Complementary Deep and Shallow Learning with Boosting for Public Transportation Safety


Abstract
:1. Introduction
1.1. Motivations
1.2. Challenges
1.3. Contributions
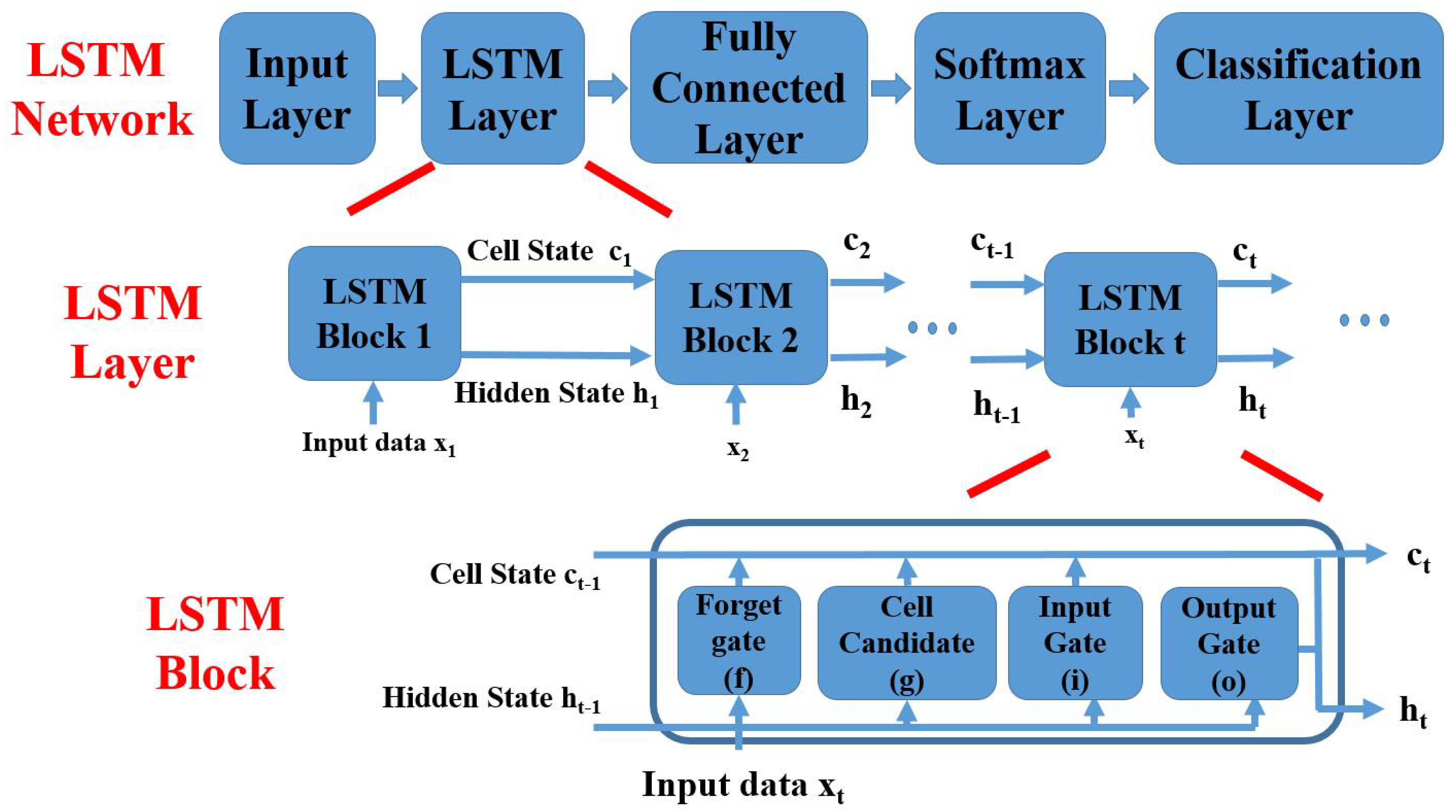
2. Related Work
3. Evaluation of Road Safety Predictions
4. The Proposed Method
4.1. Our Method for Richer Information With Feature Extraction
| Algorithm 1 Our Method for Richer Information with Feature Extraction |
| Input:n samples where |
| Output:n samples with time-series features, |
| Divide n samples into p periods, , by the recording time. |
| for do |
| for each sample do |
| end for |
| end for |
| for each sample do |
| and are the differences in the feature values of , for the latitude and the longitude respectively. |
| are the gradients of the feature values of related to the velocity, the mileage, |
| the tire pressure, the engine speed, and the engine temperature. |
| end for |
4.2. Weak Learners
4.3. Our Method with Boosting
| Algorithm 2 The Proposed Boosting Method |
| Input: Training data where , . |
| Output: Final strong classifier . |
| 1: Initialize weights for safe samples and unsafe samples, respectively, where c is the number of safe samples. |
| 2: for t = 1 to U do |
| 3: Normalize the weights, . |
| 4: Train all g weak classifiers, , using the training data D with our time-series features. |
| 5: Prediction using g classifiers, and is the classifier with the highest correctly rate a. |
| 6: Update the weights: , where , if the sample is correctly predicted, otherwise . |
| 7: end for |
| 8: The boosting classifier combines the U classifiers: if , , otherwise . |
5. Experiments
5.1. Evaluation Metrics
5.2. Experimental Setup
5.3. Safety Classification on the Warrigal Dataset
5.4. Safety Classification with Our Dataset
5.5. Further Evaluation
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tison, J.; Chaudhary, N.; Cosgrove, L.; Group, P.R. National Phone Survey on Distracted Driving Attitudes and Behaviors; Technical Report; United States National Highway Traffic Safety Administration: Washington, DC, USA, 2011.
- Wilson, F.A.; Stimpson, J.P. Trends in fatalities from distracted driving in the United States, 1999 to 2008. Am. J. Public Health 2010, 100, 2213–2219. [Google Scholar] [CrossRef] [PubMed]
- WHO. Global Status Report on Road Safety 2018; World Health Organization: Geneva, Switzerland, 2018. [Google Scholar]
- Kaplan, S.; Guvensan, M.A.; Yavuz, A.G.; Karalurt, Y. Driver behavior analysis for safe driving: A survey. IEEE Trans. Intell. Transp. Syst. 2015, 16, 3017–3032. [Google Scholar] [CrossRef]
- Hallac, D.; Sharang, A.; Stahlmann, R.; Lamprecht, A.; Huber, M.; Roehder, M.; Sosic, R.; Leskovec, J. Driver identification using automobile sensor data from a single turn. In Proceedings of the IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 953–958. [Google Scholar]
