google Scholar] [PubMed] [Green Version]
- Simonetti, G.; Bruno, S.; Padella, A.; Tenti, E.; Martinelli, G. Aneuploidy: Cancer strength or vulnerability? Int. J. Cancer 2019, 144, 8–25. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Silk, A.D.; Zasadil, L.M.; Holland, A.J.; Vitre, B.; Cleveland, D.W.; Weaver, B.A. Chromosome missegregation rate predicts whether aneuploidy will promote or suppress tumors. Proc. Natl. Acad. Sci. USA 2013, 110, 1–8. [Google Scholar] [CrossRef] [Green Version]
- McGranahan, N.; Burrell, R.A.; Endesfelder, D.; Novelli, M.R.; Swanton, C. Cancer chromosomal instability: Therapeutic and diagnostic challenges. EMBO Rep. 2012, 13, 528–538. [Google Scholar] [CrossRef] [Green Version]
- Janssen, A.; Kops, G.J.; Medema, R.H. Elevating the frequency of chromosome mis-segregation as a strategy to kill tumor cells. Proc. Natl. Acad. Sci. USA 2009, 106, 19108–19113. [Google Scholar] [CrossRef] [Green Version]
- Thompson, L.L.; Jeusset, L.M.-P.; Lepage, C.C.; McManus, K.J. Evolving therapeutic strategies to exploit chromosome instability in cancer. Cancers (Basel) 2017, 9, 151. [Google Scholar] [CrossRef] [Green Version]
- Vargas-Rondon, N.; Villegas, V.E.; Rondon-Lagos, M. The role of chromosomal instability in cancer and therapeutic responses. Cancers (Basel) 2017, 10, 4. [Google Scholar] [CrossRef] [Green Version]
- Tanaka, K.; Hirota, T. Chromosomal instability: A common feature and a therapeutic target of cancer. Biochim. Biophys. Acta 2016, 1866, 64–75. [Google Scholar] [CrossRef]
- Holland, A.J.; Cleveland, D.W. Losing balance: The origin and impact of aneuploidy in cancer. EMBO Rep. 2012, 13, 501–514. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Norppa, H.; Falck, G.C. What do human micronuclei contain? Mutagenesis 2003, 18, 221–233. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sharma, H.; Zerbe, N.; Heim, D.; Wienert, S.; Behrens, H.-M.; Hellwich, O.; Hufnag, P. A multi-resolution approach for combining visual information using nuclei segmentation and classification in histopathological images. VISAPP 2015, 3, 37–46. [Google Scholar]
- De Sousa, D.J.; Cardoso, M.A.; Bisch, P.M.; Pereira Lopes, F.J.; Nassif Travençolo, B.A. A segmentation method for nuclei identification from sagittal images of Drosophila melanogaster embryos. 21st WSCG Int. Conf. 2013, 133–142. [Google Scholar]
- Marek, K.; Filipczuk, P. Nuclei segmentation for computer-aided diagnosis of breast cancer. Int. J. Appl. Math. Comput. Sci. 2014, 24, 19–31. [Google Scholar]
- Song, Y.; Qin, J.; Lei, B.; Choi, K.-S. Automated segmentation of overlapping cytoplasm in cervical smear images via contour fragments. AAAI Conf. Artif. Intell. 2018, 99, 168–175. [Google Scholar]
- Vununu, C.; Lee, S.-H.; Kwon, K.-R. A Deep Feature Extraction Method for HEp-2 Cell Image Classification. Electronics 2019, 8, 20. [Google Scholar] [CrossRef] [Green Version]
- Kucharski, D.; Kleczek, P.; Jaworek-Korjakowska, J.; Dyduch, G.; Gorgon, M. Semi-Supervised Nests of Melanocytes Segmentation Method Using Convolutional Autoencoders. Sensors 2020, 20, 1546. [Google Scholar] [CrossRef] [Green Version]
- Ramadhani, D.; Purnami, S. Automated detection of binucleated cell and micronuclei using CellProfiler 2.0 software. HAYATI J. Biosci. 2013, 20, 151–156. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: London, UK, 2016; ISBN 0262035618. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Proc. Syst. 2012, 1, 1097–1105. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. In Proceedings of the 2013, OverFeat: Integrated Recognition, Localization and Detection Using Convolutional Networks, International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2013. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Computer Vision—ECCV 2014. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2014; Volume 8689, pp. 818–833. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. 2015 Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 2015 International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision—ECCV 2016. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, H.; Zhuang, L.; Van Der Maaten, L.; Kilian, Q. Weinberger, Densely connected convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement (Tech Report). 2018. Available online: https://pjreddie.com/media/files/papers/YOLOv3.pdf (accessed on 1 November 2018).
