1. Introduction
AIS data provide real-time trajectory data which can be used to monitor ship’s navigation status and trigger alert mechanisms for ship collision avoidance, maritime monitoring, trajectory clustering, ship traffic flow predicting, and maritime accident investigations [
1]. The most basic information from AIS data gives spatiotemporal data composed of time and location, which is usually plotted on an electronic chart that can then form a ship trajectory.
In sea areas or ports with high traffic density and complicated conditions, a key issue is to improve the safety of ships sailing at sea. Vessel Traffic Service (VTS), whose objective is to accurately and effectively monitor and predict ship trajectories and real-time ship trajectories, provides a valuable technical support for early warning of marine traffic accidents [
2]. To improve the safety of ships sailing in the environment of complex and changeable seas, it is necessary to provide trajectory prediction and danger warning functions to a ship’s intelligent navigation system. However, the maritime navigation environment is prone to many incidents, especially in crowded port waters, and it is not easy to predict moving targets.
In a related work, a Bayesian probability trajectory prediction model based on a Gaussian process is introduced. A K-order multivariate Markov chain is applied to establish a state transition matrix to train a large amount of data and support short-term prediction of ship positions, but this approach is still sensitive to previous ship positions this resulting in low accuracy [
3]. A single ship neighborhood approach based on historical data has also been suggested. The search algorithm can support short-term prediction, but it cannot deal with the branch trajectory problem [
4].
The research presented in this paper introduces a deep learning theoretical framework and a Gate Recurrent Unit (GRU) model to predict vessel trajectories. The approach is based on an integration, clustering, and correction of maritime navigation trajectories. A recurrent neural network is applied to predict and train real-time ship trajectories. Ground truth data from AIS raw data in the port of Zhangzhou, China were used to train and verify the validity of the proposed model. Further comparison was made with the Long Short-Term Memory (LSTM) network that has been widely used in the field of deep learning. The rest of the paper is organized as follows.
Section 2 briefly introduces related work and the motivation of our work.
Section 3 develops the main principles behind our data preparation approach.
Section 4 presents the GRU model.
Section 5 reports on the experiments.
Section 6 concludes the paper and outlines further work.
2. Related Work
Trajectory prediction methods based on statistical methods are commonly used in the ship field, including Gaussian process regression models, which are the most common. Anderson [
5] took time as the independent variable, obtained the measured value in discrete time, and regarded the trajectory as a one-dimensional Gaussian process. The method defines the prior continuous time through the nonlinear time-varying stochastic differential equation driven by white noise, calculates the posterior distribution of the predicted value by obtaining the joint prior density and covariance matrix of the observed value and the predicted value, and uses dynamics in combination, odel smooth trajectory estimation. Rong [
6] decomposed ship motion into horizontal and vertical. In the lateral direction, a Gaussian process is used to model the uncertainty of lateral motion, and the longitudinal direction is estimated by acceleration. The horizontal distribution model obtains the hyperparameters of the Gaussian regression model through historical AIS data, and the mean function and covariance function are determined by the hyperparameters. The predicted trajectory can be estimated by evaluating the mean value and covariance matrix, that is, the mean value and variance are used to describe the ship’s lateral position and its uncertainty. The advantage of Gaussian process regression is its strong applicability and easy to understand. The disadvantage is that the amount of calculation is large, and as the forecasting time passes, the accuracy of the forecast results will be greatly reduced. Jiang [
7] used a polynomial Kalman filter to fit the piecewise polynomial features of the ship’s track. Kalman Filter (KF) can estimate the state of the system under the condition of uncertain factors. It combines joint distributions at different times to estimate unknown variables. This method first uses polynomial fitting to obtain the state equation and observation equation; determines the initial state, error covariance matrix, and other parameters; and then it completes the first step of filtering. Next, it performs
-step prediction and compares the predicted value with the true value. The algorithm iterates
times to update the error covariance matrix of the track points to complete the trajectory prediction.
The Kalman filter implements this algorithm in the form of recursion. Its advantage is that it occupies less storage space during the calculation process and can realize short-term trajectory prediction. The disadvantage is that the initial state of the model and the assumptions under ideal conditions have a significant impact on the accuracy of prediction.
Neural networks are computing systems with interconnected nodes that work similar to neurons in the human brain. Using algorithms, they can recognize hidden patterns and correlations in raw data, cluster and classify them, and—over time—continuously learn and improve [
8]. Neural networks are also ideally suited to solving complex problems in real-life situations. They can learn and model the relationships between inputs and outputs that are nonlinear and complex; make generalizations and inferences; reveal hidden relationships, patterns, and predictions; and model highly volatile data (such as time series data) [
9]. With the popularization of artificial intelligence, neural networks have also been gradually applied to the field of maritime navigation [
10,
11]. Historical ship trajectory data and trajectory characteristics are used as an input, while predicted ship trajectory data are the output of the neural network [
11]. Zhang et al. proposed a deep learning method that integrates multiple ship movements, which can be adapted to predict different many categories of ship trajectories after training the neural network appropriately [
12]. Overall, the resulting accuracy varies as a function of ship categories, thus the modeling approach still has to be improved.