- Moll, O.; Zalewski, A.; Pillai, S.; Madden, S.; Stonebraker, M.; Gadepally, V. Exploring big volume sensor data with Vroom. Proc. VLDB Endow. 2017, 10, 1973–1976. [Google Scholar] [CrossRef]
- Massaro, E.; Ahn, C.; Ratti, C.; Santi, P.; Stahlmann, R.; Lamprecht, A.; Roehder, M.; Huber, M. The car as an ambient sensing platform [point of view]. Proc. IEEE 2016, 105, 3–7. [Google Scholar] [CrossRef] [Green Version]
- Van Ly, M.; Martin, S.; Trivedi, M.M. Driver classification and driving style recognition using inertial sensors. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Gold Coast, QLD, Australia, 23–26 June 2013; pp. 1040–1045. [Google Scholar]
- Paefgen, J.; Staake, T.; Thiesse, F. Evaluation and aggregation of pay-as-you-drive insurance rate factors: A classification analysis approach. Decis. Support Syst. 2013, 56, 192–201. [Google Scholar] [CrossRef]
- Vaitkus, V.; Lengvenis, P.; Žylius, G. Driving style classification using long-term accelerometer information. In Proceedings of the 19th International Conference on Methods and Models in Automation and Robotics (MMAR), Miedzyzdroje, Poland, 2–5 September 2014; pp. 641–644. [Google Scholar]
- Mudgal, A.; Hallmark, S.; Carriquiry, A.; Gkritza, K. Driving behavior at a roundabout: A hierarchical Bayesian regression analysis. Transp. Res. Part D Transp. Environ. 2014, 26, 20–26. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, Z.; Li, F.; Xie, C.; Ren, T.; Chen, J.; Liu, L. A deep learning framework for driving behavior identification on in-vehicle CAN-BUS sensor data. Sensors 2019, 19, 1356. [Google Scholar] [CrossRef] [Green Version]
- Ontanón, S.; Lee, Y.C.; Snodgrass, S.; Winston, F.K.; Gonzalez, A.J. Learning to predict driver behavior from observation. In Proceedings of the AAAI Spring Symposium Series, Palo Alto, CA, USA, 27–29 March 2017. [Google Scholar]
- Song, H.M.; Woo, J.; Kim, H.K. In-vehicle network intrusion detection using deep convolutional neural network. Veh. Commun. 2020, 21, 100198. [Google Scholar] [CrossRef]
- Zhou, A.; Li, Z.; Shen, Y. Anomaly Detection of CAN Bus Messages Using a Deep Neural Network for Autonomous Vehicles. Appl. Sci. 2019, 9, 3174. [Google Scholar] [CrossRef] [Green Version]
- Chockalingam, V.; Larson, I.; Lin, D.; Nofzinger, S. Detecting attacks on the can protocol with machine learning. Annu. EECS 2016, 588, 7. [Google Scholar]
- Narayanan, S.N.; Mittal, S.; Joshi, A. Using data analytics to detect anomalous states in vehicles. arXiv 2015, arXiv:1512.08048. [Google Scholar]
- Kiencke, U.; Dais, S.; Litschel, M. Automotive serial controller area network. In SAE Transactions; SAE International: Warrendale, PA, USA, 1986; pp. 823–828. [Google Scholar]
- Building Adapter for Vehicle On-board Diagnostic. Available online: obddiag.net (accessed on 9 September 2009).
- Lebrun, A.; Demay, J.C. Canspy: A Platform for Auditing CAN Devices. Available online: https://jyx.jyu.fi/bitstream/handle/123456789/67095 (accessed on 9 September 2016).
