1. Introduction
Self-driving cars, also known as autonomous vehicles (AV), driverless cars, smart transportation robots (STR) or robocars have a potential to change the way we commute [
1]. Autonomous vehicles incorporate integration with digital infrastructure and smart cities and form a critical component of the connected and autonomous vehicles (CAV) and internet of vehicles (IoV) framework [
1].
A long-standing goal of artificial intelligence (AI) has been to drive a vehicle in a safe manner [
2]. Recent advances in deep learning (DL) and state representation learning (SRL) have intensified research to develop autonomous agents with human-level capabilities [
2]. Deep reinforcement learning (DRL), a combination of DL and reinforcement learning (RL), has been widely used as a baseline format for the self-driving vehicles [
1]. This has led to a surge in research activities to achieve the quality and the speed needed to simulate, test, and run autonomous vehicles using various DL paradigms.
With ubiquitous availability of cloud based processors such as Google Cloud Platform (GCP) and Amazon Web Services’ (AWS) Elastic Compute-2 (EC2), the complex process of fine-tuning and optimizing neural network architectures in SRL has been extensively simplified [
3]. An enhanced and robust representation of driving environment leverages variational inference, stochastic gradient descent, and variational Bayes encoding in partially/completely observable driving environment [
3]. Furthermore, SRL is imperative for stabilizing long-term driving behavior in autonomous vehicles as DRL based transition models may lead to divergence of the Markov states under complex Markovian transitions [
4]. Assuming that the vehicle state-transitions may vary over each time-stamp, variational autoencoder (VAE) is used to learn the mappings in the driving environment followed by deep deterministic policy gradient (DDPG), and soft actor-critic (SAC) for inferring the latent state-action-reward tuples [
4]. The state transition variation over each time stamp refers to transitions in vehicle states, modeled according to Markov Decision Process (MDP, introduced in
Section 4). Each time-stamp refers to the duration of driving episode that is studied, before moving to next episode. The different timestamps also enable to find those state-action pairs that lead to abrupt variations, without affecting the continuous state-space of MDP.
In this paper, VAE+DDPG and VAE+SAC are proposed that combine DRL with SRL by mapping an input state vector to an action, solving the autonomous driving task. Simulation results show that the VAE+DDPG and VAE+SAC can learn reasonable continuous control policies from high-dimensional observations that contain robust task-relevant information. One of the earliest works in applying DRL to autonomous driving has been presented in Reference [
5]. This work was enhanced by Reference [
6] where some of the instabilities in policy training encountered by Reference [
5] were addressed using VAE. Our work builds on the lines of these works and compares the performance of VAE+DDPG and VAE+SAC in autonomous driving.
Deep reinforcement learning has been widely applied to various problems, predominantly in game playing [
7,
8]. Deep reinforcement learning has also been extensively applied to resource allocation and channel estimation problems in wireless communication, autonomous routing and self-healing in networking, localization and path-planning in unmanned air vehicles (UAV), smart-drones and underwater communications. As wireless networks and applications become more decentralized and autonomous, the network nodes are required to make decisions locally in order to maximize the system performance in a dynamic and uncertain environment. Obtaining an optimal policy in reasonable time, taking decisions and actions under large state-spaces using DRL have been applied to network access, wireless caching, cognitive spectrum sensing, and network security. Some of the more recent DRL applications include modeling multiple experience pools for UAV autonomous motion planning in complex unknown environments [
9], learning output reference model tracking for higher-order nonlinear systems with unknown dynamics [
10], and pick and place operations in logistics using a mobile manipulator controlled with DRL [
11]. The DRL paradigm has been extended to domains such as autonomous vehicles and has opened new research avenues [
12]. Model-free DRL technique known as Q-learning offers a compelling technique to further explore the problem of autonomous driving without explicitly modelling the driving environment [
13]. The paper explores the role of SRL to complement the autonomous driving problem modeled using an MDP. The results provide a significant groundwork for considering solutions to some autonomous driving problems using standalone SRL-DRL framework. The current work considers a simple driving environment, consisting of a single-lane straight-line driving trajectory. There are no obstacles on the driving path and the roads are devoid of any sharp turns, bends, and curvatures. In the future, the driving scenario is expected to emulate more real-world driving complexities, extended to multiple vehicles in the driving lane, vehicles on the oncoming lane, traffic lights, intersections, and curvatures in the driving trajectory. Our results outperform some data-driven models based on the accuracy, maximum error-free drive-time before deviating off the track and policy losses [
14]. The state-of-the-art developments in DL and RL were the principal motivation behind this work. The contributions of this paper are summarized as follows:
Proposing a SRL based solution using VAE, SAC, and DDPG to solve the autonomous driving problem formulated as a MDP. We propose a SRL algorithm that combines the feature extraction capabilities with the fast and powerful batch RL approach of VAE [
15].
Analysis of the autonomous driving behavior, verification of the proposed SRL-DRL scheme, and performance comparison of VAE+DDPG and VAE+SAC approaches. This is done by the implementation of VAE, DDPG, and SAC based autonomous driving in DonKey simulator [
16,
17], that closely approximates real-world driving conditions.
