Abstract
Laser-induced breakdown spectroscopy (LIBS) analysers are becoming increasingly common for material classification purposes. However, to achieve good classification accuracy, mostly noncompact units are used based on their stability and reproducibility. In addition, computational algorithms that require significant hardware resources are commonly applied. For performing measurement campaigns in hard-to-access environments, such as mining sites, there is a need for compact, portable, or even handheld devices capable of reaching high measurement accuracy. The optics and hardware of small (i.e., handheld) devices are limited by space and power consumption and require a compromise of the achievable spectral quality. As long as the size of such a device is a major constraint, the software is the primary field for improvement. In this study, we propose a novel combination of handheld LIBS with non-negative tensor factorisation to investigate its classification capabilities of copper minerals. The proposed approach is based on the extraction of source spectra for each mineral (with the use of tensor methods) and their labelling based on the percentage contribution within the dataset. These latent spectra are then used in a regression model for validation purposes. The application of such an approach leads to an increase in the classification score by approximately 5% compared to that obtained using commonly used classifiers such as support vector machines, linear discriminant analysis, and the k-nearest neighbours algorithm.
1. Introduction
Laser-induced breakdown spectroscopy (LIBS) [1] is a remote sensing technique used for both qualitative and quantitative analysis of various materials. The operational principle is to use a high pulse energy laser to instantaneously heat the matter to evaporate a small amount of the substrate and eject it as a plasma plume. Then, the light emitted by the plasma is dispersed and registered by a camera. After the specified time of continuous wavelength radiation, a time window exists with the quickly cooling plasma, whereas the individual spectral lines representing the elemental material composition can be recorded.
The LIBS itself (apart from intensity of elements’ spectral lines) does not deliver analytically relevant information, such as classification or quantification. For these purposes, software methods must be engaged based on the input spectra and some mathematical operations to deliver the expected measurement outcome. The algorithms used for such spectral data analysis are numerous and cover a large area of statistics and machine learning fields of study [2,3]. Among them, the most frequently used with LIBS are: classifiers (linear discriminant analysis (LDA) [4], support vector machines (SVM) [5], and k-nearest neighbours (KNN) [6])); regression models (partial least squares [7], lasso [8], and Bayesian regression [9])); clustering algorithms (k-means [10]) and artificial neural networks (ANN)) [11].
There are numerous fields where LIBS analysers are used [12], such as basic scrap metal analysis [13], classification of alloys [14], or mapping of geological cores [15]. Additional uses include sophisticated applications such as adulteration detection in milk [16], discrimination of heavy-metal-contamination in seafood [17], analysis of pathological tissues [18], or precision agriculture [19]. They are even used with the most demanding space missions [20] and biohazard detection [21]. The size of the LIBS equipment can vary from small handheld devices to large workstations. The size is usually commensurate with the increase in resolution, limit of detection, repeatability, and general unit functionality. However, the device size limits its usage in many in-situ applications where a handy analyser is perfect. Such situations occur when the amount of equipment is limited by personal lifting capacity or where the measurement location is extremely tight (i.e., mines and other geological sites).
In this study, we focus on the possibility of using a compact handheld LIBS to analyse the geological samples online—on-site. The materials analysed will be copper minerals existing in a natural state on their base substrate, so no sample preparations will be made. The outcome for the measurements should be a mineral identification of the rocks exposed to laser radiation. However, this is a nontrivial task because the mineral samples are very heterogeneous with irregular geometrical shapes. This heterogeneity makes it difficult for classification learners as the labels may be incorrectly assigned or impure, leading to misclassifications between minerals. Conversely, the irregular mineral shape becomes challenging for the optics and lasing capabilities of the handheld device, and the registered spectra will differ significantly in intensity and spectral channel coverage. Our proposed approach is to use a linear regression model for the classification purpose, while the regressors originate from a blind source separation algorithm. This algorithm will be capable of distinguishing the mineral spectra of interest from the base rock or other impurities of the analysed sample. In this case, a novel combination of LIBS with a non-negative tensor factorisation (NTF) [22] method was applied.
The NTF is an unsupervised learning method for extracting mode-related non-negative latent components from a multiway array (tensor). Assuming that the measured LIBS spectra from multiple measurement points can be collected to a 3-way tensor, the aim of NTF is to extract a few artificial (latent) spectra from each mineral in a given dataset, and then use them as predictors in a regression model for classification purposes. The latent spectra can be regarded as common patterns in the observed LIBS spectra and have a multilinear relationship with the spectra across each mode of the observed tensor. Such multimodal relationships cannot be revealed with matrix factorisation models, such as principal component analysis (PCA). Moreover, due to nonnegativity constraints, NTF yields spectra that have a physical sense and easy interpretation, whereas PCA provides only some orthogonal components (with negative entries) that could not be used as predictors in a regression model.
The final intent of this work is to create an analytical method that could be embedded within handheld or other mobile LIBS devices or systems, which can be used as a support and verification tool for geologists while prospecting for copper deposits.
2. Materials
2.1. Overview
This work is based on the analysis of 62 different copper minerals whose copper content varies significantly. Those minerals are: azurite, malachite, brochantite, copiapite, devilline, fornacite, langite, nakauriite, natrochalcite, osarizawaite, posnjakite, vauquelinite, arthurite, chenevixite, clinoclase, conichalcite, cornetite (co0), cornubite, descloizite, duftite, libethenite, mottramite, olivenite, parnauite, pseudomalachite, richelsdorfite, tsumebite, turquoise, tyrolite, ajoite, allophane, chrysocolla, creaseyite, dioptase, halloysite, plancheite, vesuvianite, algodonite, antimonpearceite, bornite, bournonite, chalcopyrite, colusite, covellite, digenite, enargite, freibergite, germanite, gladite, idaite, jaskolskiite, krupkaite, seligmannite, stannite, stromeyerite, tetrahedrite, umangite, boleite, kinoite, cuprite, delafossite, and tenorite.
