Face Memorization Using AIM Model for Mobile Robot and Its Application to Name Calling Function


Abstract
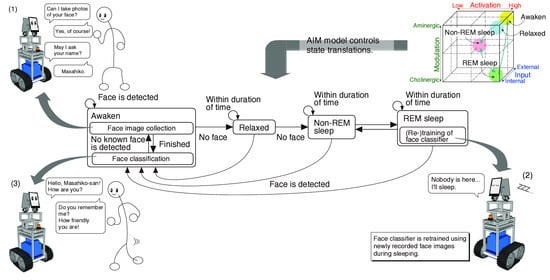
1. Introduction
2. Face Memorization System for a Mobile Robot
2.1. System Outline
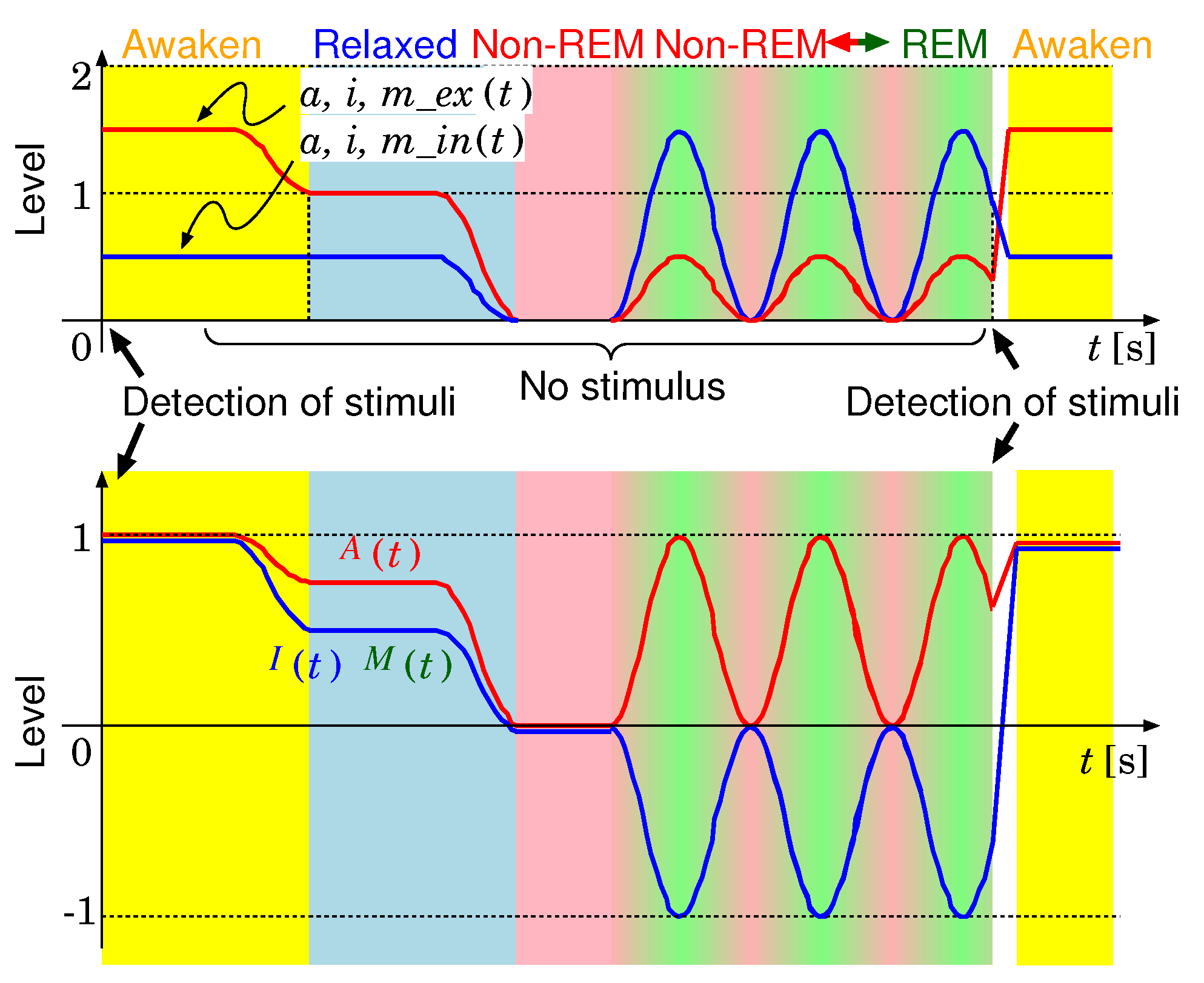
2.2. Mathematical AIM Model
2.3. Processes for Face Memorization Function Controlled by the AIM Model
2.4. Face Memorization
2.5. Consciousness State Transition
3. Experimental System
3.1. System Configuration
3.2. Implementation of the Face Classifier
3.3. Effectiveness of AIM Model
4. Experimental Results
4.1. Outline of Experiments
- (1)
- The robot calls a research participant using her/his name during a conversation.
