CNN Training with Twenty Samples for Crack Detection via Data Augmentation

Abstract
:1. Introduction
- By conducting experiments of various methods, the rotation method as a simple geometric transformation is found as the most effective data augmentation method in model training for crack detection.
- The data augmentation is also employed for the inference process, and the greedy algorithm is successively applied to search for effective strategies.
- A practical method for data augmentation comprises the two stages proposed for network training on a small dataset. When applying this method to train and deploy crack detectors, the recall of our best model reached 96% with only 20 images for training.
2. Related Work
3. Methodology
3.1. Stage One: Data Augmentation in the Network Training
- Horizontal and vertical stretch: stretch the images horizontally or vertically by a certain factor.
- Random crop: cut the images randomly according to the size of 655 × 655.
- Translation: shift the images 100 pixels in the X or Y direction.
- Rotation: rotate the images at an angle uniformly between 0° and 360°.
- Gamma transformation: correct the image with too high or too low gray, and enhance the contrast.
- Gaussian blur: reduce the difference of each pixel value to blur the image.
- Gaussian noise: add the noise whose probability density function follows Gaussian distribution.
- Salt and pepper noise: randomly add a white dot (255) or a black dot (0).
- Histogram equalization: enhance images contrast by adjusting image histogram.
3.2. Stage Two: Augmentation Strategy in the Inference Process
| Algorithm 1. Greedy Algorithm in Model Inference Process |
| Input: ; ; |
| Output: |
| For = 2; ≤ do |
| Compute all for in ; |
| Get that have ; |
| ; |
| ; |
| end |
| return ; |
4. Experiment Settings
4.1. Dataset
4.2. Architecture for Crack Detection
4.3. Training Settings
4.4. Evaluation Method
4.4.1. Evaluation Method of a Single Test Image
4.4.2. Evaluation Method for Inferencing Multiple Images
5. Results and Analysis
5.1. Stage One: Data Augmentation in the Network Training
5.1.1. Comparison of Data Augmentation Methods
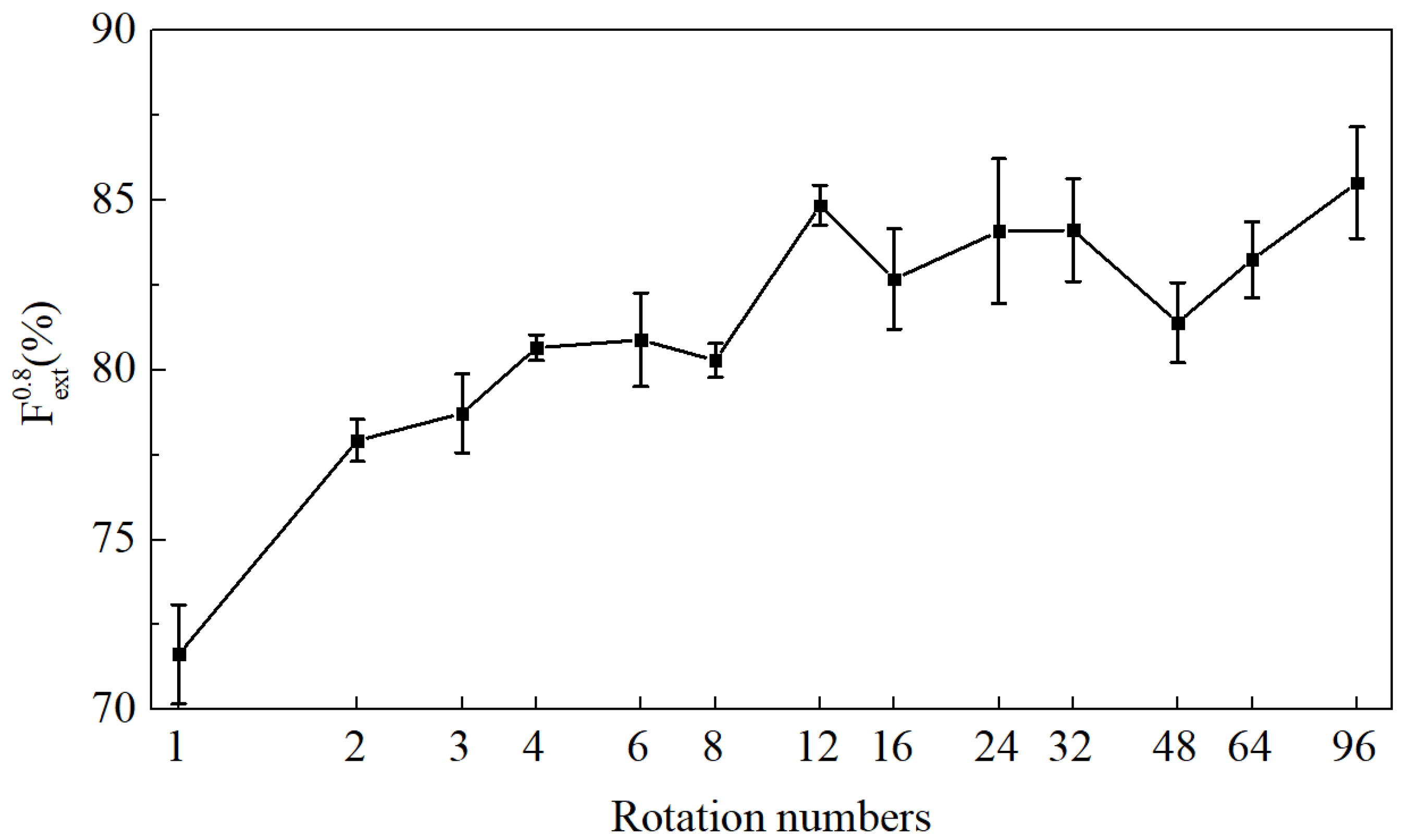
5.1.2. The Rotation Method for Data Augmentation
- a.
- Rotation for Augmenting Datasets of Different Size.
- b.
- Rotation with Different Augmentation Factors.
- c.
- Combining the Rotation with Other Methods.
- d.
- Rotation Alleviates the Over-Fitting.
5.2. Stage Two: Data Augmentation in the Inference Process
- (1)
- Rotation is still the most effective data augmentation method in the inference process, and rotations with different angles impact the model in slightly different manners.
- (2)
- Gaussian noise and salt and pepper noise are not good for improving the model in the inference process, and they even cause a negative influence in some cases.
- (3)