The rest of this paper is organized as follows—in
Section 2, a brief literature review on the topic of autonomous vehicles and application of current deep learning technologies to autonomous vehicles is presented. In
Section 3, the system model is introduced. The problem formulation describing autonomous driving in continuous state-space as MDP and proposed SRL solution approaches comprising VAE+DDPG and VAE+SAC are presented in
Section 4. The proposed solution approach based on MDP and Bellman optimality equations is presented in
Section 5. The experimental setup in DonKey simulator to capture real-time driving images for VAE pre-processing to select robust features is presented in
Section 6. Simulation results and discussions are elaborated in
Section 7 with a comparison of performance characteristics of VAE+DDPG and VAE+SAC approaches. Finally,
Section 8 provides concluding remarks and some directions for future work.
3. System Model
Let
represent the image dataset,
=
where
denotes the
t-th frame image in the dataset consisting
n frames associated with states of the vehicle at a given time, given by
, and the actions taken
based on the features learnt by the VAE feature extractor [
21]. In order to analyze the different positions of the vehicle in a given time-stamp, the vehicle while trying to maximize the reward function seeks to execute certain actions. The actions can be to accelerate, to decelerate, maintain the same velocity, to turn right, turn left, or continue in the same direction [
21]. Given that the vehicle transition from one state to another is often a continual process, a MDP is proposed in this paper to model the vehicle transitions [
1].
Learning to maintain a straight line path on the road can be defined as estimating the function
that identifies the Markovian states and predicts
. Using SRL dimensionality reduction and robust feature retention, as depicted in
Figure 3, the images captured by the autonomous driving agent in the driving environment are distributed into a Gaussian space, with the image output size represented by
, where the dimensionality was chosen experimentally and the Gaussian assumption was in accordance with Bayes variational autoencoding [
12]. The driving environment under consideration consists of a road, a navigating vehicle, and an obstacle (optional). A section of the driving scene with the road and vehicle is represented in
Figure 4. At
frame of the dataset, the vehicular agent determines its next possible set of
S states depending on selecting an action from the set of
A possible actions [
34]. The function
represents state-representation-learning approach, where driving environment images are down-sampled to only include more robust features, termed as SRL dimensionality reduction. The numbers
represent the scene size in 2 dimensions (2D), or the number of pixels in an image in 2D, experimentally chosen to retain sufficient image clarity, and multiplying by the number 3 indicates red, green, and blue (RGB) component of colors in the driving images [
35,
36]. The images in 3 dimensions (3D) are further downsampled to 2-dimensional (2D) images as this reduces processing power required while retaining robustness of features. The function
F is learned in a piecewise manner so that the efficiency and performance can be improved separately [
5]. The action values are continuously encoded as DDPG and VAE are suitable for continuous action spaces. In
Section 5.2,
Table 1, it is briefly described how these values continuously vary until vehicle stabilizes. Moreover, these values are seen to change depending on different initial reward functions, so the abstract values of these variables do not give a strong interpretation of vehicle behaviour, rather the vehicle behaviour is studied using parameters defined in
Table 2.
4. Problem Formulation
The problems of autonomous driving scene perception, environment cognition, and decision making are investigated in this paper. The vehicle is represented as an agent which receives sensory inputs and performs driving actions (maneuvres) in an environment. The vehicular agent acts on rewards, penalties, and policy losses from the environment with the goal to maximize the rewards it receives, while minimizing the policy losses [
37]. The agent learns an action based on the policy function, loss function and state-action-reward model. A state
is Markov if and only if a future action is independent of the past actions and depends on the present state and actions [
1]. We address the following issues pertaining to autonomous driving:
- 1.
To generate realistic and safe autonomous driving using SRL-DRL and related techniques [
22].
- 2.
To improve the autonomous driving policies based on continuous state space, continuous action space, and pixel space [
38].
- 3.
To learn the driving behavior and environmental conditions without manual input, using SRL-DRL [
33].
- 4.
To reduce the inaccuracies, and improve loss function, entropy, policy, loss, and learning rate using improved VAE, DDPG, and SAE [
27].
- 5.
To maintain the trade-off between policy loss and learning rate [
39].
An initial vehicle state can lead to a set of further movements and approaches to inform transitional probabilities of a Markov process over a driving state-space. Furthermore, the Markov process provides an assessment of the path through the driving environment with an expected policy loss function. When the autonomous vehicle adjusts its behaviour to make optimal decisions or to take actions that minimize an expected loss, the probability of the vehicle undergoing different state-action-reward tuples is given as:
where
defines the probability distribution of the vehicle state at a given timeframe. The state transition matrix
P defines the transition probabilities from states
s to successor states
after taking action
a. A MDP is defined as a tuple
[
34] where
S is a finite set of states,
A is a finite set of actions,
P is a state transition probability matrix,
R is a reward function, and
is a discount factor,
. The reward function is a measure of entropy in state-action pair and it decides how well an action contributes to help an agent reach the best possible next state. The learning policy
is given as [
24]:
The objective of the vehicle is to drive maximum possible distance on the road, staying in the lane without deviating off the track [
12]. The driving action is terminated once the vehicle deviates off the track or trudges on the other lane, represented as
where
represents the parameter values, that is, the set of velocities in a given timestep, at present time and past instances for a given state
S.