- (2)
- The robot calls the participant using the pronoun “you” during a conversation.
- (a)
- The robot has a face memorization function.
- (b)
- The robot has face expression detection and analysis functions, and has an ability to estimate the position of the joker based on a human’s facial expressions.
- (c)
- The purpose of this experiment is not to win Old Maid, but to let the robot guess which of two cards is the joker correctly.
4.2. Procedure of Experiments
- (1)
- An experimenter explains the fake experiment’s purpose to a research participant in a waiting space, and takes her/him to an experimental space shown in Figure 12 described in the following subsection.
- (2)
- The mobile robot that stands by in the experimental space says hello to the participant.
- (3)
- The robot asks permission to collect her/his name and face images for experimental records.
- (4)
- After the robot finishes collecting the face images, the participant returns to the waiting space once.
- (5)
- The experimenter explains to the participant that she/he has the second and third meetings with the robot and plays the card game six times in one meeting after this explanation. Then the participant enters the experimental space.
- (6)
- After sitting in a chair, she/he shuffles two cards and sets them in a card holder on a table. The robot answers which of two cards is the joker. This transaction is repeated six times in one meeting.
- (7)
- After the second meeting, the participant returns the waiting space again, and answers a questionnaire given by the experimenter.
- (8)
- The procedure (6) is repeated once more as the third meeting.
- (9)
- After the third meeting, the participant returns the waiting space again, and answers another questionnaire given by the experimenter.
- (10)
- The experimenter tells the subject the true purpose of the experiments.
- (i)
- All the experiments were conducted based on the Wizard of Oz (WOZ) method [35]; the mobile robot was teleoperated by a human operator.
- (ii)
- The robot could get the correct position of the joker five out of six times but not the fourth time. This was realized by using a hidden camera.
4.3. Experimental Environment
4.4. Evaluation Results
4.5. Discussion
- (1)
- Some participants did not notice the difference between the second and third meeting with the robot.
- (2)
- Some participants believed that the robot really had the ability to estimate the position of the joker based on human facial expressions. Since the robot could estimate correctly five out of six times, they had the impression that this robot’s ability was awesome.
- (3)
- Since the way of the robot’s speaking using the text-to-speech software was polite and humble, some participants had good impressions of the robot.
- (4)
- The two CG eyes of the robot shown in Figure 9 sometimes blinked and the line of sight was changed. However, since the movements were not synchronized with the conversation, there were some research participants who answered the questionnaire by saying that “it was impersonal”.
- (a)
- Despite the simple experimental environment, the contents of the experiment and the behaviors and appearance of the robot might have some influence on the impression evaluation.
- (b)
- The experiments were conducted based on the WOZ in order to avoid malfunctions in image processing and voice recognition.