To shed light on the given classification problem and understand the general similarities of the minerals, they were all grouped in accordance with the Strunz Classes [23] given in Table 1. The first three characters of each mineral name (indicated with bold font in the above list) together with a Strunz Class number constitute short names used in the remainder of this article (with one exception for cornetite being co0–8). The exact Strunz Class assignment for each mineral is given in Table S1 in the supplementary data.

Table 1.
List of mineral classes of analysed samples (based on original Strunz Class [23]).
The material suppliers were chosen from among different countries and/or geographical regions to differentiate the population of rocks with specific minerals and make the database more versatile. The origins of the samples include six continents, 29 countries, and 65 different regions as follows:
Australia (Kambalda), Austria (Tirol, Steiermark), Belarus (Rhodopien), Chile (Calama, Taltal, Atacama, Chuquicamata), Czechia (Severocesky, Horni Slavkov, Morava, Sredocesky), Democratic Republic Congo (Katanga), France (Corsica), Germany (Aachen, Harz, Hessen, Westerwald, Sauerland, Schwarzwald, Osthessen, Bad Ems, Saxony, Thuringia, Mansfeld), Greece (Laurion), Hungary (Rudabanya), Italy (Udine, Neapel), Japan (Aichi), Kazakhstan (Dzhezkazgan, Majkojyn), Morocco (Agadir, Bou Azzer, Bou Skour), Mexico (Durango), Namibia (Otavi, Kaokoveld), Peru (Huanzala), Poland (Polkowice), Portugal (Estremoz), Russia (Jakutien, Ural), Slovakia (Piesky, Michalovce, Lubjetova), Spain, Switzerland (Grisons, Wallis), Sweden (Gruvasen, Vena), Tajikistan (Mushiston Deposit), UK (Bristol, Cornwall), Ukraine (Nagolny Krjazh), USA (Nevada, Arizona, Montana, Utah, New Mexico, Missouri, California, Michigan, Montana), and Zambia (Kitwe).
The mineral shapes and sizes attached to the rocks were extremely diverse, from perfect crystals spread on the surface of the base rock to thin layers, often combined with the base rock, with unknown percentage distributions of both. Figure 1 presents examples of such mineral shapes. Examples are for chalcopyrite, azurite, and malachite, where each pair of photos (Figure 1a–f, respectively) shows two cases: (1) a well-built and clear crystal structure without impurities attached to the base rock, and (2) evenly distributed mineral over the rock surface with an unknown percentage mix with the base rock. Moreover, the attached crystal sizes differed from large, as in the case of chalcopyrite (Figure 1a), to very small as in the case of azurite (Figure 1c).

Figure 1.
Examples of mineral distribution on the rock samples.
A total of 127 rock samples were taken into consideration. The statistics for the number of rock samples per mineral are presented in Figure S2 in the supplementary data.
2.2. Element Composition
As the chemical bonds are destroyed during the plasma creation, the analysed spectral signal is primarily dependent on the elements that existed in the material before the laser action. All 62 minerals are described in Table S1 in the supplementary data by their empirical element composition taken from [24], where a total of 27 elements were found. Then, based on the elemental composition, an investigation of the similarities between them was conducted with the use of PCA to find theoretically undistinguishable minerals by LIBS. In this way, a new N-dimensional (N = 27) space was created with new orthogonal variables called principal components (PCs) that describe the dataset sorted from the highest to the lowest variance [25]. Even with such PCA transformation, it was impossible to find good representative PCs to determine how the minerals are distinguishable from each other in a lower dimensional space (i.e., 3D representation).
In that case, N-dimensional measures are used to find mineral pairs that are most like each other. For this purpose, the Matlab® pdist function was used with four selected distance measures: Euclidean , City block , Chebyshev, , and cosine [26]. The final computation was an average of those four measures as they gave similar yet different orders of hard to distinguish mineral pairs.
Figure 2a presents the least distinguishable 21 pairs of minerals. The worst cases were the mal-5 and azu-5 groups as well as a group consisting of lan-7, pos-7, and bro-7. These two barely reach 2% of the maximum distance between minerals in the PCA space. Figure 2b presents the worst-case groups of minerals extracted from Figure 2a with the other minerals distributed within the space of the first two PCs. Those groups are the already mentioned lan-7/pos-7/bro-7 and mal-5/azu-5 as well as co0-8/lib-8/pse-8, cli-8/cor-8/oli-8, dio-9/chr-9/ajo-9, hal-9/all-9, gla-2/kru-2, and the last one, tsu-8/vau-7, which is actually the first pair that shows close similarity above the Strunz Class division; hence, there is no need to search for another similar groups.
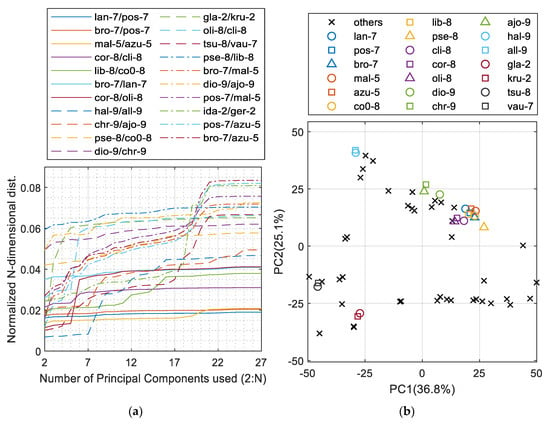
Figure 2.
PCA analysis of the mineral dataset based on element composition: (a) the N-dimensional distance measure between the closest pairs of minerals; (b) 2D PCs plot indicating the most similar groups of minerals extracted.