where
N indicates the
Nth time frame. All past and present states are in the continuous state-space [
34]. The parameter values, that is, the set of velocities in a given timestep, at present and past instances for a given state
S are obtained for the trajectory followed by the vehicle described by [
20,
40]:
where
is the difference between two subsequent timeframes while the vehicle navigates the trajectory. These parameters are used to calculate the optimal value function
and optimal Q-value
. In SRL, a reward function directly influences the behavior adopted by an an agent. Reward function refers to the feedback obtained from the environment to evaluate the viability of the actions taken. In autonomous driving, a reward function is formulated as a linear model based on the velocity of the car
v, the angle between the road and car’s heading
, and the distance from the middle of the road
d. The reward
r, given by (
7) prevents the vehicle from deviating off the track while allowing the vehicle to maintain its position on the road [
24].
We propose an extra penalty as
*
, where
represents the state at time step
t arrived due to action
a and
is the corresponding constant empirical coefficient. The experimental results show better smoothness with the new penalty and the whole reward function is given in (
8) as [
24]:
We set to 2 or 3 as driving smoothness tends to reduce with increase in throttle value. This fact conforms to human driving behavior where the faster the car runs, the harder it is to control it, indicated by failure to recognize turn/curve at high speed.
Although there may be more than one optimal policy, in autonomous driving situations, it is imperative to determine if there exists at least one optimal policy for a specific driving environment. The optimal state value function is given as [
2]:
In this paper, the autonomous driving problem is formulated as a MDP, on the lines of the work of Reference [
5]. The MDP is then solved using policy gradient mechanism DDPG and actor-critic mechanism SAC, accompanied by VAE at initial solution stages [
6]. The following questions pertaining to scene perception, environment cognition, and decision making are investigated in this paper:
- 1.
To generate realistic and safe autonomous driving using DRL and related techniques [
30].
- 2.
To improve the autonomous driving policies based on continuous state space, continuous action space, and pixel space [
12].
- 3.
To learn the driving behavior and environmental conditions without manual input, using DRL [
37].
- 4.
To solve the inaccuracies, improving loss function, entropy, policy, loss, and learning rate using improved VAE, DDPG, and SAE [
31].
- 5.
To maintain the trade-off between policy loss and learning rate [
41].
5. Proposed Solution
Autonomous driving is modelled as a multi-objective control problem with high-dimensional feature space, agent (vehicle) states, and a mono-dimensional discrete action space [
32]. We use VAE to map the vehicle state at a given time and the dynamics of the environment not directly influenced by the vehicle. We repeat this procedure iteratively in a semi-batch approach to bootstrap the algorithm, starting from a fully random exploration of the driving environment. Beginning randomly, the vehicle is trained to learn how to take better decisions over repeated attempts, reducing errors based on a reward function [
24,
42]. The proposed solution using VAE, DDPG, and SAC aims to use reward-function to learn policies for multiple state-action-reward tuples. The solution enables the optimal policy to generalize the continuous actions for states that are yet to be traversed by the vehicular agent. The proposed solution is represented in
Figure 6.
Let’s say the vehicular agent has a choice of taking one of k possible actions .
Assume that the environment can be in one of m different states .
Upon taking an action in the environment in state the vehicle incurs a loss .