- When there is a stretch method in the constructed solutions, the model can gain little improvement by adding other stretch methods.
5.3. Two-Stage Method for Network Training within 20 Images
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kurata, M.; Kim, J.; Lynch, J.P.; Van der Linden, G.W.; Sedarat, H.; Thometz, E.; Hipley, P.; Sheng, L.H. Internet-Enabled Wireless Structural Monitoring Systems: Development and Permanent Deployment at the New Carquinez Suspension Bridge. J. Struct. Eng. 2013, 139, 1688–1702. [Google Scholar] [CrossRef] [Green Version]
- Eick, B.A.; Treece, Z.R.; Spencer, B.F.; Smith, M.D.; Sweeney, S.C.; Alexander, Q.G.; Foltz, S.D. Automated damage detection in miter gates of navigation locks. Struct. Control. Health Monit. 2018, 25, 18. [Google Scholar] [CrossRef]
- Nonis, C.; Niezrecki, C.; Yu, T.-Y.; Ahmed, S.; Su, C.-F.; Schmidt, T. Structural health monitoring of bridges using digital image correlation. In Proceedings of the Health Monitoring of Structural and Biological Systems 2013, San Diego, CA, USA, 11–14 March 2013; p. 869507. [Google Scholar]
- Ruggieri, S.; Porco, F.; Uva, G. A practical approach for estimating the floor deformability in existing RC buildings: Evaluation of the effects in the structural response and seismic fragility. Bull. Earthq. Eng. 2020, 18, 2083–2113. [Google Scholar] [CrossRef]
- Losada, M.; Irizar, A.; del Campo, P.; Ruiz, P.; Leventis, A. Design principles and challenges for an autonomous WSN for structural health monitoring in aircrafts. In Proceedings of the e2014 29th Conference on Design of Circuits and Integrated Systems, Madrid, Spain, 26–28 November 2014; pp. 1–6. [Google Scholar]
- Porco, F.; Ruggieri, S.; Uva, G. Seismic assessment of irregular existing building: Appraisal of the influence of compressive strength variation by means of nonlinear conventional and multimodal static analysis. Ing. Sismica 2018, 35, 64. [Google Scholar]
- Abdel-Qader, L.; Abudayyeh, O.; Kelly, M.E. Analysis of edge-detection techniques for crack identification in bridges. J. Comput. Civil. Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef]
- Huili, Z.; Guofeng, Q.; Xingjian, W. Improvement of Canny Algorithm Based on Pavement Edge Detection. In Proceedings of the 2010 3rd International Congress on Image and Signal Processing (CISP 2010), Yantai, China, 16–18 October 2010; pp. 964–967. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, L.; Chu, H.H.; Shi, P.; Wang, W.; Kong, X. Region-Based CNN Method with Deformable Modules for Visually Classifying Concrete Cracks. Appl. Sci. 2020, 10, 18. [Google Scholar] [CrossRef] [Green Version]
- Riid, A.; Louk, R.; Pihlak, R.; Tepljakov, A.; Vassiljeva, K. Pavement Distress Detection with Deep Learning Using the Orthoframes Acquired by a Mobile Mapping System. Appl. Sci. 2019, 9, 22. [Google Scholar] [CrossRef] [Green Version]
