In this section, we evaluate the performance of proposed HDL network architecture on both the RobotCar Intersection and the Campus Intersection datasets, with the motivation of exploring its robustness against different camera models. The experimental results are evaluated by using the prevailing metric of accuracy, margin, precision and recall value, as shown below:
where TP, FP, and FN respectively denote the number of true positives, false positives, and false negatives.
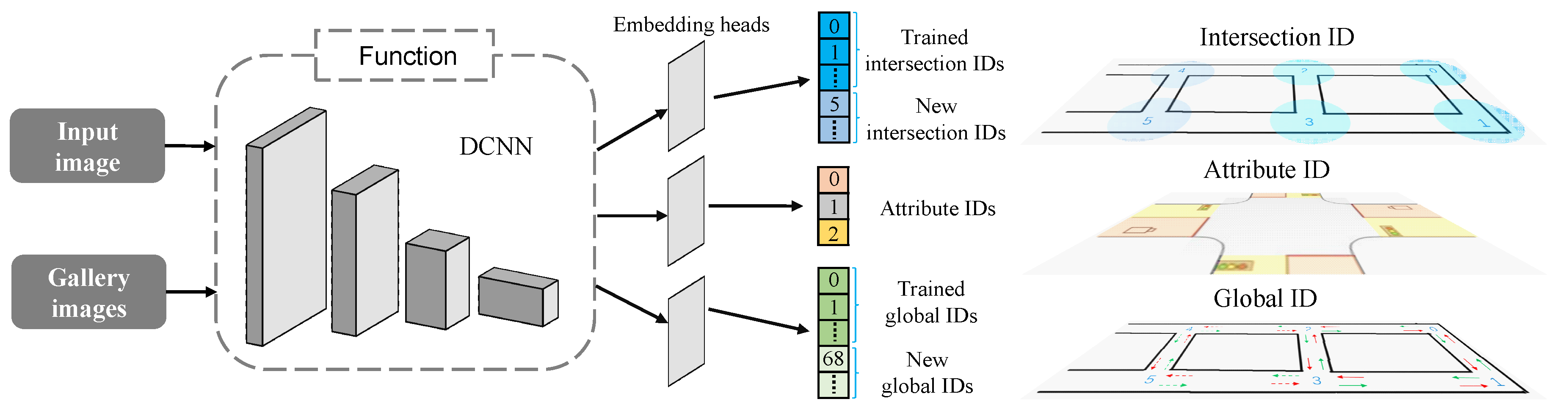
N represents the number of query images. If the similarity between query image and gallery images is larger than a pre-defined threshold, the global ID of the most similar gallery image is assigned to the query image.
5.1. Training Configuration
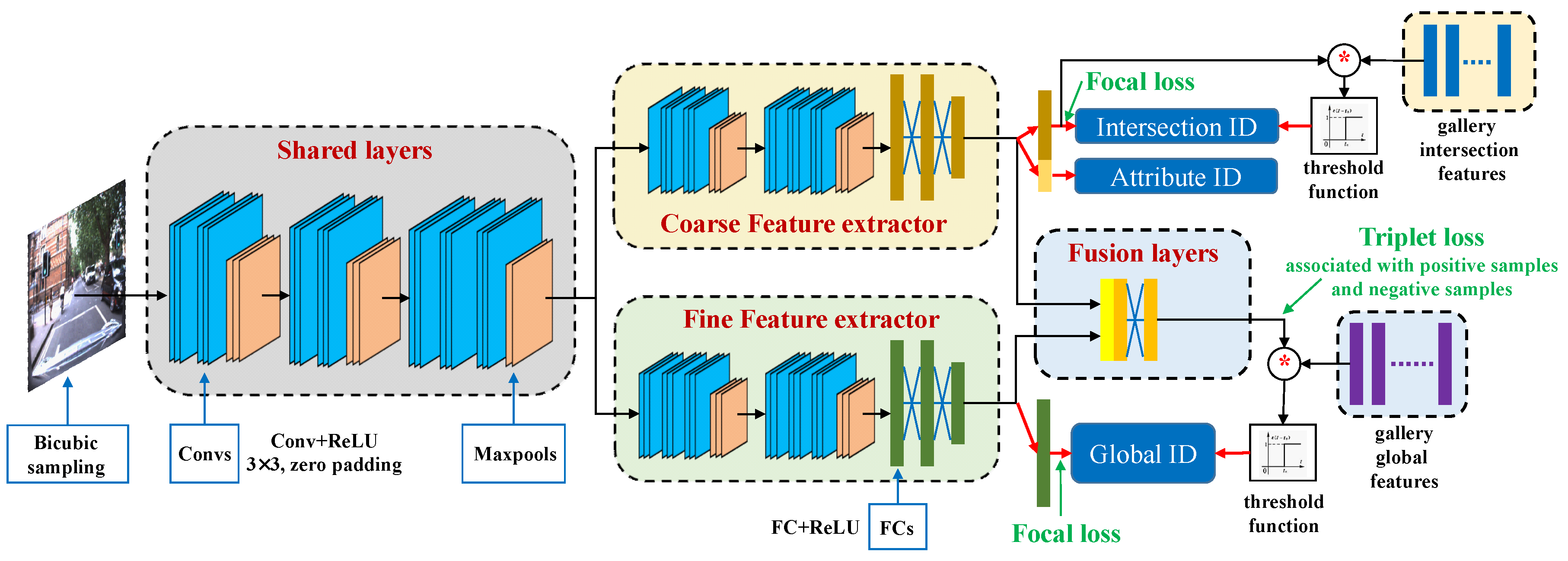
For training, the weights of our proposed network are initialized by the pre-trained layers of a VGG16 [
35] network. In detail, we use the first seven convolutional layers of the pre-trained VGG16 network to initialize the shared layers. The initial weights of each feature extractor are from the remaining layers of the pre-trained network. Weights of the fusion layer are initialized by a uniform distribution
, where
k is the input tensor size. Additionally, our proposed model is trained with respect to a combination of detection loss and embedding loss, as follows:
where
,
and
respectively denote the Focal loss of coarse, fine, and global features.
denotes the triplet loss of global features. The weights
,
,
and
for each loss are empirically set to 0.5, 0.5, 0.5, 1, respectively.
In the training process we use an online triplet mining method to select the most dissimilar positive sample and the most similar negative sample in the embedding space from the training batch. All networks are trained using the stochastic gradient descent (SGD) optimizer with an initial learning rate of 0.001, a weight decay of
and a momentum of 0.9. The Focal loss is adopted with parameters