Given the observed data D and prior background knowledge B, the vehicular agent’s beliefs about the state of the driving environment are denoted by .
The optimal action is the one which is expected to minimize loss and maximize utility.
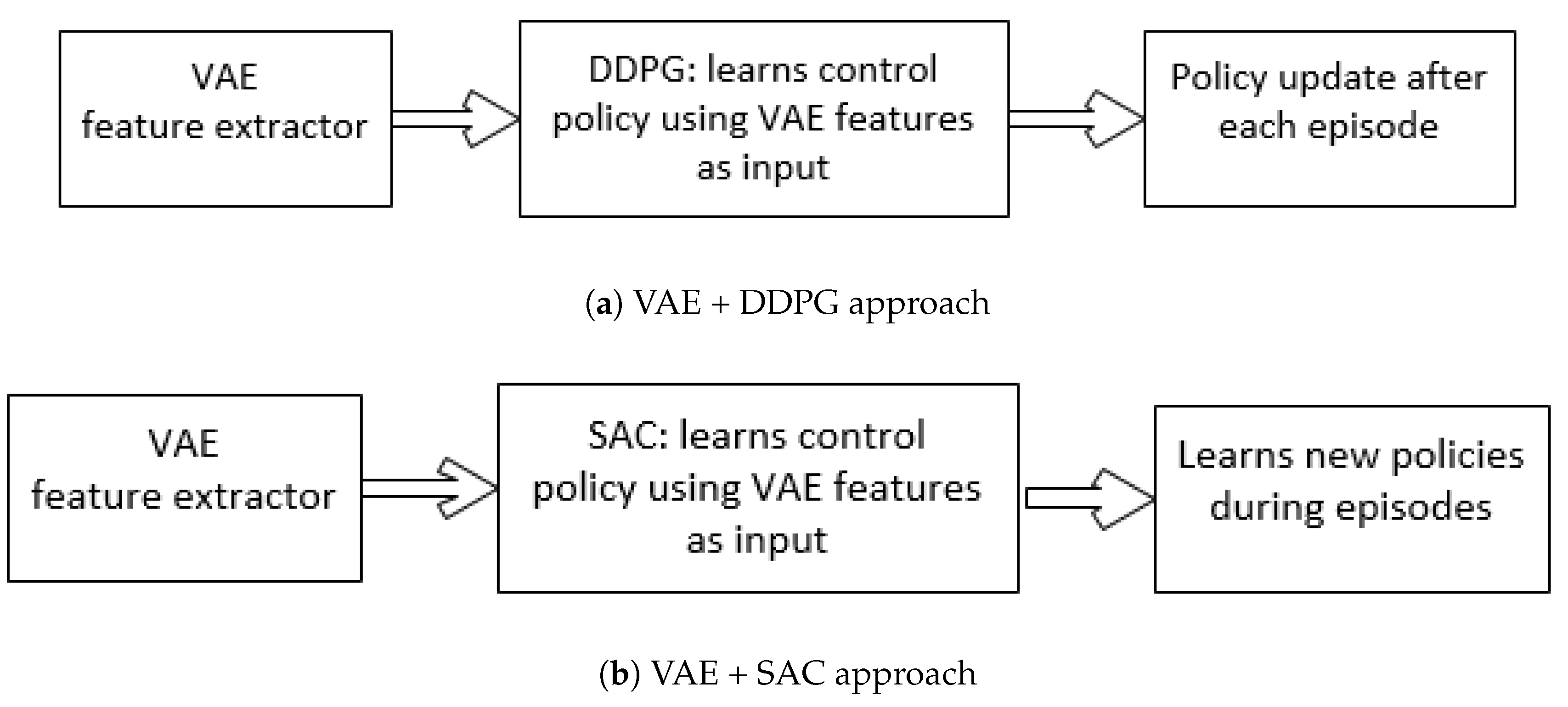
After every action, the vehicle transitions from one state to another. The initial state of an autonomous vehicle is then updated to best adapt to the current state of the driving environment. This is done through constant adjustment of acceleration (and consequently speed) so that the vehicle trajectory is aligned with the road/lane trajectory. The alignment of trajectories for extended timeframes of vehicle navigation is an indicator that the vehicle is able to follow a lane and does not deviate off the track. To simplify the problem, we assume that the vehicle has an unobstructed and unoccluded visual access to the driving environment where any curves, turns, and obstacles in the vicinity are clearly visible to the vehicle. To ameliorate the problem complexity, and to overcome non-uniform, skewed, or intractable image distributions, we implemented learning action-prediction with a policy gradient architecture, (DDPG) and an actor-critic architecture, (SAC) both preceded by a variational auto encoder (VAE). The DRL approaches used are:
VAE for efficient driving environment analysis,
DDPG for optimal policy calculation and,
SAC for faster arrival at optimal policy, without having to repeatedly train the DRL network for all the timeframes.
5.1. Solution Approach
This paper implements a feature extractor, VAE, to compress the images captured during driving to a lower dimensional space [
23]. The weights that provide gradients with similar magnitudes indicate that each feature has been kept relevant. The first step of extracting the relevant information from raw data is done by VAE by compressing the search space. This also accelerates the training in later stages by learning the control policy from the lower dimensional image space [
4,
15].
The second step after the features have been extracted is to use a DRL algorithm. This paper investigates DDPG and SAC algorithms. The DDPG policy gradient algorithm learns a control policy using VAE features as input and the policy is updated after each episode [
30]. A distinguishing feature offered by DDPG is the replay buffer, which is memory to store the interactions with the environment. These interactions can be played when needed at a later time, so that the self-driving car can update the policy without explicitly interacting with the environment in real-time again [
32].
In our experiments, the vehicle is trained to maximize the distance travelled before it steers off the track. The episode ends as soon as the vehicle steers off the road. The episode termination also prevents the vehicular agent from exploring regions that do not contribute at all to effectively learn the driving task [
40]. If a VAE feature extractor is trained after each episode, the distribution of features is not stationary. As the features change over time, this introduces instabilities in the learning policy [
28]. Moreover, on low power CPU machines, traning a VAE after each episode is time consuming and a slow process. To address these issues, in this work, a VAE is pre-trained and a fixed set of features are collected beforehand [
1]. Next, these features are provided as input to DDPG to learn and update the policy. Also, to speed up the process, we trained feature extractors using Google Colab notebook. Lastly, the DDPG algorithm is known to be inherently unstable in cases where its performance degrades during training and fails to tune if there are multiple factors that affect the learning outcome [
23]. The SAC algorithm that provides much stable performance and is easier to tune in case of multiple parameters is applied and its performance comparison with DDPG is analyzed.
