Proposal-Based Visual Tracking Using Spatial Cascaded Transformed Region Proposal Network


Abstract
:1. Introduction
2. Related Work
2.1. Deep Tracking
2.2. Tracking through Region Proposal Networks
2.3. Tracking though Multiple Features Fusion
2.4. Loss Function Variation for Data Imbalance
2.5. Our Approach
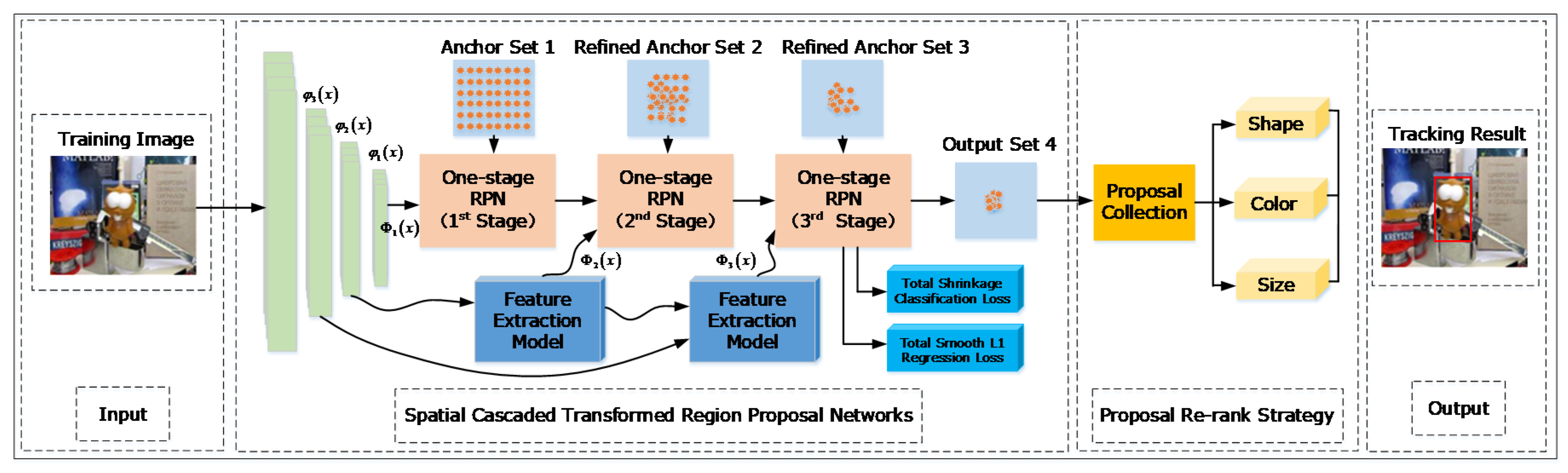
3. Proposed Method
3.1. Spatial Cascaded Region Proposal Networks
3.1.1. One-Stage Region Proposal Network
3.1.2. The Proposed Networks
3.2. Feature Extraction Model(FEM) though Spatial Transformer Network (STN)
3.3. Learning with Shrinkage Loss
3.4. Proposals Ranking Strategy
4. Experimental Results and Analysis
4.1. Training Dataset and Evaluation
| Algorithm 1 Proposed Tracking Method. |
| Input: Given sequences ; Groundtruth boundingbox of first frame named ; The trained model SCTRPN; Output: Tracking results ; Initialize anchors ; For to do Extract features for from SCTRPN; For to do If equals to 1 then ; Else ; End Calculate the classification score and regression offset using Equation (3); Coarse refining the anchor from using Equation (6); Fine re-ranking the proposal candidates using multi-cues re-ranking strategy in Equation (13); End Select the best proposal as tracking result by the selection strategies in [22]; End |
4.2. Implementation Details
4.3. Relablity Ablation Study
4.4. Comparison with State-of-the-Art Methods
4.5. Hyper Parameters Selection
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Müller, M.; Smith, N. A benchmark and simulator for uav tracking. In Proceedings of the IEEE European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 445–461. [Google Scholar]
- Ning, G.; Huang, H. LightTrack: A generic framework for online top-down human pose tracking. arXiv 2019, arXiv:1905.02822. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Online object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, X.; Wang, M. Robust visual tracking based on adaptive convolutional features and offline siamese tracker. Sensors 2018, 187, 2359. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, Z.; Wu, J.; Wang, L. SRDT: A novel robust rgb-d tracker based on siamese region proposal network and depth information. Int. J. Pattern Recognit. Artif. Intell. 2019, 37, 437–452. [Google Scholar] [CrossRef]
- Gao, P.; Ma, Y.; Yuan, R. Learning cascaded siamese networks for high performance visual tracking. arXiv 2019, arXiv:1905.02857. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8971–8980. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B. Distractor-aware siamese networks for visual object tracking. arXiv 2018, arXiv:1808.06048. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q. SiamRPN++: Evolution of siamese visual tracking with very deep networks. arXiv 2018, arXiv:1812.11703. [Google Scholar]
- Zhang, H.; Ni, W.; Yan, W. Visual tracking using siamese convolutional neural network with region proposal and domain specific updating. Neurocomputing 2018, 275, 2645–2655. [Google Scholar] [CrossRef]
- Gidaris, S.; Komodakis, N. Object detection via a multi-region and semantic segmentation-aware CNN model. arXix 2015, arXiv:1505.01749. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. arXiv 2017, arXiv:1712.00726. [Google Scholar]
- Smeulders, A.W.; Chu, D.M.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, M. Visual tracking: An experimental survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1442–1468. [Google Scholar] [PubMed] [Green Version]
