1. Introduction
Movement analysis and prediction have gained much attention in recent years. Knowing a future location in advance can assist in future predictive planning, give a strategic advantage, and create a perception of the unknown. With the availability of intelligent sensors such as the global positioning system (GPS), communities are becoming ubiquitous. Simultaneously, many application domains including health care are becoming more popular. Over the years, numerous trajectory prediction algorithms have been proposed. The focus of this study is to survey the available algorithms and offer a methodology for ranking the algorithms in terms of efficiency, performance, and ease of use. Broadly, trajectory prediction algorithms are derived from machine learning approaches such as Bayesian networks [
1], hidden Markov models [
2], decision trees [
3], neural networks [
4], and state predictor methods [
5].
This survey paper aims to assist researchers and the industry in selecting the algorithms for future location prediction. In the existing surveys, however, there are no proper guidelines for algorithm selection as per the probable use case. One such survey is [
6], in which the authors used five algorithms for four users with different patterns. In most of the studies, a few aspects of trajectory prediction are discussed, and nearly all examples relate to studies that focus on indoor and outdoor navigation. In some studies, the authors have validated the accuracy of these algorithms on given datasets. In our review, we investigated 28 algorithms mostly used in trajectory prediction.
Here, we present a comprehensive survey of several algorithms. The survey starts with a discussion on public and proprietary datasets. We designed our methodology for ranking of these algorithms based on the number of citations, type of dataset, and accuracy. Subsequently, when the rankings were created, the paper was categorized based on machine learning approaches. For example, for each approach, we investigated the type of algorithm, accuracy, dataset, setting (indoor or outdoor), and the number of citations. A detailed discussion on each approach was incorporated for better insight. Finally, the top three algorithms, which were NextPlace [
7], the Markov model [
8], and the hidden Markov model [
9], were proposed.
This research describes the selected studies and discuss the results of these trajectory prediction algorithms highlighted in the literature. This information will benefit the readers in terms of providing apparent aspects regarding the characteristics of these algorithms. The outcomes featured the qualities and shortcomings of the algorithms best studied; they will fill in as a helpful guide to the research community as well as the industry in understanding which techniques to utilize. Thus, developers will hugely benefit from this in terms of not being dependent on numerous case studies available on the Internet.
The remainder of this paper is structured as follows: In
Section 2, a summary of the existing trajectory prediction algorithms is given. In
Section 3, the related literature review is described. The available online datasets are presented in
Section 4, while public and propriety datasets and their rankings are included in
Section 5. The methodology is presented in
Section 6, and the results of our survey are presented in
Section 7. Finally, conclusions are given in
Section 8.
3. Related Work
This section provides a brief on available algorithms in the literature. In a survey carried by [
22], the authors emphasized the importance of mobile wireless systems in location prediction. The authors briefly described different types of location prediction and analysis algorithms. These algorithms are further categorized into domain-independent algorithms and domain-specific algorithms. The focus of their research was very limited to location prediction algorithms.
In a different study, the authors focused on the improvement of safety on the road by performing a survey of ways. The idea was to avoid hazardous accidents by predicting such situations in advance to practice safety precautions [
23]. The authors based the study on the models that describe motion, risk, and further describing how the single motion model effects the selection of the estimated method. They used different simulation models such as Monte Carlo, physics-based motion models, dynamic models, kinematic models, Gaussian noise simulation, and maneuver-based and interaction-aware models which are built on dynamic Bayesian networks.
In another survey [
24], issues regarding the mobility of different individuals were studied, such as transportation mode, patterns of trajectory, the significance of location, and other location-based models. The authors performed a detailed review of many different algorithms, techniques, and comparing alongside the obtained results with the issues of an individual’s mobility. Two types of graph approaches were used for mining trajectories from raw traces—first being the transitions among critical scenarios, and second being that the trajectories are changed to a spatiotemporal sequence.
The author used Augsburg indoor location tracking benchmarks as predictor loads and also used various techniques to model activities. The accuracy of different prediction methods was investigated and different location trajectories that were most frequently visited are studied [
6]. The scenarios involved visiting various offices in the building area under study. These techniques were studied, including Bayesian networks, neural networks, state, and Markov predictors. The authors established the fact that there were individual variations in the accuracies of different predictive models.