and
(under such parameters the focal loss can work best [
33]). The batch size is set to 4, which means we need to feed
images in each training iteration (which is a compromise between network convergence speed and GPU computing load). All networks in our experiments are implemented by PyTorch. The evaluation environment is with an Nvidia GTX 1080Ti GPU, an Intel Xeon E5-2667 CPU of 3.2 GHz and a memory of 16 GB.
5.2. Data Augmentation
To enhance the generalization ability of trained networks especially on the illumination change, vehicle sway, camera extrinsic and intrinsic parameter change, we deploy data augmentation methods including random illumination, affine transform, and perspective transform. Since vehicles may also drive in extreme meteorological environments such as the rain or haze, data augmentation by adding rain and fog in images will improve the network performance under the extreme weather. Here, we introduce a nonlinear raindrop model [
36], as shown below
where
is a rainy image.
is the clean background image.
is the rain map and
is the brightness of raindrops. ⊙ represents channel-wise operation between
and
. In order to simulate natural raindrops, we randomly set the raindrop falling direction within the range of
, and the transparency of raindrops from 0.7 to 1.0, as shown in the first row of
Figure 8.
For haze simulation, without the depth information, it is tricky to generate haze with only a single image. Here, we follow the classical haze generation [
37] of atmospheric scattering model as
where
is the observed hazy image value at pixel
x.
is the haze-free scene radiance to be recovered.
is the brightness of the haze.
A denotes the white atmospheric light.
is the transmission matrix which is set with nonlinear proportion of pixel distance between each pixel and vanishing point. The density and brightness of haze is adjusted smoothly from 0.7 to 1.0, as shown in in the second row of
Figure 8.