5.2. Solving MDPs Using Bellman Expectation Equations
The policy gradient DRL methods and the actor-critic methods can be solved using Bellman equations mentioned below. The parameterized policy defines how the autonomous vehicle selects its actions and the critic appraises each action taken by the vehicular agent in the driving environment. The appraisal is associated with a positive or negative reward function according to which the parameters of the actor are updated [
24]. Similarly, the actor’s parameters can be updated with a policy gradient that does not necessarily have a critic component [
1]. The policy gradient methods such as DDPG adjust the policy parameters based on a sampled reward measured against a baseline value [
28]. In DDPG, this baseline is a stationary value that does not update with experience. In SAC, a baseline is estimated from experience, making the method an actor-critic method where the vehicle updates its parameters after each step taken in the driving environment [
40]. The Bellman equations allow comparing the results of taking a different action in each state and assist in negating the wrong step, causing the agent to strengthen how it selects the apparent best action. In SAC, the critic components make the gradient point in the apparent best direction without sampling other actions [
24].
The Bellman optimality equation is given as [
5]:
Given the optimal value function,
, a popular technique to get optimal policy
is the greedy algorithm. This algorithm specifies that for a vehicle in a current state
S and an optimal value function
, the actions
A that appear best after a one-step search will be optimal. The greedy algorithm makes a choice to select an action that seems to be the best at that state, making a locally-optimal choice and verifying its suitability as a globally-optimal solution.
turns a long-term reward into a measurable quantity which is locally and immediately available.
is used to get the optimal policy [
5]. The policy improvement theorem justifies an optimal action in a given state [
43]. In Equations (
14) and (
15), the vehicular agent is characterized by policy
,
describes how good it is for a vehicle to be in a given state
s depending on policy
, and
describes how good it is for a vehicle to choose an action
a after being in a given state
s.
The vehicle at a given time in a given state has two possible actions to choose from:
- 1.
: accelerate, and
- 2.
: don’t accelerate.
In an ideal scenario, if acceleration would lead to an unsafe action such as drifting off the track, or deviating on to the other lane intended for oncoming vehicles, there are two probable outcomes:
- 1.
: safe driving, and
- 2.
: unsafe driving.
The vehicular agent needs to arrive at an optimal action for this decision problem. Based on MDP, the following variables are defined for the vehicular agent:
States:
Actions:
Rewards:
The variable
defines the state of the driving environment and the vehicular agent at time
t. The vehicular agent takes action
and receives reward or penalty
. The reward is assumed to depend on the state and the action. The optimal policy is defined by the Equation (
16).
The initial values for states and the transition probabilities are depicted in
Table 1. For a continuous dynamical driving environment, the initial probability components are non-negative entries and sum up to 1. If
is a probability that represents the initial safe driving state of the vehicle, then as per the Markov property of Equations (
1) and (
16), the subsequent components in
Table 1 represent the probability that the vehicle maintains the safe state. The transition probabilities emphasize the variations in reward function. The driving behaviour might show abrupt variations in driving due to changes that represent transitions that occur between subsequent states. Detection of abrupt change points is useful in modeling and predicting driving behavior and the transition probabilities enumerate, categorize, and compare the reward values. Under safe driving condition, if the probability of acceleration is very high, then the loss is set to a high negative value, indicating a positive reward for that action. Under unsafe driving condition, if the vehicle decides to accelerate, the associated loss is a positive value, indicating negative reward, thus prompting the vehicle to refrain from taking the accelerating action. Similarly, if the vehicle is driving in a safe state and decides not to accelerate, the reward remains neutral, indicated by zero loss. Vice versa, if the vehicle is in an unsafe state and decides not to accelerate, although the action will not deteriorate the vehicle’s state further, it will not guarantee a return to safe driving either. This is implied through a zero reward. The appraisal is associated with a positive or negative reward function according to which the parameters of the actor are updated. Similarly, the actor’s parameters can be updated with a policy gradient that does not necessarily have a critic component.
6. Experimental Setup
In this paper, the experiments are carried out on the Ubuntu operating system, DonKey simulator, OpenAIgym, and Google Collaboratory [
16,
17]. Due to the property of learning by trial and error in SRL, simulator plays an important role. Among various car simulators, the open racing car simulator (TORCS) is widely used, providing both front view images and extracted features. TORCS requires less hardware performance whereas DonKey provides flexibility and realism, hence we selected DonKey [
16,
17]. The raw sensor-data and the camera frames files are easy to use in DonKey simulator with the help of Docker, a container management software.
In DonKey simulator, driving environment consists of a road with two lanes, differentiated with a lane marker. Although the road curvature needs the vehicle to make a slight change in steering angle to stay on the road, the road is devoid of any sharp turns and the major part of the trajectory is linear. The specific inputs are gleaned as robust features from driving scenario mentioned and depicted in
Figure 4, and have been considered in
Section 4. To stay on the road, the rewards for action at a specific state are supposed to be high for preferable actions. However, once the vehicle is close to achieving good position in the lane, the reward for next action is considerably lower than in the beginning. In the simulation time over seven hours of driving, the captured frames are
pixels in the region depicting the vicinity of the middle of the road/lane.
