Data Prediction of Mobile Network Traffic in Public Scenes by SOS-vSVR Method


Abstract
:1. Introduction
2. Materials and Methods
2.1. Methods
2.1.1. Support Vector Regression Algorithm
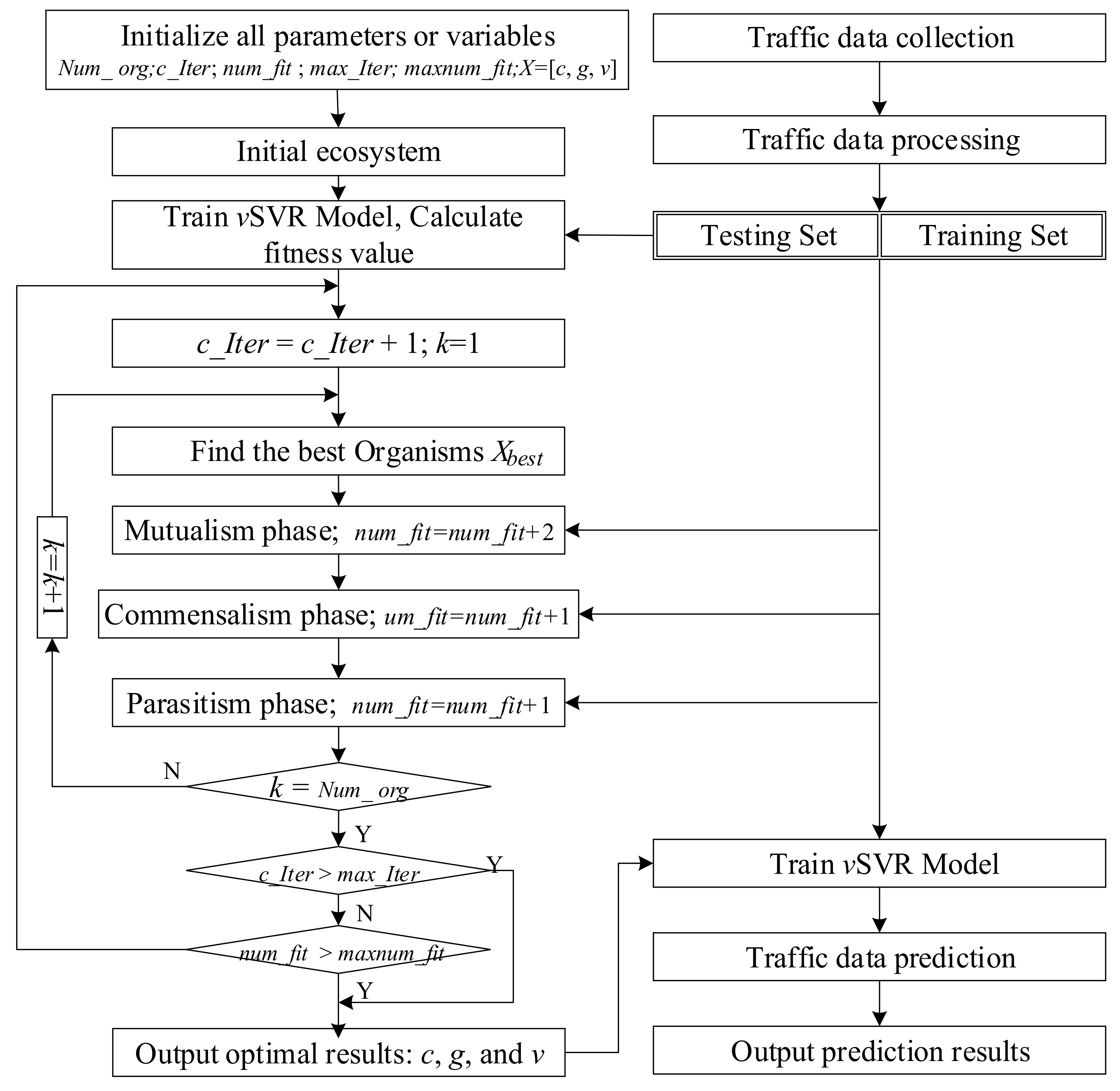
2.1.2. Symbiotic Organisms Search
- (1).
- Symbiosis
- (2).
- Features
- (3).
- Mutualism phase
- 1.
- Commensalism Phase
- 2.
