Seeing Pedestrian in the Dark via Multi-Task Feature Fusing-Sharing Learning for Imaging Sensors


Abstract
:1. Introduction
- (i)
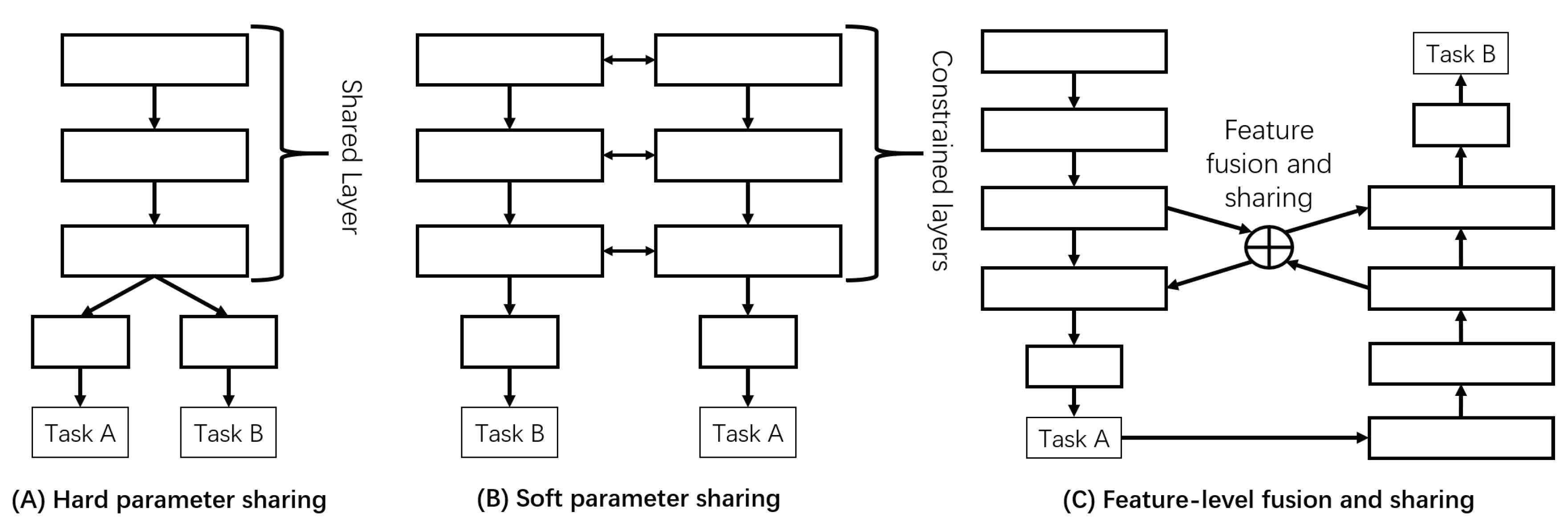
- Different from most commonly used multi-task learning methods with a parameter sharing mechanism for deep learning, we propose a novel multi-task learning method with feature-level fusion and sharing mechanism in the serial tasks. The proposed multi-task learning method is used in the feature-level multi-task fusion learning module to fuse the feature information of upstream and downstream tasks, and then the fused features are learned for each tasks to boost upstream and downstream tasks performance simultaneously.
- (ii)
- A novel Self-Calibrated Split Attention Block is proposed, named “SCSAB”, which combines Self-Calibrated convolution layer and Split Attention mechanism. SCSAB further improves the ability of SPMF to detect pedestrians in the dark.
