1. Introduction
Simultaneous Localization and Mapping (SLAM), one of the main challenges for autonomous driving technology, involves a system that simultaneously performs the localization of the vehicle itself and the map building without any prior knowledge [
1]. In order to achieve this purpose, SLAM relies on various types of sensors to acquire environmental information. Among the perception sensors, Light Detection And Ranging (LiDAR) sensor is widely used because it does not suffer from the failures caused by illumination changes and can provide high-resolution point cloud for the surrounding environments. The point clouds mainly describe the geometric information of the surroundings without semantic information. As a consequence, the map from the LiDAR-based SLAM only contains the geometry information of the environments [
2].
Recently, in addition to the geometry information, LiDAR point clouds can provide the semantic information owing to the success of deep neural network in point classification tasks [
3]. Many deep learning-based methods have been proposed to classify the point cloud into predefined semantic classes such as buildings, vehicles, trees, and poles using various deep neural network-based approaches. Moreover, these methods demonstrated success in their online segmentation performance.
Under this background, the deep learning-based semantic segmentation methods have been recently adopted for the LiDAR-based SLAM problem. There are several advantages to the combination of these two technologies. First of all, the inclusion of semantic information within an environmental map provides a much greater range of functionality for autonomous vehicles than geometry alone [
4]. For example, the semantic information in the map allows the autonomous vehicles to know what objects are around them even when the sensors cannot detect the objects, which give a cue for the drivable region. Secondly, semantic information is also useful for the mapping process. The point cloud registration, key technology for LiDAR-based SLAM, estimates the relative transformation between two consecutive poses by matching the point clouds from the poses [
5]. If the environments only consist of static objects, the point cloud registration can provide an accurate transformation result. However, in real driving environments, there are a lot of dynamic objects which cause negative effects by moving during data acquisition [
6]. In this situation, the semantic segmentation methods help to distinguish the dynamic objects because they provide the class of each point such as a car, pedestrian, and so on [
7]. Another advantage of the semantic segmentation for the SLAM is that it can make the corresponding pairs for the point cloud registration. When the consecutive point clouds are segmented with their semantic information, the point cloud registration can be performed between the points classified as the same class, which improves the registration performance.
However, there are some considerations for addressing the semantic segmentation for the SLAM algorithm. Although the semantic segmentation algorithms provide the semantic information of the surrounding points, the dynamic objects cannot be clearly distinguished only using the semantic information. The points segmented by car have the potential to move, however, they are not always dynamic objects. For example, under specific situations such as parking lot, the parked vehicles may help the point cloud registration as the static objects. Besides, a more important factor is that semantic segmentation results always contain their classification uncertainty caused by the characteristics of the segmentation algorithms as shown in
Figure 1. In this figure, RangeNet++ [
8] is used for semantic segmentation. Even though RangeNet++ is one of the state-of-the-art algorithms for semantic segmentation, the classification success rate cannot be 100 percent. As previously mentioned, when the point clouds have their own semantic information, the registration performance can be improved by matching the points with the same class. However, due to the classification uncertainty, even though two matching points from consecutive scans are classified as the same class, they cannot be directly used for the registration pair, and vice versa, because the true classes of the points are unknown. Moreover, due to this uncertainty, the same point in multiple-scans from different time steps can represent different semantic information. In that case, the class of the point cannot be determined, which causes the semantic ambiguity of the semantic map.