Brian [
13] proposed a dual linear autoencoder method to predict the future trajectory of ships. Autoencoder (AE) includes two processes of encoding and decoding, which can extract hidden features in the data and reconstruct the original input data with new features. The autoencoder can send the extracted new features to the supervised learning model and then use them to predict the trajectory. This model first clusters ship trajectories based on historical AIS data to predict the trajectories of ships in the selected category. This method generates the entire ship trajectory, rather than the iterative state based on historical predictions. Through the potential distribution of possible future trajectories of ships, the model can predict multiple ship trajectories and predict their uncertainties. The autoencoder can extract deep-level data features. In addition, using sparse autoencoder can obtain better initial parameters in engineering applications. However, the extraction of deep-level data features requires accurate grasp. Excessive extraction will lead to the extraction of useless data features, making the model effect poor.
Mao [
14] proposed an ELM-based marine trajectory prediction method to predict the trajectory of ships. Extreme Learning Machine (ELM) is a machine learning algorithm based on a single hidden layer feedforward neural network. Since the ELM algorithm does not require the weights and biases of the iterative neural network, the training time of the ELM neural network is less than that of the traditional neural network. The advantage of this algorithm is that the generalization performance of the model is better, and the calculation speed can be improved. However, it is more dependent on the number of model nodes and the selection of some optimal parameters.
A “sequence-to-sequence” recurrent neural network model has been developed to mesh and serialize a ship trajectory into a neural network model, in order to predict the main trajectory and arrival time [
15]. A LSTM model has been introduced to predict ship’s position by evaluating the probability distribution and obtains relatively valid results [
16]. To improve the accuracy of the prediction mechanisms, a multiple azimuth autonomous device sensor has been used as an additional data input, but the approach relies on a large amount of AIS data so computational performance is relatively low [
17]. While large AIS historical data can be used as references for predicting maritime trajectories, data quality is often not guaranteed, and data redundancy is a major problem: worldwide there are about 1600 AIS receivers on the coastline of more than 150 countries and 65,000 ships sailing around the world [
18]. Furthermore, abnormal data due to either environmental conditions or technical issues are likely to generate significant trajectory prediction errors [
19,
20]. The most appropriate balance between the necessary training of the prediction mechanisms with large enough trajectory data, and the negative impact of redundant and noisy data is still a crucial issue for practicality [
21]. The advantages of common statistics-based methods are that the data occupy less storage space during the calculation process, can realize short-term trajectory prediction, and the calculation method is relatively lightweight, achieving an effect similar to deep learning. The disadvantage is that the initial state of the model and the assumptions under ideal conditions have a large impact on the prediction results. However, statistical methods cannot learn the effects of shallow reefs, islands, and other spatial factors on the trajectory of ships as deep learning. This feature makes deep learning more practical in trajectory prediction. This motivates our search for a trajectory prediction approach that will take into account the impact of redundant and noisy data on the neural network training and optimize the input trajectory dataset to improve the final quality of the modeling approach. This leads us to combine a neural network with a GRU framework and that is introduced in the following sections.
3. Modeling Approach
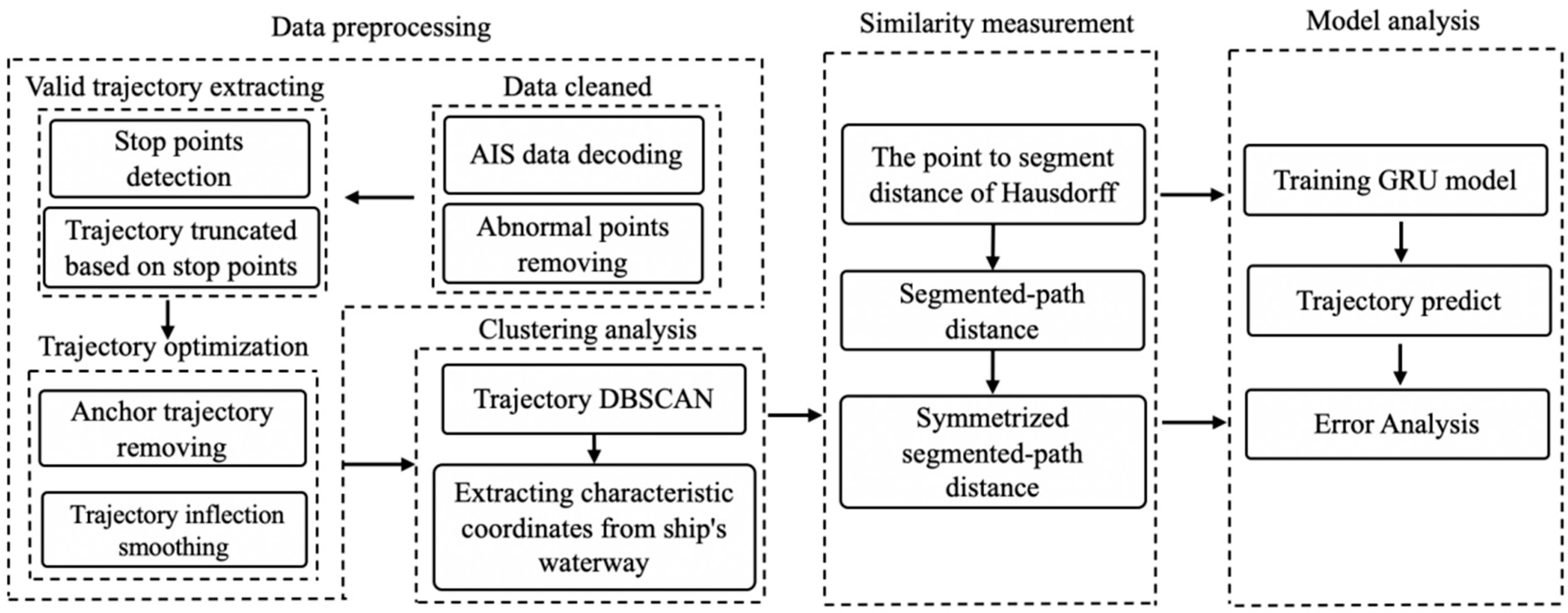
The prediction model framework consists of four parts: data preprocessing, clustering analysis, similarity measurement, and model analysis (
