AF-SSD: An Accurate and Fast Single Shot Detector for High Spatial Remote Sensing Imagery




Abstract
:1. Introduction
- To improve detection accuracy for small targets, a novel encoding–decoding module is proposed. In this module, we fuse low-level features with up-sampled high-level features to gain rich semantic information for small targets. In this way, our method with feature maps at different scales is capable of detecting both small and large targets accurately. Our up-sampling and fusion operations are very light and only add a few parameters to the network. Besides, we only regard some of these feature maps as prediction layers to reduce computation in the following steps.
- Compared with the background, features of low-contrast targets, like edge information, are not obvious, and they are more likely to be ignored by detectors. For few-texture targets, there is little information on their own and environmental information is of great importance. Therefore, we apply a cascade structure with spatial and channel attention modules to detect low-contrast and few-texture targets precisely. By calculating spatial relationships between pixels and weighting each pixel in a feature map, the spatial attention module can add contextual information for few-texture targets. The channel attention module weights each channel of a feature map by learned weights, which can guide the network to pay attention to important features for few-texture and low-contrast targets.
- To reduce the number of parameters, we design a lightweight backbone. However, lightweight networks usually have problems in feature extraction and have poor detection performance. To avoid these problems, we also apply some wide and deep convolutional blocks in the backbone to enhance the ability to capture semantic features of the network and keep the detection accuracy constant.
2. Materials and Methods
2.1. Lightweight Backbone
2.2. Novel Encoding–Decoding Module
2.3. Cascade Structure with Spatial and Channel Attention Modules