Further analysis of the elemental composition values (Figure 3) clearly indicated that malachite and azurite as well as the group of langite, posnjakite, and brochantite cannot be distinguished from each other. As a result, new mineral labels were created: a+m for the mal-5/azu-5 and blp for the other three. These minerals were combined and labelled together for further classification. The full heatmap with all 27 elements and 62 minerals is shown in Figure S3 in the supplementary data.
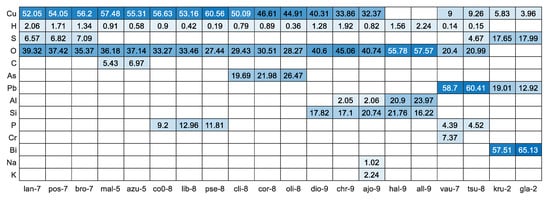
Figure 3.
Heatmap (with values) representing elemental composition among the most similar minerals in accordance with the mineral’s empirical formula [24]. The sorting from left to right was performed based on the outcome of Figure 2.
3. Experimental
The measurements were performed using a handheld LIBS device (Z-300, SciAps). The DPSS Nd:YAG laser emits radiation at a wavelength of 1064 nm, with a repetition rate up to 50 Hz, a pulse energy of 5–6 mJ, and a pulse duration of 1–2 ns. The spectrometer covers a range of 190–950 nm. Immediately before and during the measurement, the measuring region was purged with Ar gas to remove ambient air and enhance the LIBS signals. Each specific measurement point (MP) on the rock sample consisted of 64 single shots in an 8 × 8 grid covering an area of roughly 2–4 mm2. It is worth noting that the device did not save spectra below a specific intensity threshold. Therefore, in some cases, fewer than 64 spectra were recorded per MP.
The mineral crystals on the surface were uniform, and the area covered by the 8 × 8 grid often extended beyond the crystal of interest. For that reason, all MPs had to be manually labelled. An example of such labelling is shown in Figure 4 and Table 2.

Figure 4.
Image of azurite sample measuring points.
Table 2.
Example description table of the sample shown in Figure 4.
When an MP seems to cover more than 90% of the interesting mineral, it is flagged as a possible reference, and can then be used for both training and validation. If not flagged with logic 1 in the Reference column, then the MP remains as validation only. In the Coverage column of the description table, a percentage value of the mineral of interest within the 8 × 8 grid is provided. These values are rough assessments (limited to a difference of +/−5%) made just after the LIBS measurement, based on the pattern of laser spots on the sample and descriptions of the minerals of interest made by geologists. This will assist with further automated validation of MPs (because if they reach that percentage value, it means that classification succeeded). Even if the coverage description may in some cases be slightly inaccurate, this does not favour our proposed NTF method as the bias remains the same for all classification algorithms used.
During further classification, the MP is a single entity and the 8 × 8 grid spots will not be separated or analysed exclusively. In total, 458 MPs were recorded, of which 311 were flagged as possible reference and 147 as validation only. The full statistics of MPs per mineral are given in Figure S1 in the supplementary data.
4. Method
4.1. Latent Spectrum Extraction
The latent spectrum extraction in its principal form is used to select some underlying (latent) spectra from observed LIBS spectra that are considered as mixtures of multiple latent components generated by multiple spectral sources. The latent spectra are more frequent and have a common pattern across all observed LIBS spectra. In an ideal case, after the extraction, one latent spectrum should resemble an artificial spectrum of the desired source. In practise, we obtain few latent components that approximately represent the true spectra of the analysed minerals.
In the investigated case, each object is probed with several to a dozen measuring points. Thus, each MP contains a maximum of 64 spectra. Let be the i1-th spectrum of the m-th object, measured in the i2-th MP. Each MP is assumed to provide spectra, and the number of MPs is equal to , where i2 = 1, …, . The space of non-negative numbers is expressed by ℝ+. The spectra in each MP are indexed according to a lexicographical order, that is, i1 = 1, …, . The number is usually lower than 64 because some shots that correspond to the spectra of a low variance (below a threshold) must be neglected. The spectral resolution is determined by the number of samples in each spectrum, that is, the number . Because the spectral resolution is the same for each observed spectrum, then We analyse M objects, where m = 1, …, M, assuming that each registered spectrum can be regarded as a superposition of latent spectra that could be pure spectra of analysed minerals (endmembers) or other unwanted or perturbing spectra. The latent spectra for the m-th object can be collected into the matrix , where Jm is the number of latent spectra in the m-th object. Considering the above, the spectrum can be expressed by the following superposition rule:
where the coefficient determines the contribution of the jm-th latent spectrum to the i1-th observed spectrum of the i2-th MP in the m-th object. The coefficient can then be factorised as , where represents the contribution from the i1-th shot and refers to the contribution from the i2-th MP. Let be a vector of coefficients for i1 = 1, …, , and for i2 = 1, …, . Sweeping over the indices i1 and i2, let be a 3-way array (3-modal tensor) created from a set of spectra for the m-th object. It is thus easy to notice that model (1) takes the form
where the symbol ∘ denotes the outer product. Model (2) can be equivalently expressed in the form
where , , is a superdiagonal identity tensor, and the symbol stands for the tensor-matrix product across the n-th mode.
Note that all factor matrices contain only nonnegative numbers, and hence, model (3) can be regarded as the standard non-negative tensor factorisation (NTF) [22], which is a particular case of the CANDECOMP/PARAFAC (CP) decomposition [27,28].
Factor contains Jm latent spectra, and and represent the contribution coefficients (concentrations) of the latent spectra to observations across the first and second modes of the tensor , respectively. The latent spectra can thus be obtained by performing the NTF of , given the assumed number Jm.