Figure 1). Data preprocessing is an essential part of deep learning, as cleaned data can improve the model performance. Clustering analysis uses historical data to extract the main ship trajectory areas. Similarity evaluation is based on the symmetric segmented-path distance to eliminate the influence of a large number of redundant data. The model analysis applies the deep learning model of a lightweight recurrent neural network GRU to train the model and predict ship trajectories.
3.1. Data Preprocessing
The AIS is an essential component of modern vessel navigation systems, which are installed and widely used on vessels to enhance the ability to identify targets and mark the location. Raw AIS data are used to build a reference dataset and define a matrix of historic AIS data as follows:
where
is the total number of AIS messages and
is a vector where , and represent, respectively, the Maritime Mobile Service Identity (MMSI), timestamp, location (WGS84 longitude and latitude), course over ground (COG), and speed over ground (SOG). The MMSI is a unique identifier for each vessel.
During the data preprocessing process, the wandering or anchoring trajectories in the original dataset are eliminated. We set the minimum time interval of the trajectory to 1200 s, because of the AIS information receiving interval is generally specified to be about 5–10 min, and the information interval higher than 20 min is used as the next stage of navigation status [
16]. Each trajectory is optimized by a function Optimization (
) as shown in Algorithm 1.
Figure 2 and
Figure 3 show a comparison of two trajectories’ density heat maps before and after preprocessing. The green dots in
Figure 2 show the location of the vessel, the red region indicates dense areas, and many error data or anchor trajectories are still contained.
Figure 3 shows that green dots after processing are smooth and in sailing state, and yellow to red dots indicate denser trajectories. Many noisy data in the original data are eliminated. In the original ship data, the dense red ring area shown in
Figure 2 contains data about many ships floating and anchoring. The speed of these ships is affected by wind and ocean currents and is often less than 1 knot, which is an abnormal navigation state. The data required for the experiment are the data of the ship in a sailing state; accordingly, a route performs smoothly along the motion trajectory, which makes each trajectory easier to analyze.
| Algorithm 1: Data preprocessing |
Input: Original dataset , minimum voyage time interval threshold .
Output: Trajectories |
| 1: Connect to the database. |
| 2: Get where in Len and .// is the total time interval of voyage . |
| 3: if = where = // is the next state of , is the speed of the vessel, is the time interval between two-state. |
4: then Optimization (), .//Optimize () is the trajectory optimizing function.
Return: |
In
Table 1, the total number of coordinates after preprocessing is reduced by nearly 71.8% compared to the initial data, and the number of trajectories is reduced by almost 92.1%, as only the vessels underway are saved as valid trajectories (e.g., anchor or wander is filtered). Nearly all noisy data have been eliminated from raw data, and more valid and regular vessel trajectories are obtained, which can improve the processing efficiency.
During the actual reception and sending of AIS information in navigation state, due to the phenomenon of signal drift and artificial tampering of the AIS equipment, the received ship information is likely to show some abnormal locations, as illustrated in
Figure 4. As shown in
Figure 4a, the speed of the ship in the dataset is roughly concentrated at about 20 knot but also includes speed below 1 knot. In
Figure 4b, the dataset contains some abnormal speeds greater than 20 knot. To restore the true state of the navigation, AIS information should be optimized to a valid trajectory which is approximated by
while the average speed of the ship during a period can be estimated by
where
and
are the longitude and latitude coordinates of the ship
at time
. At this time, the shipping speed should meet the condition given by
where
and
are the forward and reverse acceleration when the ship is moving forward. When the current data are identified as an abnormal speed, the average speed of the two points adjacent to the point is substituted to the data.