2.3.1. Spatial Attention Module
2.3.2. Channel Attention Module
2.3.3. Cascade Structure
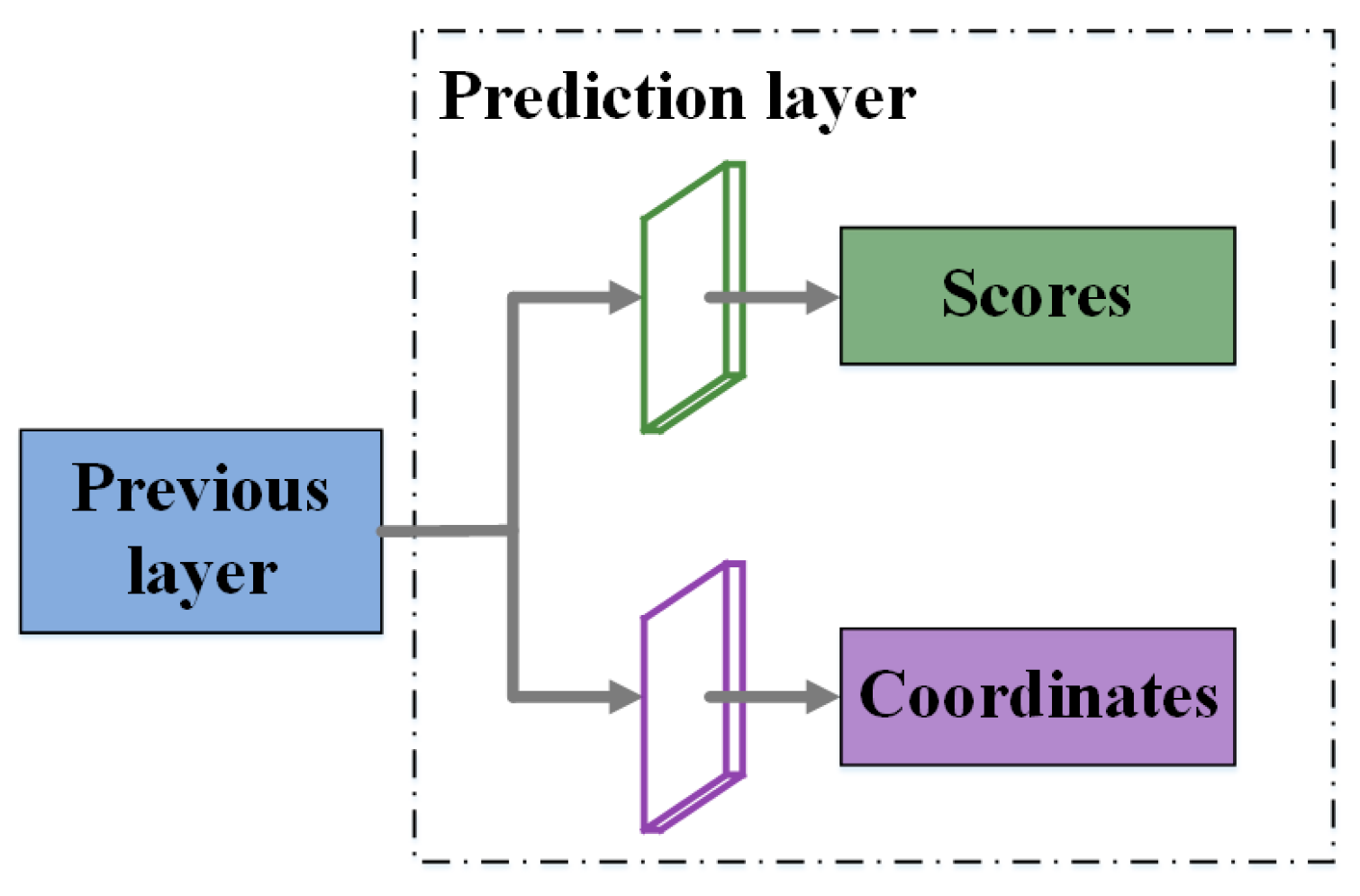
2.4. Prediction Layers
2.5. Loss Function
3. Results and Discussions
3.1. Datasets and Evaluation Metric
3.1.1. Dataset Description
3.1.2. Evaluation Metric
3.2. Implementation Details
3.3. Experimental Results and Discussions
- (1)
- (2)
- Compared with one-stage methods YOLOv2 [38], NEOON [25], SSD [4], and the method in [24], our method has the highest performance, 28.2%, 11.2%, 8.2%, and 4.9% higher than them, respectively. Particularly, for some categories, like Airplane, Ship, Tennis court, and Bridge, the AP values of our method gain significant improvement and show the superiority of our framework.
- (3)
- The AF-SSD also outperforms the two-stage methods R-P-Faster RCNN [34] and Faster R-CNN [10] by 12.2% and 7.8%, respectively, and has better performance in the categories Airplane, Ship, Storage tank, Tennis court, Ground track field, Harbor, Bridge, and Vehicle. This verifies that our method has outstanding performance for small, low-contrast, and few-texture objects.
- (4)
3.4. Ablation Study
- Light backbone: we apply the lightweight backbone in Section 2.1 to illustrate its effectiveness. There is no encoding–decoding module or cascade attention module in this model.
- Light backbone + EDM: an encoding–decoding module (EDM) is added to Setting 1 to enhance low-level features. Due to a large number of small targets in remote sensing images, we only apply feature maps to prediction.
- Light backbone + EDM + Cascade: we apply a cascade structure with spatial and channel attention modules before prediction layers on Setting 2, which is designed to gain global and important features for both low-contrast and few-texture objects.
- Light backbone + EDM + Cascade + Leaky ReLU: we replace ReLU in the network by Leaky ReLU to alleviate the negative influence that ReLU has in the interval . This structure is our AF-SSD.