2. Related Work
2.1. Multi-Task Learning in Deep Learning
2.2. Self-Calibrated Convolutions and Split Attention Network
3. Proposed Methods
3.1. Network Architecture
3.2. Self-Calibrated Split Attention Block (SCSAB)
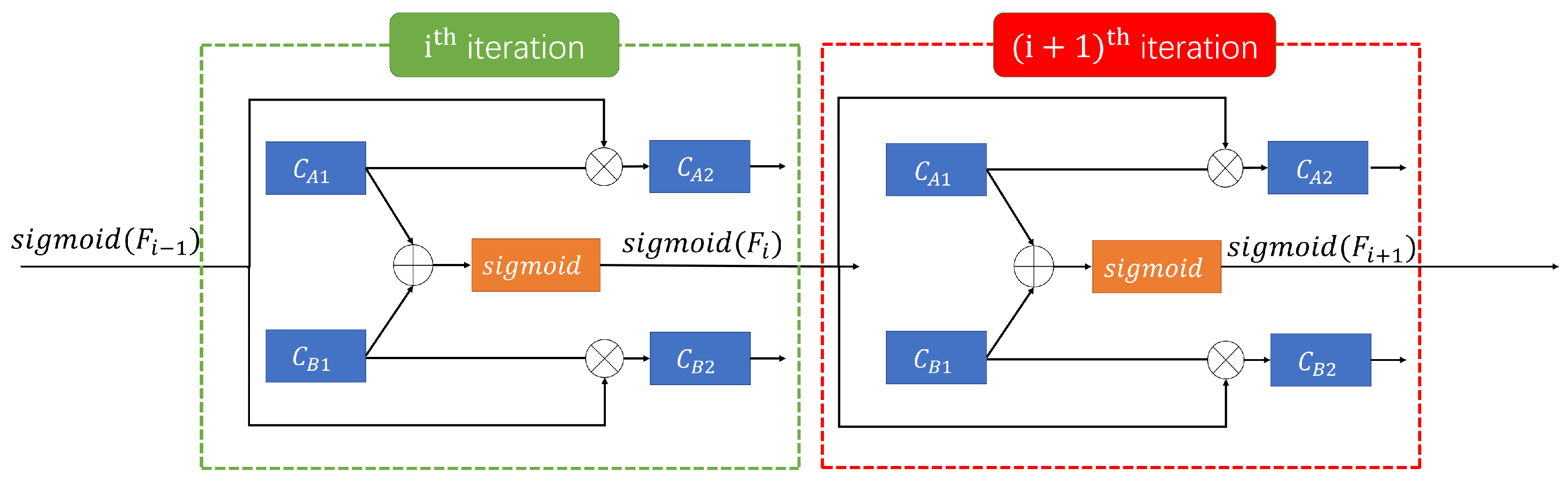
3.3. Multi-Task Learning with Feature-Level Fusion and Sharing
3.4. Image Relighting Subnetwork
3.5. Pedestrian Detection Subnetwork
3.6. Feature-Level Multi-Task Fusion Learning Module
4. Experiments and Discussion
4.1. Dataset and Implementation Details
4.2. Ablation Experiments
4.3. Comparison with State-of-the-Art
4.3.1. End-to-End Testing Mode
4.3.2. Cascade Testing Mode
4.3.3. Visual Results on Real-World Images
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Ross, G.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- GAO, F.; LIU, A.; LIU, K.; YANG, E.; HUSSAIN, A. A novel visual attention method for target detection from SAR images. Chin. J. Aeronaut. 2019, 32, 1946–1958. [Google Scholar] [CrossRef]
- Gao, F.; Ma, F.; Wang, J.; Sun, J.; Yang, E.; Zhou, H. Visual Saliency Modeling for River Detection in High-Resolution SAR Imagery. IEEE Access 2018, 6, 1000–1014. [Google Scholar] [CrossRef] [Green Version]
- Shao, Z.; Wu, W.; Wang, Z.; Du, W.; Li, C. SeaShips: A Large-Scale Precisely Annotated Dataset for Ship Detection. IEEE Trans. Multimed. 2018, 20, 2593–2604. [Google Scholar] [CrossRef]
- Sermanet, P.; Kavukcuoglu, K.; Chintala, S.; Lecun, Y. Pedestrian Detection with Unsupervised Multi-stage Feature Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, Oregon, 9 April 2013; pp. 3626–3633. [Google Scholar]
- Shen, J.; Zuo, X.; Yang, W.; Prokhorov, D.; Mei, X.; Ling, H. Differential Features for Pedestrian Detection: A Taylor Series Perspective. IEEE Trans. Intell. Transp. Syst. 2019, 20, 2913–2922. [Google Scholar] [CrossRef]
- Paolanti, M.; Romeo, L.; Liciotti, D.; Cenci, A.; Frontoni, E.; Zingaretti, P. Person Re-Identification with RGB-D Camera in Top-View Configuration through Multiple Nearest Neighbor Classifiers and Neighborhood Component Features Selection. Sensors 2018, 18, 3471. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Liao, S.; Hu, W.; Liang, X.; Chen, X. Learning Efficient Single-stage Pedestrian Detectors by Asymptotic Localization Fitting. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 618–634. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Liu, W.; Liao, S.; Ren, W.; Hu, W.; Yu, Y. High-Level Semantic Feature Detection: A New Perspective for Pedestrian Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5182–5191. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Law, H.; Teng, Y.; Russakovsky, O.; Deng, J. CornerNet-Lite: Efficient Keypoint Based Object Detection. arXiv 2019, arXiv:1904.08900. [Google Scholar]