When judging whether the data are tested as an inflection point or a sudden change point, we can approximate the location by
where
and
are the position of the ship at time
.
and
give the location of the ship at time
. If the current location of the ship does not satisfy Equation (8), the current position information is replaced as follows:
Due to the non-equal interval of AIS data reception, when the data update interval is too low, the ship’s speed and acceleration are used to interpolate the course of the route following [
9].
Figure 5 shows a comparison of two trajectories before and after optimization.
3.2. Cluster Analysis
This section introduces the trajectory clustering model based on the AIS data that were previously processed to generate regular shipping route patterns.
The DBSCAN algorithm is a density-based point or line clustering algorithm that was introduced by Ester et al. [
22]. The main advantage of this algorithm is that arbitrarily shaped clusters can be identified. By applying the DBSCAN algorithm, lines are mainly divided into three types: density-connected lines, outliers, and core lines. A line is generally classified as a core line if a minimum number of MinPts lines are included within a distance Eps, and the lines that are density connected with others are regarded as the same cluster, while points which are not density connected are regarded as outliers [
23].
The optimized trajectory set is generated by the DBSCAN trajectory clustering, and trajectories are roughly classified into incoming waterway, crossing waterway, and north–south routes. This allows us to extract the area of each trajectory to be predicted, and then each classified waterway is used as a dataset separately for subsequent data processing, as shown on
Figure 6.
This section uses statistical inferences on the crossing points of multiple ship trajectories through the cross section and extracts the trajectory with the characteristics of the trajectory cluster as the similarity measurement trajectory as shown in
Figure 7. The specific process is as follows:
- Step 1:
Select a segment of clustered trajectory cluster data, classify the AIS trajectory point set according to MMSI, and connect the AIS trajectory points into a polyline with speed and direction.
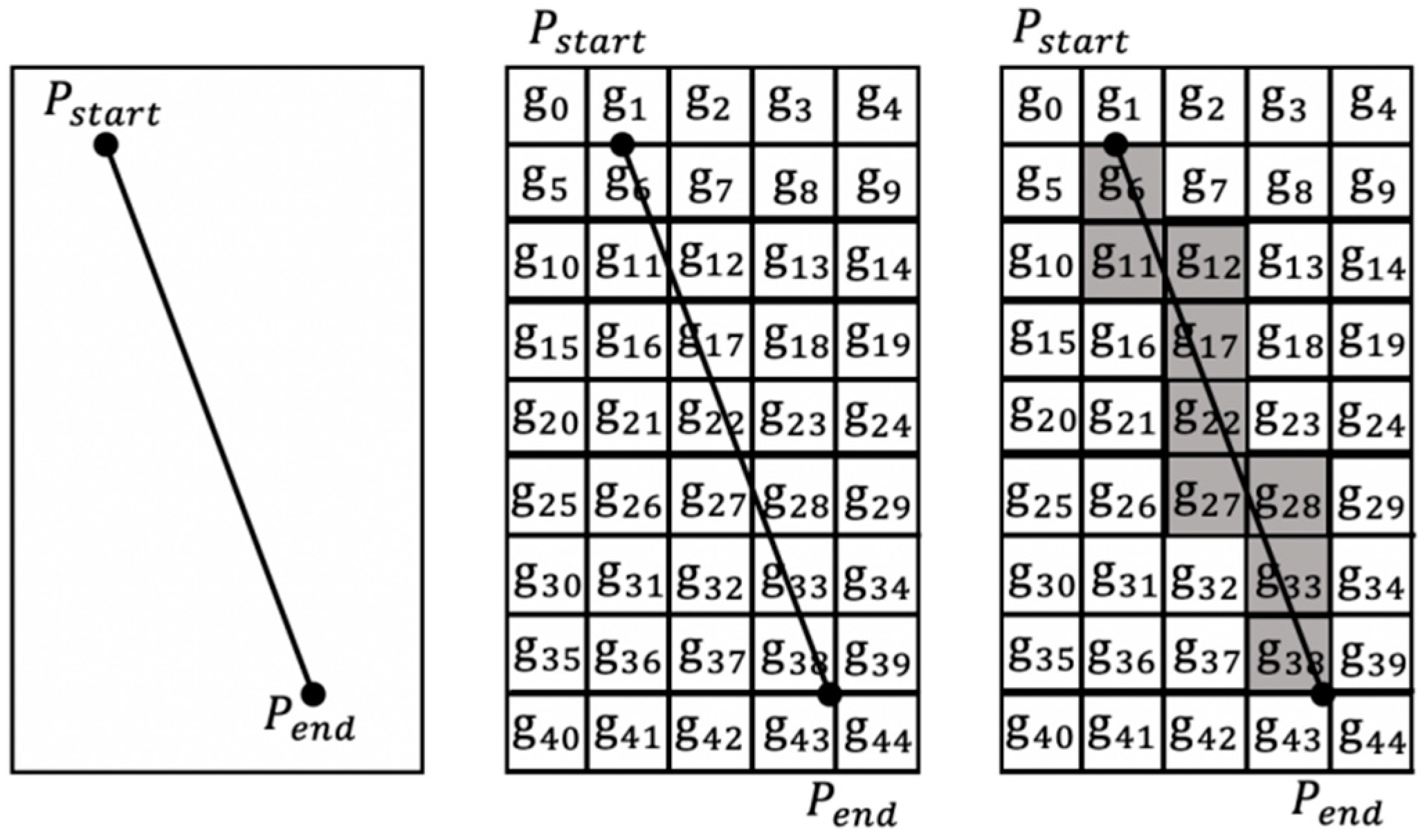
- Step 2:
Select two coordinate points on the ship trajectory cluster to form a line as the cross section, and grid the surrounding position information into , ,, , to record the crossing position of the ship trajectory.