There are numerous computational strategies for NTF, and nearly all of them are based on an alternating optimisation scheme with unfolding imposed on each mode. Model (3) expressed in the unfolded version takes the form
where is a matrix obtained by the unfolding tensor along its n-th mode; where n = 1, 2, 3, and the symbol stands for the Khatri-Rao product. Note that the system in (4) is considerably overdetermined because . To alleviate the problem of scaling ambiguity in the NTF, the columns in matrices and are normalised to the unit l1-norm. The system of linear equations in (4) can be solved with numerous linear solvers subject to nonnegativity constraints. In our study, we used the hierarchical alternating least-squares (HALS) algorithm proposed in [29], and then computationally improved in [30]. It belongs to a family of block coordinate descent update algorithms with monotonic convergence and computational complexity of . The graphical representation of the NTF model is presented in Figure S4 of the supplementary data.
4.2. Regression Model Using Latent Spectra
To estimate the percentage rate of minerals in a newly measured MP, the latent spectra are extracted from the known MPs labelled with the so-called strong reference. We assume that Jm latent spectra are extracted from the m-th labelled object using the NTF. The latent spectra after being postprocessed can be regarded as regressors for predicting the percentage of minerals in such an unknown MP. Any unknown spectrum is assumed to be approximated by a linear regression model,
Coefficient represents the contribution of the jm-th latent spectrum from the m-th object to the unknown spectrum . Let and . Coefficient can be estimated from model (5) by solving the following regularised constrained least-squares problem:
where is a regularisation parameter that controls the overfitting. In this study, problem (6) was solved using the interior-point least-squares algorithms for regularised box-constrained problems, implemented in the function lsqlin in Matlab® 2016a. Note that coefficients in vector can also be regarded as unknown percentages of expected minerals in the analysed MP.
4.3. Determining the Number of Latent Spectra per Mineral
The last problem to be solved is how to determine the correct (sufficient) Jm number of latent spectra for each m-th object. The problem would be trivial if only pure mineral samples were analysed, since only a single latent spectrum may represent the desired mineral. However, in our measurements, impurities in the spectra resulting from base rocks and other minerals will occur. Moreover, the NTF is sensitive to the difference in light intensity distribution between spectrometer channels, which is not constant because the light is propagated inside the device and thus can cause additional perturbations of the desired m-th object spectra. In that case, the assumption was made that we will search for Jm latent spectra in which most of them represent the scattered spectra of the desired mineral. The less contributing examples after the so-called self-regression will be labelled as unknown spectra (U).
In such a case, we developed an iterative process in which we start from Jm = 2 (Jm = 1 will be similar to a weighted average of the data) and increment the number until reaching a break loop condition. The loop breaking condition is based on two parameters: level L and ratio R, which will be set up prior to this procedure.
The L-condition is superior and relates to the cumulative contribution given by the sum of coefficients of the first K latent spectra (), sorted in descending order of their contributions. Note that number K cannot be equal to Jm, which means that at least one latent spectrum should be classified as undefined U. If the cumulative contribution of K latent spectra in a given iterative step is equal to or greater than the L value, then the first K spectra are assigned as the desired mineral, and the last Jm-K spectra are labelled as U. Otherwise, Jm is incremented and again the L-condition is checked.
If the L-condition is satisfied, then the second R-condition should be checked. This condition requires the minimum ratio between the last (K-th) spectrum assigned as a mineral to the first (Jm-K+1) spectrum assigned as U. This relation is very important, as for a higher value of Jm, the distribution of latent spectra contributions might end up equal. Therefore, it may be difficult to assess the U spectra, as the difference between the last labelled as mineral and first labelled as U may be only a few percentage points. If the R-condition is not met, Jm is incremented, and the L-condition is checked.
After meeting these two (L and R) conditions, we achieve the solution for which we have the desired level of contributions and the ratio of the contributions of the last mineral spectrum to the first U spectrum large enough to assume the U spectra are really the unwanted signals. An example of such a loop operation with given L/R conditions is shown in Figure S5 of the supplementary data.
Obviously, for some combination of R and L in a given m-th object, such a pair of conditions can never be met. To avoid an infinite loop, parameter is introduced, which is the maximum Jm number to be incremented in the loop. If the conditions are not met after then a given pair of L/R conditions is excluded from consideration for all m objects.
Figure 5 presents an example of such latent spectra extraction for malachite with R set to 1.8 and L to 0.96. In this case, three components were extracted as scattered in the m-th object and one as the U spectrum.
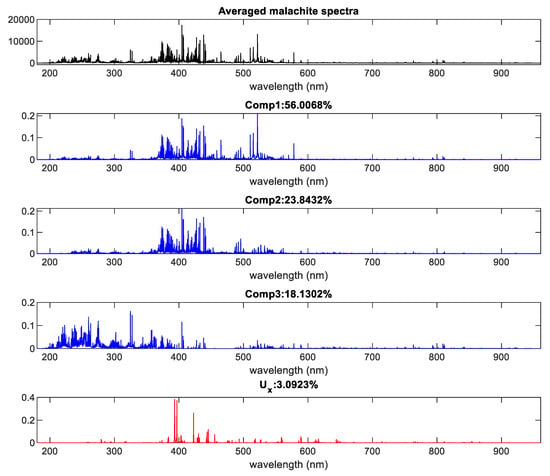
Figure 5.
Example of latent spectra extraction. The averaged spectrum originates from all malachite MPs.
For the final validation process of a new unknown MP, the scattered K latent spectra of each m-th object become different regressors. Finally, the predicted percentage contribution for the m-th object in the new MP becomes the sum of the single K contributions of the m-th object scattered latent spectra. The classifying label is then decided on the mineral that has the top percentage contribution.