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship rotated bounding box space for ship extraction from high-resolution optical satellite images with complex backgrounds. IEEE Geosci. Remote Sens. Lett. 2017, 13, 1074–1078. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. Dota: A large-scale dataset for object detection in aerial images. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the 2018 European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Detnet: A backbone network for object detection. arXiv 2018, arXiv:1804.06215. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 354–370. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-Cnn: Towards real-time object detection with region proposal networks. In Proceedings of the 2015 Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-Fcn: Object detection via region-based fully convolutional networks. In Proceedings of the 2016 Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-Cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Fu, C.-Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Zheng, L.; Fu, C.; Zhao, Y. Extend the shallow part of single shot multibox detector via convolutional neural network. arXiv 2018, arXiv:1801.05918. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: Feature Fusion Single Shot Multibox Detector. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Uijlings, J.R.R.; Sande, K.E.A.V.D.; Gevers, T.; Smeulders, A.W.M. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (Voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the 2014 European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Zhang, X.; Zhu, K.; Chen, G.; Tan, X.; Zhang, L.; Dai, F.; Liao, P.; Gong, Y. Geospatial object detection on high resolution remote sensing imagery based on double multi-scale feature pyramid network. Remote Sens. 2019, 11, 755. [Google Scholar] [CrossRef] [Green Version]
- Mo, N.; Yan, L.; Zhu, R.; Xie, H. Class-specific anchor based and context-guided multi-class object detection in high resolution remote sensing imagery with a convolutional neural network. Remote Sens. 2019, 11, 272. [Google Scholar] [CrossRef] [Green Version]
- Zhuang, S.; Wang, P.; Jiang, B.; Wang, G.; Wang, C. A Single shot framework with multi-scale feature fusion for geospatial object detection. Remote Sens. 2019, 11, 594. [Google Scholar] [CrossRef] [Green Version]
- Xie, W.; Qin, H.; Li, Y.; Wang, Z.; Lei, J. A novel effectively optimized one-stage network for object detection in remote sensing imagery. Remote Sens. 2019, 11, 1376. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. Shufflenet V2: Practical guidelines for efficient cnn architecture design. In Proceedings of the 2018 European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. In Proceedings of the 2019 IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6054–6063. [Google Scholar]
- Hu, P.; Ramanan, D. Finding tiny faces. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 951–959. [Google Scholar]
- Zhang, S.; Yang, J.; Schiele, B. Occluded pedestrian detection through guided attention in CNNs. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6995–7003. [Google Scholar]
- Han, X.; Zhong, Y.; Zhang, L. An efficient and robust integrated geospatial object detection framework for high spatial resolution remote sensing imagery. Remote Sens. 2017, 9, 666. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 850–855. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolo9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; p. 3. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Operator | Stride | Output Size | ||
|---|---|---|---|---|---|
| MobileNetV1 | Conv1 | Conv1_1 | Conv3x3 | 2 | 150 × 150 × 32 |
| Conv1_2 | SepConv3x3 | 1 | 150 × 150 × 64 | ||