In this paper, we propose a semantic segmentation-based LiDAR SLAM system considering the uncertainty of the semantic segmentation. The state-of-the-art deep learning-based semantic segmentation algorithms are used for the per-frame point cloud classification. The extracted semantic information is fed into the semantic registration module. In order to reflect the uncertainty of the segmentation algorithms, this paper presents the probability model-based point cloud registration for semantic mapping. In the proposed semantic registration algorithm, two probability models are presented. One is for considering the
movability of each class, and the other is for the classification performance. For more detail, the probability for the classification performance can describe the confidence of the registration pairs of each class. With the proposed probability model-based point cloud registration algorithm, the ambiguity of both distinction of the dynamic objects and the classification results can be considered. Using the result of the semantic registration, Graph SLAM provides the vehicle poses by optimizing the graph structure which consists of nodes (vehicle pose) and edges (the geometric relationship between the nodes). After the pose optimization, semantic segmented point cloud from each pose should be accumulated for the semantic map generation. The multiple scans can indicate different classes for one point due to the uncertainty. In order to determine the class, this paper proposes the probability-based point cloud accumulation method. During the accumulation process, the semantic information of each point is determined by the proposed probability model for the semantic map. The proposed algorithm is evaluated with both the open benchmark datasets (KITTI [
9]) and large-scale datasets from real driving environments.
The main contributions of this paper are summarized as follows:
This paper proposes the probability model-based point cloud registration method in order to consider the two types of uncertainty; movement probability of each class and classification probability of the semantic segmentation algorithms.
This paper proposes the probability-based point cloud accumulation method in order to determine the semantic information of the semantic map.
The remainder of the paper is organized as follows.
Section 2 is about related previous studies and
Section 3 presents the system architecture of the proposed mapping system.
Section 4,
Section 5 and
Section 6 describe the detailed methods of the proposed semantic mapping system considering the uncertainty.
Section 7 provides the experimental results and
Section 8 is for the conclusion.
3. System Architecture
The overall system architecture of the proposed semantic mapping consists of three steps as shown in
Figure 2. The first step is an online semantic segmentation of the LiDAR point cloud. The previously proposed deep neural network-based semantic segmentation algorithms are used for the segmentation.
The second step is the uncertainty probability-based point cloud registration. Using the prior probabilities, the class probability models which represent the uncertainty are proposed. There are two probability models in the proposed class probability;
Intra-class probability and
Inter-class probability. The
Intra-class probability is for considering the movable objects, which is derived from the movement probability. The
Inter-class probability is for the registration confidence between the classes, which is come from the classification probability. The modeled class probability is used for point cloud registration. The point cloud registration estimates the transformation relationship between two point clouds. Among the various registration methods, Normal Distribution Transform (NDT) is used in this paper, because it has been proved that NDT registration is robust in real driving environments [
40]. In order to reflect the uncertainty into the NDT registration, this paper proposes the semantic registration which combines the class probability and NDT registration. Instead of registration between the same class’ points, the proposed semantic registration algorithm performs the probabilistic matching to resolve the ambiguity from the uncertainty of the semantic segmentation algorithms.
The final step of the proposed mapping framework is semantic mapping. The transformation between two point clouds from the semantic registration is used for the Graph SLAM with additional sensor information such as motion and low-cost GNSS for the pose optimization. In the Graph SLAM, all the poses are represented as nodes. The nodes are optimized based on edge constraints which are generated by the relationship between two nodes such as point cloud registration, motion information, and low-cost GNSS. As a result, the semantic map is generated by accumulating the semantic point clouds using the optimized poses. However, because the semantic information of the segmented point clouds contains uncertainty, the conventional accumulation causes the semantic ambiguity of the generated semantic map. Instead, in the proposed framework, the classification probability is used for the accumulation step. The semantic information of arbitrary point is consistently updated by the proposed probability model which is based on the classification probability.
4. Deep Neural Network-Based Semantic Segmentation
The first step of the proposed mapping system is the online semantic segmentation of LiDAR point clouds. The LiDAR point clouds are segmented into semantic classes using the deep neural network-based approaches. This section briefly introduces the deep learning-based point cloud semantic segmentation algorithms. In this paper, three deep neural networks are used; SqueezeSeg [
25], SqueezeSegV2 [
26], and RangeNet++ [
8]. The reason why these networks are chosen is that they were demonstrated by the SemanticKITTI [
41], however, it is not an important topic in this paper, because the main purpose of this paper is to consider the uncertainty of arbitrary semantic segmentation algorithm for semantic mapping. Those models project 3-D point cloud into 2-D image and apply 2-D convolutional neural network for semantic segmentation. For the details of each model, Let
N is the number of points in the point cloud,
are the height and width of the 2-D projected image and
C is the channel of the 2-D projected image as shown in
Figure 3a. First, all three models go through the same pre-process called spherical projection. The spherical projection maps each point
to image coordinate
via Equation (
1).
where
r is the range of each point
and
is the vertical field-of-view of the sensor. As a result of the spherical projection, 3-D point cloud converts to 2-D image
. In this paper, we define 5 channels;
x,
y,
z,
intensity and
range of the point.
