1. Introduction
Synthetic aperture radar (SAR) is an active remote sensor with all day and night, high-resolution, and wide-area imaging capabilities. Because of these unique capabilities, SAR is widely used in geoscience and remote sensing. Today, numerous SAR sensors are operating on spaceborne and airborne platforms and are imaging ground targets for surveillance and reconnaissance. For efficient interpretation of SAR image data, SAR automatic target recognition (SAR-ATR) system are being developed. SAR-ATR aims to detect and recognize targets, such as trucks and armored personnel carriers, in SAR images. The workflow of an end-to-end SAR-ATR system includes three stages: detection, low-level classification, and high-level classification [
1]. Once an SAR image enters the system, detectors, such as constant false-alarm rate (CFAR) detectors, locate candidate targets in the images [
2]. The region of interest (ROI), consisting of the true target and background clutter, is extracted around each candidate target. The clutter is then analyzed and filtered out in the low-level classification. Finally, the class or even the model of the target is identified in the high-level classification. In this paper, we focus on the third stage, that is, high-level classification.
Traditional SAR-ATR methods are generally classified into two categories: feature-based and model-based. Feature-based methods extract discriminative features from SAR images and train the classifiers with these features. The features can be extracted in the spatial domain, such as templates, each of which is an average representation of a target at a particular azimuth angle [
3]. Feature extraction can also be carried out in the transformation domain, where the images are transformed into low-dimensional features. There exist various transformations, such as kernel principal component analysis (KPCA) [
4], structure-preserving projection [
5], and locality discriminant projection [
6]. Sparse and redundant representation techniques were developed and subsequently introduced to the field of SAR-ATR. Sun et al. [
7] extracted scale-invariant features and pixel amplitudes from images and then used the joint dynamic sparse representation classification technique to classify them. Dong et al. combined the monogenic signal with multiple classification methods, such as sparse representation classification [
8], manifold learning [
9], and multi-task learning [
10].
Unlike feature-based methods, model-based approaches employ computer-aided design (CAD) modeling and electromagnetic computing to provide physical descriptions of targets. Target characteristics, which are regions or parameters of scattering centers, are used as references for recognition. Zhou et al. [
11] used wideband measurements to establish the targets’ 3-D global scattering centers. These scattering centers were projected onto a 2-D imaging plane and were compared to the test images. In [
12,
13], researchers first constructed accurate CAD models of targets. The scattering centers of the targets were generated by running an electromagnetic simulator on the targets’ CAD models. Ding et al. [
14] proposed a region matching metric suitable for 3-D scattering center models. They represented scattering centers as binary regions and developed a coarse-to-fine region matching algorithm to measure the distance between two scattering centers.
Both feature-based and model-based methods require experts to manually design features or models suitable for SAR images. Convolutional neural networks (CNNs) [
15] have received much attention in SAR-ATR due to their capacity to automatically learn hierarchical image features. CNN generally consists of multiple convolutional layers used for feature extraction and fully connected (FC) layers used for feature classification. To reduce the number of network parameters, Chen et al. [
16] built an all-convolutional network without FC layers. Wagner [
17] replaced the last FC layer in the network with a support vector machine (SVM), which increased training complexity but boosted recognition performance. Min et al. [
18] used the student-teacher paradigm to compress a deep CNN into a micro CNN (MCNN) containing only two layers. Speckle noise, caused by the unique SAR imaging mechanism, degrades the performance of SAR-ATR. To reduce the influence of speckle noise, Cho et al. [
19] proposed a multiple feature-based CNN (MFCNN) that uses max-pooling and average-pooling in parallel to aggregate features. Kwak et al. [
20] added regularization to the training process of CNN to minimize feature variations caused by speckle noise. The trained CNN extracts noise-robust features and hence has improved recognition performance.
Although the CNN achieves state-of-the-art recognition performance, it requires collecting and annotating huge amounts of training data. Collecting SAR data, however, is limited by cost and security considerations. Data augmentation is a common practice to overcome this limitation. Ding et al. [
21] used augmentation operations, including translation, rotation, and the addition of noise, to generate synthetic SAR images. Jiang et al. [
22] used Gabor filters to extract multi-scale and multi-directional features of SAR images. These features, which are more diverse than raw images, can be used as training samples for the CNN. Similarly, Pei et al. [
23] trained a CNN with multiview SAR data, which is a combination of SAR images at different azimuth angles. The CNN extracted multiview image features and fused them in a parallel network. In addition to data augmentation, researchers have also utilized external data sources and developed corresponding transfer learning frameworks. Transfer learning acquires prior information from external sources such as optical data [
24] and virtual SAR data [
25]. It then uses this information to help train CNNs that recognize real SAR targets.