- Li, P.; Wang, D.; Wang, L.; Lu, H. Deep visual tracking: Review and experimental comparison. Pattern Recognit. 2018, 76, 323–338. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Doha, Qatar, 12–15 November 2012; pp. 1097–1105. [Google Scholar]
- Wang, L.; Ouyang, W.; Wang, X. Visual tracking with fully convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1093–1112. [Google Scholar]
- Danelljan, M.; Robinson, A.; Khan, F. Beyond correlation filters: Learning continuous convolution operators for visual tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 472–488. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F. ECO: Efficient convolution operators for tracking. arXiv 2016, arXiv:1611.09224. [Google Scholar]
- Song, Y.; Ma, C.; Wu, X. VITAL: Visual tracking via adversarial learning. arXiv 2018, arXiv:1804.04273. [Google Scholar]
- Fiaz, M.; Mahmood, A.; Jung, S.K. Learning soft mask based feature fusion with channel and spatial attention for robust visual object tracking. Sensors 2020, 20, 4021. [Google Scholar] [CrossRef]
- Gordon, D.; Farhadi, A.; Fox, D. Re 3: Real-time recurrent regression networks for visual tracking of generic objects. IEEE Robot. Autom. Lett. 2018, 3, 788–795. [Google Scholar] [CrossRef] [Green Version]
- Guo, Q.; Feng, W.; Zhou, C.; Huang, R.; Wan, L.; Wang, S. Learning dynamic siamese network for visual object tracking. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1763–1771. [Google Scholar]
- Ren, S.; He, K.; Girshick, R. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Yang, K.; Song, H.; Zhang, K. Hierarchical attentive Siamese network for real-time visual tracking. Neural Comput. Appl. 2019, 2, 342–356. [Google Scholar] [CrossRef]
- Ma, C.; Huang, J.; Yang, X. Hierarchical convolutional features for visual tracking. IEEE Trans. Image Process. 2015, 25, 1834–1848. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F. Convolutional features for correlation filter based visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 763–772. [Google Scholar]
- Huang, C.; Li, Y.; Loy, C.; Tang, X. Learning deep representation for imbalanced classification. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5375–5384. [Google Scholar]
- Khan, S.H.; Hayat, M.; Bennamoun, M.; Sohel, F.; Togneri, R. Cost-sensitive learning of deep feature representations from imbalanced data. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3573–3587. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 850–865. [Google Scholar]
- Li, H.; Li, Y.; Porikli, F. Robust online visual tracking with a single convolutional neural network. In Proceedings of the IEEE Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 1392–1403. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. arXiv 2015, arXiv:1506.02025. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollr, P. Focal loss for dense object detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Karamikabir, H.; Afshari, M.; Arashi, M. Shrinkage estimation of non-negative mean vector with unknown covariance under balance loss. J. Inequalitiesappl. 2018, 1, 124–135. [Google Scholar] [CrossRef] [PubMed]
- Guo, G.; Huang, H.; Yan, Y.; Liao, H.; Li, B. A new target-specific object proposal generation method for visual tracking. IEEE Trans. Cybern. 2017, 2, 132–149. [Google Scholar]