The next step is the semantic segmentation of 2-D projected image with their own backbones as described in
Figure 3b. SqueezeSeg model proposes the light-weight backbone based on the fire module. SqueezeSegV2 model designs the noise-robust backbone by adding the Contextual Aggregation Module (CAM) to the backbone of the SqueezeSeg model. RangeNet++ refers to the DarkNet backbone which is the state-of-the-art model in image semantic segmentation task and refined the segmentation result from the DarkNet backbone with GPU-enabled KNN algorithm. Finally, those models obtain 3-D semantic segmentation results by re-projecting the 2-D segmented image into the original 3-D point cloud as shown in
Figure 3c.
5. Uncertainty Probability-Based Point Cloud Registration
The objective of this paper is to reflect the uncertainty of the semantic segmentation algorithms into the semantic mapping framework. The uncertainty is divided into two categories; (1) movement probability of each class, (2) classification probability of the semantic segmentation algorithms. In order to deduce the uncertainty probability model, this paper defines the prior knowledge based on the pre-trained deep learning models. SemanticKITTI open datasets provide a set of point clouds with their semantic information and movement information. Based on the labeled point clouds, we train the deep semantic segmentation networks and extract the movability of each class and confusion matrix. The movability can indicate the movement probability of each class, and the confusion matrix can represent the classification probability of the semantic segmentation algorithms. Based on the prior knowledge, two probability models are proposed, and the probabilities are combined into the point cloud registration to reflect the uncertainty.
5.1. Prior Knowledge Definition
In order to model the uncertainty of the semantic segmentation algorithms, two types of prior knowledge are defined offline: the movability of each class and confusion matrix. The prior knowledge is calculated using the SemanticKITTI dataset. The SemanticKITTI contains the annotated point cloud into 25 classes collected from 22 different driving environments such as urban roads, highways, and countryside as described in
Figure 4. The classes include static objects such as building, pole, and parked car as well as dynamic objects like moving car, person, and so on.
The overall process for the prior knowledge definition is shown in
Figure 5. The
movability of the class represents the probability that objects belonging to that class will move. As the SemanticKITTI dataset contains the annotations that the point is moving or not, the movability of the class can be determined by the ratio of the total number of points in the class and the number of moving points in the class. The
confusion matrix indicates the class-by-class performance of the semantic segmentation of the test scene. Each row of the matrix represents the number of points of a predicted class while each column represents the number of points of a ground truth class in the SemanticKITTI as shown in
Figure 6. As same as
Section 4, SqueezeSeg, SqueezeSegV2, and RangeNet++ are used for the prior knowledge. In order to obtain the confusion matrix of these networks, three representative environments are selected to cover the various driving environments; urban road, highways, and countryside. When we test the segmentation algorithm in the urban road environment, the model is trained by other datasets in the SemanticKITTI, which is the same for other environments. Finally, three different confusion matrices can be obtained per one segmentation model and those matrices can represent the segmentation performance of the model in overall driving environments.
5.2. Class Probability Model
Based on the prior knowledge, two probability models are proposed. The first probability is for the uncertainty about the ambiguity of the movability of the semantic classes. Because moving objects have negative effects on the point cloud registration, they should be eliminated during the mapping process. The semantic segmentation algorithm can help to distinguish the moving points by their semantic classes, however, only the semantic information is not enough to achieve the purpose. In order to model the movability of each class,
Intra-class probability is proposed in this paper. The intra-class probability is directly modeled by the movement probability from the prior knowledge as described in Equation (
2).