- (c)
- The number of persons whose faces were memorized by robots was still small.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Dialogue between a Research Participant and the Mobile Robot
Appendix A.1. Fist Meeting: The Robot Collects the Participant’s Face Images and Name
- (1) R:
- Hello. A person has appeared at last. Since there has been nobody until now, I had been bored. I am glad to meet you. Then, let me introduce myself. I am the mobile robot, PIO. I appreciate that you joined this experiment today. I believe that the experimenter has already given you the instructions of this experiment, but for confirmation, I will explain again. I would like you to have three meetings with me. In this first meeting, let me collect your name and face images, as it is necessary for card games in the next meetings. Let me begin by collecting your name and face images. Are you ready?
- (2) P:
- Sure.
- (3) R:
- First of all, I’ll ask your name. Would you tell me your name?
- (4) P:
- XX. (The participant answers her/his name.)
- (5) R:
- XX-san ( The Japanese word, san, means Mr. or Ms. in English). OK, I understood.Next, let me collect your face images. Please keep moving your head from side to side and up and down until I give you a sign. It is going to take about ten seconds. Now, are you ready?
- (6) P:
- Yes.
- (7) R:
- Then I’ll begin. Please start to move your head slowly. (The robot starts to collect the face images).
- (8) R:
- Collecting your face images has finished. Thank you for your cooperation.Would you please return the waiting space until the next meeting?
Appendix A.2. Second or Third Meeting: The Robot Calls a Participant by Her/His Name or Using the Pronoun “You”
- (1) R:
- Hello. Today, I am going to play the card game Old Maid with [XX-san/you]. I will explain to you how to play it. First, please pick both of these two cards on this table, and shuffle them under the table. Secondly, please put the cards into the card stand in light blue. Lastly, when you are ready, please tell me “I am ready.”Then, XX-san, would you shuffle these two cards?
- (2) P:
- I’m ready.
- (3) R:
- Please stare at my eyes. I’ll undertake the analysis.(The robot holds for five seconds to pretend to consider).
- (4) R:
- The analysis has been completed. The joker is on the right (left) side. Is it correct?
- (5) P:
- (Except the 4th turn) Correct.(In the 4th turn) Incorrect.
- (6) R:
- (Except the 4th turn) Well, I am glad the answer is correct.XX-san, thank you for your cooperation/Thank you for your cooperation.(In the 4th turn) Too bad.In spite of XX-san’s/your great effort, my analysis didn’t work well. (Proceed to the next)
- (7) R:
- (In the 1st, 2nd, 3rd or 5th turn) Let’s do our best next time. Let’s move on to the next turn. Then, pick the cards up and shuffle them please. (Return to (2))(In the 4th turn) I’ll do my best next time. Then, pick the cards up and shuffle them please. (Return to (2))(In the 6th turn, proceed to the next (8))
- (8) R:
- The game is over. I’ll show you the results. I could get five correct answers in six turns. Thanks to XX-san/you, the results were great. I really appreciate it.Let’s wrap this up. I was very grad to play the card game with XX-san/you. I really appreciate it. Would you please return to the rest area?