In a similar survey, authors study regarding the spatial-temporal context of individuals visits [
25]. Both spatial, historical trajectories, as well as temporal periodic patterns, are considered, and improvement in the current approaches has been achieved by the use of smoothing techniques on both patterns. The authors studied and reviewed nine baseline models to evaluate the model that they proposed which include Hierarchical Pitman-Yor (HPY) prior model, HPY Prior hourly model, HPY prior daily model, Most frequently visit model, order-1 Markov model, fall-back Markov model, most frequently hourly model, most frequently daily model, and most frequent hour-day model. According to their study, the model owed its improved structure to the pre-existing approaches.
Authors in [
26] focused on developing a probabilistic model based on the generations of trajectories by tracking different objects over time. The survey also emphasizes on the use of topographical maps to specify the points of interest which are, in turn, connected by activity paths that explain the way how the object’s motion pattern takes place. The main aim of the model is to concentrate on the events of interest. This way, the surveillance systems automatically focus on events such as abnormality detection, prediction of activities, the interaction of objects, online activity analysis, classification of a path, speed profiling, and virtual fencing.
Similarly, the conventional methods were surveyed for the automotive industry and the advancement in the risk assessment techniques for intelligent vehicles [
27]. They classified the motion and risk of vehicles based on semantics related to movement. The results showed that the choice of risk estimated method along with the motion model are the two major components for motion prediction and risk estimation for intelligent automobiles. Similarly, a study analyzed the different computational approaches developed for personal mobility [
28]. An experimental analysis was performed on the unpublished mobility data of 15 users in the Helsinki metropolitan area. A variety of existing personal mobility methods were analyzed and the performance of such methods were evaluated. They also categorized the evaluation criteria to differentiate between the evaluation measures.
In a similar study [
29], the authors reviewed the existing solutions for Geolocation Prediction (GP) and divided geolocation prediction into two primary parts. The initial steps proposed manufacturing Mining Popular Geolocation Region (MPGR), and second is Mining Personal Trajectory (MPT). The results described the basic concepts of GP, the characteristics of MPGR and MPT. They also discussed the limitations, openings, and the future geolocation prediction analytical trends for mobility big data.
In order to extend our discussion, we have described spatiotemporal approaches for their effectiveness, performance, and effortless use for predicting the future locations. One such studies is a model based on the spatiotemporal context of the user visiting history proposed by [
25] for location prediction. The authors illustrated the behavior of historical spatial and temporal trails from user’s travel patterns. By applying smoothing methods to the model training, the authors obtained significant improvement in comparison to other similar approaches.
An algorithm which encompasses the trajectory patterns of a single user was developed [
30]. The data were collected for four months and used to extract location from the data. For creating a predictive model of the user’s trajectories, these locations were considered. The authors suggested that these methods might be able to find sites that are substantially meaningful to a particular user.
Bayes-based predictors were used to add to the performance of their prediction for leveraging big data [
31]. They studied a large Caller Data Record (CDR) dataset. Initially, they explored the dataset and found that they can use call activity to generate prior probabilities for use in a Bayes predictor; this was the baseline reason for which the authors developed an enhanced Bayes predictor, which uses a distance threshold and users’ regular location to improve the generation of their probabilities. Bayes predictor increased by 17 percent after enhancements proposed the experimental result. As per their concluding results, it was inferred that it is attainable to help massive cellular data to increase location predictors without depending on extraneous data.
A hybrid system was proposed by [
32] for the location identification and prediction of the critical issues of location-based facilities. They used a hybrid method combining
k-nearest neighbor (
k-NN) with a decision tree to effectively recognize the sites in both indoor and outdoor environments. For the location prediction framework’s part, the hidden Markov model (HMM) was utilized to identify the client’s next location. The location grouping together with other contextual data.A probabilistic model decreases the complexity, the quality of developing, and restrains time of the execution. G-implies calculation was utilized for the proposed framework, which performs just on the former pattern of points. The accuracy execution was assessed for the expectation display on cell phones. The authors achieved prediction accuracy higher than 90 percent through these experiments. Similarly, an algorithm is developed for next location prediction for mobility modeling of a single user called a multi-order Markov chain (n-MMC) that keeps track of the n previous visited places [
33]. The prediction algorithm achieved a 70 to 95 percent accuracy for three different datasets. The authors proposed a mining algorithm on the client’s mobility patterns and helped to predict the next location. They used simulation to evaluate the performance of the algorithm.