5. Results
5.1. Setup
The number of MPs flagged as validation only differs among minerals, some do not even have such or have only one. To make the proportion of training and validation data equal among the minerals, some of the MPs flagged as possible reference were also moved to be validation data. This new division can be observed in Figure S6 of the supplementary data.
The parameters that were set for our algorithm were a maximum number of latent spectra ( = 20), ratios R (from 1.1 to 2.0), and levels L (from 0.80 to 0.98). The following sections present 10 × 10 heatmaps with classification measures from which we can select the best parameters for the analysis of the confusion matrix.
Because we deal with an imbalanced dataset, there is a risk of the results being overwhelmed by the outcome of the larger mineral classes. Thus, the metrics of precision and recall are introduced together with their bounding metric called F-measure [31]:
where tp is the true positive rate, fp is the false positive rate, and fn is the false negative rate.
The proposed NTF-based classification also introduces the U class (Section 4.3), which should be included in some way in the metrics in (7). For that purpose, we propose to differentiate two cases: Uin and Uex.
The Uin case assumes that we include MPs labelled as U in the classification score calculation. However, the metrics in (7) require, among others, true positive rates, which in the case of U class, will never exist (U is not a true class). This will result in precision and recall being zero all the time and independently from the number of MPs labelled as U, the F-measure (if calculated) for U class will always be zero and, therefore, lower the total F-measure for all the classes together. The only way to introduce the U class into the F-measure, therefore, is assuming that if any MP is going to be assigned as U class, it will appear as a false negative value for the original true class (i.e., azurite labelled as U).
The Uex case totally excludes MPs labelled as U from the classification score calculation. This decision was made on the assumption that U labels give us the information that the measurement outcome is uncertain and the user should repeat the measurement on such a sample for more confidence (this is not yet an error at that point but restrains us from introducing false positive rates into another class).
Again, as U is not a true class, the false positive rates will never exist for it, so, actually, the only difference between Uin and Uex scores will be held by the recall part of the equation in (7) (the precision will stay the same for both).
The NaN values within the heat maps are related to the L/R pairs with which the algorithm could not find a latent extraction solution for at least one mineral. For improved clarity, each heatmap has the top three L/R solutions listed in its title.
The result of the proposed algorithm is contrasted with the performance of the Matlab® built-in classification algorithms: SVM (templateSVM: KernelFunction—linear; BoxConstraint—1; standardised input), LDA (fitcdiscr: DiscrimType—linear; standardised input), and KNN (fitcknn: Distance—Euclidean; NumNeighbors—1; DistanceWeight—equal, standardised input) [2].
As the confusion matrices in the case of our 59 classes were very large, they were added as supplementary data (Figures S8–S11).
5.2. Analysis of Training Data
The first portion of the results is focussed on finding the ideal combination of parameters for our proposed method. To do this, the model was trained and validated using the same training data (Figure S6—supplementary data). This is reasonable, as while the proposed algorithm extracts the latent spectra, it does it within a single mineral class and is unaware of the existence of other classes. Because of this, it is unlikely for the model with so many classes to reach a 100% score even when trained and validated with the same data (which is different in the case of the SVM that reached 100% under the same conditions). However, this gives us an opportunity to revise the model on the basis of training data and determine the best combination of R and L values for the given dataset.
From Figure 6, we see that the F-measure score increased with increasing L value. Moreover, it is clear that we reached the parameterisation boundary from each side of the 10 × 10 matrices, as it was impossible to deliver results for L equal or greater than 0.98 and R equal to 1.8 (or greater). If the L values were taken from the range [0.8, 0.82], we had few possible solutions and much lower scores. Finally, it was futile to use R values smaller than 1.1 because 1.0 would designate equality.
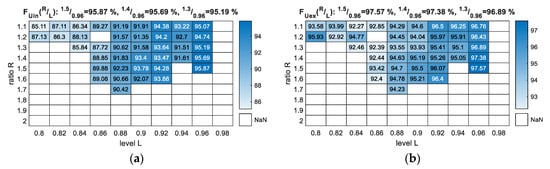
Figure 6.
F-measure output for the parameterisation of the NTF method with R and L variables (training data vs. training data): (a) FUin—scores with U class included as an error; (b) FUex—scores with U class excluded from measure.
5.3. Analysis of Validation Data
For this section, analyses were taken with separate training and validation data, in accordance with Figure S6 in the supplementary data. Although we already selected parameters in the previous section, we decided to perform the same parameterisation of R and L, resulting in 10 × 10 matrices to verify that the selection was accurate.
Similar to Figure 6, the results in Figure 7 indicate (with few exceptions) that the F-measure score increased with an increase in L. The boundary parameters also remained the same as the learned model, as in the previous section.
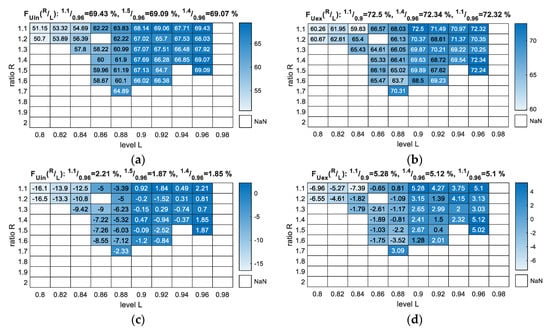
Figure 7.
Classification F-measure output for the parameterisation of the NTF method with R and L variables (validation dataset): (a) FUin—scores with U class included as an error; (b) FUex—scores with U class excluded from measure; (c) FUin—scores with U class included as an error in accordance with the best SVM result from Table 3; (d) FUex—scores with U class excluded from measure in accordance with the best SVM result from Table 3.