- Parasitism Phase
- Step 1: Define and initialize the ecosystem population, and initialize all variables or parameters;
- Step 2: Find the best individual in the population;
- Step 3: and are selected randomly. Calculate the modified organism according to Equation (8), calculate the fitness value, and update the individual information;
- Step 4: is selected randomly. Calculate the modified organism according to Equation (9), calculate the fitness value, and update the individual information;
- Step 5: and are selected randomly. Modify the values of certain dimensions of organism i, creating a Parasite_Vector. Calculate the fitness value, compare it with the organism j, and choose to update or retain;
- Step 6: If the current creature is not the last creature in the ecosystem, go back to step 3;
- Step 7: Identify the end condition of the search. If no, go back to step 2; If yes, output the optimal results.
2.1.3. SOS-vSVR Algorithm
2.2. Materials
2.2.1. Experimental Data Collection
2.2.2. Data Processing
3. The Prediction of Traffic Data
3.1. Experimental Preparation
3.1.1. Experiments Setup
3.1.2. Prediction Model Evaluation Method
3.2. Application of SOS-vSVR in Traffic Data Prediction
3.3. Compared With Non-Optimal Regression Algorithms
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Economic Operation of Communications Industry in January–March 2019. Available online: http://www.miit.gov.cn/n1146285/n1146352/n3054355/n3057511/n3057518/c6802477/content.html (accessed on 23 July 2019).
- Xu, F.L.; Lin, Y.Y.; Huang, J.X.; Shi, H.Z.; Song, J.; Li, Y. Big Data Driven Mobile Traffic Understanding and Forecasting: A Time Series Approach. IEEE Trans. Serv. Comput. 2016, 9, 796–805. [Google Scholar] [CrossRef]
- Feng, J.; Chen, X.L.; Gao, R.; Zeng, M.; Li, Y. DeepTP: An End-to-End Neural Network for Mobile Cellular Traffic Prediction. IEEE Netw. 2018, 32, 108–115. [Google Scholar] [CrossRef]
- Qiu, C.; Zhang, Y.; Feng, Z.; Zhang, P.; Cui, S. Spatio-Temporal Wireless Traffic Prediction with Recurrent Neural Network. IEEE Wirel. Commun. Lett. 2018, 7, 554–557. [Google Scholar] [CrossRef]
- Li, J.; Wang, J.; Xiong, Z. Wavelet-Based Stacked Denoising Autoencoders for Cell Phone Base Station User Number Prediction. In Proceedings of the IEEE iThings and IEEE- GreenCom and IEEE- CPSCom and IEEE-SmartData, Chengdu, China, 15–18 December 2016; pp. 833–838. [Google Scholar]
- Ni, F.; Zang, Y.; Feng, Z. A study on cellular wireless traffic modeling and prediction using Elman Neural Networks. In Proceedings of the 2015 4th ICCSNT, Harbin, China, 19–20 December 2015; pp. 490–494. [Google Scholar]
- Dietterich, T.G. Machine Learning for Sequential Data: A Review; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Kinney, R.W., Jr. ARIMA and Regression in Analytical Review: An Empirical Test. Account. Rev. 1978, 53, 48–60. [Google Scholar]
- Mitchell, T.J.; Beauchamp, J.J. Bayesian variable selection in linear regression. J. Am. Stat. Assoc. 1988, 83, 1023–1032. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.J.; Robert, C.; Williamson, R.C.; Peter, L.B. New Support Vector Algorithms. Neural Comput. 2000, 12, 1207–1245. [Google Scholar] [CrossRef]
- Paliwal, M.; Kumar, A.U. Neural networks and statistical techniques: A review of applications. Expert Syst. Appl. 2009, 36, 2–17. [Google Scholar] [CrossRef]
- Mandic, D.P.; Chambers, J. Recurrent Neural Networks for Prediction: Learning Algorithms, Architectures and Stability; John Wiley & Sons, Inc.: New York, NY, USA, 2001. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, K.R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef] [Green Version]