- Step 3:
Use the line and line intersection algorithm to determine whether the ship’s trajectory passes through the cross section, count the number of crossing points the ship passes through the cross section, and store it in the grid id.
- Step 4:
The frequency at which the ship traverses the position is expressed in the form of probability density. The estimated value of the grid unit uses the Gaussian kernel function. The grid of the longitude and latitude coordinates corresponding to the peak of the probability density curve is selected as the Get used as crossing areas as shown in
Figure 8.
- Step 5:
Intercept multiple times on the track clusters of the ship trajectory in this segment, repeat Step 4 to get the grid id that the ship is accustomed to traverse, until a trajectory is obtained that fully displays the features of the track in this segment.
- Step 6:
Use the most representative trajectory obtained in Step 5 as the similarity measurement trajectory. The specific similarity measurement method is introduced in
Section 3.3.
3.3. Trajectory Similarity Measurement
The quality of the incoming data has an important impact on vessel trajectory predictions. Due to the large difference in the shape of each trajectory, as shown in
Figure 9, there are many redundant data that are not related to the target trajectory. To solve this problem, there is a need to obtain more reliable and useful datasets. A data preprocessing algorithm based on the Symmetrized Segment-Path Distance (SSPD) is applied [
24]: First, let the historical trajectory after data preprocessing and the target trajectory be evaluated by calculating the similarity coefficient between each trajectory. Second, a filtering process is triggered according to the similarity coefficient. Finally, a subset of relevant trajectory data that meet the conditions is obtained. The SSPD model is described in detail below.
Most vessel trajectories are curves or straight, and trajectory similarity measurements mainly depend on the following conditions:
The definition of the SSPD is based on a point-to-segment distance, which is derived by the Hausdorff distance,
, as shown in
Figure 10. It is given by the minimum of distances between the points of all segments. The segmented-path distance from the trajectory
to the trajectory
is given by the average of all distances from each point that compose
to the trajectory
, as shown in
Figure 11.
Suppose one of the targets to be measured is
, and the other known trajectory is
. Since the SSPD algorithm is proposed based on the Hausdorff distance, according to the definition of the midpoint of the Hausdorff distance to the line segment, the distance between the line segment on the trajectory
and the trajectory
is given as
where
represents the orthogonal projection of the point
on the trajectory segment
and
represents the Euclidean distance between
and
.
The distance from the point on the trajectory
to the trajectory
is defined as
The segmented-path distance from the trajectory
to the trajectory
is defined as
The symmetric segmented-path distance from the trajectory
to the trajectory
is based on the segmented-path distance from the trajectory
to the trajectory
which can be written as
The smaller is the value of , the higher is the degree of similarity between and .
Let the trajectory made of the grid processed as in
Section 3.2 be target trajectory and compare the similarity with these trajectories
. The data preprocessing flow based on SSPD is shown in Algorithm 2. The similarity value of each known trajectory and the target trajectory is calculated by the SSPD algorithm; the similarity threshold is set according to the actual situation; and, among all similarity coefficients, the trajectory within the threshold is selected and used as the dataset.
| Algorithm 2: Trajectory Similarity Measurement |
Input: Trajectory dataset preprocessed by Algorithm 1, similarity threshold .
Output: Trajectories |
| 1: for in |
| 2: calculate the distance between and |
| 3: end for |
4: for in
5: save the trajectory which <
6: end for
Return: |
4. GRU Model
A Recurrent Neural Network (RNN) is a type of recurrent neural network that takes sequence data as an input while cyclic units are connected in a chain [
25] and that can deal with short-term prediction problems. However, it has been observed that RNN is prone to the problem of gradient disappearance when training the network. This leads us to introduce the GRU model initially introduced by Cho et al. [
26] to improve the performance of an RNN network. The GRU structure contains the hidden layer state of the original RNN and is also a variant of LSTM. The GRU structure is similar to the LSTM model but computationally cheaper, as the GRU combines the forgotten gate and the input gate of the LSTM into a single update gate. The main advantage is that the GRU structure can store historical time-series information. It uses a gating mechanism to remember as long as possible previous trajectories, while simplifying the processing. It has a distinct hierarchical structure different from LSTM in the sense that GRU has fewer parameters than LSTM, but it can perform similarly to LSTM. The main principles behind the GRU structure is shown in
Figure 12.