Furthermore, two other prediction algorithms were used by [
34] called Mobility Prediction based on Transition Matrix (TM) and Ignorant Prediction. Similarly, a model is presented for trajectory pattern discovery for objects that are actively moving [
14]. A movement rule gives a generalized view of a large set of moving objects and allows prediction of the next location of a moving object. Moreover, a technique is developed to predict the next place of a moving object. For a moving object, the prediction of the future location depends on the past developments of every single moving item in a specific range without taking into consideration any data about the user [
12]. The beforehand proposed systems utilized the transient data in order to arrange occasions. The T-pattern was utilized, which considers temporal dimensions.
A future location prediction method, i.e., Spatial-Temporal Recurrent Neural Networks (ST-RNN) was presented by [
20]. The experimental results on real datasets showed that ST-RNN outperformed the futuristic methods and can model the spatial and temporal contexts.
A classification approach for decision trees to predict the next place of mobile users was presented by [
35]. As every client tends to have a broad pattern of behavior, therefore for each individual, the streamlining agent was executed to locate the best parameters combination. Consequently, the execution of this approach was appeared by the results of the examinations on the real-life dataset of 80 mobile clients presented by Nokia.
This research paper presents a process, which includes assembling information from literature and combining it uniquely with the feedback acquired from a few developers and contributors through emails. The surveys carried by the authors consider several algorithms. There are a number of algorithms that need to be evaluated similarly. We have taken into consideration a large pool of algorithms that none of the surveys has considered before this study. There is a gap in choosing trajectory prediction from the available literature. This study provides a platform where all vital parameters are aggregated in a single location.
6. Our Approach
This section describes our approach towards calculating ranking of algorithms based on number of criteria. Our approach focuses on the state-of-the-art, time and data efficient and accurate outdoor algorithm. One of the key observations was that few authors used multiple datasets to validate their approach towards trajectory prediction. We assigned more weight-age to multiple dataset used in various studies. GPS data in outdoor environment was given the most importance while ranking. Similarly, outdoor datasets in comparison to indoors were given more weight. Citation is another important aspect which is considered for ranking algorithms. The more the citations of a given algorithm, the more weight-age is assigned. This also shows more trust in the research community on a particular algorithm.
Ranking System R
(S) was calculated against the following criteria as shown in Equation (
6), where A
(C) defines algorithm accuracy, Y
(R) is year of publication, D
(I) denotes indoor datasets, D
(O) refers to outdoor datasets and C
(T) is the number of citations as per Google Scholar. The higher the given criterion, the higher is the weight-age.
Furthermore, the years in which articles are published and the algorithms authors have used were added. The most recent algorithms were given the higher weightage so that the new accurate prediction algorithms that have less citations can also contribute to the overall ranking. This way the top new algorithms and the old best algorithms with large number of citations can qualify for results. Finally the top three algorithms from the survey were selected.
We further present algorithms information in form of multiple tables. These algorithms are classified into Markov model (
Table 2), hidden Markov model (
Table 3), T-pattern tree (
Table 4), Bayesian network (
Table 5) and distinct algorithms (
Table 6). All these tables show the accuracy and citations of individual algorithms in the respective categories.
Table 1 shows the studies that are surveyed in this paper. The serial number of each row is later used in the ranking.
Table 1 also shows which dataset was used for each algorithm by the authors, and also whether the dataset was publicly available or if it was a propriety dataset. Furthermore, links for data download are available for the public datasets while propriety dataset are restricted. The last column depicts if the algorithm was tested on indoor or outdoor datasets.