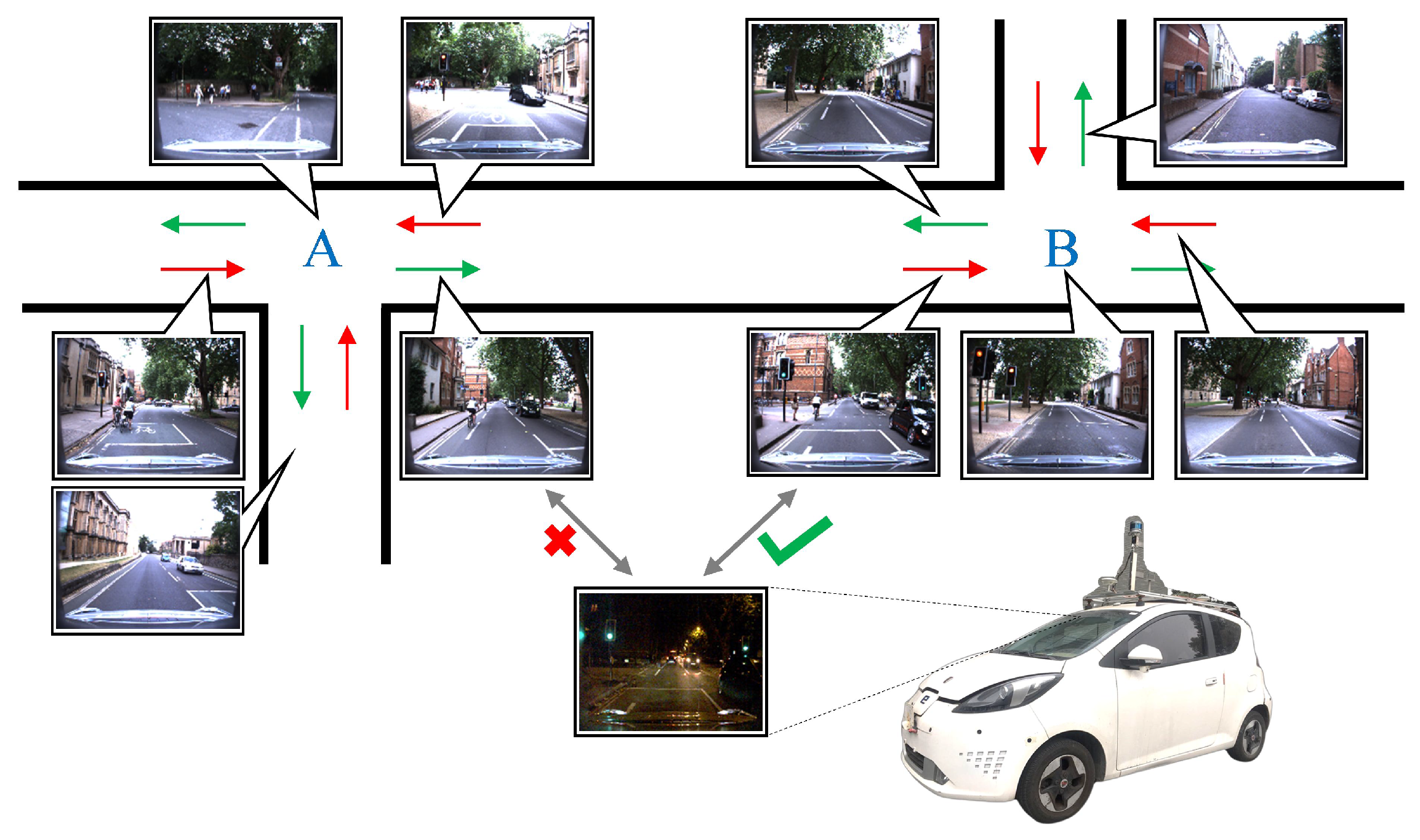
5.3. Evaluation on RobotCar Intersection
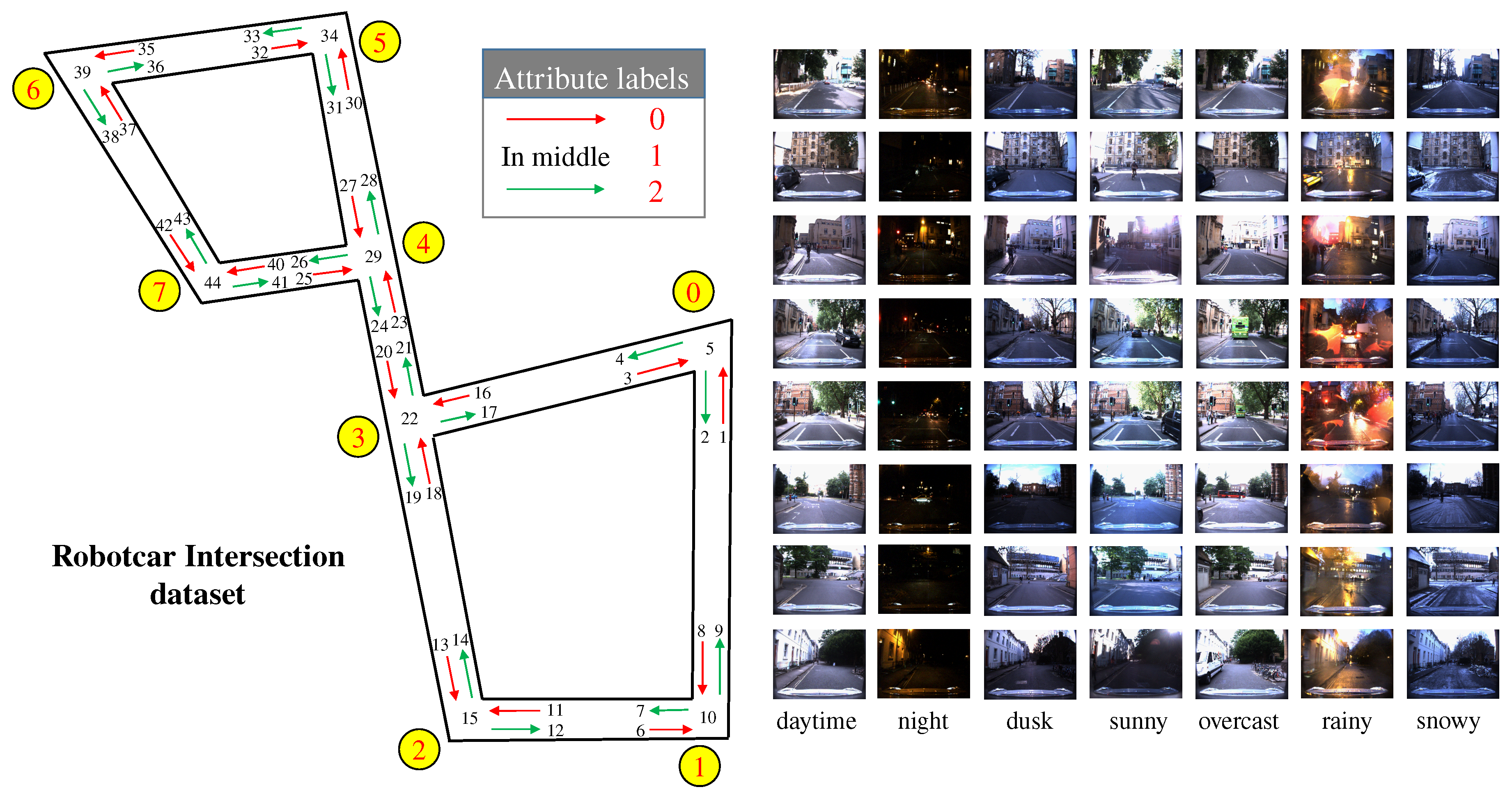
We divide the RobotCar Intersection dataset into two subsets according to the recording date. The first 60% of the total dataset, containing 21,968 images, are used for training. The remaining 40%, containing 14,620 images, are used for testing. The training data covers exactly a full year, allowing the network to fully learn the characteristics of data in different seasons and weather. The testing data are from a time period completely different from the training data.
In this experiment, we evaluate different network structures and augmentation methods. As mentioned in
Section 3.2, we keep the first three blocks as the shared layers and the last three blocks as a feature extractor to build two branch networks (2B). Additionally, we integrate the triplet loss (TRI) instead of the single focal loss (FOC) (only for estimating global ID) to reinterpret the image classification problem as an image re-identification problem. Furthermore, image generation by rain and haze model which forms data augmentation (AUG), are also verified in our experiments. Totally, networks with five different configurations (see
Table 1) are trained. Moreover, we also compare the results of the one branch networks (1B) which cancels the coarse feature extractor from the proposed HDL.
