1. Introduction
Textures constitute an important feature for human visual discrimination [
1]. Even though they do not have a precise definition in the literature, they are normally characterized by their pattern, regularity, granularity, and complexity [
2]. Although the segmentation of textures has direct applications in medical image analysis [
3,
4,
5,
6,
7] quality inspection [
8,
9], content-based image retrieval [
10], analysis of satellite and aerial images [
11,
12,
13], analysis of synthetic aperture sonar images [
14], and object recognition [
15], it is still a challenging problem due to its subjective nature and variability in terms of viewpoints, scales, and illumination conditions [
16].
Texture analysis methods in digital images can be broadly divided into four categories [
17,
18,
19]: statistical methods, structural methods, model-based methods, and filter-based methods. Statistical methods describe textures based on local spatial distribution of pixel intensities using statistical measures. As a classical example of statistical method in texture analysis, the gray level co-occurrence matrix technique [
20,
21] uses local statistics based on the spatial relationship between neighboring pixels in the image. This technique has originated many variations [
22,
23,
24,
25] and is widely used in applications of texture classification [
26,
27]. Another example of a statistical approach in texture analysis is the local binary patterns (LBP) [
28], and its variations [
29,
30,
31], which analyze the texture content of an image by comparing pixels and their neighbors by searching for local patterns is also used in many works that deal with texture classification [
32,
33].
Structural methods describe textures using well-defined primitives and the spatial relationship between those primitives using placement rules [
21]. Those primitives are considered to be fundamental structures of textural visual perception, known in the literature as textons [
34,
35]. Another structural approach based on morphological mathematical operations is presented in [
36]. Model-based techniques represent textures using stochastic models or generative image models. Examples of models used for describing textures are Markov random field models [
37,
38] and fractal models [
39,
40]. Finally, filter-based methods, also known as transform-based methods, describe textures through frequency analysis based on Fourier transforms [
41,
42], Gabor filters [
43,
44,
45] and wavelets [
46,
47,
48].
In the last few years, deep learning techniques and, more specifically, convolutional neural networks have presented remarkable results in computer vision applications [
49,
50,
51,
52,
53] and naturally, in view of the significant results, these methods were also applied in image texture analysis. However, even though many applications related to textures in computer vision involving deep learning deal with texture classification [
54,
55,
56,
57,
58,
59,
60,
61,
62] and texture synthesis [
63,
64,
65], only a few papers present deep learning techniques applied to texture segmentation. In [
66], a two-dimensional long short-term memory (LSTM) network was proposed to classify each pixel of an image according to a predefined class, where the spatial recurrent behavior of the network made it possible to consider neighborhood contributions to the final decision. A convolutional neural network was used in [
62] to segment image patches found by a region proposal algorithm through their classification. The network was used as a feature extractor and its output was used in a Fisher Vector (FV) encoding followed by a support vector machine (SVM) classifier.
In [
67], Andrearczyk and Whelan proposed a convolutional neural network with skip connections based on the fully convolutional network (FCN) [
68] to combine information from shallower and deeper layers to segment textures. In [
69], Huang et al. used a similar architecture, but they also employed texture features extracted from the images by using an empirical curvelet transform. Currently, this technique presents the best results on the Prague Texture Segmentation Datagenerator and Benchmark [
70]. Although the results presented in [
67,
69] showed a good performance, the methods were restricted to a limited number of classes of textures in the images to perform the pixel-wise classification. Karabağ et al. [
71] presented an evaluation on texture segmentation comparing a U-Net architecture with traditional algorithms, namely co-occurrence matrices, watershed method, local binary patterns, filters, and multi-resolution sub-band filtering.
Additionally, in [
72], a Siamese convolutional neural network for texture feature extraction followed by a hierarchical region merging is proposed for unsupervised texture segmentation; and in [
73], a convolutional neural network is used for one-shot texture segmentation, where a patch of texture is used to segment a whole region in another image through an encoder–decoder architecture.
This paper presents a novel method for detecting the edges between textures without the need for a prior knowledge about the types and number of texture regions in the image. Through an encoder–decoder architecture with skip connections, each pixel in the image is classified as being inside an internal texture region. In this paper, the term internal texture region refers to the internal part of a texture region of the image or in a border between two or more different textures. This way, the technique is not restricted to a specific number of texture classes and it is able to segment images with textures classes that were not present in the training stage. Moreover, the method does not need any pre-processing step and is able to separate a texture mosaic directly from the original image.