Let us introduce more formally the principles of the GRU neural network. For the hidden layer of the GRU neural network, given the input value
, the value of the hidden layer at
is [
27]:
where
is sigmoid
the calculation method [ ] indicates that two vectors are connected,
means multiplying matrix elements, and
indicates matrix multiplications as follows:
Equations (9)–(12) show that the weight matrices at time
that the GRU neural network needs to train are
,
, and
, which are, respectively, composed of two weight matrices as follows:
where
,
, and
are the weight matrix from the input value to the update gate, the reset gate, and the candidate value, respectively.
,
, and
are the weight matrix from the last candidate value to the update gate
, the reset gate
, and the candidate value
respectively.
“
” indicates that each element in the vector will be subtracted from 1. For the value of
at time
, the larger is the value, the less the hidden layer value
at time
is affected by the hidden layer value
at time
, and the more affected it is by the candidate value
at time
. If the value of
is close to 1, it means that the value
of the hidden layer at
does not contribute to the value
of the hidden layer at time
.
can better reflect the impact of the data with longer time intervals to the current moment in the time series sequence. The larger is the value
at time
, the greater is the influence of the candidate value
at time
on the hidden layer value
at time
. If the value of
is approximately null, it means that the hidden layer value
at time
does not contribute to the candidate value
at time
, and
can better reflect the impact of the data with short time intervals to the current time in the time series sequence. The GRU neural network hidden layer structure is shown in
Figure 13.
GRU merges the forgotten gate layer and input gate of the LSTM unit into the of the GRU unit, as well as merges the hidden state and unit state of the LSTM network, together with the , which is used to subject the degree of ignoring the status information of the previous time to control the flow of ship trajectory information. The updated gate is used to control how much status information of the previous moment is brought into the current state. Specifically, it combines the newly input trajectory information of the next time and the previous memory to determine what information is used in the current state to calculate the state information of the next time. The combination of GRU threshold structures retains the most important data to ensure that some information is not lost during long-term propagation. Due to the relatively simple structure of the GRU model, fewer parameters need to be trained, and it has the advantage of fast training speed during the training process.
5. Experiments and Analysis
The vessel trajectory datasets are classified after DBSCAN clustering, using the clusters of the north–south routes as the experimental dataset, which is divided into three parts: the training set, validation set, and test set. The training set is used to train the model. In the training process, the validation set is used to verify the performance of the model to improve its generalization ability [
28]. The test set is used to generate some prediction results according to the input and output ways of
to
where the status vectors of the first
steps are taken as the input sequence and the status of the next time of the vessel as the output vectors. Then, the state of the first
minutes of a vessel is the original trajectory and the state of the vessel after
minutes is the one to be predicted. To ensure dimensionless interference between the data, the original time series is converted into the input sequence of the recurrent neural network after being normalized by
where
is the normalized data and
is the minimum value of the sample. After normalization, the data are mapped in the interval
.
The result of output processed by the neural network in the interval
is denormalized and mapped to the original dimension level of the sample by
where
is the data after denormalization.
To evaluate the results of GRU in vessel traffic flow prediction, LSTM is constructed as comparative experiments, and Mean Square Error (MSE) is selected as the model error analysis index during the training process as followed.
where
is the ground-truth trajectory value and;
is the predicted value.
The selection of parameters is crucial for recurrent neural networks. Generally speaking, the more hidden layers are included in the GRU recurrent neural network, the stronger is the model’s performance and learning ability. The Adam optimizer [
29], which is a stochastic gradient descent and adaptive learning rate optimization method, was used in the experiment. It can avoid the training process from falling into a local optimum situation. After determining the sampling rate as 1 in the experiment, the essential parameters in the network, batch size and the number of neurons, were experimentally compared and demonstrated to obtain the best parameter combination [
30]. The selectable range of the batch size was {8, 16, 24, 32}, and the range of the number of neurons could be selected from {60, 80, 100, 120, 140, 160}.
The selection of parameters such as the neurons is shown in
Table 2 and
Table 3. As the number of batch size gradually increases, the calculation time gradually decreases. When the number of batch sizes is too small or large, the generated errors are excessive. When the quantity of neurons is 16 and 24, respectively, the calculation time is similar, and the former error is smaller, thus a valuable number of batch size is given as 16. As shown in
Table 3, as the number of neurons gradually increases, the consumption time also gradually increases. When the number of neurons increases from 60 to 120, the prediction error gradually decreases. When the number of neurons increases further, the error increases, thus, for the neurons, it is more reasonable to set the number at 100.
After several experimental tests and parameter comparisons, the GRU construct consists of the following parts: fully connected layer, an activation layer, two GRU layers, and a method of drop out to construct the GRU recurrent neural network. The second layer gru_1 and fourth layer gru_2 are the GRU layers, each containing 120 hidden units; the third and fifth layers are the drop out method, which can not only ensure that the model maintains the robustness of the model when information is lost during training, but it can also be used for regularization, reducing the weight connection, increasing the robustness of the network model in the event of missing individual connection information; and the fifth layer is a fully connected layer, which contains two neurons. The visualization of the GRU neural network is shown in
Figure 14.