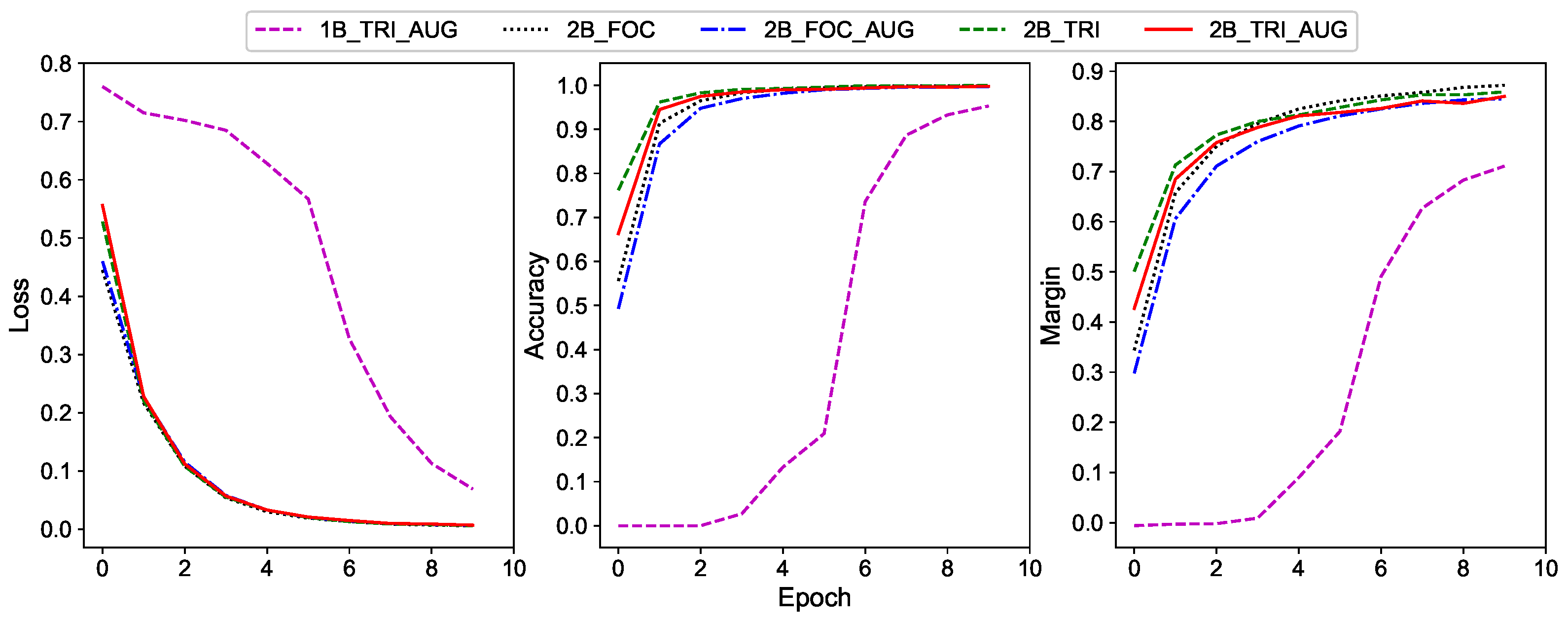
Curves of loss, accuracy, and margin w.r.t. the epoch number are shown in
Figure 9. It is obvious that the utilization of two branch networks can make the loss converge faster than those with only one branch, and the accuracy and margin curves behave similarly. This means that the coarse features indeed help the network to learn the fine features. It can also be seen that employing the triplet loss can accelerate the network learning, which demonstrates the effectiveness of triplet loss. In contrast, training with the data augmentation has larger loss value but less accuracy and margin before the network converges. This can be attributed to the fact that both data augmentation approaches increase the diversity of training data and make the learning process more complicated.