Recently, meta-learning methods [
26,
27] have made significant progress in few-shot image classification in which each class has few labeled samples available for training. By learning priors from many training tasks, meta-learning solves new testing tasks using only a few samples. Acquiring these priors requires the training and testing tasks to share some common structures, such as visual or semantic features. Tang et al. [
28] proposed an inference model based on Siamese networks, which not only improves the accuracy of few-shot SAR recognition but also reduces the prediction time. Wang et al. [
29] integrated model-agnostic meta-learning (MAML) with domain adaptation to solve cross-domain and cross-task SAR-ATR problems. In this paper, we solve SAR-ATR tasks with small data in a meta-learning framework. Simulated SAR data [
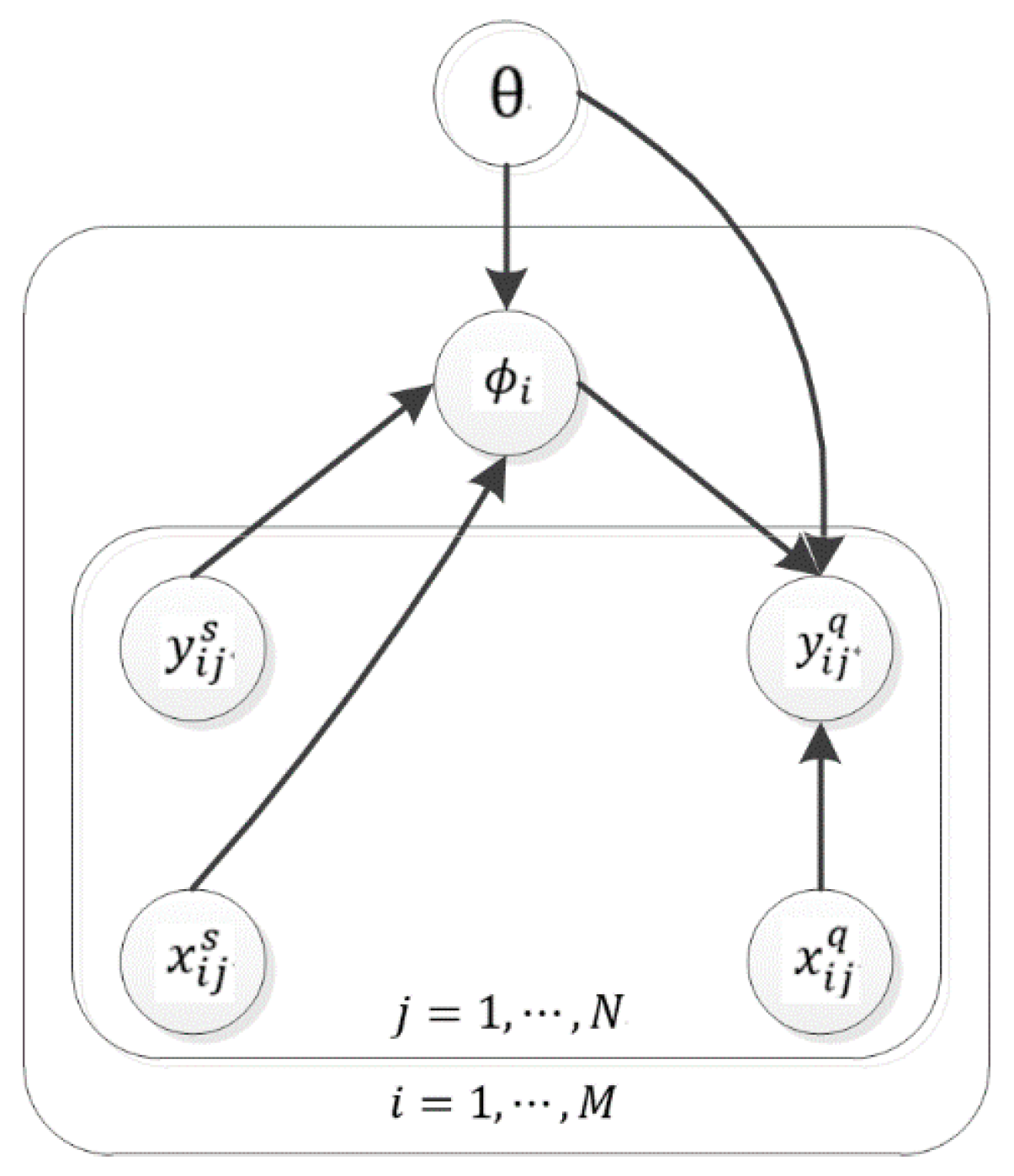
30] are also introduced to compensate for the lack of real data. We build a meta-learning model consisting of global parameters and task-specific parameters. The model is meta-learned using sufficient simulated SAR data. After meta-learning, it retains the global parameters and uses real SAR data to update task-specific parameters. To reduce the model uncertainty caused by small training data, the model places probability distributions over task-specific parameters. These parameters, vast in number, are estimated by amortized variational inference (AVI) [
31] to reduce the computation and storage cost. Most relevant to our method is the work of [
32,
33], in which amortized networks (e.g., plain neural networks) were used to approximate task-specific parameters. By contrast, our model uses variational inference to clarify the errors introduced by amortized approximation, thereby improving the training objective function. Furthermore, we propose a novel amortized network implemented with set-to-set functions [
34] to boost the performance of AVI.
The contributions of this paper are summarized as follows:
(1) We propose a novel recognition model integrating meta-learning and AVI. The model can recognize new targets with a small amount of real data.
(2) To reduce the model uncertainty caused by small data, task-specific parameters of the model are modeled by probability distributions and are inferred by AVI.
(3) The amortized network of AVI is implemented with set-to-set functions, thereby improving its performance.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}