References
- Bartneck, C.; Kanda, T.; Mubin, O.; Mahmud, A. Does the Design of a Robot Influence Its Animacy and Perceived Intelligence? Int. J. Soc. Robot. 2009, 1, 195–204. [Google Scholar] [CrossRef]
- Paiva, A.; Leite, I.; Ribeiro, T. Emotion Modelling for Social Robots. In The Oxford Handbook of Affective Computing; Oxford University Press: Oxford, UK, 2014; pp. 296–419. [Google Scholar]
- Admoni, H.; Scassellati, B. Social Eye Gaze in Human-robot Interaction: A Review. J. Hum.-Robot Interact. 2017, 6, 25–63. [Google Scholar] [CrossRef]
- Wang, E.; Lignos, C.; Vatsal, A.; Scassellati, B. Effects of Head Movement on Perceptions of Humanoid Robot Behavior. In Proceedings of the 1st ACM SIGCHI/SIGART Conference on Human-Robot Interaction (HRI2006), Salt Lake City, UT, USA, 2–3 March 2006; pp. 180–185. [Google Scholar]
- Mikawa, M.; Yoshikawa, Y.; Fujisawa, M. Expression of intention by rotational head movements for teleoperated mobile robot. In Proceedings of the 2018 IEEE 15th International Workshop on Advanced Motion Control (AMC2018), Tokyo, Japan, 9–11 March 2018; pp. 249–254. [Google Scholar]
- Lyu, J.; Mikawa, M.; Fujisawa, M.; Hiiragi, W. Mobile Robot with Previous Announcement of Upcoming Operation Using Face Interface. In Proceedings of the 2019 IEEE/SICE International Symposium on System Integration (SII2019), Paris, France, 14–16 January 2019; pp. 782–787. [Google Scholar]
- Huang, C.M.; Iio, T.; Satake, S.; Kanda, T. Modeling and Controlling Friendliness for An Interactive Museum Robot. In Proceedings of the Robotics: Science and Systems (RSS2014), Berkeley, CA, USA, 12–16 July 2014. [Google Scholar]
- Schulte, J.; Rosenberg, C.; Thrun, S. Spontaneous, short-term interaction with mobile robots. In Proceedings of the 1999 IEEE International Conference on Robotics and Automation, Detroit, MI, USA, 10–15 May 1999; pp. 658–663. [Google Scholar]
- Torta, E.; van Heumen, J.; Cuijpers, R.H.; Juola, J.F. How Can a Robot Attract the Attention of Its Human Partner? A Comparative Study over Different Modalities for Attracting Attention. In Proceedings of the 4th International Conference on Social Robotics, Chengdu, China, 29–31 October 2012; pp. 288–297. [Google Scholar]
- Kanda, T.; Hirano, T.; Eaton, D.; Ishiguro, H. A Practical Experiment with Interactive Humanoid Robots in a Human Society. In Proceedings of the Third IEEE International Conference on Humanoid Robots, Karlsruhe-Munich, Germany, 30 September–3 October 2003. [Google Scholar]
- Kanda, T.; Sato, R.; Saiwaki, N.; Ishiguro, H. A Two-Month Field Trial in an Elementary School for Long-Term Human–Robot Interaction. IEEE Trans. Robot. 2007, 23, 962–971. [Google Scholar] [CrossRef]
- Mitsunaga, N.; Miyashita, T.; Ishiguro, H.; Kogure, K.; Hagita, N. Robovie-IV: A Communication Robot Interacting with People Daily in an Office. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS2006), Beijing, China, 9–15 October 2006; pp. 5066–5072. [Google Scholar]
- Kanda, T.; Shiomi, M.; Miyashita, Z.; Ishiguro, H.; Hagita, N. An affective guide robot in a shopping mall. In Proceedings of the 2009 4th ACM/IEEE International Conference on Human-Robot Interaction, La Jolla, CA, USA, 11–13 March 2009; pp. 173–180. [Google Scholar]
- Chen, X.; Williams, A. Improving Engagement by Letting Social Robots Learn and Call Your Name. In Proceedings of the Companion of the 2020 ACM/IEEE International Conference on Human-Robot Interaction, Cambridge, UK, 23–26 March 2020; pp. 160–162. [Google Scholar]