- Cha, Y.; Choi, W.; Buyukozturk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Li, H.; Wang, J.; Zhang, Y.; Wang, Z.; Wang, T. A Study on Evaluation Standard for Automatic Crack Detection Regard the Random Fractal. arXiv 2020, arXiv:2007.12082. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambrige, MA, USA, 2016; pp. 10–180. [Google Scholar]
- Harrington, P. Machine Learning in Action; Manning Publications Co.: Cambrige, MA, USA, 2012; pp. 8–120. [Google Scholar]
- Flusser, J.; Suk, T. Pattern recognition by affine moment invariants. Pattern. Recognit. 1993, 26, 167–174. [Google Scholar] [CrossRef]
- Dellana, R.; Roy, K. Data augmentation in CNN-based periocular authentication. In Proceedings of the 2016 6th International Conference on Information Communication and Management (ICICM), Hertfordshire, UK, 29–31 October 2016; pp. 141–145. [Google Scholar]
- Taylor, L.; Nitschke, G. Improving Deep Learning using Generic Data Augmentation. arXiv 2017, arXiv:1708.06020. [Google Scholar]
- Tao, X.; Wang, Z.; Zhang, Z.; Zhang, D.; Xu, D.; Gong, X.; Zhang, L. Wire Defect Recognition of Spring-Wire Socket Using Multitask Convolutional Neural Networks. IEEE Trans. Compon. Packag. Manuf. Technol. 2018, 8, 689–698. [Google Scholar] [CrossRef]
- Jungnickel, D. The Greedy Algorithm; Springer: Berlin, HD, Germany, 2013. [Google Scholar]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for small object detection. arXiv 2019, arXiv:1902.07296. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. Autoaugment: Learning augmentation strategies from data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 113–123. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Jiang, W.; Ying, N. Improve Object Detection by Data Enhancement based on Generative Adversarial Nets. arXiv 2019, arXiv:1903.01716. [Google Scholar]
- Antoniou, A.; Storkey, A.; Edwards, H. Data Augmentation Generative Adversarial Networks. arXiv 2018, arXiv:1711.04340. [Google Scholar]
- Ratner, A.J.; Ehrenberg, H.; Hussain, Z.; Dunnmon, J.; Ré, C. Learning to compose domain-specific transformations for data augmentation. In Proceedings of the Advances in Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 3236–3246. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2013, arXiv:1311.2524. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE International Conference On Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Xian, T.; Dapeng, Z.; Zihao, W.; Xilong, L.; Hongyan, Z.; De, X. Detection of Power Line Insulator Defects using Aerial Images Analyzed with Convolutional Neural Networks. IEEE Trans. Syst. Man. Cybern. 2020, 50, 1486–1498. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Case | (%) | Relative Change (%) | |
|---|---|---|---|---|
| Baseline | 71.63 ± 1.46 | |||
| Geometric transformation | Stretch | Horizontal | 71.52 ± 1.00 | −0.11 |
| Vertical | 74.66 ± 1.73 | +3.03 | ||
| Random crop | 72.24 ± 1.87 | +0.61 | ||