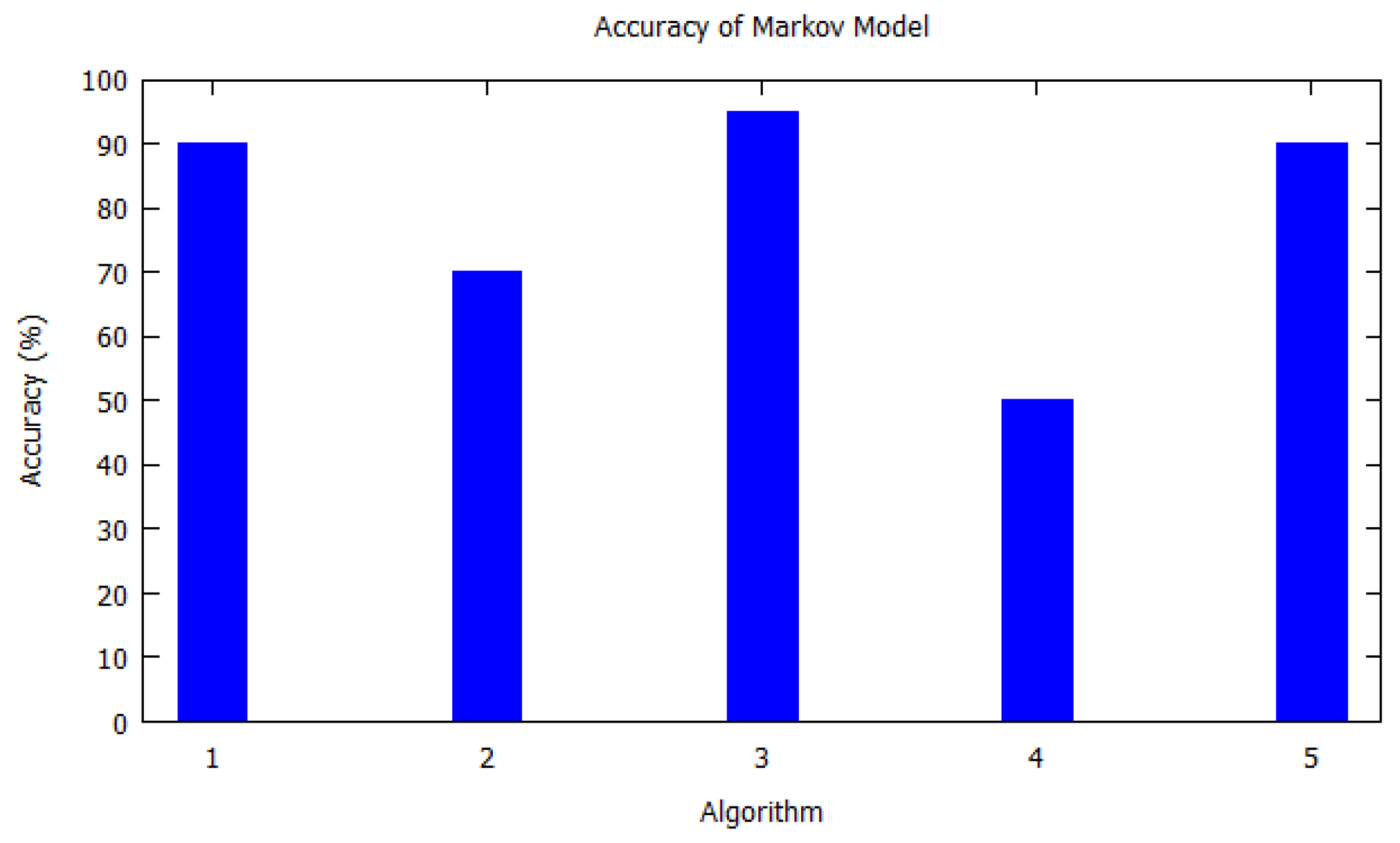
Table 2 shows the papers that have used the Markov model for predicting locations. The data shown in table is our criteria. i.e., the year the paper was published, the accuracy of the