Figure 7 presents the F-measure results of the parameterisation, but apart from the scores for the Uin and Uex cases, it also presents the results in comparison to the best selected classifier (Figure 7c,d), which, in our case, was SVM scoring 67.22%. It is important to note here that this was the highest value that was possible to reach for an SVM trying different kernel functions and their parameterisation. In fact, the basic linear SVM scored the best among all SVM variants that was investigated. The additional results for NTF covering the F-measure’s partial scores—precision and recall—are presented in Figure S7 in the supplementary data.
Although the best results in the case of Figure 7 were not for R = 1.5 and L = 0.96, these results were selected as final because they could be foreseen (Section 5.2) and did not differ much from the other high scores, especially in the case of the highest results such as FUex.
Table 3 presents the discussed measures obtained for the NTF-based method and three standard classifiers for the analysed validation data. The best built-in solution was SVM, which reached an F-measure of approximately 17.5% better than that associated with KNN and LDA. The proposed algorithm reached 1.87% (Uin) and 5.02% (Uex) of the F-measure score with respect to the second-best SVM, followed by increases in every other case where RUex had the highest gain of 6.92%.
Table 3.
Classification measures of the validation dataset with the use of analysed methods. Brackets indicate the NTF accuracy gain in comparison to the best SVM classifier.
The confusion matrices for the built-in classifiers present a trend to seek a host for the more likely hard-to-assess samples. In the case of the best out of three SVM (Figure S8—supplementary data), 23 mineral classes had a 100% score, and the classes that caused the most errors were blp (19 false positives) and a+m (12 false positives). For LDA (Figure S9—supplementary data), only 11 mineral classes had a 100% score, and the most confusing was all-5 (16 false positives). The KNN (Figure S10—supplementary data) performed similarly to LDA for the final F-measure score, while 13 mineral classes were perfectly assessed, and the classes that caused the most errors were a+m (19 false positives) and ajo-5 (13 false positives). Using the NTF method (Figure S11—supplementary data), we managed to classify the top F-measure score and the top 25 mineral classes without error. The U class perfectly took the top host position for the hardest to assess samples (17 false positives), followed by cha-2 (14 false positives) and cup-4 (8 false positives), which is very reasonable.
The CPU time and disk space usage of the above methods are compared in Table S12 in the supplementary data. It is clear from this table that the proposed NTF-based method requires less disk space and needs half the time for data validation compared to the competing SVM.
5.4. Example of Mineral Contribution for Selected MPs
The regression method proposed, apart from classifying the MPs, also gives the mineral percentage contribution followed by their geometrical distribution within the 8 × 8 shooting grid. Figure 8 presents the results for MP1 from the selected chalcopyrite sample. The bar plot presents the single contributions of the regressors (Jm latent spectra) summed for each mineral. In this MP case, the top count goes to chalcopyrite (almost 80%), leaving all the other minerals far behind, so the given classification label is correct. The geometrical distributions of the four main minerals (m-th objects) and the unknown class were equal within the 8 × 8 grid. Both can be confirmed with the MP photo, as the surface looks like an equal mineral distribution without any sign of the base rock.
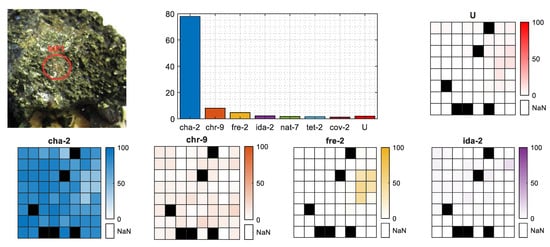
Figure 8.
Mineral contribution for selected MP of chalcopyrite sample. Bar chart presents the total percentage rate of minerals per MP, the image indicates the place of measurement on the sample surface and the heatmaps present the geometrical distribution of the four main minerals and unknown class within 8 × 8 shooting grid. Black fields are missing spectra.
However, as mentioned in Section 2, there were also samples that did not have a consistent mineral distribution on the surface, and the crystal size was even smaller than the 8 × 8 shooting grid. An example of such a situation is the selected azurite sample presented in Figure 9. From the photo, we observe that the azurite crystal actually covers less than one-quarter of the visible, burned in laser pattern. This fact is clearly visible in the mineral distribution heatmaps of a+m, cha-2, and chr-9, where in the case of the proper azurite (a+m) class in the bottom-left quarter, we observe a higher contribution of that mineral, while in the same area on the cha-2 and chr-9 heatmaps, there is almost zero contribution. The total sum of a+m contribution on the bar plot is almost 30%, which perfectly covers one-quarter of the crystal that fits within the 8 × 8 shooting grid plus some average error of the latent spectra contribution.
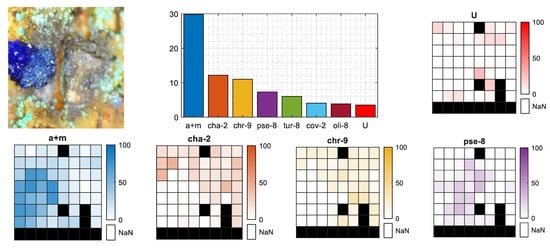
Figure 9.
Mineral contribution for selected MP of azurite sample. Bar chart presents the total percentage rate of minerals per MP, the image indicates the place of measurement on the sample surface and the heatmaps present the geometrical distribution of the four main minerals and unknown class within 8 × 8 shooting grid. Black fields are missing spectra.
In both cases, as the classification labels were correctly set, the U class did not play an important role in the final percentage rate within those MPs. Both MPs are missing some spectra.
6. Conclusions
In this research, we hypothesised that it is possible to extract artificial (latent) spectra for each of the investigated minerals and use them as predictors in a linear regression model. For this purpose, NTF was used. Because of the heterogeneity of the mineral samples and weak reproducibility of the spectra acquired with the use of a handheld LIBS device, the procedure for proper latent spectra selection was proposed. In such a procedure, a parameterisation of ratio R and level L variables is required. The results show that these variables can be limited, with high accuracy, to one selection by performing validation with the use of the same data as for the model training.