This approach is different from other pixel classification segmentation approaches in which each pixel is classified as a predefined class from a limited prior number of classes, such as the popular U-Net [
74] and SegNet [
75], and the texture segmentation networks proposed by Andrearczyk and Whelan (2017) [
67] and Huang et al. (2019) [
69].
The proposed technique is also different from an edge detector because it detects edges with a highly specific purpose. The only edges detected by the presented approach are supposed to be the boundaries between two or more textures, whereas, on the other hand, the edges in an internal texture region should be ignored, despite the internal contrast that the texture may present.
The paper is structured as follows.
Section 2 describes the neural network architecture in detail.
Section 3 presents the datasets used in the experiments.
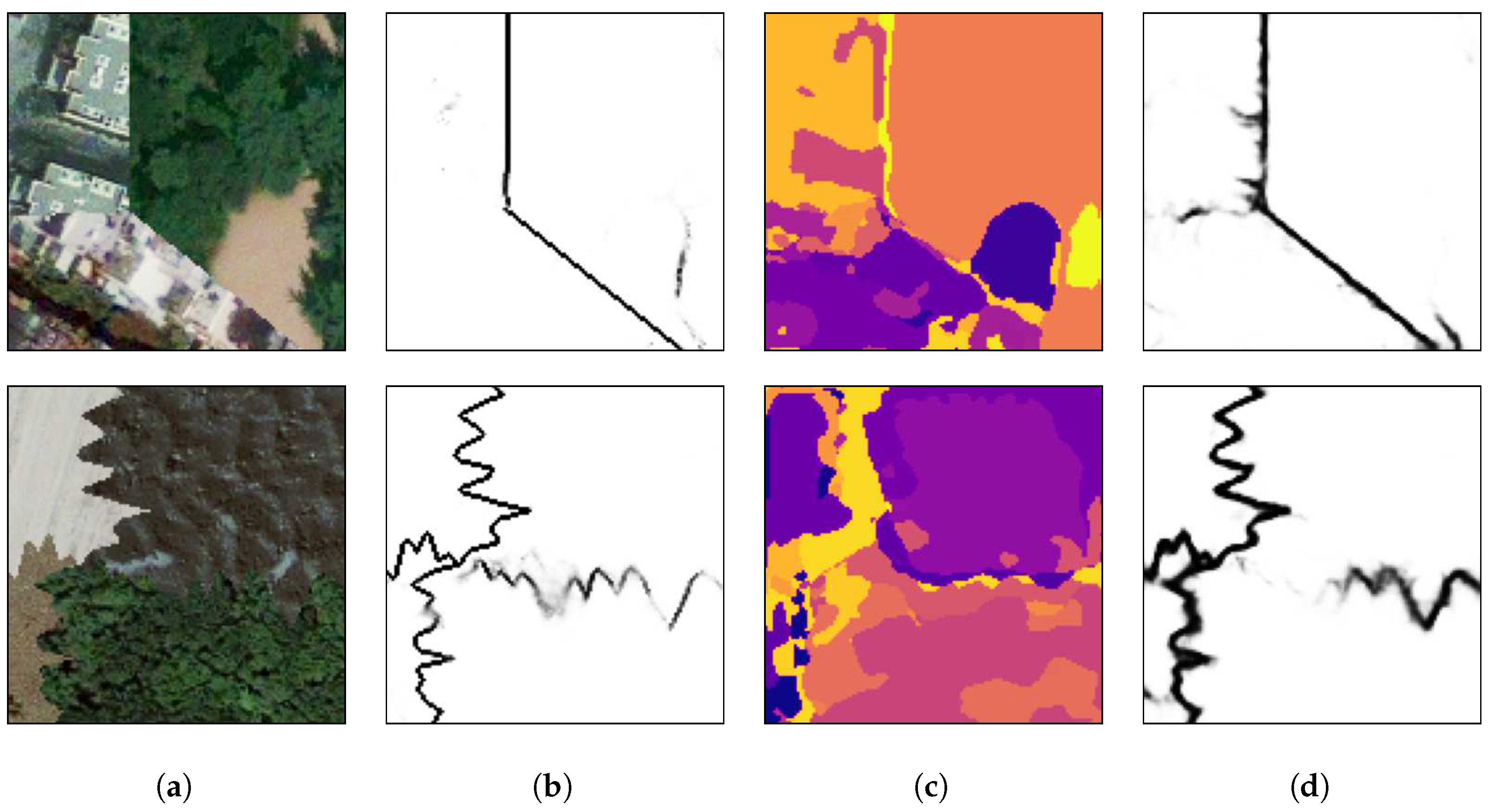
Section 4 shows the results comparing the segmentation with a conventional class-dependent convolutional neural network method and the performance of the proposed method tested on different texture sets, on mosaics containing remote sensing images and on Hematoxylin and Eosin-stained tissue images.