- Paefgen, J.; Michahelles, F.; Staake, T. GPS trajectory feature extraction for driver risk profiling. In Proceedings of the 2011 International Workshop on Trajectory Data Mining and Analysis, Beijing, China, 17–21 September 2011; pp. 53–56. [Google Scholar]
- Grengs, J.; Wang, X.; Kostyniuk, L. Using GPS data to understand driving behavior. J. Urban Technol. 2008, 15, 33–53. [Google Scholar] [CrossRef]
- Wang, W.; Xi, J.; Chen, H. Modeling and recognizing driver behavior based on driving data: A survey. Math. Probl. Eng. 2014, 2014, 20. [Google Scholar] [CrossRef] [Green Version]
- Enev, M.; Takakuwa, A.; Koscher, K.; Kohno, T. Automobile driver fingerprinting. Proc. Privacy Enhanc. Technol. 2016, 2016, 34–50. [Google Scholar] [CrossRef] [Green Version]
- Martínez, M.; Echanobe, J.; del Campo, I. Driver identification and impostor detection based on driving behavior signals. In Proceedings of the IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 372–378. [Google Scholar]
- Fung, N.C.; Wallace, B.; Chan, A.D.; Goubran, R.; Porter, M.M.; Marshall, S.; Knoefel, F. Driver identification using vehicle acceleration and deceleration events from naturalistic driving of older drivers. In Proceedings of the IEEE International Symposium on Medical Measurements and Applications (MeMeA), Rochester, MN, USA, 7–10 May 2017; pp. 33–38. [Google Scholar]
- Ezzini, S.; Berrada, I.; Ghogho, M. Who is behind the wheel? Driver identification and fingerprinting. J. Big Data 2018, 5, 9. [Google Scholar] [CrossRef]
- Martinelli, F.; Mercaldo, F.; Orlando, A.; Nardone, V.; Santone, A.; Sangaiah, A.K. Human behavior characterization for driving style recognition in vehicle system. Comp. Electr. Eng. 2018, 83, 102504. [Google Scholar] [CrossRef]
- Luo, S.; Leung, A.P.; Hui, C.; Li, K. An investigation on the factors affecting machine learning classifications in gamma-ray astronomy. Mon. Not. R. Astronom. Soc. 2020, 492, 5377–5390. [Google Scholar] [CrossRef] [Green Version]
- Luo, S.; Xu, J.; Jiang, Z.; Liu, L.; Wu, Q.; Leung, E.L.H.; Leung, A.P. Artificial intelligence-based collaborative filtering method with ensemble learning for personalized lung cancer medicine without genetic sequencing. Pharmacol. Res. 2020, 160, 105037. [Google Scholar] [CrossRef]
- McCall, J.C.; Trivedi, M.M. Driver behavior and situation aware brake assistance for intelligent vehicles. Proc. IEEE 2007, 95, 374–387. [Google Scholar] [CrossRef]
- Lin, X.; Liang, Y.; Wan, J.; Lin, C.; Li, S.Z. Region-based Context Enhanced Network for Robust Multiple Face Alignment. IEEE Trans. Multimed. 2019, 21, 3053–3067. [Google Scholar] [CrossRef]
- Lin, X.; Wan, J.; Xie, Y.; Zhang, S.; Lin, C.; Liang, Y.; Guo, G.; Li, S. Task-Oriented Feature-Fused Network With Multivariate Dataset for Joint Face Analysis. IEEE Trans. Cybern. 2019, 50, 1292–1305. [Google Scholar] [CrossRef] [PubMed]