- Kristan, M.; Leonardis, A.; Matas, J. The sixth visual object tracking vot2018 challenge results. In Proceedings of the European Conference on Computer Vision Workshop, Munich, Germany, 8–14 August 2018; pp. 1453–1484. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 4, 112–135. [Google Scholar] [CrossRef] [Green Version]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. Lasot: A high-quality benchmark for large-scale single object tracking. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2018; pp. 2012–2048. [Google Scholar]
- Müller, M.; Bibi, A.; Giancola, S.; Al-Subaihi, S.; Ghanem, B. Trackingnet: A large-scale dataset and benchmark for object tracking in the wild. arXiv 2018, arXiv:1803.10794. [Google Scholar]
- Vedaldi, A.; Lenc, K. Matconvnet: Convolutional neural networks for matlab. arXiv 2014, arXiv:1412.4564. [Google Scholar]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Xiao, Y.; Lu, C.; Tsougenis, E.; Lu, Y.; Tang, C. Complexity adaptive distance metric for object proposals generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 778–786. [Google Scholar]
- Chen, X.; Ma, H.; Wang, X.; Zhao, Z. Improving object proposals with multi-thresholding straddling expansion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2587–2595. [Google Scholar]
- Zitnick, C.; Dollar, P. Edge boxes: Locating object proposals from edges. In Proceedings of the IEEE European Conference on Computer Vision, Zurich, Switzerland, 5–12 September 2014; pp. 391–405. [Google Scholar]
- Uijlings, J.; Sande, K.; Gevers, T.; Smeulders, A. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | One Stage | Two Stages | Three Stages | One Stage without STN | Two Stages without STN | Three Stages without STN |
|---|---|---|---|---|---|---|
| Accuracy | 0.523 | 0.565 | 0.577 | 0.508 | 0.538 | 0.566 |
| Robustness | 1.23 | 1.02 | 0.97 | 1.34 | 1.19 | 1.04 |
| EAO | 0.321 | 0.352 | 0.361 | 0.314 | 0.342 | 0.349 |
| FPS | 45 | 30 | 22 | 54 | 36 | 25 |
| Methods | Number of Proposals | ||||
|---|---|---|---|---|---|
| 50 | 100 | 200 | 500 | 1000 | |
| CADM | 0325 | 0.436 | 0.574 | 0.706 | 0.735 |
| MSTE | 0.253 | 0.424 | 0.567 | 0.632 | 0.653 |
| EdgeBoxes | 0.603 | 0.743 | 0.813 | 0.924 | 0.929 |
| SelectiveSearch | 0.246 | 0.392 | 0.521 | 0.732 | 0.841 |
| SCTRPN | 0.921 | 0.932 | 0.953 | 0.983 | 0.991 |
| Tracker | SCTRPN | SCTRPN-No STN | MFT | LADCF | DRT | SiamRPN | DaSiamRPN |
|---|---|---|---|---|---|---|---|
| Accuracy | 0.583 | 0.564 | 0.525 | 0.503 | 0.519 | 0.586 | 0.569 |
| Robustness | 0.243 | 0.269 | 0.140 | 0.159 | 0.201 | 0.276 | 0.323 |
| EAO | 0.395 | 0.381 | 0.385 | 0.389 | 0.357 | 0.382 | 0.327 |
| AO | 0.478 | 0.453 | 0.393 | 0.421 | 0.426 | 0.462 | 0.439 |
| Tracker | SCTRPN | SCTRPN-No STN | ECO | MDNet | SiamFC | SiamRPN | DaSiamRPN |
|---|---|---|---|---|---|---|---|
| A(%) | 69.7 | 62.7 | 55.4 | 60.6 | 57.2 | 62.4 | 63.8 |
| P(%) | 66.4 | 59.4 | 49.3 | 56.8 | 53.6 | 58.4 | 59.2 |
| Pnorm(%) | 76.3 | 73.9 | 62.1 | 71.2 | 66.6 | 74.1 | 73.2 |
| EAO | 0.389 | 0.395 | 0.392 | 0.387 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Luo, S.; Fan, X. Proposal-Based Visual Tracking Using Spatial Cascaded Transformed Region Proposal Network. Sensors 2020, 20, 4810. https://doi.org/10.3390/s20174810
Zhang X, Luo S, Fan X. Proposal-Based Visual Tracking Using Spatial Cascaded Transformed Region Proposal Network. Sensors. 2020; 20(17):4810. https://doi.org/10.3390/s20174810
Chicago/Turabian StyleZhang, Ximing, Shujuan Luo, and Xuewu Fan. 2020. "Proposal-Based Visual Tracking Using Spatial Cascaded Transformed Region Proposal Network" Sensors 20, no. 17: 4810. https://doi.org/10.3390/s20174810