As described in
Section 5.1, the movability is extracted from the SemanticKITTI dataset which can be divided into three representative environments. Because the movability can be quite different by the environments, the intra-class probability is selectively utilized according to the environments.
The second probability models the uncertainty about the classification performance of the semantic segmentation algorithms. In ideal, if semantic segmentation does not fail to segment the points for all classes, the registration can be performed only between the same class’ points. However, due to inaccuracies in classification, the confidence of the registration pair for points of the same class cannot be determined as 100%. In order to solve the ambiguity from the classification performance,
Inter-class probability is modeled to assign confidence for registration pairs between classes. Let’s assume that two points in registration pair
are segmented by the class
and
, however, the true semantic class is unknown. Under the assumption the registration pair should represent the same class, the inter-class probability is defined by the probability that two points have the same true class in this paper. For the point
, the probability which the point has the true class
can be represented by a conditional probability
, and
for the point
. As a result, the inter-class probability between the class
and
is modeled by the sum-of-product of the conditional probabilities for all the classes as described in Equation (
3).
where
is a set of the semantic classes. Because we defined the conditional probability
as the probability of the class
when the point is segmented as class
, it is obtained by the confusion matrix (
Figure 6) in the form of
.
In summary, the intra-class probability is the internal probability of unit class which can represent the movability, and the inter-class probability is the cross probability of two classes which can determine the confidence for the registration between the classes.
5.3. Semantic Point Cloud Registration
5.3.1. Basic Normal Distribution Transform (NDT)
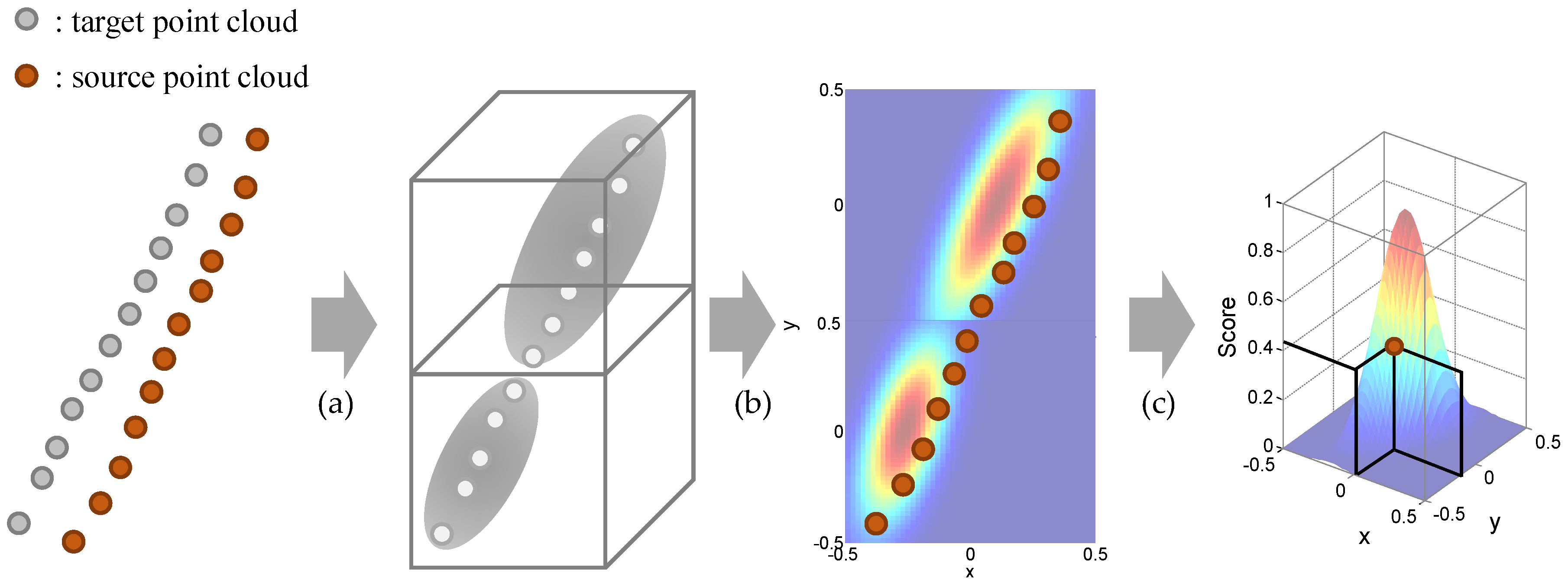
In this paper, the Normal Distribution Transform (NDT) is used for the point cloud registration. The NDT is one of the point cloud registration methods which provide the transformation relationship between two consecutive point clouds. The NDT starts by transforming the target point clouds residing within a voxel into a normal distribution as shown in
Figure 7a. A mean
and an covariance matrix
are obtained by the Equation (
4).