predicted algorithms, the datasets used by the algorithms, the citations and indoors or outdoors datasets. Similarly,
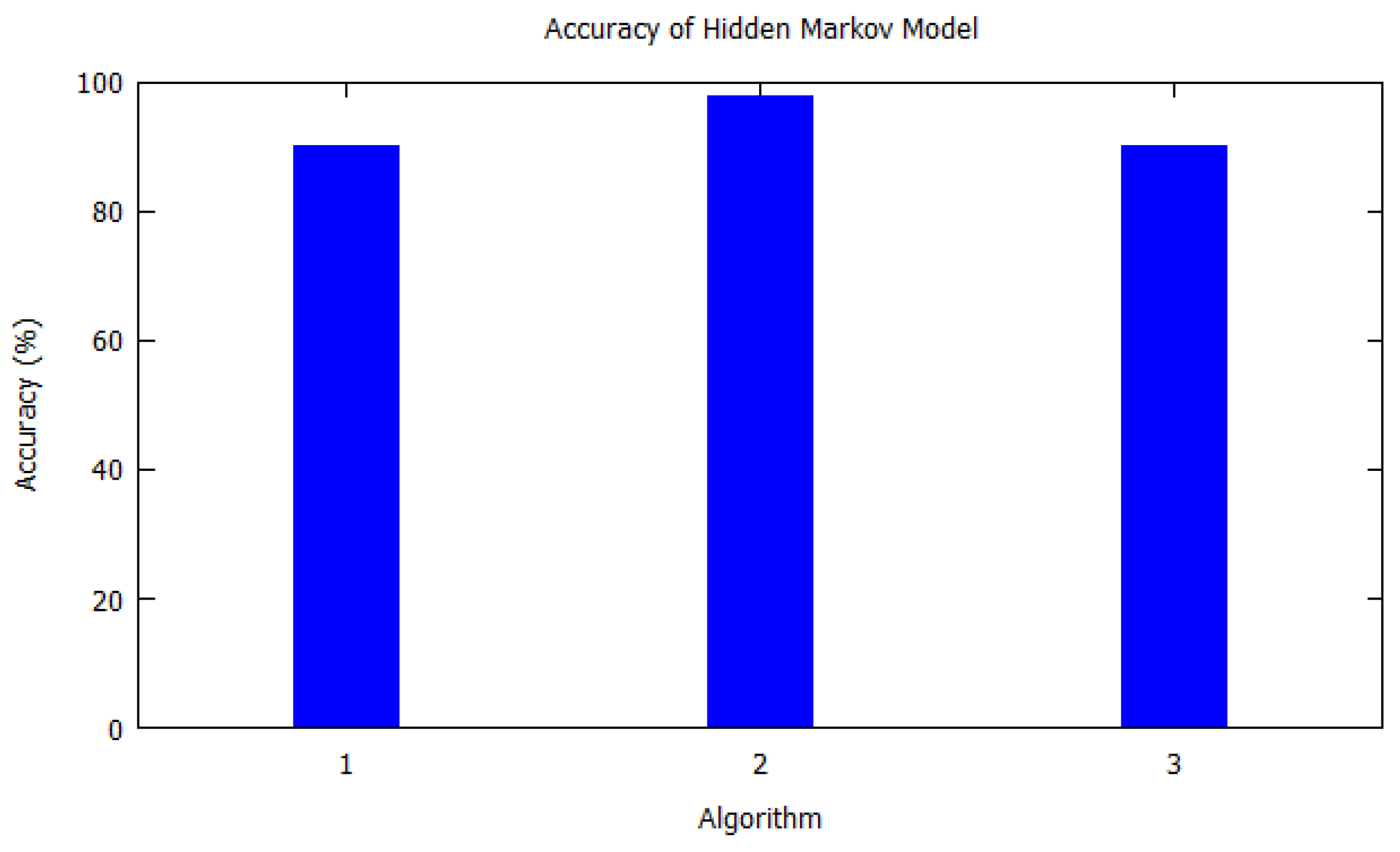
Table 3 shows details of algorithms based on the hidden Markov model.