Section 5 concludes the paper.
2. Neural Network Architecture
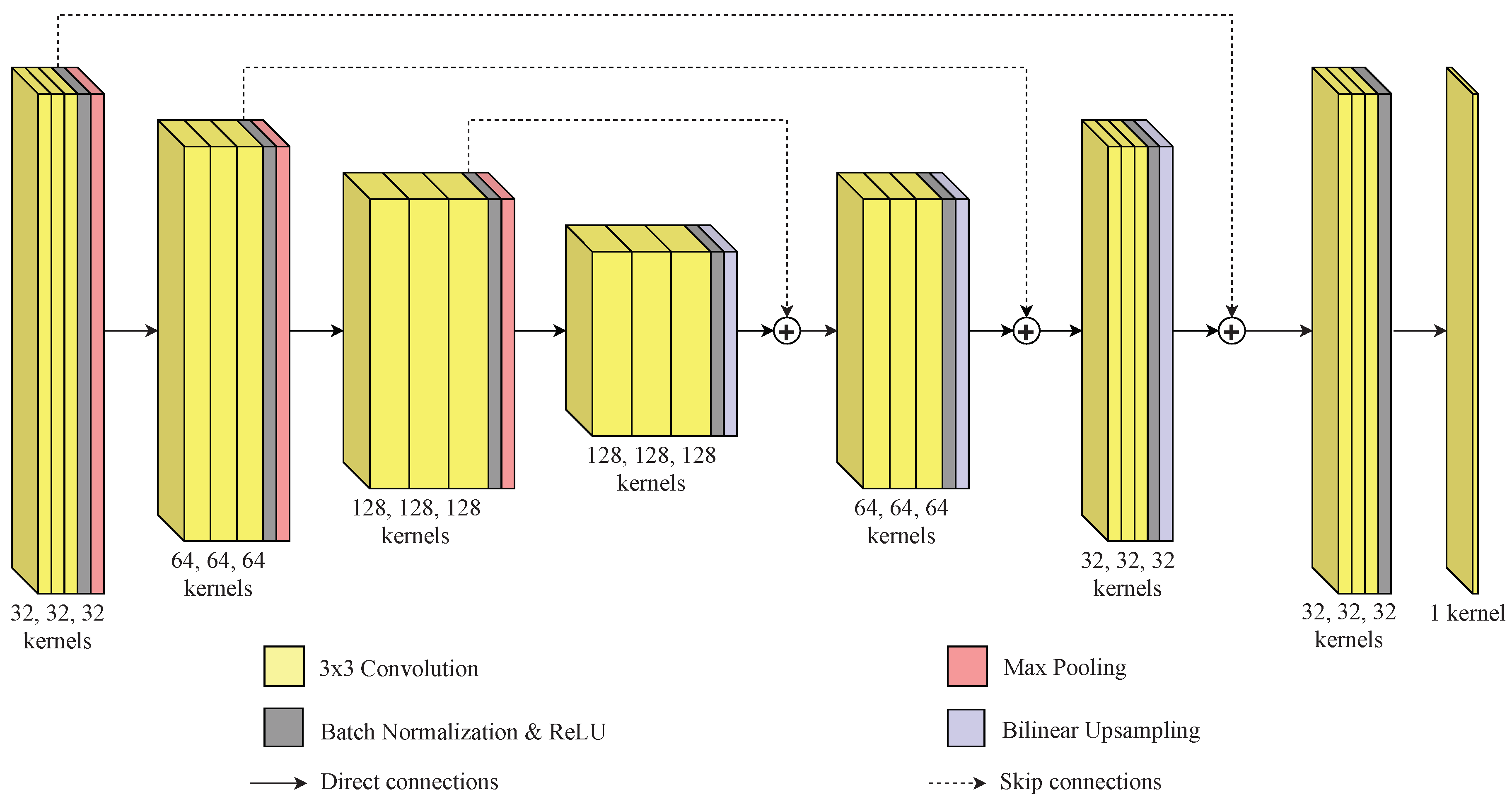
In the presented method, a convolutional neural network is used to identify the boundaries between different texture regions in an image. The convolutional neural network has an encoder–decoder architecture with skip connections that is similar to other well-known architectures in the literature, such as the U-Net [
74] and SegNet [
75]. This architecture is used because it can output an image of the same dimensions as the input image. The encoder part is responsible for mapping the main features that help on the identification of borders between different textures in the mosaic image, but due to the max pooling layers, it reduces the input dimensions. The decoder part is then responsible for retrieving the original dimensions of the image using the information from the encoder part. Moreover, the skip connections help this process by using information from different layers.