| Conv2 | Conv2_1 | SepConv3x3 | 2 | 75 × 75 × 128 | |
| Conv2_2 | SepConv3x3 | 1 | 75 × 75 × 128 | ||
| Conv2_3 | SepConv3x3 | 1 | 75 × 75 × 256 | ||
| Conv2_4 | SepConv3x3 | 1 | 75 × 75 × 256 | ||
| Conv3 | Conv3_1 | SepConv3x3 | 2 | 38 × 38 × 512 | |
| Conv3_2 | SepConv3x3 | 1 | 38 × 38 × 512 | ||
| Conv3_3 | SepConv3x3 | 1 | 38 × 38 × 512 | ||
| Conv3_4 | SepConv3x3 | 1 | 38 × 38 × 512 | ||
| Conv3_5 | SepConv3x3 | 1 | 38 × 38 × 512 | ||
| Conv3_6 | SepConv3x3 | 1 | 38 × 38 × 512 | ||
| Conv4 | Conv4_1 | SepConv3x3 | 2 | 19 × 19 × 1024 | |
| Conv4_2 | SepConv3x3 | 1 | 19 × 19 × 1024 | ||
| Extra Conv Layers | Conv5 | Conv5 | Shufflev2_block | 2 | 10 × 10 × 512 |
| Conv6 | Conv6 | Shufflev2_block | 2 | 5 × 5 × 256 | |
| Conv7 | Conv7_1 | Conv1x1 | 1 | 5 × 5 × 128 | |
| Conv7_2 | SepConv3x3 | 1 | 3 × 3 × 256 | ||
| Conv8 | Conv8_1 | Conv1x1 | 1 | 3 × 3 × 128 | |
| Conv8_2 | SepConv3x3 | 1 | 1 × 1 × 256 | ||
| Method | mAP | PL | SP | ST | BD | TC | BC | GTF | HB | BR | VH |
|---|---|---|---|---|---|---|---|---|---|---|---|
| COPD | 54.6 | 62.3 | 68.9 | 63.7 | 83.3 | 32.1 | 36.3 | 85.3 | 55.3 | 14.8 | 44.0 |
| YOLOv2 | 60.5 | 73.3 | 74.9 | 34.4 | 88.9 | 29.1 | 27.6 | 98.8 | 75.4 | 51.8 | 51.3 |
| RICNN | 72.6 | 88.4 | 77.3 | 85.3 | 88.1 | 40.8 | 58.5 | 86.7 | 68.6 | 61.5 | 71.1 |
| R-P-Faster RCNN | 76.5 | 90.4 | 75.0 | 44.4 | 89.9 | 79.7 | 77.6 | 87.7 | 79.1 | 68.2 | 73.2 |
| NEOON | 77.5 | 78.3 | 81.7 | 94.6 | 89.7 | 61.3 | 65.0 | 93.2 | 73.2 | 59.5 | 78.3 |
| SSD# | 80.5 | 94.3 | 70.9 | 69.6 | 89.7 | 80.0 | 76.2 | 96.9 | 84.7 | 82.3 | 60.2 |
| Faster RCNN | 80.9 | 94.6 | 82.3 | 65.3 | 95.5 | 81.9 | 89.7 | 92.4 | 72.4 | 57.5 | 77.8 |
| [24] | 83.8 | 93.4 | 77.1 | 87.5 | 93.0 | 82.7 | 83.8 | 83.7 | 82.5 | 72.5 | 82.3 |
| CACMOD CNN | 90.4 | 96.9 | 90.0 | 84.8 | 96.3 | 94.7 | 88.6 | 94.8 | 95.8 | 86.4 | 76.0 |
| Ours | 88.7 | 99.0 | 85.5 | 90.5 | 95.6 | 87.1 | 74.6 | 98.7 | 86.8 | 86.1 | 82.8 |
| Method | Average Running Time (s) |
|---|---|
| COPD | 1.070 |
| YOLOv2 | 0.026 |
| RICNN | 8.770 |
| R-P-Faster RCNN | 0.150 |
| NEOON | 0.059 |
| SSD# | 0.042 |
| Faster RCNN | 0.430 |
| [24] | 0.057 |
| CACMOD CNN | 2.700 |
| Ours | 0.035 |
| Method | mAP | PL | SP | ST | BD | TC | BC | GTF | HB | BR | VH |
|---|---|---|---|---|---|---|---|---|---|---|---|
| SSD# | 80.5 | 94.3 | 70.9 | 69.6 | 89.7 | 80.0 | 76.2 | 96.9 | 84.7 | 82.3 | 60.2 |
| Light | 80.8 | 90.9 | 73.1 | 72.2 | 92.5 | 82.3 | 72.0 | 98.3 | 81.6 | 85.1 | 59.7 |
| Light + EDM | 86.5 | 96.7 | 85.5 | 90.3 | 97.8 | 84.3 | 66.8 | 98.4 | 86.5 | 77.3 | 81.6 |
| Light + EDM + Cascade | 88.2 | 98.5 | 85.1 | 90.2 | 90.1 | 85.9 | 76.1 | 99.0 | 85.3 | 89.0 | 83.0 |
| AF-SSD | 88.7 | 99.0 | 85.5 | 90.5 | 95.6 | 87.1 | 74.6 | 98.7 | 86.8 | 86.1 | 82.8 |
| Method | Parameters |
|---|---|
| SSD# | 24.9 M |
| Light | 4.3 M |
| Light + EDM | 4.9 M |
| Light + EDM + Cascade | 5.7 M |
| AF-SSD | 5.7 M |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, R.; Zhao, W.; Fan, X.; Yin, Y. AF-SSD: An Accurate and Fast Single Shot Detector for High Spatial Remote Sensing Imagery. Sensors 2020, 20, 6530. https://doi.org/10.3390/s20226530
Yin R, Zhao W, Fan X, Yin Y. AF-SSD: An Accurate and Fast Single Shot Detector for High Spatial Remote Sensing Imagery. Sensors. 2020; 20(22):6530. https://doi.org/10.3390/s20226530
Chicago/Turabian StyleYin, Ruihong, Wei Zhao, Xudong Fan, and Yongfeng Yin. 2020. "AF-SSD: An Accurate and Fast Single Shot Detector for High Spatial Remote Sensing Imagery" Sensors 20, no. 22: 6530. https://doi.org/10.3390/s20226530
APA StyleYin, R., Zhao, W., Fan, X., & Yin, Y. (2020). AF-SSD: An Accurate and Fast Single Shot Detector for High Spatial Remote Sensing Imagery. Sensors, 20(22), 6530. https://doi.org/10.3390/s20226530