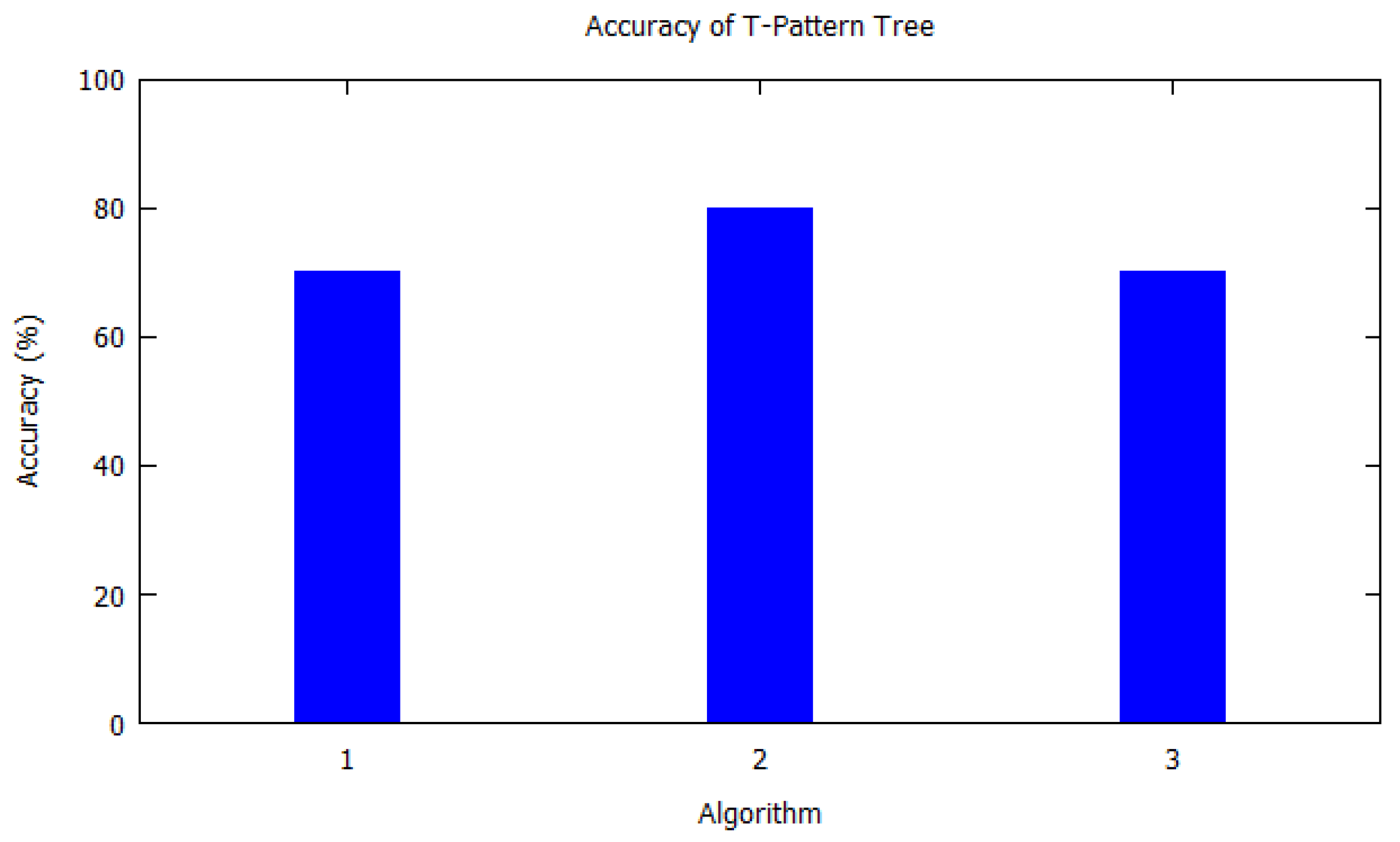
Table 4 shows the T-pattern tree algorithm details. On the other hand,
Table 5 shows the Bayesian network details while the distinct algorithm details are shown in
Table 6. These distinct algorithms are not previously categorized. This information is then fed to the criteria’s logic to find the top three algorithms.
