1. Introduction
Vision-based action recognition is an important research topic in the domain of human action recognition. Many action recognition studies have adopted vision sensors because of the rich information they provide, despite their limited field of view and sensitivity to lighting changes [
1]. Recent advances in artificial intelligence technology and vision sensors have promoted vision-based action recognition for various applications, such as education [
2], entertainment [
3,
4], and sports [
5,
6,
7,
8,
9,
10,
11,
12]. Various studies have proposed novel algorithms [
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23] or established datasets [
1,
24,
25,
26,
27] for vision-based action recognition.
Sports is one sector with significant adoption of vision-based action recognition. Several action recognition algorithms have been proposed for sports, including soccer [
5], golf [
6,
7], tennis [
8,
9,
10], table tennis [
11], and baseball [
12]. Vision-based action recognition systems have been applied to provide quantitative scoring standards or systems to assist referees. However, relatively few studies have investigated the application of vision-based action recognition to martial arts. The actions of martial arts are significantly more rapid than normal movements, which complicates the acquisition of continuous actions with sufficient clarity and without the loss of inter-frames. In addition, martial arts poses require rapid posture changes and an extreme range of action, which complicates the application of existing human action databases and software libraries developed for normal actions [
28]. Many studies have used skeleton data obtained with RGB-D sensors for action recognition [
16,
19,
20,
21,
22,
23,
29,
30]. Such skeleton data provide information on the locations of joints over time, which can be utilized for action recognition [
29]. In the literature, skeleton data have been combined with machine learning algorithms such as the convolutional neural network (CNN) [
16,
19,
21,
22,
23] or recurrent neural network [
29,
30] for human action recognition. However, using such data for martial arts with a wide range of movements, and extreme and rapid actions is difficult because the RGB-D sensors have low skeleton extraction accuracy for those actions [
31,
32]. Several studies on action recognition for martial arts have sought to address these challenges. Zang et al. [
32] and Soomro et al. [
33,
34] proposed action recognition methods that can be applied to martial arts as well as general sports and routine movements, and Heinz et al. [
35] attached sensors to users for kung fu action recognition. Salazar et al. [
36] proposed using Kinect to automate the evaluation process of martial arts forms, and Stasinopoulos and Maragos [
37] proposed an algorithm based on the historiographic method and hidden Markov model for martial arts action recognition from videos. However, while studies focused on typical human action recognition could leverage various action datasets and recognition algorithms, previous studies on martial arts action recognition had no public datasets and recognition algorithms specific to martial arts that were available to them.
Taekwondo is an official Olympic sport consisting of two major categories: gyeorugi and poomsae. Gyeorugi is a type of full-contact sparring between opponents that uses a quantitative and accurate electronic scoring system to facilitate objective judgment. In contrast, poomsae is a form competition where a single competitor arranges basic attack and defense techniques in a certain order. Unlike gyeorugi, which has quantitative and accurate scoring, poomsae is scored by judges. Except for certain penalties such as timeouts and borderline violations, the judging is subjective and qualitative. In addition, situational constraints mean that judges must often evaluate multiple competitors simultaneously. Therefore, issues have arisen over scoring fairness and consistency for poomsae, not only in competitive events but also in promotion examinations.
Several studies have focused on vision-based action recognition for taekwondo. De Goma et al. [
28] proposed a taekwondo kick detection algorithm with skeleton data preprocessing. Choi et al. [
38] proposed a system for remotely scoring poomsae by comparing actions acquired from multiple vision sensors with corresponding reference actions. Seo et al. [
39] suggested a Poisson distribution-based recognition algorithm that uses one-dimensional spatial information extracted from image sequences as its input. Kong et al. [
40] extracted taekwondo actions from a broadcast competition video and classified them with high accuracy by applying a support vector machine and defining a taekwondo action as a set of poses. However, these studies had limitations such as low accuracy despite a complex recognition system [
38], restricted applicability arising from limited movements [
28], and vulnerability to the movement of subjects because of the exclusive use of histogram images [
39]. Despite a high recognition accuracy rate, Kong et al.’s method [
40] requires two training and recognition models each for a single frame and action classification process, and the pose order needs to be defined for all action classes. This results in unique actions that greatly influence the behavior definition. Thus, if an action is performed in a different pose order (e.g., a transitional action), the recognition accuracy can decrease [
40]. Furthermore, the task of labeling 16 poses requires a significant amount of time and resources.
To address these problems, a simpler system, dataset optimized for taekwondo, and method to minimize manual intervention in the action recognition process are required. In this study, the Taekwondo Unit technique Human Action Dataset (TUHAD see
Supplementary Materials) was compiled for taekwondo action recognition, and a key frame-based action recognition algorithm was proposed. The proposed algorithm was validated through an accuracy analysis for various input configurations. The main contributions of this study are as follows:
TUHAD was constructed for application to taekwondo action recognition, and it includes the representative unit techniques of taekwondo. All actions were performed by taekwondo experts and were collected in a controlled environment for high reliability.