This paper proposes to perform the training process in an end-to-end manner considering images depicting boundaries between different texture regions.
Figure 1 presents the network architecture. The first three blocks are the compression blocks (the encoder part of the network), in which the weights are expected to be adjusted to suppress internal borders in texture regions while preserving the borders between different texture regions as the information is propagated to the deeper layers. This weight adjustment is performed by analyzing patches of the input image, given by the convolutional kernels in different scales which, in turn, are given by the different layers of the network.
Following the encoder part, the expansion (or decoder) part of the network is composed by three blocks and is responsible for recovering the information from the receptive fields in the contraction blocks in order to produce an image with the same dimensions as the input image. In addition, skip connections between the contraction part and the expansion part are used so that the network can use information from different levels, combining the information of different layers to produce the output. Finally, a final processing block and an output layer form the last part of the network.
Each compression block is composed of three convolutional layers, a batch normalization layer which reduces the internal covariate shift [
76] and accelerates the training [
77], a rectified linear unit (ReLU) activation function [
78] layer, and a maximum pooling layer that reduces the size of the input by half. The number of filters in the convolutional layers of each compression block is 32, 64, and 128, respectively.
The expansion blocks follow the same structure of three convolutional layers, a batch normalization layer, and a ReLU layer. However, instead of a maximum pooling layer, they have an upsampling layer that duplicates the size of the input using a bilinear interpolation function. The first expansion block follows the last compression block such that it is directly connected to its corresponding receptive field dimension at the compression step. The two last expansion layers combine the information from their previous expansion layer with the output of its corresponding receptive field dimension at the compression block, before the maximum pooling operation, through the sum of the filters. The number of filters in the convolutional layers of each expansion layer is 128, 64, and 32, respectively.
The input of the final processing layer block is the sum of the output of the last expansion block with the output of the first compression block before the maximum pooling operation. This block is formed by three convolutional layers with 32 filters each, a batch normalization layer, and a ReLU layer. Finally, at the end of the network there is an output layer with a single convolutional layer and a sigmoid activation function, since the model performs a binary classification. The input of this layer is the output of the final processing block. All the convolutional filters have the same size of
.
Table 1 summarizes the parameters of each layer.
It is worth noting that the proposed architecture is shallower than similar segmentation architectures. This is because the technique deals with textures instead of objects which are better represented by shapes whose information is represented in the deeper layers of convolutional neural networks [
6].
For the training process, the objective function,
J, for this binary pixel classification is defined by the binary cross-entropy error [
79], described as:
where
N is the total number of samples,
is the target class and
is the predicted class. For a given sample, only one of the two terms,
or
, in the summation is computed, since
, and a perfect classification does not increase the cross-entropy error, because, in this case,
, if
, or
, if
, and the logarithm of the term being computed would be equal to zero.
The adjustment of the weights is performed using the Adam optimization algorithm [
80] due to its popularity and performance in recent deep learning applications, but other gradient descent algorithms or other optimization techniques could be used as well. The convolutional neural network was programmed using a TensorFlow API [
81] and the parameters used for the optimization algorithm were the default ones.
3. Texture Images Datasets
The texture images used in this paper are extracted from the Prague Texture Segmentation Datagenerator and Benchmark dataset [
70], the Brodatz textures dataset [
82], and the Describable Textures Dataset (DTD) [
83].
The Prague Texture Segmentation Datagenerator and Benchmark dataset [
70] has 114 color texture images from 10 thematic classes composed of natural and artificial textures, where each image contains a unique texture.
Figure 2 presents some of the texture images from this dataset.
The Brodatz textures dataset [
82] has 112 color texture images that are relatively distinct from each other and do not have much variation in illumination, scale, and rotation.