- Sainath, T.N.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, long short-term memory, fully connected deep neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, QLD, Australia, 19–25 April 2015; pp. 4580–4584. [Google Scholar]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory recurrent neural network architectures for large scale acoustic modeling. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Wollmer, M.; Blaschke, C.; Schindl, T.; Schuller, B.; Farber, B.; Mayer, S.; Trefflich, B. Online driver distraction detection using long short-term memory. IEEE Trans. Intell. Transp. Syst. 2011, 12, 574–582. [Google Scholar] [CrossRef] [Green Version]
- Sesmero, M.P.; Ledezma, A.I.; Sanchis, A. Generating ensembles of heterogeneous classifiers using stacked generalization. Wiley Interdiscip. Rev. Data Mining Knowl. Discov. 2015, 5, 21–34. [Google Scholar] [CrossRef]
- Polikar, R. Ensemble based systems in decision making. IEEE Circuits Syst. Mag. 2006, 6, 21–45. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble methods in machine learning. In International Workshop on Multiple Classifier Systems; Springer: Cham, Switzerland, 2000; pp. 1–15. [Google Scholar]
- Hansun, S. A new approach of moving average method in time series analysis. In Proceedings of the Conference on New Media Studies (CoNMedia), Tangerang, Indonesia, 27–28 November 2013; pp. 1–4. [Google Scholar]
- Ehlers, J. FRAMA–Fractal Adaptive Moving Average. Tech. Anal. Stock. Commod. 2005, 23, 81–82. [Google Scholar]
- Johnston, F.; Boyland, J.; Meadows, M.; Shale, E. Some properties of a simple moving average when applied to forecasting a time series. J. Oper. Res. Soc. 1999, 50, 1267–1271. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Genuer, R.; Poggi, J.M.; Tuleau-Malot, C. Variable selection using random forests. Pattern Recognit. Lett. 2010, 31, 2225–2236. [Google Scholar] [CrossRef] [Green Version]
- Strobl, C.; Boulesteix, A.L.; Kneib, T.; Augustin, T.; Zeileis, A. Conditional variable importance for random forests. BMC Bioinform. 2008, 9, 307. [Google Scholar] [CrossRef] [Green Version]
- John, G.H.; Kohavi, R.; Pfleger, K. Irrelevant features and the subset selection problem. In Machine Learning Proceedings 1994; Elsevier: Amsterdam, The Netherlands, 1994; pp. 121–129. [Google Scholar]
- Almuallim, H.; Dietterich, T.G. Learning with Many Irrelevant Features; AAAI: Palo Alto, CA, USA, 1991; Volume 91, pp. 547–552. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Shalev-Shwartz, S.; Singer, Y.; Srebro, N.; Cotter, A. Pegasos: Primal estimated sub-gradient solver for svm. Math. Program. 2011, 127, 3–30. [Google Scholar] [CrossRef]
- Weinberger, K.Q.; Saul, L.K. Distance metric learning for large margin nearest neighbor classification. J. Mach. Learn. Res. 2009, 10, 207–244. [Google Scholar]