- Kruthiventi, S.S.S.; Sahay, P.; Biswal, R. Low-light pedestrian detection from RGB images using multi-modal knowledge distillation. In Proceedings of the IEEE International Conference on Image Processing, Beijing, China, 17–20 Spetember 2017; pp. 4207–4211. [Google Scholar]
- Ruder, S. An Overview of Multi-Task Learning in Deep Neural Networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- Collobert, R.; Weston, J. A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 June 2008; pp. 160–167. [Google Scholar]
- Ramsundar, B.; Kearnes, S.M.; Riley, P.; Webster, D.; Konerding, D.E.; Pande, V.S. Massively Multitask Networks for Drug Discovery. arXiv 2015, arXiv:1502.02072. [Google Scholar]
- Caruana, R. Multitask Learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Caruana, R. Multitask Learning: A Knowledge-Based Source of Inductive Bias. In Proceedings of the Tenth International Conference on Machine Learning, San Francisco, CA, USA, 27–29 June 1993; pp. 41–48. [Google Scholar]
- Long, M.; Wang, J. Learning Multiple Tasks with Deep Relationship Networks. arXiv 2015, arXiv:1506.02117. [Google Scholar]
- Misra, I.; Shrivastava, A.; Gupta, A.; Hebert, M. Cross-Stitch Networks for Multi-Task Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3994–4003. [Google Scholar]
- Gao, Y.; Ma, J.; Zhao, M.; Liu, W.; Yuille, A.L. NDDR-CNN: Layerwise Feature Fusing in Multi-Task CNNs by Neural Discriminative Dimensionality Reduction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 21–25 June 2019; pp. 3205–3214. [Google Scholar]
- Gao, Y.; Bai, H.; Jie, Z.; Ma, J.; Jia, K.; Liu, W. MTL-NAS: Task-Agnostic Neural Architecture Search Towards General-Purpose Multi-Task Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 11543–11552. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Jiang, K.; Wang, Z.; Yi, P.; Wang, G.; Lu, T.; Jiang, J. Edge-Enhanced GAN for Remote Sensing Image Superresolution. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5799–5812. [Google Scholar] [CrossRef]
- Wang, Z.; Yi, P.; Jiang, K.; Jiang, J.; Han, Z.; Lu, T.; Ma, J. Multi-Memory Convolutional Neural Network for Video Super-Resolution. IEEE Trans. Image Process. 2019, 28, 2530–2544. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Wang, Z.; Luo, Y.; Xiong, Z. Separability and Compactness Network for Image Recognition and Superresolution. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3275–3286. [Google Scholar] [CrossRef] [PubMed]
- Yi, P.; Wang, Z.; Jiang, K.; Shao, Z.; Ma, J. Multi-Temporal Ultra Dense Memory Network for Video Super-Resolution. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 2503–2516. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Wang, C.; Feng, J. Improving Convolutional Networks with Self-Calibrated Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10096–10105. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Zhang, Z.L.; Lin, H.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. ResNeSt: Split-Attention Networks. arXiv 2020, arXiv:2004.08955. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 510–519. [Google Scholar]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep Retinex Decomposition for Low-Light Enhancement. In Proceedings of the British Machine Vision Conference. British Machine Vision Association, Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Alejandro, N.; Jia, D. Pixels to Graphs by Associative Embedding. In Advances in Neural Information Processing Systems 31; Curran Associates, Inc.: Long Beach, CA, USA, 2017; pp. 2171–2180. [Google Scholar]
- Zhang, S.; Benenson, R.; Schiele, B. CityPersons: A Diverse Dataset for Pedestrian Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4457–4465. [Google Scholar]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian Detection: An Evaluation of the State of the Art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbones | Parameters |
|---|---|
| Hourglass-54 | 116.97 M |
| SCSAB-Hourglass | 100.74 M |
| SCSAB-HourglassLite | 50.18 M |
| Backbones | (%) | ||
|---|---|---|---|
| IoU = 0.5 | IoU = 0.75 | IoU = 0.5:0.95 | |
| Hourglass-54 | 15.9 | 62.3 | 64.8 |
| SCSAB-Hourglass | 12.5 | 56.6 | 58.8 |
| SCSAB-HourglassLite | 11.7 | 57.2 | 60.4 |
| Methods | (%) | ||
|---|---|---|---|
| IoU = 0.5 | IoU = 0.75 | IoU = 0.5:0.95 | |
| CSP [15] | 24.8 | 64.4 | 59.9 |
| ALFNet [13] | 35.6 | 62.5 | 62.6 |
| CenterNet [14] | 22.8 | 64.7 | 62.7 |
| CornerNet [16] | 40.2 | 79.9 | 78.0 |
| CornerNet-Saccade [17] | 35.3 | 76.6 | 77.8 |
| SPMF (Ours) | 12.5 | 56.6 | 58.8 |
| SPMF-Lite (Ours) | 11.7 | 57.2 | 60.4 |
| Methods | (%) | ||
|---|---|---|---|
| IoU = 0.5 | IoU = 0.75 | IoU = 0.5:0.95 | |
| RetinexNet+CSP [15] | 31.5 | 56.7 | 59.3 |
| RetinexNet+ALFNet [13] | 33.5 | 59.6 | 60.1 |
| RetinexNet+CenterNet [14] | 24.1 | 65.9 | 64.3 |
| RetinexNet+CornerNet [16] | 39.9 | 77.9 | 76.5 |
| RetinexNet+CornerNet-Saccade [17] | 29.9 | 71.4 | 73.1 |
| SPMF (Ours) | 12.5 | 56.6 | 58.8 |
| SPMF-Lite (Ours) | 11.7 | 57.2 | 60.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Lu, T.; Zhang, T.; Wu, Y. Seeing Pedestrian in the Dark via Multi-Task Feature Fusing-Sharing Learning for Imaging Sensors. Sensors 2020, 20, 5852. https://doi.org/10.3390/s20205852
Wang Y, Lu T, Zhang T, Wu Y. Seeing Pedestrian in the Dark via Multi-Task Feature Fusing-Sharing Learning for Imaging Sensors. Sensors. 2020; 20(20):5852. https://doi.org/10.3390/s20205852
Chicago/Turabian StyleWang, Yuanzhi, Tao Lu, Tao Zhang, and Yuntao Wu. 2020. "Seeing Pedestrian in the Dark via Multi-Task Feature Fusing-Sharing Learning for Imaging Sensors" Sensors 20, no. 20: 5852. https://doi.org/10.3390/s20205852
APA StyleWang, Y., Lu, T., Zhang, T., & Wu, Y. (2020). Seeing Pedestrian in the Dark via Multi-Task Feature Fusing-Sharing Learning for Imaging Sensors. Sensors, 20(20), 5852. https://doi.org/10.3390/s20205852