Figure 3 show some of the texture images from this dataset.
The Describable Textures Dataset [
83] is a larger image set with 5640 different texture images. Those textures are more challenging than the ones from the other two datasets since there is significant variation in illumination, scale, and rotation in the same image. There is also a greater number of complex images, such as faces and natural scenes.
Figure 4 presents some of the texture images from this dataset.
For the training, only 103 texture images from the Prague Texture Segmentation Datagenerator and Benchmark dataset were used for the creation of the texture mosaics. The other 11 texture images were used exclusively on the test mosaics. Moreover, texture images from the Brodatz dataset and from the Describable Textures Dataset were exclusively used for the tests.
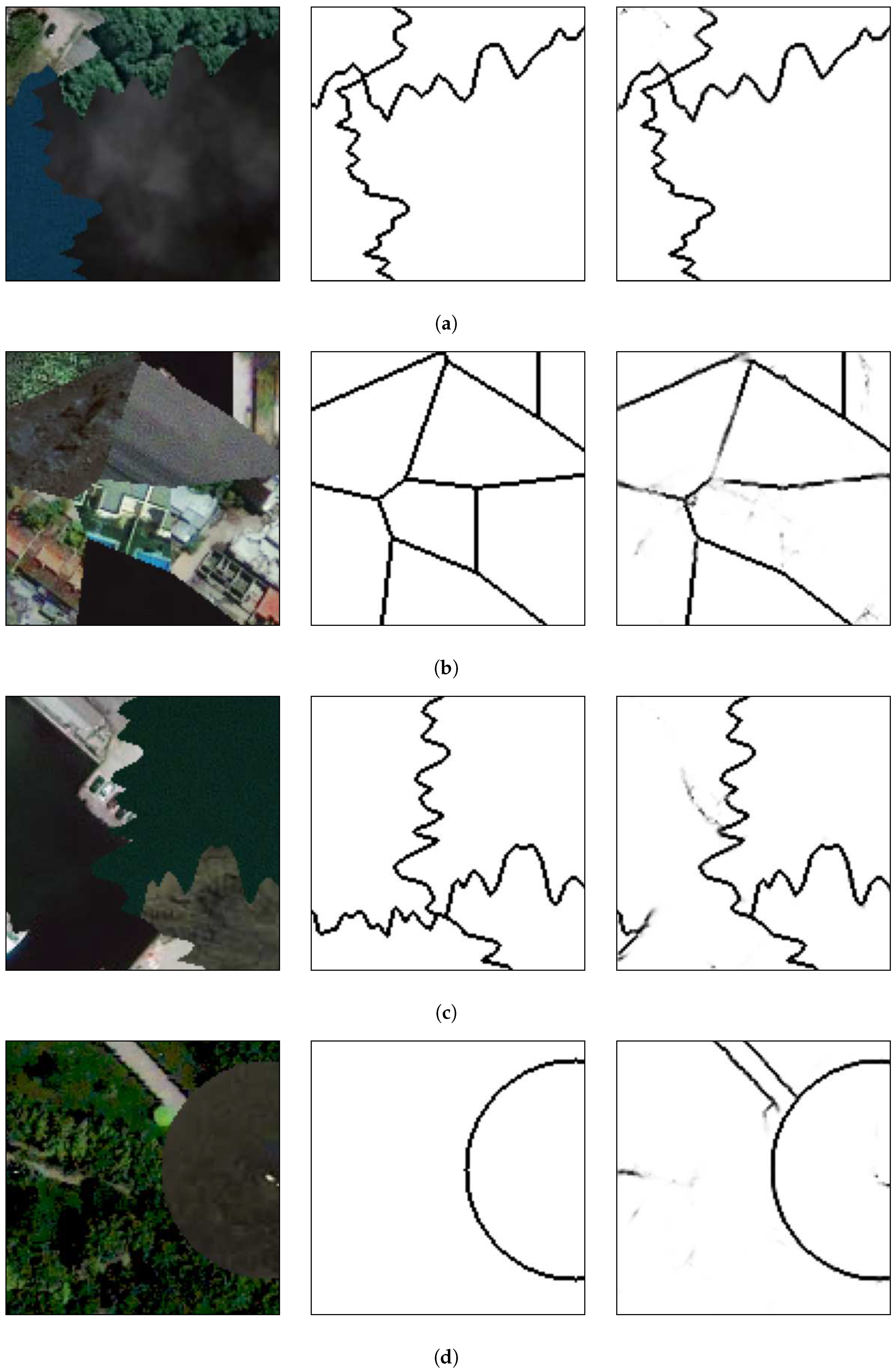
Three different types of mosaic structures types were used: Voronoi mosaics, random walk mosaics, and circular mosaics. Regarding the Voronoi structure, the mosaic images were created by placing 2 to 10 centroids in random points in the image. Afterwards, each pixel of the image was assigned to a class according to the closest centroid. The random walk mosaics were created by choosing two random points, one in the horizontal borders and another one in the vertical borders of the image and performing a random walk in the opposite direction. Finally, the circular mosaics were created by placing up to four circles on the image with random centers and radius.