We focus on the acceleration (speed), policy entropy, policy loss, and total timesteps. The acceleration is considered in x and y directions, so that maintains the vehicle velocity and position along x and y directions. Moreover, the acceleration along the y-axis takes the vehicle forward, whereas acceleration along the x-axis aligns the vehicle on the lane. We also record the timestamps at which these parameters were measured and the timestamps the camera frames were captured. We pre-processed the camera frames by downsampling them to and normalizing the pixel values between −1 and 1. The self-driving vehicle needs to learn the road images, and a VAE encodes the road images into probabilistic Gaussian space as well as decodes them to 3D space. DDPG receives random pixel samples as input from the Gaussian distributed latent space and output of the VAE network. We trained the VAE for 200 epochs. Each epoch consisted of gradient updates with a batch size of 64. The parameter fine tuning was done during programming the scenarios, using argument and the optimal policy-loss values are obtained by hyper-parameter tuning. The DRL approach is slightly advantageous compared to convolutional neural networks (CNN) based approach as the need for explicit hyper-parameter tuning beforehand is bypassed.
7. Simulation Results
The simulation results are presented to show the performance of the proposed VAE+DDPG and VAE+SAC schemes. First, the simulation parameters are introduced followed by the simulation results. Next, the rewards and penalties for DDPG and SAC approaches are compared for driving environment. Then, the performance of the proposed approach is studied in terms of learning rate and acquiring stable driving state.
Table 2 highlights the features and parameters considered in the simulation.
7.1. Performance Analysis
This section provides comparison of vehicle control algorithms using SRL based on policy gradients (VAE+DDPG) and actor-critic (VAE+SAC). The section discusses the results highlighting the probability of the autonomous vehicle transitioning into a new state, based on the cumulative reward achieved at each timeframe and the execution of an action. Since the autonomous driving problem is defined as first-order Markov decision problem, the state of the vehicle at next timeframe is dependent only on the present state and not the past states. This section compares the viability of VAE+DDPG and VAE+SAC approaches in ensuring that the autonomous vehicle arrives at the current state. The variations in cumulative reward accumulated over each timeframe in the presence of possible states in the VAE encoded driving environment is also discussed in this section.
Simulation Parameters
The parameters under consideration in this paper are described briefly as follows:
Cumulative Reward: It describes the mean cumulative episode reward over all the states of the agent over a specific timestamp. The value usually increases during a successful training session. The general trend in reward is to consistently increase over time with some small ups and downs based on the complexity of the task. However, a significant increase in reward may not be apparent until the training process has undergone multiple iterations [
44,
45].
Entropy: It is a measure of how random the decisions of the autonomous agent are. It should gradually decrease during a successful training process. In case the entropy decreases too quickly or does not decrease at all, the DRL architecture’s hyper-parameters are reset to a different initial value both in continuous as well as discrete action space [
44,
45].
Episode Length: The mean length of each episode in the driving environment for the autonomous vehicular agent [
44,
45].
Learning Rate: It signifies the step size taken at a time by the training algorithm to search for the optimal policy [
44,
45].
Policy Loss: The policy is defined as the process for deciding actions that lead to optimal driving in the given scenario. Policy loss describes the mean magnitude of policy loss function. This loss correlates to how much the policy changes during an episode in a given timeframe [
44,
45].
Value Estimate: It is the mean value estimate for all states visited by the autonomous agent. It corresponds to how much future reward the agent expects to receive at any given state [
44,
45].
Value Loss: It defines the mean loss of the value function update. It correlates to how well the model is able to predict the value of each state. This should increase while the agent is learning, and then decrease once the reward stabilizes. These values also increase as the reward increases, and then decrease as the reward tends to becomes stable [
44,
45].
7.2. Rewards vs. Timesteps
Figure 7 represents the variation in cumulative reward with number of timesteps covererd by the vehicle in the simulated driving environment. For the first 20,000 timeframes, the cumulative reward gradually increases. This gradual increase indicates that the vehicle begins with a randomly defined initial state
S, and selects a random action
A with an aim to maintain its position on the lane. After initial haphazard movements, from 20,000–40,000 timeframes, the cumulative reward continues to increase at a similar rate for VAE+SAC approach, whereas the increase is steeper for VAE+DDPG approach. Furthermore, the VAE+DDPG approach shows minor fluctuations in a specific range, from 10,000–25,000 timeframes. This indicates that as the vehicle learns an optimum action, the deviation from those set of actions attracts a higher penalty as compared to that in the beginning. Consequently, the reward for successive favorable set of actions is less and indicates that the vehicle has to process a smaller set of data to arrive at that action, resulting in nearly smooth cumulative reward.
Figure 8 represents the variations in episode length with the number of timeframes in the driving environment. The episode length defines how long the autonomous vehicle occupies the road before returning to the original position. For the first 10,000 timesteps, the episode length traversed by the vehicle is approximately 900 cm for VAE+SAC algorithm and 700 cm for VAE+DDPG algorithm. This period indicates random initial learning by the vehicle that results in a haphazard motion. After the iterations in the first 10,000 timesteps, the episode length traversed by the vehicle begins to constantly increase. After 40,000 timesteps, the episode length does not show a large increase for both VAE+DDPG and VAE+SAC algorithms. This is congruous to the pattern followed by cumulative reward, indicating that once the vehicle identifies a set of favourable actions, the vehicle is able to remain on the road for longer episode lengths, before resorting to terminating action.