The NTF-based classification performed well, reaching higher F-measure scores of around 1.9% (when the Unknown class was included in the measures) and around 5.0% (when the Unknown class was excluded from the measures), both in accordance with the best SVM classifier. The standard methods seem to find a host class for the hardest-to-assess samples, so using the method that already contains an Unknown class inside its model was even more reasonable here.
In addition to the output labelling required for classification purposes, a percentage contribution of the minerals within measuring points is given. Such additional information on the MPs allows the creation of 2D mapping of the shooting area 8 × 8 grids with a smooth distribution of the mineral classes among them.
The final regression model can be stored using low disk space, and the regression function is not as memory- and CPU-intensive (compared to the commonly used classifiers SVM, LDA, and KNN). Such a model may even be implemented in mobiles and other handheld LIBS devices and thus increase their functionality as fast, on-site mineral analysers.
Future research will be devoted to applying the method to minerals other than those containing copper as their primary element and verifying its universal usability. The NTF was confirmed as a method for extracting artificial spectra for the mineral classes and was successfully used as a regressor in a linear model.
Supplementary Materials
The following are available online at https://www.mdpi.com/1424-8220/20/18/5152/s1, Table S1: detailed list of 62 minerals used in research; Figure S1: the number of measurement points (MPs) taken per mineral together with their partitions into possible reference and validation only ones; Figure S2: the number of different (exclusive) rock samples on which MPs were taken—listed per mineral; Figure S3: heatmap representing elements composition among all 62 minerals in accordance with the mineral’s empirical formula [24]; Figure S4: NTF model; Figure S5: example of Jm number of latent spectra decision for one m-th object; Figure S6: dataset partitioning of the training and validation data using some of the possible reference MPs as validation data to evenly match the dataset among mineral classes; Figure S7: classification precision and recall output for the parametrisation of the NTF method with R and L variables (validation dataset), Figure S8: confusion matrix of SVM classifier for validation dataset; Figure S9: confusion matrix of KNN classifier for validation dataset; Figure S10: confusion matrix of LDA classifier for validation dataset; Figure S11: confusion matrix of NTF based classifier for validation dataset; Table S12: CPU time and disk space usage of the compared methods.
Author Contributions
Conceptualization, M.W., R.Z., A.A., D.R., and T.B.; methodology, R.Z. and M.W.; software, M.W. and R.Z.; validation, M.W., S.M., and K.C.; formal analysis, R.Z.; investigation, P.B. and M.W.; resources, P.B., D.R., and T.B.; data curation, P.B. and M.W.; writing—original draft preparation, M.W. and R.Z.; writing—review and editing, D.R., S.M., T.B., and A.A.; visualization, M.W.; supervision, T.B., A.A., and D.M.; project administration, K.C., D.R., and T.B.; funding acquisition, P.B., D.R., T.B., S.M., K.C., and D.M. All authors have read and agreed to the published version of the manuscript.
Funding
The authors are grateful for financial support from the German federal state of Brandenburg and the European Regional Development Fund (ERDF 2014-2020) as well as for project management by the Investitionsbank des Landes Brandenburg (ILB) and the economic development agency Brandenburg (WFBB) in the LIBSqORE project (grant number 80172489).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Cremers, D.A.; Multari, R.A.; Knight, A.K. Laser-Induced Breakdown Spectroscopy. In Encyclopedia of Analytical Chemistry; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2016; pp. 1–28. ISBN 9780470027318. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2009; ISBN 9780387848587. [Google Scholar]
- Alpaydin, E. Introduction to Machine Learning; Adaptive Computation and Machine Learning Series; MIT Press: Cambridge, MA, USA, 2014; ISBN 9780262325752. [Google Scholar]
- Pontes, M.J.C.; Cortez, J.; Galvão, R.K.H.; Pasquini, C.; Araújo, M.C.U.; Coelho, R.M.; Chiba, M.K.; de Abreu, M.F.; Madari, B.E. Classification of Brazilian soils by using LIBS and variable selection in the wavelet domain. Anal. Chim. Acta 2009, 642, 12–18. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Wu, S.; Dong, J.; Wei, J.; Wang, K.; Tang, H.; Yang, X.; Li, H. Quantitative and classification analysis of slag samples by laser induced breakdown spectroscopy (LIBS) coupled with support vector machine (SVM) and partial least square (PLS) methods. J. Anal. At. Spectrom. 2015, 30, 368–374. [Google Scholar] [CrossRef]
- Li, X.; Yang, S.; Fan, R.; Yu, X.; Chen, D. Discrimination of soft tissues using laser-induced breakdown spectroscopy in combination with k nearest neighbors (kNN) and support vector machine (SVM) classifiers. Opt. Laser Technol. 2018, 102, 233–239. [Google Scholar] [CrossRef]
- Feng, J.; Wang, Z.; West, L.; Li, Z.; Ni, W. A PLS model based on dominant factor for coal analysis using laser-induced breakdown spectroscopy. Anal. Bioanal. Chem. 2011, 400, 3261–3271. [Google Scholar] [CrossRef] [PubMed]