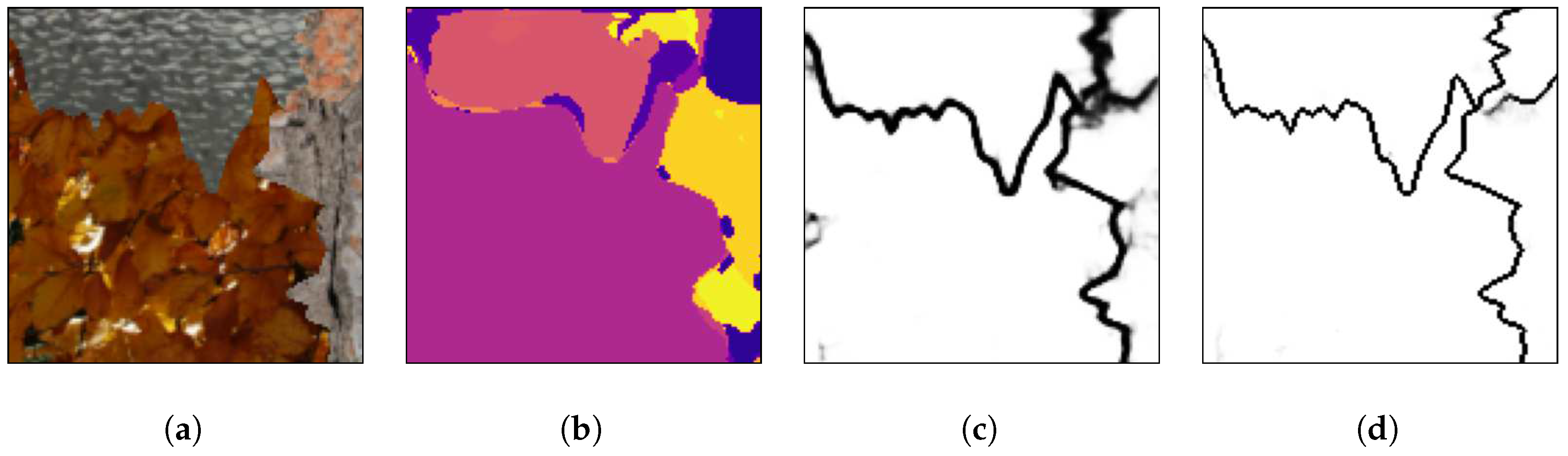
All pixels placed in a transition between two or more different regions were labeled as being in a border between two textures, therefore, the borders in the targets are always more than two pixels wide.
Figure 5 presents one mosaic structure with the different regions and the associated borders, and
Figure 6 presents one of each type of mosaic structure.
For each mosaic image from the training set, a random type of structure was chosen and after the mosaic structure was created, each region was filled with a randomly chosen image from the 103 texture images belonging to the Prague Texture Segmentation Datagenerator and Benchmark dataset. In order to increase the network robustness, an image augmentation technique was applied to each texture [
84].
The augmentation was made by randomly rotating, translating, shearing, and changing the scale of the image, applying a random uniform noise and a random image processing technique. The image processing techniques considered were adaptive histogram equalization, histogram equalization, logarithmic adjustment, sigmoid adjustment, a random Gamma correction, a random Gaussian blurring, or an image inversion [
85]. All random parameters used for the image augmentation procedure were taken from uniform distributions.
Table 2 presents the interval limits for each procedure. The techniques of adaptive histogram equalization, histogram equalization, logarithmic adjustment, and sigmoid adjustment used the default parameters of the scikit-image library [
86].