The
represents a position vector
for
point in
voxel and
is the number of points in the voxel. With the two parameters, the point cloud in the voxel is modeled by the normal distribution
:
The purpose of the NDT is to find the optimal transformation matrix
, which maximizes the score for source point clouds
transformed by the matrix
. The transformed source point clouds
can be obtained by the transformation relationship
as the following equation:
where
and
is the rotation and translation matrix, respectively. After that, the transformed points are projected into the normal distribution of the corresponding voxels as shown in
Figure 7b. With the projected points, the cost function for the NDT is defined as summation of the negative-score functions as shown in Equation (
1) and
Figure 7c.
where
and
are the mean and covariance of the corresponding voxel for the point
. In order to find the optimal 3-D transformation matrix
, Newton’s method is adopted as explained in [
42].
5.3.2. Semantic NDT Based on the Class Probability
Based on the class probability described in
Section 5.2, this subsection provides a detailed method of the semantic NDT. There are two key points of the semantic NDT; Multi-modal normal distribution for the segmented classes using the intra-class probability, Weighted scoring by the inter-class probability. As explained in the previous subsection, the NDT starts with the construction of the normal distribution using the target points in a voxel. Instead of generating a single normal distribution, the multi-modal distribution is constructed per one voxel as shown in
Figure 8. The number of distribution is the number of classes which points in the voxel contain. In this point, the intra-class probability is used as the scale factor for combining the multiple distributions into a multi-modal distribution, because the intra-class probability represents the movement probability of each class. The modified mathematical equation for the multi-modal distribution as described in Equations (
8) and (
9).
where the additional notation
c represents the segmented class.
describes the intra-class probability derived by the movement probability of the corresponding class and
is the normalization constant.
The next is the weighted scoring with inter-class probability. The inter-class probability modeled by a cross probability of two classes (
) represents the registration confidence between classes. In order to reflect the probability into the generated multi-modal distribution, two steps are required. The first step is to determine the maximum likelihood class of the multi-modal normal distribution of each source point. Unlike the basic NDT, in the proposed semantic NDT, one voxel contains multiple normal distributions from the segmented classes. After the projection of the source point into the multi-modal distribution, the maximum likelihood class is determined with the Equation (
10).
where
represents the likelihood of a point
with the corresponding the normal distribution’s class
in the voxel
k. As a result, the maximum likelihood class
means the class of the target distribution of the corresponding source point as described in
Figure 8b. After determining the target class
, the inter-class probability is used for the weight factor for the scoring function. The scoring function of the basic NDT (
7) is modified by the weighted form as described in Equation (
11).
where
is the class of the
source point and
describes the closest target distribution’s class.
is the inter-class probability which is obtained in
Section 5.2. As a result, the transformation can be obtained by the transformation matrix
.