- Vezzetti, E.; Marcolin, F.; Tornincasa, S.; Ulrich, L.; Dagnes, N. 3D geometry-based automatic landmark localization in presence of facial occlusions. Multimed. Tools Appl. 2018, 77, 14177–14205. [Google Scholar] [CrossRef]
- Lin, T.; Chiu, C.; Tang, C. Rgb-D Based Multi-Modal Deep Learning for Face Identification. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal, Barcelona, Spain, 4–8 May 2020; pp. 1668–1672. [Google Scholar]
- George, A.; Mostaani, Z.; Geissenbuhler, D.; Nikisins, O.; Anjos, A.; Marcel, S. Biometric Face Presentation Attack Detection With Multi-Channel Convolutional Neural Network. IEEE Trans. Inf. Forensics Secur. 2020, 15, 42–55. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. ArcFace: Additive Angular Margin Loss for Deep Face Recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4685–4694. [Google Scholar]
- Chen, H.; Mikawa, M.; Fujisawa, M.; Hiiragi, W. Face Memorization System Using the Mathematical AIM Model for Mobile Robot. In Proceedings of the 2019 IEEE/SICE International Symposium on System Integration (SII2019), Paris, France, 14–16 January 2019; pp. 651–656. [Google Scholar]
- Allan Hobson, J. The Dream Drugstore; The MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Mikawa, M.; Yoshikawa, M.; Tsujimura, T.; Tanaka, K. Intelligent Perceptual Information Parallel Processing System Controlled by Mathematical AIM Model. In Proceedings of the 2007 7th IEEE-RAS International Conference on Humanoid Robots, Pittsburgh, PA, USA, 29 November–1 December 2007; pp. 389–403. [Google Scholar]
- Mikawa, M.; Yoshikawa, M.; Tsujimura, T.; Tanaka, K. Librarian Robot Controlled by Mathematical AIM Model. In Proceedings of the ICROS-SICE International Joint Conference, Fukuoka, Japan, 18–21 August 2009; pp. 1200–1205. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Sandberg, D. Face Recognition Using Tensorflow. Available online: https://github.com/davidsandberg/facenet (accessed on 2 October 2019).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Lee, A.; Kawahara, T.; Shikano, K. Julius—An Open Source Real-Time Large Vocabulary Recognition Engine. In Proceedings of the 7th European Conference on Speech Communication and Technology (EUROSPEECH 2001), Aalborg, Denmark, 3–7 September 2001; p. 1691. [Google Scholar]
- Open JTalk. Available online: http://open-jtalk.sourceforge.net (accessed on 7 October 2020).
- ROS (Robot Operating System). Available online: http://wiki.ros.org (accessed on 7 October 2020).
- TensorFlow. Available online: https://www.tensorflow.org (accessed on 7 October 2020).
- Bradski, G. The OpenCV Library. Dr. Dobb’S J. Softw. Tools 2000, 25, 120, 122–125. [Google Scholar]
- Lee, A.; Kawahara, T. Julius-Speech/Julius: Release 4.5. 2019. Available online: https://doi.org/10.5281/zenodo.2530396 (accessed on 7 October 2020).
- Traeger, M.L.; Strohkorb, S.S.; Jung, M.; Scassellati, B.; Christakis, N.A. Vulnerable robots positively shape human conversational dynamics in a human–robot team. Proc. Natl. Acad. Sci. USA 2020, 117, 6370–6375. [Google Scholar] [CrossRef] [PubMed]
- Mikawa, M.; Lyu, J.; Fujisawa, M.; Hiiragi, W.; Ishibashi, T. Previous Announcement Method Using 3D CG Face Interface for Mobile Robot. J. Robot. Mechatron. 2020, 32, 97–112. [Google Scholar] [CrossRef]
- Kelley, J.F. An Empirical Methodology for Writing User-friendly Natural Language Computer Applications. In Proceedings of the the SIGCHI Conference on Human Factors in Computing Systems, Boston, MA, USA, 12–15 December 1983; pp. 193–196. [Google Scholar]