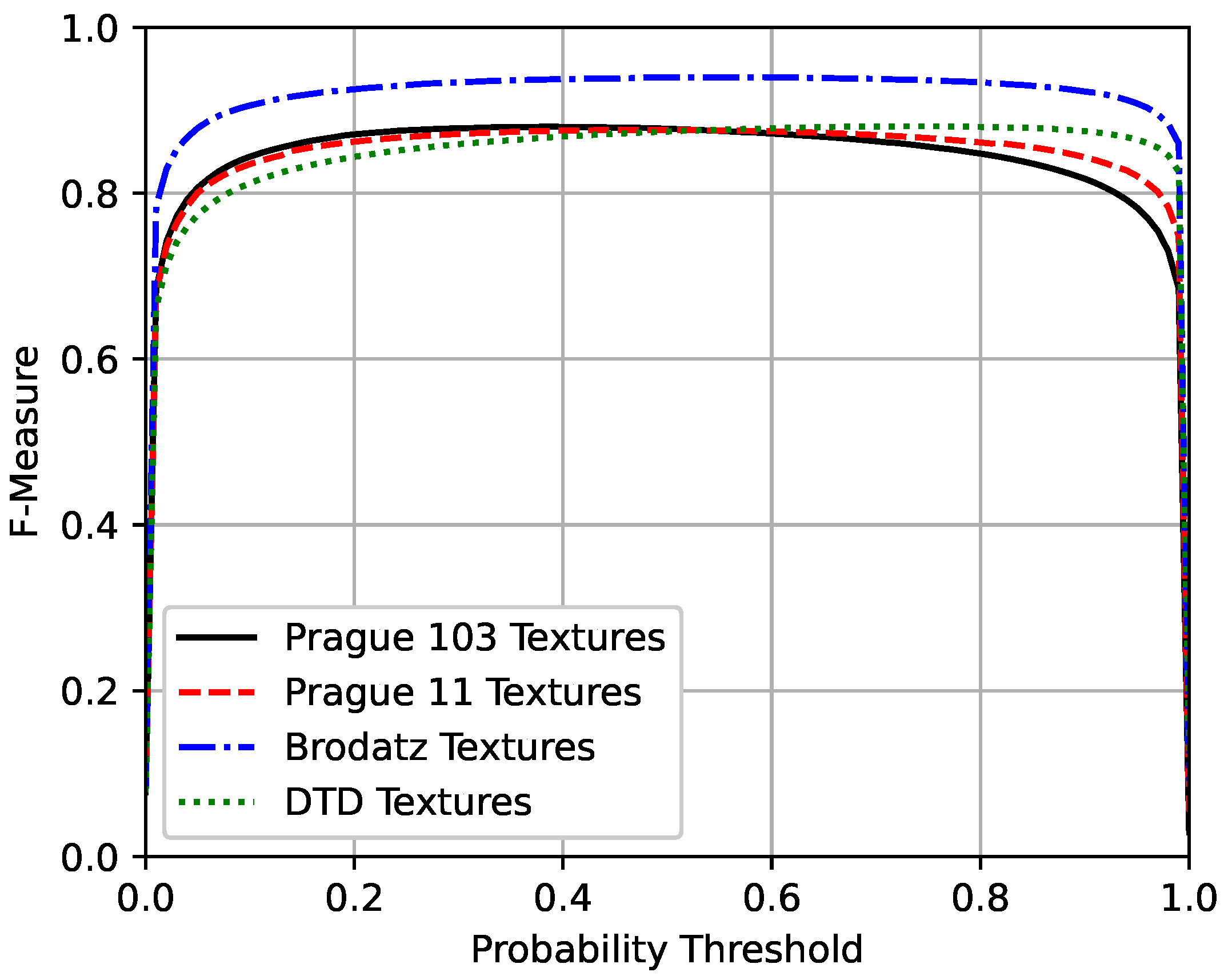
With this procedure, 100,000 different training mosaics were created. Four different test sets were created with 10,000 mosaics each. The first one contained textures from the 103 images belonging to the Prague Texture Segmentation Datagenerator and Benchmark that were also used to construct the training mosaics, whereas the second test set had only textures from the 11 remaining texture images, from this dataset, that were not used for the training. The third and fourth test sets were filled with texture images from the Brodatz and Describable Textures Dataset, respectively. It is important to note that each individual mosaic image from the training and test sets had a different mosaic structure. This was done in order to prevent the network from learning the mosaic structure instead of the separation of textures.

 ,
, 





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}