- Harpham, C.; Dawson, C.W.; Brown, M.R. A review of genetic algorithms applied to training radial basis function networks. Neural Comput. Appl. 2004, 13, 193. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NA, USA, 2013; p. 314. [Google Scholar] [CrossRef]
- Wu, C.H.; Ho, J.M.; Lee, D.T. Travel-time prediction with support vector regression. IEEE Trans. Intell. Transp. Syst. 2004, 5, 276–281. [Google Scholar] [CrossRef] [Green Version]
- Santamaría-Bonfil, G.; Reyes-Ballesteros, A.; Gershenson, C. Wind speed forecasting for wind farms: A method based on support vector regression. Renew. Energy 2016, 85, 790–809. [Google Scholar] [CrossRef]
- Kaytez, F.; Taplamacioglu, M.C.; Cam, E.; Hardalac, F. Forecasting electricity consumption: A comparison of regression analysis, neural networks and least squares support vector machines. Int. J. Electr. Power Energy Syst. 2015, 67, 431–438. [Google Scholar] [CrossRef]
- Chen, R.; Liang, C.Y.; Hong, W.C.; Gu, D.X. Forecasting holiday daily tourist flow based on seasonal support vector regression with adaptive genetic algorithm. Appl. Soft. Comput. 2015, 26, 435–443. [Google Scholar] [CrossRef]
- Qiang, S.; Lu, W.; Du, D.S.; Chen, F.X.; Niu, B.; Chou, K.C. Prediction of the aquatic toxicity of aromatic compounds to tetrahymena pyriformis through support vector regression. Oncotarget 2017, 8, 49359–49369. [Google Scholar]
- Wang, F.K.; Mamo, T. A hybrid model based on support vector regression and differential evolution for remaining useful lifetime prediction of lithium-ion batteries. J. Power Sources 2018, 40, 49–54. [Google Scholar] [CrossRef]
- Wei, J.; Dong, G.; Chen, Z. Remaining Useful Life Prediction and State of Health Diagnosis for Lithium-Ion Batteries Using Particle Filter and Support Vector Regression. IEEE Trans. Ind. Electron. 2018, 65, 5634–5643. [Google Scholar] [CrossRef]
- Golkarnarenji, G.; Naebe, M.; Badii, K.; Milani, A.S.; Jazar, R.N.; Khayyam, H. Support vector regression modelling and optimization of energy consumption in carbon fiber production line Computers. Chem. Eng. 2018, 109, 276–288. [Google Scholar]
- Sivaramakrishnan, K.; Nie, J.J.; Klerk, A. Least squares-support vector regression for determining product concentrations in acid-catalyzed propylene oligomerization. Ind. Eng. Chem. Res. 2018, 57, 13156–13176. [Google Scholar] [CrossRef]
- Jiang, H.; He, W.W. Grey relational grade in local support vector regression for financial time series prediction. Expert Syst. Appl. 2012, 39, 2256–2262. [Google Scholar] [CrossRef]
- Peng, Y.; Albuquerque, P.H.M. The best of two worlds: Forecasting high frequency volatility for cryptocurrencies and traditional currencies with Support Vector Regression. Expert Syst. Appl. 2017, 97, 177–192. [Google Scholar] [CrossRef]
- Ghorbani, M.A.; Shamshirband, S.; Haghi, D.Z.; Azani, A.; Bonakdari, H.; Ebtehaj, I. Application of firefly algorithm-based support vector machines for prediction of field capacity and permanent wilting point. Soil Tillage Res. 2017, 172, 32–38. [Google Scholar] [CrossRef]
- Felipe, A.; Marco, M.; Miguel, O.; Alex, Z.; Claudio, F. A Method to Construct Fruit Maturity Color Scales based on Support Vector Machines for Regression: Application to Olives and Grape Seeds. J. Food Eng. 2015, 162, 9–17. [Google Scholar]
- Cheng, M.Y.; Prayogo, D. Symbiotic organisms search: A new metaheuristic optimization algorithm. Comput. Struct. 2014, 139, 98–112. [Google Scholar] [CrossRef]
- Das, S.; Bhattacharya, A. Symbiotic organisms search algorithm for short-term hydrothermal scheduling. Ain Shams Eng. J. 2018, 9, 499–516. [Google Scholar] [CrossRef] [Green Version]