- Ho, T.K. A data complexity analysis of comparative advantages of decision forest constructors. Pattern Anal. Appl. 2002, 5, 102–112. [Google Scholar] [CrossRef]
- Rennie, J.; Shih, L.; Teevan, J.; Karger, D. Tackling the poor assumptions of Naive Bayes classifiers. In Proceedings of the Twentieth International Conference on Machine Learning (ICML 2003), Washington, DC, USA, 21–24 August 2003. [Google Scholar]
- Guo, Y.; Hastie, T.; Tibshirani, R. Regularized linear discriminant analysis and its application in microarrays. Biostatistics 2006, 8, 86–100. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 September 2001; Volume 1, pp. 511–518. [Google Scholar]
- Ward, J.; Worrall, S.; Agamennoni, G.; Nebot, E. The warrigal dataset: Multi-vehicle trajectories and v2v communications. IEEE Intell. Transp. Syst. Mag. 2014, 6, 109–117. [Google Scholar] [CrossRef]
- Luo, S.; Leung, A.P.; Qiu, X. A Machine Learning Framework for Road Safety of Smart Public Transportation. In Proceedings of the International Joint Conferences on Artificial Intelligence (IJCAI) Workshops 2019, Macao, China, 10–16 August 2019. [Google Scholar]

{kind=link}
| Feature Name | Meaning | Used to Train our Method? |
|---|---|---|
| LOGID | Bus identifier | No |
| GPSDATE TIME | Time | No |
| VELOCITY | Instantaneous speed | Yes |
| MILEAGE | GPS mileage | Yes |
| TOTAL MILEAGE | Total mileage | Yes |
| FRONT PRESSURE | Front pressure | Yes |
| REAR PRESSURE | Rear pressure | Yes |
| ENGINESPEED | Engine speed | Yes |
| ENGINETEMP | Engine temperature | Yes |
| CARSWITCH | Switches of the bus | No |
| CARLIGHT STATE | Switches of light | No |
| CANALARM STATE | Switches of alarm | No |
| CREATETIME | Time | No |
| GPS VELOCITY | Instantaneous speed | Yes |
| DRIVERID | Driver identifier | No |
| LONGITUDE | Longitude | Yes |
| LATITUDE | Latitude | Yes |
| DIRECTION | Turn | Yes |
| STATIONID | Station identifier | No |
| ROUTEID | Route identifier | No |
| BUSSTATE | Bus status | No |
| ALARM STATE | Alarm light status | No |
| STATION MILEAGE | Mileage each station | Yes |
| UPDOWN | Up and down | No |
| Feature Name | Mean | Std. Dev. | Median |
|---|---|---|---|
| VELOCITY | 147.9 | 159.9 | 90 |
| MILEAGE | 65,220,323.4 | 12,868,396.8 | 77,710,500 |
| TOTAL MILEAGE | 66,584,813.3 | 15,653,632.7 | 81,771,740 |
| FRONT PRESSURE | 843.4 | 71.7 | 852 |
| REAR PRESSURE | 794.4 | 32.7 | 796 |
| ENGINESPEED | 976.5 | 342.6 | 803 |
| ENGINETEMP | 81.6 | 7.1 | 83 |
| GPS VELOCITY | 141.2 | 152.8 | 90 |
| LONGITUDE | 113.5 | 0.0066 | 113.5 |
| LATITUDE | 22.1 | 0.0195 | 22.1 |
| DIRECTION | 197.3 | 104.8 | 195 |
| STATION MILEAGE | 346.7 | 589.3 | 170 |
| Machine Learning Methods |
|---|
| Support Vector Machine (SVM) |
| k Nearest Neighbour (KNN) |
| Random Forest (RF) |
| Naive Bayes |
| Discriminant Analysis |
| Adaptive Boosting (AdaBoost) |
| Long Short-Term Memory (LSTM) |
| Components | Purposes |
|---|---|