7. Experiment
The proposed semantic mapping framework was evaluated in both KITTI datasets and real driving environments. The experimental evaluation is aimed to support our main contributions that 1) Probability models for the uncertainty of the deep neural network-based semantic segmentation 2) Probability model-based semantic mapping. To do this, this section consists of four sub-sections. The
Section 7.1 provides the information about experiment environments. The explanation of the SemanticKITTI and of the real driving environments including vehicle configuration are covered. Next,
Section 7.2 presents the results of deep-neural network-based semantic segmentation. This part also provides the learning parameters as well as the segmentation results. The
Section 7.3 describes the probability-based semantic registration. In this part, the prior knowledge from the SemanticKITTI is quantified as the proposed two probability models. Also, the optimized vehicle trajectory of the proposed framework is compared with other LiDAR SLAM methods using KITTI datasets and our driving data. The generated semantic map is presented in
Section 7.4. The semantic map from the proposed framework reduces the semantic ambiguity from the segmentation uncertainty by the probabilistic update of the point’s semantic class.
7.1. Experiment Environments
The SemanticKITTI provides the point-wise annotations of KITTI Odometry Benchmark. It contains over 20,000 point cloud data from Velodyne HDL-64E LiDAR with a rate of 10 Hz and those data were collected from 22 different driving environments such as urban roads, highways, and countryside. Also, the dataset annotates point cloud into 25 classes including the static objects such as building, pole, and parked car as well as the dynamic objects like moving car, person, and so on. It also provides ground truth vehicle poses from high-cost GNSS/INS. The labeled point clouds are used for training the semantic segmentation networks and for the prior knowledge definition, and the unlabeled point clouds in the KITTI datasets are used for the evaluation of the proposed algorithm. The evaluation in real driving environments is conducted using the autonomous car
A1 of Hanyang University, as shown in
Figure 11a. The test vehicle is equipped with 32-channel LiDAR, on-board sensors, and a low-cost GNSS sensor for the localization. The RTK (Real-Time Kinematic) GNSS was used for a high-cost GNSS for a reference sensor for the evaluation. The outdoor evaluation dataset includes both a highly dynamic urban scenario with a lot of moving objects and a parking lot with a lot of parked vehicles, which is challenging for the SLAM problem as shown in
Figure 11b. The proposed algorithm is run on Intel i5-4690 CPU @3.5GHz with 16GB RAM. The GPU for semantic segmentation is performed on Nvidia RTX 2080 GPU with 8GB RAM. The semantic segmentation algorithms are run within 100ms which is shorter than the LiDAR data frequency.
7.2. Semantic Segmentation
The three semantic segmentation models (SqueezeSeg, SqueezeSegV2, RangeNet++) are trained by the SemanticKITTI dataset. Among the sequences 00 to 10, sequence 08 is used for validation and the remaining sequences are used for the training, as the same with [
8]. The training is performed on Nvidia RTX 2080ti GPU. For the hyper-parameters for the training, the maximum epoch is 150, the initial learning rate is 0.001, and the learning rate decay is 0.99 per 1 epoch. The size of the projected image is (2046, 64) for laser scan data. These hyper-parameters were evaluated by the papers which proposed these semantic segmentation models [
8,
25,
26]. The studies used these parameters and provided the successful segmentation results. The segmentation results of three segmentation models for sequence 01 (Highway scene) are described in
Figure 12, in which the semantic class information is represented by color. As shown in the red markers in this figure, the algorithms cannot always provide true semantic information for the surrounding objects, which causes the uncertainty of the semantic information. Furthermore, the semantic segmentation algorithms are executed within 100 milliseconds (the data duration of the LiDAR point clouds) as shown in
Table 1.
7.3. Uncertainty Probability-Based Registration
In this part, the uncertainty of the semantic segmentation is modeled as probabilities using the prior knowledge. Again, there are two uncertainties covered in this paper: movability and classification performance. The movability is modeled by the intra-class probability and the classification performance is modeled by the inter-class probability. The modeled probabilities are used for the point cloud registration in order to reflect the uncertainty of the semantic segmentation algorithms.