| Translation | 69.94 ± 1.80 | −1.69 | ||
| Rotation | 77.92 ± 0.63 | +6.29 | ||
| Photometric transformation | Gamma transformation | Slight | 71.91 ± 2.81 | +0.28 |
| Strong | 73.34 ± 0.98 | +1.71 | ||
| Gaussian blur | Slight | 66.84 ± 1.97 | −4.79 | |
| Strong | 66.04 ± 3.29 | −5.59 | ||
| Gaussian noise | Slight | 72.06 ± 1.49 | +0.43 | |
| Strong | 75.42 ± 1.06 | +3.79 | ||
| Salt and pepper noise | Slight | 75.34 ± 1.56 | +3.71 | |
| Strong | 71.82 ± 3.18 | +0.19 | ||
| Histogram equalization | 72.25 ± 1.92 | +0.62 |
| Method | (%) | Relative Changes (%) |
|---|---|---|
| Black | 78.40 ± 1.68 | 0 |
| White | 77.96 ± 2.36 | −0.44 |
| Replicating edge pixel | 78.72 ± 1.16 | +0.32 |
| Augmentation Method | (%) | Relative Changes (%) |
|---|---|---|
| Rotation | 85.50 ± 1.64 | 0 |
| Rotation + salt and pepper noise | 83.96 ± 0.27 | −1.54 |
| Rotation + Gaussian noise | 83.36 ± 1.07 | −2.14 |
| Rotation + stretch | 84.54 ± 0.35 | −0.96 |
| Rotation + salt and pepper noise + stretch | 83.79 ± 1.17 | −1.71 |
| Rotation + Gaussian noise + stretch | 82.94 ± 1.37 | −2.56 |
| Method | Case | Number |
|---|---|---|
| Rotation | Rotate 60° | 1 |
| Rotate 120° | 2 | |
| Rotate 180° | 3 | |
| Rotate 240° | 4 | |
| Rotate 300° | 5 | |
| Gaussian noise (m is the mean, σ is the standard deviation) | m = 0 σ = 10 | 6 |
| m = 0 σ = 20 | 7 | |
| m = 0 σ = 30 | 8 | |
| Salt and pepper noise (p is the probability of random salt and pepper noise) | p = 0.025 | 9 |
| p = 0.0375 | 10 | |
| p = 0.05 | 11 | |
| Vertical Stretch | Stretch 1.25 times | 12 |
| Stretch 1.5 times | 13 | |
| Stretch 1.75 times | 14 | |
| Stretch 2 times | 15 |
| Rounds of the Greedy Algorithm | Specific Strategies | (%) |
|---|---|---|
| 1 | No augmentation | 85.50 |
| 2 | Rotate 240° | 88.81 |
| 3 | Rotate 240°, stretch 1.5 times | 89.69 |
| 4 | Rotate 240°, 60°, respectively, stretch 1.5 times | 90.28 |
| 5 | Rotate 240°, 60°, 180°, respectively, stretch 1.5 times | 90.81 |
| 6 | Rotate 240°, 60°, 180°, 300°, respectively, stretch 1.5 times | 91.18 |
| Method | Number of Training Set | (%) | XR(%) |
|---|---|---|---|
| Li’s paper | 320 | 91.64 | 93.6 |
| No augmentation (ours) | 20 | 71.63 | 69.16 |
| First-stage method (ours) | 20 | 85.50 | 88.91 |
| Two-stage method (ours) | 20 | 91.18 | 96 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Yang, J.; Jiang, H.; Fan, X. CNN Training with Twenty Samples for Crack Detection via Data Augmentation. Sensors 2020, 20, 4849. https://doi.org/10.3390/s20174849
Wang Z, Yang J, Jiang H, Fan X. CNN Training with Twenty Samples for Crack Detection via Data Augmentation. Sensors. 2020; 20(17):4849. https://doi.org/10.3390/s20174849
Chicago/Turabian StyleWang, Zirui, Jingjing Yang, Haonan Jiang, and Xueling Fan. 2020. "CNN Training with Twenty Samples for Crack Detection via Data Augmentation" Sensors 20, no. 17: 4849. https://doi.org/10.3390/s20174849