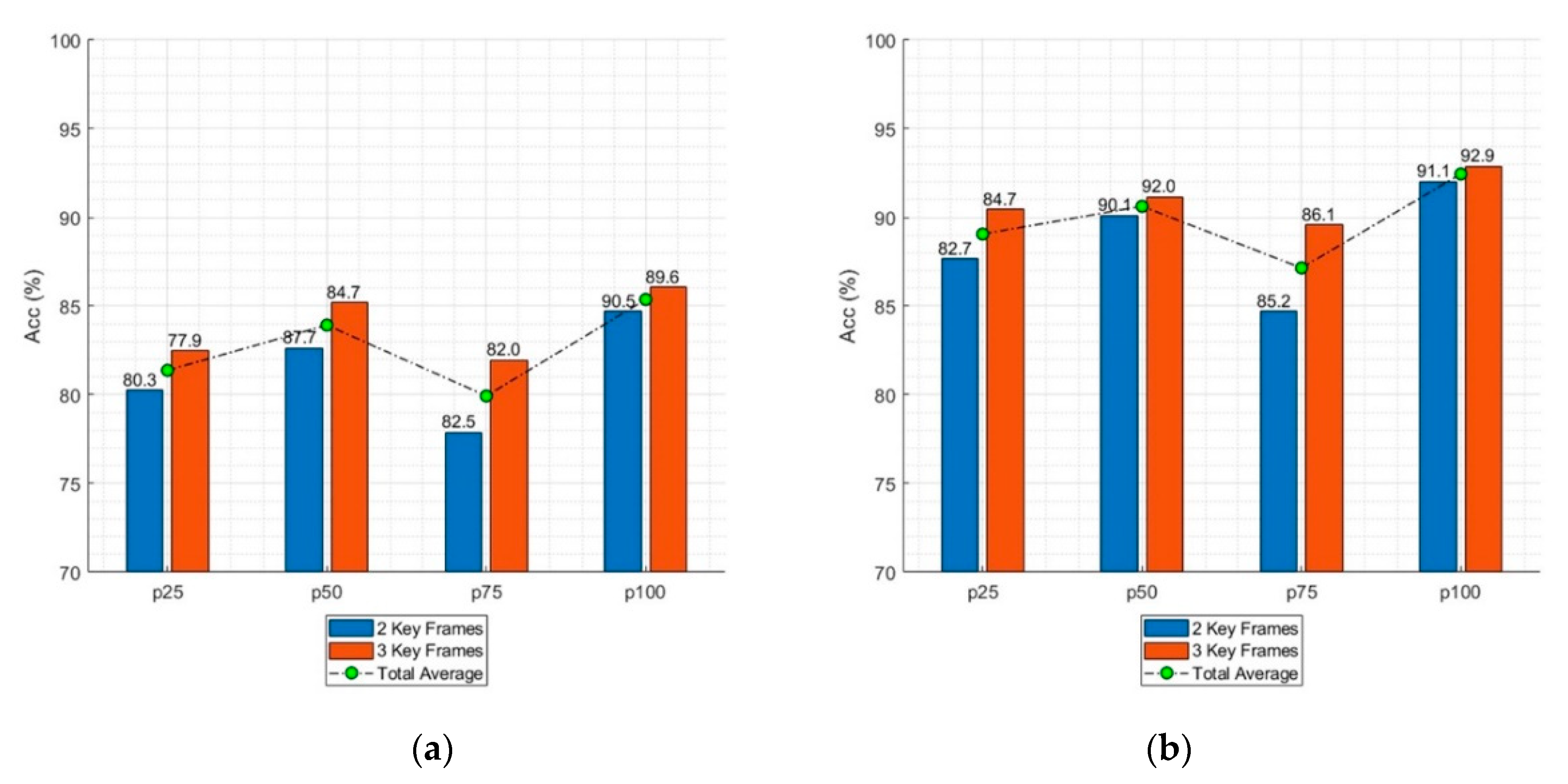
A key frame-based CNN architecture was developed for taekwondo action recognition. The accuracy of the proposed model was analyzed according to various input configurations regarding the image modality, key frame position, camera view, and target action to determine the optimal settings for data gathering and action recognition based on taekwondo-specific characteristics.
5. Conclusions
In this study, TUHAD was established to provide data for accurate vision-based action recognition of taekwondo. TUHAD contains 1936 samples representing eight fundamental unit techniques performed by 10 taekwondo experts who were recorded from two camera views. A key frame-based CNN classifier was developed, and the recognition accuracy was analyzed according to the image modality, key frame, and camera view. The results demonstrated that the CNN classifier achieved a recognition accuracy of up to 95.833%. TUHAD and the proposed classifier can contribute to advancing research regarding taekwondo action recognition, and the results on the optimal image capture setup can have broader applicability. For example, this information may also be applicable to other situations entailing the recognition of rapid actions outside the range of normal human movements. However, a critical prerequisite for applying the proposed method to action recognition is that the beginning and ending frames of the action (i.e., action detection) should be given prior to action classification. This will be explored in following research papers. TUHAD will be expanded to include more unit techniques as well as combinations of various unit techniques to recognize more complex and diverse taekwondo actions. In addition, more advanced action recognition and detection algorithms, such as trajectory-based and multi-view conditions, will be investigated.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}