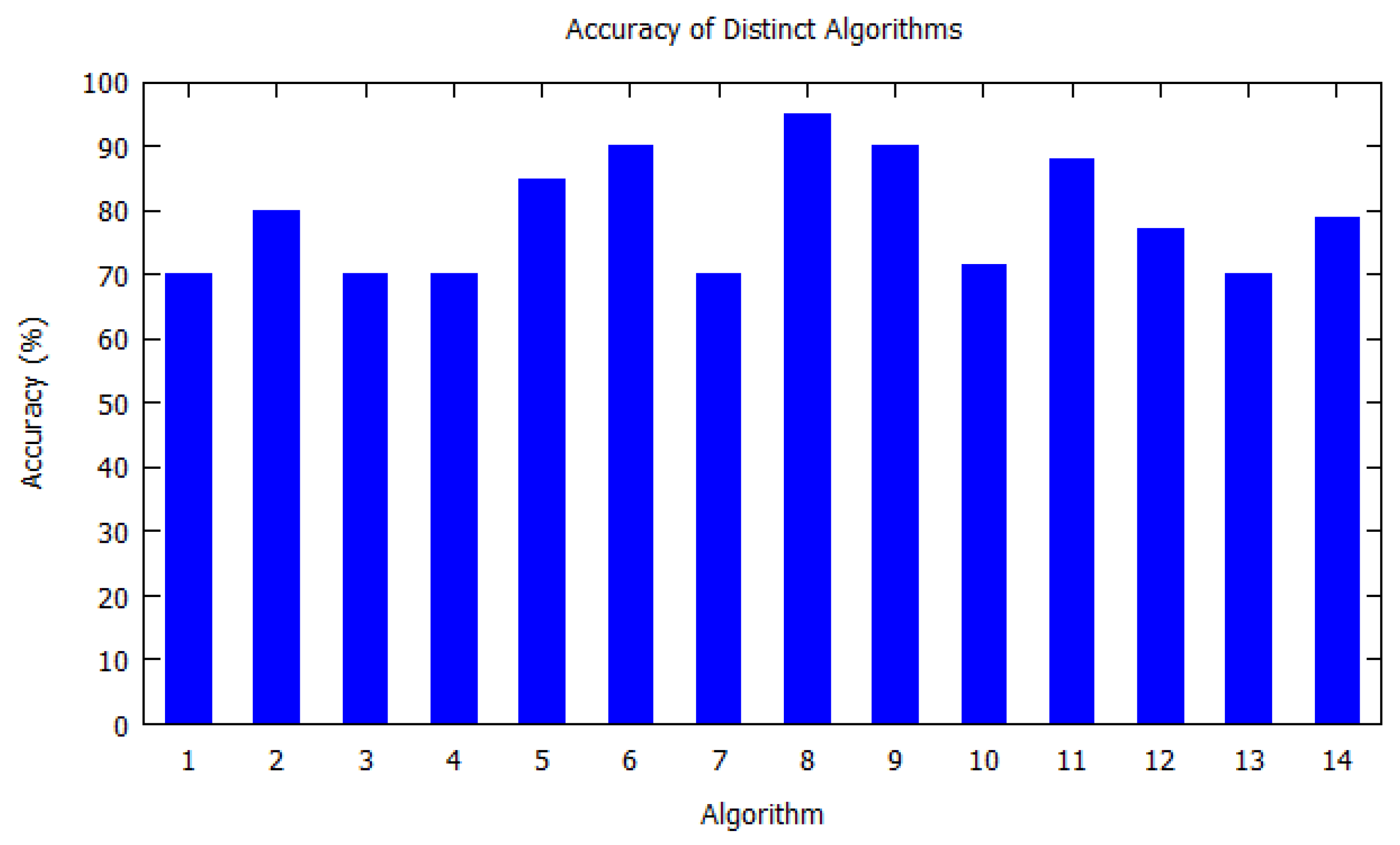
Similarly, bar charts are drawn for improved visual understanding on the accuracy of algorithms. For each table corresponding bar graphs are drawn. In
Figure 2, Markov model from
Table 2 is shown with
X-axis depicting the algorithms used, i.e., the serial number as per
Table 2. Similarly, the
Y-axis shows the accuracy of the algorithm that was used by the authors for that study. In
Figure 3, Hidden Markov model is visualized as per
Table 3.