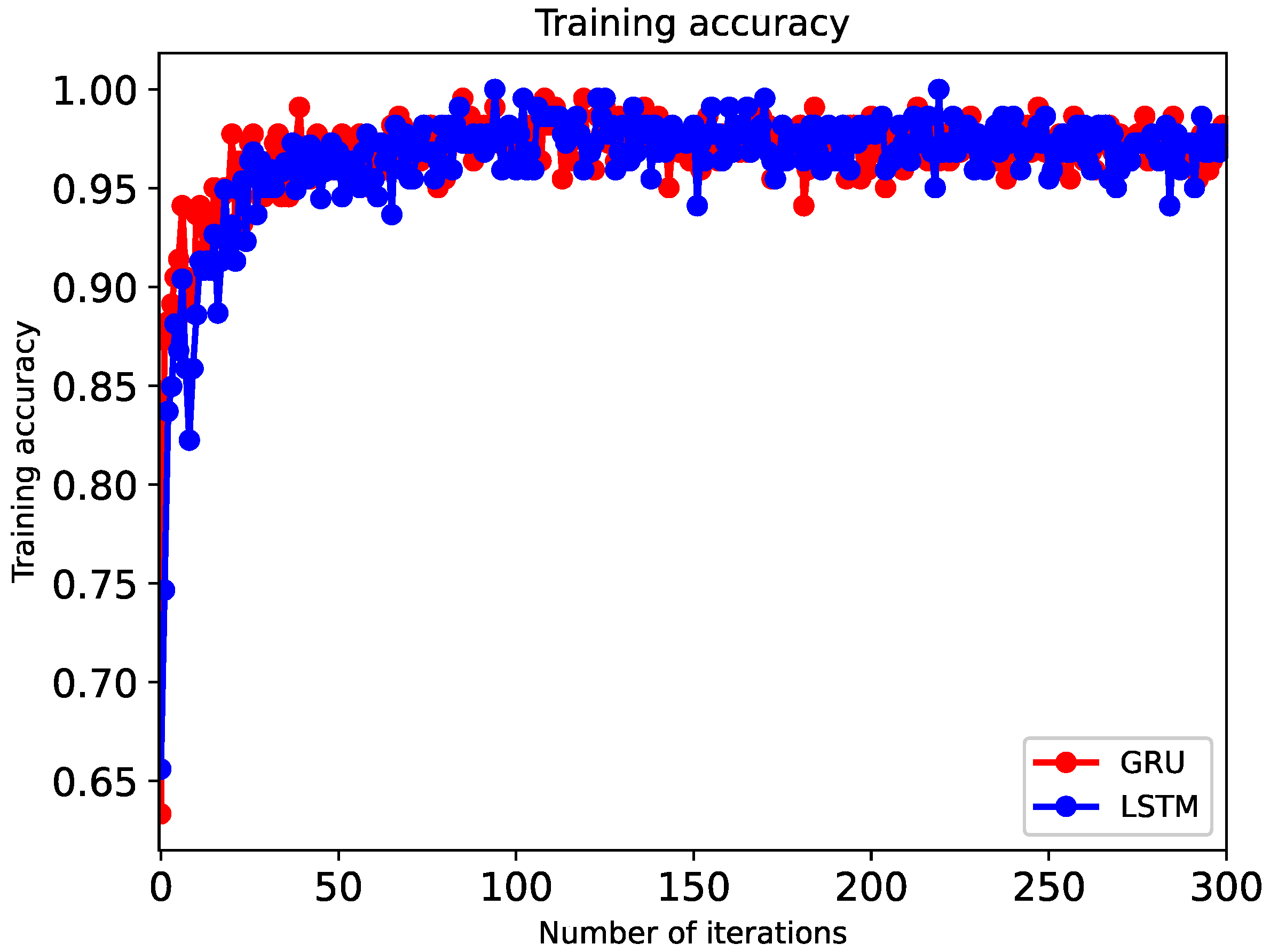
In the training process, as shown in
Figure 14, both models iterate quickly, and the training loss value can quickly obtain a better convergence effect. When the number of training rounds is about 30, GRU has reached the extremum; LSTM as a control test reached the extremum value at 50 rounds. The improved GRU model based on LSTM can converge to the extreme point more quickly than the LSTM model in the training phase. The fast convergence speed is mainly due to the simplified GRU gate structure for the gate design of the LSTM structure.
The model training is shown in
Figure 15 and
Figure 16, and one of the results of the trajectory fitting process is presented in
Figure 17, from which we can see that the fitting effect is satisfactory. When the training phase reaches about 30 rounds, the accuracy of the GRU model reaches 96%; the accuracy rate from the 200th round to the 300th round reaches about 98%; and then it gradually smooths, which shows that the efficiency of GRU is better than that of LSTM.