Figure 9 depicts the value loss versus the distance traversed by the vehicle before terminating an episode. For the first 10,000 timeframes, the value loss for each successive timestamp indicates that even when the reward function stabilizes, the value loss continues to increase in accordance with the time spent by the vehicle in the driving environment. This implies that at every new timeframe, the vehicle calculates a set of state-action-reward tuple to seek an optimum action. In addition, the value loss tends to exhibit lesser variations based on the multiple state-action-reward cycles that allow the vehicle to arrive at an optimal policy and learn future actions.
7.3. Learning Losses and Optimal Driving Policy
The losses describe the delay at arriving at optimal policy in VAE+DDPG and VAE+SAC. The policy losses indicate how much the policy is changing at each timestep with subsequent actions. During a successful learning phase, the vehicle after starting with random decisions must arrive at more coherent pattern of state, action, and reward.
Figure 10 highlights the fact that at the time of prediction of next state and to choose an appropriate action, the vehicle uses the cumulative reward in variation with policy loss to predict the next best action to take in the driving environment. The input state is the Q-values for all actions and the maximum cumulative reward for taking an action impacts the next reward predicted.
The optimal driving policy indicates that the optimal action is taken at a given state. At a given state whether the action is optimal or not is plotted in policy loss vs. no. of timeframes as shown in
Figure 11. As the vehicle approaches optimal decision, the randomness in decisions tends to decrease. During a successful scene understanding of the driving environment, decreasing randomness indicates that the vehicle has learnt optimally. The higher policy loss in the beginning indicates that as the vehicle moves in a haphazard direction, the algorithm traverses large number of states to adjust vehicle behavior. However, as the vehicle learns more about the driving environment, the haphazard motion is replaced by a more stable trajectory with less random movements, leading to gradually decreasing policy loss. In DDPG and SAC, these losses are defined and synthesized from unlabeled inputs (processed through VAE), and the variations in losses defined by the reward function.
7.4. Performance Comparison for VAE+DDPG vs. VAE+SAC
This subsection compares the performance characteristics of VAE+DDPG and VAE+SAC approaches for the autonomous vehicle to learn driving behavior. The vehicle arrives at an optimal state-value function after a specific timestep encompassing different iterations of function representing state-action tuple for the driving environment.
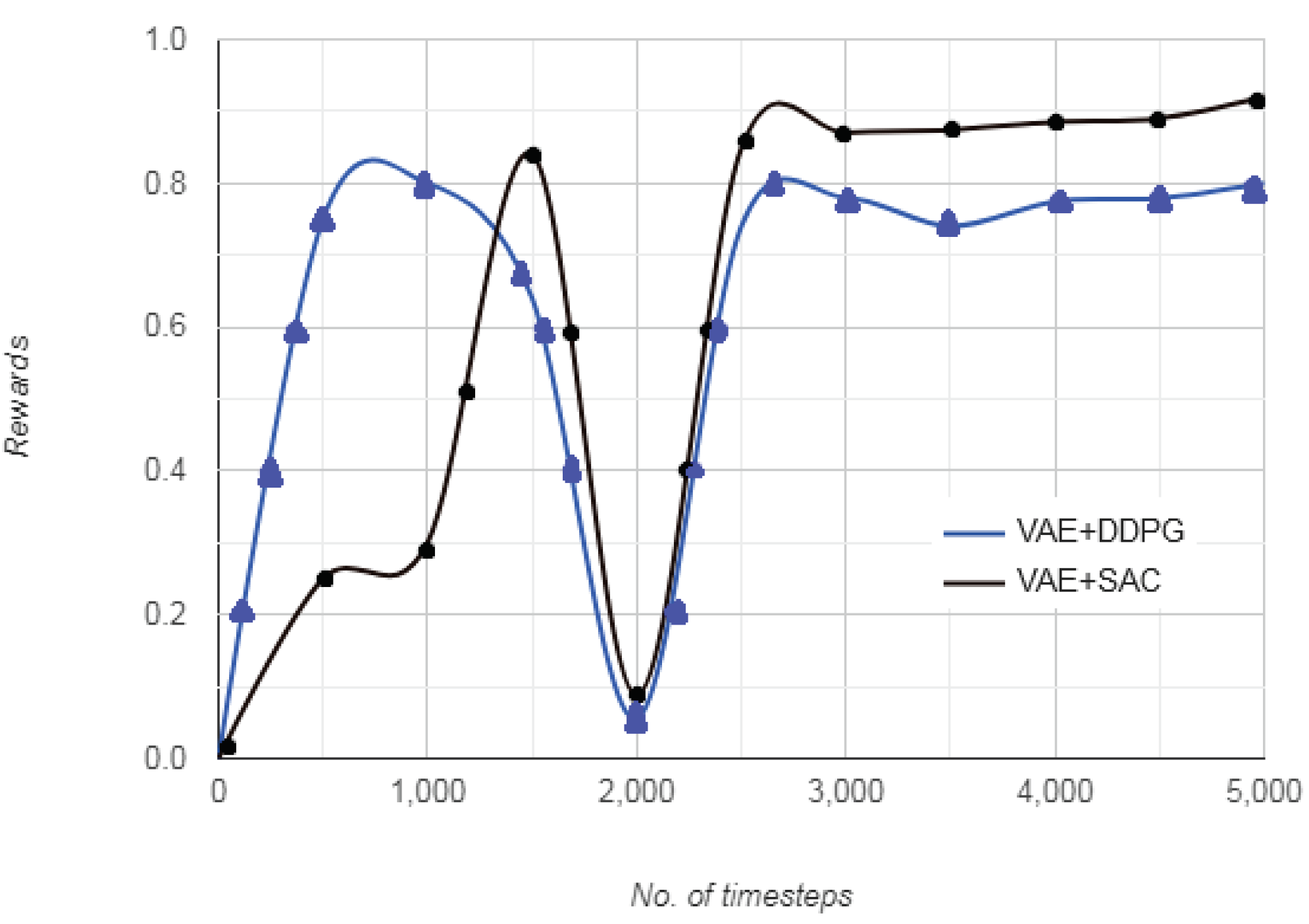
Figure 12 represents the plot of rewards vs. the number of timesteps in the driving environment. As seen from the figure, for same number of timesteps, after the driving scenario images are processed through VAE, both DDPG and SAC converge after approximately 3000 timesteps. However, the initial randomness in vehicle motion is less in VAE+SAC as compared to VAE+DDPG. For upto 2000 timesteps during training phase, the vehicle depicts more haphazard movement to arrive at an optimum action for VAE+DDPG and settles comparatively quicker with VAE+SAC approach. The reward becomes constant after approximately 3000 timesteps, indicating that optimal value function
and optimal state-action value function
has been approximated by the vehicular agent. The gradual increase indicates that the vehicle begins with a randomly defined initial state
S, and selects a random action
A with an aim to maintain its position on the lane. After initial movement, the cumulative reward continues to increase at a similar rate for VAE+SAC approach, whereas the increase is steeper for VAE+DDPG approach. Furthermore, as the vehicle learns an optimum action, the deviation from those set of actions attracts a higher penalty as compared to that in the beginning. Consequently, the reward for successive favorable set of actions is lesser and indicates that the vehicle has to process a smaller set of data to arrive at that action, resulting in nearly smooth cumulative reward.