Figure 4 illustrates the accuracy of algorithms used by the papers in
Table 4 for the T-pattern tree. Similarly,
Figure 5 corresponds to
Table 5 for Bayesian network. The distinct algorithms can be seen in
Figure 6. Most of the algorithms have achieved accuracy more than 70%.
7. Results and Discussion
Based on the proposed methodology, three of the best and unique algorithms were selected. Keeping in mind that if two algorithms made it to the top, one of them was rejected as we wanted to propose three of the best as well as unique algorithms for the survey.
Table 7 highlights the three best algorithms.
A brief discussion of these algorithms is as follows:
Next Place, which qualified at the top as per our algorithm, is a nonlinear time analysis technique was used to predict single user’s most important location. The author used four different datasets and achieved up to 90% probability for users next location along with performance increment of at least 50%. This technique uses a new predictive framework which was developed for a spatiotemporal viewpoint. This does not consider the transitional locations that comes in between the most significant locations of the user. The algorithm predicts the duration of visit, the residence and arrival time of the user. The random behavior which is normally considered as an anomaly is also captured by this approach. The author described an effective technique to predict the user significant location. Once the significant locations are identified then the residence time at those locations are predicted and the amount of time for next visit. NextPlace also predict further in the future which existing models are unable to do. Furthermore, four human movement datasets (which is one of the criteria in our approach) were utilized for this research. These datasets considered total number of attributes including number of users, number of visits, number of significant places, average number of significant places per user, average number of visits per users, average residence time, total trace length, and average time spent by each user in significant places.
In the Markov model, the authors used the algorithm for predicting the nearest route taken by the vehicle driver. Markov Model was used to make probable locations by analyzing the drivers recent routes. The data is analyzed over a long period of time from the GPS history of the vehicle. The algorithm takes account of the discrete road segments. Here, the authors predicted the next road segments with 90% of accuracy. The application of this algorithm is traffic disruptions to drivers and automation of vehicle behaviours using forecasting. The Markov model was the top prediction algorithm as per our criteria and due to its simplicity, effectiveness and accurate prediction.
The hidden Markov model proposes a visit-history-based activity prediction algorithm for services of activity-aware mobile in smart cities named Agatha. The algorithm uses region-based activities, the likelihood that where you have been so far affects what you will do immediately. The casualties are inherent in common daily activities that regularly reveal a development pattern. The model gets such development causalities similarly as an activity course of action plans from supposed ground-breaking settings, for instance, visit place, visit time, term, and transportation mode. This algorithm efficiently deals with the complexity of learning new causalities between various diverse convincing settings. The prediction model was evaluated using the American Time-Use Audit (ATUS) dataset that fuses more than 10,000 individuals’ locations and activity history. The evaluation results show that it can envision customers’ relied upon practices with up to 90% of accuracy for the top three activities. The hidden Markov model also made it to top algorithms as per our methodology.
8. Conclusions
This article provides analysis of 28 algorithms that we surveyed in the area of trajectory location prediction. This survey was carried out to provide guidelines for professionals (researchers and developers) to select best suited algorithms for their needs which was otherwise missing in the literature.
We applied a simple yet effective approach to come up with a ranking of available algorithms. Firstly, an extensive literature review was done to choose candidate algorithms covering the domain of GPS trajectory prediction. In order to preform ranking multiple criteria was selected such as dataset type (public and/or propriety datasets), the number of citations a particular algorithm received over a number of years, and use of outdoor and/or indoor datasets. Moreover, while ranking the algorithms, other parameters are also considered such as accuracy (performance) and ease of use. The results gives top three best algorithms which are selected and recommended as part of this study. These include NextPlace, Markov Model, and Hidden Markov Model. These algorithms when studied are quite simple yet effective for trajectory prediction. Trajectory research has gained a lot of pace in last decade. There are many use cases which can be effectively explored and implemented. For example, health care engineering, transportation, socialization, artificial intelligence, surveillance, and indoor navigation’s.
As part of future work, we plan to add more algorithms which can further strengthen our ranking mechanism. Furthermore, we will consider other factors such as algorithm complexity, application use, bench marking, context awareness, prediction robustness, and integration [
45] for decision-making in electronic health care applications.

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}