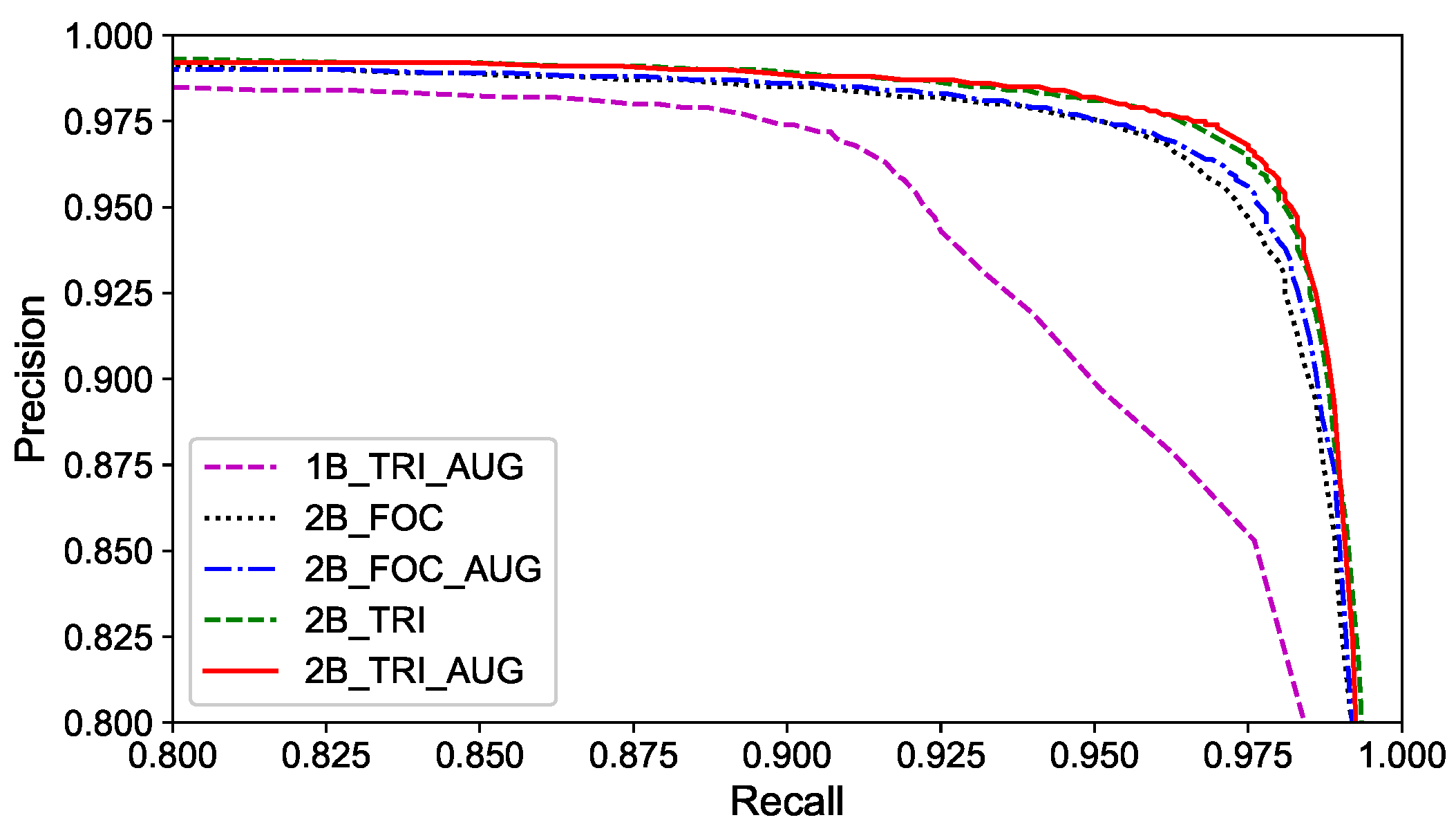
In experiments, the precision–recall (PR) curves of compared methods are depicted in
Figure 10. From the curves, following points can be observed: (1) The method proposed in the paper can achieve high precision on intersection re-identification. (2) The performance of hybrid double-level network is better than that of the single-branch network, which is mainly because the HDL network can integrate coarse-grained features into the mainstream and provide semantic information of different scales. (3) The data augmentation also brings a minor performance gain, which demonstrates the positive effect by improving the diversity of training data.