The VAE+SAC eliminates the need to retain the state-action information until episode termination to compute value loss, being independent of cumulative rewards and other domain dynamics that might render driving environment representation challenging. The rewards represent the entropy of the learned policy giving an insight into how the vehicular agent learned to navigate the driving environment as well as managed to keep the episode length high. The autonomous vehicle agent has to choose from a set of possible actions, that is, accelerating, decelerating, or maintaining the same velocity. The reward for the first 1000 timesteps indicates that the vehicle proceeds with a random direction, so it has learned a policy with 0–80% probability of going haphazardly. From 1000–3000 timesteps, the rewards reorganize, indicating a reset of state-action-reward pair. After 3000 timesteps to 5000 timesteps, the rewards are almost stationary for both VAE+DDPG and VAE+SAC approaches. This indicates that the autonomous vehicle has learned the driving environment and has decided on the optimal action. Also, the reward is slightly higher for VAE+DDPG as compared to VAE+SAC.
8. Conclusions and Future Work
In this paper, we applied state representation learning to object detection and safe navigation while enhancing an autonomous vehicle’s ability to discern meaningful information from surrounding data. The proposed method used VAE, DDPG, and SAC to implement and analyze a combination of policy function, reward, and penalty to ensure that the autonomous vehicle stays on the track for maximum time in a given timeframe. In a particular driving state, based on the past instances of off-track deviations and episode terminations over several frames of previous iterations, the vehicle reinforces its behavior to maximize the reward function.
Applying SRL to autonomous driving has been proposed and implemented as an alternative approach to conventional DRL algorithms that require a large number of training samples for learning, which is infeasible and time-consuming in real-world driving scenarios. The application of VAE preprocessing enhanced the sample efficiency facilitating the learning process with fewer but robust samples. In this paper, capturing and interpreting the driving environment and possible set of actions a vehicle can take is effectively done using MDP for modeling the environment and generating complex distributions using VAE. The interpretation of the gathered data to execute meaningful action is done using policy gradient or actor critic based DRL methods.
The contribution of this paper is twofold. We proposed two DRL algorithms, VAE+DDPG and VAE+SAC. The combination of these techniques leads to smooth policy update in value function based DRL with enhanced capability of automatic feature extraction. Performing basic driving manoeuvres using non-DRL methods requires direct access to state variables as well as well-designed hand-engineered features extracted from sensory inputs. The DRL paradigm allows an autonomous vehicular agent to learn complex policies with high-dimensional observations as inputs. The driving environment images offer a suitable mechanism to learn to drive on a road in a manner similar to human driving.
Some future research directions are proposed below:
To enhance the performance speed of the SRL approach used in this paper, the autonomous vehicle can be trained to learn a transition model in the embedded state-space using action conditioned RNN and long short term memory (LSTM).
We aim to extend the VAE to learn the pixel space defined by Gaussian framework to generate realistic looking frames, images and videos predicting the autonomous vehicle behaviour. This would be a step forward towards receiving feedback-based corrective action ahead of the next timeframe.
The driving environments can be subjected to real-world limitations, disturbances, and abrupt variations in operating conditions.
For an autonomous vehicles to increase the uninterrupted drive-time, DRL techniques can be used in conjunction with probabilistic DL models to learn features from latent variables.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}