| Input gate | Preprocess the input data |
| Output gate | Updata the output hidden state |
| Forget gate | Reset (forget) the input data |
| Cell candidate | Update the output cell state |
| Classifying the Warrigal Dataset WITHOUT Our Features | ||||||||
|---|---|---|---|---|---|---|---|---|
| Methods | 70% Percent Data for Training | 90% Percent Data for Training | ||||||
| Accu. (%) | AUC | Specificity | Sensitivity | Accu. (%) | AUC | Specificity | Sensitivity | |
| Our Method | 92.9 | 0.923 | 0.932 | 0.912 | 93.7 | 0.931 | 0.939 | 0.922 |
| AdaBoost | 79.5 | 0.761 | 0.832 | 0.608 | 83.5 | 0.798 | 0.871 | 0.652 |
| Simple Bayes | 77.3 | 0.742 | 0.825 | 0.513 | 80.1 | 0.764 | 0.857 | 0.522 |
| Discriminant Analysis | 77.1 | 0.728 | 0.815 | 0.551 | 82.5 | 0.776 | 0.869 | 0.607 |
| KNN | 83.2 | 0.733 | 0.873 | 0.628 | 84.3 | 0.745 | 0.886 | 0.628 |
| RF | 90.7 | 0.903 | 0.923 | 0.828 | 91.8 | 0.910 | 0.935 | 0.830 |
| SVM | 75.9 | 0.756 | 0.722 | 0.896 | 82.3 | 0.815 | 0.796 | 0.906 |
| LSTM | 91.4 | 0.818 | 0.938 | 0.791 | 92.6 | 0.822 | 0.951 | 0.801 |
| Classifying the Warrigal Dataset WITH Our Features | ||||||||
|---|---|---|---|---|---|---|---|---|
| Methods | 70% Percent Data for Training | 90% Percent Data for Training | ||||||
| Accu. (%) | AUC | Specificity | Sensitivity | Accu. (%) | AUC | Specificity | Sensitivity | |
| Our Method | 94.1 | 0.944 | 0.943 | 0.927 | 95.8 | 0.952 | 0.962 | 0.937 |
| AdaBoost | 80.7 | 0.781 | 0.833 | 0.674 | 84.3 | 0.820 | 0.868 | 0.718 |
| Simple Bayes | 80.2 | 0.759 | 0.828 | 0.669 | 82.7 | 0.804 | 0.858 | 0.672 |
| Discriminant Analysis | 79.5 | 0.776 | 0.814 | 0.697 | 82.9 | 0.808 | 0.848 | 0.731 |
| KNN | 83.5 | 0.751 | 0.854 | 0.737 | 87.4 | 0.782 | 0.898 | 0.752 |
| RF | 91.3 | 0.913 | 0.919 | 0.879 | 93.9 | 0.937 | 0.946 | 0.903 |
| SVM | 78.2 | 0.755 | 0.746 | 0.907 | 82.8 | 0.819 | 0.801 | 0.907 |
| LSTM | 92.7 | 0.825 | 0.941 | 0.853 | 94.8 | 0.901 | 0.961 | 0.883 |
| Classifying the New Real-World Dataset WITHOUT Our Features | ||||||||
|---|---|---|---|---|---|---|---|---|
| Methods | 70% Percent Data for Training | 90% Percent Data for Training | ||||||
| Accu. (%) | AUC | Specificity | Sensitivity | Accu. (%) | AUC | Specificity | Sensitivity | |
| Our Method | 91.2 | 0.870 | 0.921 | 0.838 | 92.9 | 0.881 | 0.940 | 0.844 |
| AdaBoost | 78.1 | 0.740 | 0.808 | 0.574 | 80.0 | 0.753 | 0.827 | 0.592 |
| Simple Bayes | 62.7 | 0.586 | 0.643 | 0.521 | 62.0 | 0.577 | 0.634 | 0.515 |
| Discriminant Analysis | 58.4 | 0.539 | 0.589 | 0.543 | 60.0 | 0.564 | 0.604 | 0.568 |
| KNN | 72.1 | 0.648 | 0.726 | 0.579 | 75.2 | 0.685 | 0.769 | 0.619 |
| RF | 89.7 | 0.816 | 0.924 | 0.696 | 91.2 | 0.804 | 0.936 | 0.727 |
| SVM | 57.7 | 0.558 | 0.532 | 0.852 | 61.1 | 0.598 | 0.567 | 0.873 |
| LSTM | 77.3 | 0.757 | 0.786 | 0.676 | 85.2 | 0.790 | 0.873 | 0.694 |
| Classifying the New Real-World Dataset WITH Our Features | ||||||||