The quantitative experiments are designed with three additional baseline methods, i.e., the bag-of-words (BOW) [
17], which is frequently used in visual SLAM to determine if a vehicle revisits the starting position in a loop closure detection, ConvNet [
22] and SiameseNet [
24], which are widely used in image classification or image matching for visual place recognition. For a better impression of network performance, we report the precision of evaluated methods w.r.t. different environmental conditions in
Table 2. Normally, because of the low-light, image features of intersections strongly degrade at night compared with the daytime. In addition, the road texture in rainy and snowy weather has lower contrast, and the light scattering of raindrops also forms light spots on the image. All of these phenomena mentioned have severely affected the performance of the traditional bag-of-words method. However, the precision of deep learning based methods fluctuates much less. We owe it to the fact that the neural network can automatically learn more distinctive and robust intersection information from the image feature embedding space than the hand-crafted features used in traditional methods.
From the results in
Table 2, our proposed methods surpass the three baseline methods in the test on RobotCar Intersection data. This depends on the reasonable network structure and mixed loss. It can also be seen that the training with data augmentation fused with rain and haze model can further improve the precision of intersection re-identification. This is because the training and test dataset contains a small number of images captured during light rain or on a wet road. Training with augmented image data from rain and haze model alleviates the imbalance of training samples. This also shows that the utilized rain and haze model can well simulate the image noise by rain and haze in the real traffic environment. For a further analysis, we also add generated rain and haze images (which are different from the images used in training) to the test data and re-evaluate each network. The dataset becomes more difficult, which can be seen from the decreased precision results shown in
Table 3. However, the networks trained on augmented data still obtain better re-identification results on the augmented test data.
Since dynamic objects can also interfere with the captured intersection scene by camera sensor, we conduct further experiments to evaluate the performance of proposed approach in different traffic flows. First, we assign intersection images of test set with labels which indicate different traffic flow: 0 for less surrounding dynamic objects, and 1 for more dynamic objects. The precision of compared methods are shown in
Table 4 and
Table 5.
Comparing results in
Table 4 and
Table 5, it is obvious that the accuracy of all intersection re-ID methods is reduced in high traffic flow with more dynamic traffic participants. This is mainly because the surrounding dynamic targets occlude part of the image of static environmental background, which makes some landmark signs, e.g., road markings, traffic facilities, surrounding buildings, not well recognized, and thus causes the mis-identification of intersection images. However, as seen from the comparison results, our proposed approach only exhibits a small accuracy decline and still outperforms other compared approaches.
In addition, the test results of BOW [
17] show that the images captured on overcast days can be better recognized in different traffic flow. This indicates that the intersection images in overcast condition have richer textures than in other conditions, since the training of BOW [
17] is to extract all point features in images. Moreover, the network by the training with rain-haze augmentation (2B + TRI + AUG), in some extreme environmental conditions, such as in the rain, can obtain better re-identification results. This is mainly because the rain-haze augmentation imposes noise disturbance (which resembles the real scene) on the network. This enables the network to extract more robust features from the static environmental background.