- Bartneck, C.; Croft, E.; Kulic, D. Measurement instruments for the anthropomorphism, animacy, likeability, perceived intelligence, and perceived safety of robots. Int. J. Soc. Robot. 2009, 1, 71–81. [Google Scholar] [CrossRef]
- Weiss, A.; Bartneck, C. Meta analysis of the usage of the Godspeed Questionnaire Series. In Proceedings of the 24th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN 2015), Kobe, Japan, 31 August–4 September 2015; pp. 381–388. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| State | Value of A | Value of I | Value of M |
|---|---|---|---|
| Awaken | |||
| Relaxed | |||
| Non-REM | |||
| REM |
| Library | ROS | TensorFlow | Scikit-Learn | OpenCV | Julius | Open JTalk |
|---|---|---|---|---|---|---|
| Version | Kinetic Kame | 1.12.0 | 0.20.1 | 3.3.1 | 4.3.1 | 1.07 |
| Computational Time | |
|---|---|
| Face detection | 0.14 [s] |
| Face classification | 0.07 [s] |
| Face detection & classification | 0.21 [s] (=4.77 [fps]) |
| With AIM | Without AIM | |
|---|---|---|
| Prepossessing | 1589.4 [s] | 1040.1 [s] |
| FaceNet | 791.7 [s] | 356.1 [s] |
| SVM | 7.88 [s] | 7.23 [s] |
| Precision | 100.0 [%] | 100.0 [%] |
| Section | Items | ||
|---|---|---|---|
| Anthropomorphism | Fake | - | Natural |
| Machinelike | - | Humanlike | |
| Unconscious | - | Conscious | |
| Artificial | - | Lifelike | |
| Moving rigidly | - | Moving elegant | |
| Animacy | Dead | - | Alive |
| Stagnant | - | Lively | |
| Mechanical | - | Organic | |
| Artificial | - | Lifelike | |
| Inert | - | Interactive | |
| Apathetic | - | Responsive | |
| Likeability | Dislike | - | Like |
| Unfriendly | - | Friendly | |
| Unkind | - | Kind | |
| Unpleasant | - | Pleasant | |
| Awful | - | Nice | |
| Perceived Intelligence | Incompetent | - | Competent |
| Ignorant | - | Knowledgeable | |
| Irresponsible | - | Responsible | |
| Unintelligent | - | Intelligent | |
| Foolish | - | Sensible | |
| Perceived Safety | Anxious | - | Relaxed |
| Agitated | - | Calm | |
| Quiescent | - | Surprised | |
| Scale | Call by Name | Call by Pronoun | |
|---|---|---|---|
| Anthropomorphism | Mean | 3.155 | 3.009 |
| Standard deviation | 0.617 | 0.683 | |
| Significance probability | 0.195 | ||
| Animacy | Mean | 3.568 | 3.409 |
| Standard deviation | 0.521 | 0.621 | |
| Significance probability | 0.226 | ||
| Likeability | Mean | 4.273 | 4.009 |
| Standard deviation | 0.544 | 0.606 | |
| Significance probability | 0.039 (*) | ||
| Perceived Intelligence | Mean | 4.036 | 3.927 |
| Standard deviation | 0.368 | 0.511 | |
| Significance probability | 0.117 | ||
| Perceived Safety | Mean | 3.727 | 3.636 |
| Standard deviation | 0.935 | 0.959 | |
| Significance probability | 0.701 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mikawa, M.; Chen, H.; Fujisawa, M. Face Memorization Using AIM Model for Mobile Robot and Its Application to Name Calling Function. Sensors 2020, 20, 6629. https://doi.org/10.3390/s20226629
Mikawa M, Chen H, Fujisawa M. Face Memorization Using AIM Model for Mobile Robot and Its Application to Name Calling Function. Sensors. 2020; 20(22):6629. https://doi.org/10.3390/s20226629
Chicago/Turabian StyleMikawa, Masahiko, Haolin Chen, and Makoto Fujisawa. 2020. "Face Memorization Using AIM Model for Mobile Robot and Its Application to Name Calling Function" Sensors 20, no. 22: 6629. https://doi.org/10.3390/s20226629
APA StyleMikawa, M., Chen, H., & Fujisawa, M. (2020). Face Memorization Using AIM Model for Mobile Robot and Its Application to Name Calling Function. Sensors, 20(22), 6629. https://doi.org/10.3390/s20226629