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 4th ed.; Pearson: London, UK, 2018; ISBN 9780133356724. [Google Scholar]
- Verevka, O. Color image quantization in window system with local k-means algorithm. In Proceedings of the Western Computer Graphics Symposium, Geneva, Switzerland, 19–21 April 1995; pp. 74–79. [Google Scholar]
- Dong, Y.; Wang, J.; Sheng, Z.; Li, G.; Ma, H.; Wang, X.; Zhang, R.; Lu, G.; Hu, Q.; Sugimura, H.; et al. Downregulation of EphA1 in colorectal carcinomas correlates with invasion and metastasis. Mod. Pathol. 2009, 22, 151–160. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- LabelImg. Available online: https://github.com/tzutalin/labelImg (accessed on 3 November 2018).
- CellProfiler. Available online: https://cellprofiler.org/examples (accessed on 15 July 2020).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total Regions: 70 | |||||||
|---|---|---|---|---|---|---|---|
| Nucleus Detection by YOLO: 45 | Free Regions: 25 | ||||||
| Regions within the Image: 38 | Regions in the Boundary: 7 | Free Regions: 25 | |||||
| Non-Micronuclei: 29 | Micronuclei: 9 | In Boundary/Invalid Regions: 23 | Regions of Mitotic Defects or Micronuclei: 9 | ||||
| TN1 | FN2 | TP3 | FP4 | TP | FP | TP | FP |
| 26 | 3 | 8 | 1 | 23 | 0 | 9 | 0 |
| Total Regions: 309 | |||||||
|---|---|---|---|---|---|---|---|
| Nucleus Detection by YOLO: 246 | Free Regions: 63 | ||||||
| Regions within Image: 238 | Regions in Boundary: 8 | Free Regions: 63 | |||||
| Non-Micronuclei: 237 | Micronuclei: 1 | In Boundary/Invalid Regions: 33 | Regions of Mitotic Defects or Micronuclei: 38 | ||||
| TN1 | FN2 | TP3 | FP4 | TP | FP | TP | FP |
| 234 | 3 | 1 | 0 | 33 | 0 | 38 | 0 |
| Manual Detection: (The Average Inspection Time Was 5.1 min for One Image) Normal Nucleus: Abnormal Nucleus | The Proposed Method: (The Average Computation Time Was 9.7 s for One Image) Normal Nucleus: Abnormal Nucleus | ||
|---|---|---|---|
| HCT116 + DMSO | 486: 42 (92.0%: 8.0%) | HCT116 + DMSO | 489: 44 (91.7%: 8.3%) |
| HCT116 + Dinaciclib | 335: 113 (74.8%: 25.2%) | HCT116 + Dinaciclib | 317: 134 (70.3%: 29.7%) |
| DLD-1 + DMSO | 597: 73 (89.1%: 10.9%) | DLD-1 + DMSO | 593: 80 (88.1%: 11.9%) |
| DLD-1 + Dinaciclib | 450: 143 (75.9%: 24.1%) | DLD-1 + Dinaciclib | 422: 163 (72.1%: 27.9%) |
| HT29 + DMSO | 546: 54 (91.0%: 9.0%) | HT29 + DMSO | 536: 74 (87.9%: 12.1%) |
| HT29 + Dinaciclib | 479: 99 (82.9%: 17.1%) | HT29 + Dinaciclib | 473: 106 (81.7%: 18.3%) |
| SW480 + DMSO | 486: 56 (89.7%: 10.3%) | SW480 + DMSO | 490: 42 (92.1%: 7.9%) |
| SW480 + Dinaciclib | 615: 125 (83.1%: 16.9%) | SW480 + Dinaciclib | 612: 136 (81.8%: 18.2%) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, H.-H.; Pan, H.-W.; Lu, C.-P.; Chuang, J.-J.; Yang, T. Automatic Detection Method for Cancer Cell Nucleus Image Based on Deep-Learning Analysis and Color Layer Signature Analysis Algorithm. Sensors 2020, 20, 4409. https://doi.org/10.3390/s20164409
Su H-H, Pan H-W, Lu C-P, Chuang J-J, Yang T. Automatic Detection Method for Cancer Cell Nucleus Image Based on Deep-Learning Analysis and Color Layer Signature Analysis Algorithm. Sensors. 2020; 20(16):4409. https://doi.org/10.3390/s20164409
Chicago/Turabian StyleSu, Hsing-Hao, Hung-Wei Pan, Chuan-Pin Lu, Jyun-Jie Chuang, and Tsan Yang. 2020. "Automatic Detection Method for Cancer Cell Nucleus Image Based on Deep-Learning Analysis and Color Layer Signature Analysis Algorithm" Sensors 20, no. 16: 4409. https://doi.org/10.3390/s20164409
APA StyleSu, H.-H., Pan, H.-W., Lu, C.-P., Chuang, J.-J., & Yang, T. (2020). Automatic Detection Method for Cancer Cell Nucleus Image Based on Deep-Learning Analysis and Color Layer Signature Analysis Algorithm. Sensors, 20(16), 4409. https://doi.org/10.3390/s20164409