5.4. Results on Campus Intersection
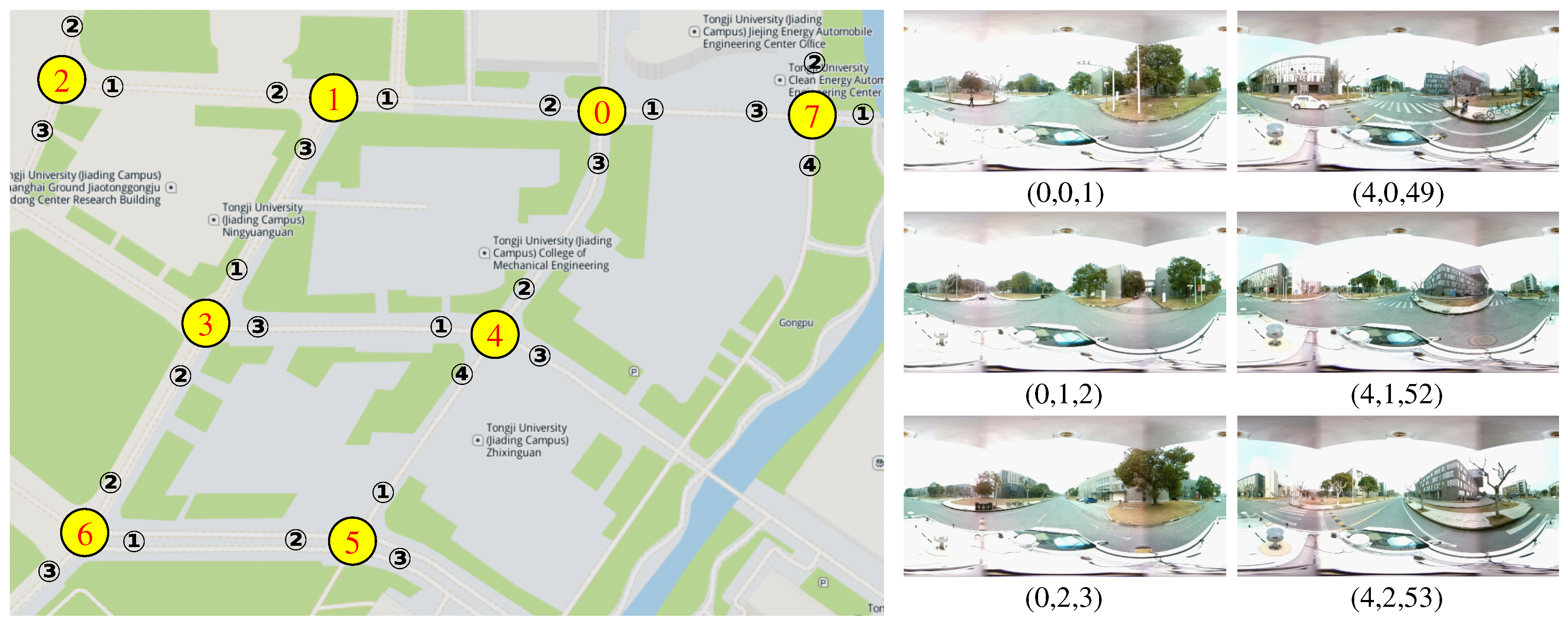
In this chapter, we use the Campus Intersection dataset to accomplish two main tasks: (1) verifying the effectiveness of the proposed method under panoramic camera modality; and (2) verifying if the double-level network could be used to detect new intersection images and expand the topological map. Hence, we divide the Campus Intersection dataset into two subsets according to the intersection ID. The 60% data of the first five intersections, containing 1456 images, are used to train the network. The remaining 40% images of the first five intersections, containing 995 images, are used to test the network on panoramic intersection images for existed intersection re-ID. The images of the last three intersections, containing 897 images, build the other subset of new intersection images and are used for the re-ID task of new intersections.
Due to minor changes in weather condition, in this experiment, we solely employ the double-level network with triplet loss and without rain-haze augmentation (2B + TRI). Similarly, images of each global ID are randomly selected from training images to form gallery images. Each testing image then is compared with each gallery image by the similarity function, and we calculate the accuracy of re-identification. The high precision results from the first row of the
Table 6 show that the proposed network can well detect existed intersections with their intersection ID and attribute ID in the panorama image modality; meanwhile, it can re-identify the intersection with the global ID.
Moreover, according to the expansion strategy of intersection topological map, the proposed network structure must be able to detect new intersection images, which can be categorized into two types: the first type of image is from an existed intersection but at a new lane or in a new direction. Thus, it is with a high intersection ID similarity but with a low global ID similarity. The second image type is from an entire new intersection, and thus with low similarities for both kinds of IDs. In this part of experiment, we use the global intersection ID to detect new intersection images. To determine the optimal threshold of similarity function, we first obtain the histograms by summarizing the similarity values between all query images (existed IDs and new IDs) and gallery images. Then, we set the trough of the histograms as the threshold, which is 0.87 for best detect precision of global ID. By adopting the optimal parameter settings in our experiment, the detection precision of attribute ID is 0.855 and for global ID, it is 0.990, as shown in the second row of
Table 6.
For images with the same new global ID, we randomly select one of them and add it to the gallery. Then, we run the re-ID test with the new gallery again. The results are shown in the third row of
Table 6 and demonstrate that our proposed intersection re-ID network can successfully handle images of new IDs. Since the attribute ID is from the classification of coarse features, it will be consistent with the result of the second row. Now, the gallery is updated by the images of new IDs, then forming larger closed-paths. All the query images in the larger area will be tested and shown in the forth row of
Table 6. All the results in
Table 6 show that our proposed network are suitable for road intersection re-identification.
In the intelligent driving system, real-time performance is usually an important performance parameter of the designed network model. In the experiments, our approach can achieve a fast image processing speed of 16 frames per second (FPS). It can be applied in real-time autonomous driving tasks.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}