|---|---|---|---|---|---|---|---|---|
| Methods | 70% Percent Data for Training | 90% Percent Data for Training | ||||||
| Accu. (%) | AUC | Specificity | Sensitivity | Accu. (%) | AUC | Specificity | Sensitivity | |
| Our Method | 95.6 | 0.947 | 0.960 | 0.921 | 96.7 | 0.969 | 0.968 | 0.957 |
| AdaBoost | 83.7 | 0.781 | 0.857 | 0.685 | 85.1 | 0.802 | 0.867 | 0.731 |
| Simple Bayes | 66.8 | 0.651 | 0.674 | 0.622 | 72.1 | 0.702 | 0.724 | 0.692 |
| Discriminant Analysis | 77.8 | 0.698 | 0.794 | 0.651 | 80.1 | 0.732 | 0.816 | 0.686 |
| KNN | 77.2 | 0.716 | 0.789 | 0.640 | 77.6 | 0.727 | 0.790 | 0.669 |
| RF | 93.9 | 0.903 | 0.958 | 0.790 | 94.1 | 0.904 | 0.956 | 0.827 |
| SVM | 77.9 | 0.689 | 0.753 | 0.857 | 80.4 | 0.732 | 0.781 | 0.881 |
| LSTM | 75.1 | 0.734 | 0.765 | 0.642 | 80.3 | 0.767 | 0.820 | 0.675 |
| On Our Real-World Dataset | ||
|---|---|---|
| Methods | With Our Features | Without Our Features |
| Our Method | 86.4% | 68.7% |
| AdaBoost | 69.3% | 66.4% |
| Simple Bayes | 69.4% | 59.9% |
| Discriminant Analysis | 62.3% | 58.7% |
| KNN | 71.9% | 56.9% |
| RF | 65.6% | 61.1% |
| SVM | 84.1% | 62.0% |
| LSTM | 82.3% | 63.9% |
| On Our New Dataset | On the Warrigal Dataset | |||||||
|---|---|---|---|---|---|---|---|---|
| With Our Features | Without Our Features | With Our Features | Without Our Features | |||||
| Scales of Training Set | 70% | 90% | 70% | 90% | 70% | 90% | 70% | 90% |
| Our Method | 12.8 | 17.4 | 7.5 | 10.6 | 42.1k | 62.9k | 21.7k | 34.5k |
| AdaBoost | 2.7 | 3.3 | 1.9 | 2.2 | 13.3k | 17.2k | 9.72k | 14.5k |
| Simple Bayes | 0.11 | 0.13 | 0.04 | 0.05 | 6.6k | 8.3k | 4.52k | 6.1k |
| Discriminant Analysis | 0.08 | 0.10 | 0.04 | 0.07 | 1.7k | 2.1k | 1.1k | 1.5k |
| KNN | 0.07 | 0.12 | 0.06 | 0.08 | 5.4k | 7.2k | 3.2k | 5.1k |
| RF | 0.35 | 0.49 | 0.31 | 0.35 | 2.9k | 3.6k | 2.1k | 2.4k |
| SVM | 2.1 | 2.8 | 1.5 | 2.6 | 12.6k | 15.4k | 8.7k | 12.5k |
| LSTM | 1.9 | 2.3 | 1.6 | 2.0 | 11.7k | 14.2k | 7.1k | 10.5k |
| Values of U | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|
| Methods Trained with 70% Examples | 91.2% | 93.5% | 93.9% | 94.1% | 94.0% |
| Methods Trained with 90% Examples | 92.7% | 93.9% | 95.6% | 95.8% | 95.2% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, S.; Leung, A.P.; Qiu, X.; Chan, J.Y.K.; Huang, H. Complementary Deep and Shallow Learning with Boosting for Public Transportation Safety. Sensors 2020, 20, 4671. https://doi.org/10.3390/s20174671
Luo S, Leung AP, Qiu X, Chan JYK, Huang H. Complementary Deep and Shallow Learning with Boosting for Public Transportation Safety. Sensors. 2020; 20(17):4671. https://doi.org/10.3390/s20174671
Chicago/Turabian StyleLuo, Shengda, Alex Po Leung, Xingzhao Qiu, Jan Y. K. Chan, and Haozhi Huang. 2020. "Complementary Deep and Shallow Learning with Boosting for Public Transportation Safety" Sensors 20, no. 17: 4671. https://doi.org/10.3390/s20174671