7.3.1. Prior Knowledge-Based Class Probability
The intra-class probability is directly derived from the movability which is analyzed with the SemanticKITTI dataset. Because the dataset provides the independent labels for the moving objects, the movability of each sequence can be obtained by Equation (
2). However, the movability of the objects is quite different according to driving environments. For example, on the highway the movability of car is high, however, in the parking lot, the movability is relatively low. In order to consider the environmental dependency, all of the points in the SemanticKITTI dataset are categorized as scene-by-scene by three representative environments; urban roads, highways, and countryside. Consequently, three intra-class probability tables are generated for each class as shown in
Figure 13. The number of points of each environment is about 1.7 billion, 0.1 billion, and 0.9 billion for urban roads, highways, and countryside, respectively. As expected, in the highways, all of the points labeled by car, motorcyclist, and other-vehicle are moving. The reason why the movabilities of truck, person, and bicyclist are zero is that there is no point labeled by them in the SemanticKITTI. For the urban roads and countryside, most of the car-like objects are not labeled as
moving objects because they are parked. So, the intra-class probabilities for them are high, which means that the points can be highly used for the registration.
The inter-class probability is derived from the confusion matrix which represents the classification performance. In order to cover the general environments, three semantic segmentation algorithms are trained and tested for all the sequences in the SemanticKITTI. When the algorithms are tested in sequence 00, they are trained by sequence 01 to 10, and so does the rest. This training process is only for the inter-class probability, which is independent with the
Section 7.2. As a result, the total confusion matrix for one semantic segmentation algorithm is obtained by summation of the confusion matrices for all the sequences. As explained in Equation (
3), the conditional probability
called as
precision is used for the intra-class probability. The precision matrices from the confusion matrices of three deep neural networks are shown in
Figure 14. As a result, the inter-class probability for all the pairs can be calculated from Equation (
3), which is described in
Figure 15. This probability matrix is used for the weight factor of the semantic NDT as described in Equation (
11). When the classes of two matching points segmented by the algorithms are the same(values of the principal diagonal of the matrix), the probability is relatively high, however, they are not 1. On the other hand, even if the matching points are segmented as different classes, they are used for the semantic registration with their inter-class probability values because there is classification uncertainty of the semantic segmentation algorithms.
7.3.2. Semantic Registration-Based Pose Optimization
This section shows the mapping trajectories of the proposed mapping algorithm using KITTI datasets and our outdoor dataset. The proposed mapping trajectory is from the semantic registration-based pose optimization based on the two probability models (
Figure 13 and
Figure 15). The mapping trajectory is compared with two types of previous approaches; Basic LiDAR SLAM without semantic information, Semantic mapping without the explicit model of uncertainty. More specifically, LOAM [
16] is adopted for the basic LiDAR SLAM, and SuMa++ [
7] is selected for the comparison with the semantic mapping only when the RangeNet++ is used for the semantic segmentation algorithm.
Figure 16 shows the trajectory evaluation results using KITTI datasets. Three raw datasets in the KITTI are used for the evaluation in order to verify the proposed semantic mapping in the overall driving environments. These datasets were not used both for the training of semantic segmentation algorithm and for the prior knowledge definition. The raw indicates the same datasets and the column indicates the semantic segmentation algorithm. For all cases, the trajectory from the proposed algorithm (blue line) is closest to the ground truth trajectory (gray line). The outdoor evaluation results with our driving data are shown in
Figure 17. In the same manner, it is verified that the proposed mapping algorithm generates a consistent trajectory compared with previous approaches.
Because the trajectory evaluation can be insufficient due to the drift effects, the quantitative results of the proposed framework in terms of translation and rotation error are also shown in
Table 2. The translation and rotation errors are obtained by comparing the transformation relationship between the ground truth (RTK-GNSS for outdoor evaluation) and the registration results. As shown in this table, LOAM provides a lower maximum rotation error in the urban road and lower RMS translation error in the countrysides when the SqueezeSegV2 is used for the semantic segmentation algorithm. It is a reasonable result because there are a lot of buildings in the datasets and LOAM uses a feature-based registration method. Moreover, in the highway dataset, SuMa++ shows better performance in the RMS translation error and the maximum rotation error, because SuMa++ aimed at the reliable mapping in the highways including moving objects. However, the proposed algorithm provides lower transformation errors in the other scenarios including our driving data with dynamic urban roads and parking lot. In summary, the proposed algorithm is evaluated in the overall driving environments with various semantic segmentation algorithms.