- Ezugwu, A.E.; Prayogo, D. Symbiotic organisms search algorithm: Theory, recent advances and applications. Expert Syst. Appl. 2018, 119, 184–209. [Google Scholar] [CrossRef]
- Ezugwu, A.E.S.; Adewumi, A.O.; Frîncu, M.E. Simulated annealing based symbiotic organisms search optimization algorithm for traveling salesman problem. Expert Syst. Appl. 2017, 77, 189–210. [Google Scholar] [CrossRef]
- Cheng, M.Y.; Prayogo, D.; Tran, D.H. Optimizing multiple-resources leveling in multiple projects using discrete symbiotic organisms search. J. Comput. Civ. Eng. 2015, 30, 04015036. [Google Scholar] [CrossRef] [Green Version]
- Verma, S.; Saha, S.; Mukherjee, V. A novel symbiotic organisms search algorithm for congestion management in deregulated environment. J. Exp. Theor. Artif. Intell. 2015, 29, 59–79. [Google Scholar] [CrossRef]
- Çelik, E.; Öztürk, N. A hybrid symbiotic organisms search and simulated annealing technique applied to efficient design of PID controller for automatic voltage regulator. Soft Comput. 2018, 22, 8011–8024. [Google Scholar] [CrossRef]
- Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl. Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, W.D.; Jiao, L.C. Wavelet support vector machine. IEEE Trans. Syst. 2004, 34, 34–39. [Google Scholar] [CrossRef] [PubMed] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Parameter | Value |
|---|---|---|
| SOS | max_Iter; | 30 |
| maxnum_fit | 100 | |
| Number of organisms | 40 | |
| PSO | Acceleration constants | [1.7; 1.5] |
| Inertia w | [0.9, 0.75] | |
| Generations | 30 | |
| Number of particles | 40 | |
| MFO | b | 1 |
| Iterations | 30 | |
| Number of search agents | 40 | |
| SOS/PSO /MFO-vSVR | lbcgv | [0.1; 0.001; 0.01] |
| ubcgv | [100; 10; 1] | |
| SOS/PSO /MFO-SVR | lbcg | [0.1; 0.001] |
| ubcg | [100; 10] |
| Algorithm | Time Steps (k) | Train | Test | c | g | v | Optimization Time (s) | ||
|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAPE | RMSE | MAPE | ||||||
| SOS-vSVR | 26 | 0.0332 | 9.25% | 0.0409 | 12.36% | 3.28 | 0.2602 | 0.837 | 298.25 |
| MFO-vSVR | 26 | 0.0333 | 9.43% | 0.0408 | 12.19% | 5.84 | 0.1969 | 0.776 | 1433.11 |
| PSO-vSVR | 26 | 0.0346 | 9.81% | 0.0415 | 12.37% | 57.12 | 0.0557 | 0.891 | 1189.03 |
| SOS-SVR | 24 | 0.0432 | 17.38% | 0.0476 | 20.61% | 63.73 | 0.0692 | — | 2.94 |
| MFO-SVR | 24 | 0.0432 | 17.43% | 0.0475 | 20.54% | 100.00 | 0.0568 | — | 30.37 |
| PSO-SVR | 24 | 0.0432 | 17.30% | 0.0476 | 20.51% | 64.83 | 0.0675 | — | 23.16 |
| Algorithm | Optimal Time Step (k) | Train | Test | ||
|---|---|---|---|---|---|
| RMSE | MAPE | RMSE | MAPE | ||
| vBLR | 26 | 0.0429 | 13.79% | 0.0472 | 15.98% |
| ELM | 27 | 0.0371 | 12.42% | 0.0426 | 14.35% |
| εSVR | 24 | 0.0554 | 39.05% | 0.0624 | 43.41% |
| SOS-εSVR | 24 | 0.0432 | 17.38% | 0.0476 | 20.61% |
| vSVR | 26 | 0.0402 | 12.25% | 0.0457 | 14.23% |
| SOS-vSVR | 26 | 0.0332 | 9.25% | 0.0409 | 12.36% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, X.; Lai, W.; Chen, H.; Fang, S. Data Prediction of Mobile Network Traffic in Public Scenes by SOS-vSVR Method. Sensors 2020, 20, 603. https://doi.org/10.3390/s20030603
Zheng X, Lai W, Chen H, Fang S. Data Prediction of Mobile Network Traffic in Public Scenes by SOS-vSVR Method. Sensors. 2020; 20(3):603. https://doi.org/10.3390/s20030603
Chicago/Turabian StyleZheng, Xiaoliang, Wenhao Lai, Hualiang Chen, and Shen Fang. 2020. "Data Prediction of Mobile Network Traffic in Public Scenes by SOS-vSVR Method" Sensors 20, no. 3: 603. https://doi.org/10.3390/s20030603