A total of 330 sets of trajectory data was used to predicted using LSTM, Extended Kalman Filter (EKF), and GRU models as shown in
Figure 18. From the experimental results, the deep learning method is better than the traditional statistical-based method EKF; EKF’s prediction results are good, but, compared with deep learning, the prediction error is not stable and much bigger errors appear due to the strong nonlinearity of the data. Based on the same framework, the prediction results of GRU and LSTM are relatively similar, and the errors are basically stable within 0.02. With similar prediction accuracy, it can be seen in
Table 2 and
Table 3 that the calculation efficiency of GRU model is slightly better than LSTM.
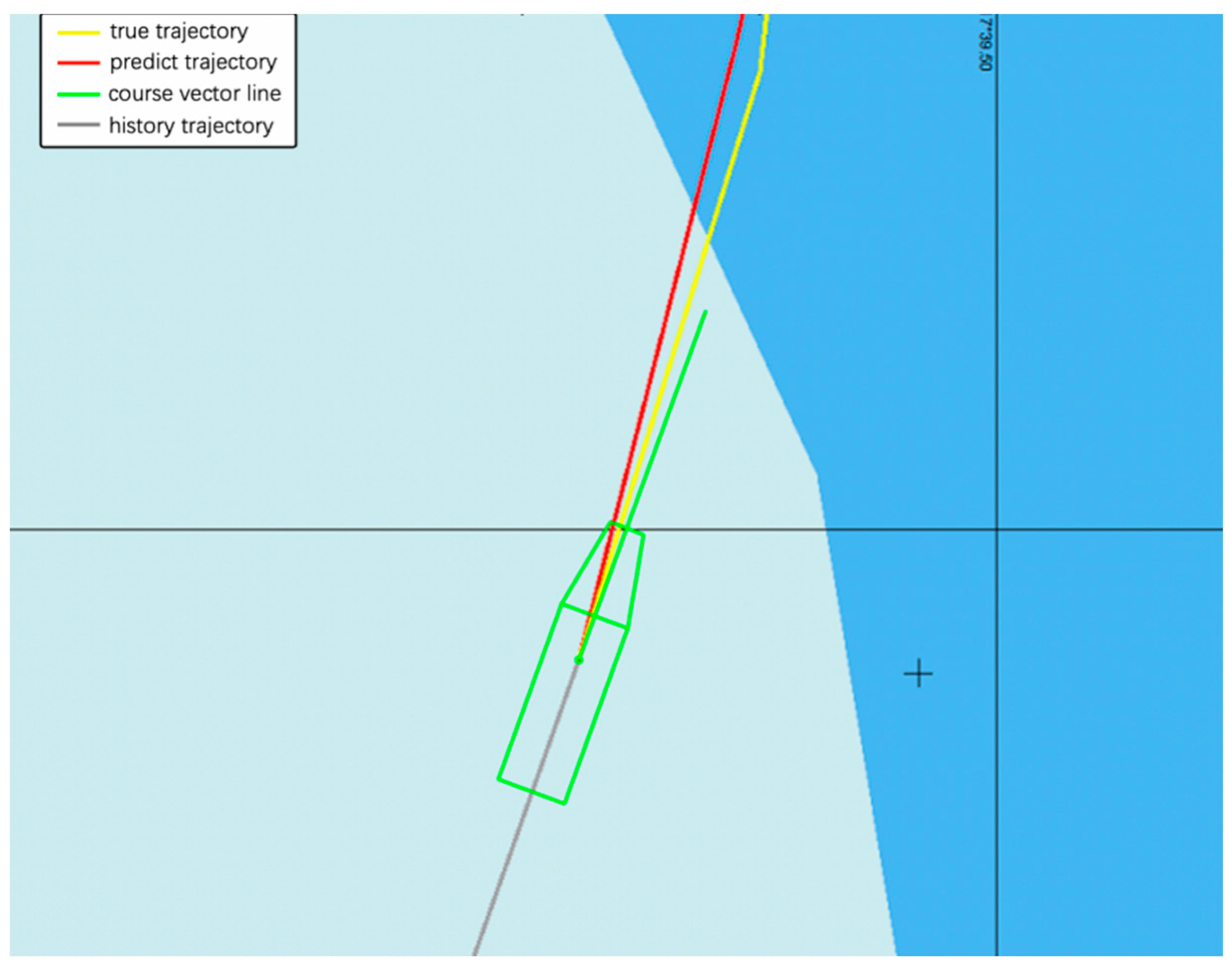
A vessel trajectory is selected from the historical AIS data of Zhangzhou Port, China, visualized in the Electronic Chart Display and Information System (ECDIS), as shown in
Figure 19 and
Figure 20. The prediction trajectory of the GRU model is illustrated, and prediction results are visualized. The gray line represents the observed history trajectory until the current time, the red line denotes the predicted trajectories, the yellow line represents the ground-truth trajectory at the 30th minute of the path, while the green line represents the course vector bar of the vessel. There is a turning point in the trajectory, which can verify that the predictive performance of our model can be applied to nonlinear data. The predicted trajectory almost overlaps with the real trajectory, and a good prediction effect is achieved.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}