- Bricklemyer, R.S.; Brown, D.J.; Turk, P.J.; Clegg, S. Comparing vis-NIRS, LIBS, and Combined vis-NIRS-LIBS for Intact Soil Core Soil Carbon Measurement. Soil Sci. Soc. Am. J. 2018, 82, 1482–1496. [Google Scholar] [CrossRef]
- Menking-Hoggatt, K.; Arroyo, L.; Curran, J.; Trejos, T. Novel LIBS method for micro-spatial chemical analysis of inorganic gunshot residues. J. Chemom. 2019, e3208. [Google Scholar] [CrossRef]
- Wójcik, M.R.; Zdunek, R.; Antończak, A.J. Unsupervised verification of laser-induced breakdown spectroscopy dataset clustering. Spectrochim. Acta Part B At. Spectrosc. 2016, 126, 84–92. [Google Scholar] [CrossRef]
- Ramil, A.; López, A.J.; Yáñez, A. Application of artificial neural networks for the rapid classification of archaeological ceramics by means of laser induced breakdown spectroscopy (LIBS). Appl. Phys. A Mater. Sci. Process. 2008, 92, 197–202. [Google Scholar] [CrossRef]
- Hahn, D.W.; Omenetto, N. Laser-Induced Breakdown Spectroscopy (LIBS), Part II: Review of Instrumental and Methodological Approaches to Material Analysis and Applications to Different Fields. Appl. Spectrosc. 2012, 66, 347–419. [Google Scholar] [CrossRef]
- Merk, S.; Scholz, C.; Florek, S.; Mory, D. Increased identification rate of scrap metal using Laser Induced Breakdown Spectroscopy Echelle spectra. Spectrochim. Acta—Part B At. Spectrosc. 2015, 112, 10–15. [Google Scholar] [CrossRef]
- Herrera, K.K.; Tognoni, E.; Gornushkin, I.B.; Omenetto, N.; Smith, B.W.; Winefordner, J.D. Comparative study of two standard-free approaches in laser-induced breakdown spectroscopy as applied to the quantitative analysis of aluminum alloy standards under vacuum conditions. J. Anal. At. Spectrom. 2009, 24, 426–438. [Google Scholar] [CrossRef]
- Kuhn, K.; Meima, J.A.; Rammlmair, D.; Ohlendorf, C. Chemical mapping of mine waste drill cores with laser-induced breakdown spectroscopy (LIBS) and energy dispersive X-ray fluorescence (EDXRF) for mineral resource exploration. J. Geochem. Explor. 2015, 161, 72–84. [Google Scholar] [CrossRef]
- Moncayo, S.; Manzoor, S.; Rosales, J.D.; Anzano, J.; Caceres, J.O. Qualitative and quantitative analysis of milk for the detection of adulteration by Laser Induced Breakdown Spectroscopy (LIBS). Food Chem. 2017, 232, 322–328. [Google Scholar] [CrossRef] [PubMed]
- Ji, G.; Ye, P.; Shi, Y.; Yuan, L.; Chen, X.; Yuan, M.; Zhu, D.; Chen, X.; Hu, X.; Jiang, J. Laser-induced breakdown spectroscopy for rapid discrimination of heavy-metal-contaminated seafood Tegillarca granosa. Sensors 2017, 17, 2655. [Google Scholar] [CrossRef]
- Hamzaoui, S.; Khleifia, R.; Jaïdane, N.; Ben Lakhdar, Z. Quantitative analysis of pathological nails using laser-induced breakdown spectroscopy (LIBS) technique. Lasers Med. Sci. 2011, 26, 79–83. [Google Scholar] [CrossRef] [PubMed]
- Erler, A.; Riebe, D.; Beitz, T.; Löhmannsröben, H.G.; Gebbers, R. Soil nutrient detection for precision agriculture using handheld laser-induced breakdown spectroscopy (LIBS) and multivariate regression methods (PLSR, lasso and GPR). Sensors 2020, 20, 418. [Google Scholar] [CrossRef]
- Cremers, D.A. Space Applications of LIBS. In Laser-Induced Breakdown Spectroscopy: Theory and Applications; Musazzi, S., Perini, U., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 257–291. ISBN 978-3-642-45085-3. [Google Scholar]
- DeLucia, F.C.; Samuels, A.C.; Harmon, R.S.; Walters, R.A.; McNesby, K.L.; LaPointe, A.; Winkel, R.J.; Miziolek, A.W. Laser-induced breakdown spectroscopy (LIBS): A promising versatile chemical sensor technology for hazardous material detection. IEEE Sens. J. 2005, 5, 681–689. [Google Scholar] [CrossRef]
- Shashua, A.; Hazan, T. Non-negative tensor factorization with applications to statistics and computer vision. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 792–799. [Google Scholar]
- Nickel, H.S.E. Strunz Mineralogical Tables, 9th ed.; Schweizerbart Science Publishers: Stuttgart, Germany, 2001; ISBN 9783510651887. [Google Scholar]
- Mineralogy Database. Available online: http://webmineral.com/ (accessed on 1 July 2020).
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- MathWorks Pdist—Pairwise Distance between Pairs of Observations. Available online: https://www.mathworks.com/help/stats/pdist.html (accessed on 27 July 2020).
- Carroll, J.D.; Chang, J.J. Analysis of individual differences in multidimensional scaling via an n-way generalization of “Eckart-Young” decomposition. Psychometrika 1970, 35, 283–319. [Google Scholar] [CrossRef]
- Harshman, R.A. Foundations of the PARAFAC procedure: Models and conditions for an “explanatory” multimodal factor analysis. UCLA Work Pap. Phon. 1970, 16, 1–84. [Google Scholar]
- Cichocki, A.; Zdunek, R.; Amari, S.I. Hierarchical ALS algorithms for nonnegative matrix and 3D tensor factorization. Lect. Notes Comput. Sci. 2007, 4666 LNCS, 169–176. [Google Scholar] [CrossRef]
- Phan, A.-H.; Cichocki, A. Multi-Way Nonnegative Tensor Factorization Using Fast Hierarchical Alternating Least Squares Algorithm (HALS). In Proceedings of the 2008 International Symposium on Nonlinear Theory and Its Applications, Budapest, Hungary, 7–10 September 2008; pp. 41–44. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]









© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).