7.4. Probabilistic Semantic Mapping
The final experiment result is for the probabilistic semantic mapping. The semantic map is generated by the accumulation of the segmented point cloud based on the optimized mapping trajectory. The evaluation result about the generated semantic map is shown in
Figure 18. The semantic map is built using the trajectory from the proposed algorithm with our driving data, and RangeNet++ is used for semantic segmentation. As shown in
Figure 18a, one object contains multiple semantic classes, which causes the ambiguity of the semantic map. This is because the multiple scans from different poses indicate the different semantic classes due to the classification uncertainty. In the proposed method, the precision matrix (
Figure 14) is used for the probabilistic update of the semantic class in order to reflect the classification uncertainty. The class probabilities for all classes are consistently updated by the proposed update model (Equation (
17)), consequently the semantic ambiguity is reduced as shown in
Figure 18b.
8. Conclusions
This paper proposed semantic segmentation-based LiDAR mapping reflecting the uncertainty of the deep neural network-based segmentation algorithms as probability models. The state-of-the-art semantic segmentation algorithms were used for the point cloud segmentation. The uncertainty of the segmentation was modeled by two data-based probability models; inter-class and intra-class probability. These probabilities were utilized for the point cloud registration in the proposed semantic registration. Based on the proposed registration, the mapping trajectory was optimized by Graph SLAM. The final semantic map was constructed by the proposed probabilistic accumulation of the segmented point clouds. The main advantages of the proposed mapping framework are summarized as follows:
The uncertainty of the semantic segmentation algorithms was modeled by data-driven approaches. The uncertainty about the movability of a class was quantified by the intra-class probability, and the uncertainty about classification performance was modeled by the inter-class probability. These probability models were derived from the labeled point clouds from various environments (SemanticKITTI), which means that the proposed probability models can be applied to the overall driving environments.
The semantic registration was proposed to apply the probability models to point cloud registration. Instead of using the semantic classes for the registration directly, the proposed registration combined the NDT registration and uncertainty probabilities. The intra-class probability was used to generate the multi-modal distribution and the inter-class probability played a role as the weight factor for the NDT optimization. Based on the semantic registration, the mapping trajectory was optimized by Graph SLAM with additional motion information.
The probabilistic semantic map building was proposed to reflect the uncertainty about the classification performance. In practice, because the multiple scans can indicate different classes for one point, the semantic ambiguity exists in the semantic map. In order to avoid ambiguity, this paper proposed the class probability update method using the precision matrix which represents the classification performance of the semantic segmentation algorithms. The class probability of points was consistently updated by the proposed method until the points were out of field-of-view.
The proposed mapping framework was evaluated with both KITTI datasets and outdoor driving dataset from our vehicle. First of all, the intra-class and inter-class probabilities were quantified as class-by-class tables. Next, the mapping trajectory of the proposed framework was evaluated by comparing it with representative LiDAR SLAM methods (LOAM, SuMa++). The evaluation datasets included the overall driving environments, and the proposed algorithm provided reliable trajectories. Furthermore, the transformation error of the mapping trajectory was compared with the previous algorithms. In specific environments, the previous algorithms showed better performance, however, the proposed algorithm provided lower errors in overall cases. Lastly, the generated semantic map was also verified. With the proposed probability-based mapping framework, the semantic ambiguity of the semantic map was reduced compared with the previous mapping algorithm.
Even though the proposed framework provides a reliable semantic map, there could still be semantic ambiguity due to the classification performance of the semantic segmentation algorithm. When the semantic segmentation repeatedly provided wrong semantic information for a point, the generated semantic map can indicate the wrong class of the point. In order to compensate for the problem, the authors plan to apply offline semantic segmentation to the generated semantic map. By applying the recursive segmentation, the more reliable semantic information is expected to be obtained even if the proposed semantic map contains the semantic ambiguity.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}